导航
用量统计
最近更新时间:2025.04.17 10:12:47首次发布时间:2024.11.08 10:35:19
本文介绍了边缘大模型网关的用量统计方法,以及如何查询您的用量。
用量统计说明
边缘大模型网关根据您(通过边缘大模型网关)向模型发出的请求以及模型的响应来统计您的用量。
说明
- 边缘大模型网关只负责汇总经过网关发生的模型用量,实际对模型请求进行计费的是模型提供商。
- 当一个模型请求成功时,模型提供商通常会在模型响应中包含本次请求的用量。边缘大模型网关从模型响应中获取用量数据进行统计。
- 不同模型提供商对模型用量的计量方式可能有所不同,以模型提供商的官方说明为准。
用量统计方式
不同类型的模型使用不同的方式来计算使用情况。
| 方式 | 适用的模型类型 | 说明 |
|---|---|---|
按 “Token” 计算模型用量 |
| Token 有以下两种类型:
不同模型的 Token 转换算法不同。关于 Token 的详细说明,可参考 OpenAI 官网文档 - What are tokens and how to count them?。 |
| 按 “调用次数” 计算模型用量 | TextToImage(文生图) | 关于平台预置的豆包 - 文生图模型的计费说明,请参见图像技术 - 产品计费。 |
按 “字符数” 计算模型用量 | Speech(语音合成) |
|
| 按 “语音时长” 计算模型用量 | Audio(语音识别) | 关于平台预置的豆包 - 语音识别模型的计费说明,请参见语音技术 - 计费概述。 |
用量统计数据
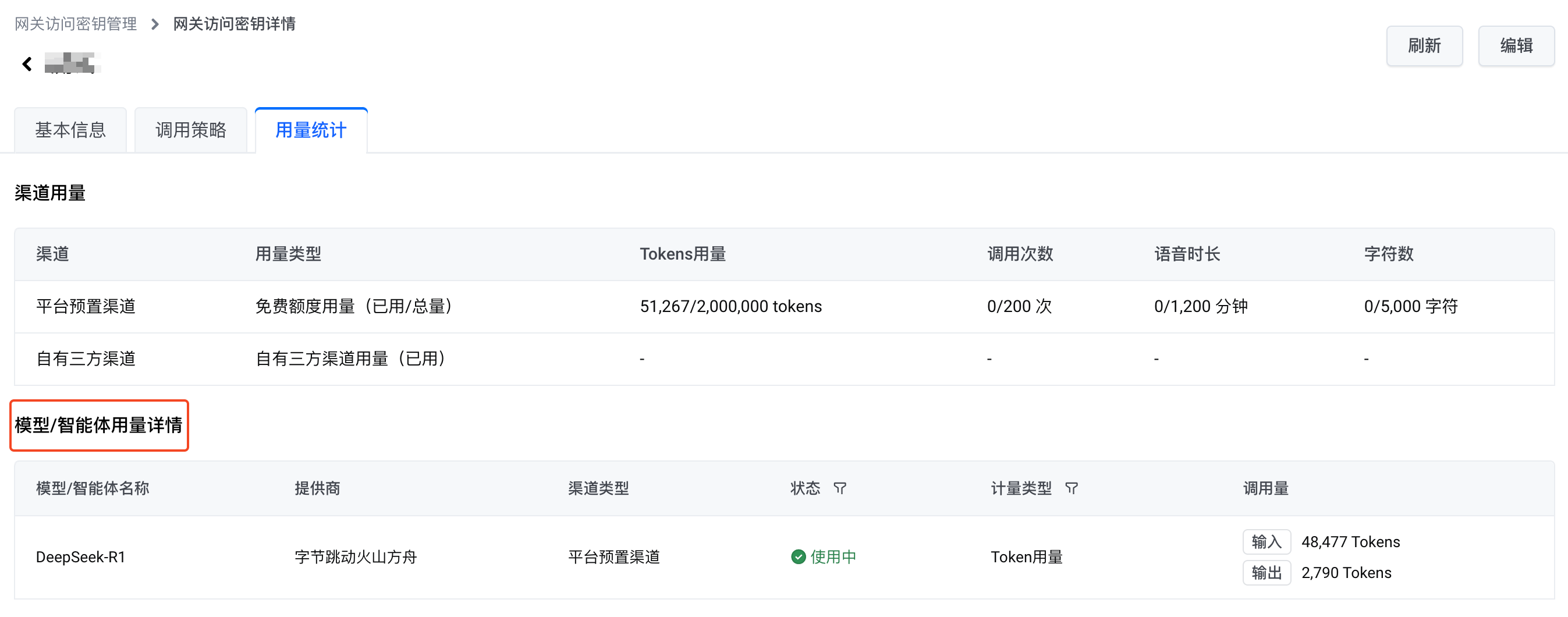
您可以在边缘大模型网关控制台查看通用网关访问密钥的用量统计数据。统计数据包含:
- 汇总数据:
- 平台预置渠道用量:调用平台预置模型和智能体消耗的资源(如 Token)总量
- 自有三方渠道用量:调用第三方模型和智能体消耗的资源(如 Token)总量
- 细分数据:
- 模型/智能体维度用量统计:调用特定模型或智能体消耗的资源量
查询用量统计
要查询您的通用网关访问密钥的用量统计数据:
登录边缘大模型网关控制台。
在左侧导航栏,单击 网关访问密钥。
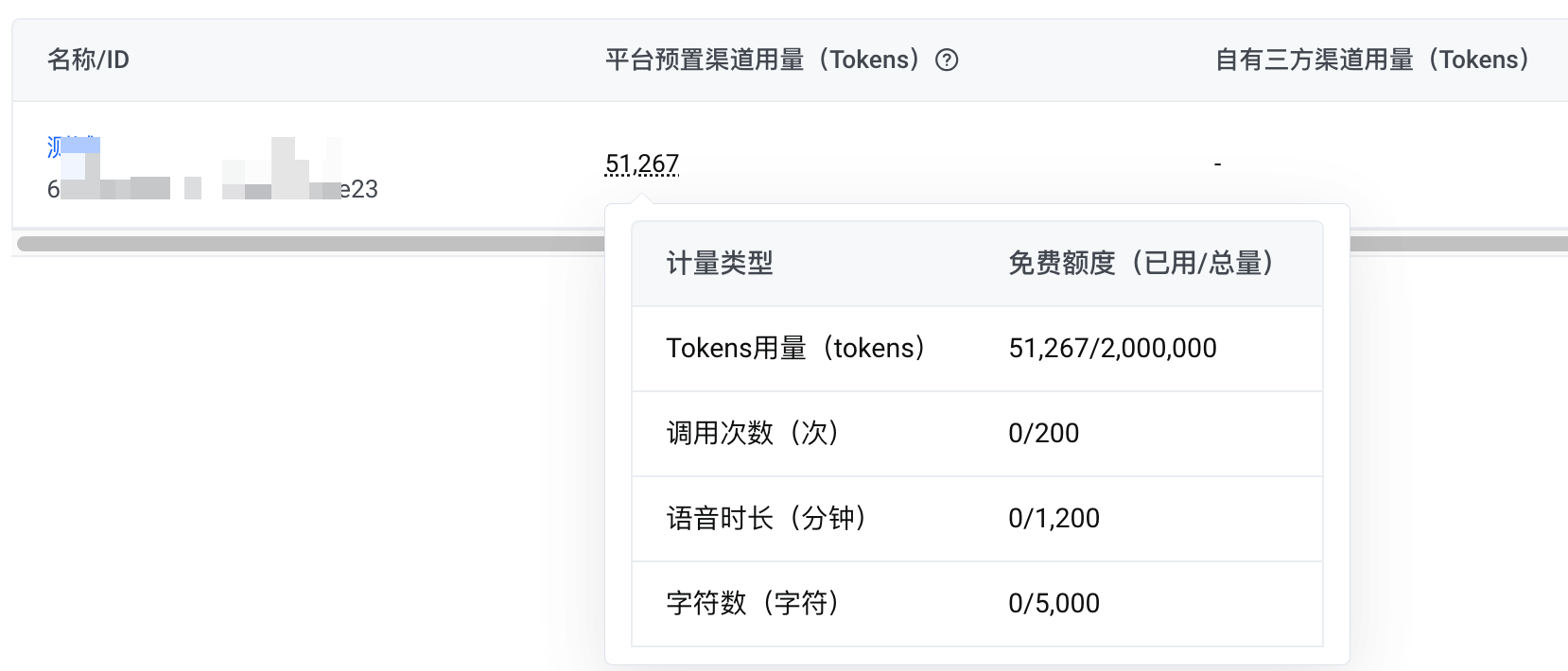
在网关访问密钥列表找到您的网关访问密钥,查看 平台预置渠道用量 和 自有三方渠道用量。
说明
- 列表中的用量统计数据默认显示 Token 消耗量。要查看其他类型的用量,可以将光标放置在用量数值上。详细的用量数据将会显示。
- 为确保获取最新数据,您可以单击列表右上方的刷新按钮,对列表中的数据进行刷新。
要查看模型/智能体维度的用量统计:
- 单击密钥名称进入密钥详情。
- 单击 用量统计 页签,查看 模型/智能体用量详情。