任务创建,是指可视化建模任务的创建环节,通常包含新建任务、数据连接等步骤。可视化建模任务支持抽取数据源中的数据,通过拖拽形式添加数据处理节点,将处理完成的数据输出到目标源中。
说明
- 任务类型:实时任务、离线任务(任务创建后不可切换任务类型)
- 实时任务,指的是任务跟随实时更新的数据源可被实时执行,输出为实时更新的数据。实时任务支持输入的数据源为:Kafka、Pulsar;
- 离线任务,指的是任务跟随离线更新的数据源可被设置为手动和周期执行,输出为定期更新的数据或模型文件。离线任务支持输入的数据源为:Hive, MySQL, ClickHouse, Kafka, HttpAPI, 飞书, CSV/Excel, Oracle, Impala, PostgreSQL, Hbase, SQLServer, MaxCompute, ADB, MongoDB, Hana, Teradata, Db2, Vertica, GreenPlum等20余种主流的数据源;
本文将结合产品实操界面介绍 离线任务 的创建步骤。
- 用户需具备 项目编辑 权限或者 可视化建模模块的新建任务 权限,才能使用该功能。
- 可视化建模中部分功能为 付费能力,如有需要,请联系您的商务经理
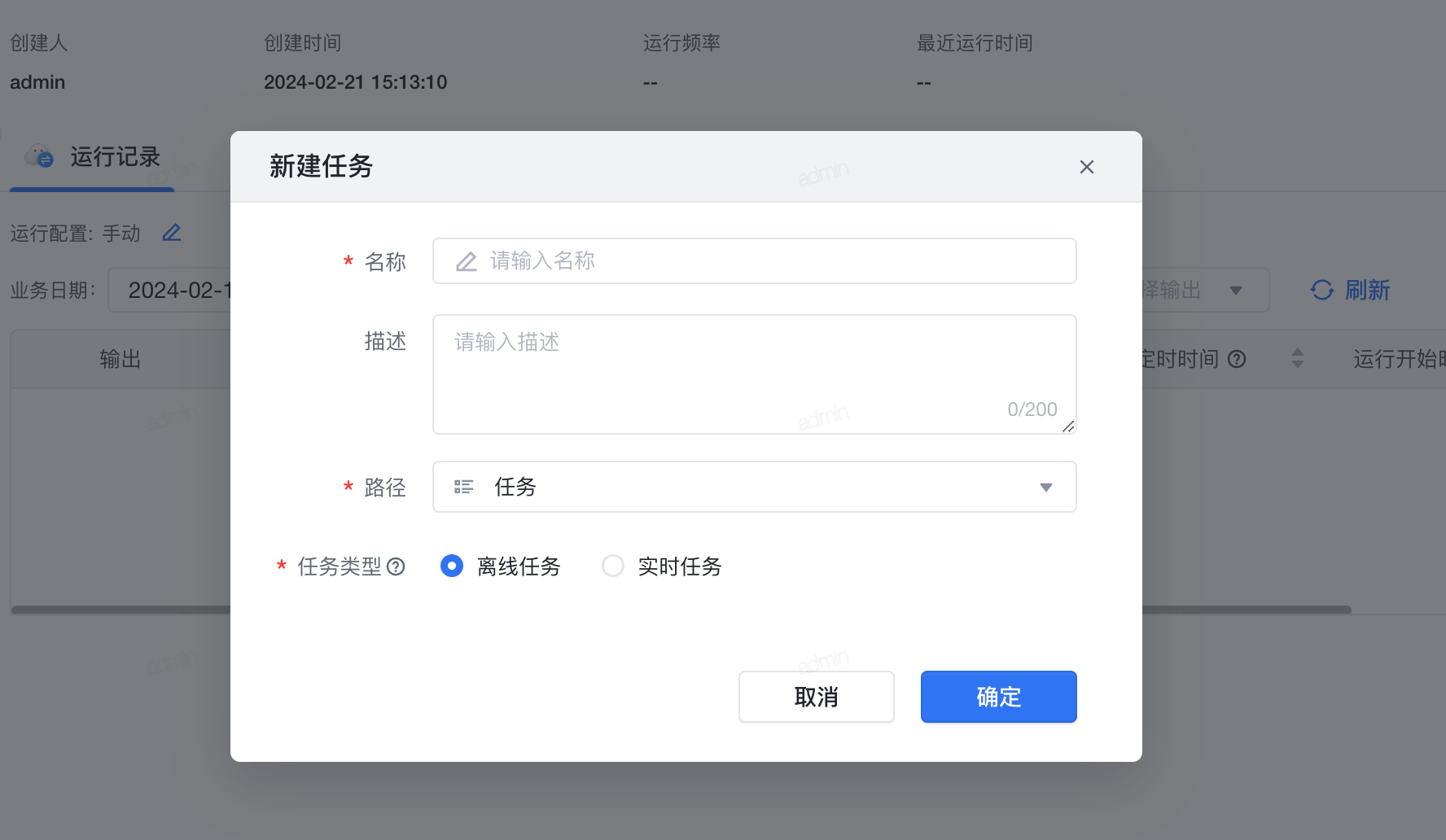
3.1 新建任务
- 点击 数据管理>可视化建模 。
- 点击左上角 新建任务 。
- 选择 路径 ,将当前任务存放在左侧某个可视化建模任务文件夹下。
- 选择创建 离线任务 。
3.2 应用示例模板
在可视化建模任务编辑页面,提供多样化的算子模板,点击 全部模板 可快速查看。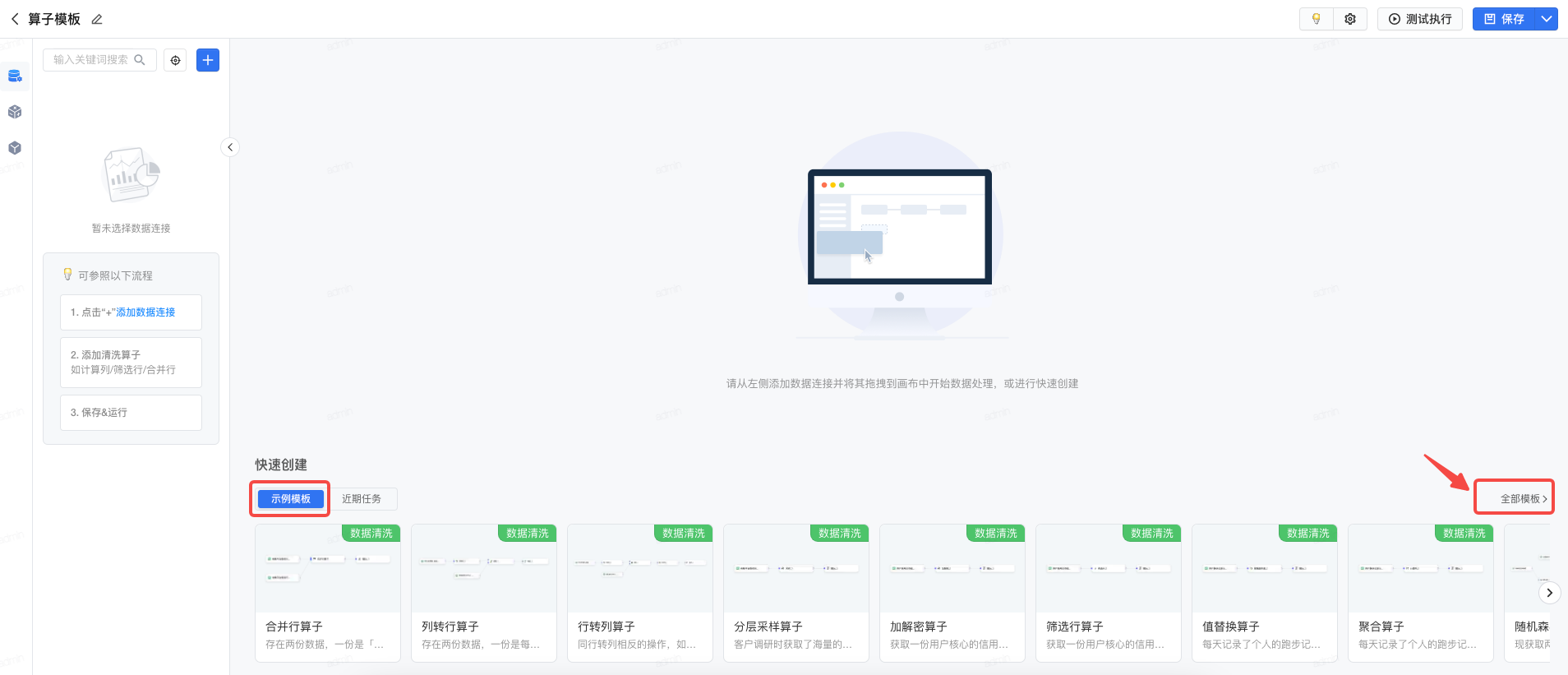
