导航
自定义 Nginx Ingress Controller 观测最佳实践
最近更新时间:2024.06.06 14:35:17首次发布时间:2023.09.08 14:01:37
ingress 作为集群中接入层的资源对象,其稳定性与业务质量息息相关。本文为您介绍集群中自定义 Nginx Ingress Controller 的监控最佳实践。
背景
容器服务支持在集群中同时部署多套独立的 Nginx Ingress Controller 服务,各服务之间互不影响,包括:
- 系统默认 ingress-nginx:在集群组件中心中,使用 ingress-nginx 组件部署,并按照系统提示安装。详情请参见 ingress-nginx 组件。
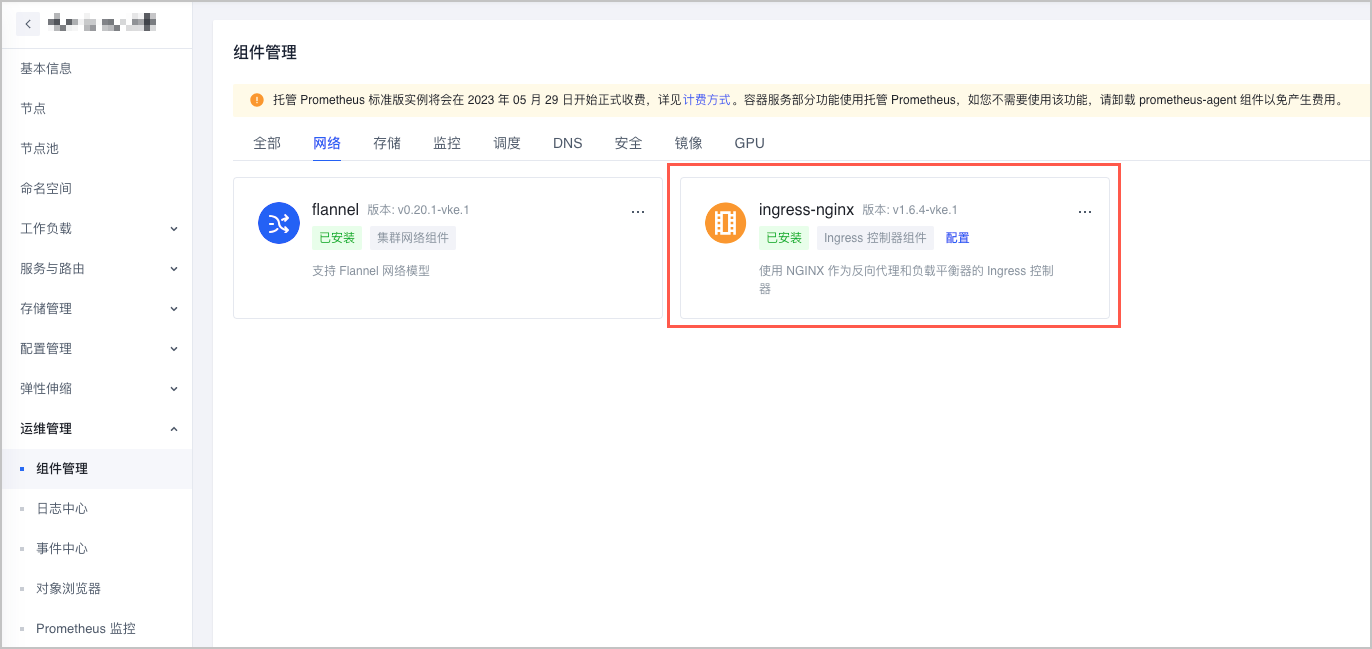
