本文介绍了如何在边缘智能控制台创建一个自定义模型。
概述
除了使用边缘智能提供的官方模型,您也可以创建自定义模型。自定义模型可以基于边缘智能 Triton 推理框架(Triton Inference Server ),也可以基于自定义推理框架。
- 使用 Triton 推理框架时,边缘智能允许您创建以下几类自定义模型:
- 单模型:基于主流模型框架训练的模型。
支持的框架包括:TensorRT、ONNX、TensorFlow、OpenVINO、PyTorch、ByteNN、PaddlePaddle、TensorFlow-LLM。更多信息,请参见支持的框架。 - 模型组合:将多个单模型组装在一起,实现更加复杂的功能。
模型组合是指将一个或多个模型以管道的形式组合在一起,以及定义这些模型之间输入和输出张量的连接。模型组合用来封装包含多个模型的过程,例如“数据预处理 -> 推理 -> 后处理”。使用模型组合可以避免传输中间张量的开销,并减少发送到服务端的请求数量。
模型组合对应的方法为 Ensemble,模型组合能够接入 Python 类型的后处理脚本。 - 模型组合的 Python 后处理脚本
- 单模型:基于主流模型框架训练的模型。
- 使用自定义推理框架时,模型框架是不受限制的。
前提条件
您已经开通了边缘智能。相关操作,请参见开通边缘智能。
操作步骤
登录边缘智能控制台。
在左侧导航栏,从 我的项目 下拉列表选择一个项目。
- 在左侧导航栏,选择 边缘推理 > 模型管理。
- 在 自定义模型 页签下,单击 新建模型。
- 在 创建模型 页面,参照配置说明完成相关参数的配置,然后单击 确定。
完成以上操作后,您可以在模型管理列表看到刚刚创建的模型。
配置说明
通用配置项
配置项 | 说明 |
|---|---|
名称 | 为模型设置名称。您可以使用以下字符:英文字母、数字、汉字、下划线(_)和连字符(-)。请注意以下规则:
|
模型分类 | 选择模型的用途。可选项: |
推理框架 | 选择模型使用的推理框架(即推理框架)。可选项:
|
描述 | 为模型添加描述。长度不超过 128 个字符。 |
Triton 框架特有配置项
当 推理框架 为 Triton 框架 时,您需要完成以下参数配置。
配置项 | 子配置项 | 说明 |
|---|---|---|
模型框架 | N/A | 选择模型的框架。可选项:
|
输入、输出 说明 框架 为 TensorRT 或 ONNX 时,无需配置 输入和 输出。 | 名称 | 设置输入、输出参数的名称。请注意以下规则:
|
类型 | 选择输入、输出参数的类型。可选项: | |
形状 | 设置输入和输出形状信息。输入和输出形状由 max_batch_size 和输入或输出维度(dimensions)属性指定的尺寸组合指定。
示例:
| |
转换形状 | 设置输入、输出数据的转换形状信息。每输入一个维度后,按回车确认。允许输入多个维度。 说明 模型框架 为 Ensemble 时,该参数不会出现。 转换形状用于指示推理 API 可接受的输入或输出的形状。它与底层推理框架模型或自定义模型所期望或生成的输入或输出形状不同。 | |
格式 | 输入数据的格式。可选项:
说明
| |
不规则处理 | 是否允许该张量在动态创建的批处理中是不规则的。
说明 输出 配置中不包含该参数。 | |
是否可选 | 该输入是否对模型执行是可选的。默认值为否,表示该输入是必选的。如果设置为是,则推理请求中不需要该输入。 说明 输出 配置中不包含该参数。 | |
模型配置 | N/A | Ensemble 模型中包含一个或多个已有模型。该参数表示 Ensemble 模型中输入、输出参数的映射关系。关于 Ensemble 模型配置的具体方法,请参见 模型组合配置说明。 说明 只有当 模型框架 为 Ensemble 时,您需要配置该参数。 |
Ensemble 配置说明
当您创建模型组合(模型框架 为 Ensemble)时,您需要完成模型配置。以下是模型配置的具体方法:
说明
您可以参考配置示例,了解 Ensemble 模型配置的逻辑。
- 从模型下拉列表选择一个已有模型(为了描述方便,用“子模型”来指代)。
- 所选择子模型的输入和输出配置将被读取出来,作为 原始输入 和 原始输出。
- 您可以单击 添加,在 Ensemble 模型中添加多个子模型。顺序靠前的子模型优先处理。
- 为每个子模型配置 输入映射 和 输出映射。
您需要为每个子模型的原始输入、原始输出设置在 Ensemble 模型中映射的输入和输出。原始输入在 Ensemble 模型中映射的输入是 输入上游、原始输出在 Ensemble 模型中映射的输出是 输出下游。- 输入上游 允许配置为:
- Ensemble 模型的某个输入。
- 前置子模型的某个自定义输出。
当一个子模型的原始输入有多个时,您必须为每个原始输入指定一个输入上游,并且这些输入上游不允许重复。
- 输出下游 允许配置为:
- Ensemble 模型的某个输出。
- 自定义输出:您自定义一个输出,在 Ensemble 模型内流转使用。
当一个子模型的原始输出有多个时,您可以为其中至少一个原始输出指定输出下游,其他输出下游允许留空。
- 输入上游 允许配置为:
注意
- Ensemble 模型的输入可以在不同模型中重复使用。
- Ensemble 模型的每个输出都必须映射到一个原始输出。Ensemble 模型的输出不允许在不同模型中重复使用。
配置示例
您可以参考以下示例,以便理解 Ensemble 模型的配置逻辑。
假设您要将两个模型组装在一起使用,它们依次是:前处理模型、推理模型。
- 前处理模型有 2 个输入(input-1 和 input-2) 和 2 个输出(output-1 和 output-2)。
- 推理模型有 1 个输入(input.1)和 1 个输出(output.1)。
您希望前处理模型对数据进行预处理后,将数据流转到推理模型进行推理。
为满足该需求,您可以创建一个 Ensemble 模型。Ensemble 模型包含 2 个输入(src-1 和 src-2)和 1 个输出(des-1)。它的数据处理逻辑如下图所示。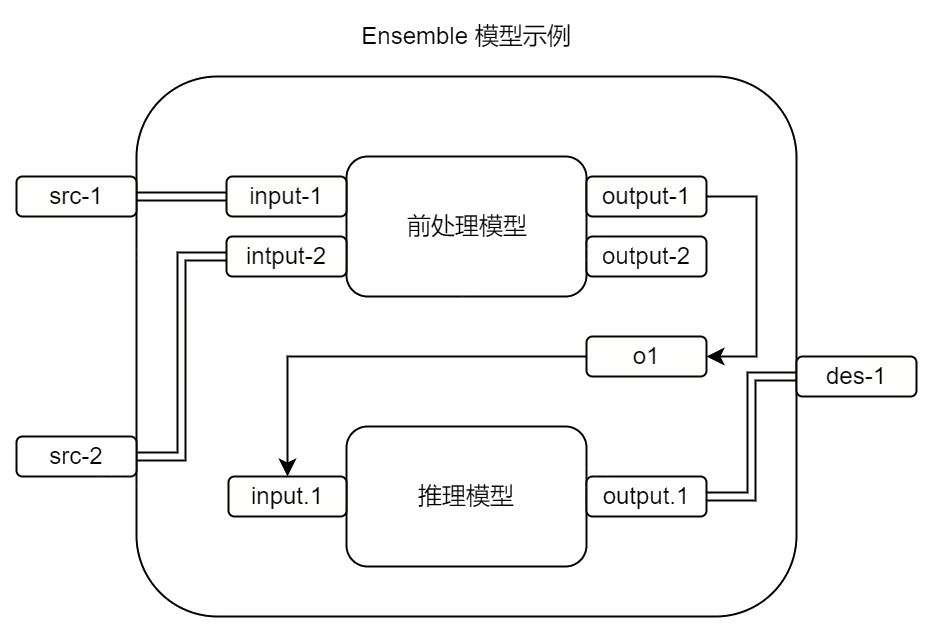
在这个场景下,Ensemble 模型的 Tensor 可以按照如下方式配置。其中,m-pre 表示前处理模型、m-post 表示推理模型。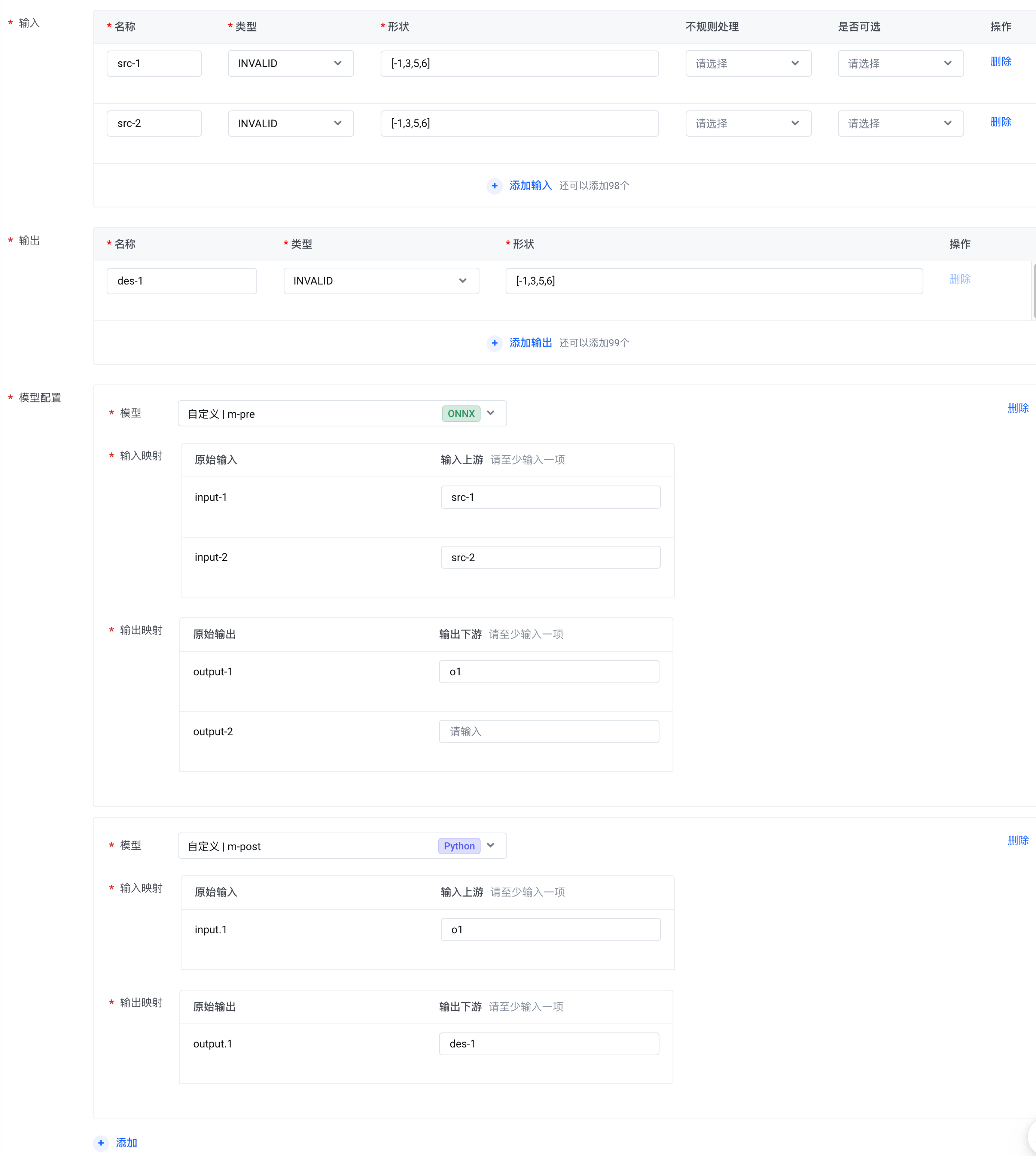
后续步骤
新建的模型还无法使用。接下来,您需要为该模型创建并发布版本。在版本中,您将要添加相应的模型文件。针对不同的推理框架,版本管理方法不同。请根据自定义模型的推理框架,参考相关文档:
- Triton 框架:请参见创建一个版本和发布版本。
基于 Triton 框架的模型支持前后处理版本和 ONNX 模型文件加密功能。如需使用相关功能,您需要创建一个前后处理版本、为 ONNX 模型文件加密。更多信息,请参见创建一个前后处理版本、使用 ONNX 模型加密功能。 - 自定义框架:请参见创建一个版本和发布版本。