本文主要介绍节点发生故障时,业务负载如何进行容灾和迁移的方案。
背景信息
Kubernetes 节点承载着用户众多线上业务的运行。容器服务推荐业务负载采用多副本、多节点打散部署的方式,避免单节点故障时,Pod 短时间无法完成迁移而造成业务整体不可用的情况。
多副本、多节点打散部署的示例 YAML 如下所示,更多相关说明,请参见 Kubernetes 官方文档。
apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment spec: selector: matchLabels: app: nginx replicas: 3 # 采用多副本部署 template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.14.2 ports: - containerPort: 80 topologySpreadConstraints: # 控制 Pod 在集群的拓扑上如何分布。 - maxSkew: 1 # 控制 Pod 的最大偏差数量。设置为 1,表示任意两个 Node 中,属于 app=nginx 的 Pod 数量之差不可以超过 1。 topologyKey: "kubernetes.io/hostname" # 拓扑域,当前配置表示节点级别分布;topology.kubernetes.io/zone 表示区域级别分布。 whenUnsatisfiable: ScheduleAnyway # 设置当 Pod 的分布无法满足约束时的行为,可取值:DoNotSchedule(不调度)或 ScheduleAnyway(尽管约束得不到满足,但还是会尽力调度)。 labelSelector: # 表示 Pod 的 Label 匹配。 matchLabels: app: nginx
但实际业务中因种种原因,可能遇到节点故障导后 Pod 无法迁移导致业务受损的情况,本文围绕节点故障场景,提供多种负载(尤其是 StatefulSet 类型负载)的容灾迁移方案,帮助用户进行快速止损。
Kubernetes 状态机变化情况
在节点发生故障时(人工介入恢复前),不同 Kubernetes 资源有不同的表现。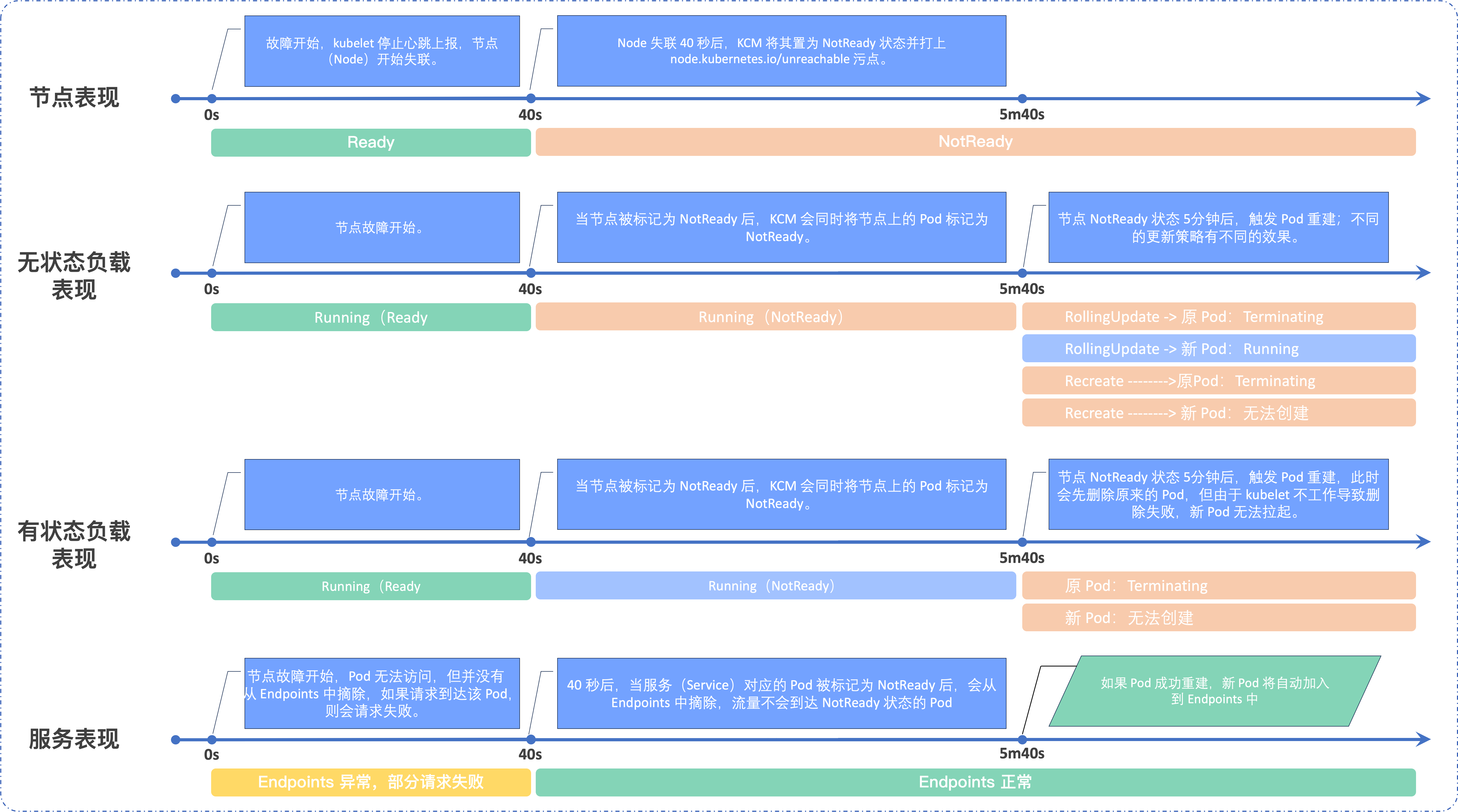
节点表现
- 节点故障后,kubelet 无法进行心跳上报状态,节点开始失联。
- 节点失联 40 秒后,会被 kube-controller-manager(以下称 KCM)置为 NotReady 状态,同时打上
node.kubernetes.io.unreachable污点。说明
节点状态的时长由如下 KCM 参数控制:
- node-monitor-period:节点控制器(Node Controller) 检查每个节点状态的时间间隔,默认 5 秒。
- node-monitor-grace-period:节点控制器判断节点故障的时间窗口。默认 40 秒,即 40 秒没有收到节点消息则判断为节点发生故障。
无状态负载表现
- 当节点被标记为 NotReady 后,KCM 会同时将节点上的 Pod 标记为 NotReady。
- 当节点 NotReady 状态持续 5 分钟后,触发 KCM 对 Pod 的重建。
- Pod 的重建策略为 RollingUpdate(滚动更新)时:即先创建新的 Pod,再删除原 NotReady 状态的 Pod(以下简称原 Pod)。但由于节点处于故障中,kubelet 无法删除节点上的原 Pod,因此原 Pod 将无限期卡在 Terminating 状态(除非节点恢复或者强制删除该 Pod)。
- Pod 的重建策略为 ReCreate 时:即先删除原 Pod 再创建新 Pod,由于原 Pod 无法删除,因此新 Pod 也无法创建。
说明
节点状态的时长由 kube-apiserver 参数控制:
- default-not-ready-toleration-seconds:对污点
NotReady:NoExecute的容忍时长,单位为秒,默认 300 秒。默认情况下这一容忍度会被添加到尚未具有此容忍度的每个 Pod 中。 - default-unreachable-toleration-seconds:对污点
Unreachable:NoExecute的容忍时长,单位为秒,默认 300 秒。默认情况下这一容忍度会被添加到尚未具有此容忍度的每个 Pod 中。
有状态负载表现
- 当节点被标记为 NotReady 后,KCM 会同时将节点上的 Pod 标记为 NotReady。
- 当节点 NotReady 状态持续 5 分钟后,触发 KCM 对 Pod 的重建。对于有状态负载,会先删除原 Pod 再新建 Pod,但由于节点故障导致 kubelet 无法删除节点上的原 Pod,因此原 Pod 会卡在 Terminating 状态,新 Pod 也无法拉起。
说明
如果 Pod 绑定了存储卷声明(PVC),有状态负载的迁移会伴随着存储卷(PV)的释放和重绑动作。节点故障后,关联的存储卷也无法与节点解绑。
服务(Service)表现
- 当节点故障后,节点上的 Pod 可能无法访问,如果 Pod 关联了 Service,那么 Pod 短时间内不会从 Endpoints 中摘除。当请求通过 Service 路由到该 Pod 时,会导致请求失败。
- 当节点 NotReady 状态持续 40 秒后,随着 Pod 被标记为 NotReady,对应 Service 相关 Endpoints 中的
subsets.notReadyAddresses参数下会增加 NotReady 的 Pod 信息,此时 Service 流量将不会到达 NotReady 状态的 Pod。
人工介入恢复步骤
使用限制
人工介入恢复前,还需要注意如下使用限制:
- 当前集群中除了故障节点外,还需要有其他可用的节点,并且能足够容纳待迁移的负载。
- 人工介入操作时,不能操作虚拟节点(Virtual Node),否则会导致 VCI Pod 被驱逐。如必须操作 Virtual Node,请 提交工单 获取专业的技术支持。
- 节点故障场景大致可分为 节点体面关闭、节点非体面关闭、 kubelet 程序异常 三类。其中 节点体面关闭 无需人工介入操作,本文主要描述其余两个场景的节点故障负载迁移方案:
- 节点体面关闭:开启 节点体面关闭功能,在系统关闭时 kubelet 会尝试监测该事件并优雅关闭节点上运行的 Pod。该场景无需人为介入即可自动完成负载迁移。该功能的开启需要满足一定的条件,详细说明,请参见 Kubernetes 文档。
- 节点非体面关闭:节点的关闭操作无法被 kubelet 检测到,例如节点发生 crash 故障,无法触发 kubelet 优雅退出流程,或者没有启用 kubelet 体面关闭功能,节点的关闭就会出现上述的 Kubernetes 状态机变化情况。
- Kubelet 程序异常: 节点与 Master 失联,但节点上的负载可能处于正常状态。该场景建议先尝试重启 kubelet 或者尝试恢复节点,如果不能恢复建议从 VKE 控制台中移除节点(即从集群中移除节点),避免节点上的负载在脱离 Kubernetes 管控的情况下,对业务造成干扰(例如 Dubbo 等有独立微服务注册发现的 RPC 框架的业务)。
无状态负载
- 确保负载的更新策略为
RollingUpdate。strategy: type: RollingUpdate rollingUpdate: maxUnavailable: 25% maxSurge: 25% - 手动执行
rollout命令来完成无状态负载 下 Pod 的快速重建。kubectl rollout restart deployment/nginx预期返回结果如下:说明
deployment/nginx为无状态负载名称/其下 Pod 名称,请替换为您实际的负载名称。deployment.apps/nginx restarted
有状态负载
Kubernetes v1.26 之前
通过强制删除 Pod,等待独占资源解绑并释放来完成负载迁移。具体步骤如下:
- 强制删除故障节点上的原 Pod,使得独占资源与原 Pod 解绑。
说明
独占资源没有与原 Pod 解绑时,新 Pod 会卡在 Creating 状态。
预期返回结果如下:kubectl delete pod nginx-1 --forceWarning: Immediate deletion does not wait for confirmation that the running resource has been terminated. The resource may continue to run on the cluster indefinitely. pod "nginx-1" force deleted - 等待独占资源释放( 若有独占资源)。
- Pod 关联的存储卷:6 分钟后,会触发 KCM 与 PVC 自动解绑逻辑,csi-controller 会 watch 该操作后调用云服务器(ECS)的 DetachVolume 接口做云盘的解绑,完成资源释放。
- Pod 固定 IP(Trunk ENI):立即释放。
- 查看 Pod 信息。
预期返回结果如下:kubectl get pod -o wideNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-0 1/1 Running 0 100m 192.168.0.108 192.168.0.12 <none> <none> nginx-1 0/1 ContainerCreating 0 8s <none> 192.168.0.13 <none> <none>
- 资源释放后,新 Pod 绑定资源成功且状态变为 Running,完成负载迁移。
预期返回结果如下:kubectl get pod -o wideNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-1 1/1 Running 0 6m 192.168.0.63 192.168.0.13 <none> <none> nginx-0 1/1 Running 0 114m 192.168.0.108 192.168.0.12 <none> <none>
Kubernetes v1.26 及之后
通过为故障节点打上指定污点,触发 NodeOutOfServiceVolumeDetach 特性门控来快速完成负载迁移。具体步骤如下:
- 确保目标节点对应的 ECS 实例处于 关闭 或 断电 等状态,且目标节点不是虚拟节点。
说明
节点状态不可以为 运行中 或节点对应的 ECS 实例状态不可以为 重启中,否则会导致节点出现 mount 挂载残留、Pod 读写异常等一系列不可预期的行为。
- 确保要迁移的负载(Pod)没有容忍
node.kubernetes.io/out-of-service污点。kubectl get statefulset <sts-name> -o jsonpath="{.spec.template.spec.tolerations}"预期返回结果如下,其中说明
<sts-name>为有状态负载的名称,请替换为您实际的负载名称。key的取值表示 Pod 容忍的污点(即容忍了temp这个污点 );若返回结果为空,则表示没有容忍任何污点:[{"key":"temp","effect":"NoSchedule","operator":"Exists"}] - 执行以下命令为故障节点打上污点。
kubectl taint nodes <node-name> node.kubernetes.io/out-of-service=nodeshutdown:NoExecute说明
请替换
<node-name>为您实际的故障节点名称。 - 成功打上污点后,会触发 Pod 被 KCM 删除,同时关联的独占资源被立即解绑,被删除的 Pod 很快在不同的节点恢复,完成迁移。