在完成数据输入之后,即可对输入数据进行进一步加工处理操作,该章节介绍数据清洗算子的功能。
目前可视化建模模块支持的数据清洗算子如下:
算子型 | 描述 | 场景释义 | 任务类型 |
|---|---|---|---|
连接 | 基于连接字段和给定的连接方式,进行两份数据字段的组合后得到新的数据。 | 「订单表」中只有”商品id“,没有商品的具体信息,需要连接「商品信息表」,根据”商品id“匹配到”商品名称“、”商品品类“等信息。 | 离线任务 |
多表连接 | 将多张表根据某些字段联合成一张新表 | 将[学生表]、[成绩表]、[课程表]合成一张表,看到学生每门功课的成绩。 | 离线任务 |
合并行 | 合并行 | 「1月订单表」和「2月订单表」两份数据的字段一致,合并为一份数据。 | 离线任务 |
聚合 | 通过分组实现明细数据的聚合计算 | 从「订单表」中计算每个用户下单的次数和总金额,按”用户id“分组,聚合计算”订单id“的计数和”订单金额“的总和。 | 离线任务 |
筛选行 | 选择字段,确认筛选条件,支持两层且/或逻辑关系 | 「行为表」中包含用户所有的行为记录,只关注注册、登录行为时,可以筛选”事件名称“属于注册、登录。 | 离线任务、实时任务 |
拆分字段 | 根据字段格式或内容进行拆分成多个字段(列),支持根据分隔符拆分、Map JSON嵌套字段解析拆分、数组JSON嵌套字段解析拆分,同时也支持将纯数组字段中的内容解析铺开成多行,注意数组JSON嵌套字段解析之后会根据数组内容平铺成多行,可能会造成数据量变大,请提前确认数据内容。 | 1.分隔符拆分:存在城市字段存储内容为「城市-Code」,需要根据分隔符'-'拆分成城市名+城市Code两个字段,此时可以选择分隔符的拆分方式拆分生成两个字段 | 离线任务、实时任务 |
去重 | 将一份数据按照设定比例拆分成两份数据 | 「待回访用户表」中可能有用户重复出现,对“用户id”去重,每个用户只保留一行数据。 | 离线任务 |
列转行 | 将一列的字段值转化为表头列,高表变为宽表 | 「学生各科成绩表」中100个学生有100行数,分6列展示6个科目的成绩。转换成”姓名-科目-成绩“3列600行的数据。 | 离线任务 |
行转列 | 将一列的字段值转化为表头列,高表变为宽表 | 列转行的逆操作。将”姓名“、”科目“、”成绩“3列600行的数据,转换成“姓名-科目1成绩-科目2成绩-科目3成绩-科目4成绩-科目5成绩-科目6成绩”100行的数据。 | 离线任务 |
替换缺失值 | 将缺失的数据替换为该列的最大/最小/平均值、最高频值或自定义值 | 「订单表」中部分订单的“优惠金额”为空,即没有优惠、原价购买。将空替换为0。 | 离线任务 |
字段设置 | 支持选择保留字段、设置字段类型、设置字段名称、设置字段排序。 | 离线任务、实时任务 | |
计算列 | 支持自定义表达式,使用Spark函数处理上游字段并添加新字段 | 离线任务、实时任务 | |
加解密 | 指根据特定的加密或解密算法,将数据源中的指定字段数据进行加密或解密的数据安全管理功能。 | 离线任务 | |
采样 | 「待回访用户表」中可能有用户重复出现,对“用户id”去重,每个用户只保留一行数据。 | 离线任务 | |