- 自定义 ingress-nginx:在容器服务 应用中心 中,使用模版部署自定义的 ingress-nginx 应用。详情请参见 部署多套 Nginx Ingress Controller。
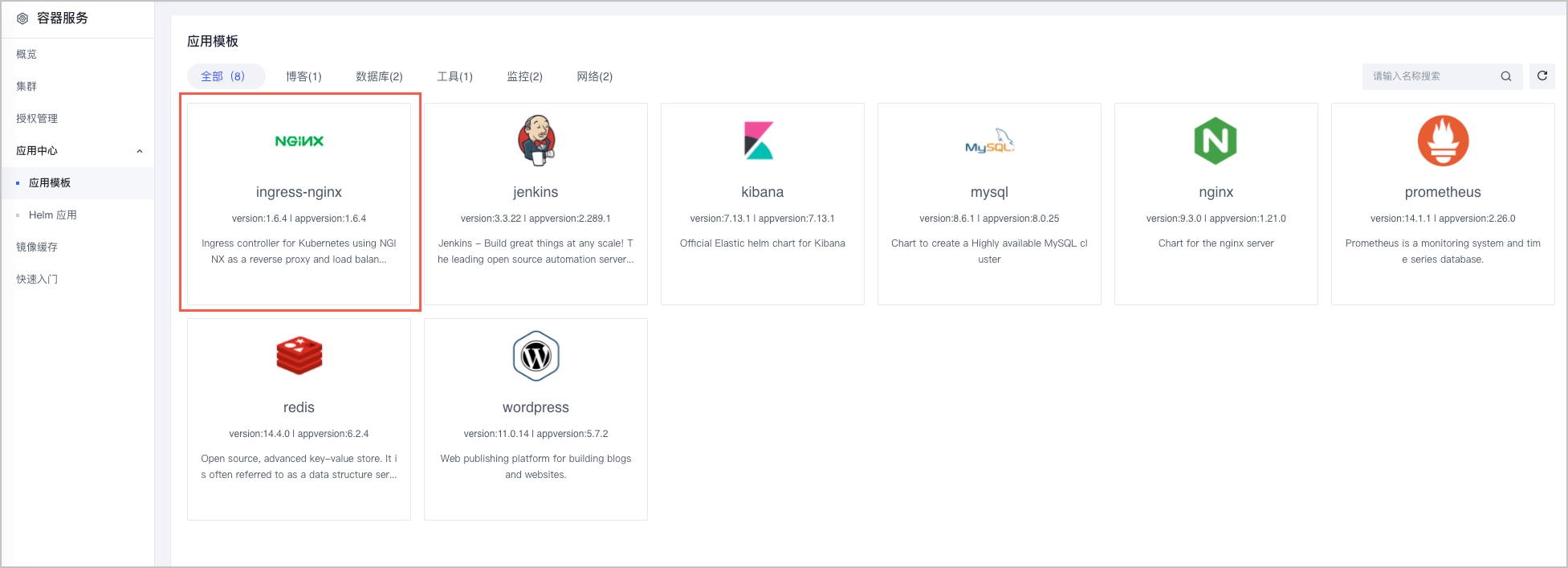
日志采集
默认情况下,自定义 Nginx Ingress Controller 的日志没有进行采集和持久化存储,需要您进行配置开启,实现自定义 Nginx Ingress Controller 日志持久化采集、存储以及查询。
说明
- 已开通 火山引擎日志服务。
- 已在日志服务中创建 日志项目 和 日志主题。详细操作,请参见 日志项目 和 日志主题。
- 已在集群中部署自定义 Nginx Ingress Controller,详情请参见 部署多套 Nginx Ingress Controller。
配置日志采集
- 登录 容器服务控制台。
- 单击左侧导航栏中的 集群。
- 在集群列表页面,单击目标集群。
- 在集群管理页面的左侧导航栏中,单击 日志中心。
