模型信息
您可以在边缘智能控制台的 官方模型 列表访问 Qwen2.5-VL-7B-HF 模型。下图展示了本模型的基本信息。
说明
访问 Qwen/Qwen2.5-VL-7B-Instruct · Hugging Face 了解关于本模型的更多信息。
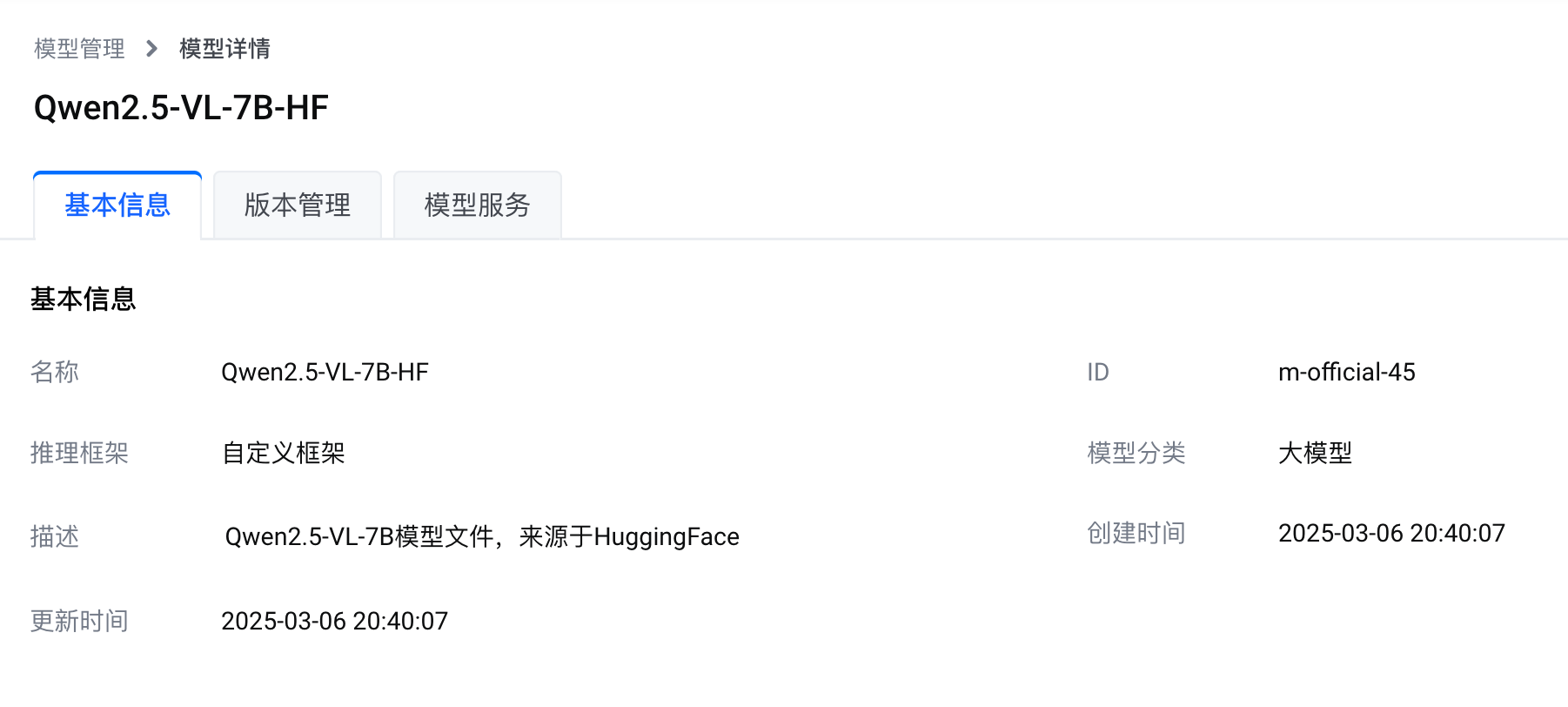
推理框架
本模型基于自定义推理框架。要部署本模型,您需要一个满足模型安装要求的推理框架镜像。
边缘智能提供了基于 vLLM 官方镜像制作的推理框架镜像。您可使用该镜像或者自行准备的推理框架镜像来部署 Qwen2.5-VL-7B-HF 模型。
vLLM 是一个快速且易于使用的 LLM 推理和服务库。vLLM 支持 Qwen2.5-VL-7B 模型,详见支持的模型。关于 vLLM 的更多信息,请参见预置推理框架镜像。
模型版本
本模型提供一个可部署版本。
模型部署示例
参考部署模型服务 - 自定义框架进行模型服务的部署。在 部署模型服务 参数配置页面,修改以下配置:
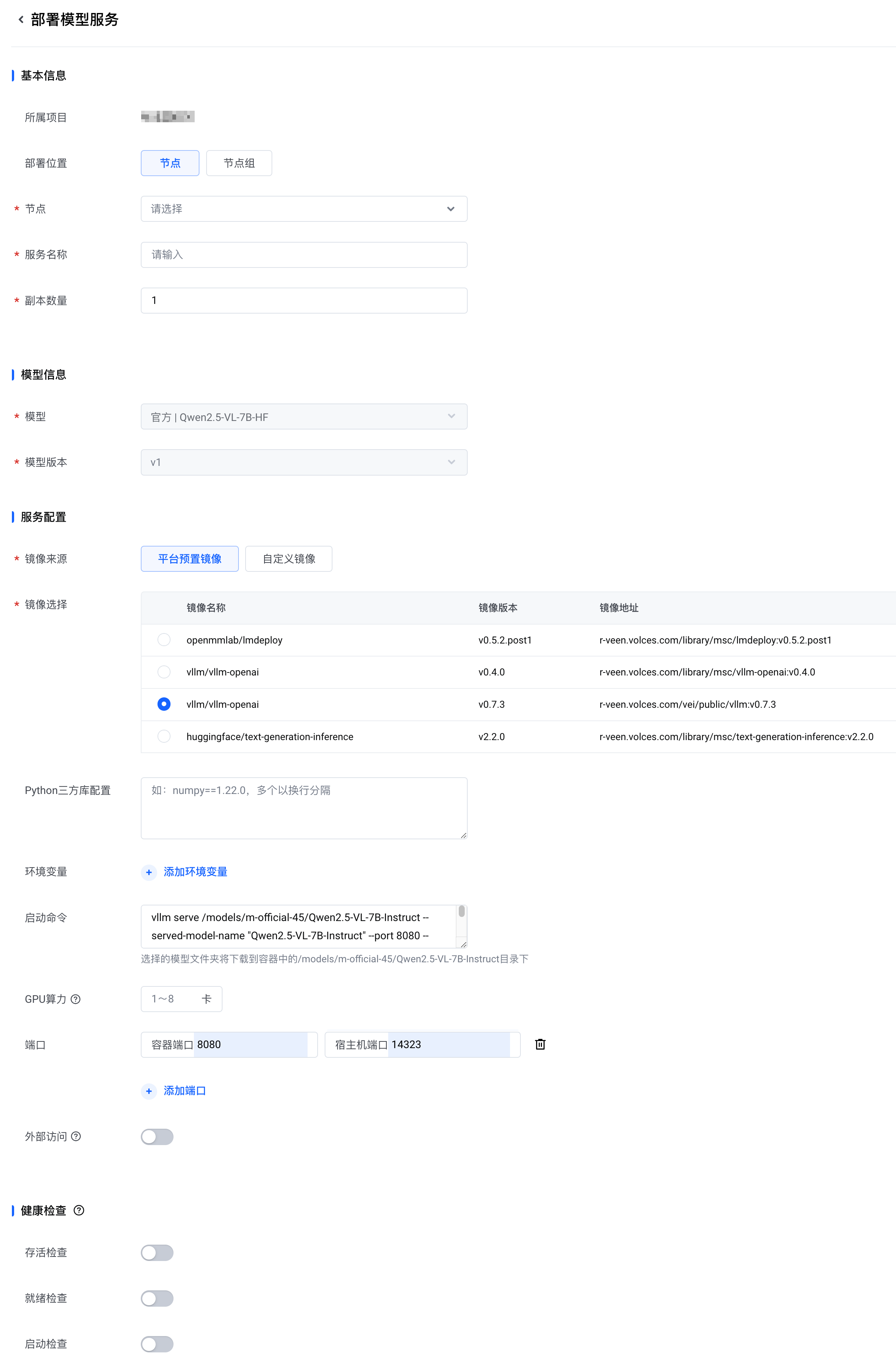
说明
下表中未包含的配置项无需修改,建议使用默认值。
配置项 | 说明 |
|---|---|
节点 | 选择一个边缘节点。 注意 必须选择 x86 架构的边缘节点。 |
服务名称 | 设置一个服务名称。该名称不能与节点上其他服务的名称重复。 |
模型 | 选择 Qwen2.5-VL-7B-HF。 |
模型版本 | 选择 v1。 |
镜像来源 | 选择 平台预置镜像。 |
镜像选择 | 选择 vllm/vllm-openai - v0.7.3。 |
启动命令 | 设置成 |
端口 | 设置以下映射规则:
说明 如果边缘节点上的 14323 端口已被其他服务占用,请使用其他空闲的端口。 |