每个模板均支持 预览 或 应用 。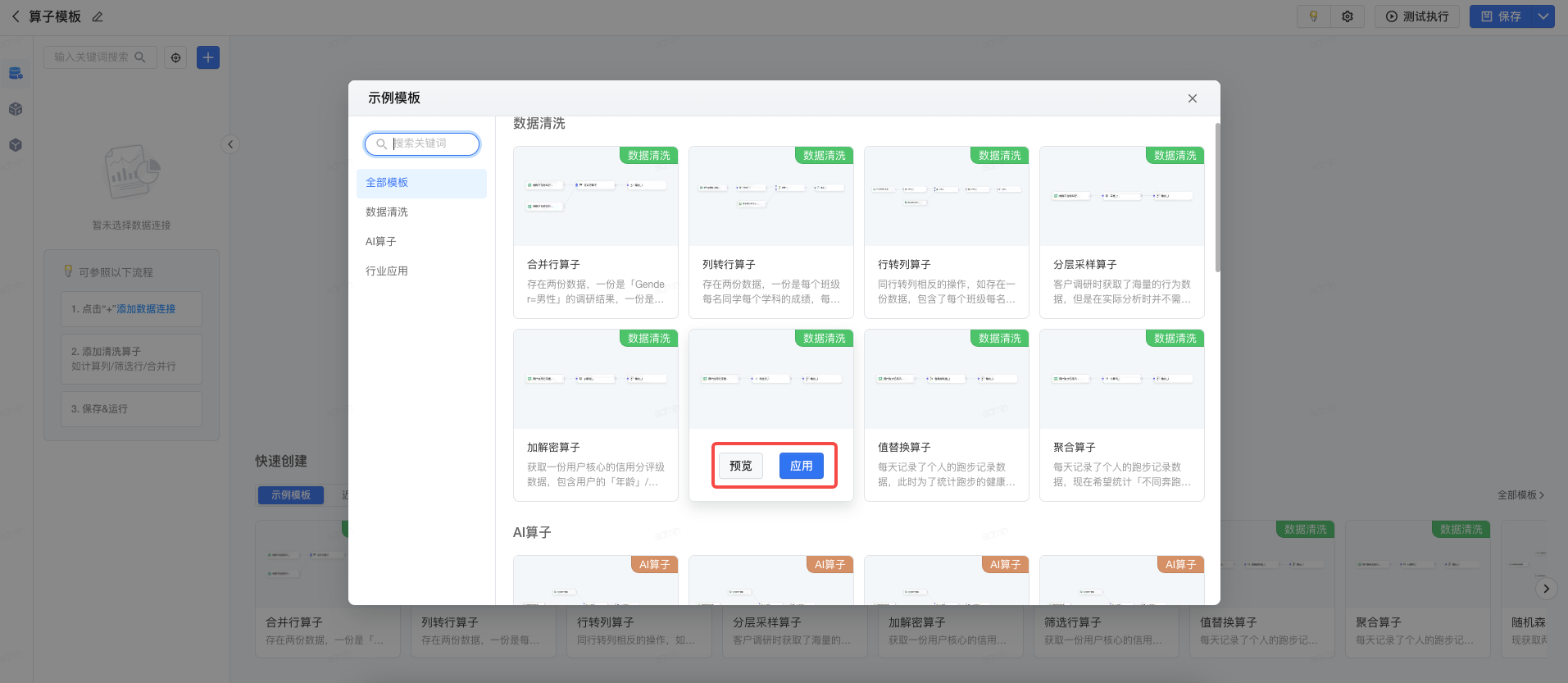
点击 预览 ,将详细介绍当前算子模板内置的样例数据、场景说明、使用到的算子,点击 使用模板 可快速套用。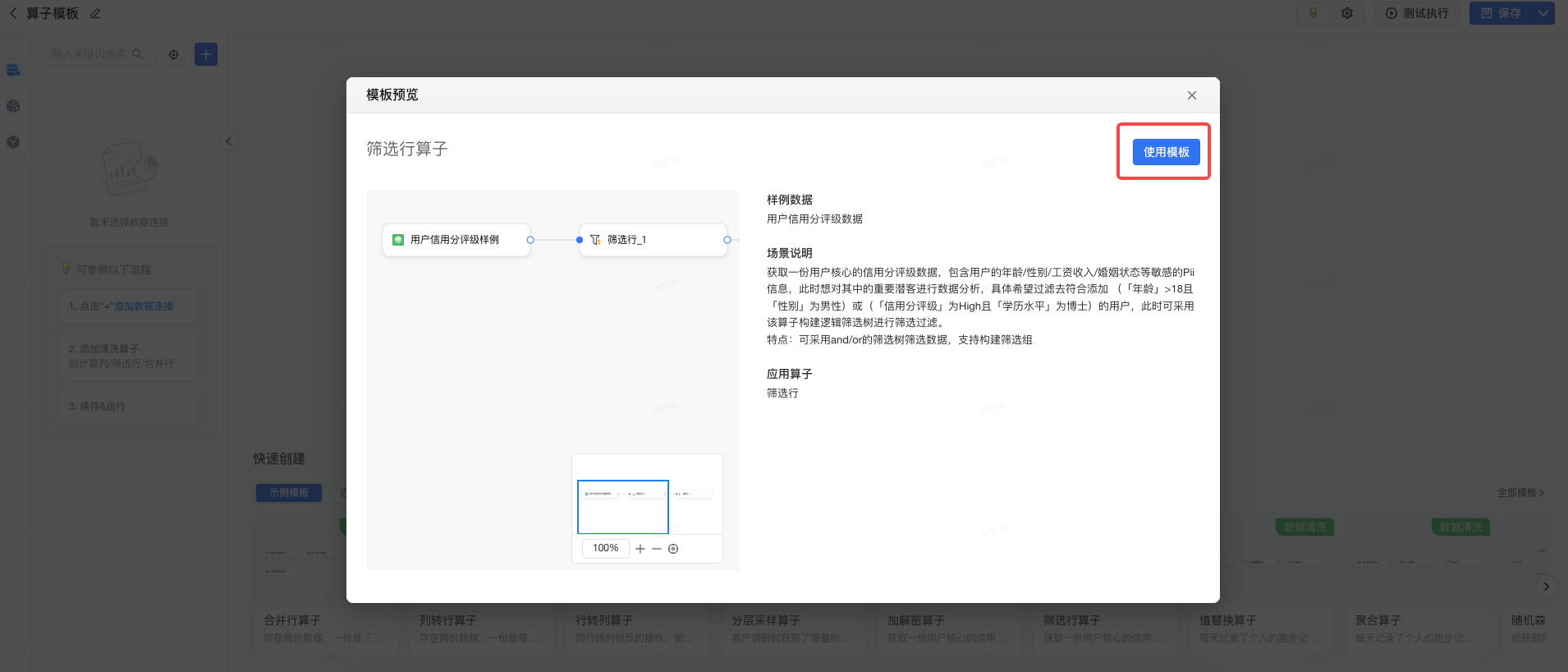
使用模板后,系统将展示使用系统样例数据处理对应应用场景的详细配置,帮助用户进一步了解当前算子的能力及使用方式。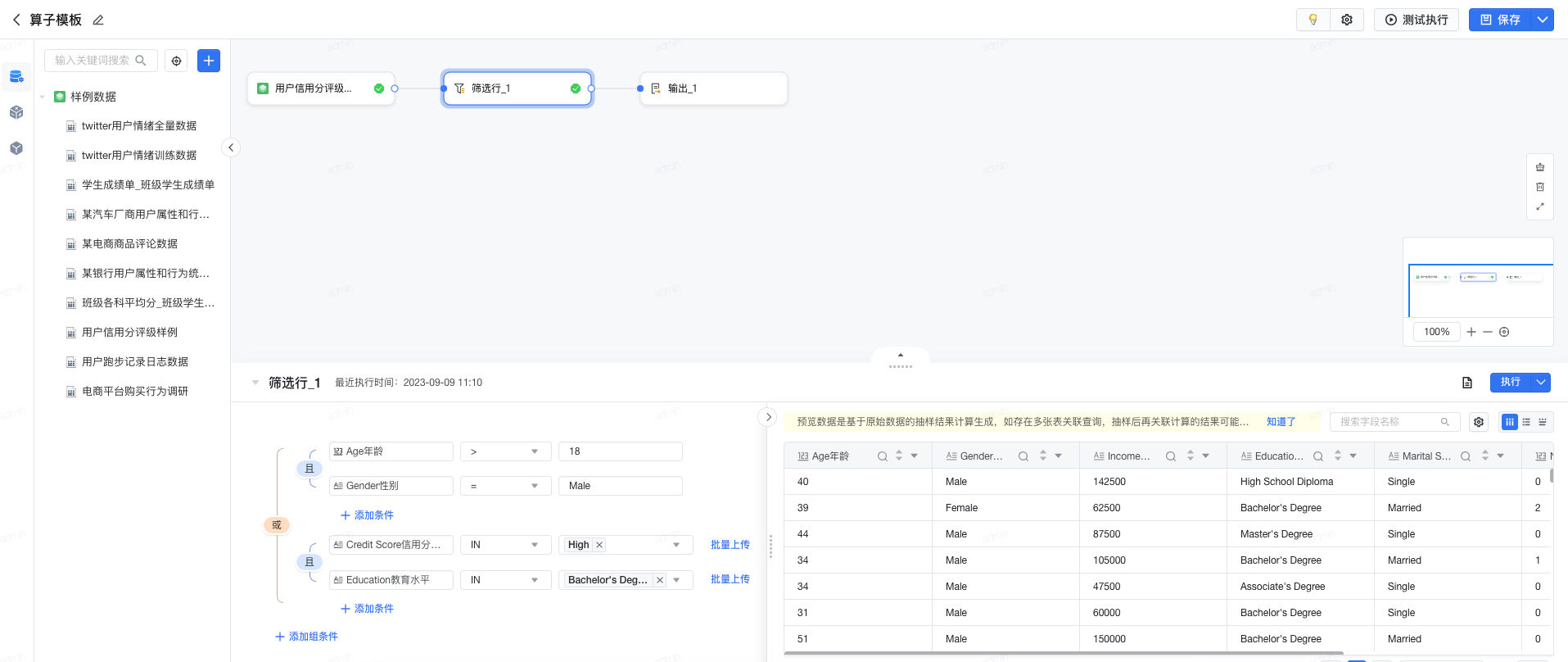
3.3 数据连接
新建数据连接。 在新建任务页面,点击左上方的加号,添加数据连接;可以选择添加多种类型的数据连接,平台支持对大部分离线存储做自定义SQL。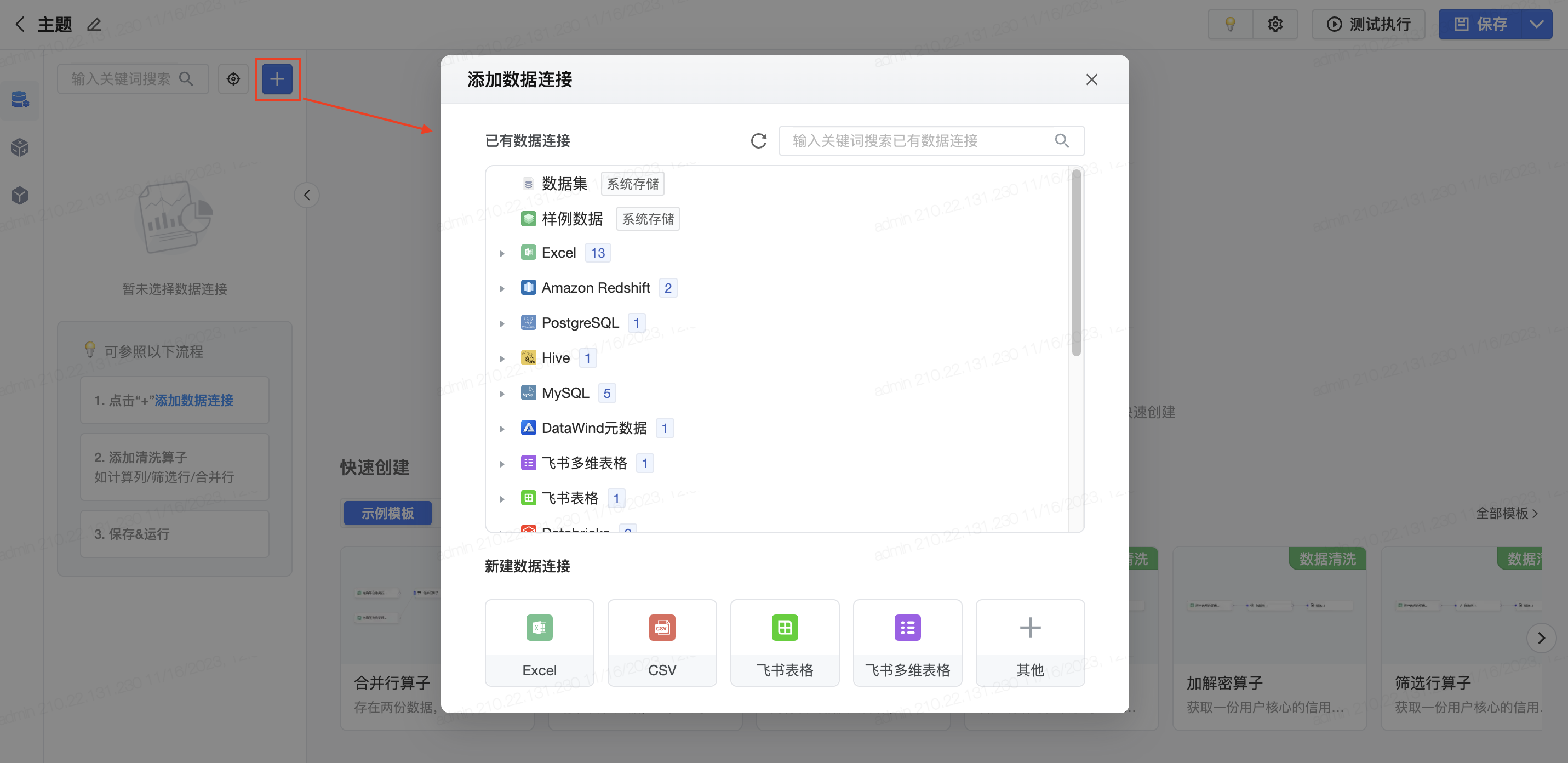
注意
如果选择了数据集,在左侧画布中会加载:自定义SQL、可视化建模数据集、客户数据平台数据集:
- Hive/ClickHouse自定义SQL:
- Hive:可视化建模界面,展示当前登录用户有权限的hive库表:
1)基于当前登录的用户的权限,库表清单通过 api 调用获取;
2)如果需要使用具体某一个表构建可视化建模 etl 任务,需要针对具体库表给火山底座的kerbros账号授权,例如用户想要使用 db1.tbl1,在 uat 环境,需要给 minibase_uat 授权; - ClickHouse:可视化建模输出并且数据存储为Clickhouse数据集,可以写SQL,满足ClickHouse语法即可
- Hive:可视化建模界面,展示当前登录用户有权限的hive库表:
- 可视化建模数据集:可视化建模输出的数据集,不区分输出存储类型是Hive/ClickHouse
- 客户数据平台数据集:购买并部署客户数据平台,系统生产的数据集。
移除数据连接。 可视化建模任务创建页面的数据连接列表中,点击具体某个数据连接右侧的删除按钮,即可移除数据连接。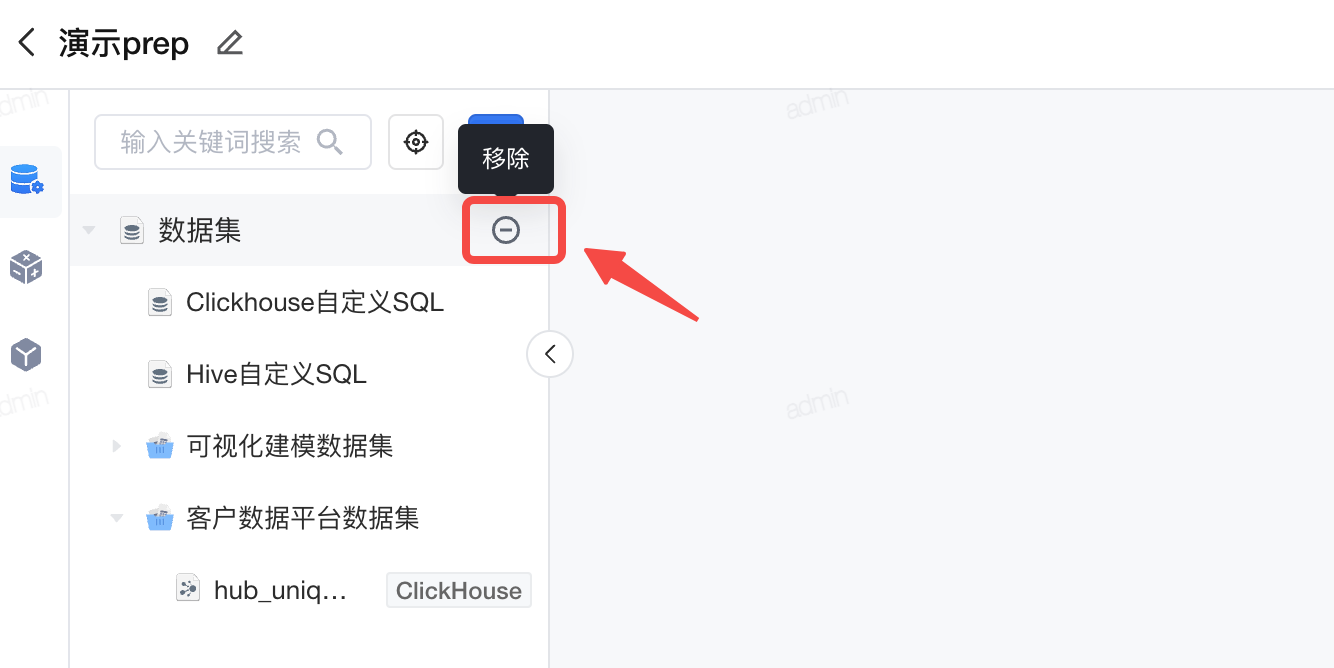
3.4 处理节点
通过点击节点右侧加号添加并配置处理节点,拖拽上一节点右侧加号和下一节点左侧原点连线,配置节点流转关系。点击“应用”后可展开处理后的数据结果预览。
如下图所示,点击输入数据算子块的输出+号,展开操作节点:输出、数据清洗、AI-特征工程、AI-机器学习、AI-自然语言,点击其中一类,则可看到可以使用的算子。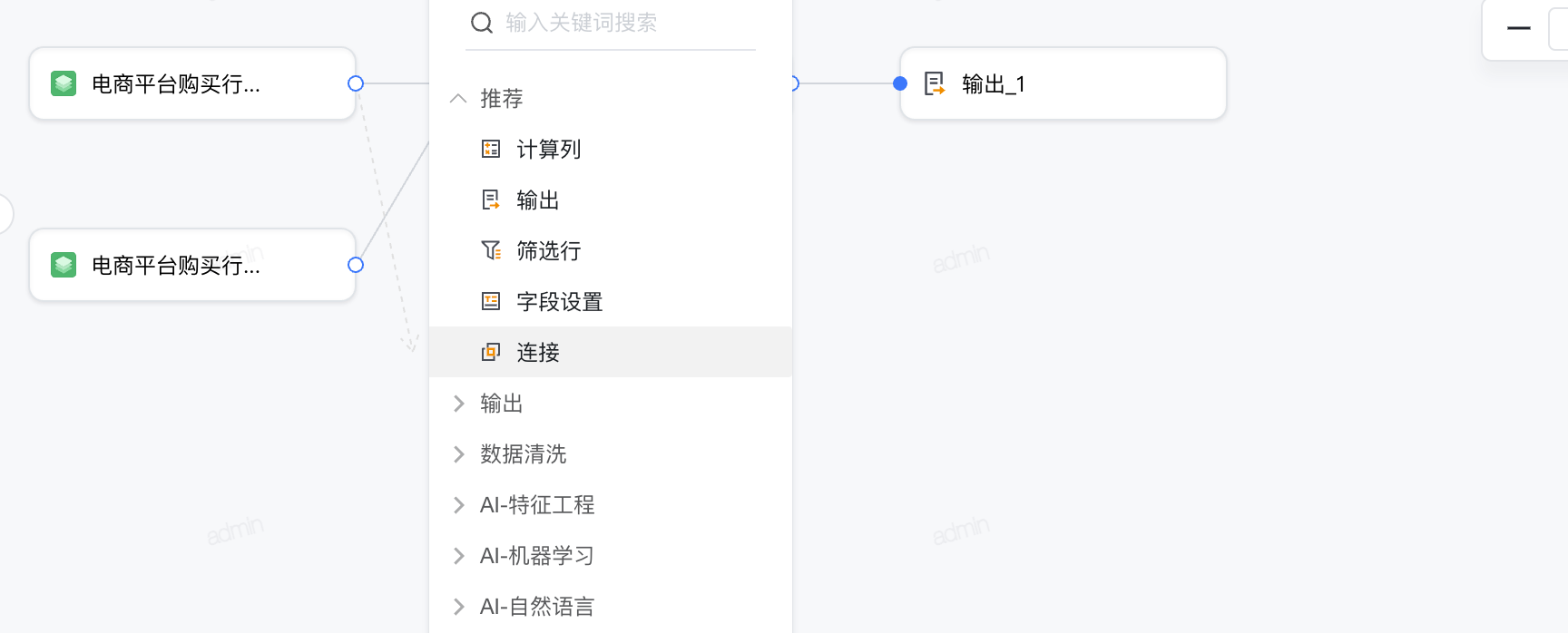
说明
常用算子如下:
- 输出:表示画布流程执行完数据输出到指定位置并配置任务执行逻辑
- 数据清洗:主要负责模型搭建(如多表连接、多表合并)、字段格式转换(如字段设置、行转列、列转行)、数据计算(如计算字段、聚合、前K值Top值)、数据过滤(如去重、采样)等
- 特征工程/机器学习:表示如主成分分析、特征重要度、聚类、分类、回归等AI算法能力
- 自然语言处理:表示NLP自然语言处理能力,其中分词、移除停用词采用词包为开源词包
3.5 画布配置
常规数据处理
- 添加输入算子:从左侧拖拽数据连接到画布中
- 添加中间算子:添加数据处理算子(数据清洗算子、AI类算子)
- 添加输出算子:选择「输出」算子,将数据输出到数据集
AI数据挖掘
- 添加输入算子:从左侧拖拽数据连接到画布中
- 添加中间算子:添加AI类算子(AI-特征工程、AI-机器学习、AI-自然语言、AI-预测)
- 添加输出算子:选择「保存模型」算子,将数据保存到模型
添加节点 方式一:点击算子卡片中的“+”,展开下拉菜单并添加节点。 方式二:从左侧拖拽算子到画布中。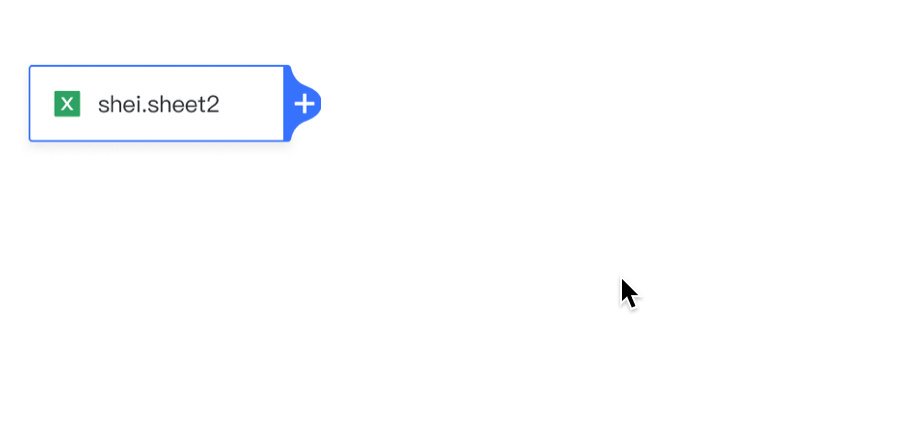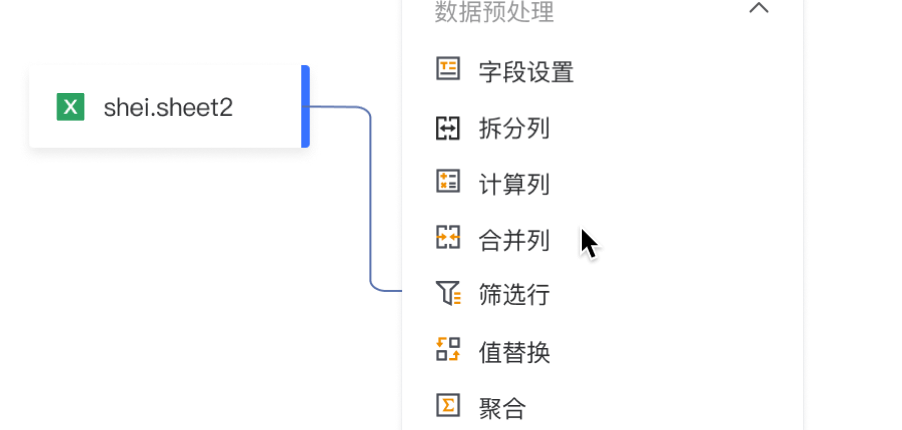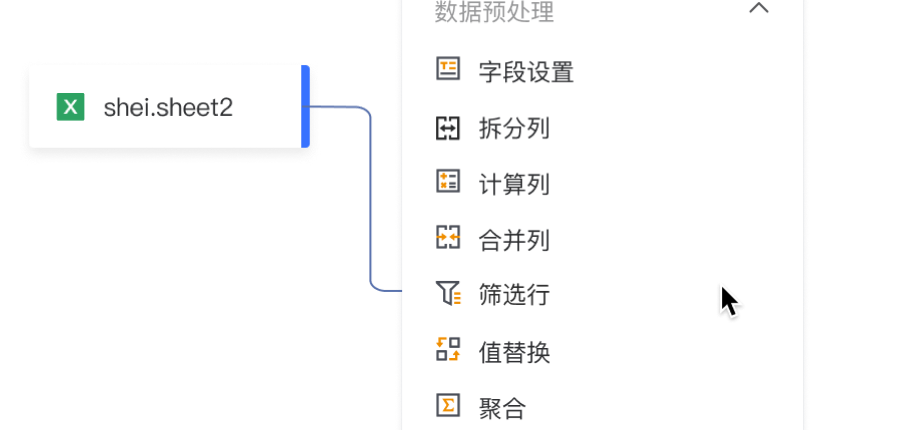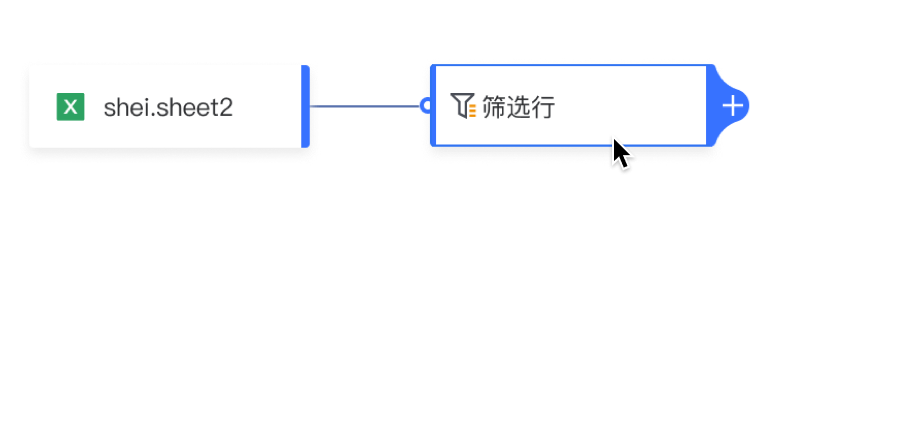
添加分支: 点击算子卡片中的“+”,展开下拉菜单并添加新分支。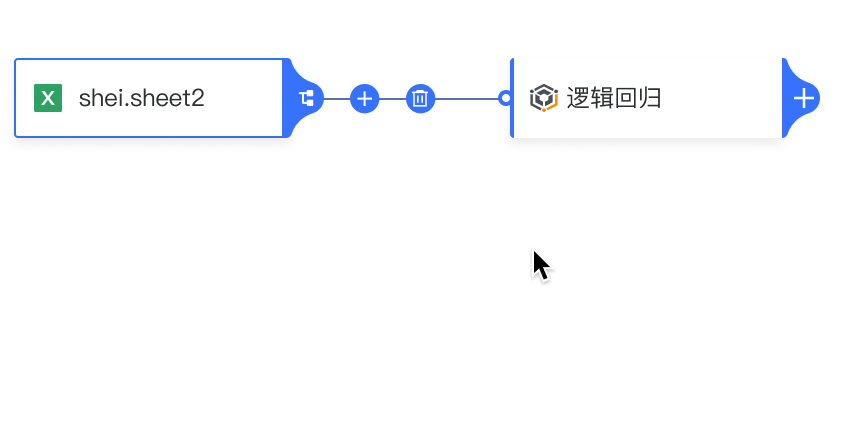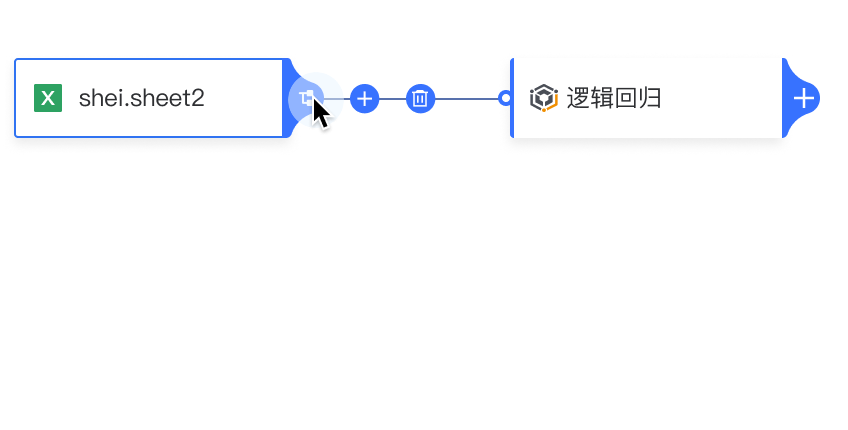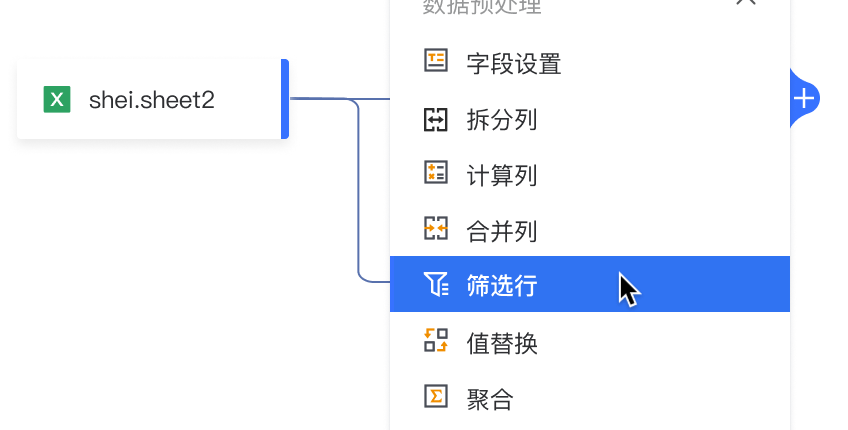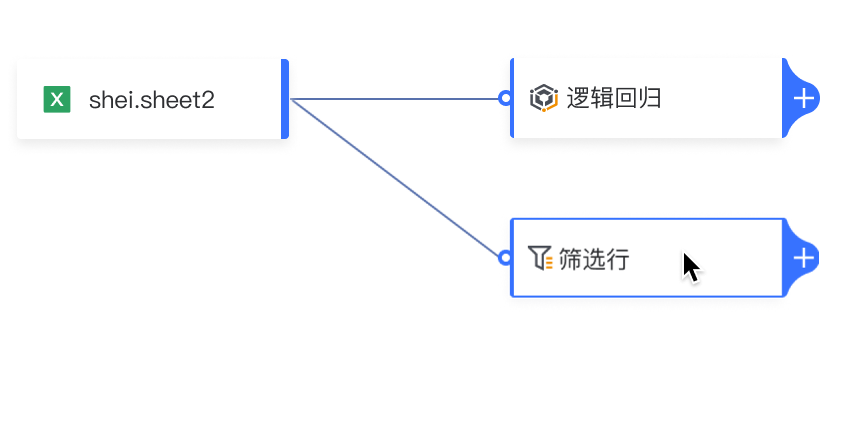
插入节点: 点击连线中的“+”,展开下拉菜单并插入节点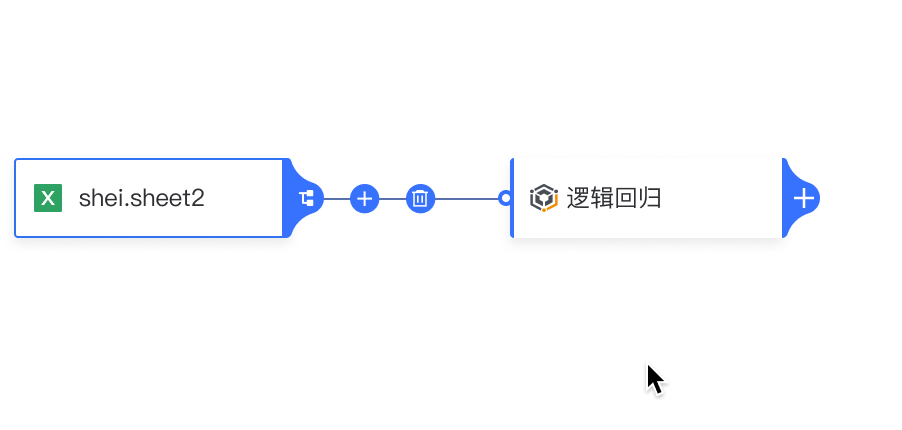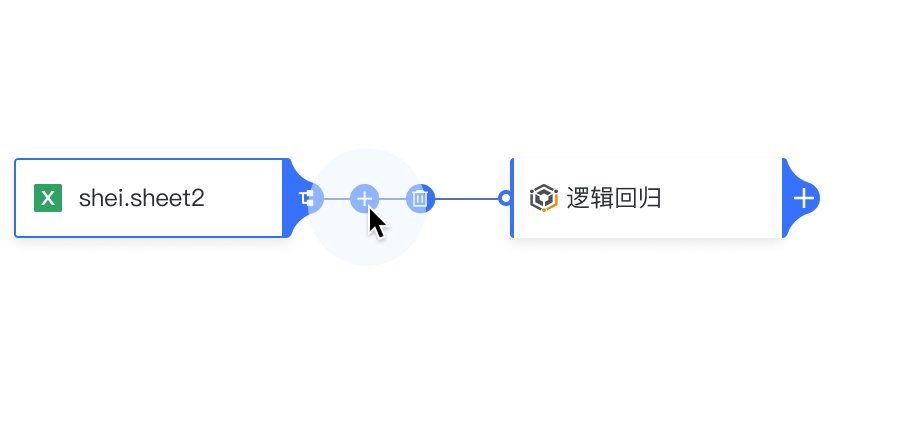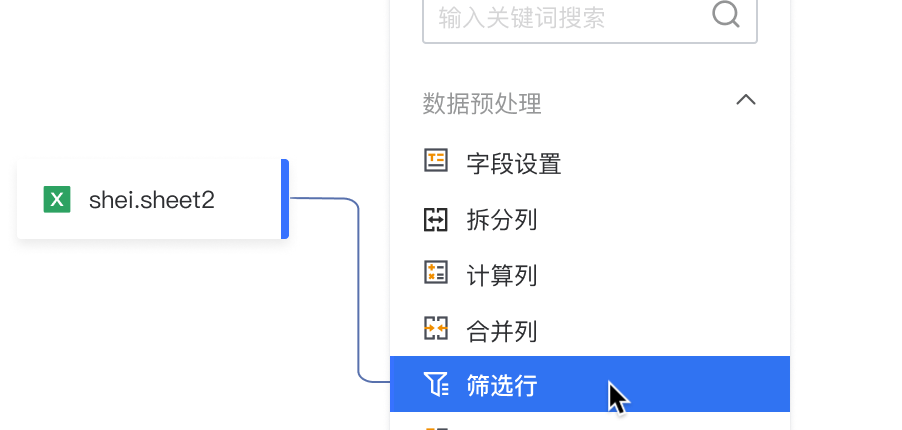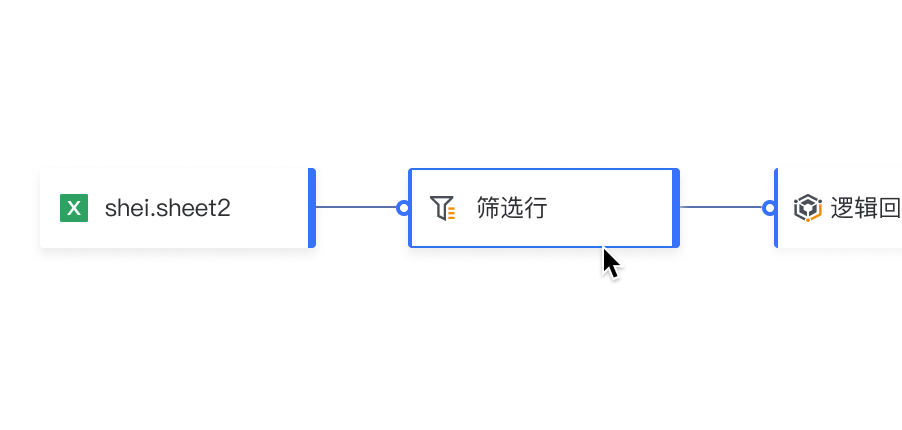
添加连线: 按住前一个算子右侧的输出点,将连线拖拽到后一个算子左侧的输入点上
切换节点: 点击算子卡片中的更多按钮或右键算子卡片,展开下拉菜单并切换节点 删除节点: 点击算子卡片中的更多按钮或右键算子卡片,展开下拉菜单并删除节点
在实际使用中,可视化建模算子支持增加文字描述,帮助用户更清晰地了解当前算子的备注信息。
可视化建模任务创建页面,支持自由布局与网格布局切换,灵活调整任务各节点的布局。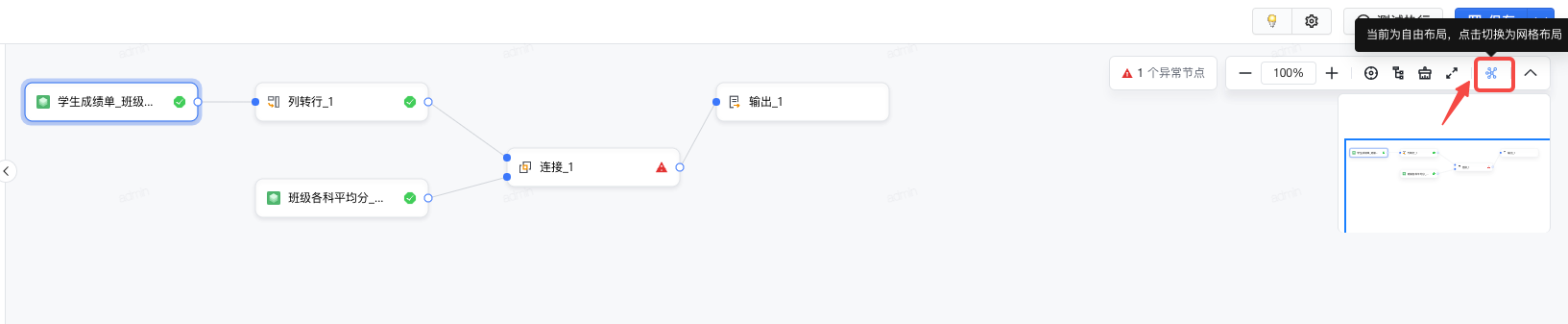
可视化建模新建任务页面,支持统一展示任务异常节点,辅助排查任务问题。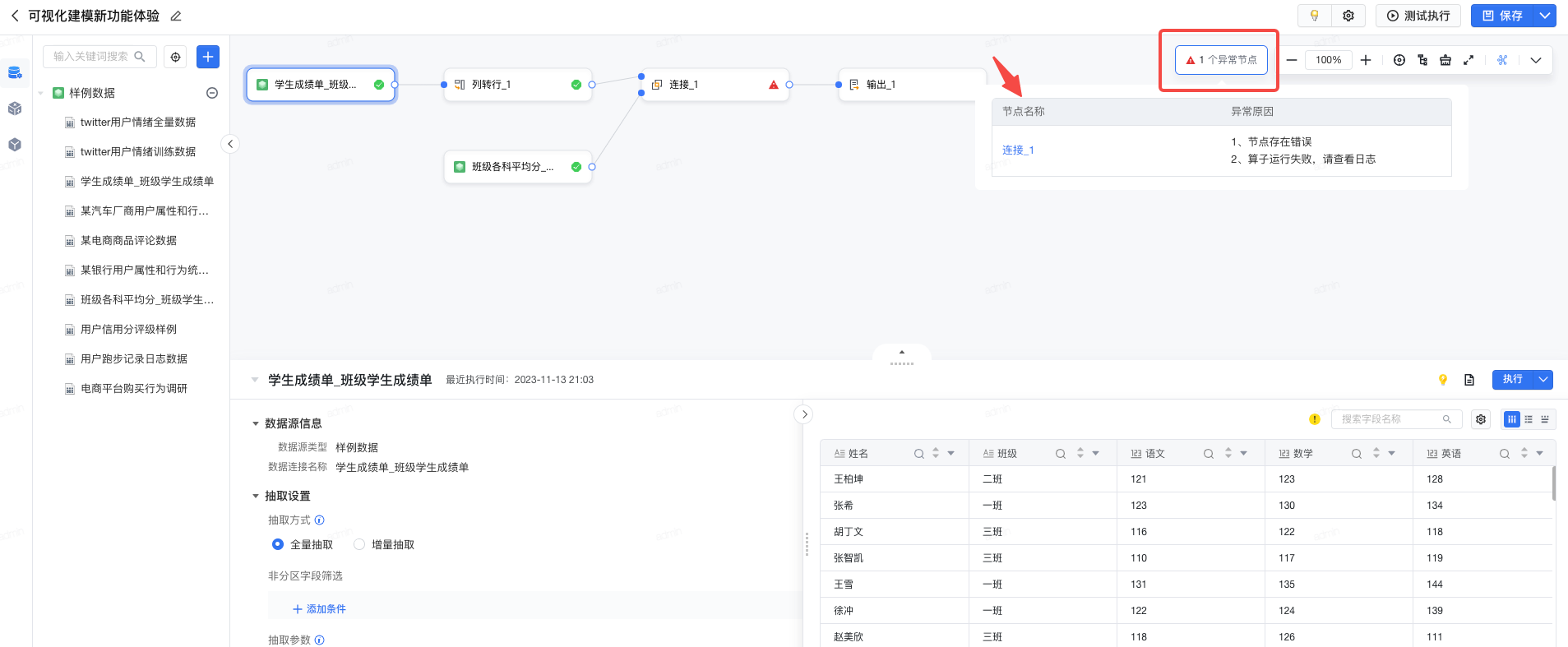
可视化建模任务创建页面,也支持通过点击Back或Delete键执行算子删除操作,提高数据清洗效率。
3.6 数据预览
3.6.1 查看预览
在可视化建模任务的编辑页面,选择数据连接后,支持便捷的预览能力。用户可预览 明细数据、表结构、数据探查 。点击每列数据的 “▼”按钮 ,支持快速选择算子,进行数据处理。如下图所示: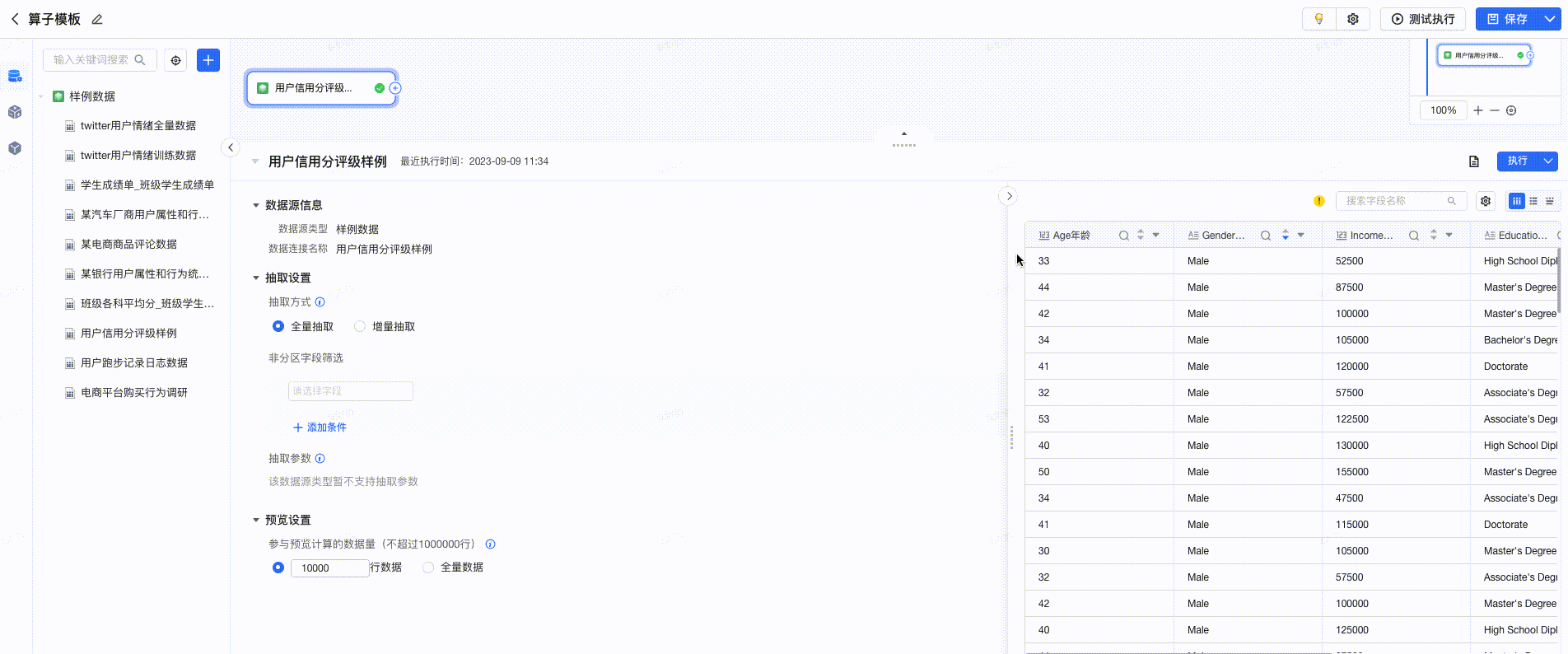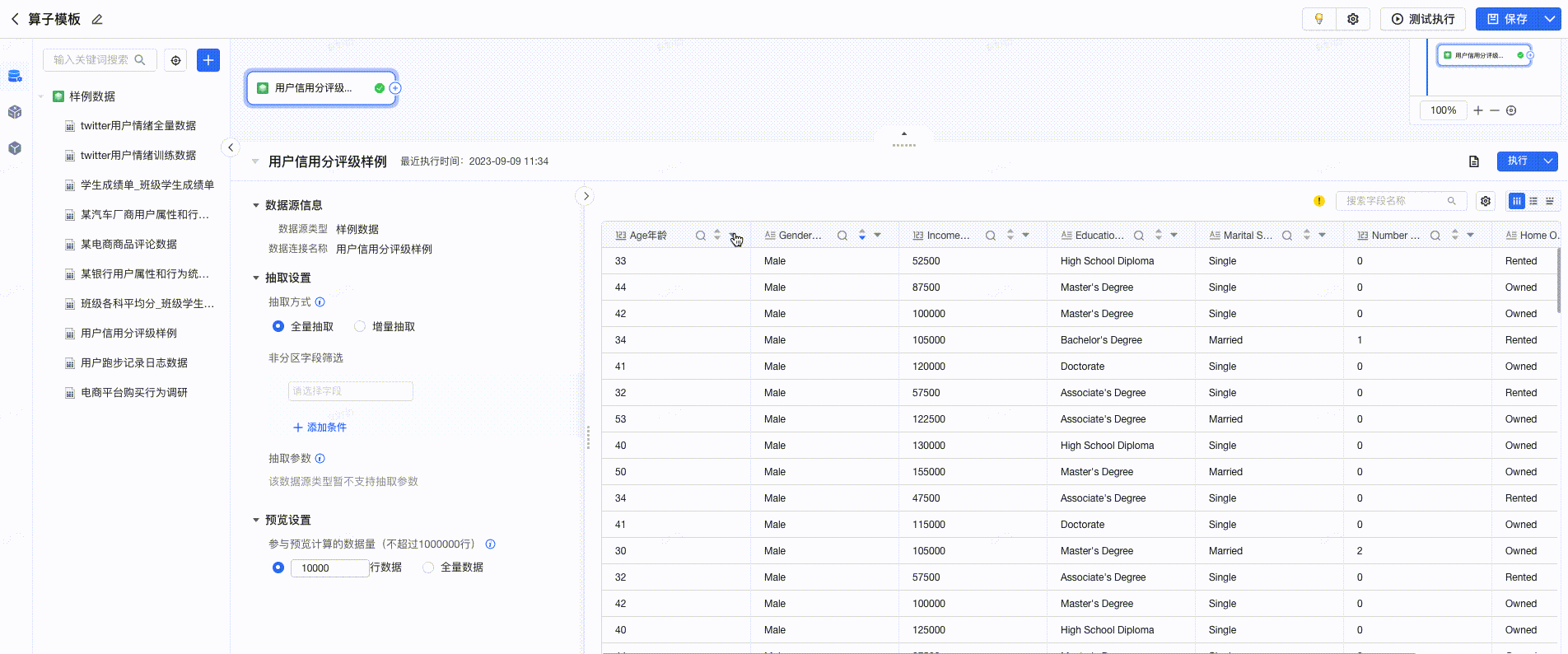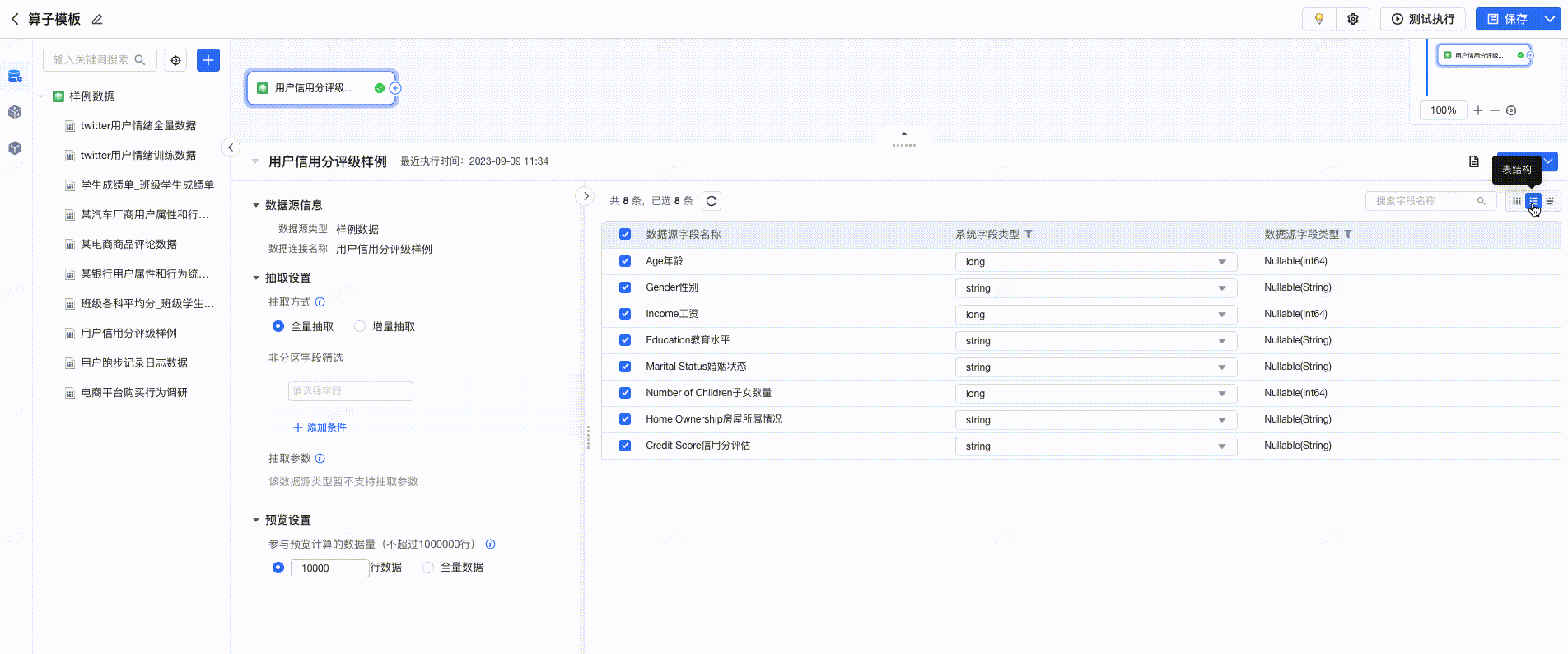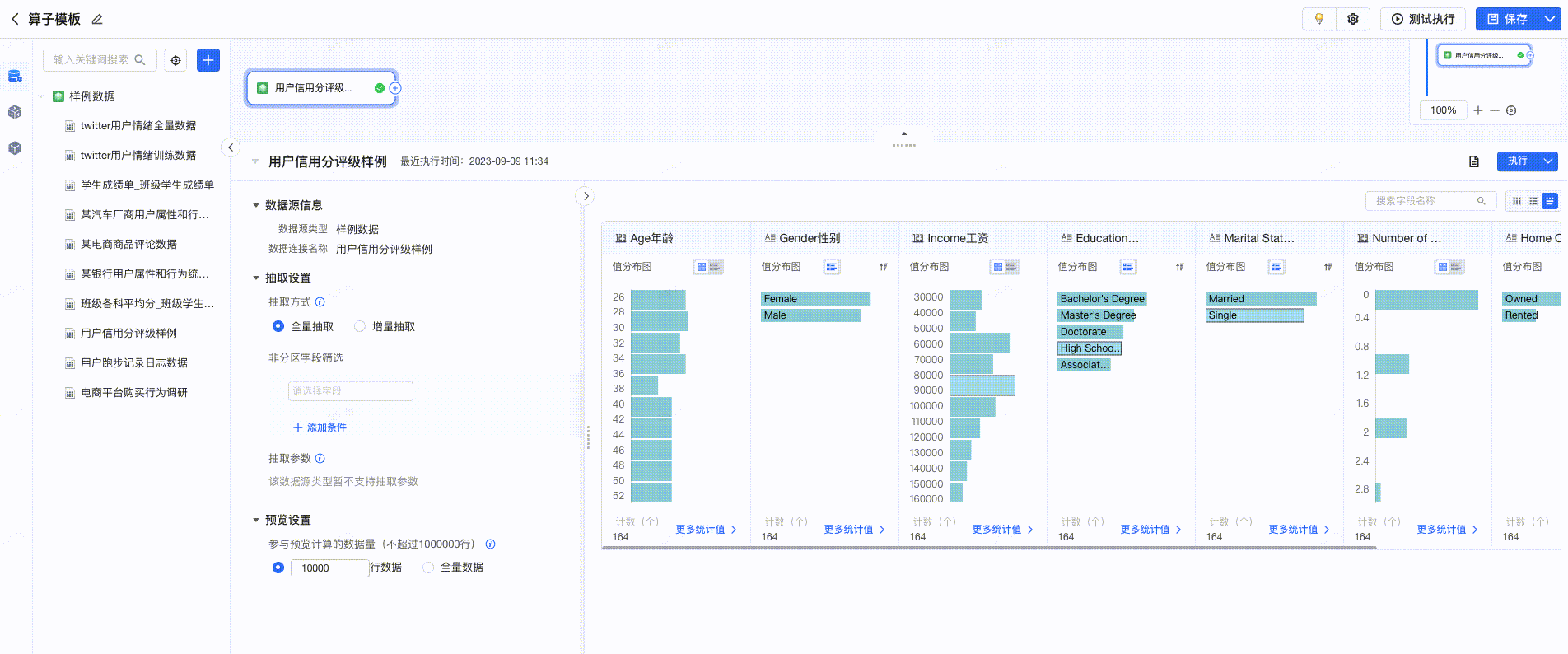
3.6.2 一键清洗
在预览中,提供数据清洗建议,用户点击后可一键完成清洗,提高数据清洗的效率。如下图所示: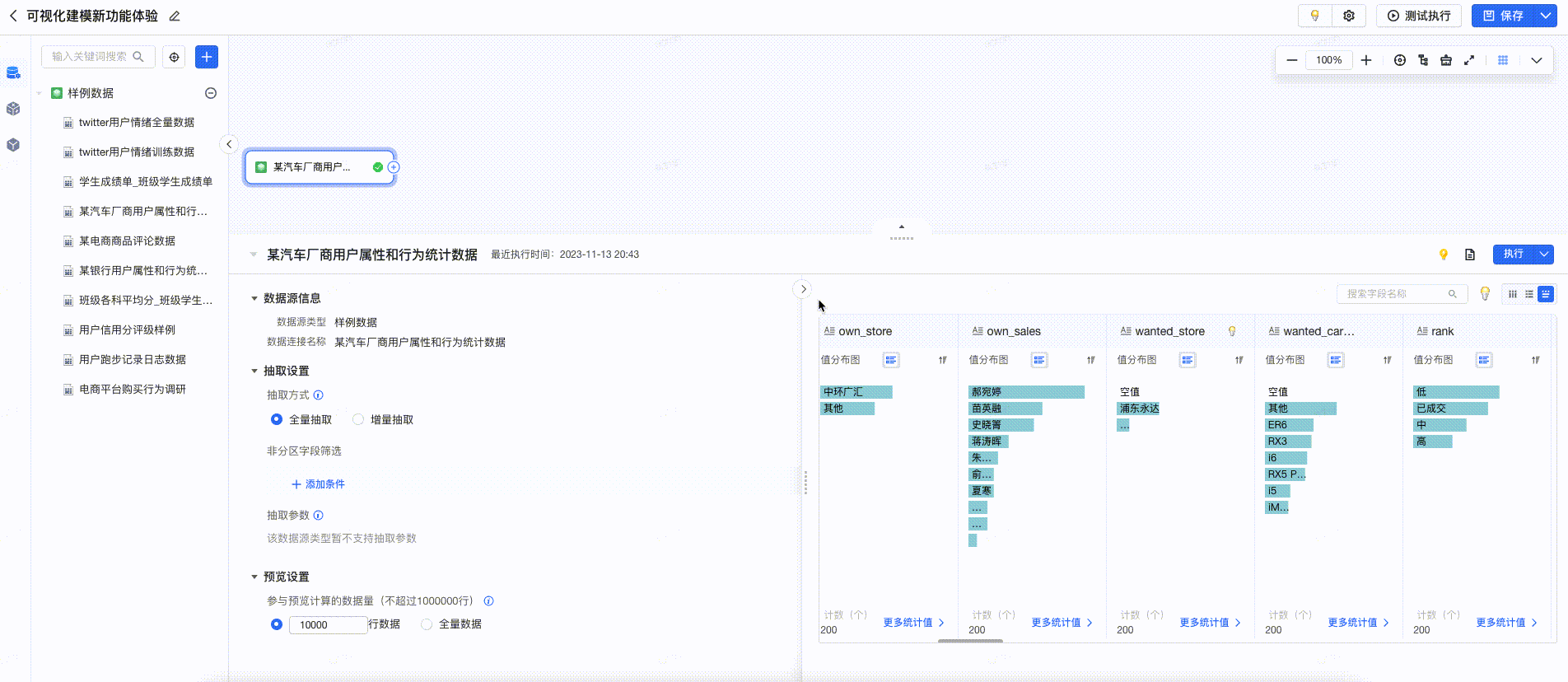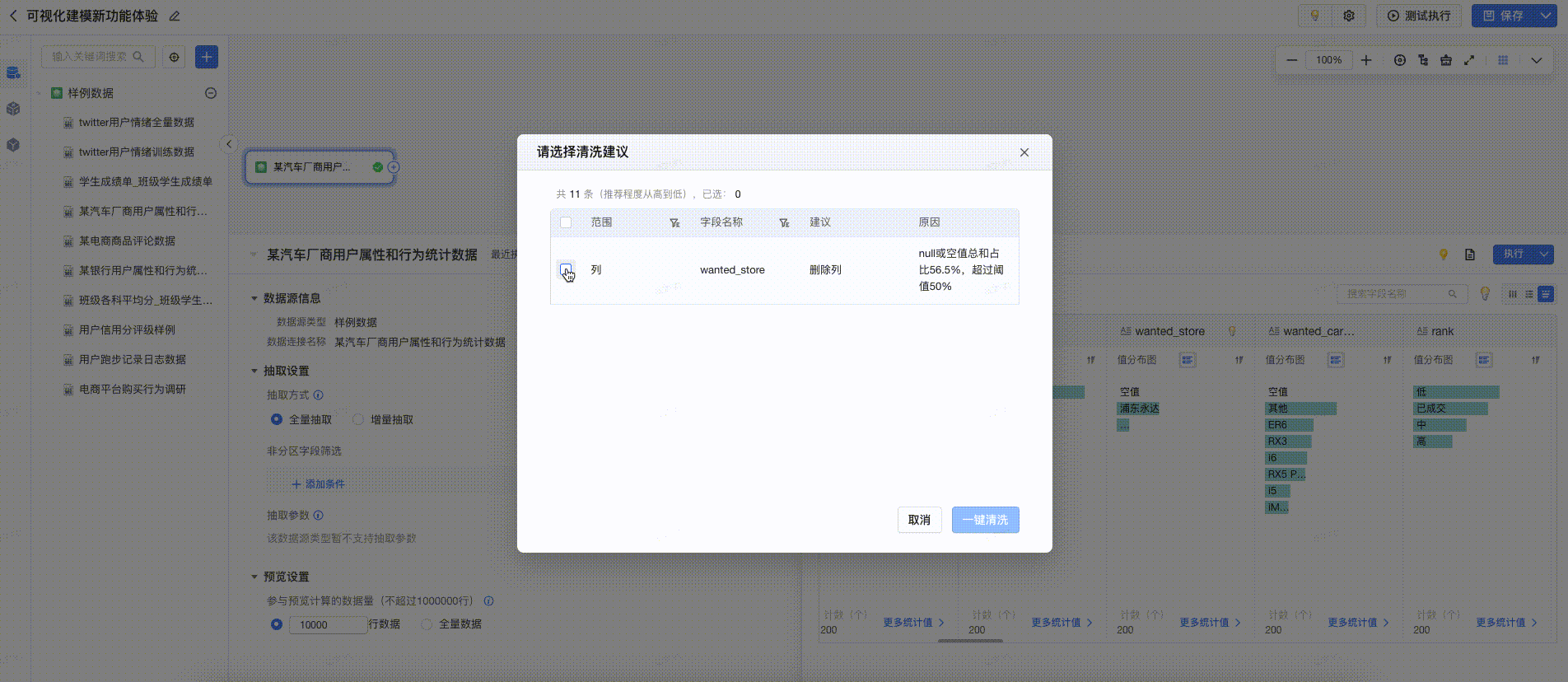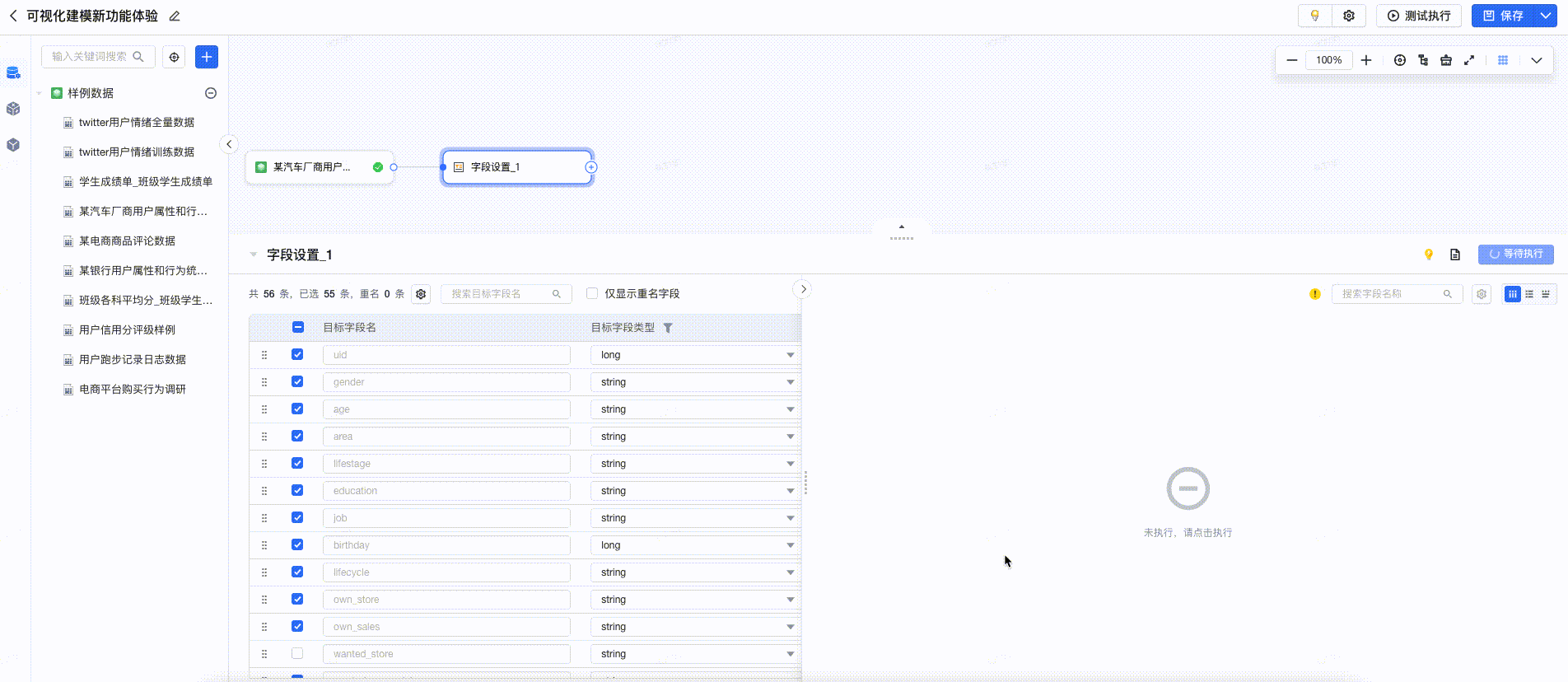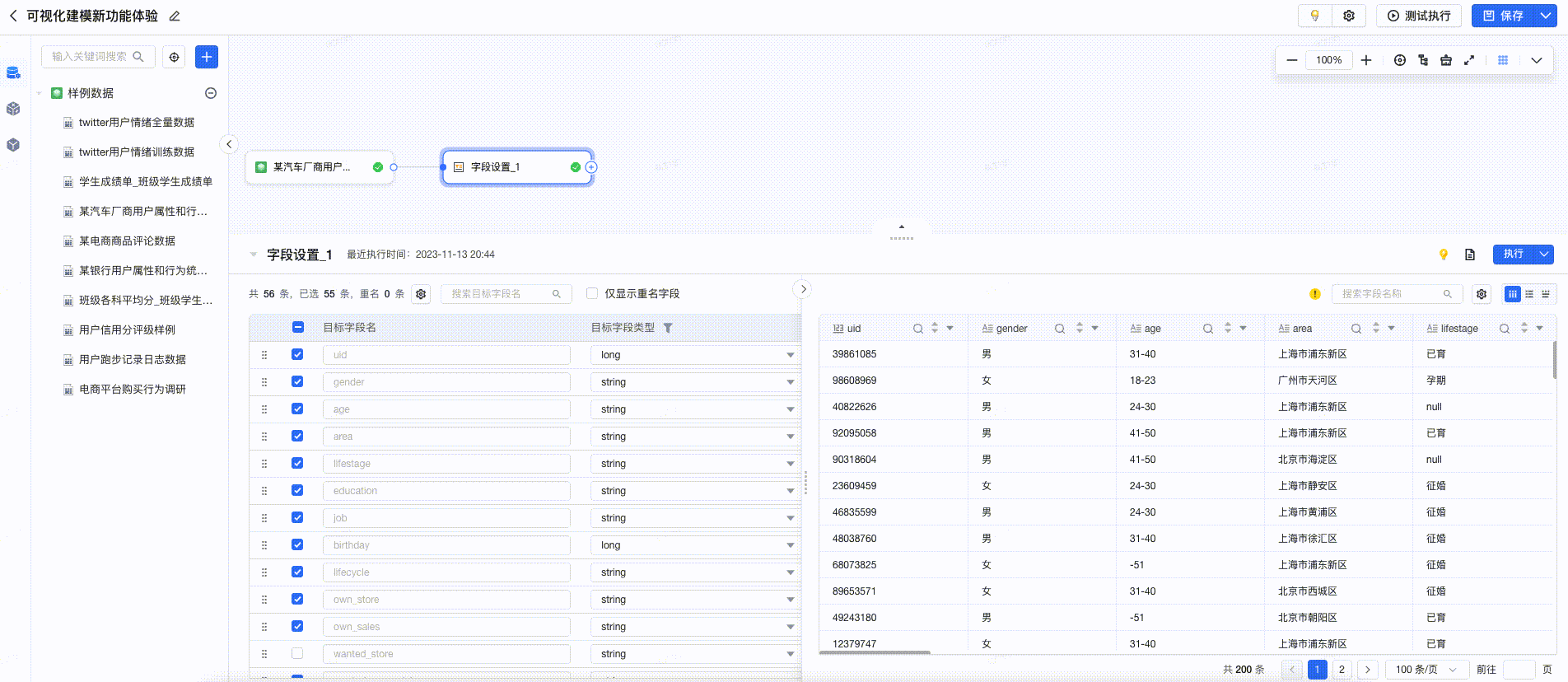
3.6.3 即时设置
在可视化建模任务的编辑页面,打开数据预览时,在预览界面左下方,可针对预览进行即时编辑或设置。用户可以配置参与预览计算的数据量(默认不超过1000000行),支持自定义行数或选择全量数据。配置后,预览将进行实时刷新。如下图所示: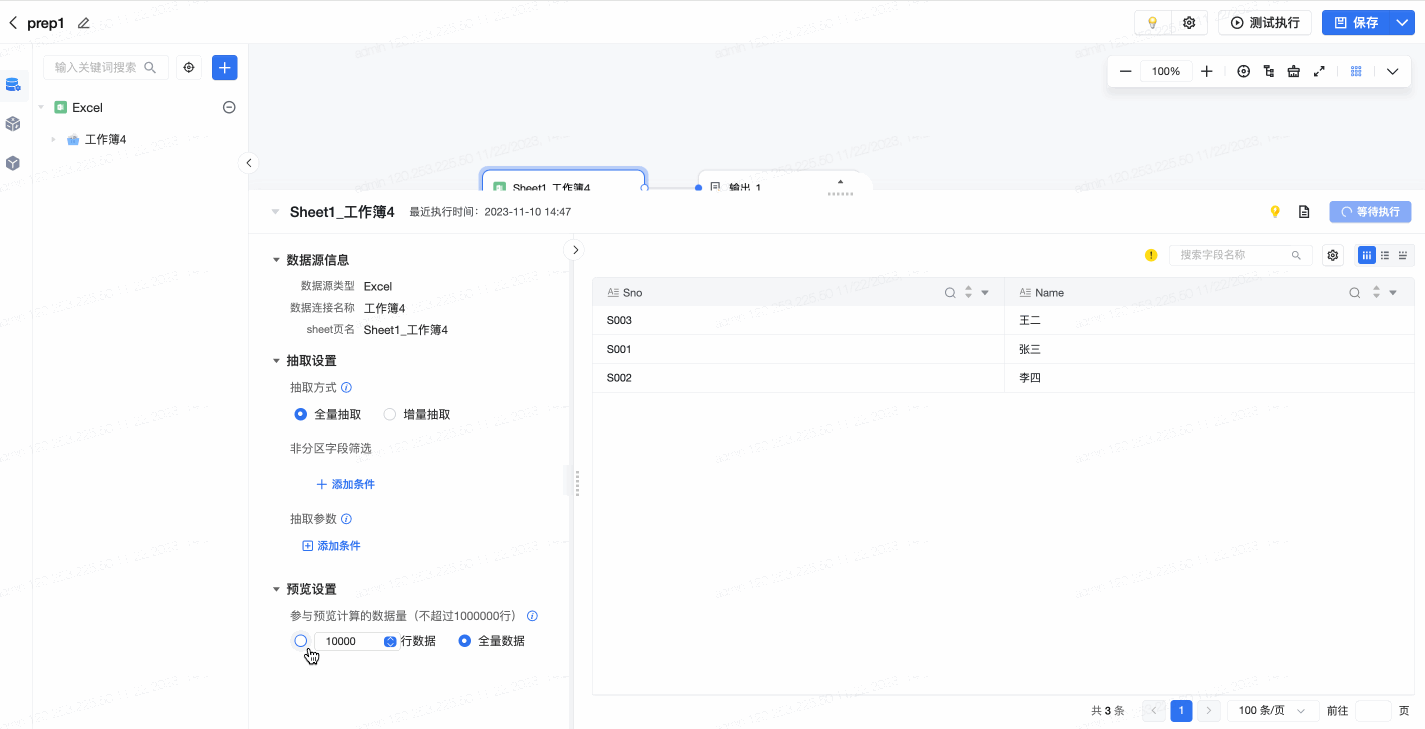
3.7 节点执行
配置中可以选中某节点并运行节点,进行运行检查。需注意的是,当上游节点更改后,必须重新执行上游节点后才能执行当前及下游节点。
- 执行该节点:运行当前节点,需要上游节点均执行完成
- 执行到此处:依次运行上游未执行的节点和当前节点
- 从此处开始执行:依次运行当前节点和后续节点,需要上游节点均执行完成,一般在当前节点更改后使用
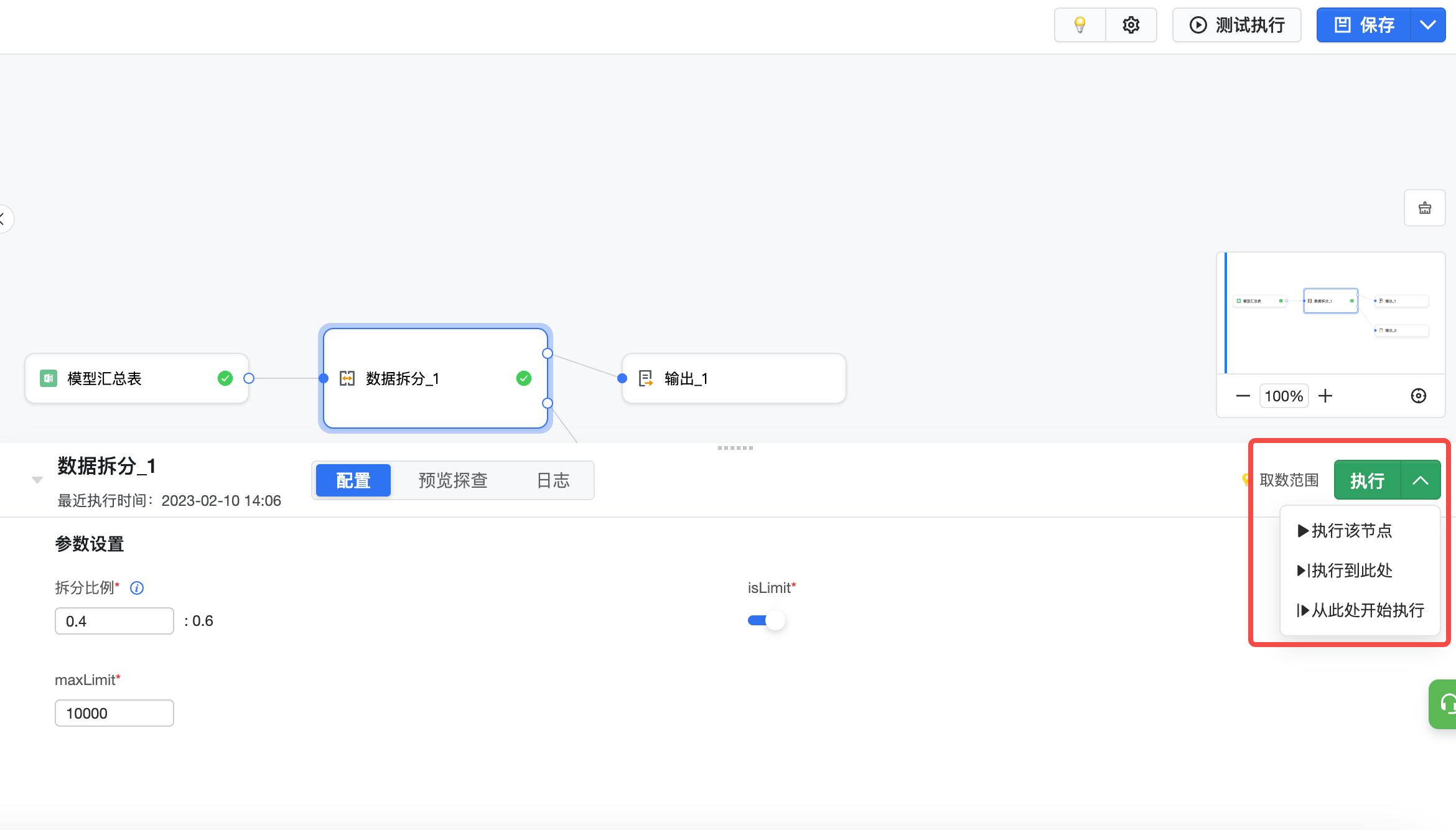
节点执行完成后,节点旁会有绿色对号标记,表示当前节点已完成执行。
3.8 输出
输出方式有:输出数据集、输出标签、外部输出、输出数据档案
3.8.1 输出数据集
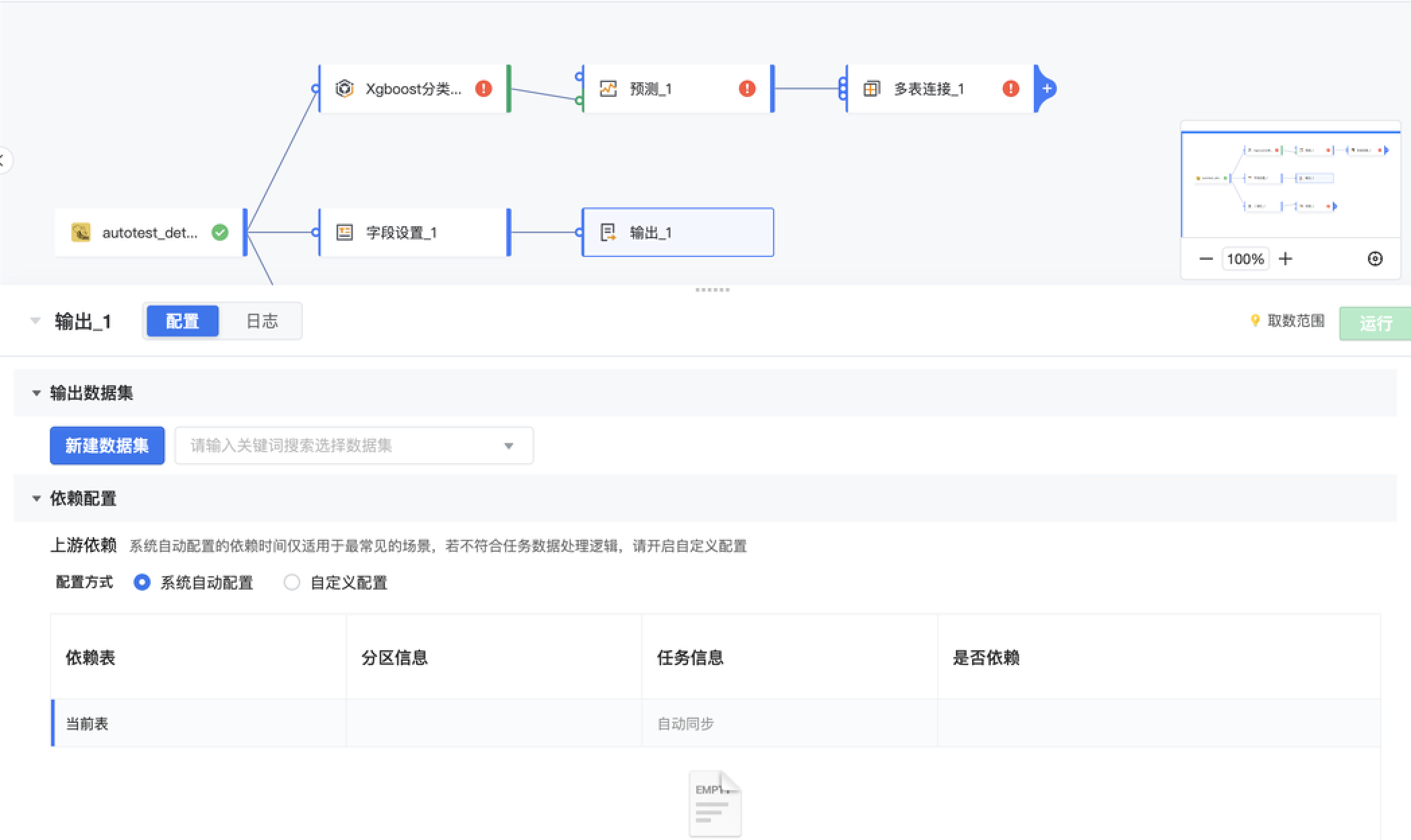
添加输出节点,选择输出到已有数据集或新建数据集。
已支持输出数据集:以Hive、ClickHouse、ByteHouse存储的数据集
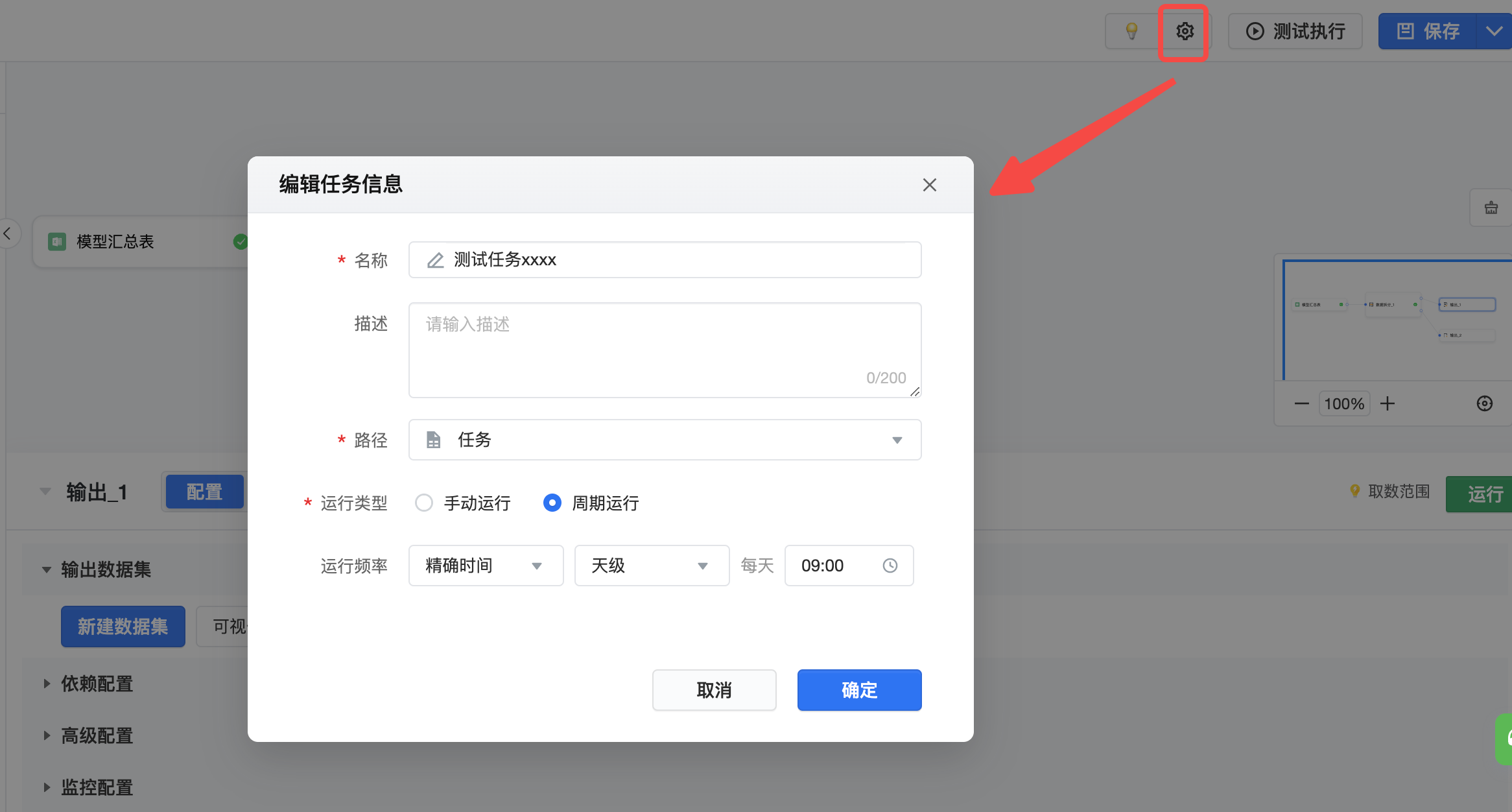
最后,您可以打开运行配置弹窗,编辑运行周期,或手动运行。运行频率可以选择“精确时间”或设置“间隔时长”。
- 精确时间:小时级、天级、周级、月级
- 间隔时长:10分钟、20分钟、30分钟
监控配置
可设置数据结果告警规则:
- 差异百分比(相比前一天)
- 计算公式:(昨天数据行数-前天数据行数)/前天数据行数;
- 昨天、前天指的是业务日期,不是运行日期,比如实例是5月7号运行,则昨天指的是5月6号业务日期的数据行数。
- 差异百分比(相比前七天平均)
- 计算公式:(昨天数据行数-近7天数据行数平均值)/近7天数据行数平均值;
- 差异百分比(相比上月同期)
- 计算公式:(昨天数据行数-上月同期数据行数)/上月同期数据行数;
- 上月同期的定义:比如这个月是每月1号跑的,那上月同期就是上月1号;这个月是每月31号跑的,上月没有31号时,就取上月最后一天。
- 差异百分比(相比上周同期)
- 计算公式:(昨天数据行数-上周同期数据行数)/上周同期数据行数;
- 上周同期的定义:比如这周是周三跑的,上周同期指的便是上周三。
模型配置完成时,可以点击右上角的保存或另存为。如果模型未完成,也可以将运行频率调整为手动运行后点保存或另存为。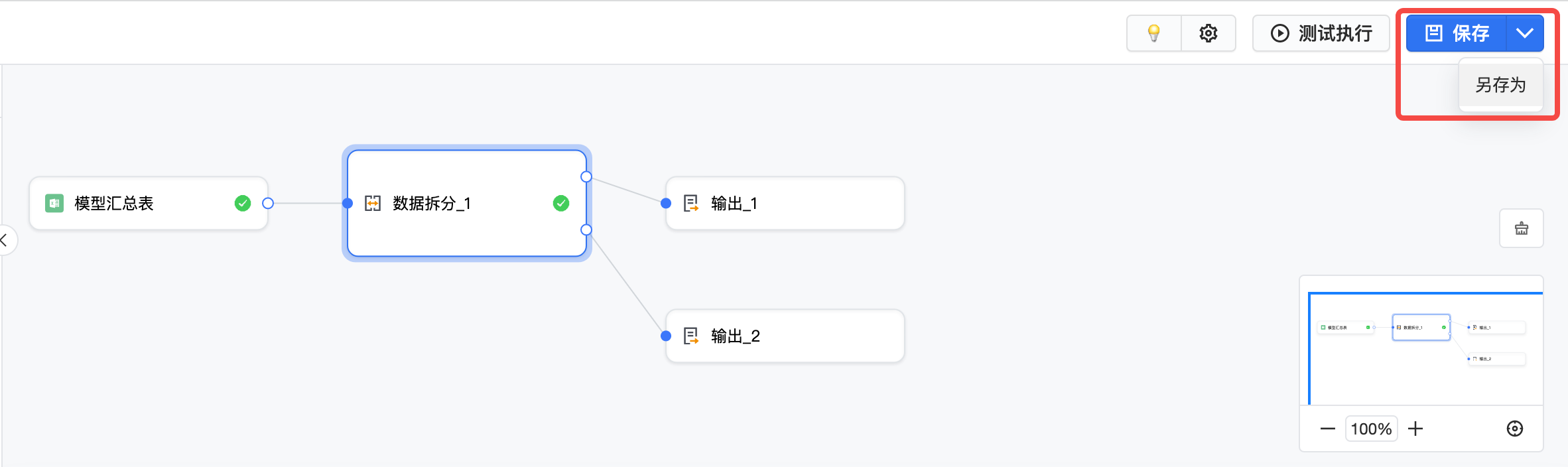
保存任务配置,点击左上角返回可跳转到任务详情。
返回可视化建模页面,点击当前任务的「运行记录」,可以手动运行。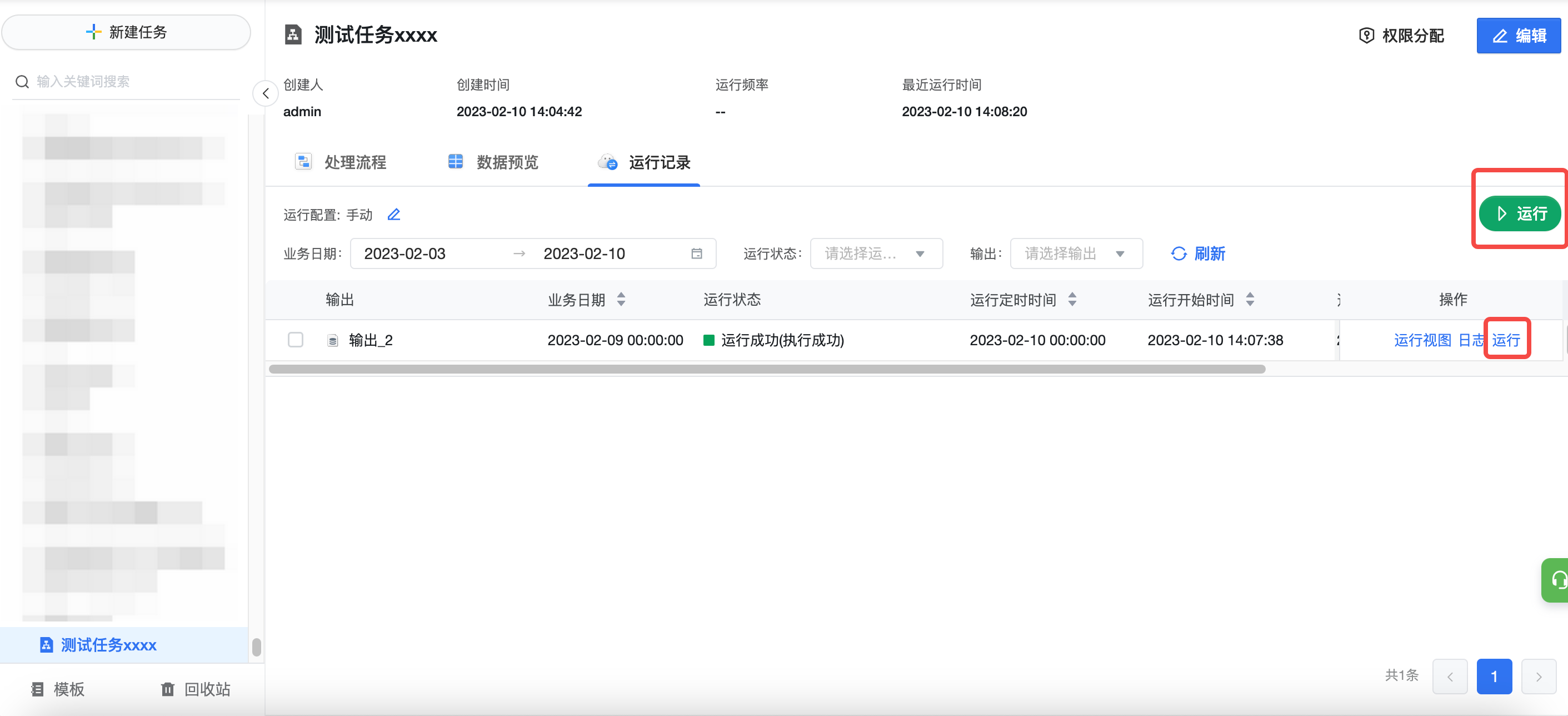
3.8.2 输出数据档案
“输出数据档案”算子支持将对应数据输出成行为档案。
付费项,需要付费购买DataFinder“融合分析”功能
档案定义
- 选择档案:可以选择该项目下已有的数据档案进行输出(有appid的数据档案)。当与Finder混部时,档案名称前标识“档案类型:行为事件/Finder行为事件;
行为字段配置:
* 基准ID(OneID)字段:只能选择int\bigint类型字段 * 行为时间字段:Event_time,通常用13位时间戳,限制字段类型为int/long数值类型 * 行为事件字段:Event_type,存储事件名称的字段,如「page_view」「Clickbutton」,限制字段类型为string字符串类型 * 行为属性字段:Event_params,通常以json的方式存储点击事件的内容,如「Clickbutton」涉及的页面信息/按钮/设备等,限制字段类型为Map类型
监控配置
可设置数据结果告警规则:
- 差异百分比(相比前一天)
- 计算公式:(昨天数据行数-前天数据行数)/前天数据行数;
- 昨天、前天指的是业务日期,不是运行日期,比如实例是5月7号运行,则昨天指的是5月6号业务日期的数据行数。
- 差异百分比(相比前七天平均)
- 计算公式:(昨天数据行数-近7天数据行数平均值)/近7天数据行数平均值;
- 差异百分比(相比上月同期)
- 计算公式:(昨天数据行数-上月同期数据行数)/上月同期数据行数;
- 上月同期的定义:比如这个月是每月1号跑的,那上月同期就是上月1号;这个月是每月31号跑的,上月没有31号时,就取上月最后一天。
- 差异百分比(相比上周同期)
- 计算公式:(昨天数据行数-上周同期数据行数)/上周同期数据行数;
- 上周同期的定义:比如这周是周三跑的,上周同期指的便是上周三。
模型配置完成时,可以点击右上角的保存或另存为。如果模型未完成,也可以将运行频率调整为手动运行后点保存或另存为。
保存任务配置,点击左上角返回可跳转到任务详情。
返回可视化建模页面,点击当前任务的「运行记录」,可以手动运行。