数据拆分 | 将一份数据按照设定比例拆分成两份数据 | 离线任务 | |
字符串索引 | 将指定的属性的值映射成数值型索引,使得只能对数值型数据做处理的算子 也可以对属性进行处理。 | 离线任务 | |
IDMapping算子 | 根据所选择的ID-Mapping类型,通过ID-Mapping服务转换查询到已经存在的OneID,如未购买CDP产品,此算子将无法使用。
| 离线任务、实时任务 | |
IDM多主体转换关系算子 | 将实时的关系数据存储保存下来并构建完整的实时转换链路,即实时将主体1转换为主体2,如人访问门店的行为记录构建访问关系,可以基于人的手机号ID与门店ID构建【到访】关系,在人和门店两个主体相互转换时可以基于【到访】关系进行营销活动,如对N个门店的到访用户发短信进行召回。 | 实时任务 | |
2.1 字段设置
支持选择保留字段、设置字段类型、设置字段名称、设置字段排序。
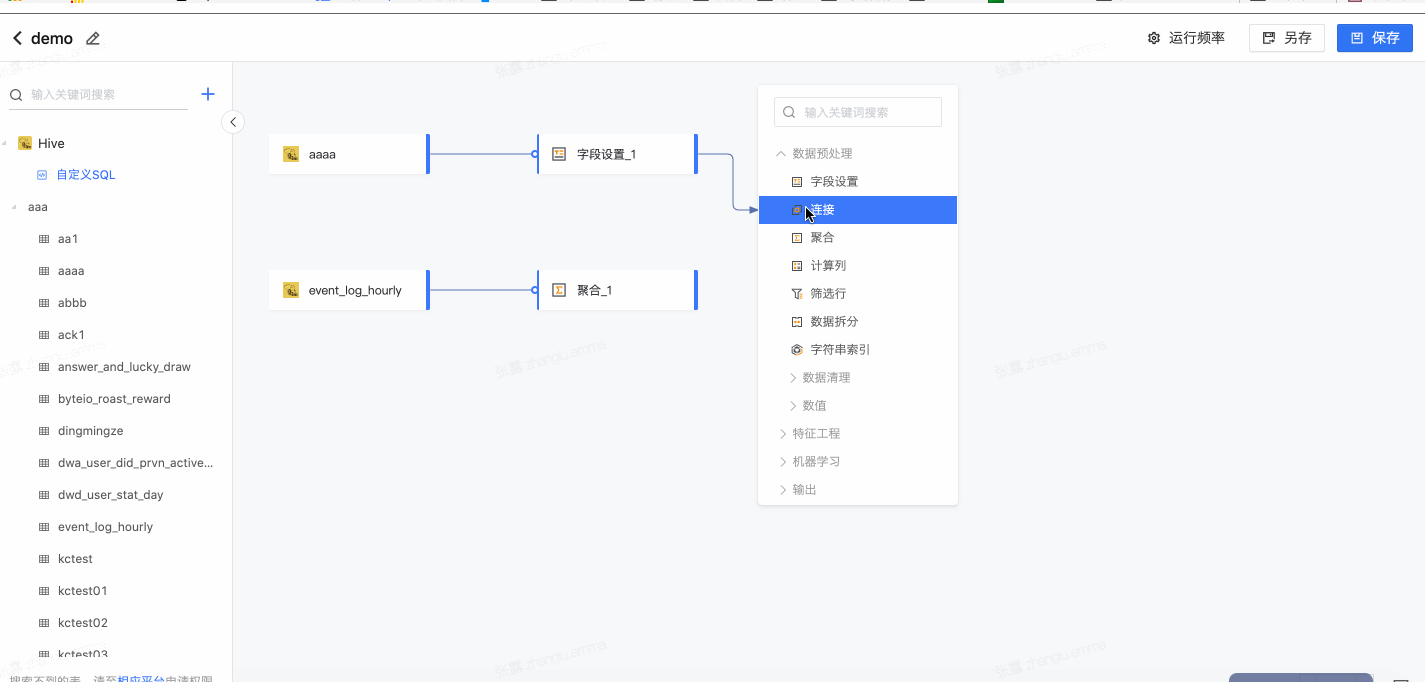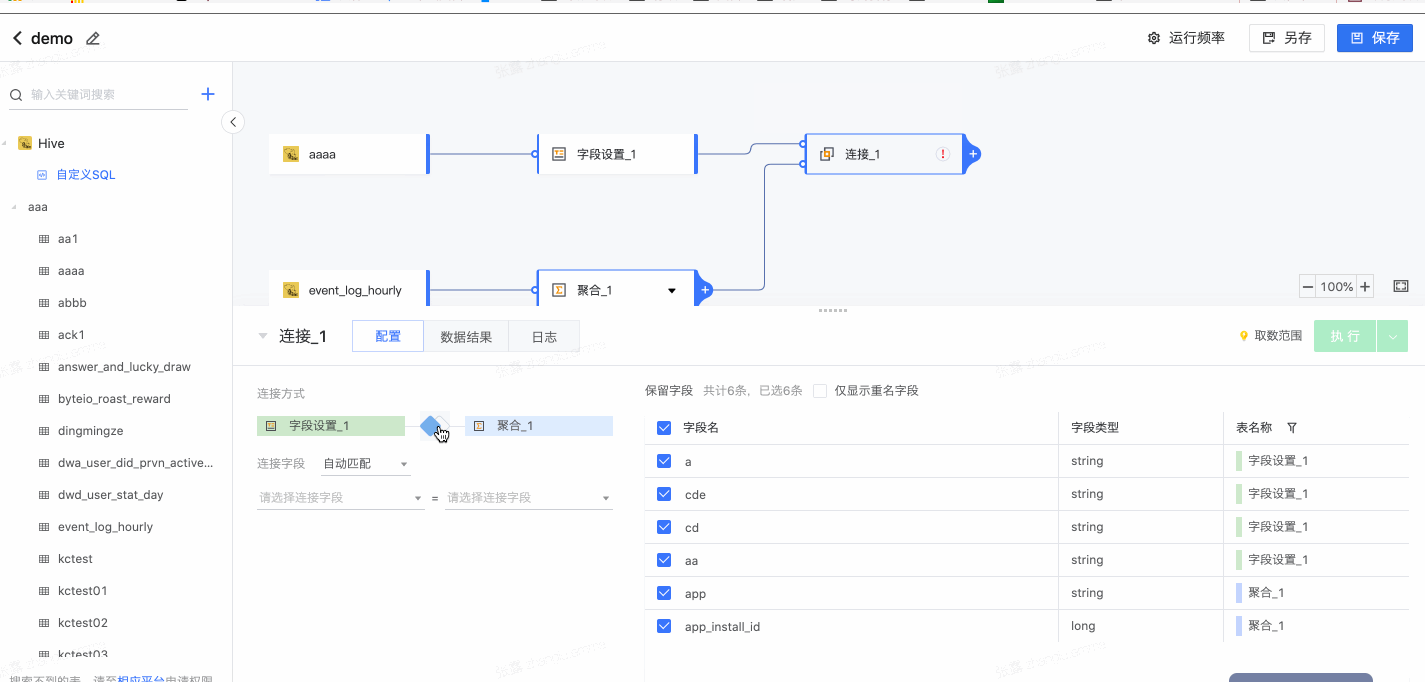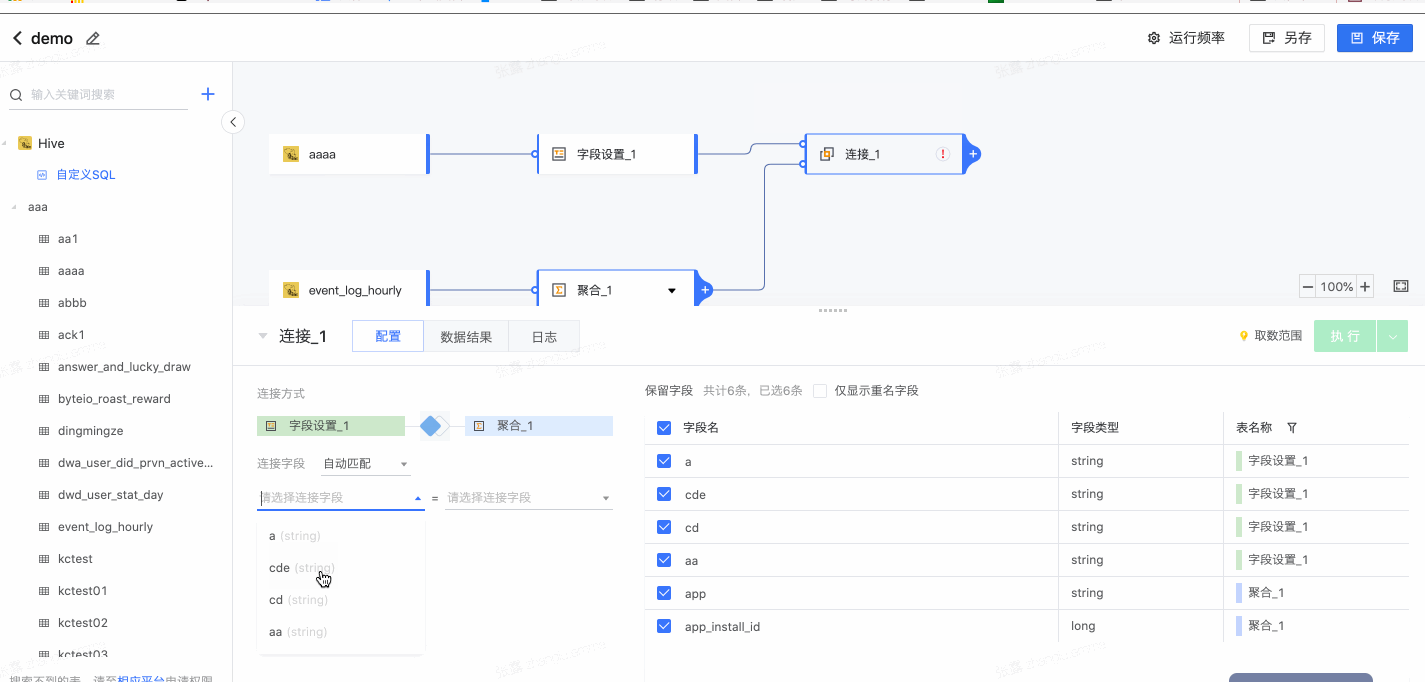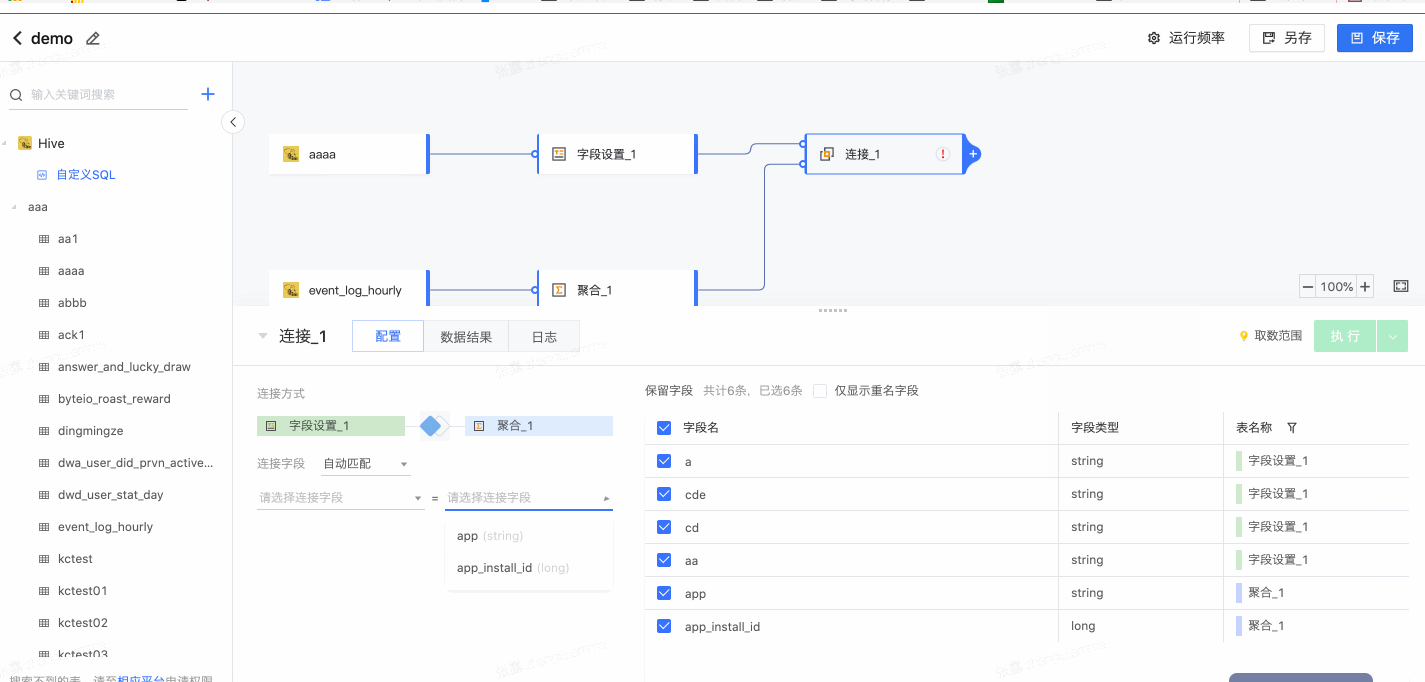
2.2 连接
支持创建多表间的连接关系。
- 选择连接方式
- 设置连接字段
- 选择保留字段
2.3 合并行
用于合并多表数据 操作面板 点击配置多表字段的匹配关系,注意仅相同格式的字段支持匹配,如字段格式不相同,请添加字段设置或计算列等算子处理字段格式后进行合并 处理示例 将不同表拖入画布,并点击其中一个需要合并的表,添加合并行节点。
点击其他需要合并的表右侧+按钮,拖拽至合并行算子左侧。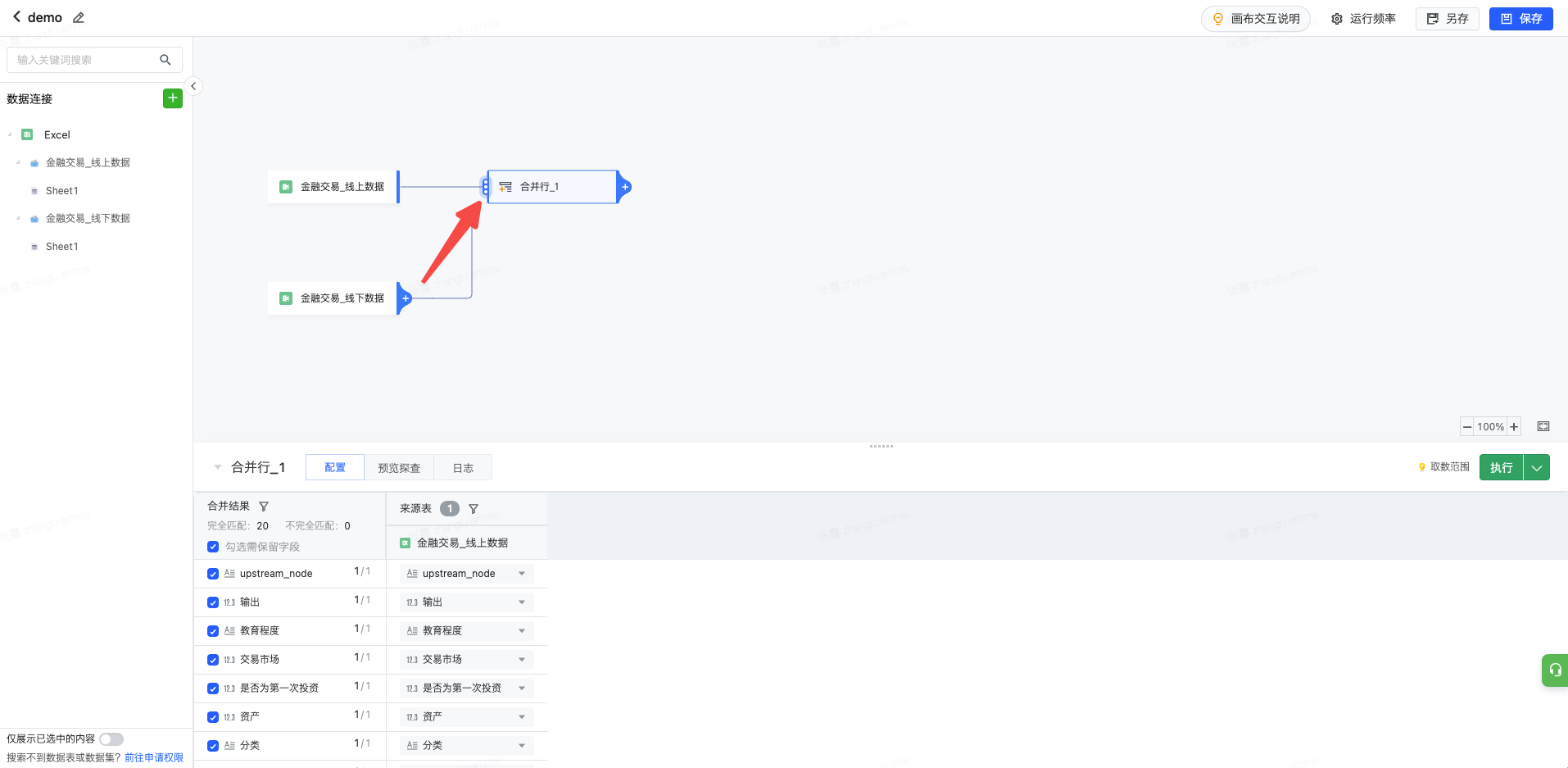
在页面下方配置匹配关系,并点击执行保存配置。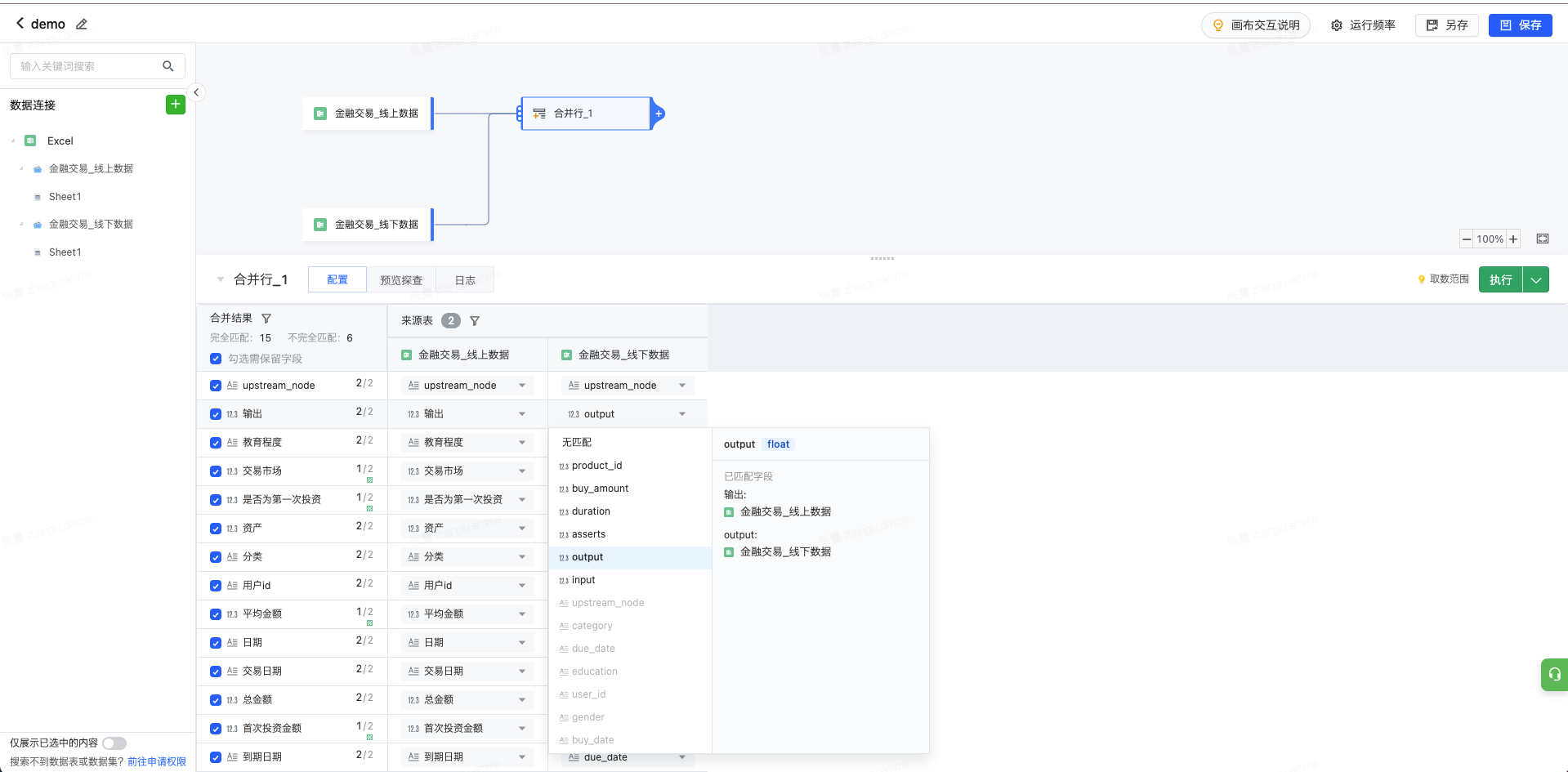
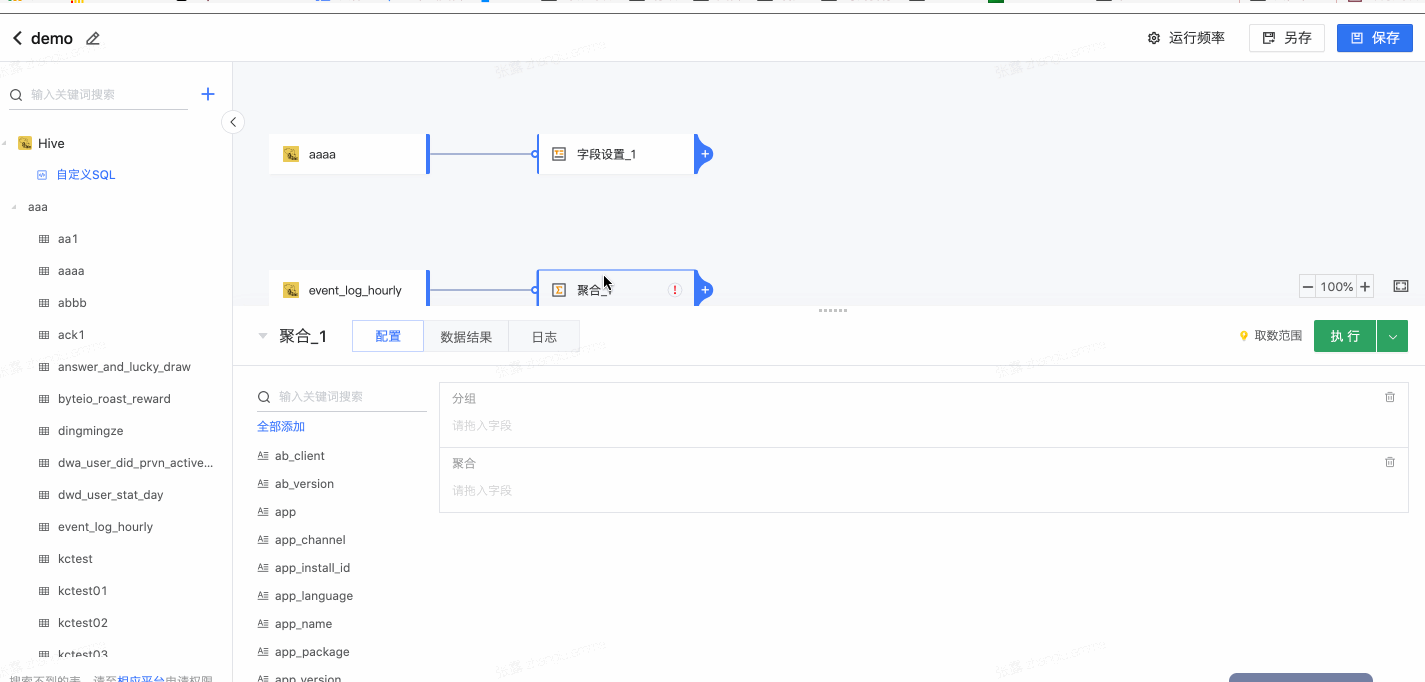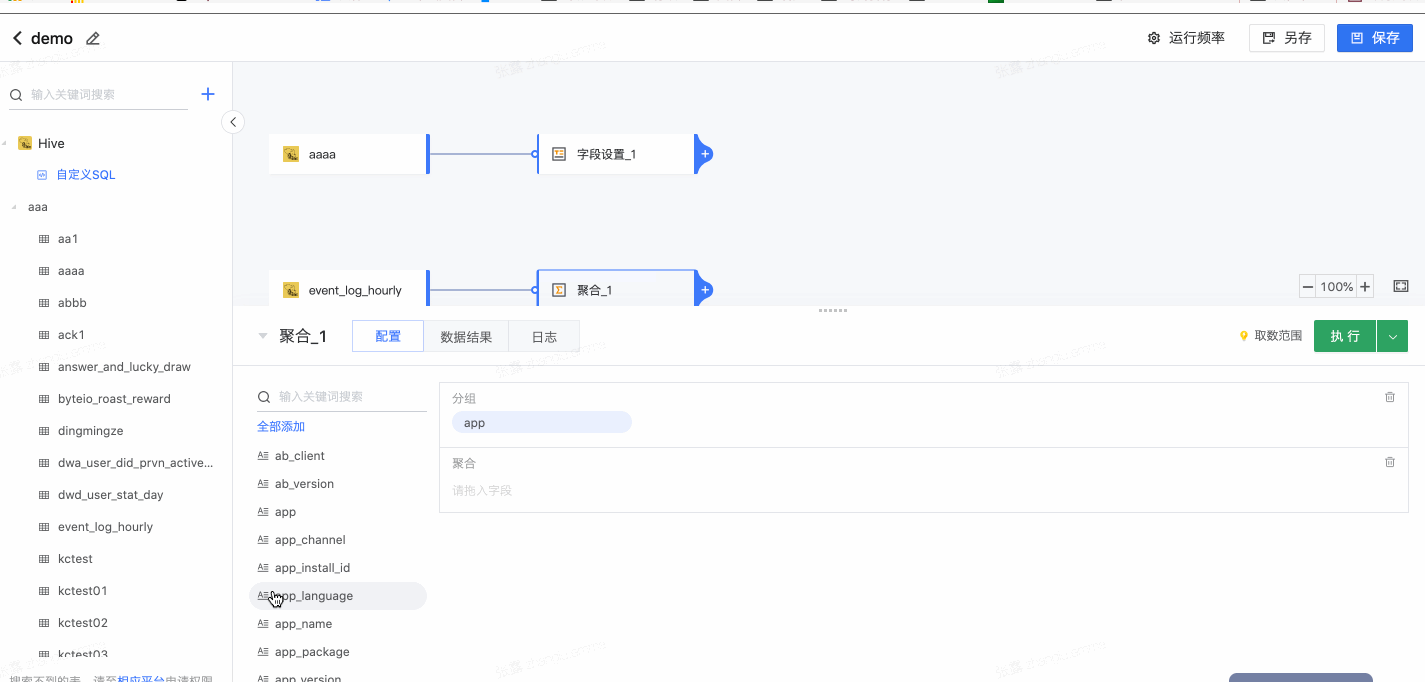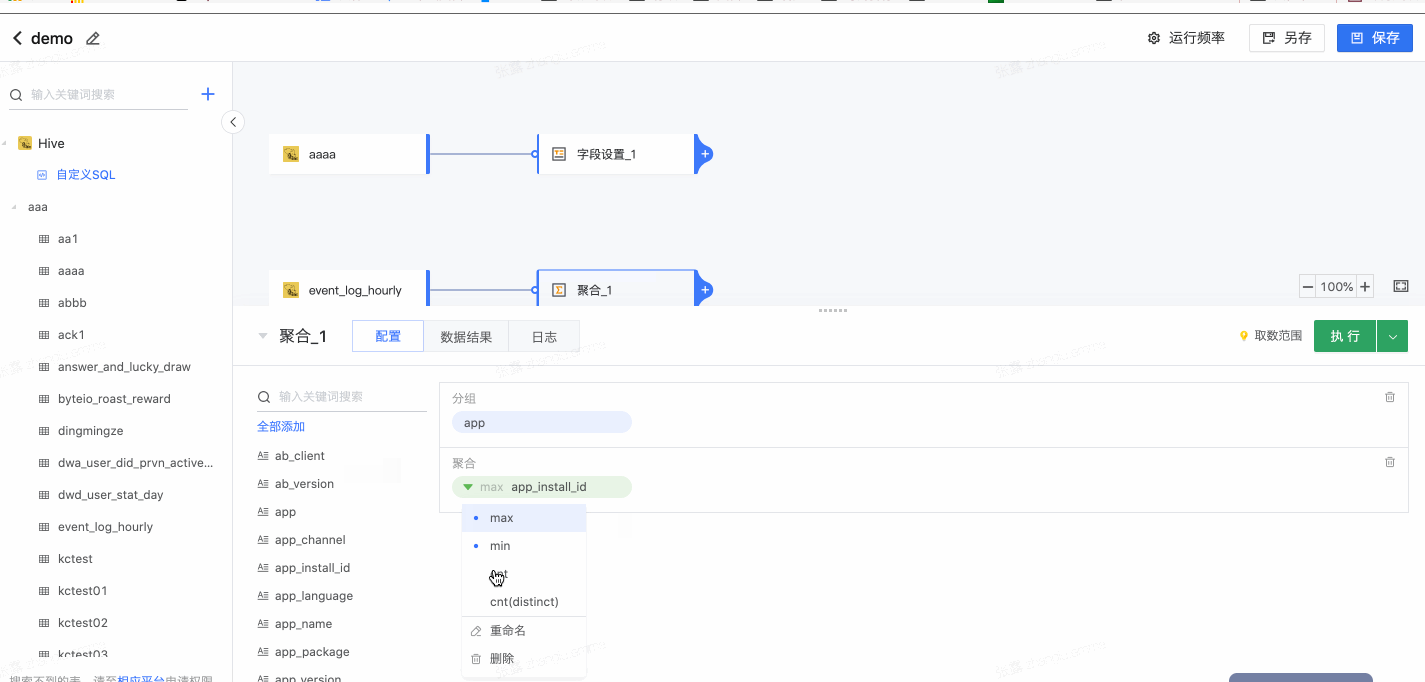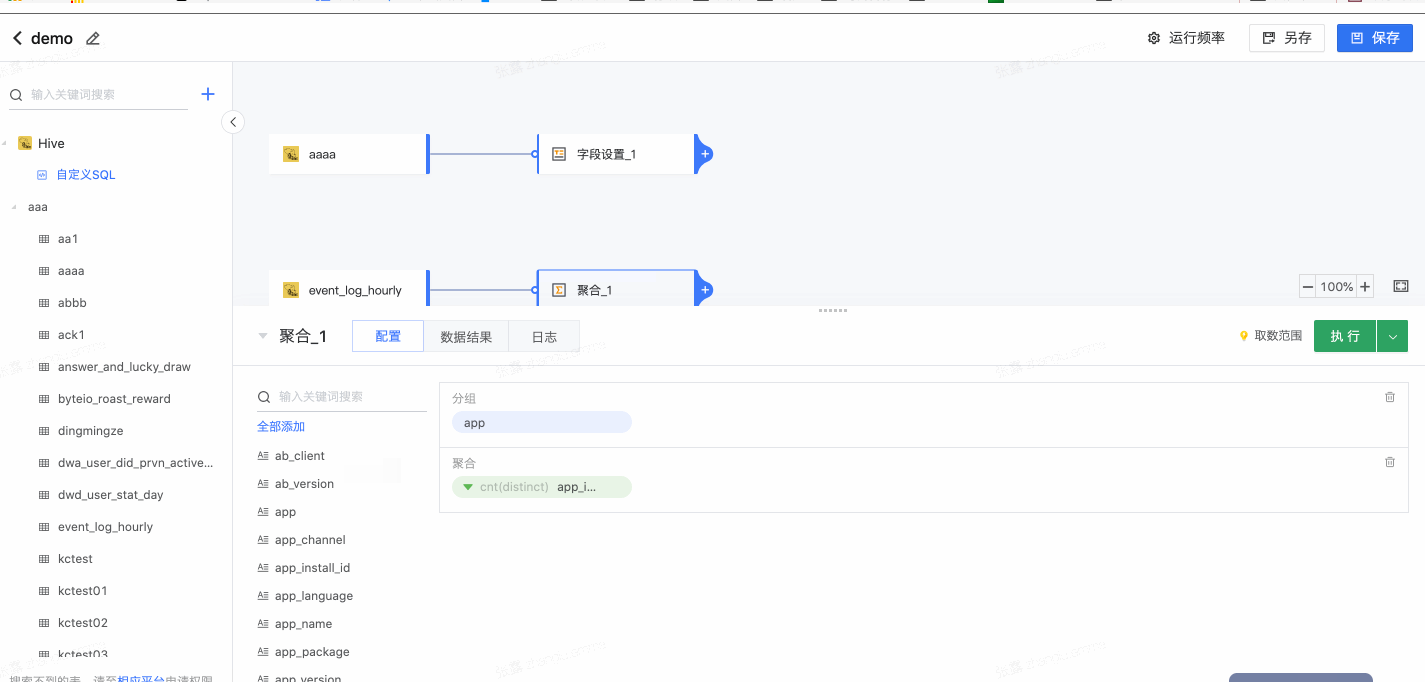
2.4 聚合
通过分组实现明细数据的聚合计算。
- 选择分组,拖拽字段到“分组”
- 选择聚合字段及方式: 拖拽字段到“聚合”,可更改聚合方式、设置聚合后的字段名称
2.5 计算列
计算列算子,支持自定义表达式,使用Spark函数处理上游字段并添加新字段。计算列的配置流程可以表格形式清晰展示新增的字段。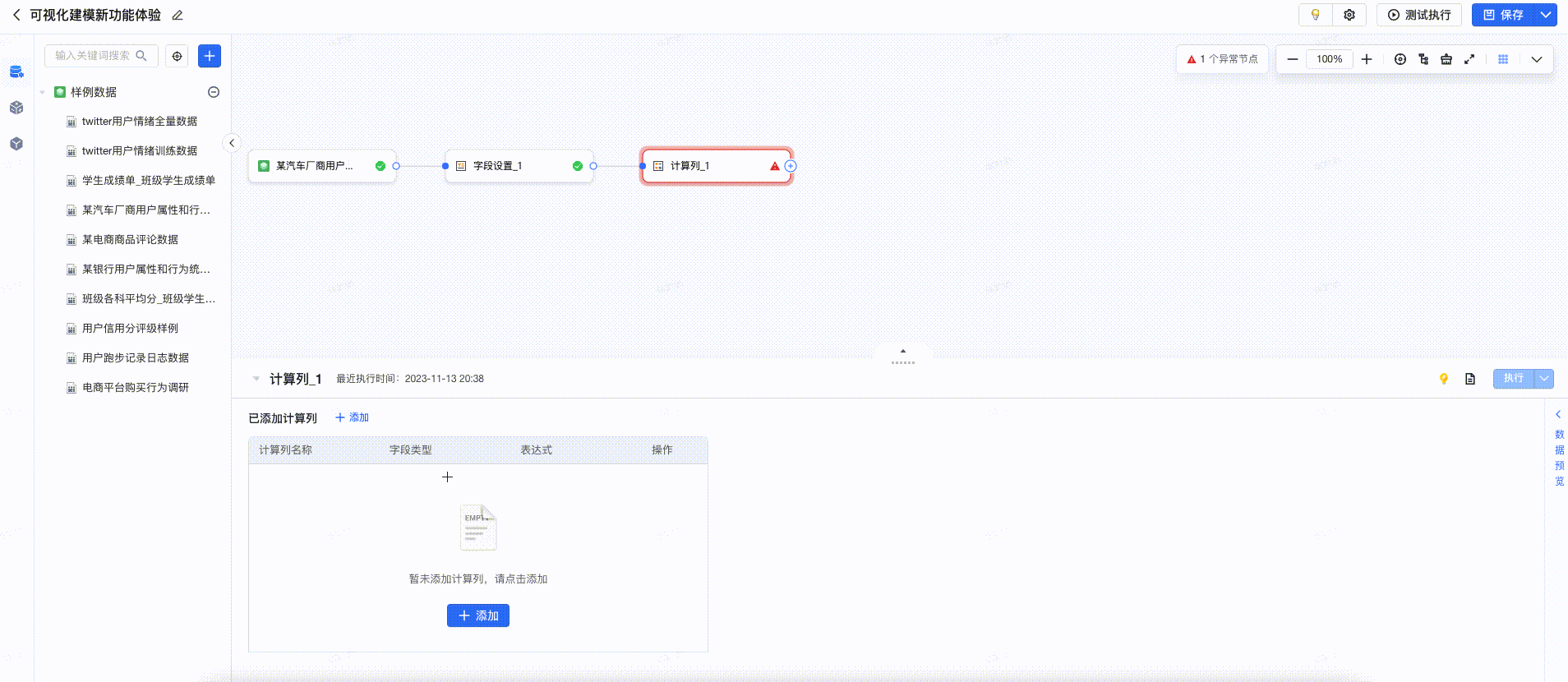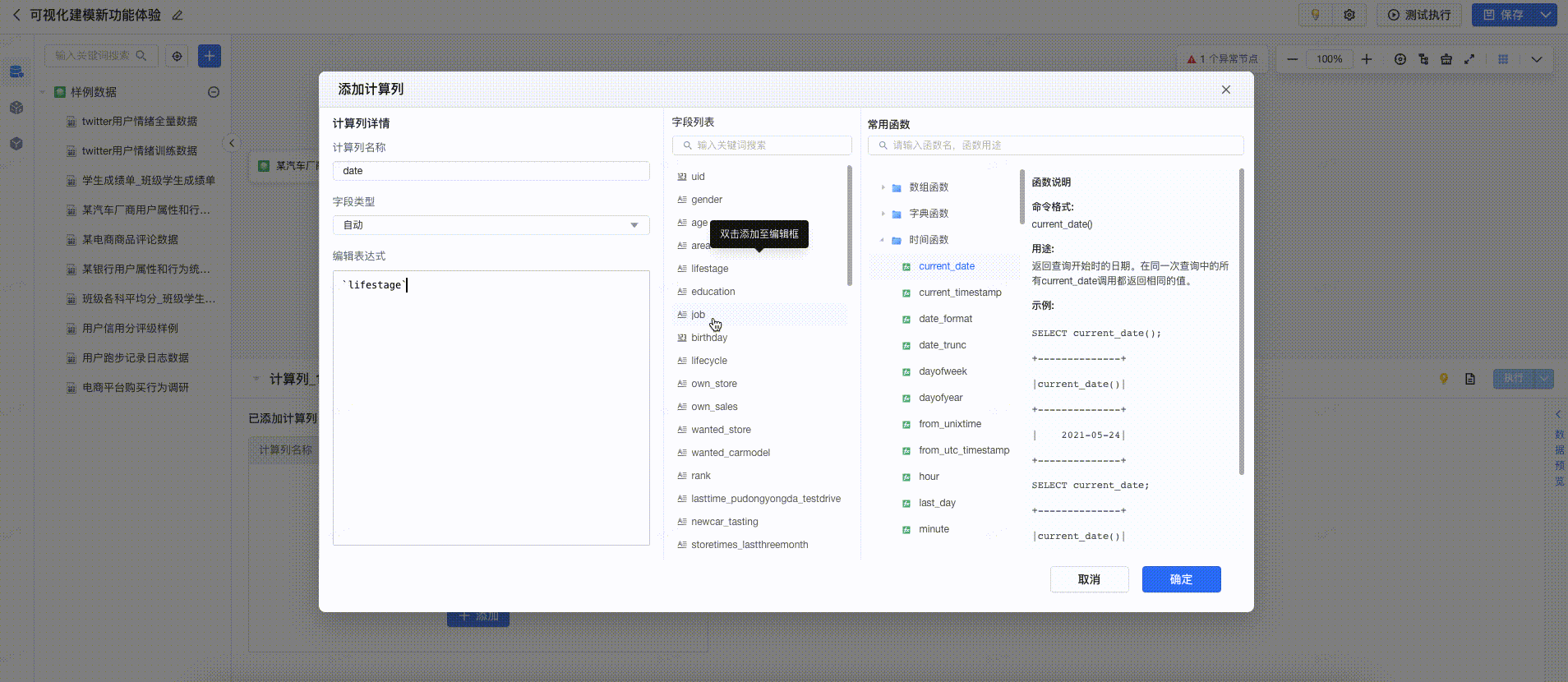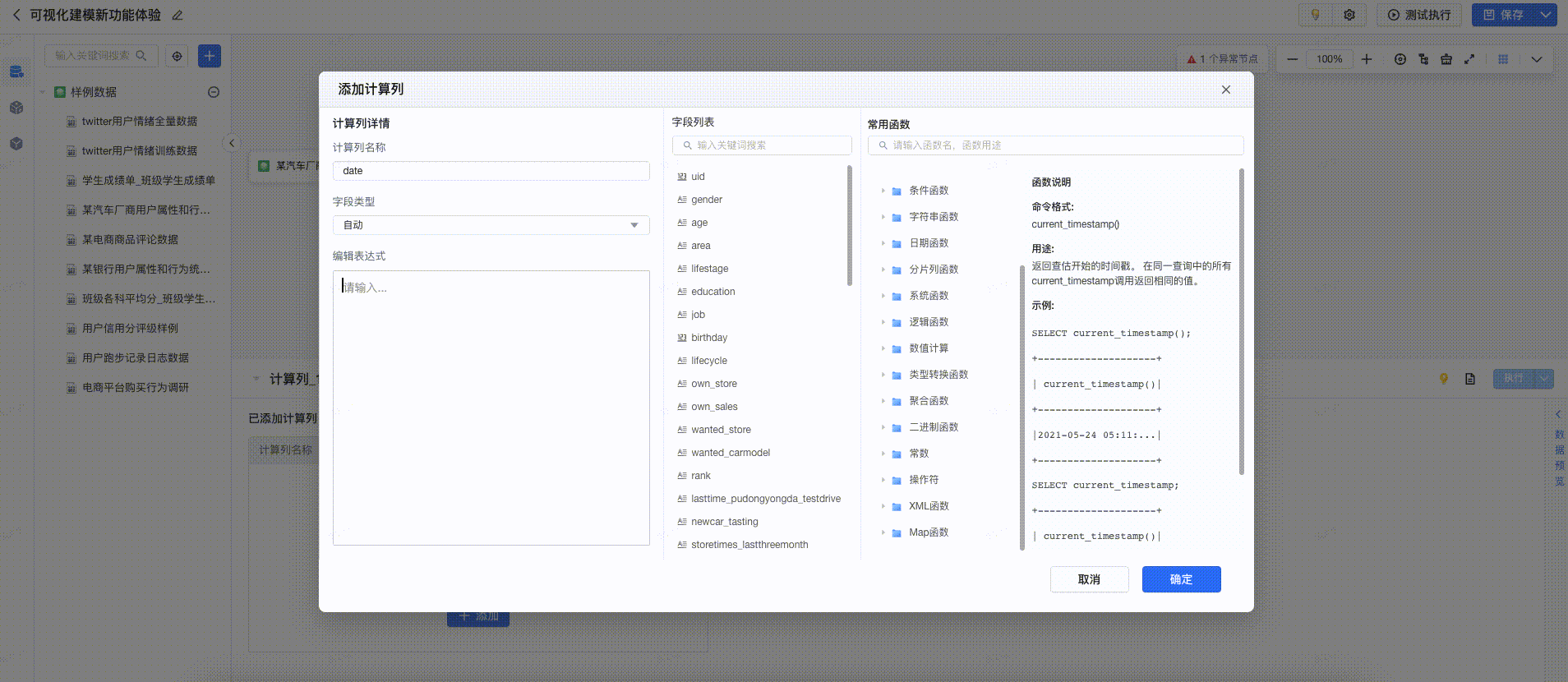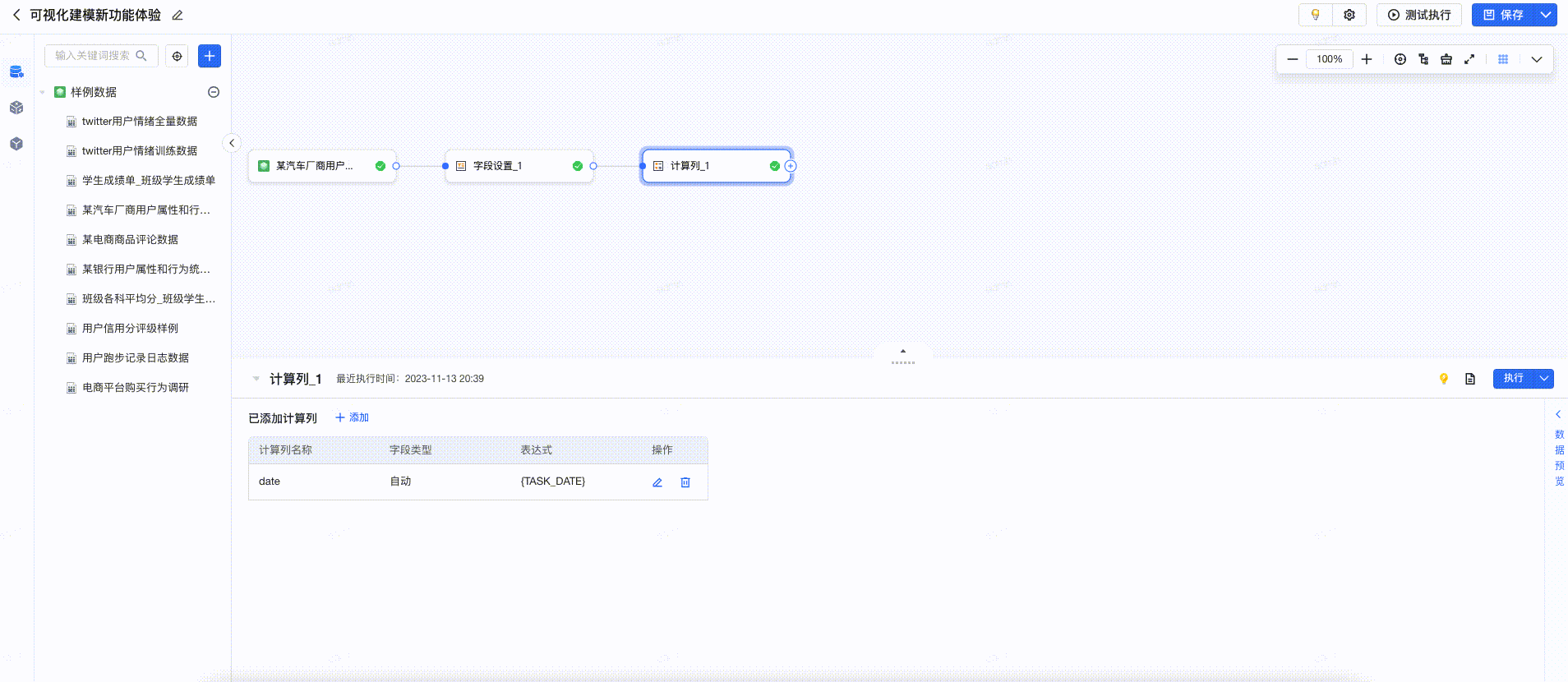
2.6 筛选行
选择字段,确认筛选条件,支持两层且/或逻辑关系。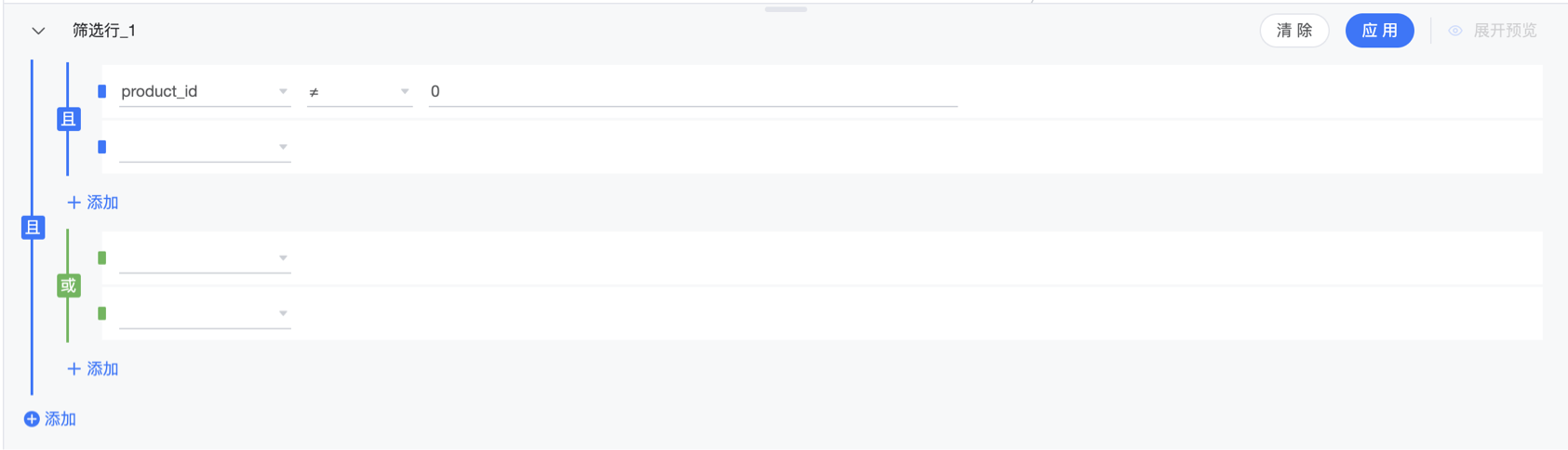
2.7 列转行
