本文介绍了如何使用边缘大模型网关平台预置的语音对话智能体。
能力介绍
边缘大模型网关平台预置了一个语音对话智能体。该智能体适用于语音对话场景,具备以下能力:
- 中文、英文语音输入与输出。
- 保留最多 10 轮对话历史。
- 【New】未收到语音时返回语音应答。
- 【New】对话支持打断。
说明
对话打断只适用于单独使用语音对话智能体场景。对于组合使用语音对话智能体与您自己的 Coze 智能体场景,暂不支持对话打断。
- 【New】与第三方智能体组合使用。
- 【New】支持 WebSocket 连接保活。
使用流程
语音对话智能体支持两种使用模式:单独使用、与您在 Coze 平台搭建的智能体组合使用。
场景1:单独使用语音对话智能体
- 参考调用平台预置智能体创建一个网关访问密钥,并为该密钥绑定 语音对话智能体。
- 参考查看密钥(API Key),获取网关访问密钥的 API key。
- 调用 Realtime API 实现与智能体进行语音对话。关于 API 的说明,请参见 Reamtime API。
场景2:组合使用语音对话智能体和您自己的 Coze 智能体
完成第三方智能体调用准备工作,具体包括:
创建一个网关访问密钥。在 模型选择 中同时选择:
- 您的 Coze 智能体(渠道类型 为 自有三方智能体)
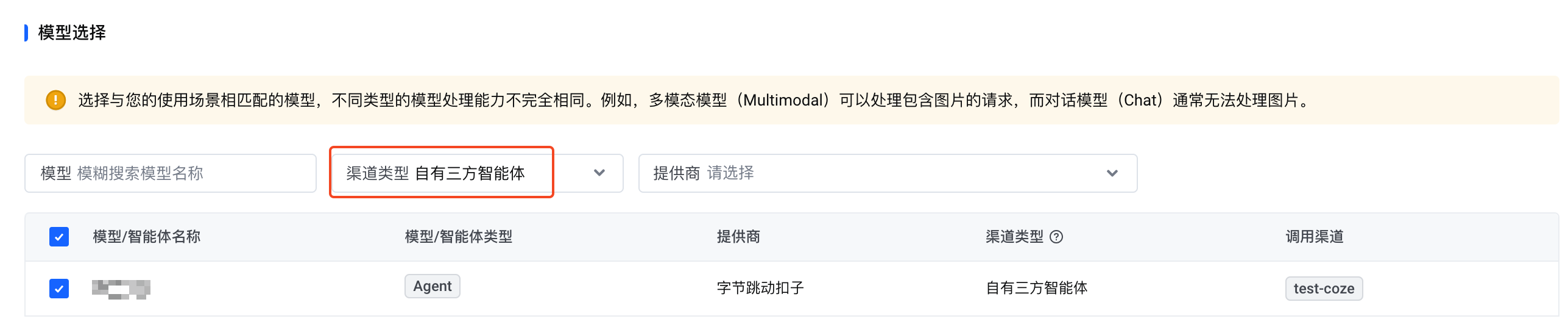
- 平台预置的 语音对话智能体(渠道类型 为 平台预置智能体)
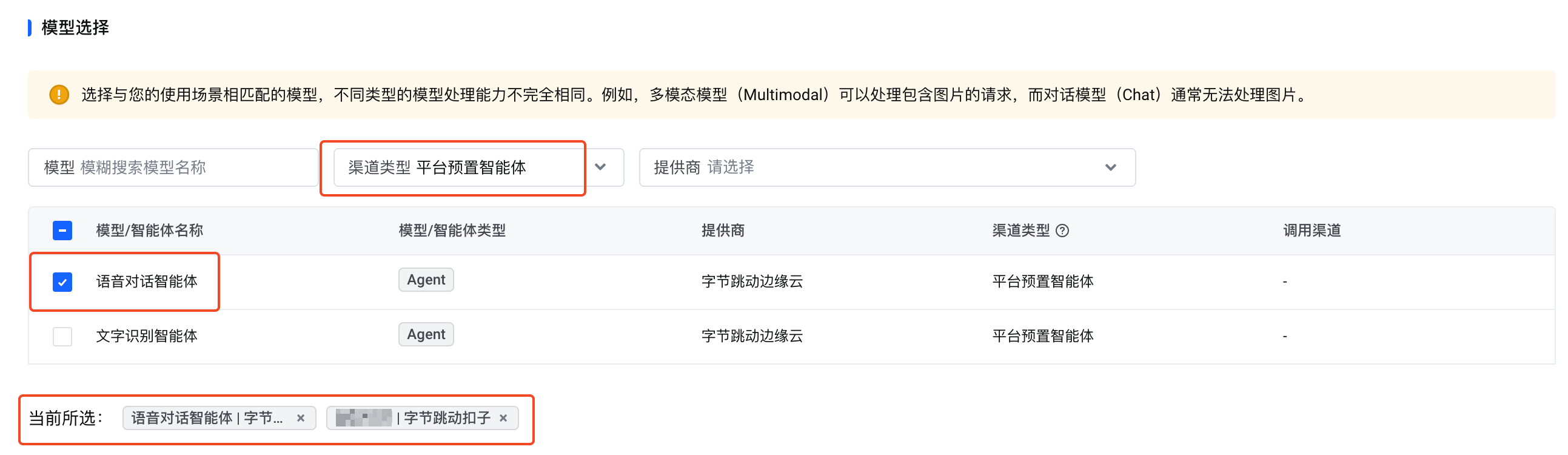
完成创建后,该网关访问密钥可用于调用您的 Coze 智能体和平台预置的语音对话智能体。
- 您的 Coze 智能体(渠道类型 为 自有三方智能体)
参考查看密钥(API Key),获取网关访问密钥的 API key。
调用 Realtime API 实现与智能体进行语音对话。关于 API 的说明,请参见 Reamtime API。
Realtime API 简介
Realtime API 是一个有状态的、基于事件的 API,通过 WebSocket 进行通信。您可以使用 Realtime API 与边缘大模型网关的预置语音对话智能体构建语音对话。目前,Realtime API 支持音频作为输入和输出。
注意
Realtime API 仍处于测试阶段。
与 RealTime API 建立 WebSocket 连接需要以下参数:
单独使用语音对话智能体(后端为内置的豆包语言大模型)
- URL:
wss://ai-gateway.vei.volces.com/v1/realtime - 查询参数:
?model=AG-voice-chat-agent:以 Doubao-pro-32k 为后端。?model=AG-voice-chat-agent&ag-custom-model=doubao-pro-32k-functioncall:以 Doubao-pro-32k-functioncall 为后端。在工具调用场景下有更好的表现。
- 请求头:
Authorization: Bearer $YOUR_API_KEY说明
$YOUR_API_KEY需要替换成绑定了 语音对话智能体 的网关访问密钥的 API key。详情请参见使用流程。
- URL:
组合使用语音对话智能体和您自己的 Coze 智能体(后端为您的 Coze 智能体)
URL:
wss://ai-gateway.vei.volces.com/v1/realtime查询参数:
?model=AG-voice-chat-agent&ag-coze-bot-id=<Coze Bot ID>请求头:
Authorization: Bearer $YOUR_API_KEYX-Conversation-Id: sess_xxxx(可选字段)
说明
$YOUR_API_KEY需要替换成绑定您的 Coze 智能体和 语音对话智能体的网关访问密钥的 API key。详情请参见使用流程。X-Conversation-Id:用于将服务端返回的session.created中的session id保存下来以继续之前的会话。
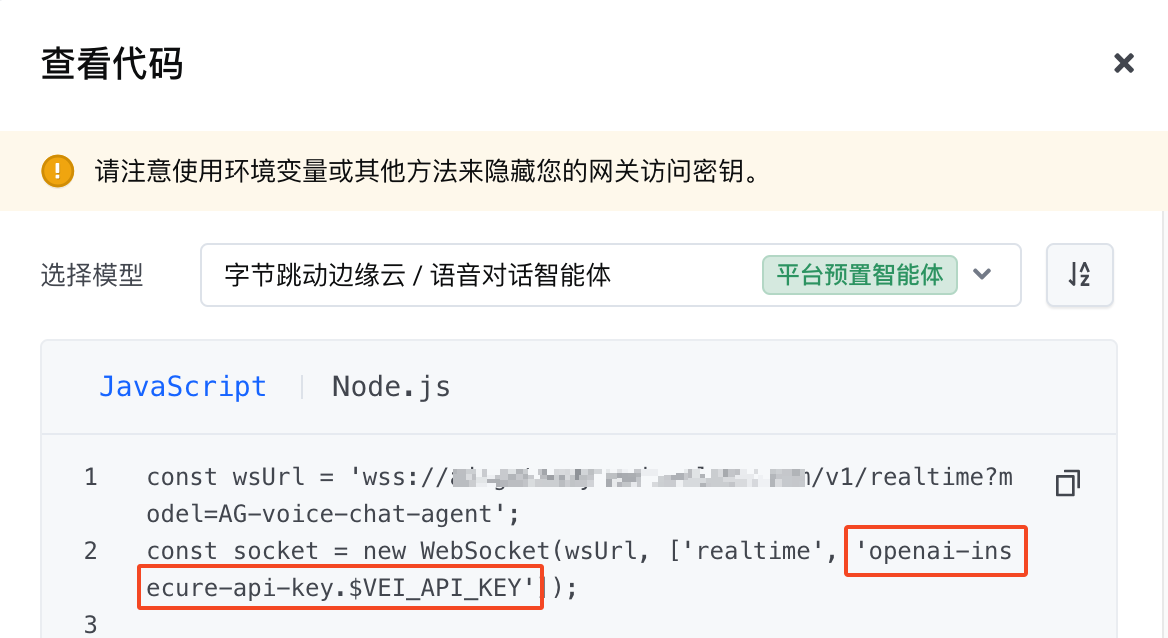
在基于 JavaScript 的 Websocket 连接请求中使用子协议认证
针对浏览器 JavaScript 环境发起的 websocket 请求,由于不支持添加请求头,参照 OpenAI 示例 采用了在 Sec-WebSocket-Protocol 请求头中添加子协议的方式来实现认证。该认证体现在语音对话智能体的 JavaScript 示例代码,如下图所示。
WebSocket 连接保活
语音对话智能体支持通过心跳包(ping/pong 帧)来维持 WebSocket 连接的活跃状态,防止因长时间无数据传输导致连接被超时中断。
具体机制如下:
- 服务端在 2 分钟内未收到 ping 帧和任何语音包则断开连接。
- 服务端收到 ping 帧时,回复 pong 帧并将连接延长 2 分钟。
- 服务端在 60 分钟内未收到任何语音包则断开连接。
API 定义
Realtime API 兼容 OpenAI 的 Realtime 接口,支持的事件如下表所示。
| 类型 | 事件 | 说明 |
|---|---|---|
| 客户端 | session.update | 将此事件发送以更新会话的默认配置。 |
| input_audio_buffer.append | 发送此事件以将音频字节追加到输入音频缓冲区。 | |
| input_audio_buffer.commit | 发送此事件以提交用户输入的音频缓冲区。 | |
| conversation.item.create | 向对话的上下文中添加一个新项目,包括消息、函数调用响应。目前只支持函数调用应答。 | |
| response.create | 此事件指示服务器创建一个响应,这意味着触发模型推理。 | |
| response.cancel | 发送此事件来取消当前正在回复的语音应答。 | |
| 服务端 | session.created | 在会话创建时返回。新连接建立时自动触发,作为第一个服务器事件。 |
| session.updated | 发送此事件以确认客户端更新的会话配置。 | |
| conversation.item.input_audio_transcription.completed | 发送此事件输出用户音频的文本转录。 | |
