本实践提供了一种针对 DeepSeek 模型调用的容灾方案。您可以通过边缘大模型网关接入主流模型提供商的 DeepSeek 模型并配置灵活的调用策略,实现多模型间的故障转移,确保服务高可用性。
方案介绍
业务痛点
您的应用接入了主流模型提供商的 DeepSeek 模型服务,但客户端用户在调用模型时频繁遇到失败问题,严重影响了使用体验。
方案概述
边缘大模型网关提供与 OpenAI 规范兼容的 API 和 SDK,并支持市面上主流模型提供商平台。通过边缘大模型网关,您可以统一调用不同模型提供商的模型(包括 DeepSeek 模型)。此外,边缘大模型网关支持灵活的调用策略配置,帮助您实现以下功能:
- 故障转移:当主模型调用失败时,(网关)自动切换到备用模型。
- 自动重试:当单次模型请求失败时,(网关)自动重试最多三次。
- 请求超时定义:允许自定义单次模型请求的超时时间。
故障转移机制
边缘大模型网关支持“一主多备”架构。您可以配置一个 DeepSeek 模型列表,其中首个模型为主模型,其余为备模型。当主模型调用失败时,网关会按顺序调用备模型,确保服务的高可用性。
模型调用顺序设置建议
在配置模型调用顺序时,建议综合考虑模型性能、成本和稳定性:
- 优先选择满足日常需求且成本适中的模型作为主模型。
- 以稳定性较高(性能可能较低)的模型作为兜底备模型。
- 在满足需求的前提下,优先使用低成本模型以控制成本。
示例:模型选择策略
有的模型提供商提供了多种不同尺寸的 DeepSeek 模型蒸馏版本:
- 大尺寸模型:在资源充足的情况下表现稳定,尤其适合复杂任务,但在资源不足时可能出现性能波动。
- 小尺寸模型:在资源有限的环境中更稳定,但在复杂任务上可能表现不佳。
从稳定性角度出发,建议选择满足日常需求的模型作为主模型;以较小尺寸的蒸馏版本模型作为备模型。按模型尺寸从大到小依次排列。这样当主模型故障时,(网关)调用尺寸较小的备模型,确保服务持续可用。
注意事项
仅支持相同类型的模型之间进行故障转移。例如:
- DeepSeek R1 和 DeepSeek R1 蒸馏版本之间可以故障转移。
- DeepSeek V3(对话模型) 和 DeepSeek R1(推理模型) 之间不支持故障转移。
支持的 DeepSeek 模型