将表头多列的指标转化到一列中展示,宽表变为高表。 实现效果 如学生的学科成绩表,语文、英语、数学三门学科分数各为一个字段
学生姓名 | 学号 | 性别 | 语文 | 数学 | 英语 |
|---|---|---|---|---|---|
张三 | 2014010201 | 男 | 88 | 88 | 88 |
李四 | 2014010202 | 女 | 87 | 76 | 99 |
王五 | 2014010203 | 男 | 79 | 75 | 78 |
小贾 | 2014010204 | 女 | 60 | 60 | |
小一 | 2014010205 | 男 | 90 | 97 | 96 |
小冰 | 2014010206 | 女 | 80 | 100 | 95 |
小丁 | 2014010207 | 男 | 90 | 99 | 98 |
小小 | 2014010208 | 女 | 78 | 98 | 85 |
通过列转行,可以将三门课成绩合并为一个“成绩”字段,并添加“学科”字段区分各门科的成绩
学生姓名 | 学号 | 性别 | 学科 | 成绩 |
|---|---|---|---|---|
张三 | 2014010201 | 男 | 语文 | 88 |
李四 | 2014010202 | 女 | 语文 | 87 |
王五 | 2014010203 | 男 | 语文 | 79 |
小贾 | 2014010204 | 女 | 语文 | 60 |
小一 | 2014010205 | 男 | 语文 | 90 |
小冰 | 2014010206 | 女 | 语文 | 80 |
小丁 | 2014010207 | 男 | 语文 | 90 |
小小 | 2014010208 | 女 | 语文 | 78 |
张三 | 2014010201 | 男 | 数学 | 88 |
李四 | 2014010202 | 女 | 数学 | 76 |
王五 | 2014010203 | 男 | 数学 | 75 |
小贾 | 2014010204 | 女 | 数学 | |
小一 | 2014010205 | 男 | 数学 | 97 |
小冰 | 2014010206 | 女 | 数学 | 100 |
小丁 | 2014010207 | 男 | 数学 | 99 |
小小 | 2014010208 | 女 | 数学 | 98 |
张三 | 2014010201 | 男 | 英语 | 88 |
李四 | 2014010202 | 女 | 英语 | 99 |
王五 | 2014010203 | 男 | 英语 | 78 |
小贾 | 2014010204 | 女 | 英语 | 60 |
小一 | 2014010205 | 男 | 英语 | 96 |
小冰 | 2014010206 | 女 | 英语 | 95 |
小丁 | 2014010207 | 男 | 英语 | 98 |
小小 | 2014010208 | 女 | 英语 | 85 |
处理示例 在模型后添加列转行节点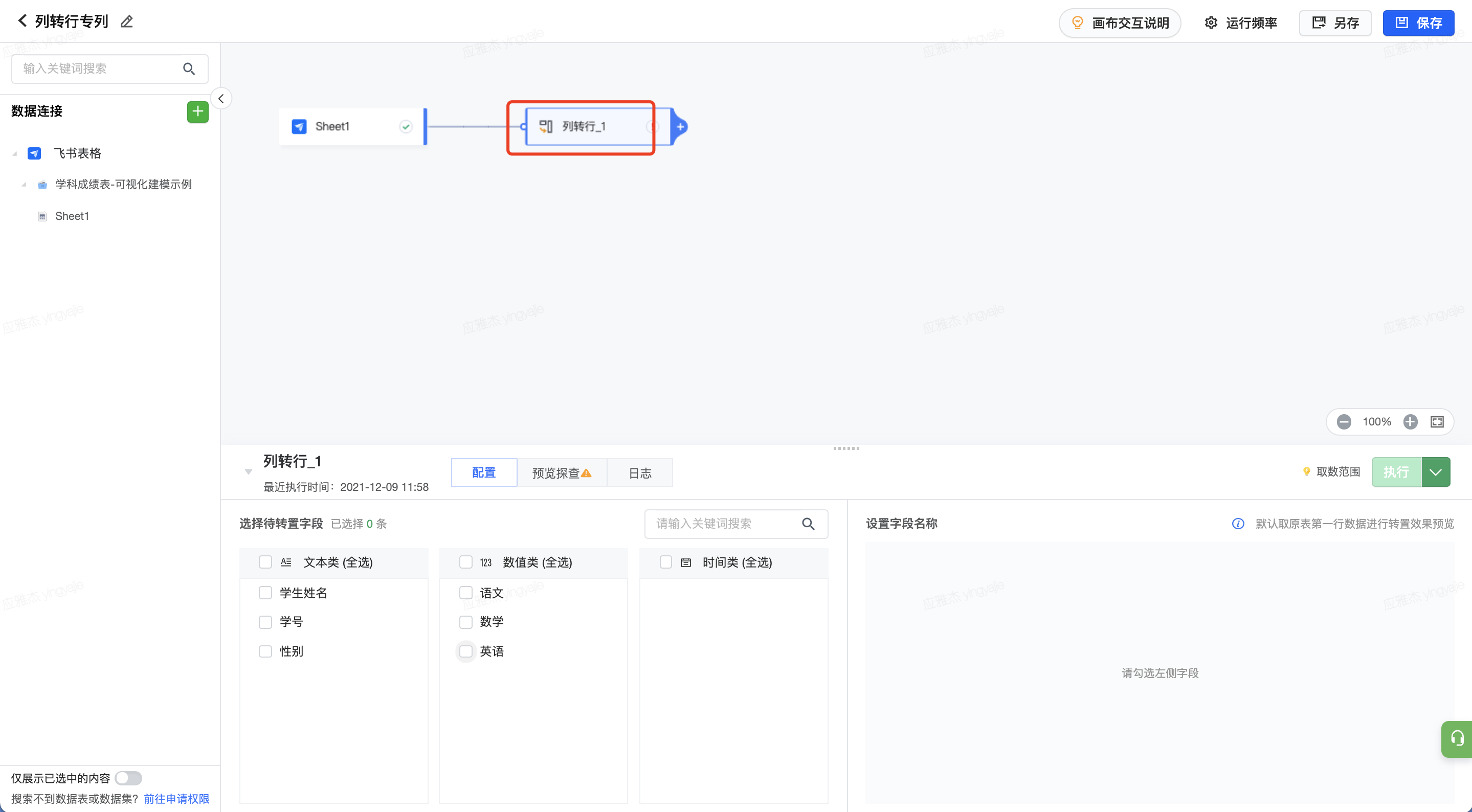
勾选需要转化的字段,本案例中选择“语文”、“数学”、“英语”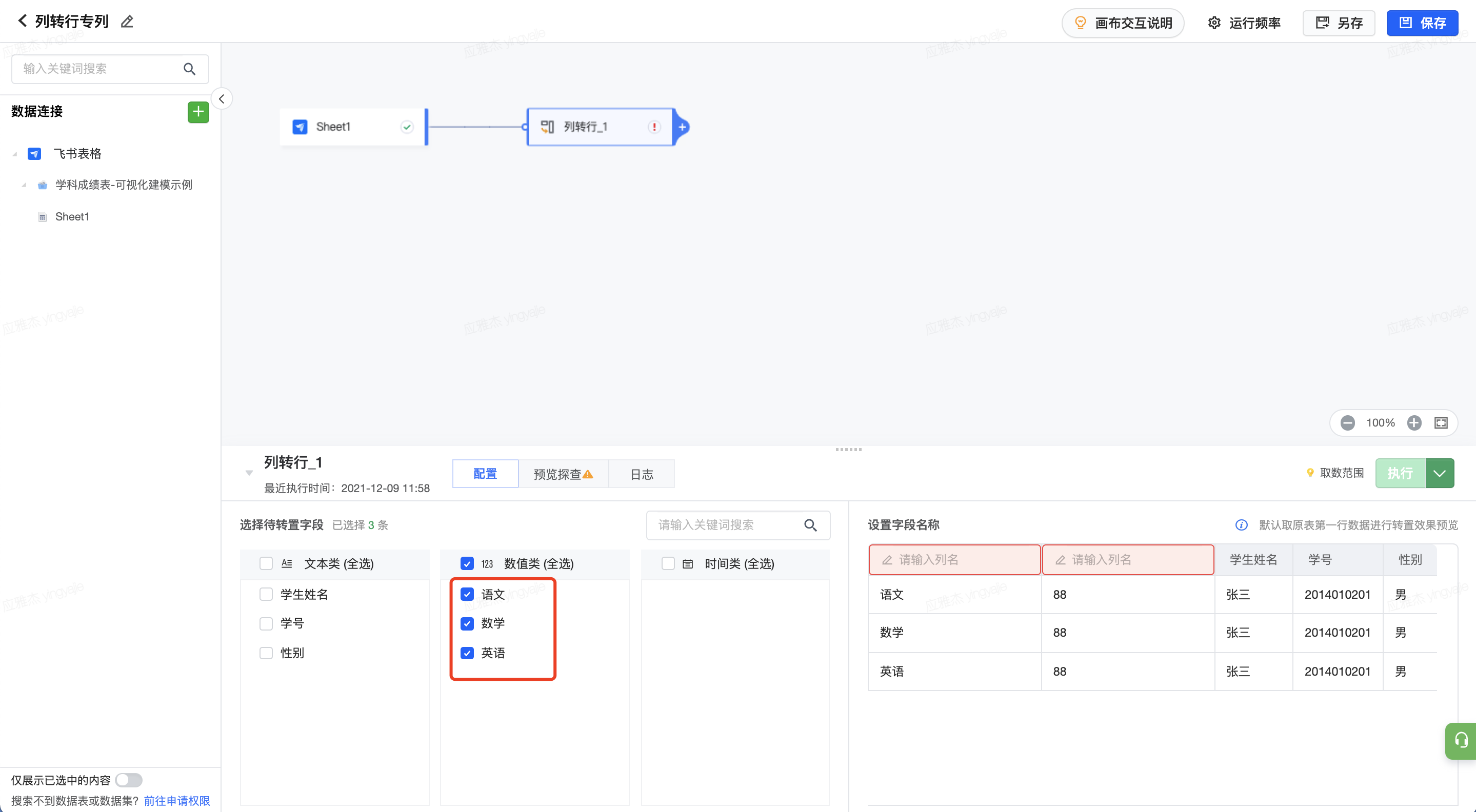
