本文介绍了如何向边缘节点部署基于自定义推理框架(非 Triton 框架)的模型服务。自定义框架在服务大语言、视觉语言等模型上更具优势。
预置推理框架镜像
推理框架提供了模型的运行环境。要为模型应用自定义推理框架,您必须提供自定义框架的镜像地址。边缘智能在部署您的模型时,会先自动拉取镜像进行安装,然后再部署模型。
边缘智能预置了一些来自第三方的推理框架镜像,方便您直接使用;若预置镜像无法满足您的需求,请自行准备好推理框架镜像。
下表罗列了边缘智能预置的推理框架。预置推理框架均来自第三方开源系统。在选择框架时,请注意以下内容:
- 不同推理框架有不同的安装要求。选择特定框架时,请自行评估边缘节点是否满足其安装要求。
- 不同推理框架支持的模型不同。选择特定框架时,请自行评估要部署的模型是否被支持。
推理框架 | 简介 | 预置 |
|---|---|---|
LMDeploy |
|
|
vLLM |
|
|
TGI |
|
|
前提条件
- 您已经为项目绑定了边缘节点。相关操作,请参见绑定节点。
- 如果您使用边缘节点型 aPaaS 工具,则 aPaaS 工具必须是 高级版。
边缘节点 - 基础版 aPaaS 工具不包含边缘推理功能。更多信息,请参见资源包(aPaaS 工具)计费说明。 - 如果您要部署自定义模型,您必须完成以下任务:创建自定义模型并为自定义模型创建和发布版本。相关操作,请参见创建自定义模型、创建一个版本。
操作步骤
登录边缘智能控制台。
在左侧导航栏,从 我的项目 下拉列表选择一个项目。
- 在左侧导航栏,选择 边缘推理 > 模型服务。
- 单击 自定义框架 页签,然后单击 部署模型服务。
- 在 部署模型服务 页面,配置以下参数,然后单击 确认。
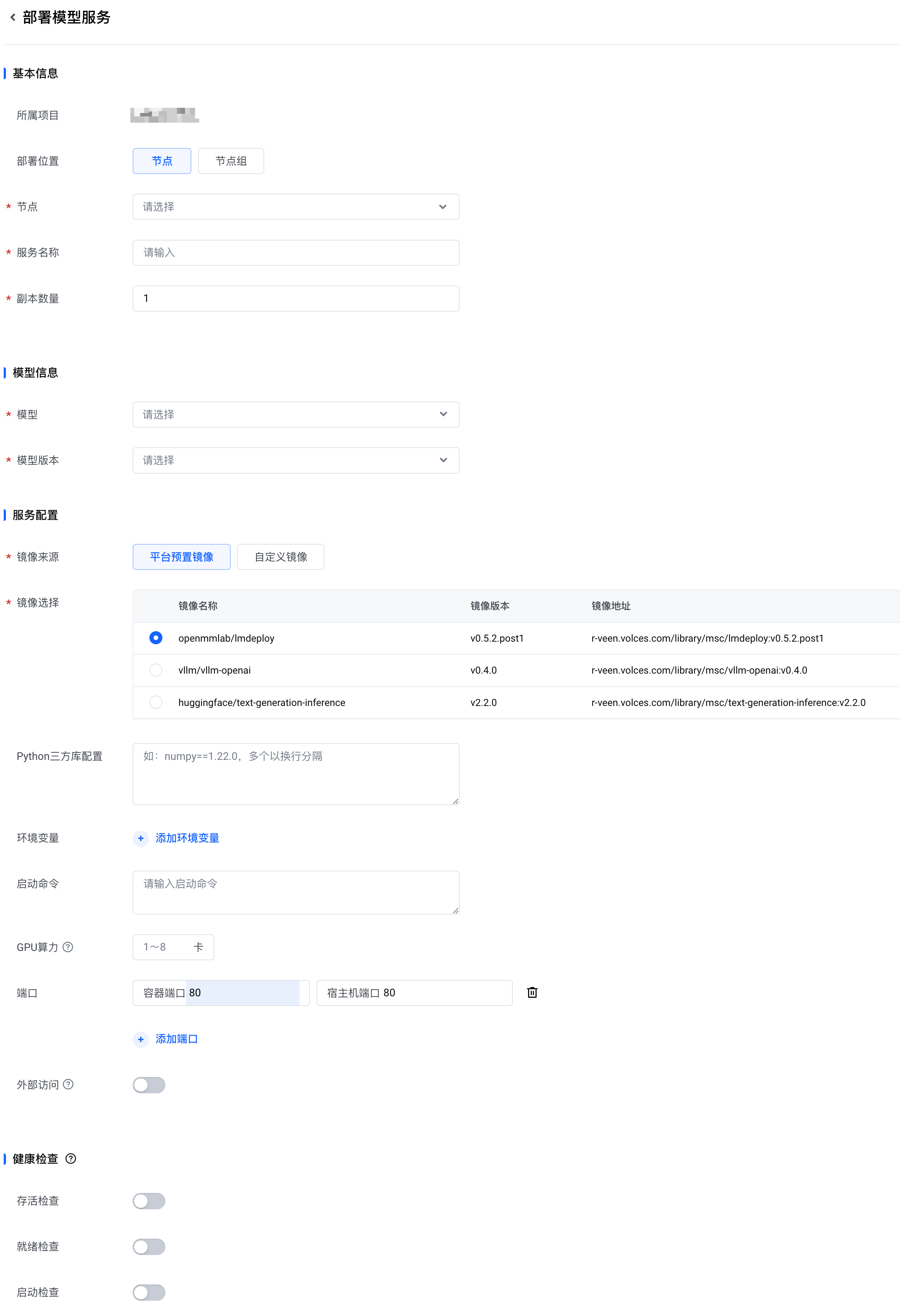
完成以上操作后,您可以在 模型服务 列表看到刚刚部署的模型服务。此时,模型服务的状态是 部署中。您可以将光标放置在状态旁边的问号图标上,了解部署进度。
- 当模型服务的状态变为 运行中,表示模型服务已经部署成功。
- 如果模型服务的状态是 部署失败,您可以将光标放置在 部署失败 上,然后单击 查看原因,以获取具体的错误消息。
配置说明
| 区域 | 参数 | 说明 |
|---|---|---|
| 基本信息 | 所属项目 | 默认为当前选择的项目。 |
部署位置 | 选择将模型服务部署到指定的 节点 或 节点组。 | |
节点 | 说明 只有当 部署位置 为 节点 时,该参数才会出现。 选择一个或多个节点,将模型服务部署到指定的节点。 | |