边缘大模型网关支持以下模型提供商的 DeepSeek 模型系列:
- 字节跳动火山方舟
- DeepSeek 开放平台
- 阿里云 DashScope 模型服务灵积
- 硅基流动 SiliconCloud
- 腾讯云大模型知识引擎 LKE
- 百度千帆 ModelBuilder
通过边缘大模型网关调用上述第三方平台的 DeepSeek 模型时,将消耗您在对应平台上的资源额度。此外,边缘大模型网关平台还预置了(基于字节跳动火山方舟的)DeepSeek 模型系列,您可以使用平台提供的免费资源额度进行测试和体验。
如需查看完整的 DeepSeek 模型列表,请参见支持的调用渠道。
示例场景
在本教程中,您将通过边缘大模型网关使用两家模型提供商的 DeepSeek 推理模型,并在业务应用中调用边缘大模型网关 API,实现模型调用及故障转移功能。
示例模型:
- 自有三方模型:硅基流动平台的 DeepSeek-R1-Distill-Qwen-32B
- 平台预置模型:边缘大模型网关平台预置的 DeepSeek-R1-Distill-Qwen-7B
准备工作
- 若完成企业实名认证,默认拥有网关访问密钥配额。
- 若仅完成个人实名认证,需额外提交网关访问密钥配额申请。相关操作,请参见申请提升网关访问密钥数量。
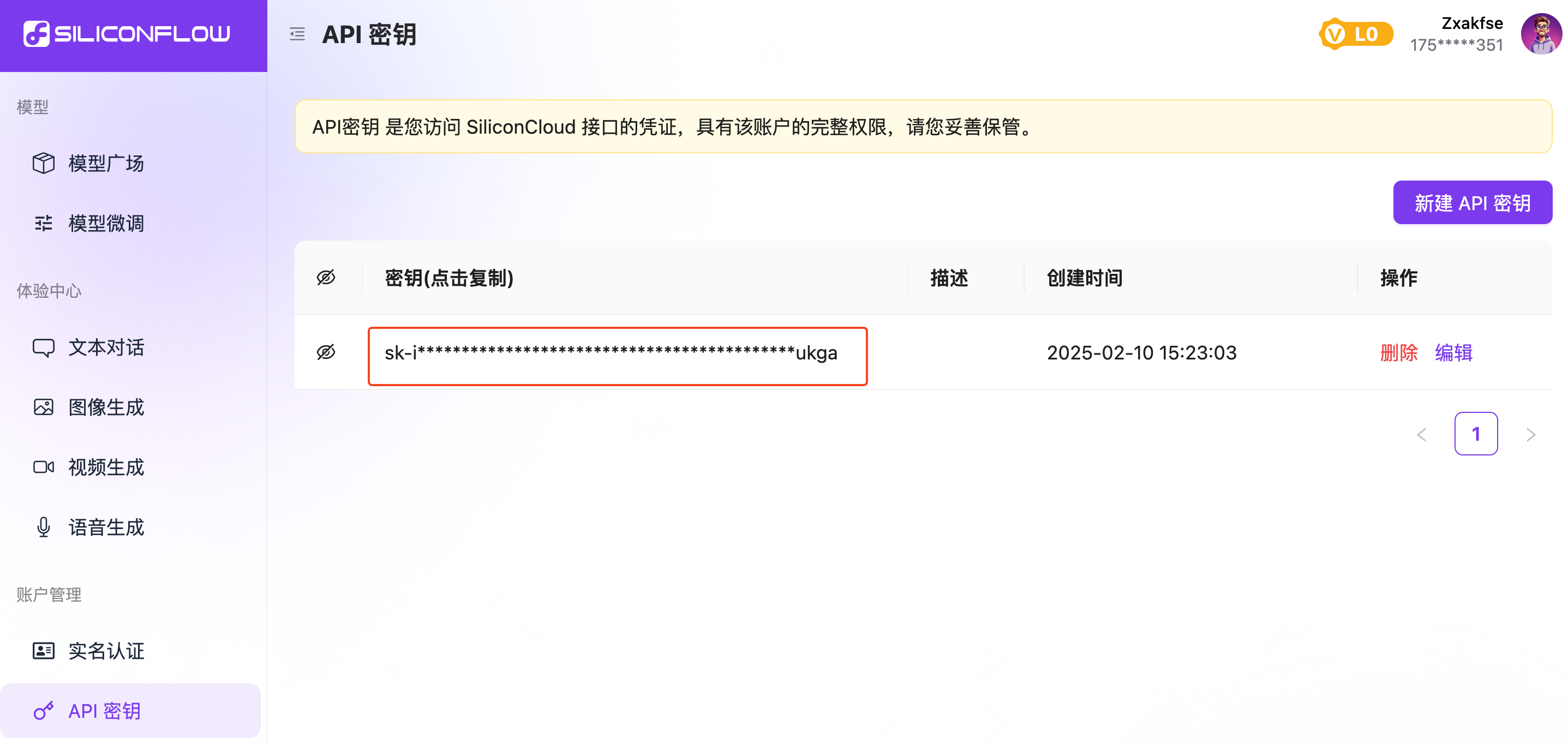
获取第三方模型调用密钥。
- 在支持的第三方模型提供商平台注册账号,并获得模型调用密钥。
- 本文以硅基流动平台的 DeepSeek 模型为例。因此,需先在硅基流动平台注册账号,并获取 API 密钥。
操作流程

配置模型调用密钥。
根据您使用的 DeepSeek 模型,在边缘大模型网关控制台中配置模型调用密钥,以创建调用第三方 DeepSeek 模型的“调用渠道”。创建网关访问密钥并配置策略。
创建边缘大模型网关访问密钥,关联您的 DeepSeek 模型调用渠道,并按需配置模型调用策略(例如,设置多家 DeepSeek 模型间的故障转移规则)。调用边缘大模型网关 API。
在您的应用代码中直接调用边缘大模型网关 API,由网关向模型提供商发起请求,并将模型响应返回给您的应用。
步骤一:配置模型调用密钥
登录边缘大模型网关控制台。
在左侧导航栏,选择 模型配置管理 > 大模型管理。