分别为原来的字段名和字段数值设置转化后的列名,本案例中分别为“学科”和“成绩”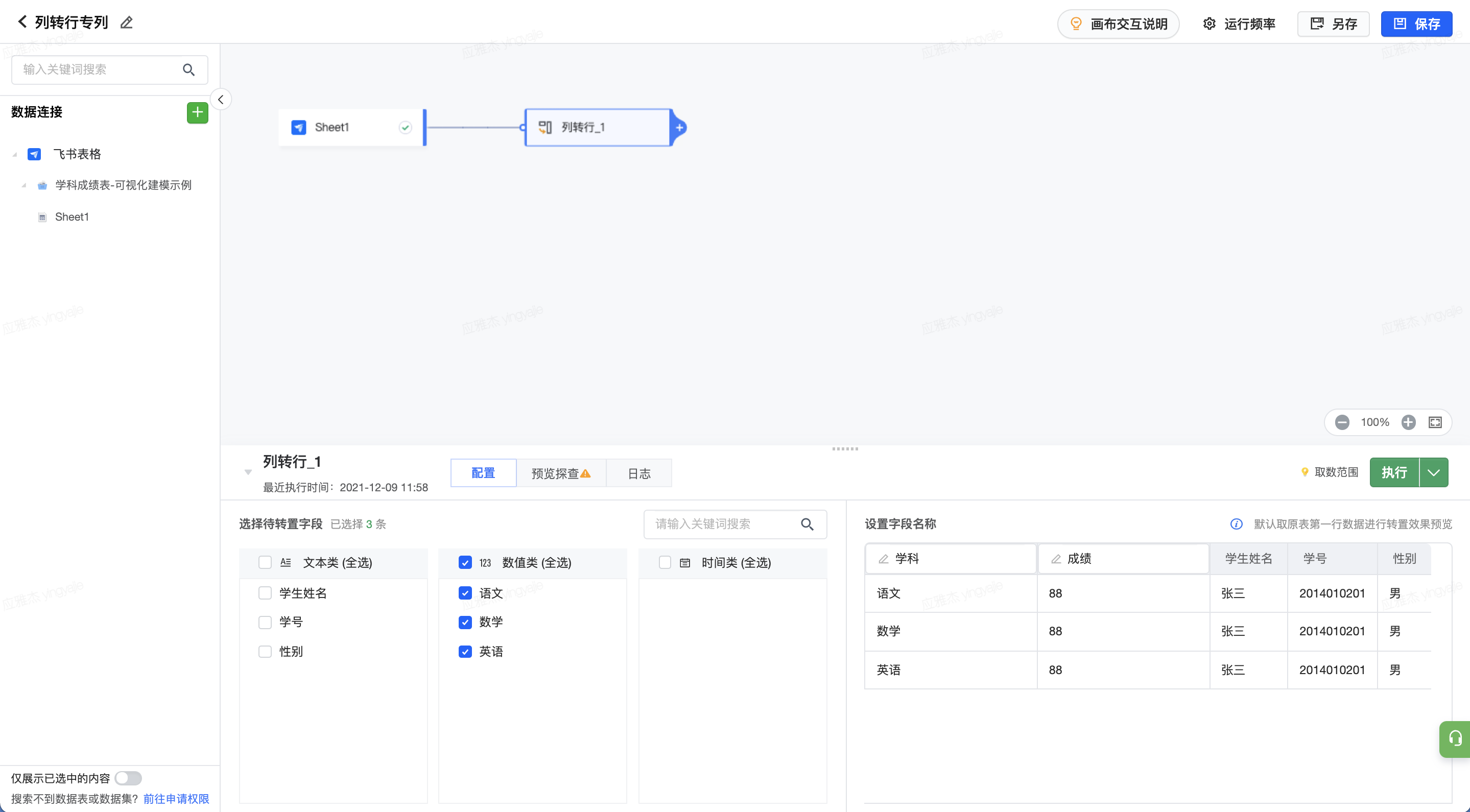
执行节点,即可预览数据。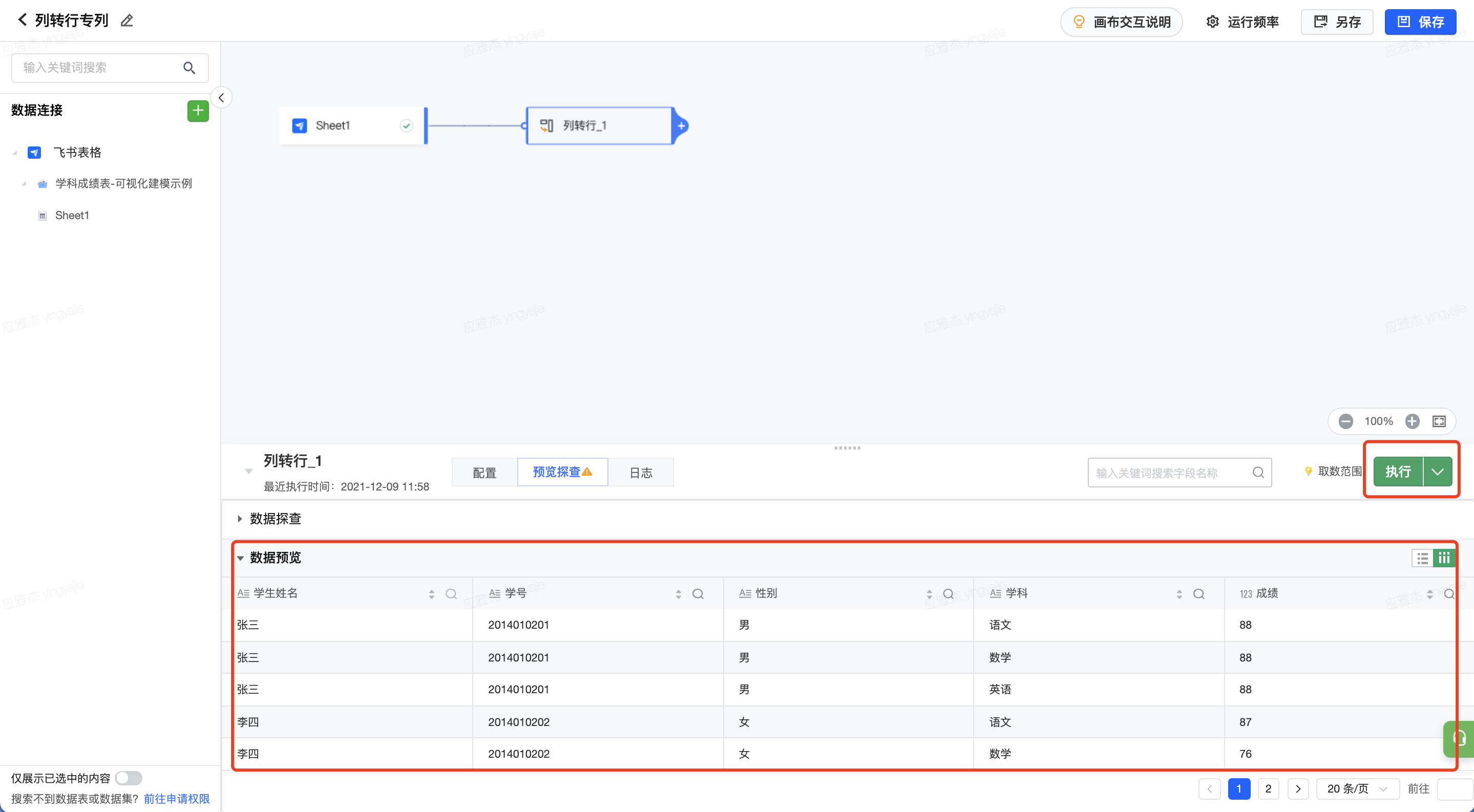
2.8 行转列
将一列的字段值转化为表头列,高表变为宽表 实现效果 如学生的学科成绩表,有学科和成绩字段,记录了各门课的成绩
学生姓名 | 学号 | 性别 | 学科 | 成绩 |
|---|---|---|---|---|
张三 | 2014010201 | 男 | 语文 | 88 |
李四 | 2014010202 | 女 | 语文 | 87 |
王五 | 2014010203 | 男 | 语文 | 79 |
小贾 | 2014010204 | 女 | 语文 | 60 |
小一 | 2014010205 | 男 | 语文 | 90 |
小冰 | 2014010206 | 女 | 语文 | 80 |
小丁 | 2014010207 | 男 | 语文 | 90 |
小小 | 2014010208 | 女 | 语文 | 78 |
张三 | 2014010201 | 男 | 数学 | 88 |
李四 | 2014010202 | 女 | 数学 | 76 |
王五 | 2014010203 | 男 | 数学 | 75 |
小贾 | 2014010204 | 女 | 数学 | |
小一 | 2014010205 | 男 | 数学 | 97 |
小冰 | 2014010206 | 女 | 数学 | 100 |
小丁 | 2014010207 | 男 | 数学 | 99 |
小小 | 2014010208 | 女 | 数学 | 98 |
张三 | 2014010201 | 男 | 英语 | 88 |
李四 | 2014010202 | 女 | 英语 | 99 |
王五 | 2014010203 | 男 | 英语 | 78 |
小贾 | 2014010204 | 女 | 英语 | 60 |
小一 | 2014010205 | 男 | 英语 | 96 |
小冰 | 2014010206 | 女 | 英语 | 95 |
小丁 | 2014010207 | 男 | 英语 | 98 |
小小 | 2014010208 | 女 | 英语 | 85 |
通过行转列,可以将学科成绩拆分成“语文成绩”、“数学成绩”、“英语成绩”三个字段,成为学生粒度的宽表
学生姓名 | 学号 | 性别 | 语文 | 数学 | 英语 |
|---|---|---|---|---|---|
张三 | 2014010201 | 男 | 88 | 88 | 88 |
李四 | 2014010202 | 女 | 87 | 76 | 99 |
王五 | 2014010203 | 男 | 79 | 75 | 78 |
小贾 | 2014010204 | 女 | 60 | 60 | |
小一 | 2014010205 | 男 | 90 | 97 | 96 |
小冰 | 2014010206 | 女 | 80 | 100 | 95 |
小丁 | 2014010207 | 男 | 90 | 99 | 98 |
小小 | 2014010208 | 女 | 78 | 98 | 85 |
