Realtime API 是一个有状态的、基于事件的 API,通过 WebSocket 进行通信。您可以使用 Realtime API 调用边缘大模型网关平台预置的 Doubao-语音合成模型。
注意
Realtime API 仍处于测试阶段。
建连参数
与 RealTime API 建立 WebSocket 连接以调用平台预置的 Doubao-语音合成模型,需要以下参数:
URL:
wss://ai-gateway.vei.volces.com/v1/realtime查询参数:
?model=doubao-tts请求头:
Authorization: Bearer $YOUR_API_KEY说明
$YOUR_API_KEY必须替换成绑定了(平台预置模型)Doubao-语音合成 的网关访问密钥的 API key。详情请参见调用平台预置模型。
事件列表
边缘大模型网关 Realtime API 兼容 OpenAI 的 Realtime 接口,并在其基础上扩充了一些事件。与 Doubao-语音合成模型相关的所有事件如下表所示。
| 事件类型 | 事件 | 说明 |
|---|---|---|
| 客户端 | tts_session.update | 客户端发送此事件以更新语音合成会话的默认配置。此事件必须且仅在连接初始化后发送。 |
| input_text.append | 客户端发送此事件以将待合成的文本上报服务端。 | |
| input_text.done | 客户端发送此事件以通知服务端本次文字数据上报结束。 | |
| 服务端 | tts_session.updated | 服务端已完成参数配置及连接建立。 |
| response.audio.delta | 服务端实时增量输出合成的音频。 | |
| response.audio.done | 服务端通知客户端本次音频合成完毕。 |
交互过程
客户端与服务端基于 Realtime API 进行事件交互的过程如下图所示。
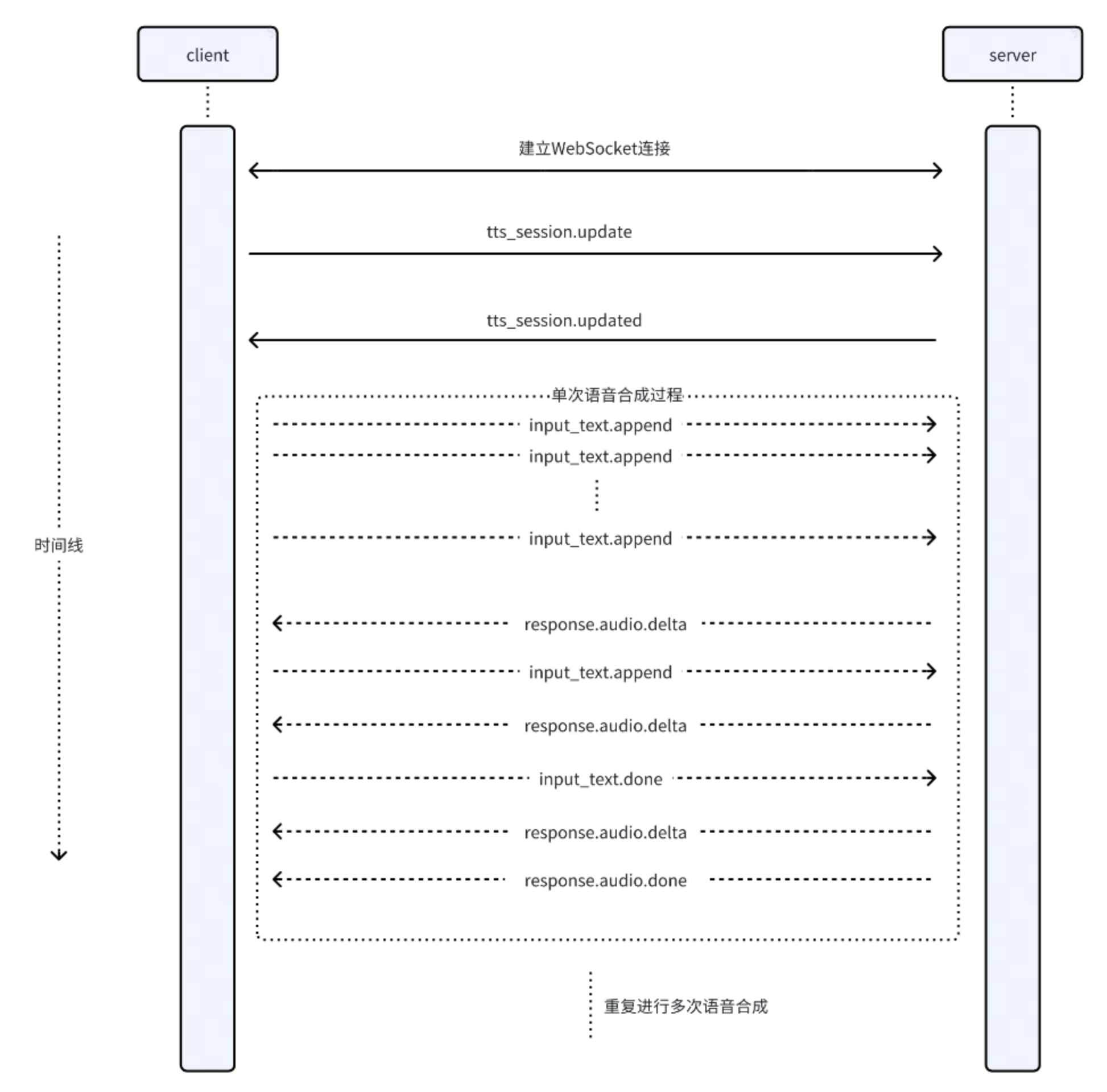
客户端事件
tts_session.update
客户端发送此事件以更新语音合成会话的配置。此事件必须且仅在连接初始化后发送。
参数:
type: string
事件类型,取值为tts_session.update。session: object
包含以下字段:voice: string
合成音频的音色。具体取值可参考 Doubao-语音合成 音色列表文档中voice_type参数说明,如zh_female_kailangjiejie_moon_bigtts表示开朗姐姐。说明
仅可使用双向流式 API 支持的音色。
output_audio_format: string
输出的音频格式。具体取值可参考 Doubao-语音合成双向流式 API 文档中req_params.audio_params.format参数说明,如mp3、ogg_opus、pcm。output_audio_sample_rate: int
输出的音频采样率。text_to_speech: object
语音合成的其他配置。model: string
使用的语音合成模型,与查询参数中的model一致。
示例:
{ "event_id": "event_123", "type": "tts_session.update", "session": { "voice": "xxx", "output_audio_format": "pcm", "output_audio_sample_rate": 16000, "text_to_speech": { "model": "doubao-tts" } } }
input_text.append
客户端发送此事件以将待合成音频的文本数据上报到服务端。
参数:
event_id: string
可选字段,由客户端生成的事件 ID。type: string
事件类型,取值为input_text.append。delta: string
待合成的增量文本信息。
示例:
{ "event_id": "event_345", "type": "input_text.append", "delta": "Hello" }
input_text.done
客户端发送此事件以告知服务端本次待合成音频的文字数据上报完成,服务端对应会通知后端的语音合成服务。
参数:
event_id: string
可选字段,由客户端生成的事件 ID。type: string
事件类型,取值为input_text.done。
示例:
{ "type": "input_text.done" }
服务端事件
tts_session.updated
服务端发送此事件以更新语音合成会话的默认配置。此事件必须且仅在连接初始化后发送。
参数:
type: string
事件类型,取值为tts_session.updated。session: object
包含以下字段:voice: string
合成音频的音色。具体取值可参考 Doubao-语音合成 音色列表文档中voice_type参数说明,如zh_female_kailangjiejie_moon_bigtts表示开朗姐姐。说明
仅可使用双向流式 API 支持的音色。
output_audio_format: string
输出的音频格式。具体取值可参考 Doubao-语音合成双向流式 API 文档中req_params.audio_params.format参数说明,如mp3、ogg_opus、pcm。output_audio_sample_rate: int
输出的音频采样率。text_to_speech: object
语音合成的其他配置。model: string
使用的语音合成模型,与查询参数中的model一致。
示例:
{ "event_id": "event_123", "type": "tts_session.updated", "session": { "voice": "xxx", "output_audio_format": "pcm", "output_audio_rate": 16000, "text_to_speech": { "model": "doubao-tts" } } }
