本文介绍了如何通过边缘大模型网关调用平台预置的“Doubao-同声传译”模型。
Realtime API 简介
Realtime API 是一个有状态的、基于事件的 API,通过 WebSocket 进行通信。使用 Realtime API,您可以通过边缘大模型网关调用“Doubao-同声传译”模型。
与 RealTime API 建立 WebSocket 连接需要以下参数:
- URL:
wss://ai-gateway.vei.volces.com/v1/realtime - 查询参数:
?model=doubao-clasi-s2t - 请求头:
Authorization: Bearer $YOUR_API_KEY
注意
$YOUR_API_KEY必须替换成绑定了“Doubao-同声传译”模型的网关访问密钥的 API key。详情请参见调用平台预置模型。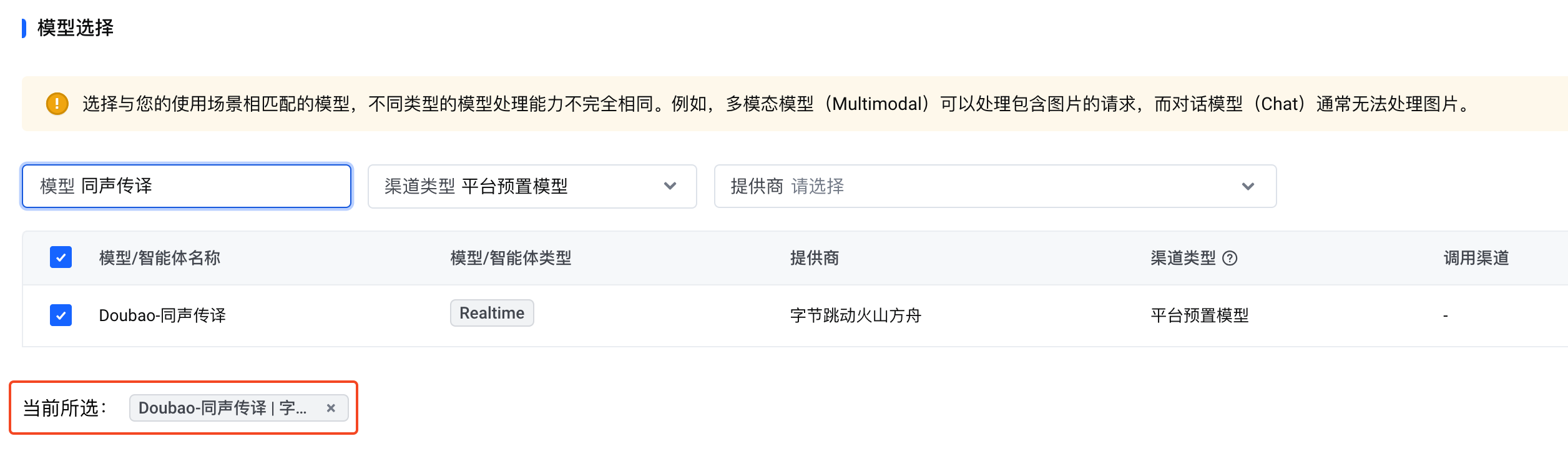
API 定义
Realtime API 兼容 OpenAI 的 Realtime 接口,支持的事件如下表所示。其中标记*的事件类型为同声传译接口特有的事件类型。
| 类型 | 事件 | 说明 |
|---|---|---|
| 客户端 | session.update | 将此事件发送以更新会话的默认配置。 |
| input_audio_buffer.append | 发送此事件以将音频数据发送给服务端。 | |
| *input_audio.done | 此事件告知服务端已经完成了所有计划发送的音频数据的发送。 | |
| 服务端 | session.created | 在会话创建时返回。新连接建立时自动触发,作为第一个服务器事件。 |
| session.updated | 发送此事件以确认客户端更新的会话配置。 | |
| response.created | 当创建新的响应时返回。这是响应创建时的第一个事件,此时响应处于 in_progress 的初始状态。 | |
| response.audio_transcript.delta | 当模型生成的音频转录输出发生更新时返回该事件。 | |
| *response.audio_translation.delta | 当模型生成的音频翻译输出发生更新时返回该事件。 | |
| response.done | 在响应完成流式传输时返回。 | |
| error | 错误事件。 |
客户端事件
session.update
将此事件发送以更新会话的默认配置。如需更新配置,客户端必须在创建会话的一开始就发送该消息(发送音频之前),服务器将以 session.updated 事件响应,显示完整的有效配置。
event_id: string
可选字段,由客户端生成的事件 ID。type: string
事件类型,取值为session.update。session: object
包含以下字段:modalities: string[]
目前仅支持配置为["text"]。input_audio_format: string
输入的音频格式。目前只支持pcm16。input_audio_translation: object
包含以下字段:source_language: string
源语种,使用 ISO 639-1 语言代码(二位字母) 指定。目前仅支持zh和en。target_language: string
目标语种,使用 ISO 639-1 语言代码(二位字母) 指定。目前仅支持zh和en。注意
源语种和目标语种不能相同。
add_vocab: object
自定义词典,包含热词列表和术语列表。热词和术语的总数不能超过 200 个。如果超过数量限制,那么只有先定义的 200 个热词或术语被保留,其他会被丢弃。
包含以下字段:add_vocab: string[]
热词列表。必须使用源语种来定义热词,使用其他语种无效。glossary_list: object[]
翻译时可参考的术语列表。
包含以下字段:input_audio_transcription:原文。input_audio_translation:译文。
示例:
{ "event_id": "event_120", "type": "session.update", "session": { "input_audio_format": "pcm16", "modalities": ["text"], "input_audio_translation": { "source_language": "zh", "target_language": "en", "add_vocab": { "hot_word_list": [], "glossary_list": [ { "input_audio_transcription": "火山引擎智能创作平台", "input_audio_translation": "volcengine creative cloud" } ] } } }, }
input_audio_buffer.append
发送此事件以将音频字节追加到输入音频缓冲区。边缘大模型网关在收到音频数据后,会将其发送到豆包-同声传译模型。
event_id: string
可选字段,由客户端生成的事件 ID。type: string
事件类型,取值为input_audio_buffer.append。audio: string
Base64 编码的 audio bytes。目前只支持 pcm16 格式。
示例:
{ "type": "input_audio_buffer.append", "audio": "your_audio_data", }
*input_audio.done
发送此事件以告知服务端已经完成了所有计划发送的音频数据的发送。该事件通常在麦克风结束输入时发送。客户端发送该事件后,服务端将不再接受任何新的 input_audio_buffer.append 事件,当服务端处理完已接收到的所有音频数据后会发送 response.done 事件并断开连接。