在 自有三方模型 标签页,找到 硅基流动SiliconCloud,点击 操作 列的 创建调用渠道。
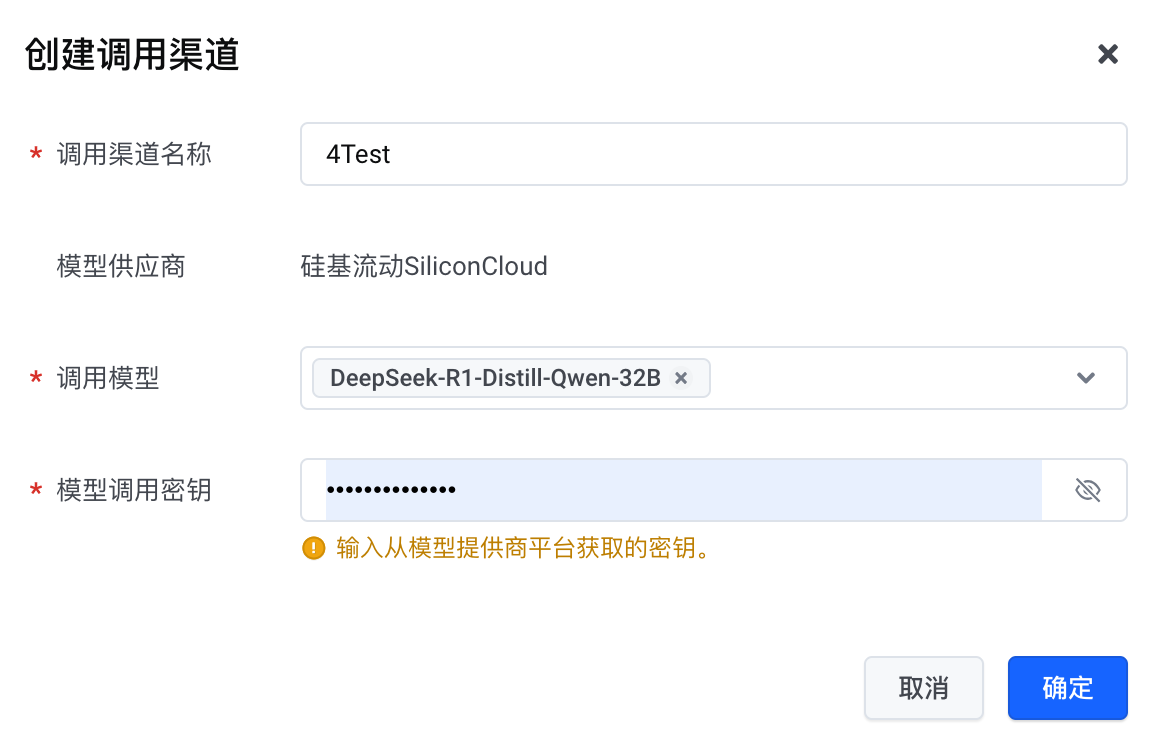
在 创建调用渠道 对话框,完成以下配置,然后点击 确定。
- 调用渠道名称:
为该渠道设置一个显示名称。 - 调用模型:
选择 DeepSeek-R1-Distill-Qwen-32B。注意
确保您拥有调用该模型的权限。建议先在模型提供商平台测试,确认模型可用。
- 模型调用密钥:
填写从硅基流动平台获取的 API 密钥。
- 调用渠道名称:
调用渠道创建成功后,硅基流动SiliconCloud 的 调用渠道 列将显示 1。点击该数字,可以查看和管理(如编辑、删除)调用渠道。

步骤二:创建网关访问密钥并配置策略
在 硅基流动SiliconCloud 所在行,点击 创建网关访问密钥,并完成以下配置:
创建网关访问密钥:设置基本信息与选择模型。
名称:
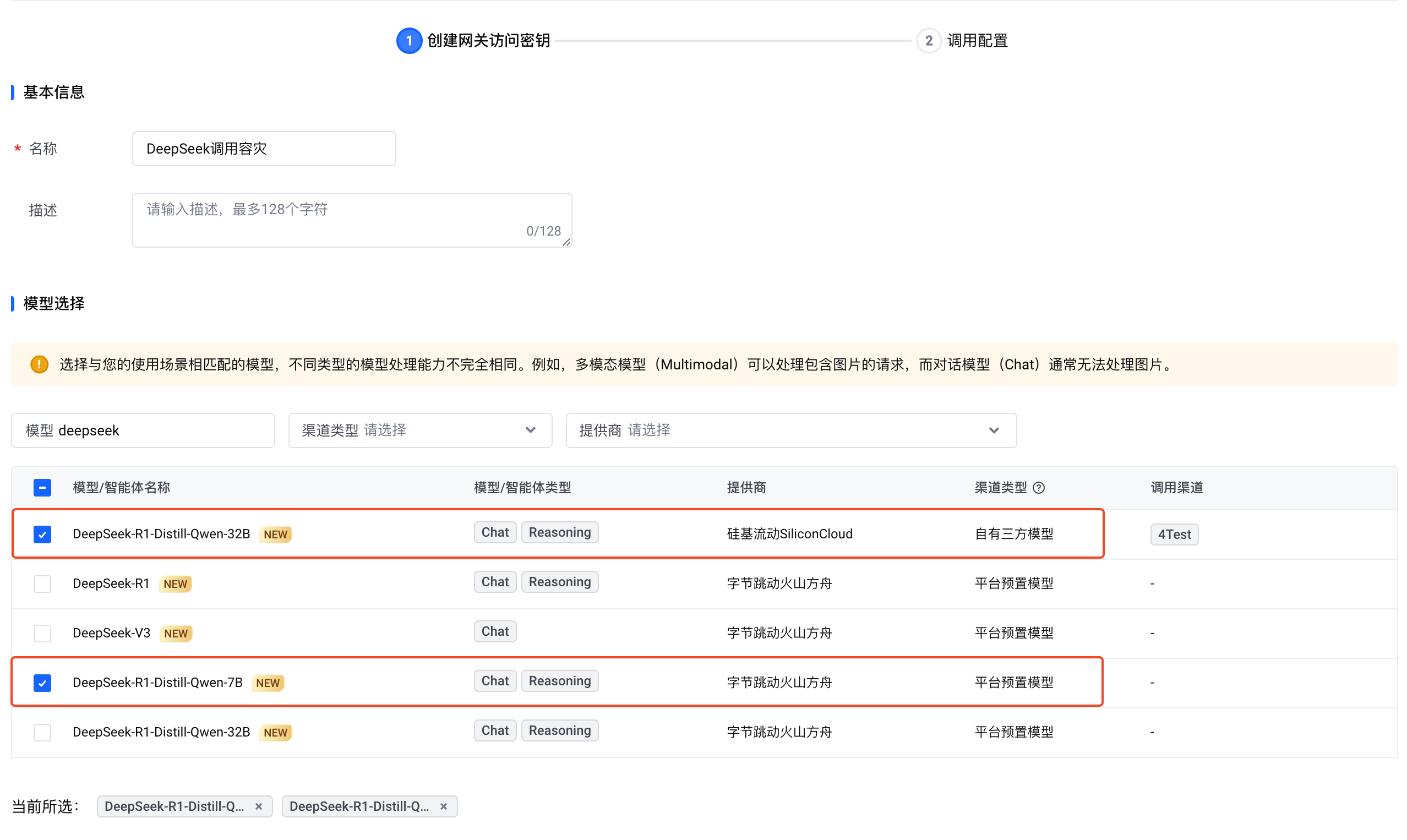
为该密钥设置一个显示名称。模型选择:
选择以下两个 DeepSeek 模型:- 自有三方模型:DeepSeek-R1-Distill-Qwen-32B(硅基流动)
- 平台预置模型:DeepSeek-R1-Distill-Qwen-7B(字节跳动火山方舟)
说明
可使用列表上方的过滤器快速查找所需模型。
调用配置:设置调用策略及高级配置。
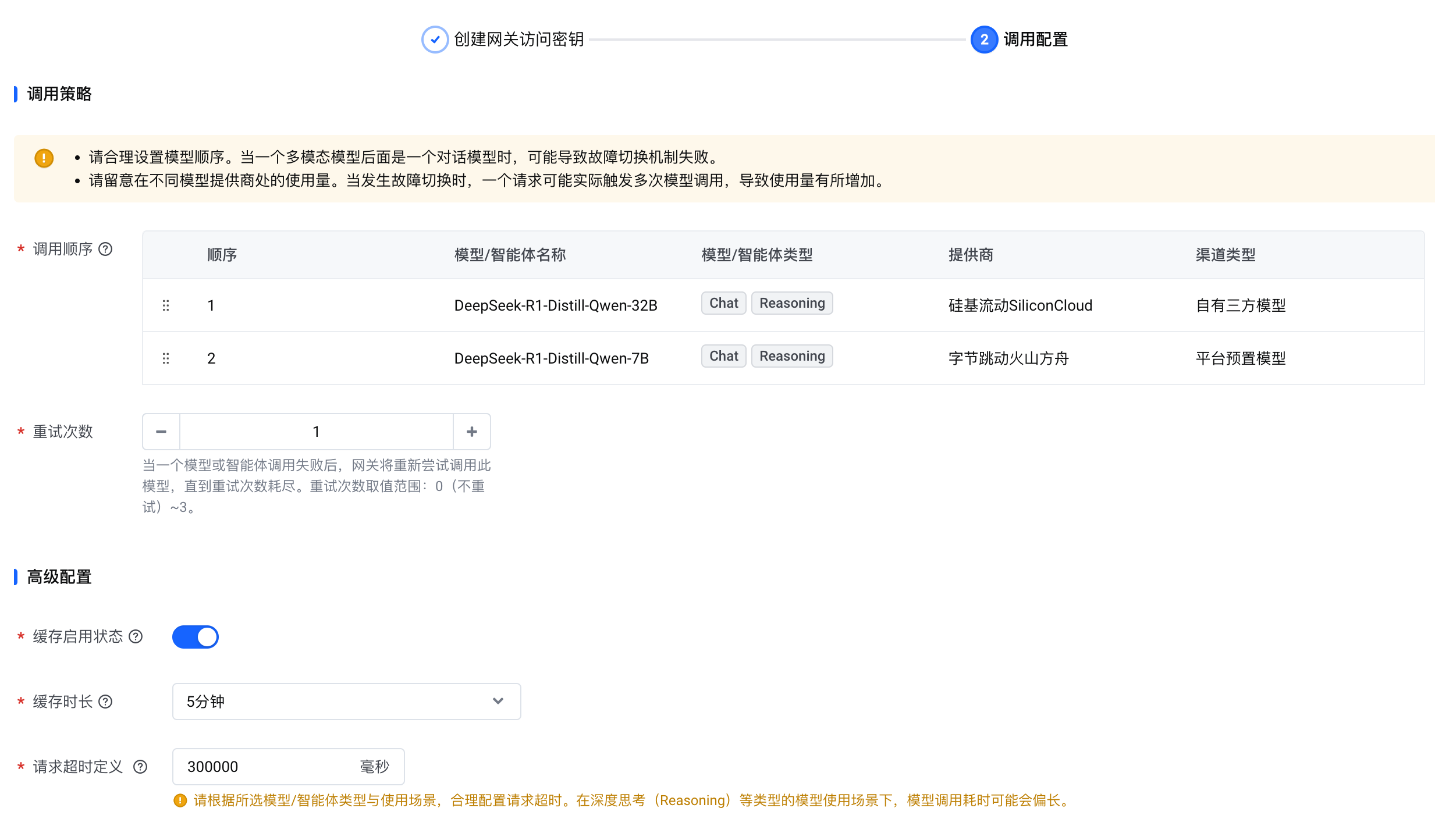
调用顺序:
将自有三方模型(DeepSeek-R1-Distill-Qwen-32B)置于首位,平台预置模型(DeepSeek-R1-Distill-Qwen-7B)作为兜底。重试次数:
设置模型请求失败时的自动重试次数。示例:若重试次数为 1,则请求失败或超时后会重试一次;若重试仍失败,则判定为调用失败。
缓存启用状态 和 缓存时长:
无需修改默认配置。开启缓存可加速模型响应。请求超时定义:
设置请求超时时长。建议为推理模型设置较长的超时时长。初始可使用默认配置,后续根据实际测试调整。
步骤三:调用边缘大模型网关 API
成功创建网关访问密钥后,可基于 OpenAI 规范调用边缘大模型网关 API。您可以从控制台获取网关访问密钥 API key 和示例代码(Curl、Python)。

