本文介绍了如何向边缘节点部署基于 Triton 推理框架(即 Triton Inference Server)的模型服务。您可以部署边缘智能提供的官方模型,也可以部署自定义模型。
支持的模型框架
推理框架提供了模型的运行环境。Triton 推理框架兼容各种主流训练框架的模型。支持的模型框架包括:
ONNX、TensorRT、PyTorch、TensorFlow、OpenVINO、ByteNN、PaddlePaddle、Python、Ensemble、TensorRT-LLM
不同模型框架对边缘节点指令集架构、协处理器类型有不同的要求。具体如下表所示。在部署模型服务前,请确保您的边缘节点与要部署的模型是兼容的。
| 模型框架 | 指令集架构要求 | 协处理器要求 |
|---|---|---|
| ONNX | x86/amd64、arm | CPU、GPU |
| TensorRT | x86/amd64、arm | GPU |
| PyTorch | x86/amd64、arm | CPU、GPU |
| TensorFlow | x86/amd64、arm | CPU、GPU |
| OpenVINO | x86/amd64 | CPU、GPU |
| Bytenn | x86/amd64、arm | CPU、GPU |
| PaddlePaddle | x86/amd64 | CPU、GPU |
前提条件
- 您已经为项目绑定了边缘节点。相关操作,请参见绑定节点。
- 如果您使用边缘节点型 aPaaS 工具,则 aPaaS 工具必须是 高级版。
边缘节点 - 基础版 aPaaS 工具不包含边缘推理功能。更多信息,请参见资源包(aPaaS 工具)计费说明。 - 如果您要部署自定义模型,您必须完成以下任务:创建自定义模型并为自定义模型创建和发布版本。相关操作,请参见创建自定义模型、创建一个版本。
操作步骤
登录边缘智能控制台。
在左侧导航栏,从 我的项目 下拉列表选择一个项目。
在左侧导航栏,选择 边缘推理 > 模型服务。
在 Triton框架 标签页,单击 部署模型服务。
在 部署模型服务 页面,配置以下参数,然后单击 确认。
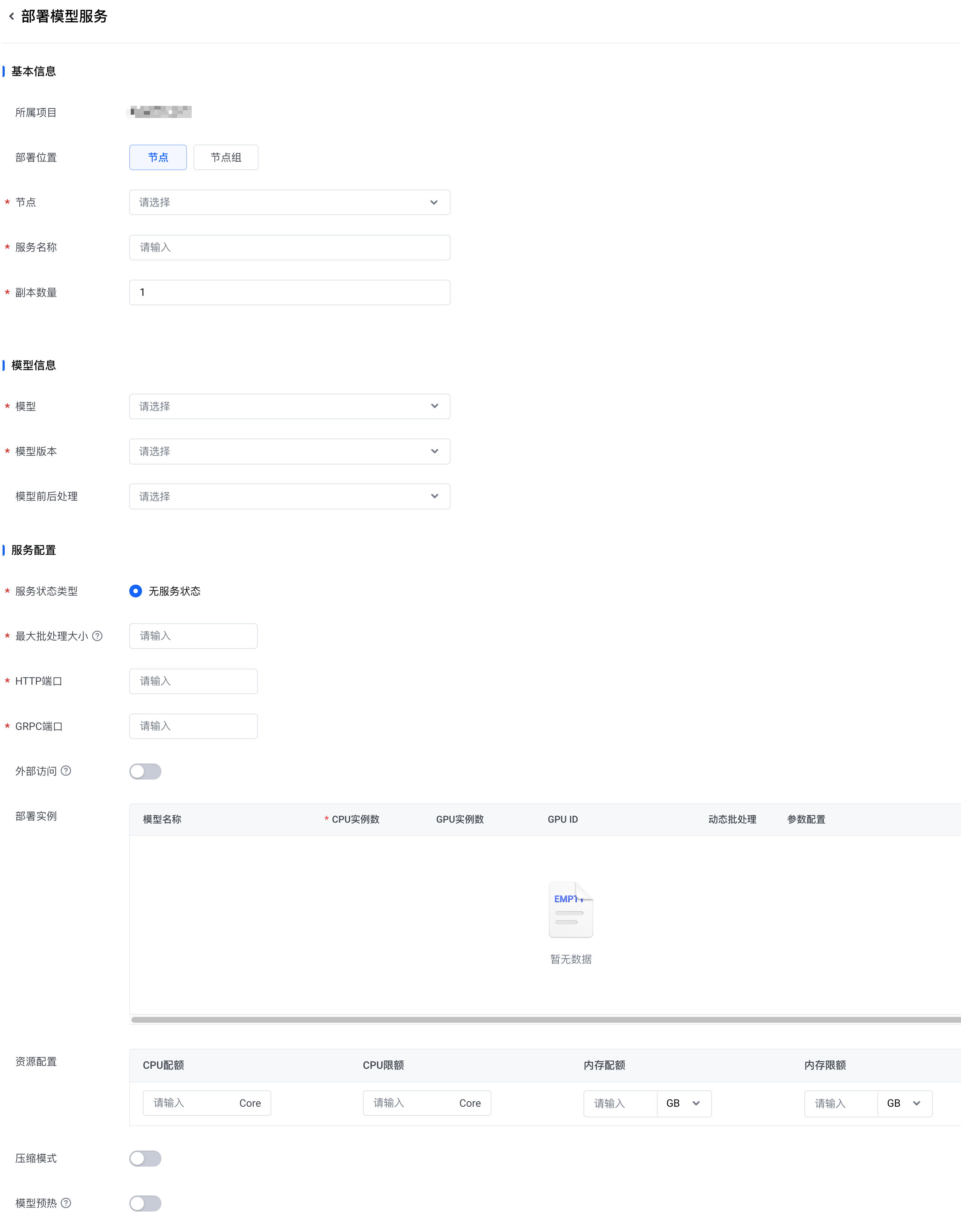
区域 参数 说明 基本信息 所属项目 默认为当前选择的项目。 部署位置 选择将模型服务部署到指定的 节点 或 节点组。 节点
说明
只有当 部署位置 为 节点 时,该参数才会出现。
选择一个或多个节点,将模型服务部署到指定的节点。
节点组
说明
只有当 部署位置 为 节点组 时,该参数才会出现。
选择一个节点组,将模型服务部署到指定的节点组。
- 请确保节点组中所有节点架构相同,否则可能部署失败。
- 模型服务只会部署到节点组中的在线节点上。
服务名称
为模型服务设置一个名称。您可以使用以下字符:字母、数字、汉字、下划线(_)和连字符(-)。请注意以下规则:
- 长度限制为 32 个字符以内。
- 下划线和连字符不能用在开头或结尾,也不能连续使用。
- 名称不能与边缘节点上其他模型服务名称重复。
副本数量 设置要创建的副本数量。取值范围:1~10。默认值:1。 模型信息 模型 选择要使用的模型。您可以选择边缘智能的官方模型,也可以选择您创建的自定义模型。 模型版本 选择要使用的模型版本。 模型前后处理 选择要使用的前后处理版本。更多信息,请参见创建一个前后处理版本。 服务配置 服务状态类型 默认为 无服务状态。 最大批处理大小