- 在 日志中心 页面的 日志采集规则 页签下,单击 新建采集规则。
- 在 创建采集规则 页面,配置自定义 Nginx Ingress Controller 的日志采集。
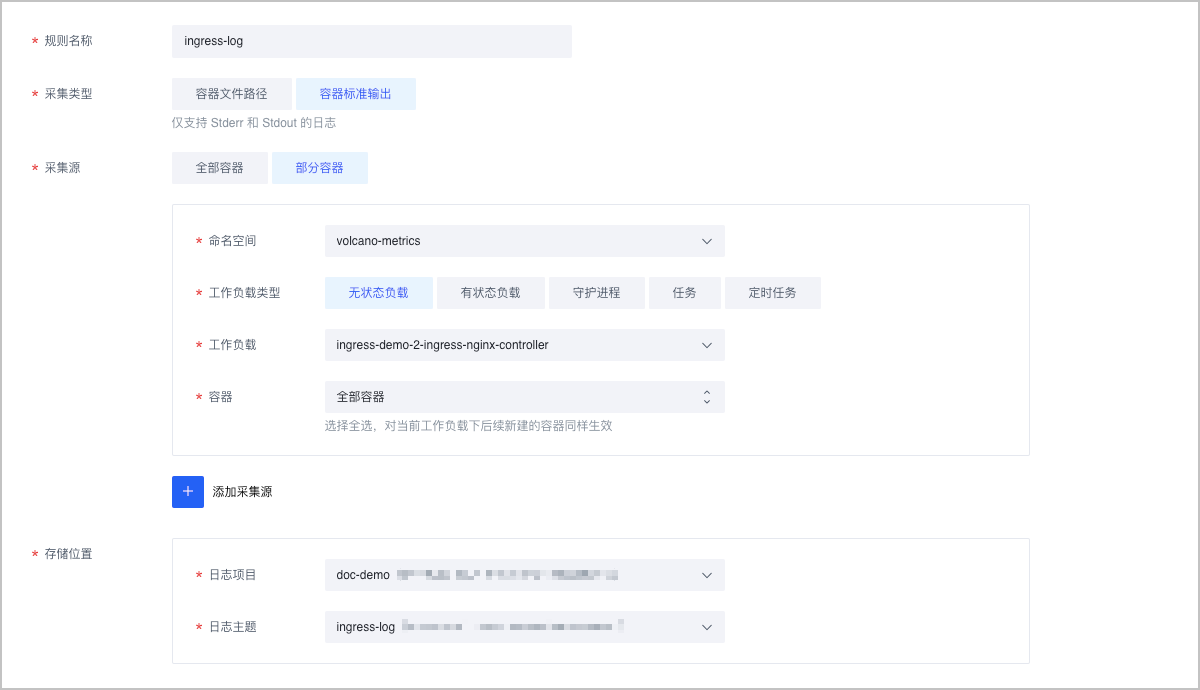
配置项 说明 规则名称 配置采集规则的名称。在同一个集群下,名称必须唯一。 采集类型 选择 容器标准输出。 采集源 选择 部分容器,并选择自定义 Nginx Ingress Controller 的工作负载和容器。 存储位置 选择日志服务中的 日志项目 和 日志主题。 说明
容器日志采集规则的详细配置方式和参数解释,请参见 采集容器日志。
- 单击 确定,完成配置。
查看日志
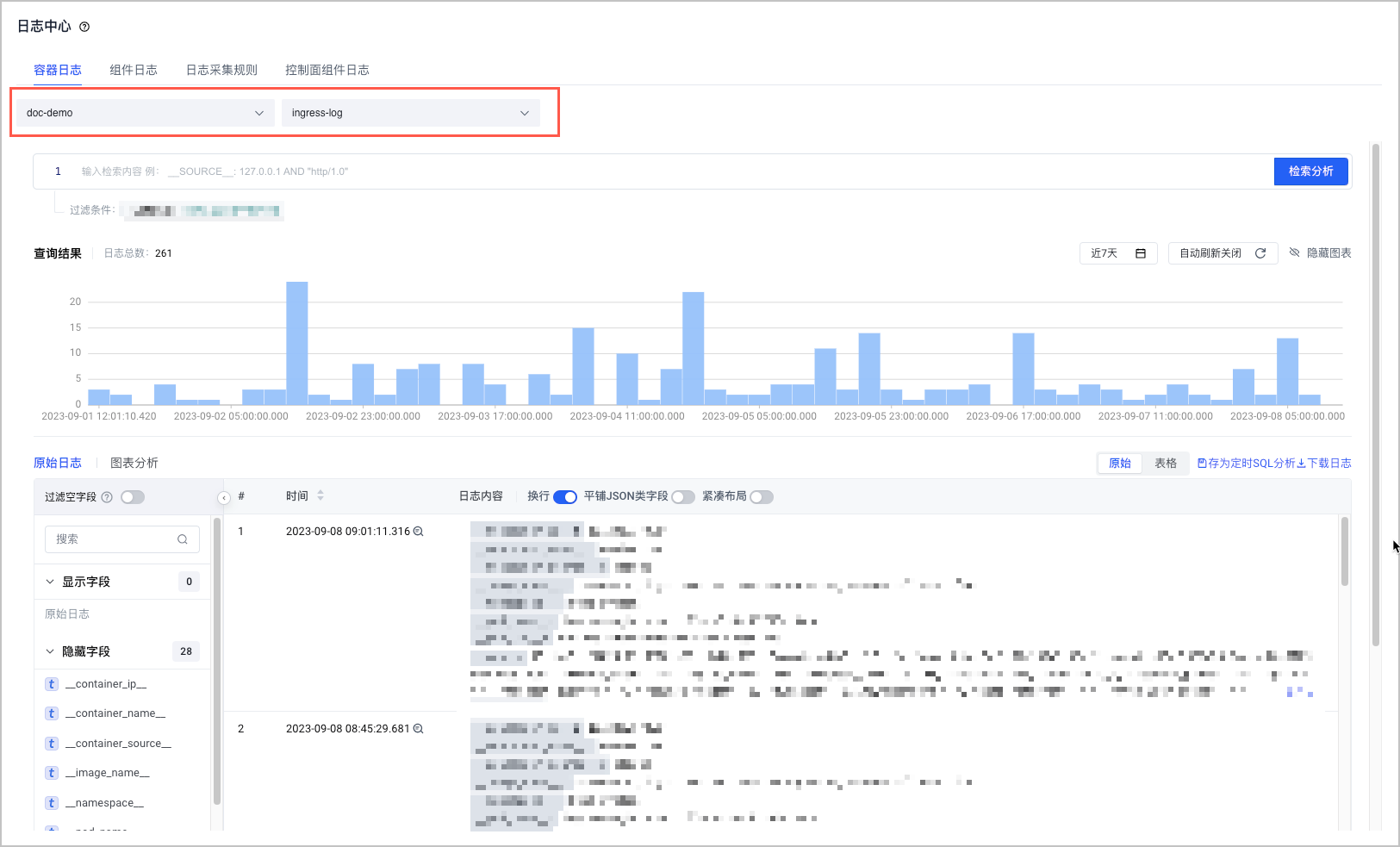
- 在集群管理页面的左侧导航栏中,单击 日志中心。