点击 操作 列的 查看密钥,在弹出的对话框复制网关访问密钥。
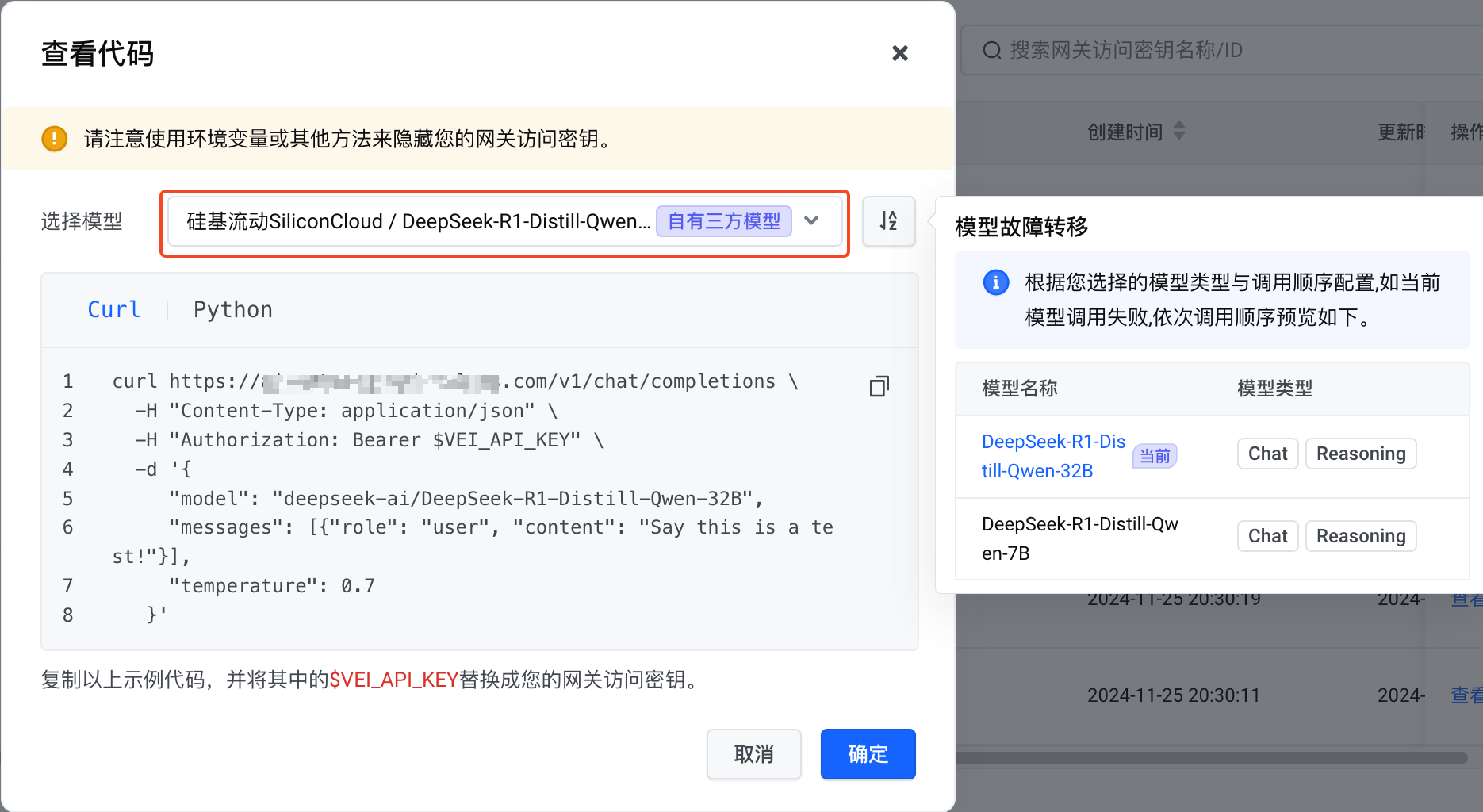
点击 操作 列的 查看代码,在 查看代码 对话框,选择自有三方模型(硅基流动 DeepSeek 模型),查看 Curl 和 Python 示例代码。
方案验证
下面将基于 Curl 示例代码验证容灾效果。
打开本地计算机的 Shell 工具(如 macOS 系统的终端、Windows 的 PowerShell)。
将获取的 Curl 示例代码中的
$VEI_API_KEY替换为您复制的网关访问密钥,然后将示例代码粘贴到 Shell 工具中运行。说明
您可以修改 Curl 示例代码中
content的值,以自定义向模型提出的问题。
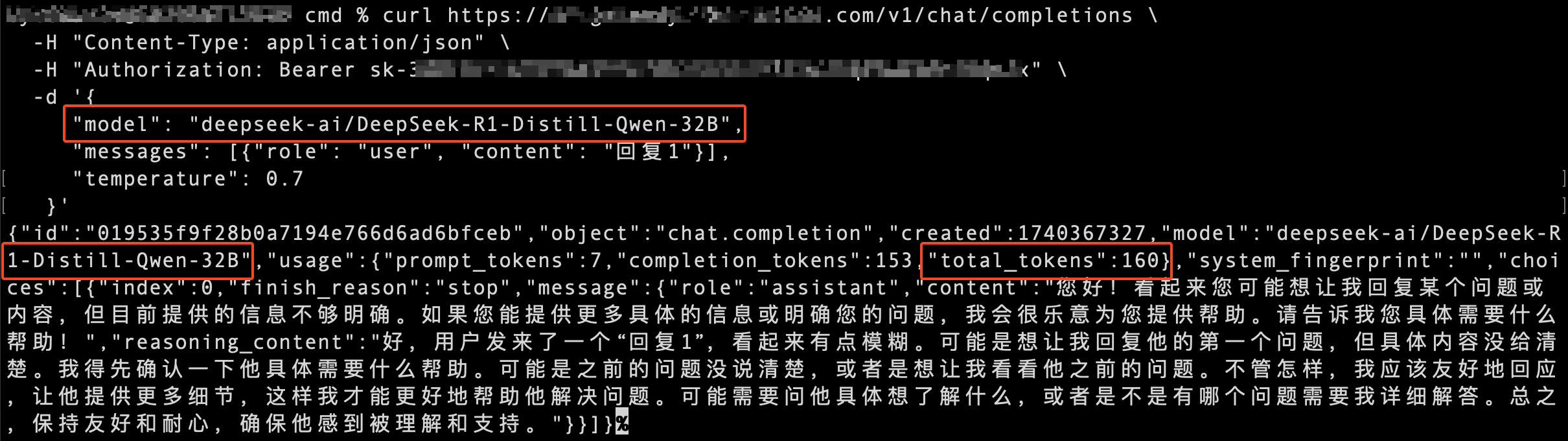
示例一:主模型调用成功
在此示例中,主模型(硅基流动 DeepSeek 32B 模型)成功回答了提问。API 响应中显示本次请求消耗的 tokens 数量为 160。注意