response.audio.delta
包含增量的语音合成的音频数据。
参数:
type: string
事件类型,取值为response.audio.delta。event_id: string
可选字段,由服务端生成的事件 ID。item_id: string
响应 item 的 ID。delta: string
增量的语音合成结果。
示例:
{ "type": "response.audio.delta", "event_id": "event_001", "item_id": "item_001", "delta": "base64_encoded_audio_data" }
response.audio.done
通知客户端当前轮次语音合成结果已经输出完毕。
参数:
type: string
事件类型,取值为response.audio.done。event_id: string
可选字段,由服务端生成的事件 ID。item_id: string
响应 item 的 ID。
示例:
{ "type": "response.audio.done", "event_id": "event_001", "item_id": "item_001" }
调用示例
示例代码
import asyncio import base64 import json import pyaudio from concurrent.futures import ThreadPoolExecutor import websockets import logging logger = logging.getLogger('my_logger') async def send_text(client): text = ["你好", ",今天", "天气", "怎", "么", "样?"] for t in text: event = { "type": "input_text.append", "delta": t } await client.send(json.dumps(event)) event = { "type": "input_text.done" } await client.send(json.dumps(event)) def write_audio_data(stream, data): stream.write(data) async def write_audio_data_async(stream, data): loop = asyncio.get_event_loop() with ThreadPoolExecutor() as pool: await loop.run_in_executor(pool, write_audio_data, stream, data) FORMAT = pyaudio.paInt16 CHANNELS = 1 RATE = 16000 # init pyaudio audio = pyaudio.PyAudio() stream = audio.open(format=FORMAT, channels=CHANNELS, rate=RATE, output=True) async def receive_messages(client): while not client.closed: message = await client.recv() event = json.loads(message) message_type = event.get("type") if message_type == "response.audio.delta": audio_bytes = base64.b64decode(event["delta"]) event['delta'] = "[MASKED]" print(json.dumps(event)) await write_audio_data_async(stream, audio_bytes) continue else: print(message) if message_type == 'response.audio.done': break continue def get_session_update_msg(): config = { "voice": "zh_female_kailangjiejie_moon_bigtts", "output_audio_format": "pcm", "output_audio_sample_rate": RATE, } event = { "type": "tts_session.update", "session": config } return json.dumps(event) async def with_openai(): key = "your_api_key" ws_url = "wss://ai-gateway.vei.volces.com/v1/realtime?model=doubao-tts" headers = { "Authorization": f"Bearer {key}", } async with websockets.connect(ws_url, ping_interval=None, logger=logger, extra_headers=headers) as client: session_msg = get_session_update_msg() await client.send(session_msg) await asyncio.gather(send_text(client), receive_messages(client)) if __name__ == "__main__": asyncio.run(with_openai())
操作步骤
创建一个 tts.py 文件,将 Python 示例代码粘贴进来。
下载以下依赖文件(requirements.txt)。


运行
pip install requirements.txt安装依赖。运行
python3 tts.py。