示例:
{ "type": "input_audio.done", }
服务端事件
session.created
在会话创建时返回。新连接建立时自动触发,作为第一个服务器事件。此事件将包含默认的会话配置。
event_id: string
可选字段,由客户端生成的事件 ID。type: string
事件类型,取值为session.update。session: object
包含以下字段:id: string
会话的唯一 ID。object: string
会话对象的类型,取值为"realtime.session"modalities: string[]
目前仅支持["text"]。input_audio_format: string
输入的音频格式。目前只支持pcm16。model: string
实际使用的模型名称和版本。input_audio_translation: object
包含以下字段:source_language: string
源语种,使用 ISO 639-1 语言代码(二位字母) 指定。目前仅支持zh和en。target_language: string
目标语种,使用 ISO 639-1 语言代码(二位字母) 指定。目前仅支持zh和en。注意
源语种和目标语种不能相同。
add_vocab: object
自定义词典,包含热词列表和术语列表。热词和术语的总数不能超过 200 个。
包含以下字段:add_vocab: string[]
热词列表。glossary_list: object[]
翻译时可参考的术语列表。
包含以下字段:input_audio_transcription:原文。input_audio_translation:译文。
示例:
{ "event_id": "event_123", "type": "session.created", "session": { "id": "sess_***", "object": "realtime.session", "modalities": [ "text" ], "model": "doubao-clasi-s2t", "input_audio_format": "pcm16", "input_audio_translation": { "source_language": "zh", "target_language": "en", "add_vocab": null } } }
session.updated
发送此事件以确认客户端更新的会话配置。服务器将以 session.updated 事件响应,显示完整的有效配置。
event_id: string
可选字段,由客户端生成的事件 ID。type: string
事件类型,取值为session.update。session: object
包含以下字段:id: string
会话的唯一ID。object: string
会话对象的类型,取值为"realtime.session"modalities: string[]
目前仅支持["text"]。input_audio_format: string
输入的音频格式。目前只支持pcm16。model: string
实际使用的模型名称和版本。input_audio_translation: object
包含以下字段:source_language: string
源语种,使用 ISO 639-1 语言代码(二位字母) 指定。目前仅支持zh和en。target_language: string
目标语种,使用 ISO 639-1 语言代码(二位字母) 指定。目前仅支持zh和en。注意
源语种和目标语种不能相同。
add_vocab: object
自定义词典,包含热词列表和术语列表。热词和术语的总数不能超过 200 个。
包含以下字段:add_vocab: string[]
热词列表。glossary_list: object[]
翻译时可参考的术语列表。
包含以下字段:input_audio_transcription:原文。input_audio_translation:译文。
示例:
{ "event_id": "event_124", "type": "session.updated", "session": { "id": "sess_***", "object": "realtime.session", "modalities": [ "text" ], "model": "doubao-clasi-***", "input_audio_format": "pcm16", "input_audio_translation": { "source_language": "zh", "target_language": "en", "add_vocab": { "hot_word_list": [], "glossary_list": [ { "input_audio_transcription": "火山引擎智能创作平台", "input_audio_translation": "volcengine creative cloud" } ] } } } }
response.created
当创建新的响应时返回。这是响应创建时的第一个事件,此时响应处于 in_progress 的初始状态。
event_id: string
可选字段,由服务端生成的事件 ID。type: string
事件类型,取值为response.created。response: object
响应的对象详情,包含以下字段:id: string
响应的 ID。object: string
对象类型,必须为realtime.response。status: string