| response.created | 在创建新响应时返回。响应创建的第一个事件,此时响应处于初始的进行中状态。 | |
| response.output_item.added | 在响应生成过程中创建新项目时返回。 | |
| response.function_call_arguments.done | 当模型生成的函数调用参数完成流式传输时返回。 | |
| response.audio_transcript.delta | 在模型生成的文本信息流式返回。 | |
| response.audio_transcript.done | 在模型生成的文本信息完成流式传输时返回。 | |
| response.audio.delta | 在模型生成的语音流式返回。 | |
| response.audio.done | 在模型完成生成的音频流式传输时返回。 | |
| response.output_item.done | 在一次响应完成流式传输时返回。 | |
| response.done | 在响应完成流式传输时返回。 | |
| - | error | 在发生错误时返回,这可能是客户端问题或服务器问题。 |
客户端事件
session.update
将此事件发送以更新会话的默认配置。如需更新配置,客户端必须在创建会话的一开始就发送该消息(发送音频之前),服务器将以 session.updated 事件响应,显示完整的有效配置。
event_id: string
可选字段,由客户端生成的事件 ID。type: string
事件类型,取值为session.update。session: object
包含以下字段:modalities: array
目前支持配置为["text", "audio"]或["audio"]。当为["audio"]时服务器只不会返回response.audio_transcript中的文本消息。instructions: string
配置智能体的人物设定。示例:你是一个玩具对话智能体,你的名字叫豆包,你的回答要尽量简短。该字段对后端为 Coze 不生效。voice: string
目前只支持在 语音技术 - 音色列表 通用场景 中 包含中文语种且以 zh_ 开头 的音色。默认为zh_female_tianmeixiaoyuan_moon_bigtts。input_audio_format: string
输入的音频格式。目前只支持pcm16。output_audio_format: string
输出的音频格式。目前只支持pcm16。input_audio_transcription: object
通过配置此项来将用户语音输入的文本转录发送给客户端。配置为空表示关闭此功能。
包含以下字段:model: string
配置为"model": "any"来打开此功能。
turn_detection: object
暂不支持,设置为空。tools: array of object
调用的工具。包含以下字段:type: string
工具类型。取值为function,表示函数。name: string
函数名称。示例:get_weather。description: string
函数描述。parameters: object
函数的参数对象,使用 JSON Schema 格式。说明
如果后端为您自己的 Coze 智能体,那么
tools字段不生效。实际生效的是您在 Coze 智能体中定义的端插件。
tool_choice: string
暂不支持。temperature: number
暂不支持。max_response_output_tokens: integer or "inf"
暂不支持。
示例:
{ "type": "session.update", "session": { "modalities": ["audio"], "instructions": "你的名字叫豆包,你是一个智能助手,你的回答要尽量简短。", "voice": "zh_female_tianmeiyueyue_moon_bigtts", "input_audio_format": "pcm16", "output_audio_format": "pcm16", "tool_choice": "auto", "turn_detection": None, "input_audio_transcription": { "model": "any" }, "tools": [{ "type": "function", "name": "get_weather", "description": "获取当前天气", "parameters": { "type": "object", "properties": { "location": { "type": "string" } }, "required": ["location"] } }], "temperature": 0.8 } }
input_audio_buffer.append
发送此事件以将音频字节追加到输入音频缓冲区。音频缓冲区是临时存储,您可以在其中写入数据并稍后进行提交。
event_id: string
可选字段,由客户端生成的事件 ID。type: string
事件类型,取值为input_audio_buffer.append。audio: string
Base64 编码的 audio bytes。目前只支持 pcm16 格式。
示例:
{ "type": "input_audio_buffer.append", "audio": base64_audio }
input_audio_buffer.commit
发送此事件以提交用户输入的音频缓冲区。提交输入音频缓冲区将触发音频转录,但不会生成模型的响应。服务器将以 input_audio_buffer.committed 事件进行响应。
event_id: string
可选字段,由客户端生成的事件 ID。type: string
事件类型,取值为input_audio_buffer.commit。
示例:
{ "type": "input_audio_buffer.commit" }
conversation.item.create
向对话的上下文中添加一个新项目,包括消息、函数调用响应。目前只支持函数调用应答。如果成功,服务器将响应一个 conversation.item.created 事件,否则将发送错误事件。