处理示例 在模型后添加行转列节点
选择需要行转列的字段和对应的值字段,将其他需保留字段放入保留字段一栏。然后,点击配置新增列,也就是需要将“学科”拆分成哪几个字段,并填入对应的“学科”中的值。
该步骤还支持对值字段同时作聚合。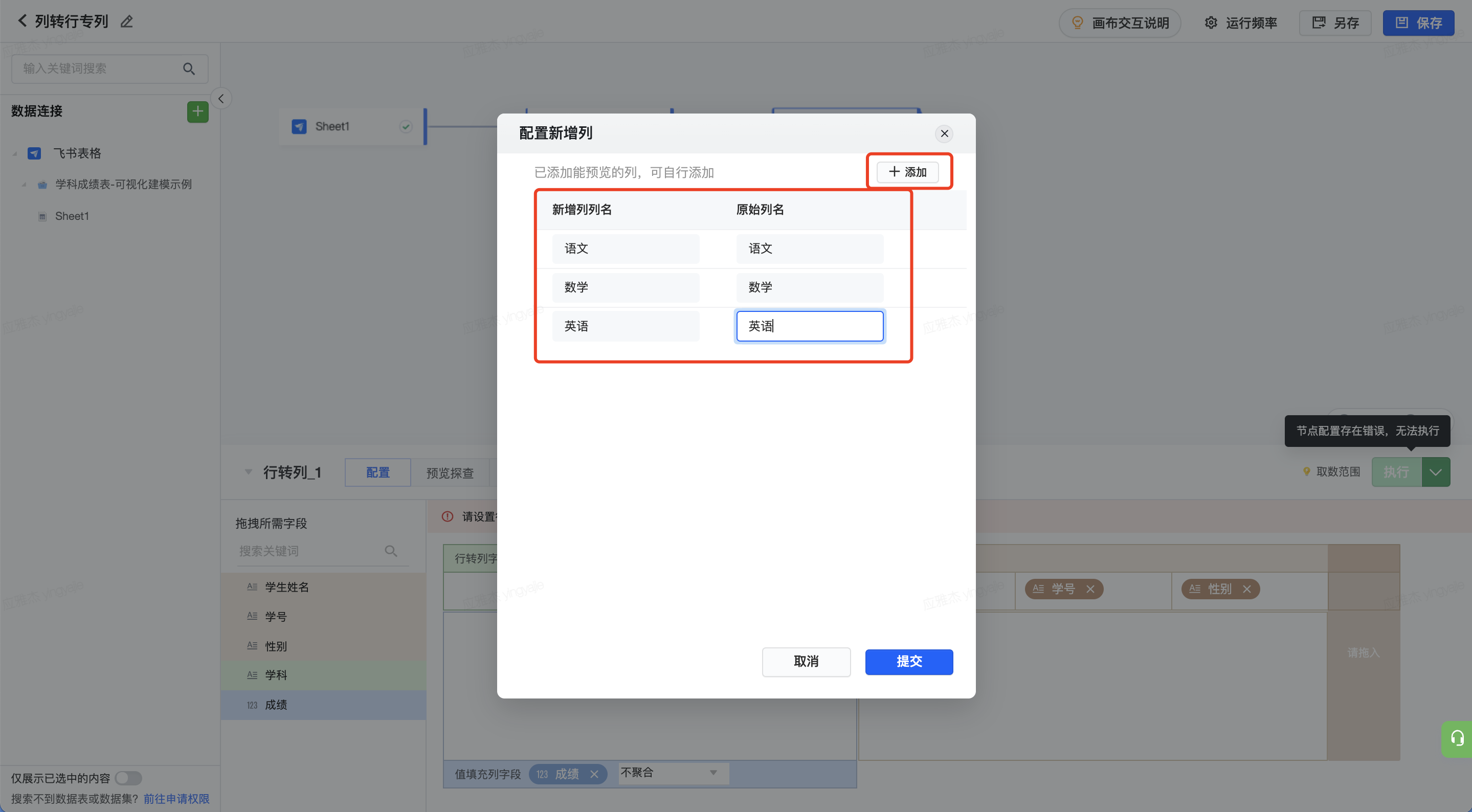
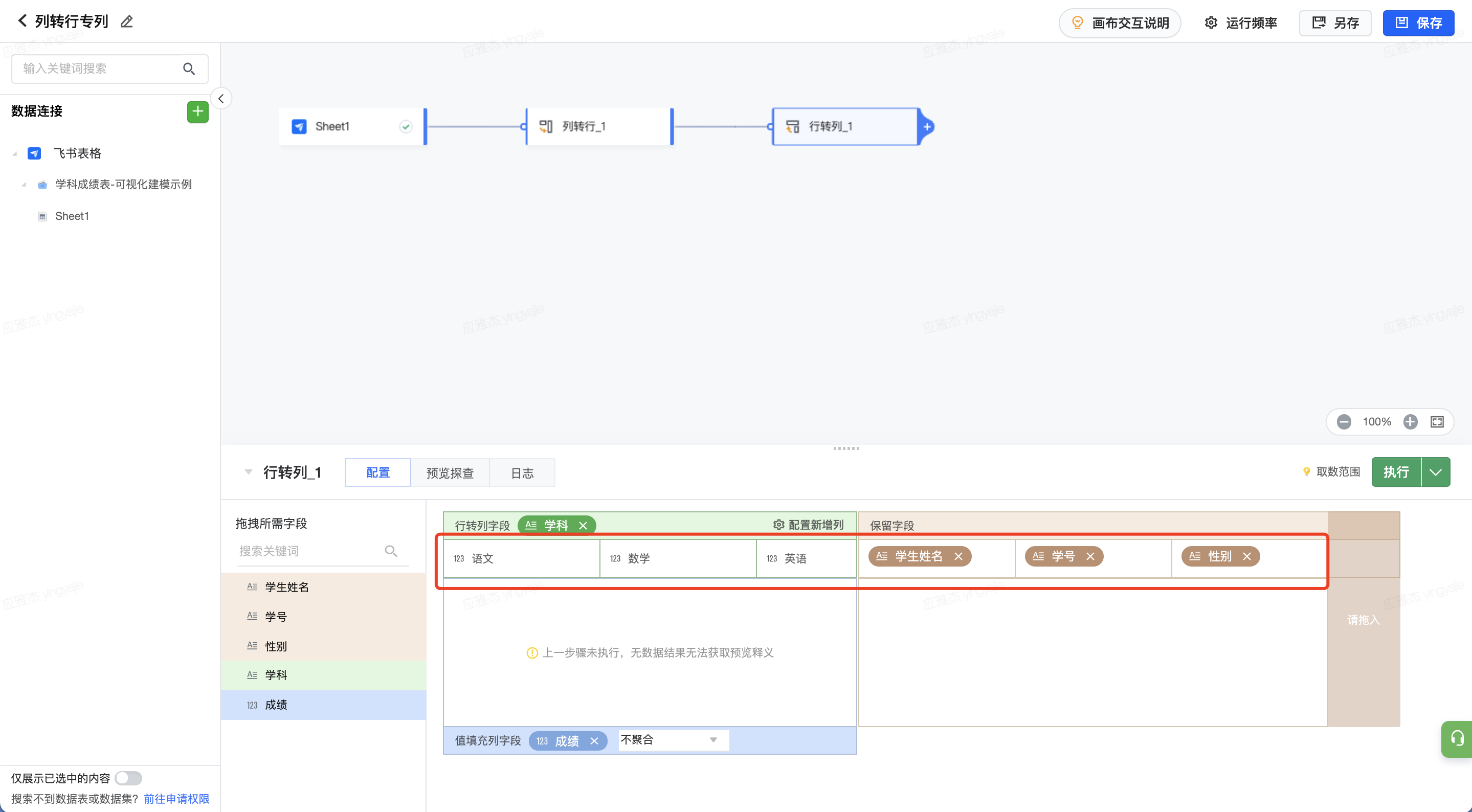
上图中红框内容即为执行行转列后的表结构。执行节点,即可预览数据。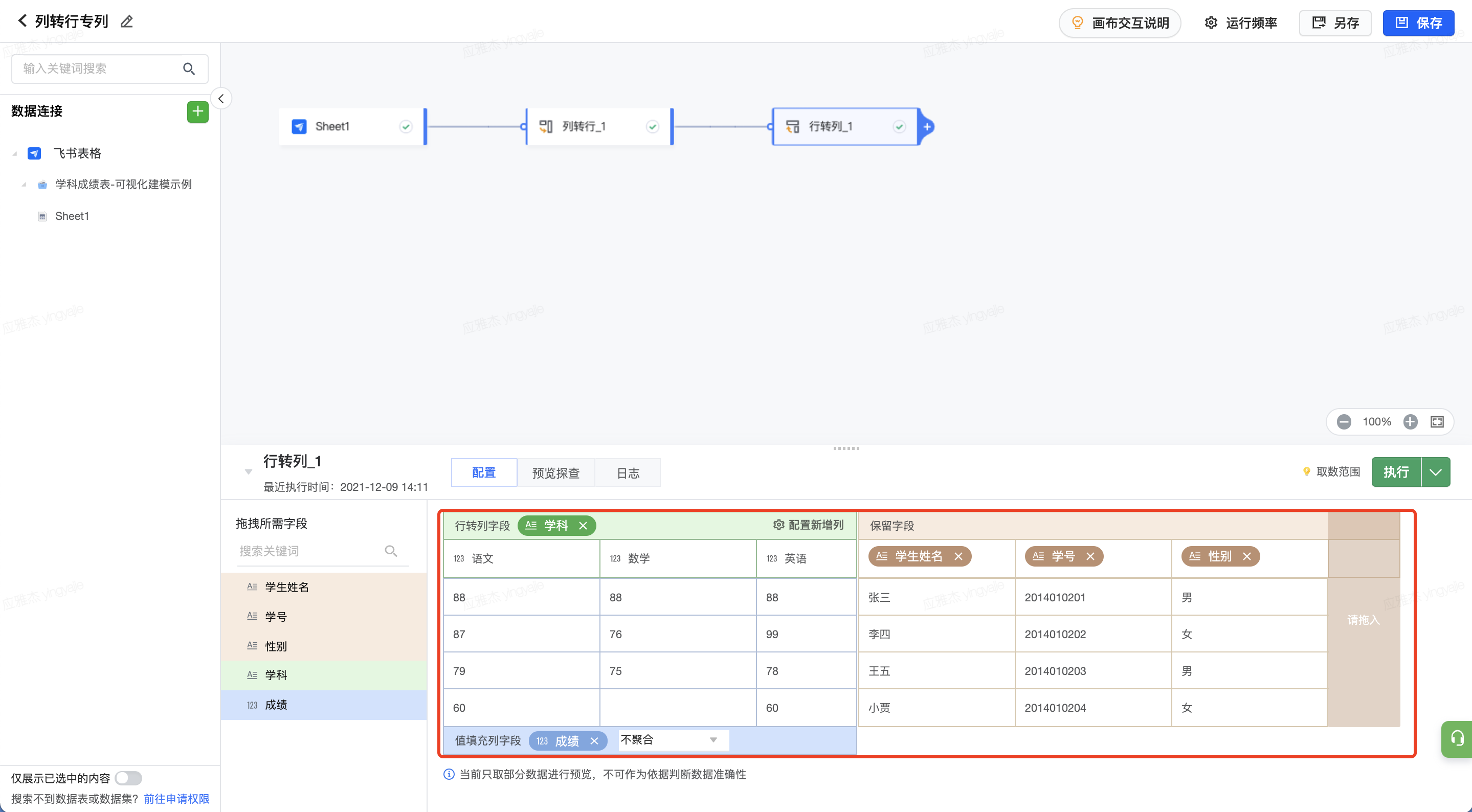
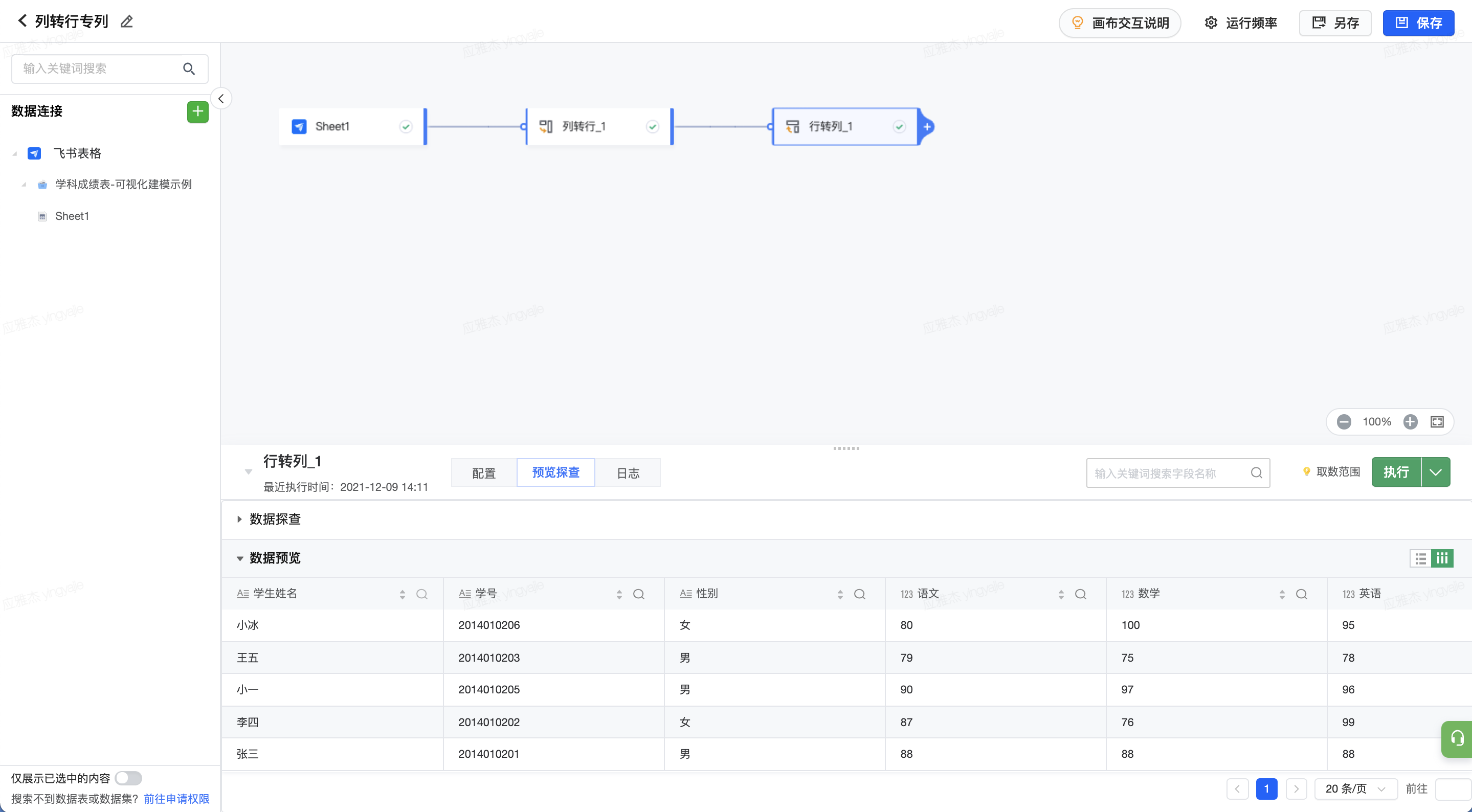
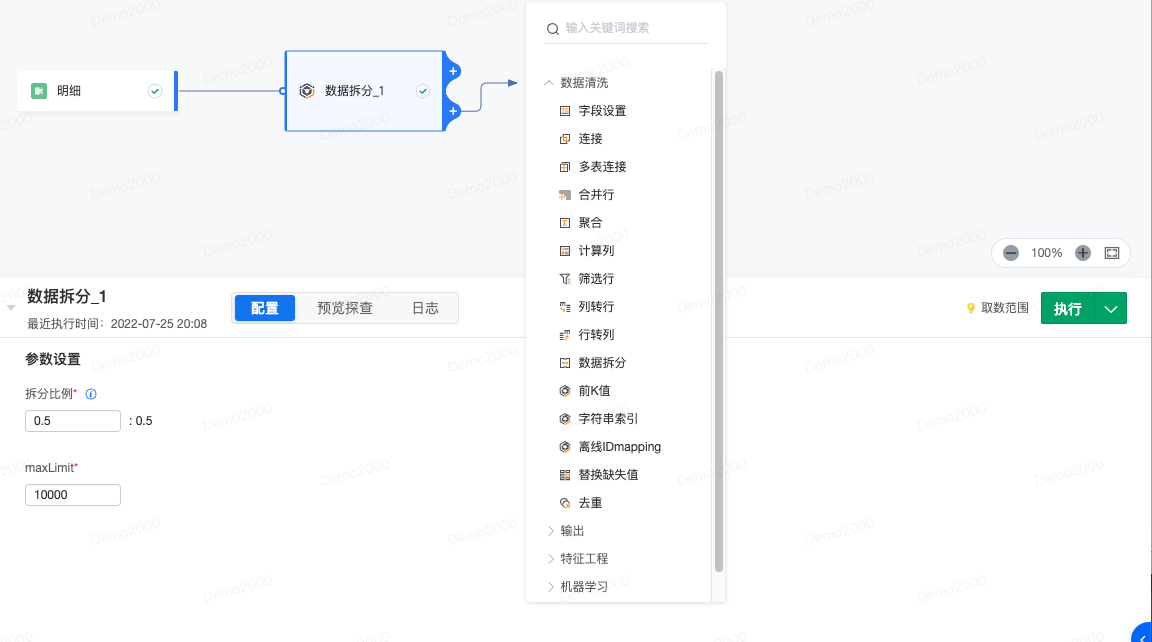
2.9 数据拆分
拆分算子会将算子按照这个比例拆分成两份数据,这个值代表第一份数据占输入数据的比例。之后按照比例拆分的两份数据即可进行下一步操作。
2.10 字符串索引
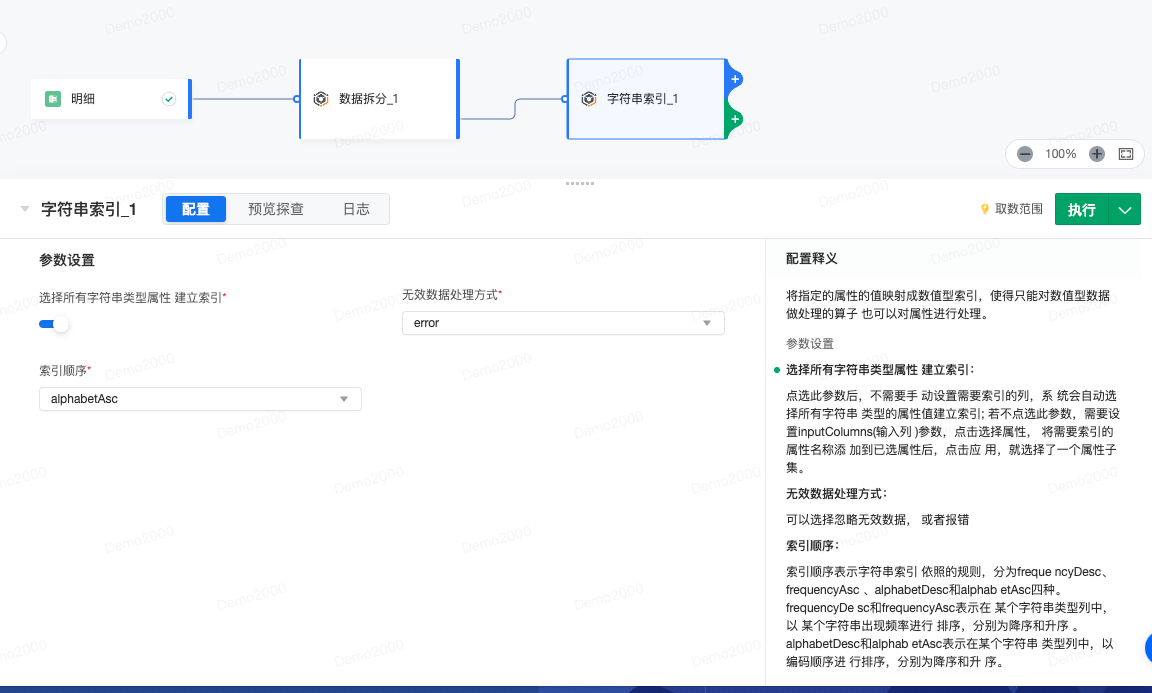
一种类型转换算子,它将指定的属性的值映射成数值型索引,使得只能对数值型数据做处理的算子 也可以对属性进行处理。该算子一般用于数据预处理,另外,不适合对于包含连续型数据的列执行该算子,如ID列。
说明
配置释义 将指定的属性的值映射成数值型索引,使得只能对数值型数据做处理的算子 也可以对属性进行处理。
参数设置 选择所有字符串类型属性 建立索引: 点选此参数后,不需要手动设置需要索引的列,系统会自动选择所有字符串类型的属性值建立索引; 若不点选此参数,需要设置inputColumns(输入列 )参数,点击选择属性,将需要索引的属性名称添加到已选属性后,点击应用,就选择了一个属性子集。
无效数据处理方式 可以选择忽略无效数据(skip),或者报错(error),也可以不做处理(keep)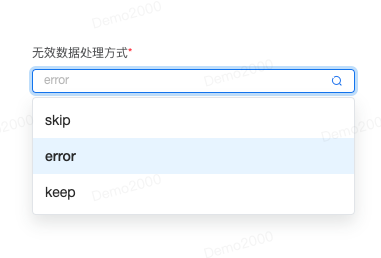
索引顺序 索引顺序表示字符串索引依照的规则,分为frequencyDesc、frequencyAsc 、alphabetDesc和alphabetAsc四种。
- frequencyDesc和frequencyAsc表示在某个字符串类型列中,以某个字符串出现频率进行排序,分别为降序和升序 。
- alphabetDesc和alphab etAsc表示在某个字符串 类型列中,以编码顺序进行排序,分别为降序和升序。
2.11 替换缺失值
数据模型中,可能存在一些字段存在空值。替换缺失值算子支持将缺失的数据替换为该列的最大/最小/平均值、最高频值或自定义值。
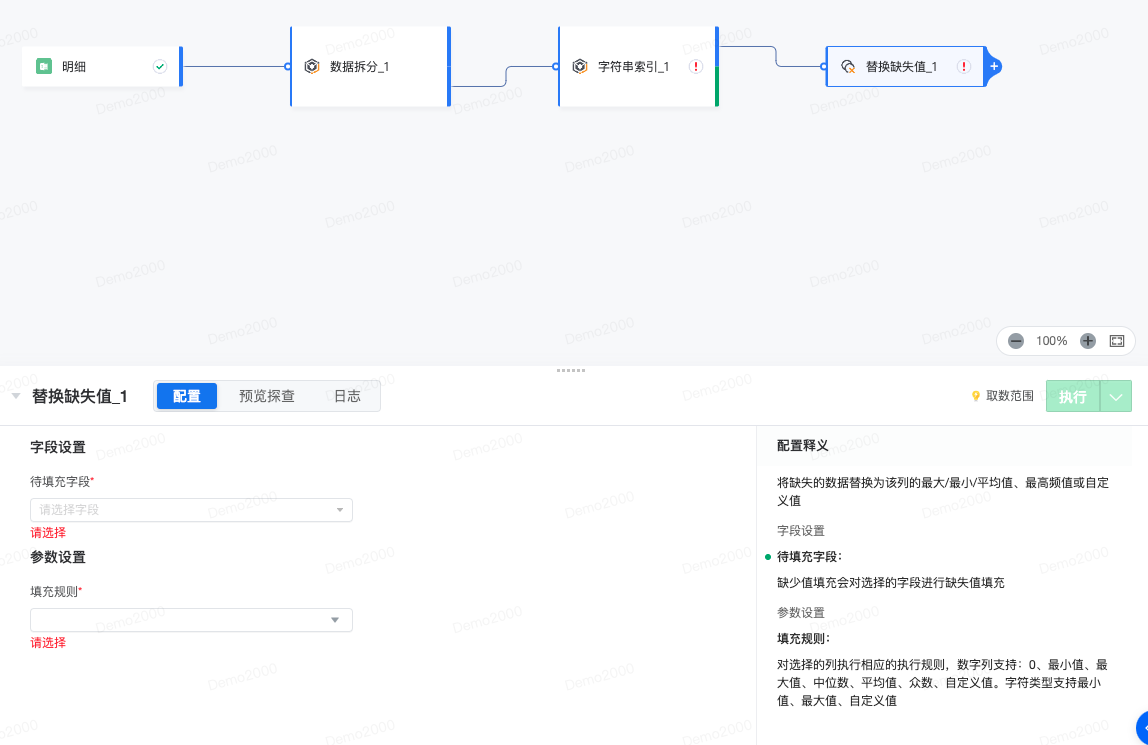
配置释义 将缺失的数据替换为该列的最大/最小/平均值、最高频值或自定义值
字段设置:
- 待填充字段:缺少值填充会对选择的字段进行缺失值填充
- 参数设置--填充规则: 对选择的列执行相应的执行规则,数字列支持:0、最小值、最大值、中位数、平均值、众数、自定义值。字符类型支持最小值、最大值、自定义值
处理示例 如图所示,模型中存在科目成绩为空的数据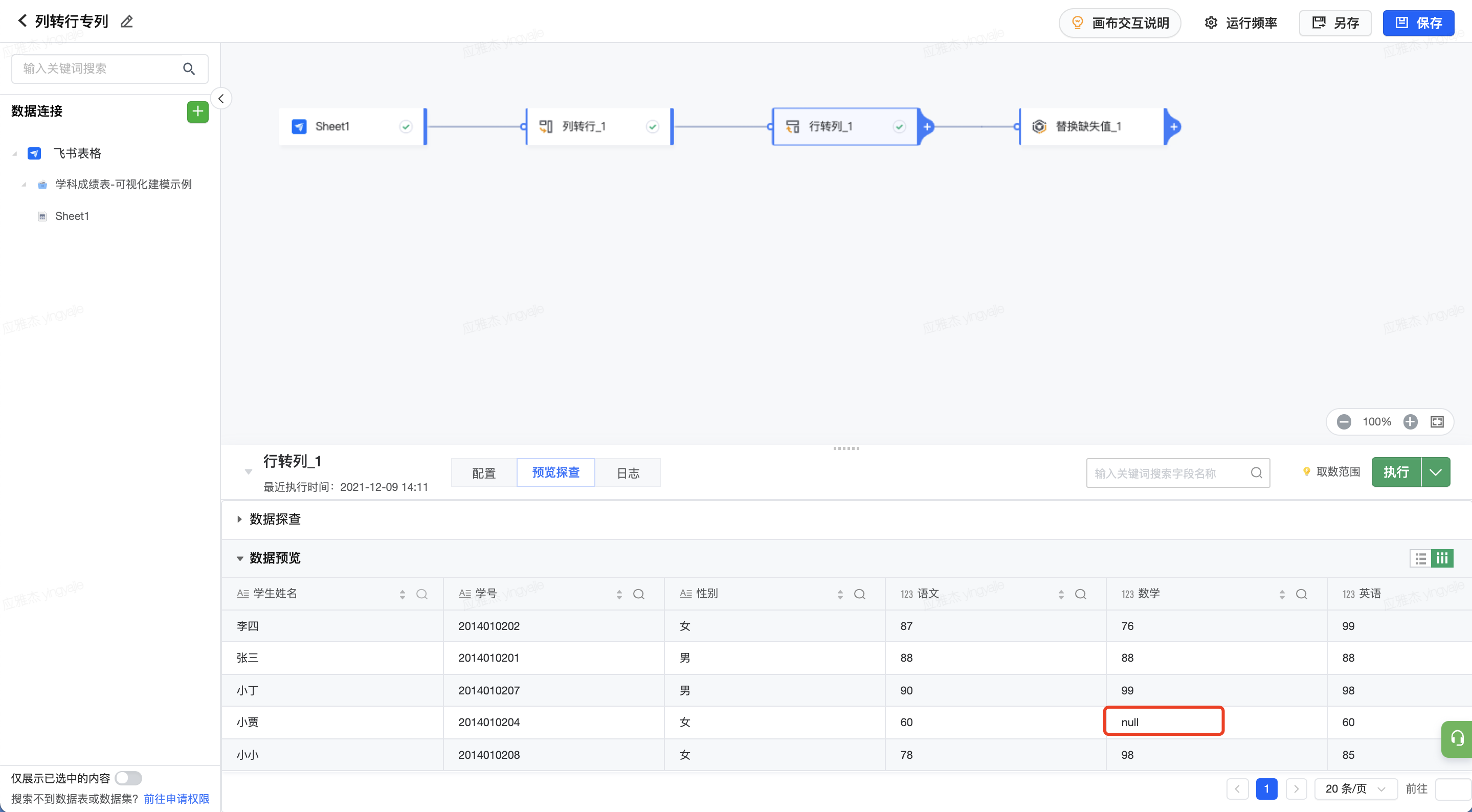
添加替换缺失值节点,在下方节点设置中选择需要填充缺失值的字段和填充规则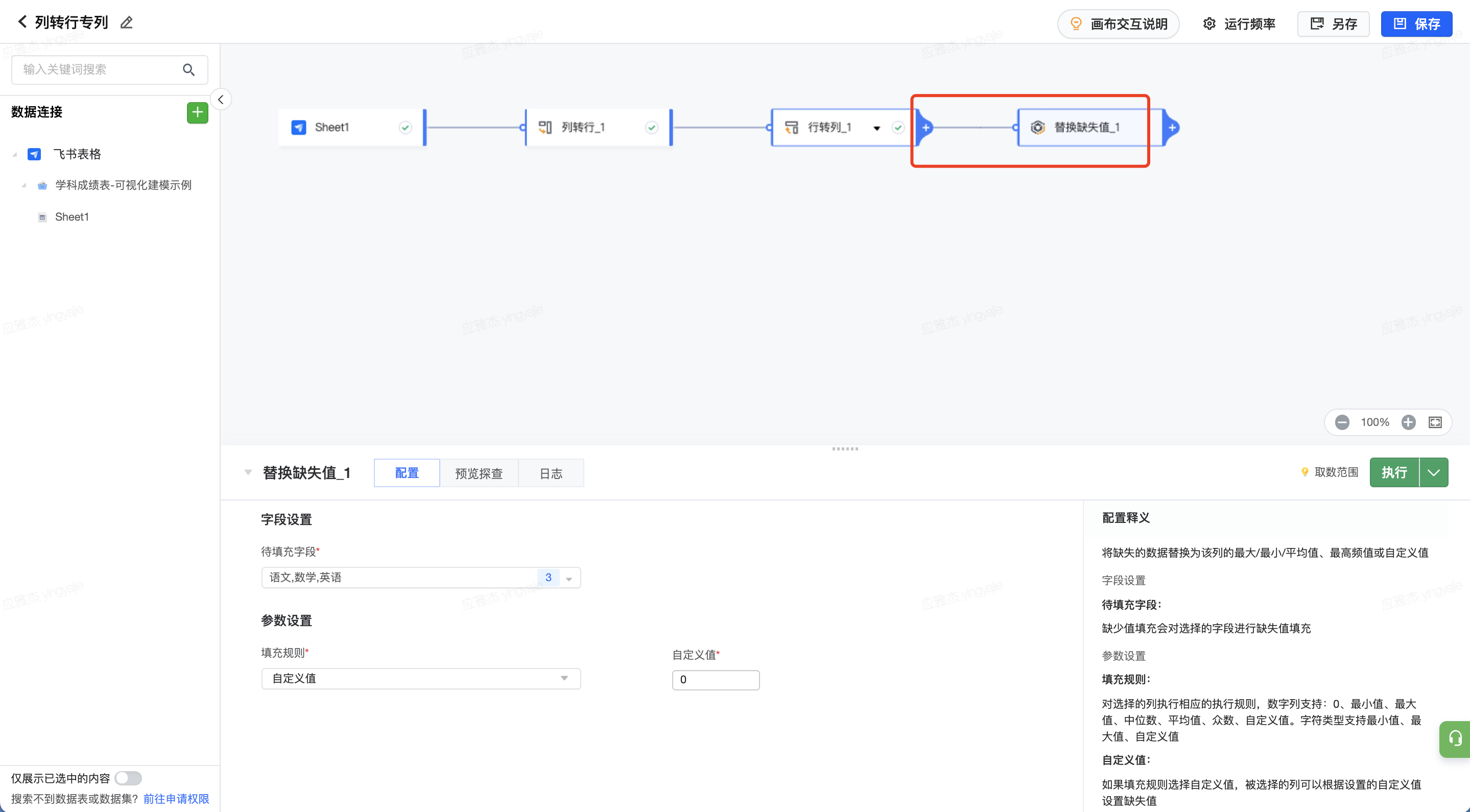
如果选择字段类型为数值,则填充规则可选0、最小值、最大值、中位数、平均值、众数、自定义值。字符类型支持最小值、最大值、自定义值;其他类型支持自定义值填充,如“其他”。
点击执行,可预览处理后数据。
2.12 自由排序
算子释义
选择某个排序字段,对全部数据或某种组合维度下进行排序,并可以选择根据排序截取前K值的数据,K即为截取的排序序号,如按照分数取前100名,100即为K值。 分组排序功能等同于采用窗口函数设置分区并排序的过程。
场景释义
存在包含 商场、销售人员、销售日期、销售额的数据,先通过销售额进行整体排序,查看Top100的销售记录,则选中销售额作为排序字段,倒序取前100值;如果再对每个商场的每个销售人员的销售额进行排序,分别取出Top100的销售记录,则增加选中商场、销售人员作为分组字段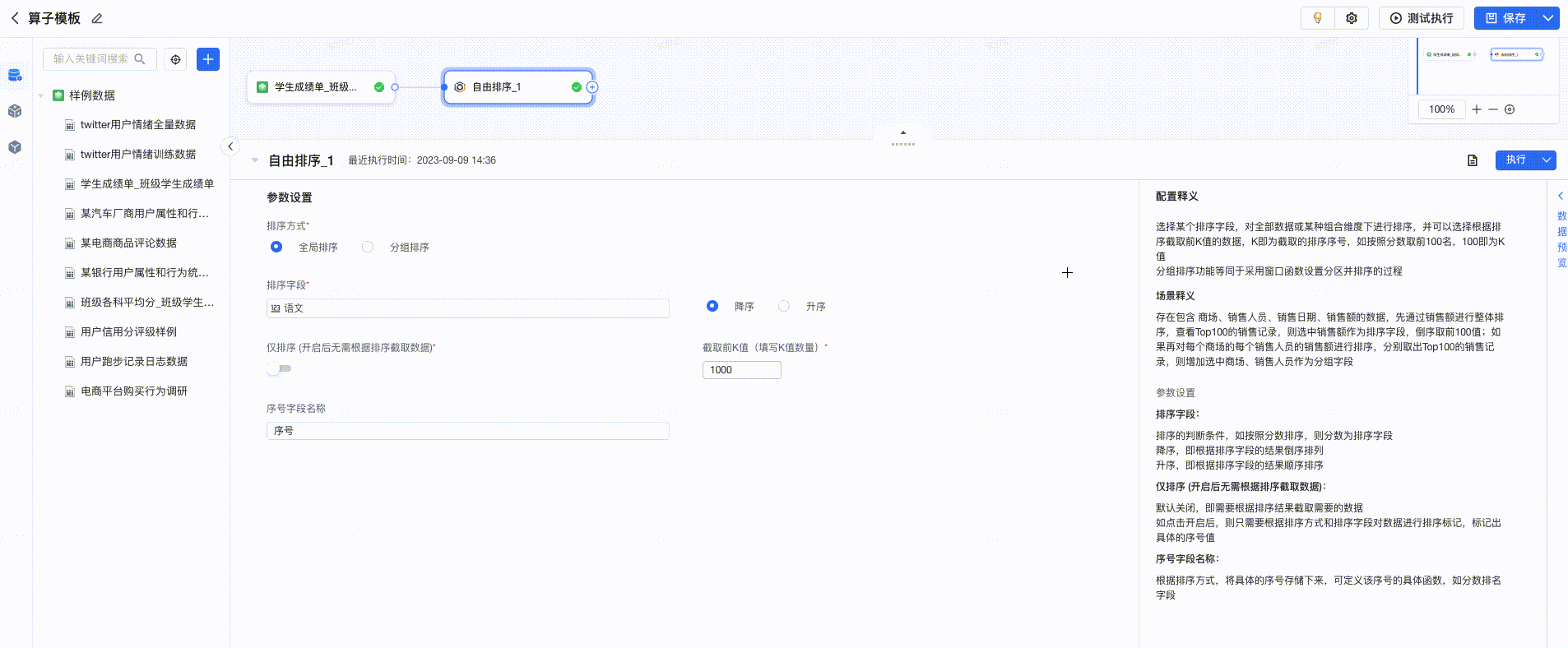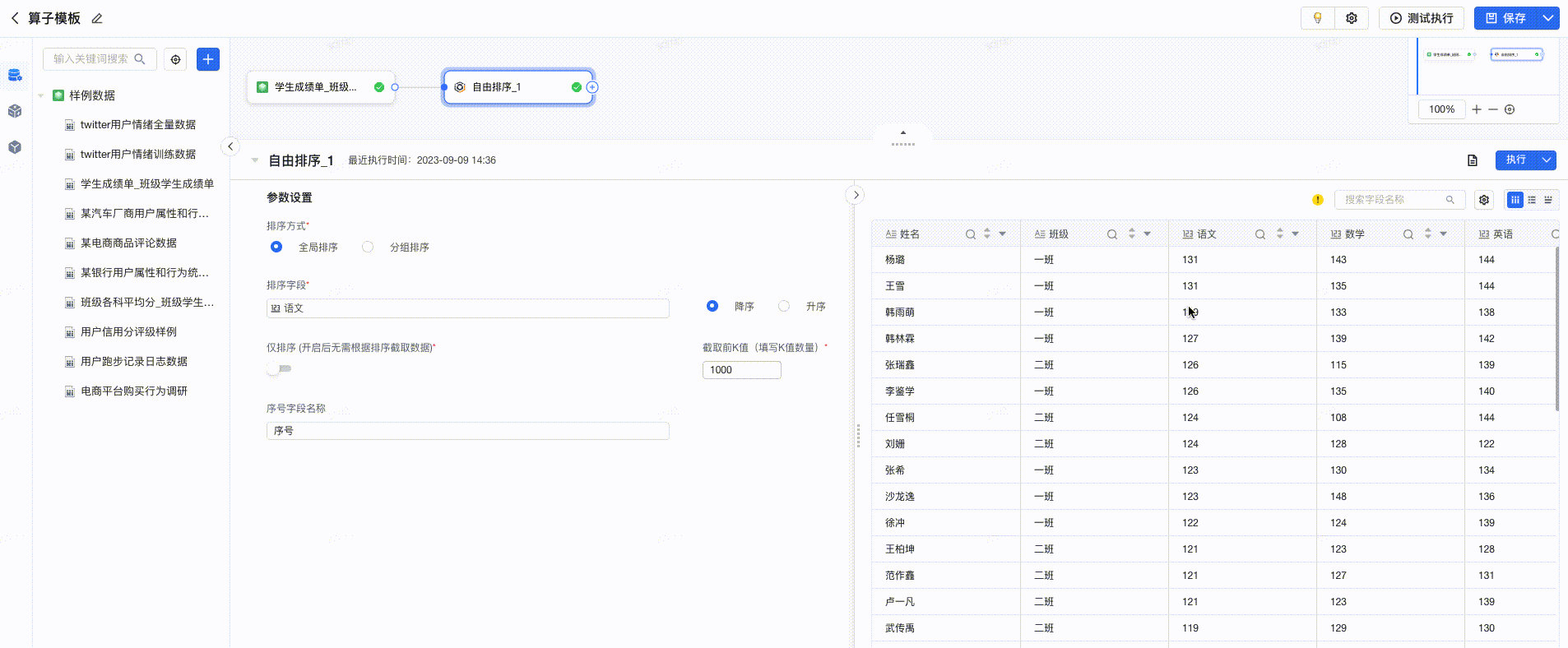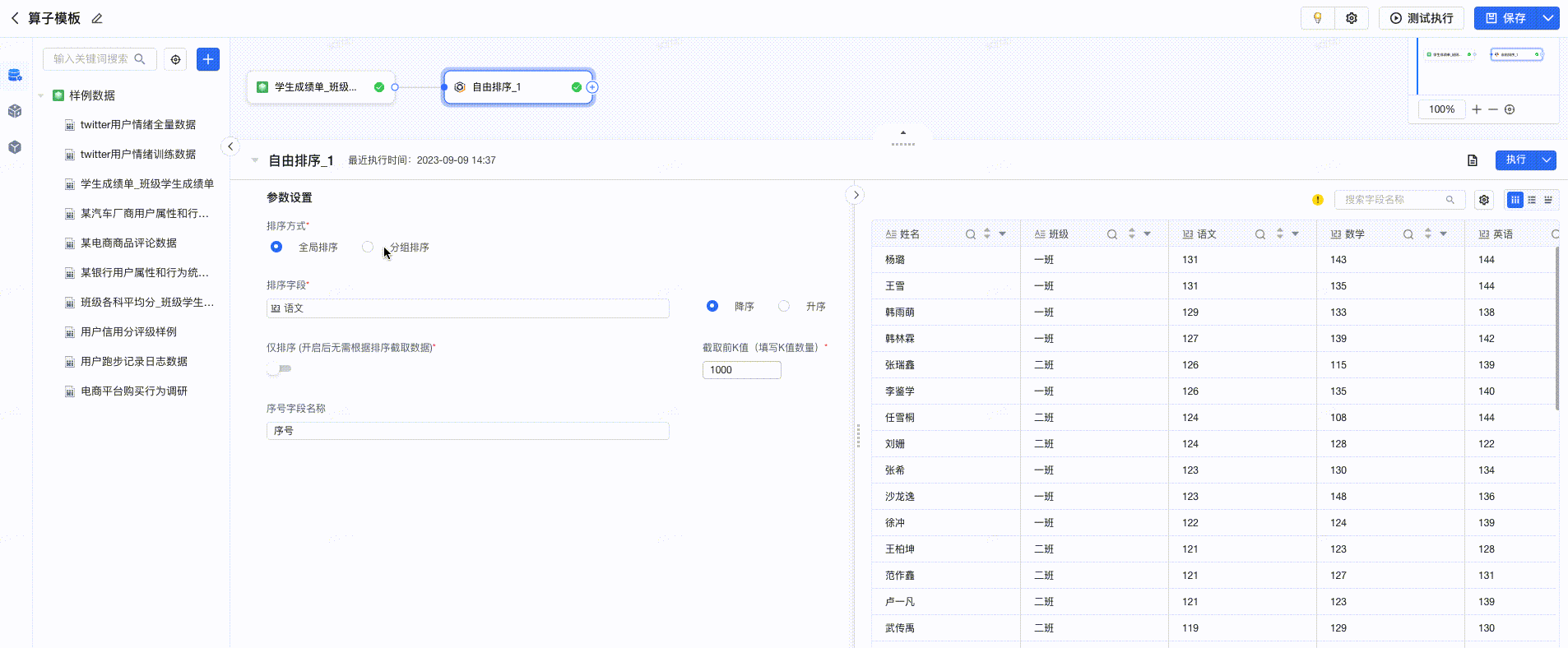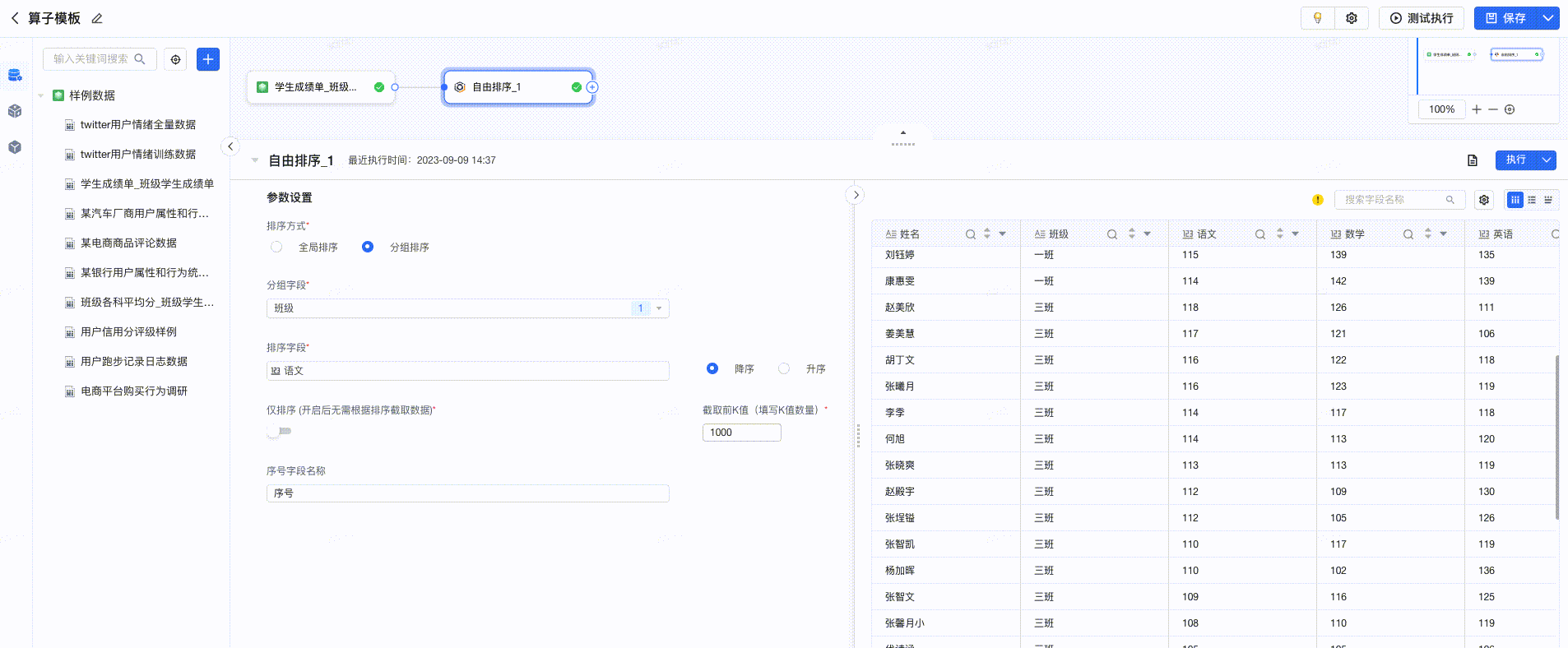
配置项说明如下:
- 排序方式: 支持全局排序和分组排序两种方式。全局排序是根据排序字段对全部数据进行排序,分组排序则是根据分组字段设置不同组合方式,对每种组合方式内的数据进行排序。
- 分组字段: 设置排序的类型,即分别对每个分类下内容进行排序,如选择多个字段,则是根据多个字段的组合结果定义不同的类进行排序。
- 排序字段: 排序的判断条件,如按照分数排序,则分数为排序字段,支持降序/升序两种排序方式:
- 降序,即根据排序字段的结果倒序排列
- 升序,即根据排序字段的结果顺序排序
- 若开启【仅排序】按钮,则只需要根据排序方式和排序字段对数据进行排序标记,标记出具体的序号值。
- 序号字段名称: 根据排序方式,将具体的序号存储下来,可定义该序号的具体函数,如分数排名字段。
注意
- K值数量:默认1000,仅支持整数,最低不能小于1;
- 分组字段和排序字段不可重复;
- 分组字段以及排序字段都是仅支持数值型(整数、浮点数等)、字符串型、日期型、时间型、时间戳型,数组及map等特殊类型不支持。
2.13 去重
用于删除数据集中的重复行 字段设置 待去重字段:根据选择的字段去重,如果被选择的字段行数有重复,随机保留一行 如果复选多个字段,则需多个字段均相同才会删除该条数据。 处理示例 以下图为例,上游数据包含6条数据,其中有三条数据的姓名为‘张三’,有两条数据用户的姓名和电话完全相同;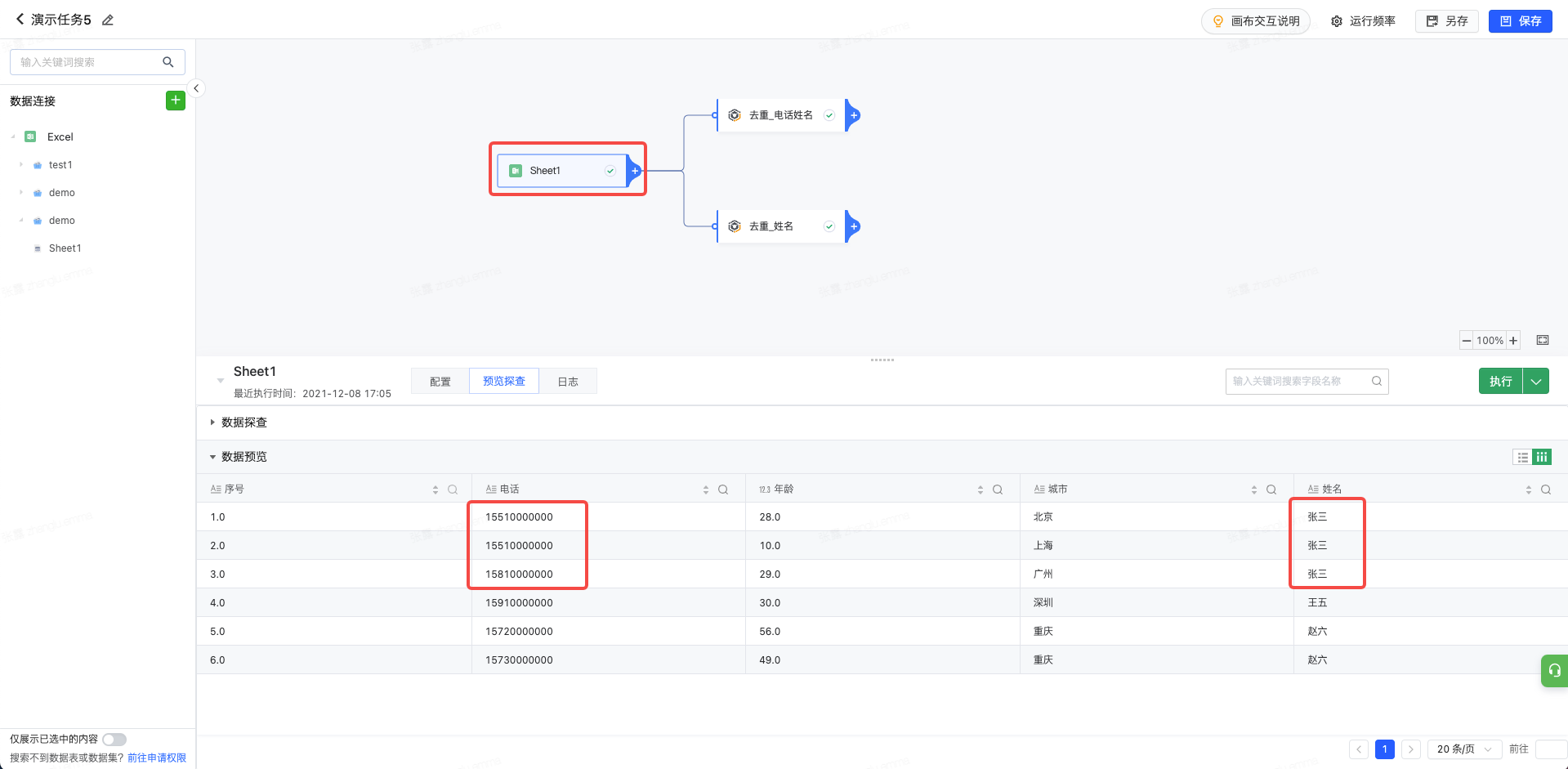
当我们添加去重算子,并添加待去重字段为姓名与电话并执行当前节点;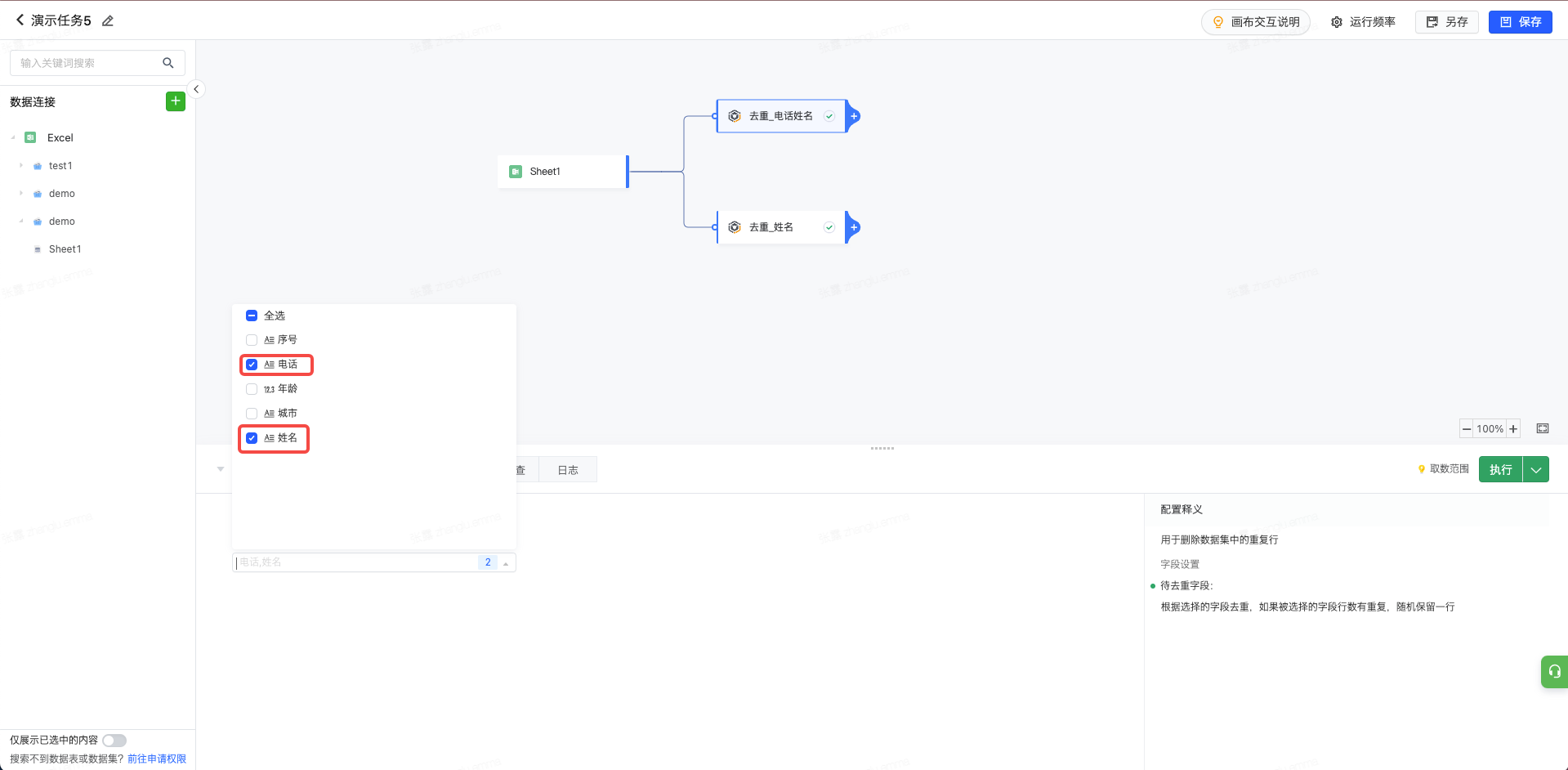
我们可以发现去重后的数据共包含5条,其中序号为2的数据因为与1的姓名和电话均相同被删除。具体如下: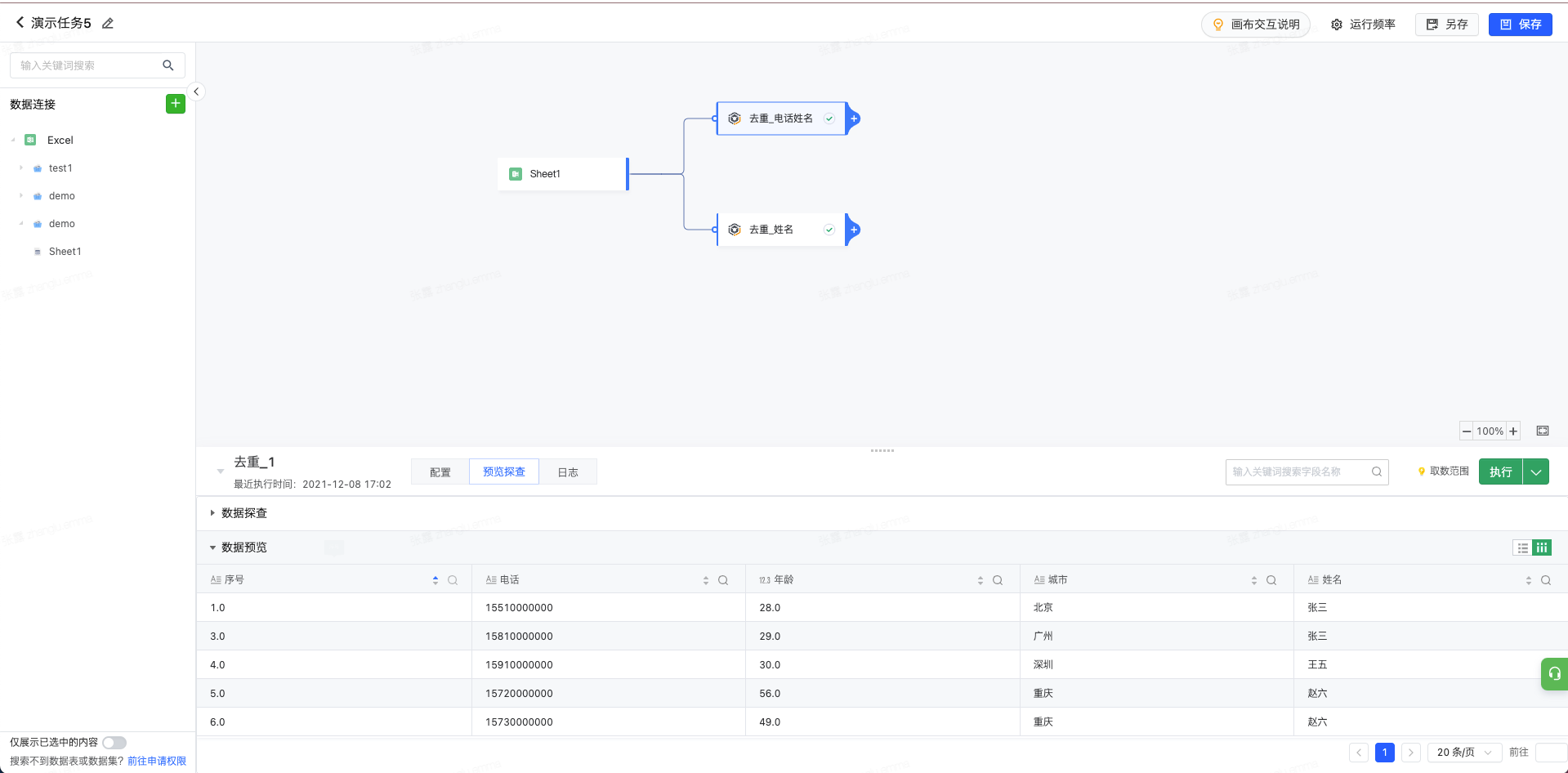