设置最大批处理数量。取值范围:0 ~ 100。
注意
如果部署官方模型,在选择 模型 和 模型版本 后,请勿修改最大批处理的默认填充值。
如果部署自定义模型,可以参考以下说明设置最大批处理:
- 如果模型不支持批处理,最大批处理必须设置为 0,模型每次仅推理一个 batch。
- 如果模型支持批处理,最大批处理可以设置为一个大于等于 1 的整数,以便模型进行多批次动态推理。假设最大批处理为 N,则模型每次推理的 batch 数可以是 1~N。
推理框架在将 input 送入模型前会增加一个维度,用来表示批次数。
示例:
假设 Tensor 配置的输入形状为 [3, 640, 640],最大批处理为 3。那么,送入模型的 input 为 [1, 3, 640, 640]、 [2, 3, 640, 640] 或 [3, 3, 640, 640] 都是可以接受的。HTTP端口
说明
只有当 副本数量 为 1 时,该参数才会出现。
输入 HTTP 服务端口号。取值范围:30000 ~ 40000。
请确保您设置的端口号在目标边缘节点上未被其他服务占用。GRPC端口
说明
只有当 副本数量 为 1 时,该参数才会出现。
输入 GRPC 服务端口号。取值范围:30000 ~ 40000。
请确保您设置的端口号在目标边缘节点上未被其他服务占用。外部访问 设置是否允许从集群外部访问推理服务。开启外部访问后,可以在集群外部通过 <节点ip:port>/path来访问推理服务。具体访问方式,可在模型服务部署成功后,前往模型详情的 服务配置 页面查看。更多信息,请参见查看模型服务。部署实例
为每个子模型分别配置以下参数:
说明
当 模型 是 Ensemble 以外的类型时,子模型只有一个;当 模型 是 Ensemble 类型时,子模型有多个。更多信息,请参见创建自定义模型。
- CPU实例数:
表示预期在 CPU 上水平扩展的模型实例的数量。取值范围:0 ~ 100。 - GPU实例数:
表示预期在 GPU 上水平扩展的模型实例的数量。取值范围:0 ~ 100。 - GPU ID:
表示在哪个或哪些 GPU 上创建模型实例。仅在边缘节点上包含 GPU 时允许配置该参数。
默认情况下,模型实例会在指定节点的所有 GPU 上创建。如果设置了 GPU ID,则仅在指定的 GPU 上创建模型实例。
假设节点包含 N 个 GPU,则 GPU ID 使用 0、1、……、N-1 表示。 - 动态批处理:
设置是否开启动态批处理功能。该功能让模型服务器得以将多个推理请求组合,动态地生成一个批次。一般来说,创建请求批次可以优化吞吐量。
动态批处理 开启时,将会显示 最大延迟 参数。
最大延迟 表示表示批处理延迟的最大时间。(超过该时间会立刻开始推理。)单位:us。取值范围:0~1000000。 - 参数配置:
通过该参数自定义参数配置。自定义的参数配置将被推送到边缘节点。说明
- 只有当 模型 的类型是 Python 时,自定义的参数配置才会被启用。
- 如果您希望自定义 参数配置,请联系售后技术支持来协助您完成配置。
资源配置
为模型服务分配边缘节点资源。支持的配置项包括:
- CPU配额:
容器需要使用的最小 CPU 核数。单位:Core。使用一位小数表示。取值范围:0.1 ~ 128.0。 - CPU限额:
容器可以使用的最大 CPU 核数。单位:Core。使用一位小数表示。取值范围:0.1 ~ 128.0。 - 内存配额:
容器需要使用的最小内存值。单位:MB 或 GB。使用整数表示。取值范围:0MB ~ 128GB。 - 内存限额:
容器可以使用的最大内存值。单位:MB 或 GB。使用整数表示。取值范围:0MB ~ 128GB。
注意
如果模型服务在 CPU 或内存方面超过限额,容器将会被终止。
压缩模式
选择是否采用输入压缩模式来部署模型服务。
说明
当 模型 是 Ensemble 类型时,不支持开启压缩模式。
在模型服务与数据流分开部署的场景(如云边协同)建议开启输入压缩模式。开启输入压缩模式后,模型服务的部署会自动转化为一个 Ensemble 联合模型服务的部署,它包含三部分:Ensemble 模型,Python 前处理模型以及您选择的模型本身。
在这种模式下,整个 Ensemble 模型的输入图片 Tensor 会变成压缩后的 jpeg string。相对于原始模型,输入 Tensor 的大小有大幅度的缩小。Python 前处理模型则是用来将压缩后的 jpeg string 恢复成原始模型的输入 Tensor。示例:
假设原始模型的图片输入 Tensor 大小是 3×640×640,因此该输入 Tensor 大小是 4.6875MB。而压缩后,输入 Tensor 大小仅仅是 jpeg string 的大小,大约是几十 KB。模型预热
开启模型预热可加快模型第一次推理的速度。
Triton 在加载模型时进行后端初始化。初始化过程可能因模型实例等待第一个推理请求而延迟。模型预热允许 Triton 在后端初始化时发送一些预热请求作为样本。模型实例成功处理预热样本请求后即可提供服务。
开启模型预热后,需要配置 预热输入配置 和 预热次数。预热输入配置
说明
只有在 模型预热 开启时,该参数才会出现。
预热请求的输入 Tensor 配置。
- 与您选择的模型的输入 Tensor 配置保持一致。需要注意的是,形状 中不允许包含负数(如 -1)。
- 如果 模型框架 是 Ensemble,则需要为每个子模型配置预热输入。
预热次数
说明
只有在 模型预热 开启时,该参数才会出现。
在模型预热阶段,针对单个预热样本重复执行的次数。取值范围:1~10。
共享内存
说明
只有当 模型框架 是 Python 或者 Ensemble 时,共享内存 才会显示。
设置 Docker 共享内存。带有模型服务的容器通常需要比 Docker 默认的 64MB 更大的共享内存。在大多数情况下,256MB 通常就足够了。您可以增加单个容器的共享内存 (SHM) 大小,也可以更改 Docker 的默认值。
- 对于 Python 类型的模型,默认共享内存为 64MB。
- 对于 Ensemble 类型的模型,默认共享内存为 512MB。
完成以上操作后,您可以在 模型服务 列表看到刚刚部署的模型服务。此时,模型服务的状态是 部署中。您可以将光标放置在状态旁边的问号图标上,了解部署进度。
说明
Triton 模型服务的部署基于边缘智能下发的 GPU 镜像文件。当您首次在某个边缘节点上部署模型服务时,该边缘节点将自动下载必要的 GPU 镜像文件。下载所需的时间长度取决于该边缘节点的网络环境,过程大约需耗时 5~10 分钟。若边缘节点已开启 GPU 镜像预加载 功能,则部署模型服务的时间将会明显缩短。更多信息,请参见绑定节点。
- 当模型服务的状态变为 运行中,表示模型服务已经部署成功。
- 如果模型服务的状态是 部署失败,您可以将光标放置在 部署失败 上,然后单击 查看原因,以获取具体的错误消息。