节点组 | 说明 只有当 部署位置 为 节点组 时,该参数才会出现。 选择一个节点组,将模型服务部署到指定的节点组。
| |
服务名称 | 为模型服务设置一个名称。您可以使用以下字符:英文字母、数字、汉字、下划线(_)和连字符(-)。请注意以下规则:
| |
副本数量 | 设置要创建的副本数量。取值范围:1~10。默认值:1。 | |
模型信息 | 模型 | 选择要使用的模型。您可以选择边缘智能的官方模型,也可以选择您创建的自定义模型。 |
模型版本 | 选择要使用的模型版本。 | |
服务配置 | 镜像来源 | 从以下两种推理框架镜像来源中选择一种:
|
镜像选择 | 说明 当 镜像来源 是 平台预置镜像 时,该配置项才会出现。 选择一个预置镜像。关于不同镜像的介绍,请参见预置推理框架镜像。 | |
镜像地址 | 说明 当 镜像来源 是 自定义镜像 时,该配置项才会出现。 输入您的推理框架镜像的 URL 地址。地址需符合 URL 格式。长度不超过 1024 个字符。 说明 您可以将制作好的应用镜像托管在某个镜像仓库,获取镜像的 URL。我们推荐您将镜像托管到火山引擎镜像仓库。 若您提供的私有镜像仓库地址,请单击 输入,并提供您的 仓库密钥。否则,边缘智能无法访问您的镜像,这将导致服务部署失败。仓库密钥 包含 用户名 和 密码。 注意 不使用免密组件,且需要拉取私有镜像时,必须配置 仓库密钥。 | |
Python三方库配置 | 设置您希望在边缘节点上安装的第三方 Python 库。格式为
| |
环境变量 | 您可以手动设置环境变量。Kubernetes 在创建 Pod 时,会将环境变量的信息注入到容器中。 | |
启动命令 | 输入容器启动前运行的命令。多行命令使用换行符分隔。 | |
GPU算力 | 设置允许此模型服务使用的 GPU 数量。取值范围:1~8。 注意 要使用 GPU 算力调度能力,必须确保您的节点已经启用了 NVIDIA device plugin 组件。更多信息,请参见绑定节点。 | |
端口 | 将容器内端口与宿主机(即边缘节点)的端口进行映射。单击 + 添加端口映射。可以添加多个端口映射。 | |
外部访问 | 设置是否允许从集群外部访问推理服务。开启外部访问后,可以在集群外部通过 注意 要启用外部访问,必须先设置 端口。 | |
健康检查 | 您可选择启用 Kubernetes 健康检查,即配置存活、就绪、启动探针。
三类探针具有相同的配置项,具体说明如下。 | |
检查方式 |
| |
时间设置 |
| |
阈值设置 |
| |