当我们添加去重算子,并添加待去重字段为姓名与电话并执行当前节点;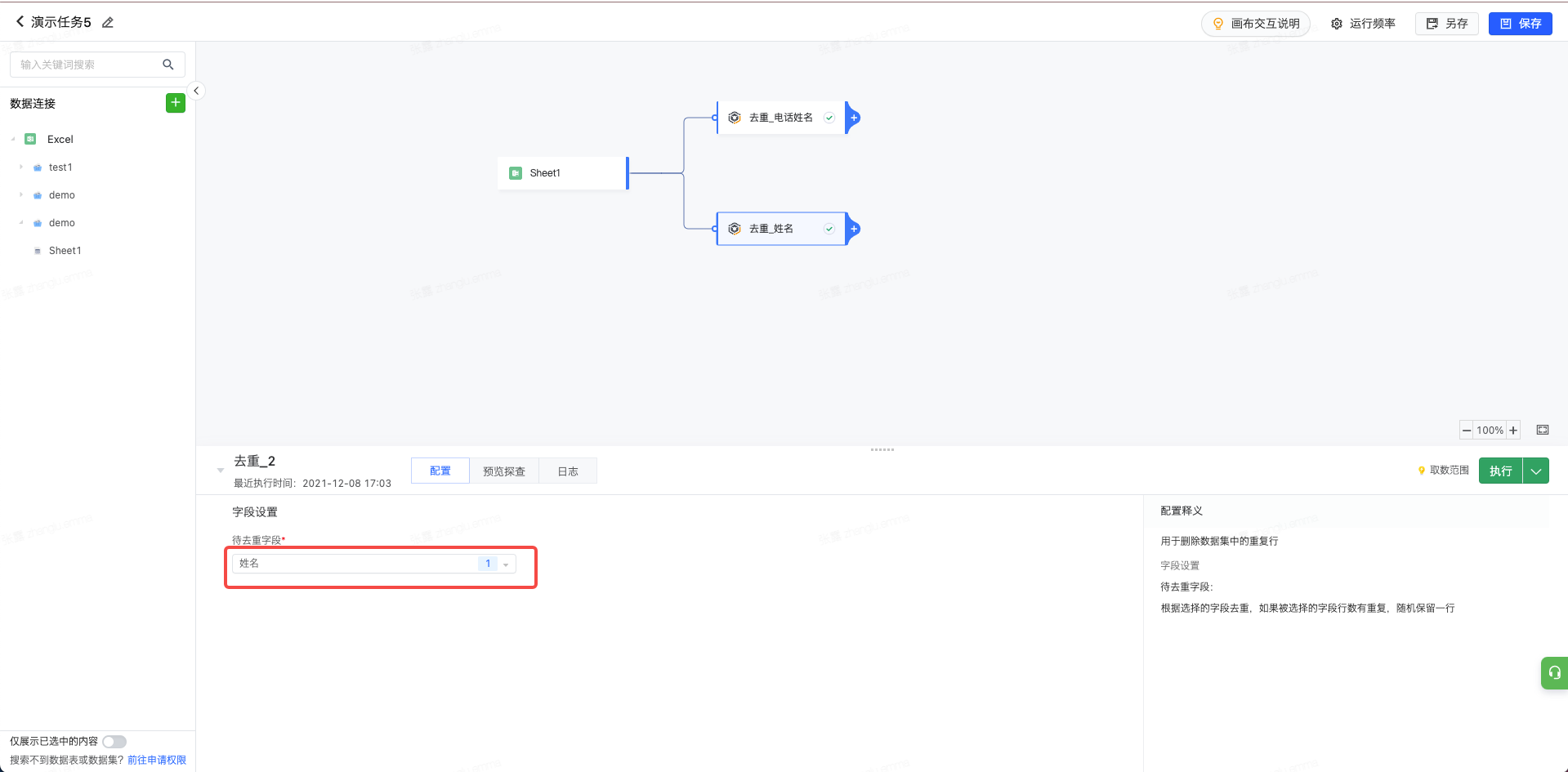
我们可以发现去重后的数据共包含3条,其中序号为2,3的数据因为与1的姓名均相同被删除。具体如下: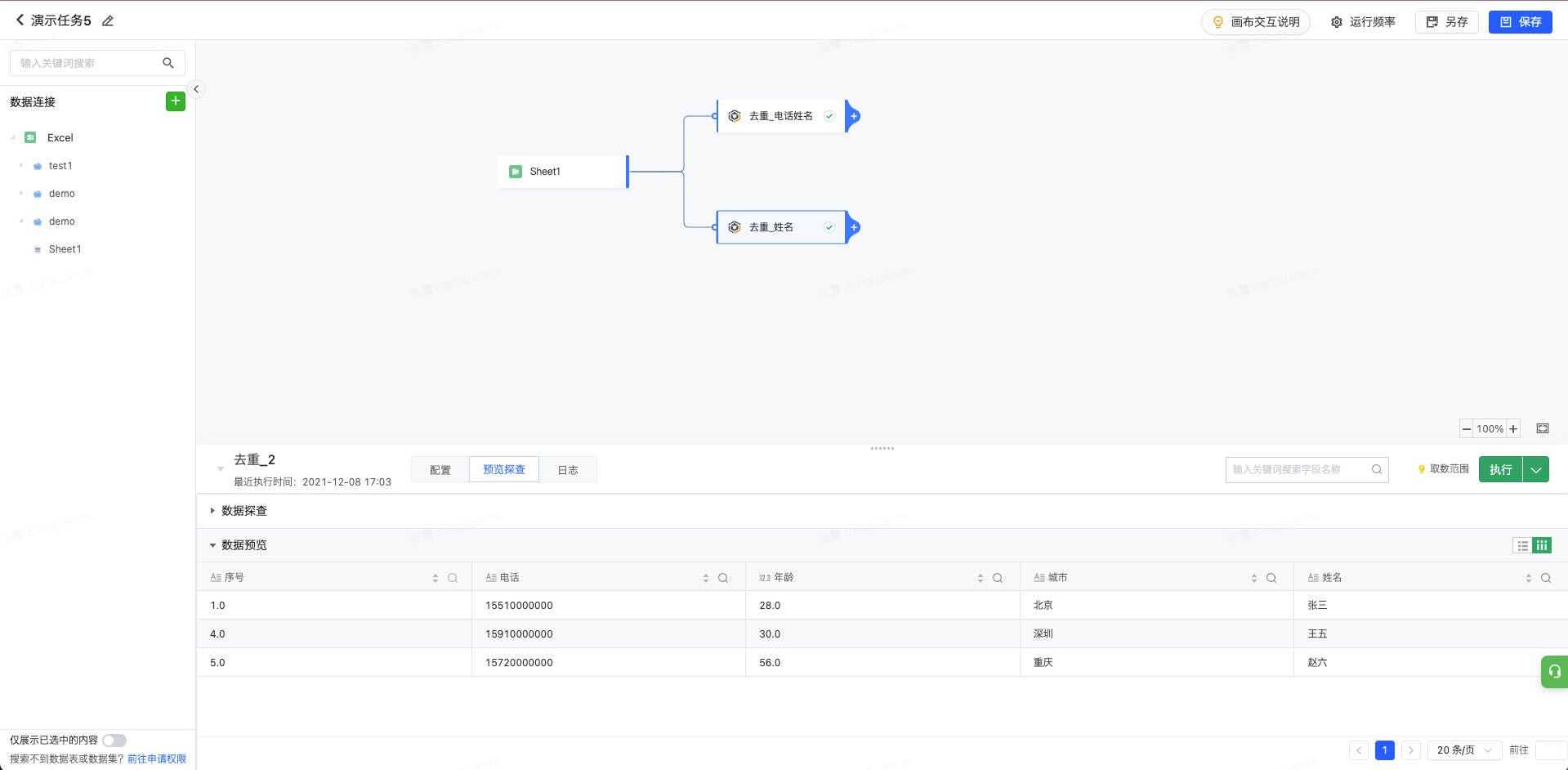
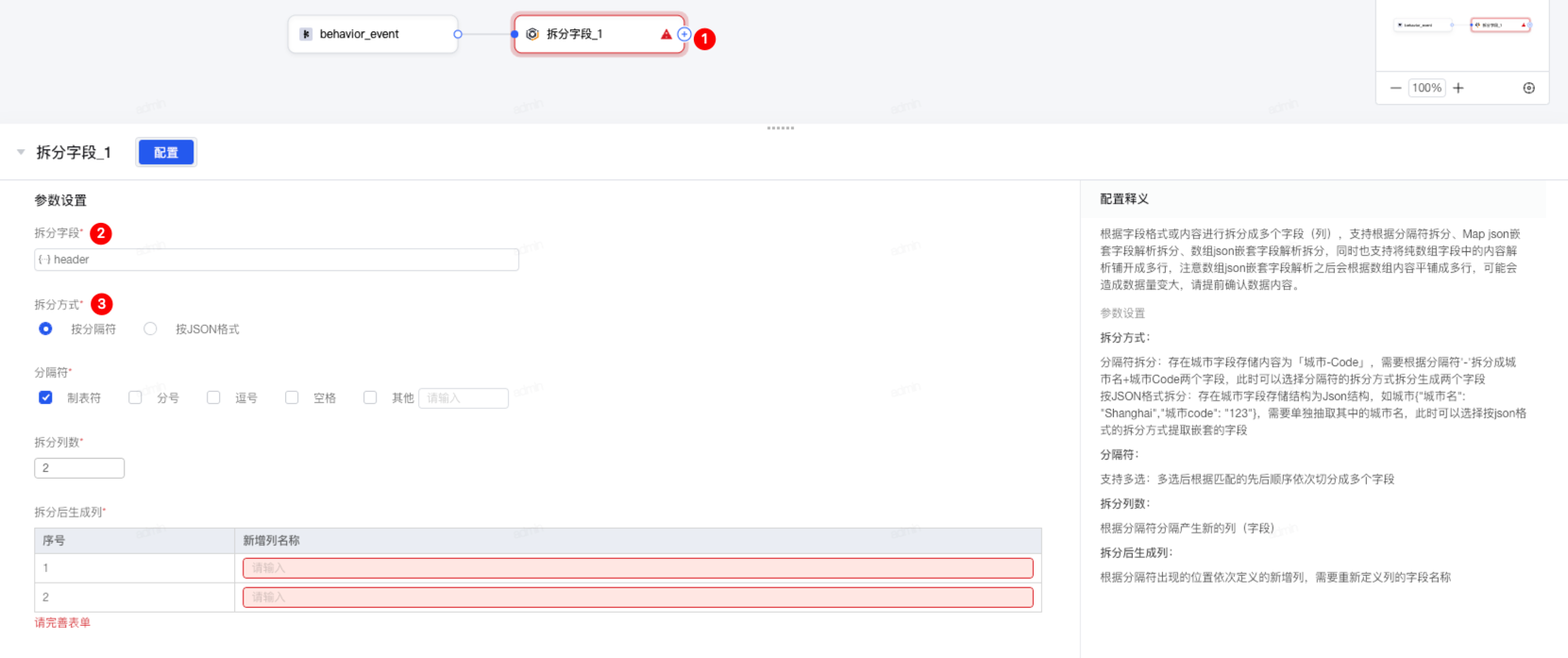
2.14 拆分字段
1.新建「拆分字段」算子并选中进行编辑。
2.选择需要拆分的字段类型。
3.支持 按分隔符 及 按JSON格式 两种方式进行拆分。
4.当选中 按分隔符 时:
- 分隔符支持多选:多选后根据匹配的先后顺序依次切分成多个字段。
- 最多拆分为10列。
- 根据分隔符出现的位置依次定义的新增列,需要重新定义列的字段名称。
5.当选中 按JSON格式 时,Json格式包含以下三种:
- Map({key:value}):如城市{"城市名": "Shanghai","城市code": "123"}
- 数组[{key:value}]:如城市[{"城市名": "Shanghai"},{"城市名": "Beijing"}]
- 数组[value]:如城市["上海",“北京”] *
注意
数组类型字段拆分会根据内容平铺成多行,数据量可能会增加
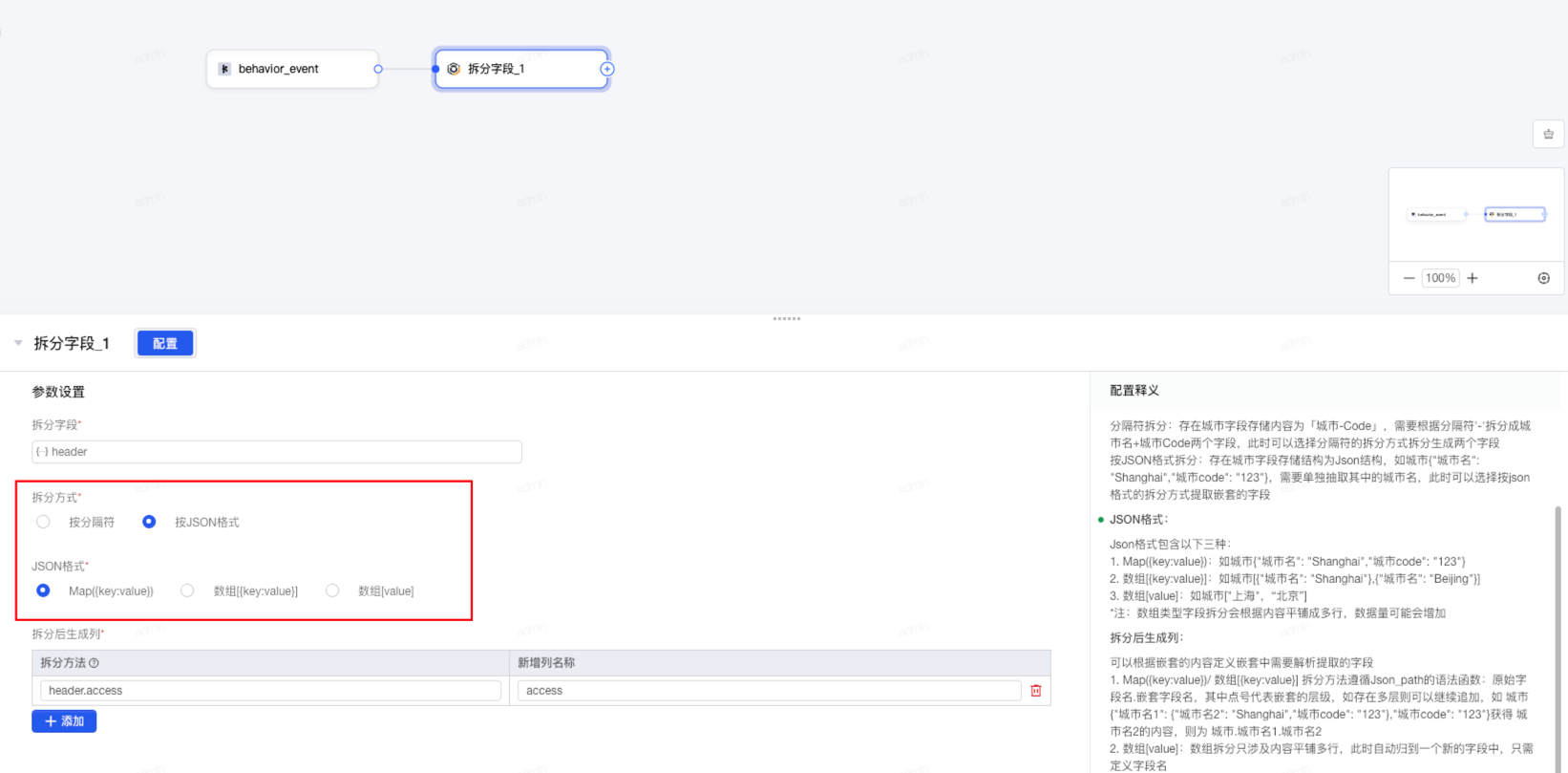
定义拆分后生成列的名称: 可以根据嵌套的内容定义嵌套中需要解析提取的字段
- Map({key:value})/ 数组[{key:value}] 拆分方法遵循Json_path的语法函数:原始字段名.嵌套字段名,其中点号代表嵌套的层级,如存在多层则可以继续追加,如 城市{"城市名1": {"城市名2": "Shanghai","城市code": "123"},"城市code": "123"}获得 城市名2的内容,则为 城市.城市名1.城市名2
- 数组[value]:数组拆分只涉及内容平铺多行,此时自动归到一个新的字段中,只需定义字段名
2.15 ID-Mapping算子
根据所选择的ID-Mapping类型,通过ID-Mapping服务转换查询到已经存在的OneID:
- 根据输入的ID类型,查询该ID对应的OneID,如果ID中包含纯新ID可能会被过滤
- 根据输入的ID类型转换成另外一个ID,此时可能因为数据映射关系导致数据量增加,请根据需要选用,如通过手机号查询到设备号,手机号: 设备号为1:N,此时原来1行数据可能变成多行数据
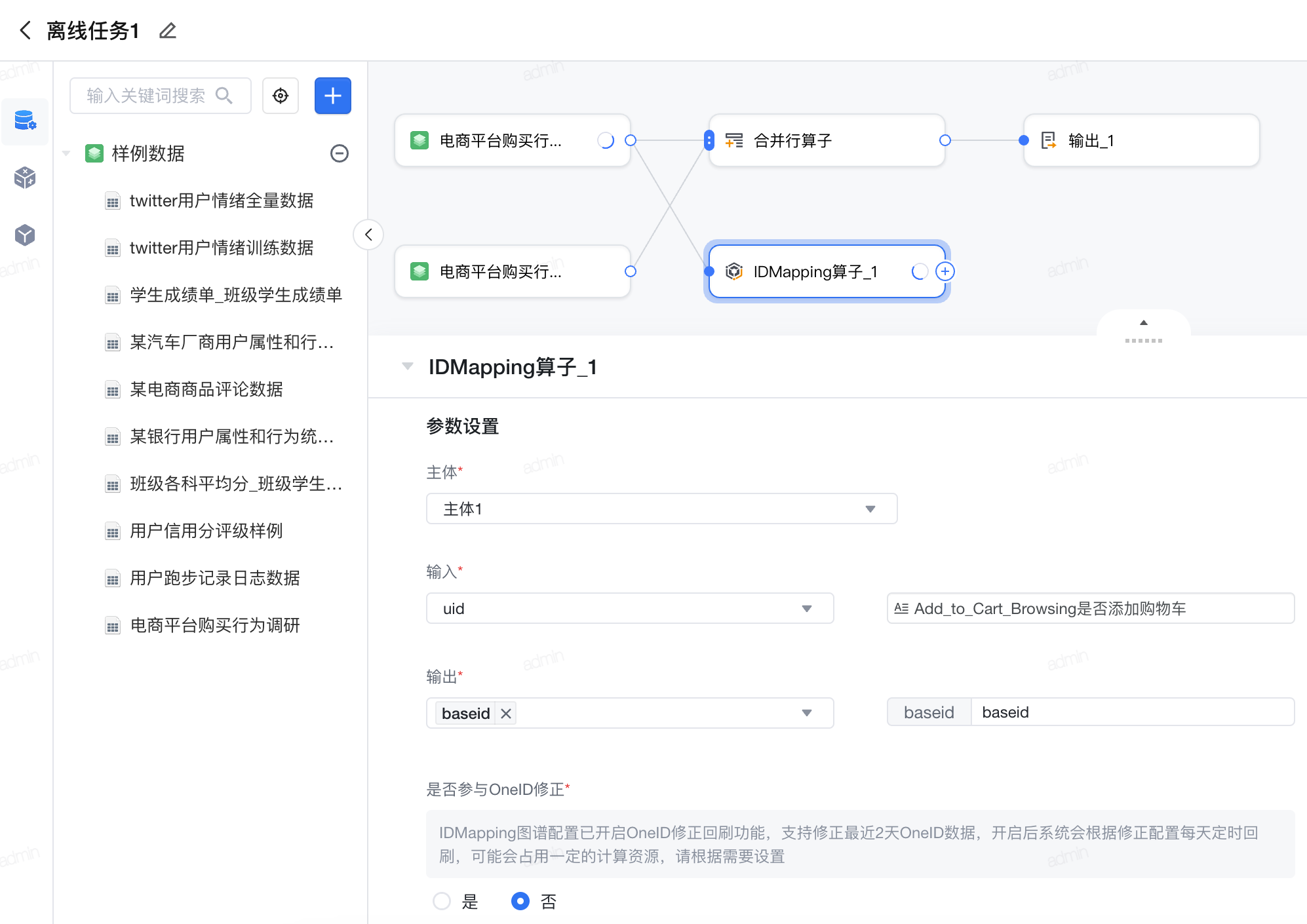
参数设置说明如下:
- 主体: CDP中画像主体,即ID-Mapping OneID的目标对象
- 输入: 选择输入ID类型及其输入字段,是ID间转换的数据输入条件
- 输出: 选择输出ID类型并定义字段名,用于保存交换获得的OneID或其他ID数据(举例: 如手机号转换OneID,此时手机号为输入,OneID为输出)
- 是否参与OneID修正: IDMapping图谱配置已开启OneID修正回刷功能,支持修正最近2天OneID数据,开启后系统会根据修正配置每天定时回刷,可能会占用一定的计算资源,请根据需要设置。
2.16 IDM多主体转换关系