event_id: string
可选字段,由客户端生成的事件 ID。type: string
事件类型,取值为conversation.item.create。previous_item_id: string
暂不支持。item: object
对话的 Item。包含以下字段:id: string
可选字段,客户端生成的 Item ID。object: string
可选字段,取值为realtime.item。type: string
Item 的类型。取值为function_call_output。call_id: string
仅适用于type为function_call_output,表示函数调用的 ID。如果在function_call_output项中传递,服务器将检查对话历史中是否存在具有相同 ID 的function_call。output: string
仅适用于type为function_call_output,表示函数调用的输出。
示例:
{ "type": "conversation.item.create", "item": { "call_id": function_call_id, "type": "function_call_output", "output": "{"result ": "打开成功"}", } }
response.create
此事件指示服务器创建一个响应,这意味着触发模型推理。服务器将以 response.created 事件进行响应,包含为项目和内容创建的事件,最后发送 response.done 事件以指示响应已完成。
event_id: string
可选字段,由客户端生成的事件 ID。type: string
事件类型,取值为response.create。response: object
响应的对象详情,包含以下字段:modalities: array
可选字段,目前只支持配置为["text", "audio"]或["audio"]。当为["audio"]时服务器只不会返回response.audio_transcript中的文本消息。instructions: string
可选字段,配置智能体的人物设定。示例:你是一个玩具对话智能体,你的名字叫豆包,你的回答要尽量简短。该字段对后端为 Coze 不生效。voice: string
可选字段,目前只支持在 语音技术 - 音色列表 通用场景 中 包含中文语种且以 zh_ 开头 的音色。默认为zh_female_tianmeixiaoyuan_moon_bigtts。output_audio_format: string
可选字段,输出的音频格式。目前只支持pcm16。
示例:
{ "type": "response.create", "response": { "modalities": ["text", "audio"] } }
response.cancel
发送到服务器将来需取消正在应答的语音消息。可以在收到服务端的 response.audio.delta 后发送该消息来取消后续的语音消息,服务端最终会应答 response.done 中带 cancelled 状态以指示响应已完成。
event_id: string
可选字段,由客户端生成的事件 ID。type: string
事件类型,取值为response.create。
示例:
{ "type": "response.cancel", }
示例(服务端最终应答 response.done 中带 cancelled):
{ "event_id": "event_5fe8c9c224ee4d6d82cf7", "response": { "id": "resp_7a4c14b7ac884610a115c", "output": [], "object": "realtime.response", "status": "cancelled", "status_details": None, "usage": { "total_tokens": 201, "input_tokens": 131, "output_tokens": 70, "input_token_details": { "cached_tokens": 0, "text_tokens": 123, "audio_tokens": 8 }, "output_token_details": { "text_tokens": 35, "audio_tokens": 35 } } }, "type": "response.done" }
服务端事件
session.created
在会话创建时返回。新连接建立时自动触发,作为第一个服务器事件。此事件将包含默认的会话配置。
event_id: string
可选字段,由服务端生成的事件 ID。type: string
事件类型,取值为session.created。session: object
包含以下字段:id: string
session 的 ID。model: string
模型的名称。modalities: array
目前支持为["text", "audio"]或["audio"]。instructions: string
返回当前智能体的默认人设配置。voice: string
目前只支持在 语音技术 - 音色列表 通用场景 中 包含中文语种且以 zh_ 开头 的音色。input_audio_format: string
输入的音频格式。目前只支持pcm16。output_audio_format: string
输出的音频格式。目前只支持pcm16。input_audio_transcription: object
暂不支持。turn_detection: object
暂不支持。tools: array
暂不支持。tool_choice: string
暂不支持。temperature: number
暂不支持max_response_output_tokens: integer or "inf"
暂不支持。
示例:
{ "event_id": "event_5408c86192a14ae088d55", "session": { "id": "sess_7441921809949130779", "model": "7441883325217882146", "expires_at": 1732709032, "object": "realtime.session", "modalities": ["text", "audio"], "instructions": None, "voice": "zh_male_shaonianzixin_moon_bigtts", "turn_detection": None, "input_audio_format": "pcm16", "output_audio_format": "pcm16", "input_audio_transcription": None, "tools": [], "tool_choice": "auto", "temperature": 0.8, "max_response_output_tokens": "inf" }, "type": "session.created" }
session.updated
发送此事件以确认客户端更新的会话配置。目前只支持在连接刚创建的时候发送该消息以更新配置。服务器将以 session.updated 事件响应,显示完整的有效配置。只有存在的字段会被更新。
event_id: string
可选字段,由服务端生成的事件 ID。type: string
事件类型,取值为session.updated。session: object
包含以下字段:id: string
session 的 ID。model: string
模型的名称。modalities: array
目前只支持配置为["text", "audio"]或["audio"]。instructions: string
返回已配置的instructions。voice: string
目前只支持在 语音技术 - 音色列表 通用场景 中 包含中文语种且以 zh_ 开头 的音色。input_audio_format: string
输入的音频格式。目前只支持pcm16。output_audio_format: string
输出的音频格式。目前只支持pcm16。input_audio_transcription: object
暂不支持。turn_detection: object
暂不支持。tools: array of object
调用的工具。包含以下字段:type: string
工具类型。取值为function,表示函数。name: string
函数名称。示例:get_weather。- description: string
函数描述。 - parameters: object
函数的参数对象,使用 JSON Schema 格式。
tool_choice: string
暂不支持。temperature: number
暂不支持。max_response_output_tokens: integer or "inf"
暂不支持。
示例:
{ "event_id": "event_7ac8c51cda964aa38932f", "session": { "id": "sess_c3e26a46bd2043e184d06", "model": "ep-20240725155030-gd2s2", "expires_at": 1736846451, "object": "realtime.session", "modalities": ["audio"], "instructions": "你的名字叫豆包,你是一个智能助手,你的回答要尽量简短。", "voice": "zh_female_tianmeiyueyue_moon_bigtts", "turn_detection": None, "input_audio_format": "pcm16", "output_audio_format": "pcm16", "input_audio_transcription": { "model": "any" }, "tools": [{ "type": "function", "name": "get_weather", "description": "获取当前天气", "parameters": { "type": "object", "properties": { "location": { "type": "string" } }, "required": ["location"] } }], "tool_choice": "auto", "temperature": 0.8, "max_response_output_tokens": "inf" }, "type": "session.updated" }
conversation.item.input_audio_transcription.completed
发送此事件输出用户音频的文本转录。
event_id: string
可选字段,由服务端生成的事件 ID。type: string
事件类型,取值为conversation.item.input_audio_transcription.completed。item_id: string
响应 item 的 ID。content_index: integer
输出的 content 在 item 数组中的索引。transcript: string
转录的文本。
示例:
{ "event_id": "event_df9885d3f04041e1832a7", "item_id": "item_504367449f1c42bb9ee8c", "content_index": 0, "transcript": "背唐诗登鹳雀楼。", "type": "conversation.item.input_audio_transcription.completed" }
response.created
在创建新响应时返回。响应创建的第一个事件,此时响应处于初始的进行中状态。
event_id: string
可选字段,由服务端生成的事件 ID。type: string
事件类型,取值为response.created。response: object
响应的对象详情,包含以下字段:id: string
响应的 ID。object: string
对象类型,必须为realtime.response。status: string
响应的状态,目前包含以下取值:in_progress,completed。status_details: object
状态详情,暂不支持。output: array
响应输出的列表,暂不支持。usage: object
使用统计,暂不支持。
示例:
{ "event_id": "event_cb7646e899e648cfb269e", "response": { "id": "resp_06348064b26b412196e32", "output": [], "object": "realtime.response", "status": "in_progress", "status_details": None, "usage": None }, "type": "response.created" }
response.output_item.added
在响应生成过程中创建新项目时返回。
event_id: string
可选字段,由服务端生成的事件 ID。type: string
事件类型,取值为response.output_item.added。response_id: string
响应的 ID。output_index: integer
响应的 item 索引。item: object
对话的 Item,包含以下字段:id: string
服务端生成的 Item IDobject: string
目前该值为realtime.item。type: string
Item 的类型,目前只支持message。status: string
Item 的状态,目前包含以下取值:in_progress,completed。role: string
发送的角色,包含以下取值:user,assistant,system。content: array
消息的内容,暂时为空。
示例:
{ "event_id": "event_81efe6cf663040d6a6579", "response_id": "resp_06348064b26b412196e32", "output_index": 0, "item": { "content": [], "id": "item_73fe51150f4a446abd9d9", "status": "in_progress", "type": "message", "role": "assistant", "object": "realtime.item" }, "type": "response.output_item.added" }
response.function_call_arguments.done
当模型生成的函数调用参数完成流式传输时返回。
event_id: string
可选字段,由服务端生成的事件 ID。type: string
事件类型,取值为response.function_call_arguments.done。response_id: string
响应的 ID。item_id: string
响应 item 的 ID。output_index: integer
响应的 item 索引。call_id: string
调用函数唯一 ID。arguments: string
调用的函数参数,以 JSON 字符串形式表示。
示例:
{ "event_id": "event_c8f465ef567f402c8bf19", "type": "response.function_call_arguments.done", "item_id": "item_df02814b553144319728d", "response_id": "resp_33c3f294518b4102b2c19", "output_index": 0, "call_id": "call_w5z9kqyptdxasubd8y4smu60", "arguments": "{\"location\": \"上海\"}" }
response.audio_transcript.delta
在模型生成的文本信息流式返回。
event_id: string
可选字段,由服务端生成的事件 ID。type: string
事件类型,取值为response.audio_transcript.delta。response_id: string
响应的 ID。item_id: string
响应 item 的 ID。output_index: integer
响应的 item 索引。content_index: integer
输出的 content 在 item 数组中的索引。delta: string
在模型生成的文本信息的增量返回。
示例:
{ "event_id": "event_3ce9f18992e1461fb486d", "response_id": "resp_06348064b26b412196e32", "item_id": "item_73fe51150f4a446abd9d9", "output_index": 0, "content_index": 0, "delta": "你", "type": "response.audio_transcript.delta" }
response.audio_transcript.done
在模型生成的文本信息完成流式传输时返回。
event_id: string
可选字段,由服务端生成的事件 ID。type: string
事件类型,取值为response.audio_transcript.done。response_id: string
响应的 ID。item_id: string
响应 item 的 ID。output_index: integer
响应的 item 索引。content_index: integer
输出的 content 在 item 数组中的索引。transcript: string
模型生成的完整的文本信息内容。
示例:
{ "event_id": "event_bb2c02ef6fa542ed9027d", "response_id": "resp_06348064b26b412196e32", "item_id": "item_73fe51150f4a446abd9d9", "output_index": 0, "content_index": 0, "transcript": "你好,有没有好玩的事呀?", "type": "response.audio_transcript.done" }
response.audio.delta
在模型生成的语音流式返回。
event_id: string
可选字段,由服务端生成的事件 ID。type: string
事件类型,取值为response.audio.delta。response_id: string
响应的 ID。item_id: string
响应 item 的 ID。output_index: integer
响应的 item 索引。content_index: integer
输出的 content 在 item 数组中的索引。delta: string
在模型生成的语音 base64 编码的增量返回。
示例:
{ "event_id": "event_3ce9f18992e1461fb486d", "response_id": "resp_06348064b26b412196e32", "item_id": "item_73fe51150f4a446abd9d9", "output_index": 0, "content_index": 0, "delta": "base64", "type": "response.audio.delta" }
response.audio.done
在模型完成生成的音频流式传输时返回。
event_id: string
可选字段,由服务端生成的事件 ID。type: string
事件类型,取值为response.audio.done。response_id: string
响应的 ID。item_id: string
响应 item 的 ID。output_index: integer
响应的 item 索引。content_index: integer
输出的 content 在 item 数组中的索引。
示例:
{ "event_id": "event_51bb61cdab5e4ad8ac925", "response_id": "resp_06348064b26b412196e32", "item_id": "item_73fe51150f4a446abd9d9", "output_index": 0, "content_index": 0, "type": "response.audio.done" }
response.output_item.done
在一次响应完成流式传输时返回。
event_id: string
可选字段,由服务端生成的事件 ID。type: string
事件类型,取值为response.output_item.done。response_id: string
响应的 ID。output_index: integer
响应的 item 索引。item: object
对话的 Item,包含以下字段:id: string
服务端生成的 Item ID。object: string
目前该值为realtime.item。type: string
Item 的类型,取值包括message和function_call。status: string
Item 的状态,目前包含以下取值:in_progress,completed。role: string
发送的角色,包含以下取值:user,assistant,system。content: array
消息的内容,包含以下字段:type: string
内容的类型,包含以下取值:input_text,input_audio,audio,text。text: string
文本内容。适用于内容类型为input_text和text的情形。audio: string
音频的 base64 编码。适用于内容类型为input_audio的情形。transcript: string
音频的文本内容。适用于内容类型为input_audio和audio的情形。call_id: string
仅当type为function_call时返回,表示本次函数调用的 ID。在conversation.item.create事件中,call_id被用于上报函数调用的结果。name: string
仅当type为function_call时返回,表示本次函数调用所调用函数的名称。arguments: string
仅当type为function_call时返回,表示本次函数调用的函数参数,以 JSON 字符串形式表示。
示例:
- 纯文本消息(message)返回
{ "event_id": "event_57938730a5764a7c83cb4", "response_id": "resp_06348064b26b412196e32", "output_index": 0, "item": { "content": [ { "type": "audio", "transcript": "你好,有没有好玩的事呀?" } ], "id": "item_73fe51150f4a446abd9d9", "status": "completed", "type": "message", "role": "assistant", "object": "realtime.item" }, "type": "response.output_item.done" } - 函数调用(function_call)返回
{ "event_id": "event_e26c05a0068e41189f2ec", "type": "response.output_item.done", "item": { "id": "item_84dfdf6448634d0990d4b", "type": "function_call", "status": "completed", "call_id": "call_gln0xh7bi7fx0mai1d3gsthh", "name": "get_weather", "arguments": "{\"location\": \"上海\"}" }, "response_id": "resp_b06b5bddad494be89b097", "output_index": 0 }
response.done
在响应完成流式传输时返回。
event_id: string
可选字段,由服务端生成的事件 ID。type: string
事件类型,取值为response.done。response: object
响应的对象详情,包含以下字段:id: string
响应的 ID。object: string
对象类型,必须为realtime.response。status: string
响应的状态,目前包含以下取值:in_progress,completed。status_details: object
状态详情,暂不支持。output: array
响应输出的列表,暂不支持。usage: object
使用统计,包含以下字段:total_tokens: integer
应答使用的所有 token 数量,包括输入输出的文本和音频 token。input_tokens: integer
应答使用的输入 token 数量,包含文本和音频 token。output_tokens: integer
应答使用的输出 token 数量,包含文本和音频 token。input_token_details: object
应答的输入 token 使用详情,包含以下字段:cached_tokens: integer
应答中被缓存的 token 数量。text_tokens: integer
应答中使用的输入文本 token 数量。audio_tokens: integer
应答中使用的输入音频 token 数量。
output_token_details: object
应答中的输出 token 使用详情,包含以下字段:text_tokens: integer
应答中使用的输出文本 token 数量。audio_tokens: integer
应答中使用的输出音频 token 数量。
示例:
{ "event_id": "event_767d3f51a1c84e99a4185", "response": { "id": "resp_33a7a44490354861ab3c0", "output": [], "object": "realtime.response", "status": "completed", "status_details": None, "usage": { "total_tokens": 157, "input_tokens": 141, "output_tokens": 16, "input_token_details": { "cached_tokens": 0, "text_tokens": 133, "audio_tokens": 8 }, "output_token_details": { "text_tokens": 8, "audio_tokens": 8 } } }, "type": "response.done" }
error
在发生错误时返回,这可能是客户端问题或服务器问题。对于一些输入错误的请求,会返回应答但是不会影响连接。对于一些服务端的错误,会返回应答,并会断开连接,客户端这时必须重连。如果服务端在 120 秒内没有收到新的消息,会返回 error,并主动断开 WebSocket 连接。
event_id: string
可选字段,由服务端生成的事件 ID。type: string
事件类型,取值为error。error: object
错误的详情,包含以下字段:type: string
错误的类型,包含以下取值:invalid_request_error,server_error。code: string
错误码。message: string
错误的文本内容。param: string
错误的相关参数。event_id: string
相关的客户端事件 ID,目前为空。
示例:
{ "event_id": "event_f2aac7bbab6f4854a7c2d", "error": { "type": "server_error", "message": "There is problem in server side, please try again later", "code": "server_error", "param": None, "event_id": None }, "type": "error" }
时序示例
以下是一个时序图示例:
Python 代码示例
pip install soundfile scipy numpy websockets==12.0
测试音频


import asyncio import base64 import json import wave import numpy as np import soundfile as sf from scipy.signal import resample import websockets def resample_audio(audio_data, original_sample_rate, target_sample_rate): number_of_samples = round( len(audio_data) * float(target_sample_rate) / original_sample_rate) resampled_audio = resample(audio_data, number_of_samples) return resampled_audio.astype(np.int16) def pcm_to_wav(pcm_data, wav_file, sample_rate=16000, num_channels=1, sample_width=2): print(f"saved to file {wav_file}") with wave.open(wav_file, 'wb') as wav: # Set the parameters # Number of channels (1 for mono, 2 for stereo) wav.setnchannels(num_channels) # Sample width in bytes (2 for 16-bit audio) wav.setsampwidth(sample_width) wav.setframerate(sample_rate) wav.writeframes(pcm_data) async def send_audio(client, audio_file_path: str): sample_rate = 16000 duration_ms = 100 samples_per_chunk = sample_rate * (duration_ms / 