响应的状态,目前包含以下取值:in_progress。
示例:
{ "event_id": "event_125", "type": "response.created", "response": { "id": "resp_***", "object": "realtime.response", "status": "in_progress", } }
response.audio_transcript.delta
当模型生成的音频转录输出发生更新时返回该事件。
event_id: string
可选字段,由服务端生成的事件 ID。type: string
事件类型,取值为response.audio_transcript.delta。response_id: string
响应的 ID。delta: string
模型转录生成的增量文本信息(源语种)。
示例:
{ "event_id": "event_127", "type": "response.audio_transcript.delta", "response_id": "resp_0217355307251692f1d0fe07ac2ef6d29344c285c5cccbb1eed50", "delta": "定制服务" }
*response.audio_translation.delta
当模型生成的音频翻译输出发生更新时返回该事件。
event_id: string
可选字段,由服务端生成的事件 ID。type: string
事件类型,取值为response.audio_translation.delta。response_id: string
响应的 ID。delta: string
模型翻译生成的增量文本信息(目标语种)。
示例:
{ "event_id": "event_127", "type": "response.audio_translation.delta", "response_id": "resp_0217355307251692f1d0fe07ac2ef6d29344c285c5cccbb1eed50", "delta": "translated text" }
response.done
发送此事件以告知客户端,服务端已经处理完所有接收到的音频数据,并且已经发送了所有的文本数据,本次连接结束。
event_id: string
可选字段,由服务端生成的事件 ID。type: string
事件类型,取值为response.done。response: object
响应的对象详情,包含以下字段:id: string
响应的 ID。object: string
对象类型,必须为realtime.response。status: string
响应的最终状态,目前支持completed:服务端处理完已接收到的所有音频数据,正常结束连接。failed:发生错误,连接中断。timeout:连接超时,服务端强制断开连接。
usage: object
使用统计,包含以下字段:total_tokens: integer
应答消耗的所有 token 数量,包括输入和输出的 token。input_tokens: integer
应答消耗的输入 token 数量。output_tokens: integer
应答消耗的输出 token 数量。
说明
当前同声传译模型仅有
output_tokens。
示例:
{ "event_id": "event_126", "type": "response.done", "response": { "id": "resp_0217355307251692f1d0fe07ac2ef6d29344c285c5cccbb1eed50", "object": "realtime.response", "status": "completed", "usage": { "total_tokens": 423 "output_tokens": 423 } } }
error
发生错误时返回,可能是客户端或服务端导致的问题。大多数错误均可恢复,且会话将保持连接状态,建议您默认监控和记录错误消息。
event_id: string
可选字段,由服务端生成的事件 ID。type: string
事件类型,取值为error。error: object 错误的详情,包含以下字段:type: string
错误的类型,包含以下取值:invalid_request_error、server_error。code: string
错误码。message: string
错误的文本内容。param: string
错误的相关参数。event_id: string
相关的客户端事件 ID,目前为空。
示例:
{ "event_id": "event_129", "type": "error", "error": { "code": "InvalidParameter", "message": "A parameter specified in the request is not valid: input audio format must be pcm16 Request id: ****", "type": "BadRequest", "param": "input audio format must be pcm16" } }
Python 代码示例
安装依赖包:
pip install soundfile scipy numpy websockets==12.0
下载测试音频:


import asyncio import base64 import json import numpy as np import soundfile as sf from scipy.signal import resample import websockets def resample_audio(audio_data, original_sample_rate, target_sample_rate): number_of_samples = round( len(audio_data) * float(target_sample_rate) / original_sample_rate) resampled_audio = resample(audio_data, number_of_samples) return resampled_audio.astype(np.int16) async def send_audio(client, audio_file_path: str): sample_rate = 16000 duration_ms = 200 samples_per_chunk = sample_rate * (duration_ms / 1000) bytes_per_sample = 2 bytes_per_chunk = int(samples_per_chunk * bytes_per_sample) extra_params = {} audio_data, original_sample_rate = sf.read( audio_file_path, dtype="int16", **extra_params) if original_sample_rate != sample_rate: audio_data = resample_audio( audio_data, original_sample_rate, sample_rate) audio_bytes = audio_data.tobytes() for i in range(0, len(audio_bytes), bytes_per_chunk): # await asyncio.sleep((duration_ms-10)/1000) chunk = audio_bytes[i: i + bytes_per_chunk] base64_audio = base64.b64encode(chunk).decode("utf-8") append_event = { "type": "input_audio_buffer.append", "audio": base64_audio } await client.send(json.dumps(append_event)) input_audio_done_msg = { "type": "input_audio.done" } await client.send(json.dumps(input_audio_done_msg)) async def receive_messages(client): while not client.closed: message = await client.recv() if message is None: continue print(message) event = json.loads(message) message_type = event.get("type") if message_type == "response.audio_transcript.delta": print("response.audio_transcript.delta: {}\n".format(event["delta"])) continue if message_type == "response.audio_translation.delta": print("response.audio_translation.delta: {}\n".format(event["delta"])) continue if message_type == 'response.done': print("================Done================") return continue def get_session_update_msg(): config = { "input_audio_translation": { "source_language": "en", "target_language": "zh", }, "modalities": ["text"], "input_audio_format": "pcm16", } event = { "type": "session.update", "session": config } return json.dumps(event) async def with_realtime(audio_file_path: str): ws_url = "wss://ai-gateway.vei.volces.com/v1/realtime?model=doubao-clasi-s2t" key = "your_api_key" # 您的 API key headers = { "Authorization": f"Bearer {key}", } async with websockets.connect(ws_url, extra_headers=headers) as client: session_msg = get_session_update_msg() await client.send(session_msg) await asyncio.gather(send_audio(client, audio_file_path), receive_messages(client)) await asyncio.sleep(0.5) if __name__ == "__main__": audio_file_path = "translation_demo.mp3" #示例音频的路径 asyncio.run(with_realtime(audio_file_path))