支将实时的关系数据存储保存下来并构建完整的实时转换链路,即实时将主体1转换为主体2,如人访问门店的行为记录构建访问关系,可以基于人的手机号ID与门店ID构建【到访】关系,在人和门店两个主体相互转换时可以基于【到访】关系进行营销活动,如对N个门店的到访用户发短信进行召回。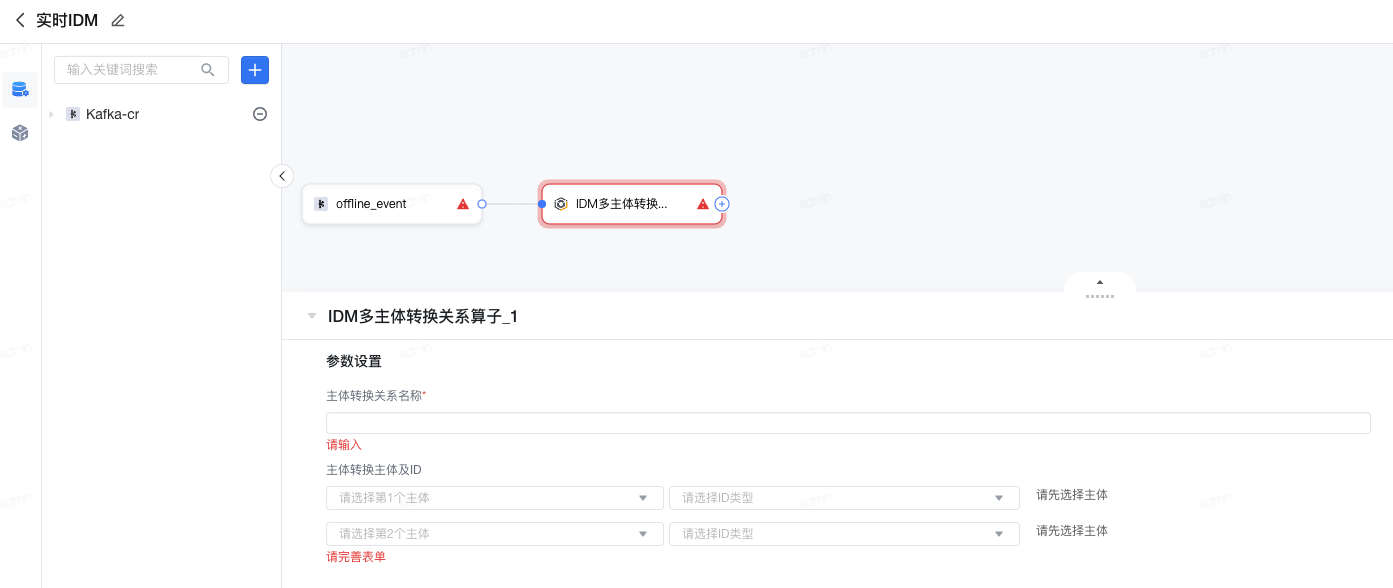
配置说明如下:
- 主体转换关系名称:填写描述,是帮助下游在使用主体转换时可理解的业务定义,如【到访】/【购买】关系等。
- 主体转换主体及ID:选择构建转换关系的两个主体及主体下游联系的ID,如【到访】关系里面的人-手机号和门店-门店ID。
注意
- 实时主体转换不会参与实时生成OneID,即参与转换的ID里面如存在纯新的ID(ID全量表里不包含),建议在当前节点前增加【实时IDMapping】算子进行生成OneID
- 该算子配置在保存后且启动任务后生效,相关配置信息在IDM图谱配置内也可以看到,同样当前算子删除也等同于该关系删除,保存后生效。
- 实时产生的关系会存储在系统关系表内,会保留所有关系数据,请根据需要转换逻辑
2.17 加解密
指根据特定的加密或解密算法,将数据源中的指定字段数据进行加密或解密的数据安全管理功能。
注意
系统层面不管理密钥,如自动生成、手工输入秘钥请自行妥善管理
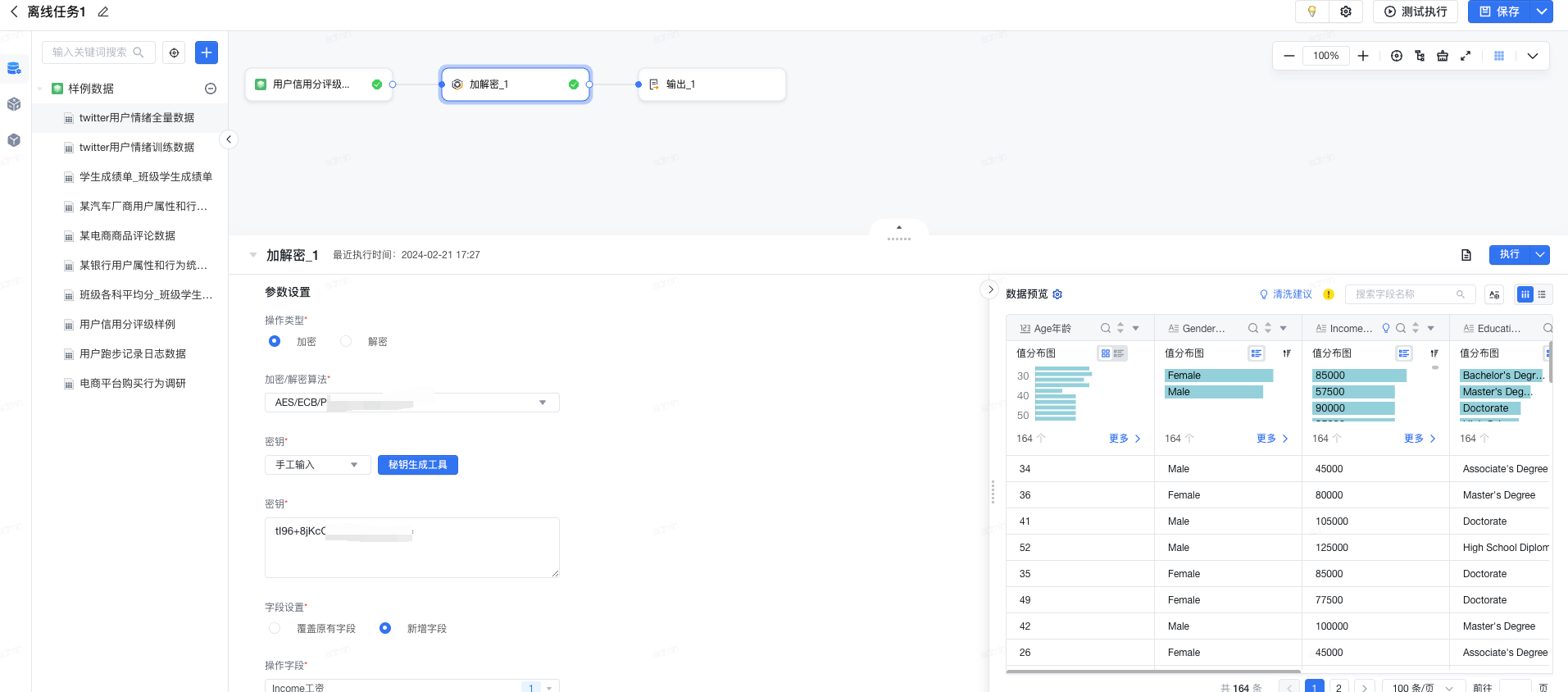
- 操作类型: 需要对字段进行的操作类型,即对数据加密还是解密操作。
- 加密/解密算法: 选择数据加密或解密的算法类型,加密和解密的算法存在差异早,具体可分为对称加解密(如AES/DES)和非对称加解密 (RSA),其中非对称加密存在公钥和私钥,需同时输入方可加密或解密,请根据需要选择不同算法。
- 密钥: 输入或选择加密或解密的密钥,用于作为加密或解密的密码使用。
- 手工输入: 支持自定义密钥内容,或者通过密钥生成工具直接生成。
- 字段设置: 选择需要加密或解密的字段,并根据需要选择加密或解密后的的数据内容的存储方式。
- 覆盖原有字段: 加密或解密的原有字段名称不变,数据内容根据操作多类型覆盖更新成加密后的密文或解密好的明文
- 新增字段: 原有字段名称及数据内容不变,根据操作类型新地加密或解密的字段,字段名称可自定义。
2.18 采样
采样从全部数据中选择部分数据进行分析,以发掘适用于更大数据集的有用信息。常见的采样分三种:随机采样,分层采样,下采样。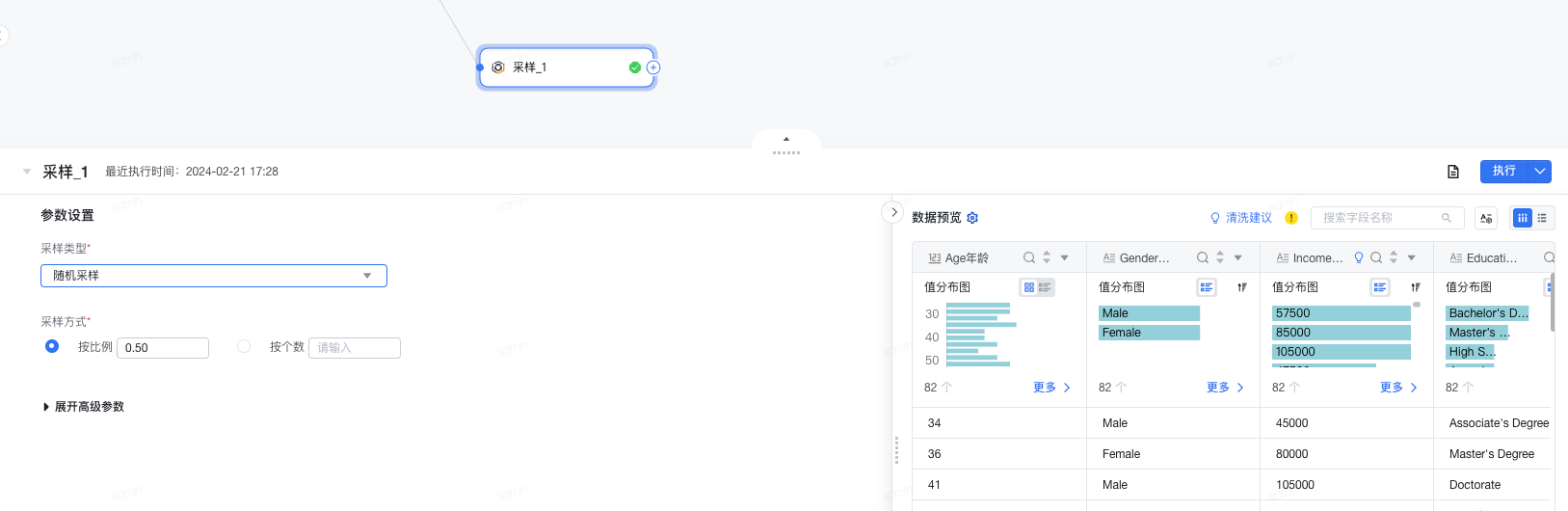
- 采样类型: 目前支持三种采样类型,分别为随机采样,分层采样和下采样
- 随机采样: 按照给定的比例或者数目,对输入进行随机采样
- 分层采样: 将输入数据分成不同的组,对每组分别进行随机采样
- 下采样: 又称欠采样,主要解决数据不平衡问题,减少数值过多部分的数据量
说明
应用场景举例:
客户调研时获取了海量的行为数据,但是在实际分析时并不需要那么多数据,因此希望对数据进行抽样分析,未保证抽样结果的均匀性,希望根据不同年龄分别抽取一定比例的数据。因此可通过该算子进行分类抽样,如基于样例数据根据「年龄」设置不同年龄提取50%的数据进行采样分析,输出结果将只剩余50%的数据并应用于后续的算子中。