- 在 容器日志 页签中,选择正确的 日志项目 和 日志主题,即可查看自定义 Nginx Ingress Controller 的日志。
监控和告警
您可以在集群中开启云原生观测功能,实现对自定义 Nginx Ingress Controller 的监控和告警。
说明
- 已开通 托管 Prometheus。
- 已创建托管 Prometheus 工作区,详情请参见 创建工作区。
- 已在集群中部署自定义 Nginx Ingress Controller,详情请参见 部署多套 Nginx Ingress Controller。
配置指标采集
- 在集群中开启云原生观测,详情请参见 开启云原生观测。
- (可选)配置服务发现。
说明
- 当您的自定义 Nginx Ingress Controller 部署在 kube-system 命名空间时,无需配置服务发现,即可查看实例的指标和大盘。
- 当您的自定义 Nginx Ingress Controller 部署在其他命名空间时,需要配置服务发现,才能查看实例的指标和大盘。
- 在集群管理页面的左侧导航栏中,单击 服务与路由 > 服务,在 命名空间 下拉菜单中选择目标命名空间。
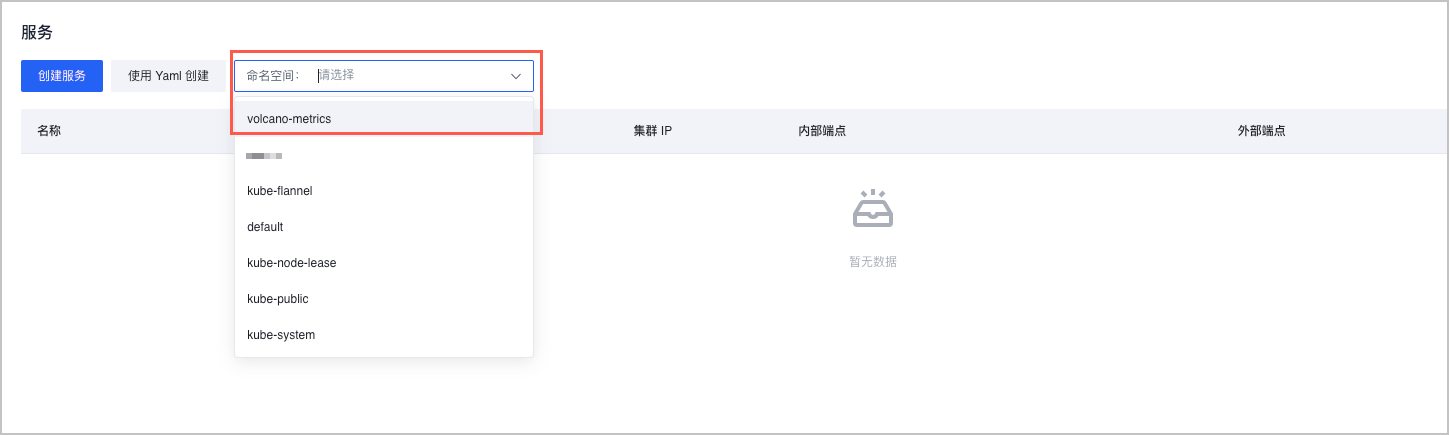
- 在服务列表中,选择名称为
*-ingress-nginx-controller-metrics的服务。其中*代表您自定义的名称。例如:在本例中的服务名称为ingress-demo-2-ingress-nginx-controller-metrics。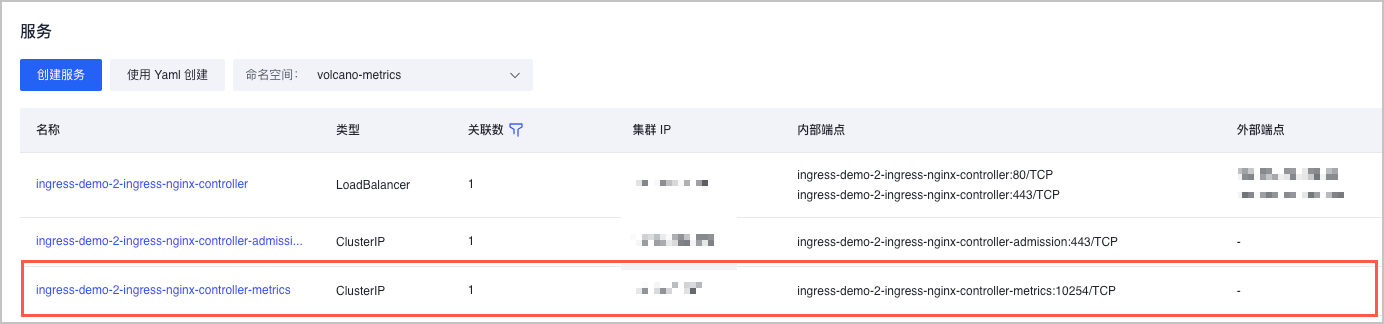
- 在 操作 栏中,选择
...> 更新,为服务配置如下 Annotation,实现服务发现。prometheus.io/scrape: "true" # 配置为 true 表示开启采集 prometheus.io/port: "10254" # 