边缘大模型网关 API 仅返回最后一次成功请求的结果,结果中包含本次请求的 tokens 消耗数量。(若所有请求失败,则返回错误结果。)由于存在自动重试和故障转移机制,在请求成功前可能已发生多次失败或超时的模型请求,这些请求也会在模型提供商平台上产生 tokens 消耗。
因此,第三方模型提供商平台上统计的 tokens 消耗数量可能多于边缘大模型网关 API 返回的 tokens 数量。
示例二:主模型调用失败,备模型调用成功
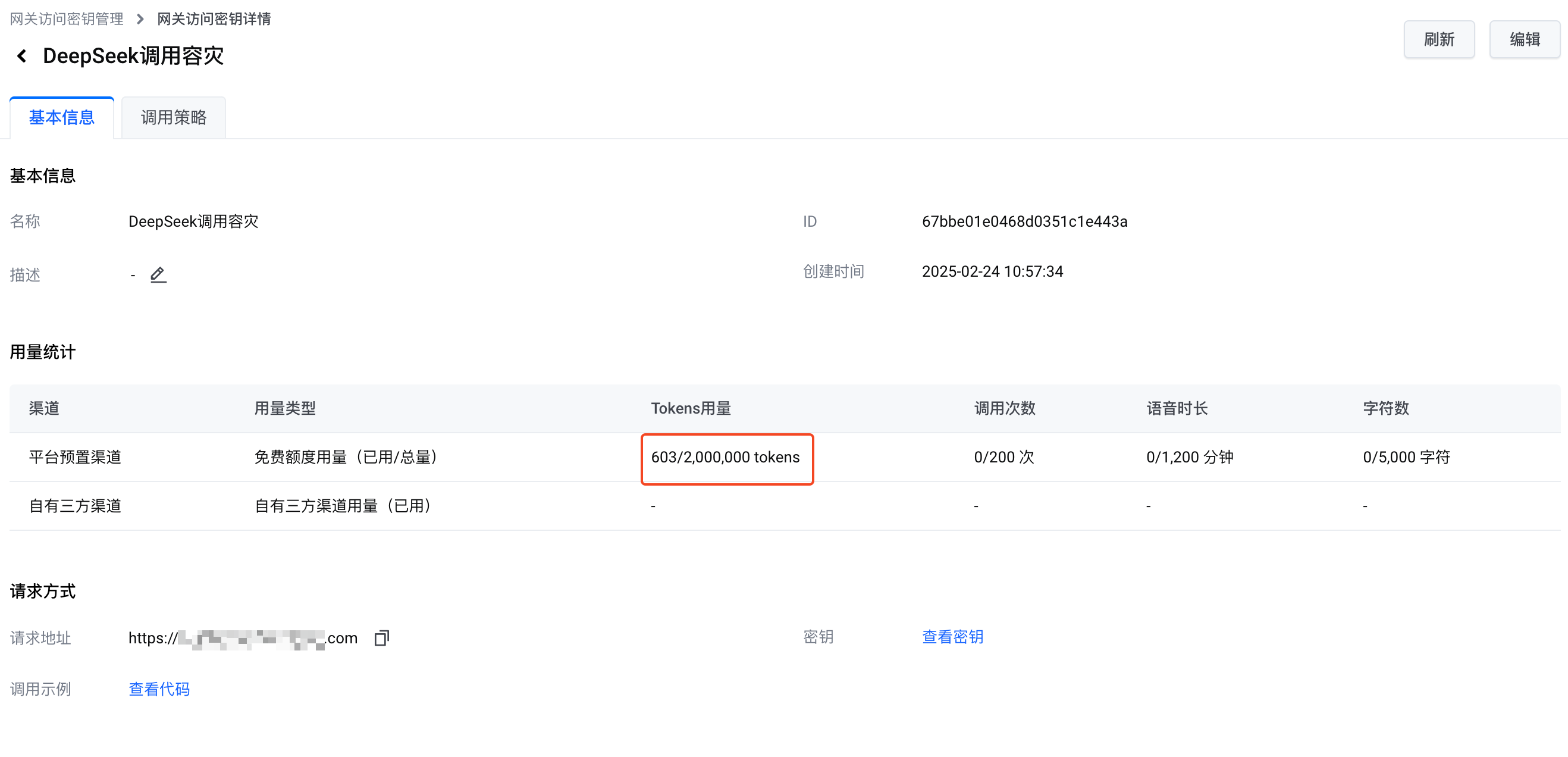
在此示例中,主模型(硅基流动 DeepSeek 32B 模型)调用失败,边缘大模型网关自动切换到备模型(平台预置 DeepSeek 7B 模型),并由备模型回答了提问。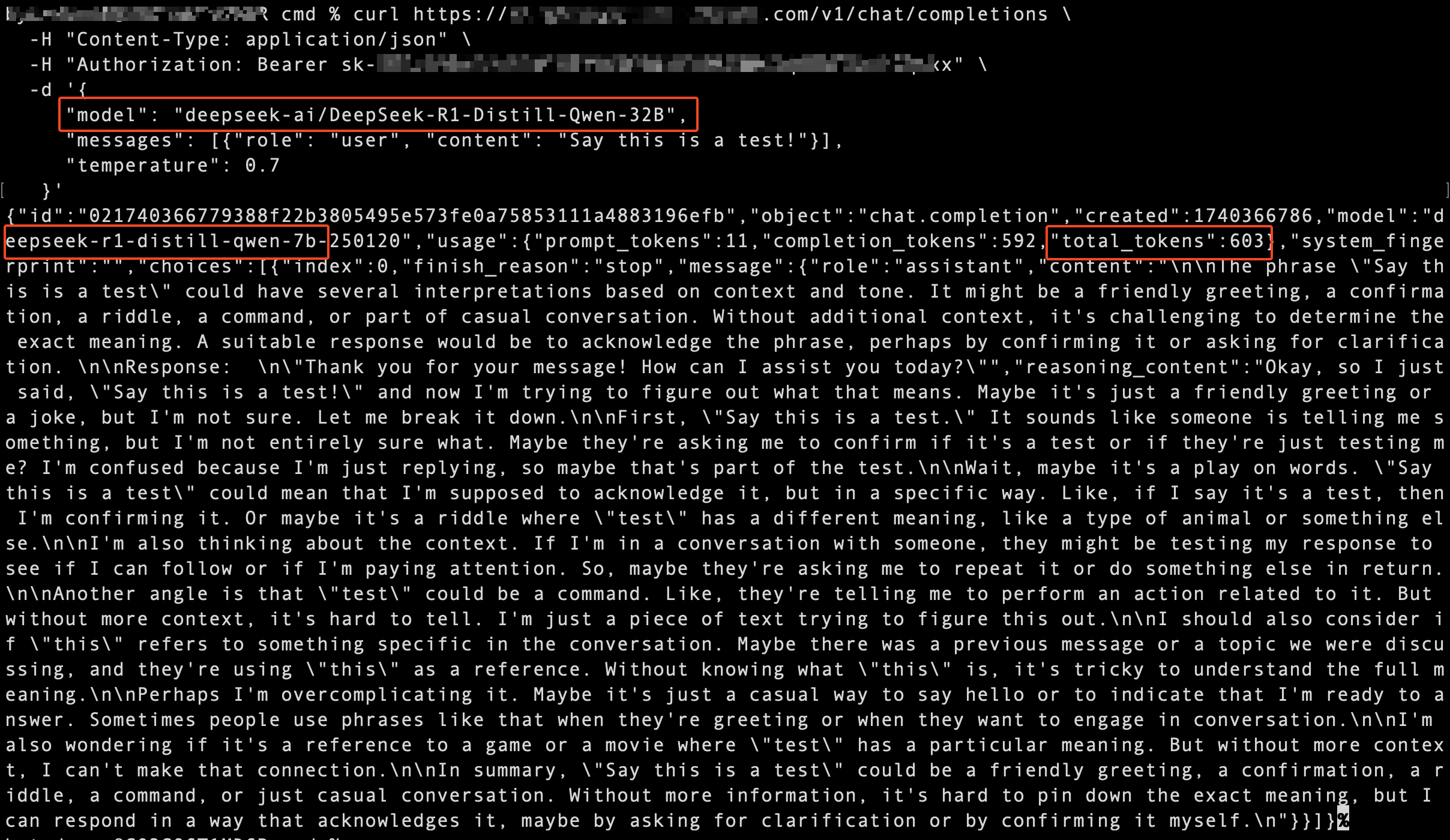
调用平台预置模型消耗的 tokens 数量为 603,与网关访问密钥 用量统计 中的免费 tokens 使用量一致。
以上示例表明,通过边缘大模型网关调用不同模型提供商的 DeepSeek 模型,成功实现了故障转移功能。