1000) bytes_per_sample = 2 bytes_per_chunk = int(samples_per_chunk * bytes_per_sample) audio_data, original_sample_rate = sf.read( audio_file_path, dtype="int16") if original_sample_rate != sample_rate: audio_data = resample_audio( audio_data, original_sample_rate, sample_rate) audio_bytes = audio_data.tobytes() for i in range(0, len(audio_bytes), bytes_per_chunk): await asyncio.sleep((duration_ms - 10)/1000) chunk = audio_bytes[i: i + bytes_per_chunk] base64_audio = base64.b64encode(chunk).decode("utf-8") append_event = { "type": "input_audio_buffer.append", "audio": base64_audio } await client.send(json.dumps(append_event)) commit_event = { "type": "input_audio_buffer.commit" } await client.send(json.dumps(commit_event)) event = { "type": "response.create", "response": { "modalities": ["text", "audio"] } } await client.send(json.dumps(event)) async def receive_messages(client, save_file_name): audio_list = bytearray() while not client.closed: message = await client.recv() if message is None: continue event = json.loads(message) message_type = event.get("type") if message_type == "response.audio.delta": audio_bytes = base64.b64decode(event["delta"]) audio_list.extend(audio_bytes) continue if message_type == 'response.done': pcm_to_wav(audio_list, save_file_name) break print(event) continue def get_session_update_msg(): config = { "modalities": ["text", "audio"], "instructions": "你的名字叫豆包,你是一个智能助手", "voice": "zh_female_tianmeixiaoyuan_moon_bigtts", "input_audio_format": "pcm16", "output_audio_format": "pcm16", "tool_choice": "auto", "turn_detection": None, "temperature": 0.8, } event = { "type": "session.update", "session": config } return json.dumps(event) async def with_realtime(audio_file_path: str, save_file_name: str): ws_url = "wss://ai-gateway.vei.volces.com/v1/realtime?model=AG-voice-chat-agent" key = "xxx" # 修改为你的 key headers = { "Authorization": f"Bearer {key}", } async with websockets.connect(ws_url, extra_headers=headers) as client: session_msg = get_session_update_msg() await client.send(session_msg) await asyncio.gather(send_audio(client, audio_file_path), receive_messages(client, save_file_name)) await asyncio.sleep(0.5) if __name__ == "__main__": audio_file_path = "demo_audio_nihaoya.wav" #下载示例音频 save_file_name = "demo_response.wav" asyncio.run(with_realtime(audio_file_path, save_file_name))
FAQ
Realtime API 目前支持哪些模态?
目前,Realtime API 需要使用音频输出或音频输入。只接受如下组合:
- 音频输入 → 文本 + 音频输出
- 音频输入 → 音频输出
是否支持打断?
支持客户端通过发送 response.cancel 来打断当前输出的语音消息。
是否支持会话历史记录?
目前只支持保留当前 WebSocket 的对话历史,最多保留 10 轮。当 WebSocket 断开后,对话历史不会被保留。
是否支持服务端自动 VAD?
目前暂不支持服务端的 VAD,必须客户端主动提交告知服务端完成当前的语音采集。
输入的音频参数
目前只支持 pcm16 的格式,默认为 16000Hz 的采样频率。
输出支持哪些音色?
目前只支持在 语音技术 - 音色列表 通用场景 中 包含中文语种且以 zh_ 开头 的音色。默认为 zh_female_tianmeixiaoyuan_moon_bigtts。