配置为采集指标暴露的端口号 prometheus.io/path: "/metrics" # 填写指标暴露的 URI 路径,一般是 /metrics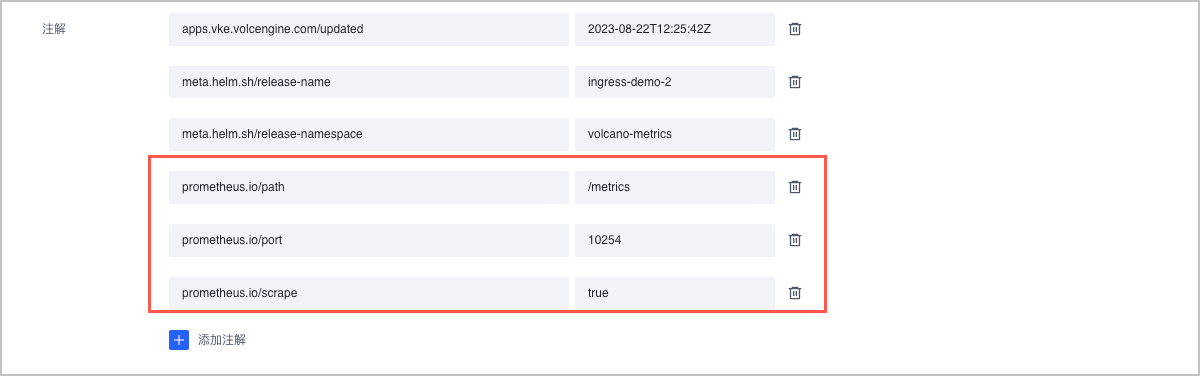
- 单击 确定,完成配置。
查看资源监控
您可以使用系统预置的监控大盘,查看自定义 Nginx Ingress Controller 的指标。详情请参见 Ingress 服务观测。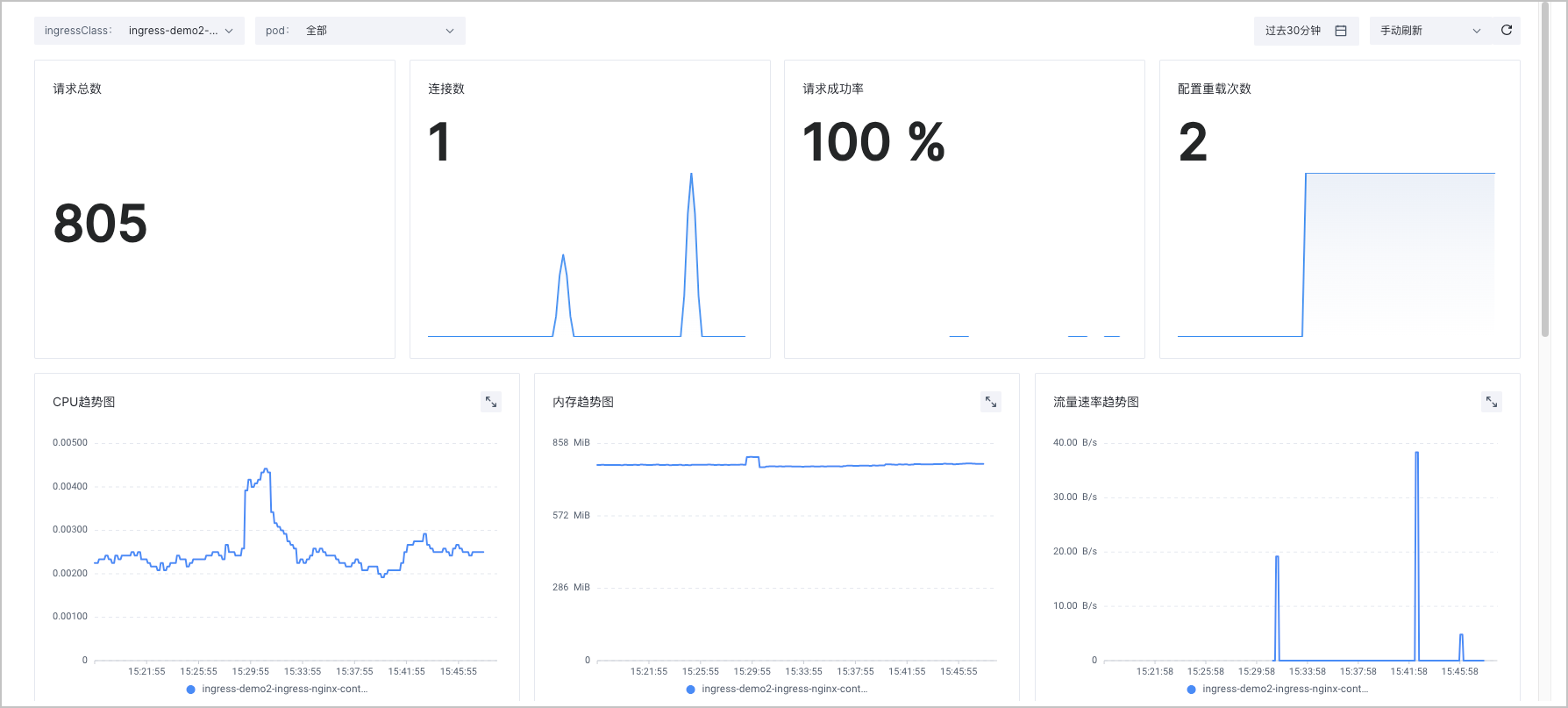
配置资源告警
托管 Prometheus 支持配置资源告警策略。您可以在控制台上使用 Ingress 服务观测 配置告警。当监控数据达到阈值,触发告警后,系统会将告警资源、故障类型、当前值、告警持续时间等详细信息发送给告警联系人。
托管 Prometheus 支持多种类型的告警通知方式,包括:邮件、飞书、钉钉、电话等。详细的配置方式,请参见: