容器服务支持监控集群的 AI 资源,即 GPU 资源、RDMA 资源的状态。本文为您介绍如何配置 AI 资源观测。
使用限制
- 仅支持 NVIDIA GPU 模式下,采集节点和 Pod 的 RDMA 指标。不支持 mGPU 模式。
- 共享(shared)模式下,仅上报节点的 RDMA 指标。
- 独占(exclusive)模式下,仅上报 Pod 的 RDMA 指标。
前提条件
- 已开启云原生观测功能,详情请参见 开启观测。
- 已开启容器服务观测功能,详情请参见 容器服务观测。
- 已安装对应的组件,包括:
- prometheus-agent 组件已经升级到 v2.2.0 及以上版本。详情请参见 组件发布记录。
操作步骤
步骤一:开启观测
- 登录 容器服务控制台。
- 在左侧导航栏单击 集群,找到目标集群,单击集群名称。
- 在集群管理页面的左侧导航栏中,单击 观测配置,并选择 基础观测 页签。
- 选择 AI 资源 卡片,单击 启用,开启集群 AI 资源观测。
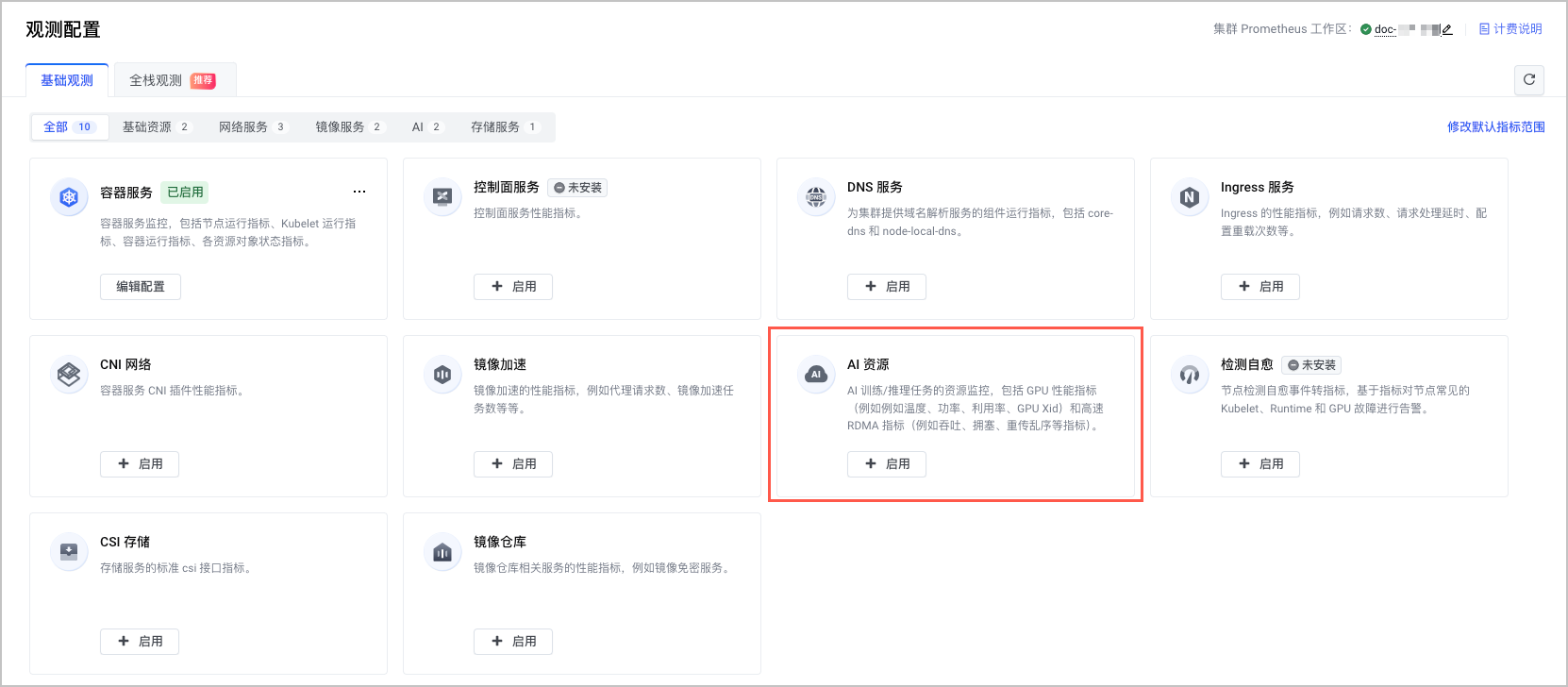
- 系统自动检查开启观测所需的必要条件。包括:工作区配置、组件状态等。
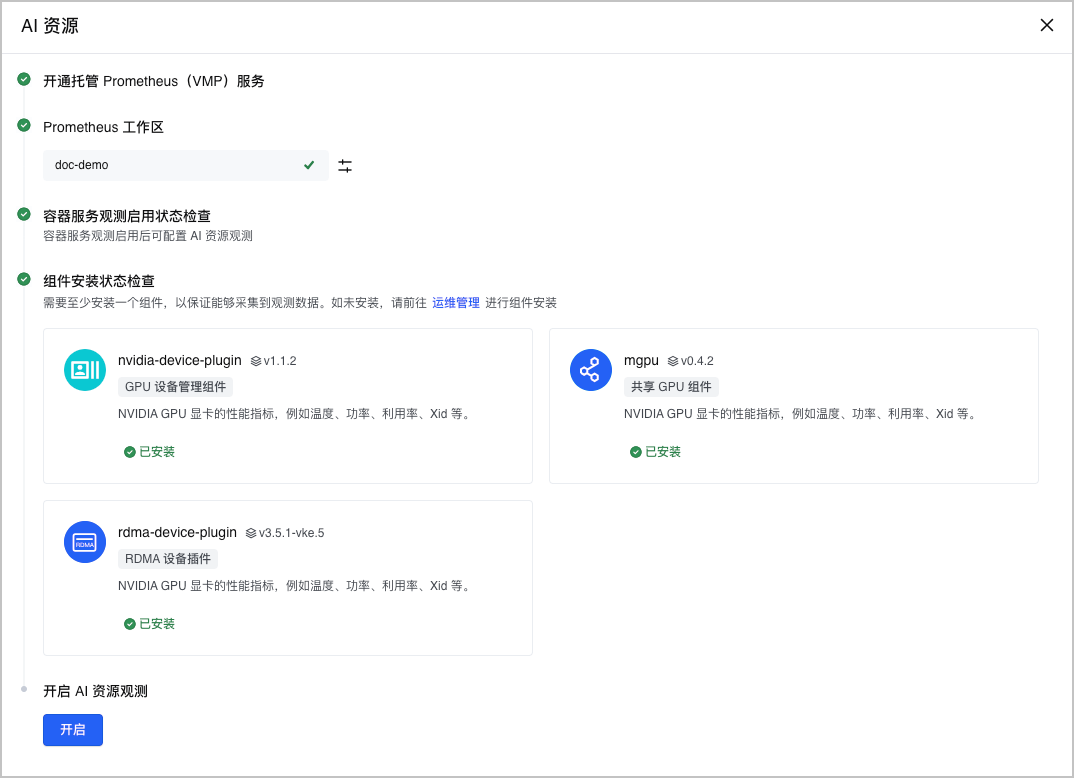
- 单击 开启,开启 AI 资源观测。
步骤二:配置采集规则
观测功能开启后,您可以配置采集规则,选择需要采集的目标组件、具体指标项及采集间隔。可以根据实际需求丢弃一些不用的指标。
- 在集群管理页面的左侧导航栏中,单击 观测配置,并选择 基础观测 页签。
- 选择 AI 资源 卡片,单击 编辑配置 并选择 指标 页签,配置采集规则,并选择具体的采集指标。
- 在组件列表 操作 列,单击开关,开启或关闭组件的采集规则。当关闭组件的采集规则时,系统不会采该集组件的所有指标。
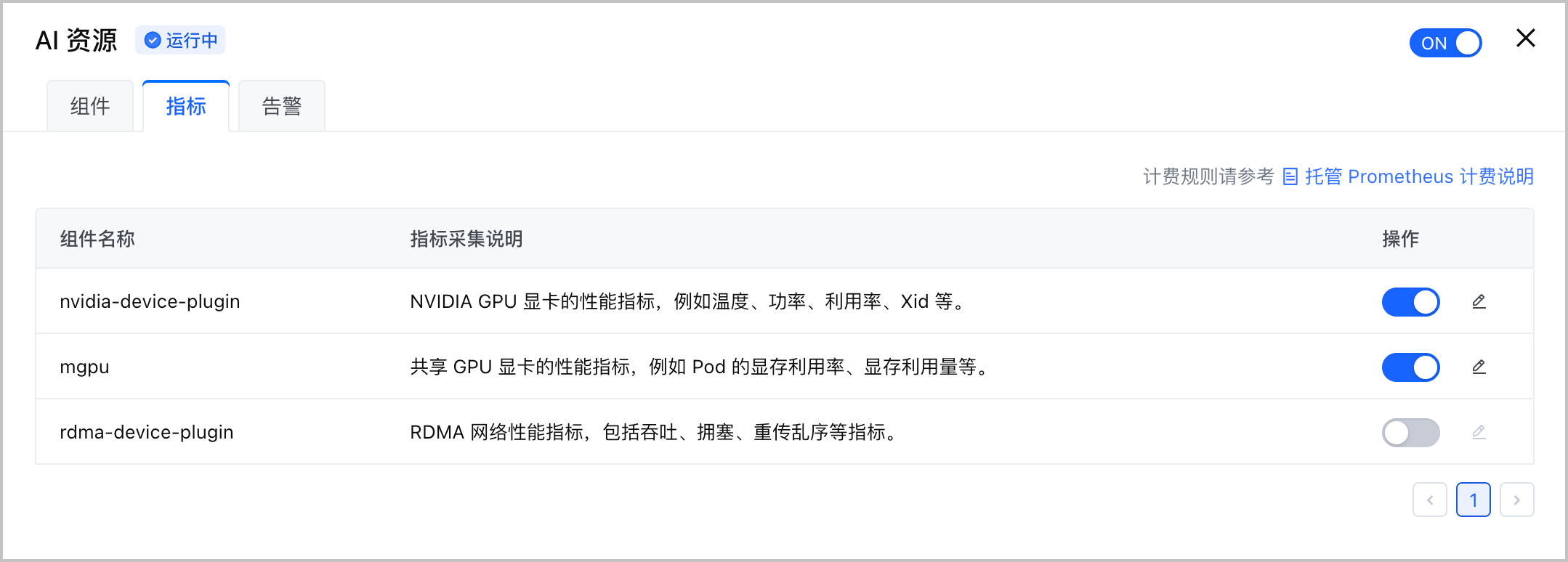
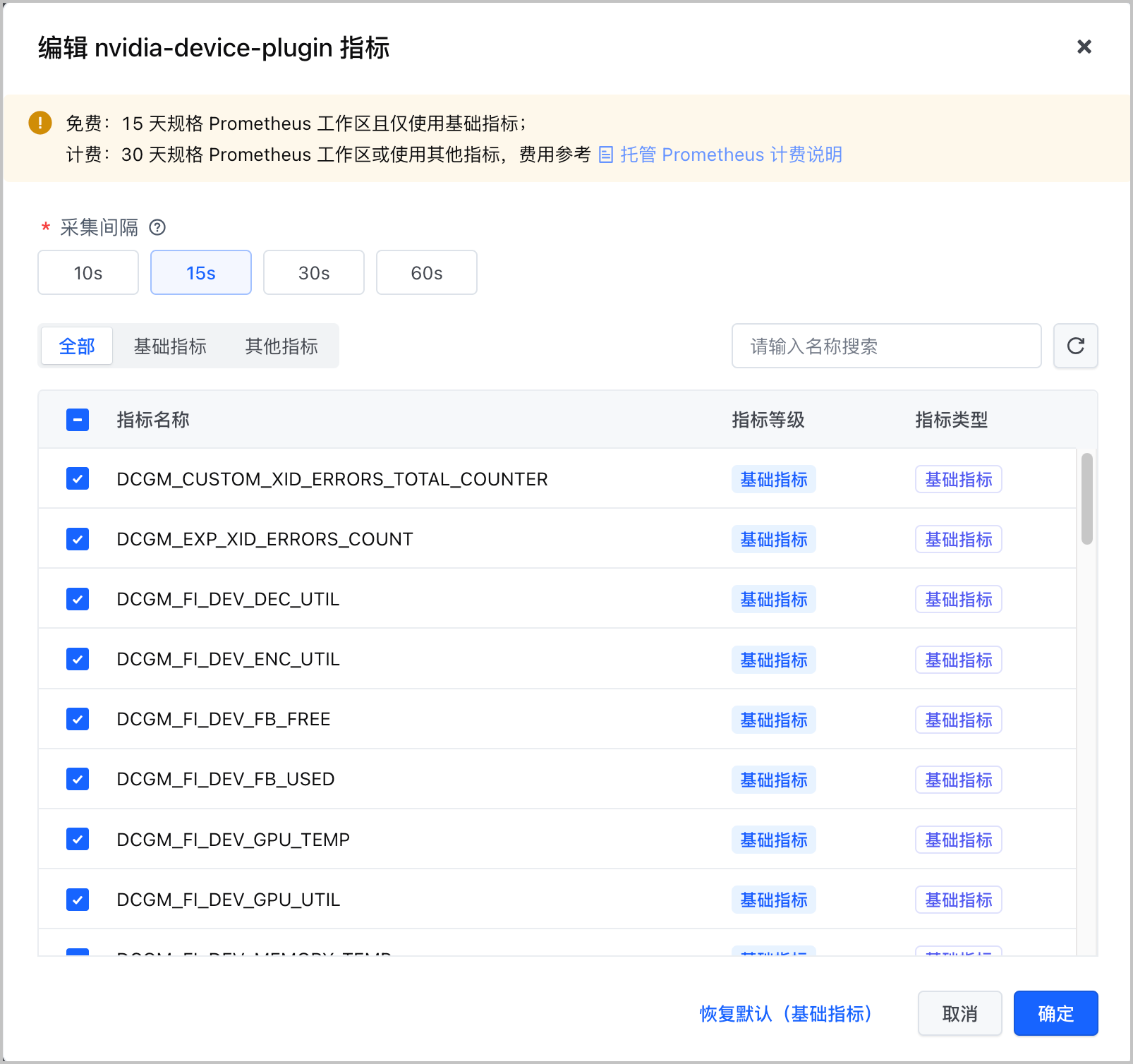
- 单击组件列表 操作 栏中的
 ,支持选择或丢弃组件的具体指标,并配置面向该组件的采集间隔。
,支持选择或丢弃组件的具体指标,并配置面向该组件的采集间隔。
- 在 采集间隔 中,选择该组件指标的采集间隔。不同组件支持的采集间隔不同。
- 在 指标列表 中,勾选指标,则采集该指标。取消勾选,则丢弃该指标。单击 全部、基础指标 或 其他指标 页签,允许基于指标类型对指标项进行筛选。
说明
- 减小指标采集间隔,会增加单位时间内上报的指标数量,可以提升监控精度。但会增加托管 Prometheus 标准版工作区的费用。增加指标采集间隔,会减少单位时间内上报的指标数量,可以减少托管 Prometheus 标准版工作区的费用,但会降低监控精度。请根据实际需要配置。
- 云产品的指标类型分为 基础指标 和 其他指标,不同类型指标的计费方式不同,详情请参见 托管 Prometheus 计费方式。
- 在组件列表 操作 列,单击开关,开启或关闭组件的采集规则。当关闭组件的采集规则时,系统不会采该集组件的所有指标。
- 单击 确认,完成配置。
步骤三:配置告警
容器服务集群基于托管 Prometheus 产品的告警中心功能,允许一键开启集群告警能力,并使用告警模板快速配置告警规则。
在集群管理页面的左侧导航栏中,单击 观测配置,并选择 基础观测 页签。
选择 AI 资源 卡片,单击 编辑配置 并选择 告警 页签,配置告警的相关参数。
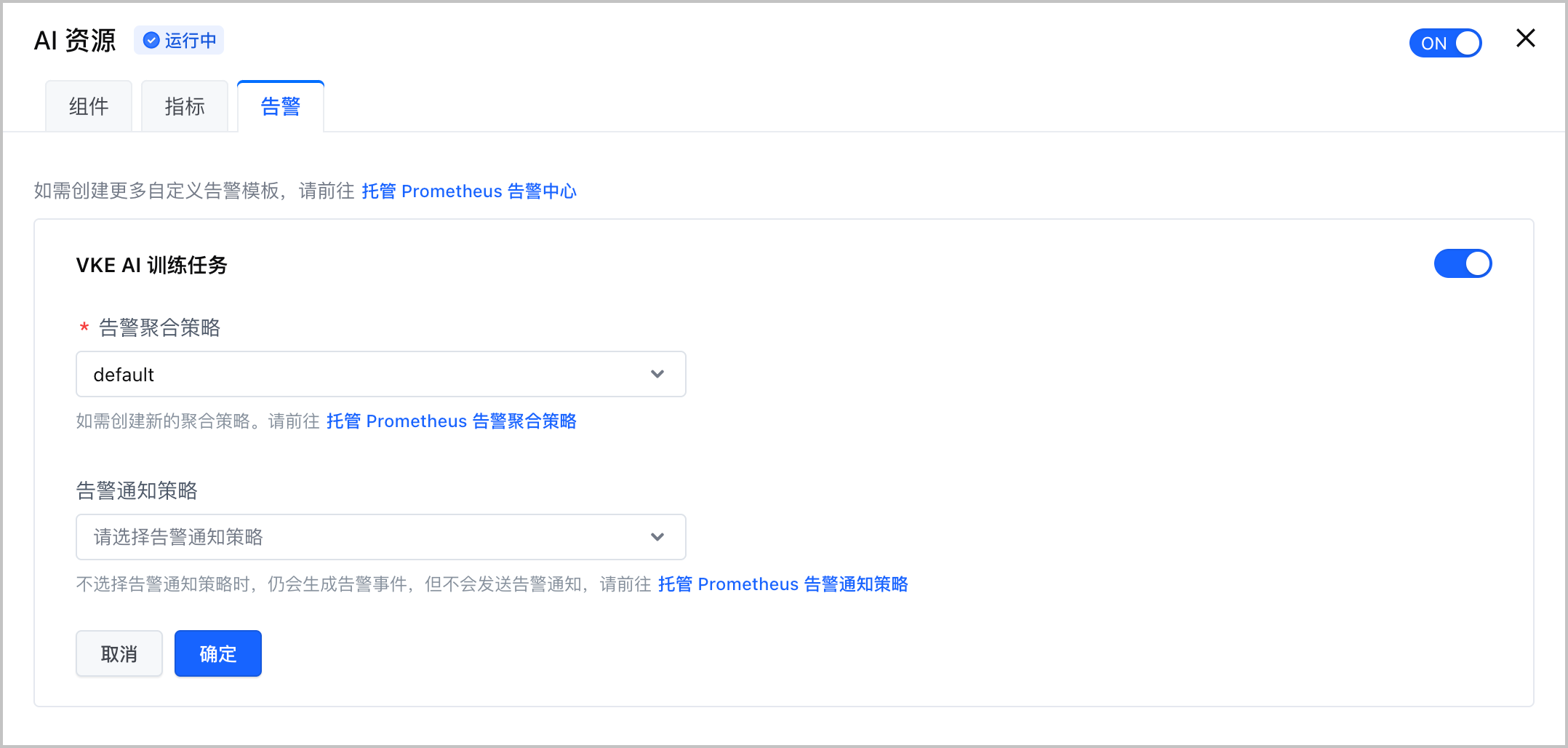
单击 确定,完成配置。
说明
如果告警模板无法满足您的要求,也可以在托管 Prometheus 的告警中心配置自定义告警,详情请参见 创建告警规则。
观测看板
集群 GPU 监控
集群 GPU 监控看板展示了集群纬度的 GPU 监控信息,包括:集群总 GPU 数、已分配 GPU 数、已使用 GPU 数等。您可以从该看板中了解整个集群的 GPU 监控信息。支持设置查询的时间段,并指定刷新方式(手动刷新、自动刷新)。
- 在集群管理页面的左侧导航栏中,选择 监控中心 > 监控看板。
- 在左侧看板列表中选择 GPU 监控 > 集群 GPU 监控,即可查看监控看板。
该看板的指标清单如下表所示。
| 看板名称 | 指标单位 | PromQL 语句 |
|---|---|---|
| 集群总 GPU 数 | Count | sum(kube_node_status_capacity{resource="nvidia_com_gpu", cluster="$clusterId",node!~"vci.*"}) |
| 已分配 GPU 数 | Count | sum(kube_pod_container_resource_limits{resource="nvidia_com_gpu", cluster="$clusterId",node!~"vci.*"}) |
| 已使用 GPU 数 | Count | count(DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",job=~"dcgm"}>0) |
| 故障的 GPU 数 | Count | count(DCGM_FI_DEV_XID_ERRORS{cluster="$clusterId",job=~"dcgm"}>0) or on() vector(0) |
| GPU 节点数 | Count | count(kube_node_status_capacity{resource="nvidia_com_gpu", cluster="$clusterId",node!~"vci.*"}>0) |
| GPU 故障节点数 | Count | count(count(DCGM_FI_DEV_XID_ERRORS{cluster="$clusterId",job=~"dcgm"}>0)by(nodename)) or on() vector(0) |
| 8 GPU 卡可用节点 | Count | count(count(DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",job=~"dcgm",pod= ""})by(nodename) ==8) or on() vector(0) |
| 碎片节点数 | Count | (count(count(DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",job=~"dcgm",pod= ""})by(nodename) ==1 and (count(DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",job=~"dcgm"})by(nodename) >3)) or on() vector(0) )+ (count(count(DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",job=~"dcgm",pod= ""})by(nodename) ==2 and (count(DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",job=~"dcgm"})by(nodename) >3) ) or on() vector(0)) + (count(count(DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",job=~"dcgm",pod= ""}) by(nodename) ==1 and (count(DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",job=~"dcgm"})by(nodename) ==2) ) or on() vector(0)) |
| 集群 GPU 分配率 | % | sum(kube_pod_container_resource_requests{resource="nvidia_com_gpu",cluster="$clusterId",node!~"vci.*"})/sum(kube_node_status_capacity{resource="nvidia_com_gpu", cluster="$clusterId",node!~"vci.*"})by(cluster)*100 |
| 集群 GPU 利用率 | % | count(DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",job=~"dcgm"}>0)by(cluster)/sum(kube_pod_container_resource_requests{resource="nvidia_com_gpu",cluster="$clusterId",node!~"vci.*"})*100 |
| 集群 GPU 故障率 | % | 100*count(DCGM_FI_DEV_XID_ERRORS{cluster="$clusterId",job=~"dcgm"}>0)by(cluster)/sum(kube_node_status_capacity{resource="nvidia_com_gpu", cluster="$clusterId",node!~"vci.*"}) or on() vector(0) |
| GPU 节点故障率 | % | 100*count(count(DCGM_FI_DEV_XID_ERRORS{cluster="$clusterId",job=~"dcgm"}>0)by(nodename))/count(kube_node_status_capacity{resource="nvidia_com_gpu", cluster="$clusterId",node!~"vci.*"}>0) or on() vector(0) |
| 节点空闲率 | % | (count(kube_node_status_capacity{resource="nvidia_com_gpu", cluster="$clusterId",node!~"vci.*"}>0)-count(sum(kube_pod_container_resource_requests{resource="nvidia_com_gpu",cluster="$clusterId",node!~"vci.*"}) by(node) >0))/count(kube_node_status_capacity{resource="nvidia_com_gpu",cluster="$clusterId",node !~"vci.*"}>0) *100 |
| 节点碎片率 | % | ((count(count(DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",job=~"dcgm",pod= ""}) by(nodename) ==1 and (count(DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",job=~"dcgm"})by(nodename) >3)) or on() vector(0) )+(count(count(DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",job=~"dcgm",pod= ""}) by(nodename) ==2 and (count(DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",job=~"dcgm"})by(nodename) >3) ) or on() vector(0)) + (count(count(DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",job=~"dcgm",pod= ""}) by(nodename) ==1 and (count(DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",job=~"dcgm"})by(nodename) ==2) ) or on() vector(0))/count(kube_node_status_capacity{resource="nvidia_com_gpu",cluster="$clusterId",node !~"vci.*"}>0)*100 ) or on() vector(0) |
说明
如果您需要在托管 Prometheus 中的 Explore 功能或告警中心使用上述 PromQL 语句查看具体的指标或配置告警,请修改或删除语句中关于集群、节点、容器组的变量。例如:将 cluster=~"$ClusterId"参数中的$ClusterId变量修改为具体的集群 ID ,或直接删除该参数。
GPU 实例监控
GPU 实例监控看板展示了 GPU 卡实例纬度的 GPU 监控信息,包括:GPU 利用率、GPU 使用显存、GPU 温度、GPU 功耗等。您可以从该看板中了解指定 GPU 卡的监控信息。支持设置查询的时间段,并指定刷新方式(手动刷新、自动刷新)。
- 在集群管理页面的左侧导航栏中,选择 监控中心 > 监控看板。
- 在左侧看板列表中选择 GPU 监控 > GPU 实例监控,即可查看监控看板。
该看板的指标清单如下表所示。
| 看板名称 | 指标单位 | PromQL 语句 |
|---|---|---|
| GPU 利用率 | % | DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",nodename=~"$node",gpu_id=~"$instance",job=~"dcgm|dcgm-vci"} |
| GPU 使用显存 | Byte | DCGM_FI_DEV_FB_USED{cluster="$clusterId",nodename=~"$node",gpu_id=~"$instance",job=~"dcgm|dcgm-vci"} |
| Pod GPU 显存使用率 | % | 100*DCGM_FI_DEV_FB_USED{cluster="$clusterId",nodename=~"$node",gpu_id=~"$instance",job=~"dcgm|dcgm-vci"}、(DCGM_FI_DEV_FB_USED{cluster="$clusterId",nodename=~"$node",gpu_id=~"$instance",job=~"dcgm|dcgm-vci"}+DCGM_FI_DEV_FB_FREE{cluster="$clusterId",nodename=~"$node",gpu_id=~"$instance",job=~"dcgm|dcgm-vci"}) |
| GPU 温度 | ℃ | DCGM_FI_DEV_GPU_TEMP{cluster="$clusterId",nodename=~"$node",gpu_id=~"$instance",job=~"dcgm|dcgm-vci"} |
| GPU 功耗 | W | DCGM_FI_DEV_POWER_USAGE{cluster="$clusterId",nodename=~"$node",gpu_id=~"$instance",job=~"dcgm|dcgm-vci"} |
| GPU 时钟频率 | Hz | DCGM_FI_DEV_SM_CLOCK{cluster="$clusterId",nodename=~"$node",gpu_id=~"$instance",job=~"dcgm|dcgm-vci"} |
| GPU 解码器利用率 | % | DCGM_FI_DEV_DEC_UTIL{cluster="$clusterId",nodename=~"$node",gpu_id=~"$instance",job=~"dcgm|dcgm-vci"} |
| GPU 编码器利用率 | % | DCGM_FI_DEV_ENC_UTIL{cluster="$clusterId",nodename=~"$node",gpu_id=~"$instance",job=~"dcgm|dcgm-vci"} |
| GPU Xid (By instance) | Count | sum(DCGM_CUSTOM_XID_ERRORS_TOTAL_COUNTER{cluster="$clusterId",nodename=~"$node",gpu_id=~"$instance",job=~"dcgm|dcgm-vci"})by(gpu_id) |
| GPU Xid (By xid) | % | sum(DCGM_CUSTOM_XID_ERRORS_TOTAL_COUNTER{cluster="$clusterId",nodename=~"$node",gpu_id=~"$instance",job=~"dcgm|dcgm-vci"})by(xid) |
说明
如果您需要在托管 Prometheus 中的 Explore 功能或告警中心使用上述 PromQL 语句查看具体的指标或配置告警,请修改或删除语句中关于集群、节点、容器组的变量。例如:将 cluster=~"$ClusterId"参数中的$ClusterId变量修改为具体的集群 ID ,或直接删除该参数。
容器组 GPU 监控
容器组 GPU 监控看板展示了容器组纬度的 GPU 监控信息,包括:GPU 使用率、GPU 显存使用率、GPU 显存用量等。您可以从该看板中了解指定容器组的 GPU 监控信息。支持设置查询的时间段,并指定刷新方式(手动刷新、自动刷新)。
- 在集群管理页面的左侧导航栏中,选择 监控中心 > 监控看板。
- 在左侧看板列表中选择 GPU 监控 > 容器组 GPU 监控,即可查看监控看板。
该看板的指标清单如下表所示。
| 看板名称 | 指标单位 | PromQL 语句 |
|---|---|---|
| GPU 使用率 | % | DCGM_FI_DEV_GPU_UTIL{cluster="$clusterId",namespace="$namespace",pod="$pod",job=~"dcgm|dcgm-vci"} |
| GPU 显存使用率 | % | (DCGM_FI_DEV_FB_USED{cluster="$clusterId",namespace="$namespace",pod="$pod",job=~"dcgm|dcgm-vci"}/(DCGM_FI_DEV_FB_USED{cluster="$clusterId",namespace="$namespace",pod="$pod",job=~"dcgm|dcgm-vci"} + DCGM_FI_DEV_FB_FREE{cluster="$clusterId",namespace="$namespace",pod="$pod",job=~"dcgm|dcgm-vci"}))*100 |
| GPU 显存用量 | Byte | DCGM_FI_DEV_FB_USED{cluster="$clusterId",namespace="$namespace",pod="$pod",job=~"dcgm|dcgm-vci"} |
| GPU 显存未使用量 | Byte | DCGM_FI_DEV_FB_FREE{cluster="$clusterId",namespace="$namespace",pod="$pod",job=~"dcgm|dcgm-vci"} |
| 共享 GPU 显存用量 | Byte | nvml_container_mem_usage{cluster="$clusterId",namespace="$namespace",pod="$pod"} |
| 共享 GPU 显存未使用量 | Byte | nvml_container_mem_request{cluster="$clusterId",namespace="$namespace",pod="$pod"}-nvml_container_mem_usage{cluster="$clusterId",namespace="$namespace",pod="$pod"} |
| 共享 GPU 显存使用率 | % | nvml_container_mem_utilization{cluster="$clusterId",namespace="$namespace",pod="$pod"} |
说明
如果您需要在托管 Prometheus 中的 Explore 功能或告警中心使用上述 PromQL 语句查看具体的指标或配置告警,请修改或删除语句中关于集群、节点、容器组的变量。例如:将 cluster=~"$ClusterId"参数中的$ClusterId变量修改为具体的集群 ID ,或直接删除该参数。
节点 GPU 监控
节点 GPU 监控看板展示了集群节点的 GPU 监控信息,包括:节点资源使用情况、节点 GPU 使用详情、GPU 利用率、GPU 使用现存等。您可以从该看板中了解指定节点的 GPU 监控信息。支持设置查询的时间段,并指定刷新方式(手动刷新、自动刷新)。
- 在集群管理页面的左侧导航栏中,选择 监控中心 > 监控看板。
- 在左侧看板列表中选择 GPU 监控 > 节点 GPU 监控,即可查看监控看板。
- 在 节点资源使用情况 列表中,单击选择具体的节点,可以查看指定节点的监控信息。
- 在 节点 GPU 使用详情 列表中,单击选择具体的 GPU 卡,可以查看指定 GPU 卡的监控信息。
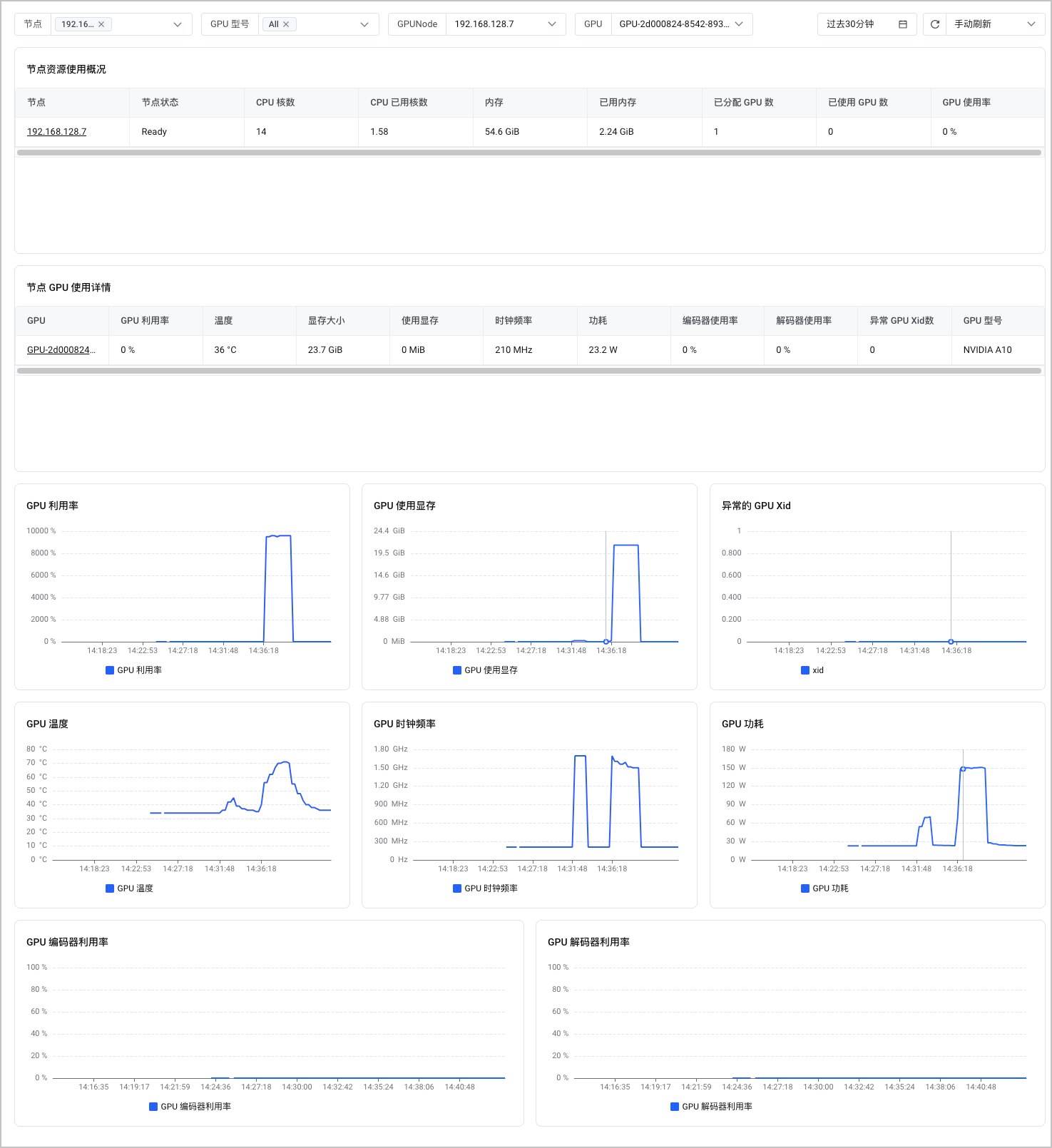
该看板的指标清单如下表所示。
| 看板名称 | PromQL 语句 |
|---|---|
| GPU 利用率 | DCGM_FI_DEV_GPU_UTIL{cluster="$ClusterId",UUID="$gpuId"} |
| GPU 使用显存 | DCGM_FI_DEV_FB_USED{cluster="$ClusterId",UUID="$gpuId"} |
| 异常的 GPU Xid | DCGM_CUSTOM_XID_ERRORS_TOTAL_COUNTER{cluster="$ClusterId",UUID="$gpuId"} |
| GPU 温度 | DCGM_FI_DEV_GPU_TEMP{cluster="$ClusterId",UUID="$gpuId"} |
| GPU 时钟频率 | DCGM_FI_DEV_SM_CLOCK{cluster="$ClusterId",UUID="$gpuId"} * 1000000 |
| GPU 功耗 | DCGM_FI_DEV_POWER_USAGE{cluster="$ClusterId",UUID="$gpuId"} |
| GPU 编码器利用率 | DCGM_FI_DEV_ENC_UTIL{cluster="$ClusterId",UUID="$gpuId"} |
| GPU 解码器利用率 | DCGM_FI_DEV_DEC_UTIL{cluster="$ClusterId",UUID="$gpuId"} |
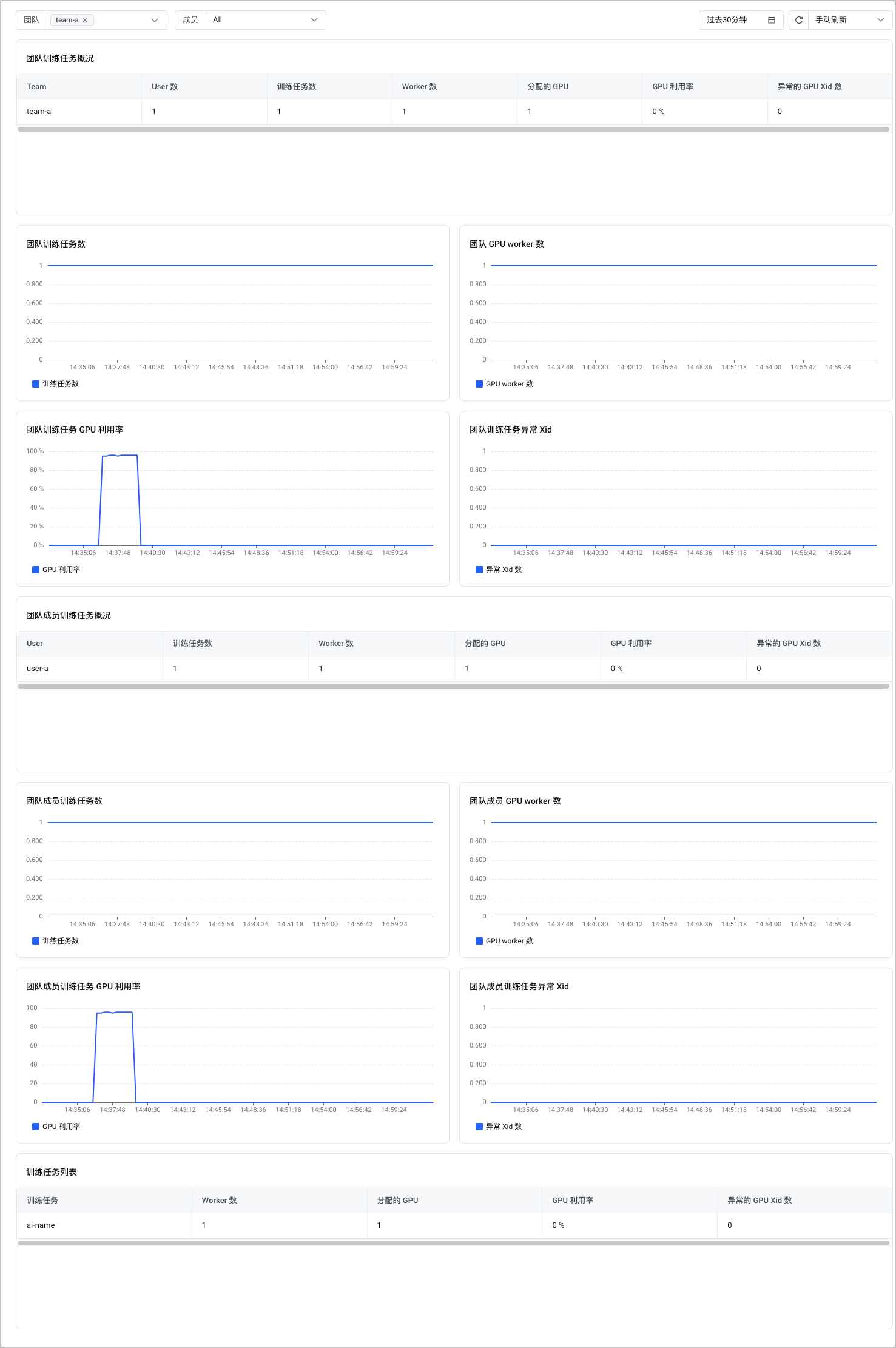
用户 GPU 监控
用户 GPU 监控看板展示了展示了团队维度的 AI 训练监控信息。包括:团队训练任务数、团队 GPU worker 数、团队训练任务 GPU 利用率、团队训练任务异常 Xid 等。您可以从该看板中了解整个团队的 GPU 监控信息。支持设置查询的时间段,并指定刷新方式(手动刷新、自动刷新)。
- 在集群管理页面的左侧导航栏中,选择 监控中心 > 监控看板。
- 在左侧看板列表中选择 GPU 监控 > 用户 GPU 监控,即可查看监控看板。
- 在 团队训练任务概况 列表中,单击选择具体的团队,可以查看指定团队的监控信息。
- 在 团队成员训练任务概况 列表中,单击选择具体的团队成员,可以查看指定团队成员的监控信息。
说明
为了能够在大盘中查看到团队训练任务的监控信息,您需要在训练任务中增加ai.vke.volcengine.com/task、ai.vke.volcengine.com/job、ai.vke.volcengine.com/team和ai.vke.volcengine.com/user标签。详情请参见 AI 训练任务监控。
指标清单
rdma-device-plugin 监控
RDMA 网络性能指标暂未提供观测看板,您可以通过 rdma-device-plugin 组件的指标清单查看监控信息,如下表所示。
| 指标分类 | 指标名称 | 指标类型 | 指标含义 |
|---|---|---|---|
| 节点指标 | rdma_exporter_node_infiniband_implied_nak_seq_err_total | Counter | Read response 乱序次数。 |
| rdma_exporter_node_infiniband_local_ack_timeout_err_total | Counter | 出方向超时次数。 | |
| rdma_exporter_node_infiniband_np_cnp_sent_total | Counter | 出方向采集周期内网卡发出的 CNP 报文数量。代表接收端路径上出现了拥塞,需要通知发送端减少发送。 | |
| rdma_exporter_node_infiniband_np_ecn_marked_roce_packets_total | Counter | 入方向采集周期内网卡收到的 ECN mark 的报文数量。代表路径上出现了拥塞。 | |
| rdma_exporter_node_infiniband_out_of_sequence_total | Counter | 入方向乱序次数。该指标增长可能是链路有问题。 | |
| rdma_exporter_node_infiniband_packet_seq_err_total | Counter | 出方向乱序次数。 | |
| rdma_exporter_node_infiniband_port_data_received_bytes_total | Counter | 驱动层面入方向流量,包括 TCP/IP 和 RDMA。 | |
| rdma_exporter_node_infiniband_port_data_transmitted_bytes_total | Counter | 驱动层面出方向流量,包括 TCP/IP 和 RDMA。 | |
| rdma_exporter_node_infiniband_port_packets_received_total | Counter | 驱动层面入方向包数量,包括 TCP/IP 和 RDMA。 | |
| rdma_exporter_node_infiniband_port_packets_transmitted_total | Counter | 驱动层面出方向包数量,包括 TCP/IP 和 RDMA。 | |
| rdma_exporter_node_infiniband_rdma_data_received_bytes_total | Counter | RDMA 入方向流量。 | |
| rdma_exporter_node_infiniband_rdma_data_transmitted_bytes_total | Counter | RDMA 出方向流量。 | |
| rdma_exporter_node_infiniband_rdma_packets_received_total | Counter | RDMA 入方向包数量。 | |
| rdma_exporter_node_infiniband_rdma_packets_transmitted_total | Counter | RDMA 出方向包数量。 | |
| rdma_exporter_node_infiniband_rp_cnp_handled_total | Counter | 入方向采集周期内网卡处理的 CNP 报文数量。需要降低发送频率。 | |
| rdma_exporter_node_infiniband_rp_cnp_ignored_total | Counter | 入方向采集周期内网卡忽略的 CNP 报文数量。该指标不应该增长。如果增长要查看网卡的拥塞控制配置是否正常,是否使能 ECN/CNP。 | |
| rdma_exporter_node_infiniband_rx_pause_duration_seconds | Counter | 入方向 pause 时长。该指标一般指向网络拥塞,代表网卡作为发送端收到的 PFC 包, 意味着接收端处于严重拥塞,接收端要求网卡停止发送。 | |
| rdma_exporter_node_infiniband_tx_pause_duration_seconds | Counter | 出方向 pause 时长。该指标一般指向主机异常,网卡发出 PFC 包,意味着网卡作为接收端处于严重拥塞,网卡要求发送端停止发送。 | |
| rdma_exporter_node_infiniband_rx_pause_total | Counter | 入方向接收到的 PFC pause 报文数量,当前都是使用了优先级 5。 | |
| rdma_exporter_node_infiniband_tx_pause_total | Counter | 出方向发送的 PFC pause 报文数量。 | |
| Pod 指标 | rdma_exporter_pod_infiniband_implied_nak_seq_err_total | Counter | Read response 乱序次数。 |
| rdma_exporter_pod_infiniband_local_ack_timeout_err_total | Counter | 出方向超时次数。 | |
| rdma_exporter_pod_infiniband_np_cnp_sent_total | Counter | 出方向采集周期内网卡发出的 CNP 报文数量。代表接收端路径上出现了拥塞,需要通知发送端减少发送。 | |
| rdma_exporter_pod_infiniband_np_ecn_marked_roce_packets_total | Counter | 入方向采集周期内网卡收到的 ECN mark 的报文数量。代表路径上出现了拥塞。 | |
| rdma_exporter_pod_infiniband_out_of_sequence_total | Counter | 入方向乱序次数。该指标增长可能是链路有问题。 | |
| rdma_exporter_pod_infiniband_packet_seq_err_total | Counter | 出方向乱序次数。 | |
| rdma_exporter_pod_infiniband_port_data_received_bytes_total | Counter | 驱动层面入方向流量,包括 TCP/IP 和 RDMA。 | |
| rdma_exporter_pod_infiniband_port_data_transmitted_bytes_total | Counter | 驱动层面出方向流量,包括 TCP/IP 和 RDMA。 | |
| rdma_exporter_pod_infiniband_port_packets_received_total | Counter | 驱动层面入方向包数量,包括 TCP/IP 和 RDMA。 | |
| rdma_exporter_pod_infiniband_port_packets_transmitted_total | Counter | 驱动层面出方向包数量,包括 TCP/IP 和 RDMA。 | |
| rdma_exporter_pod_infiniband_rdma_data_received_bytes_total | Counter | RDMA 入方向流量。 | |
| rdma_exporter_pod_infiniband_rdma_data_transmitted_bytes_total | Counter | RDMA 出方向流量。 | |
| rdma_exporter_pod_infiniband_rdma_packets_received_total | Counter | RDMA 入方向包数量。 | |
| rdma_exporter_pod_infiniband_rdma_packets_transmitted_total | Counter | RDMA 出方向包数量。 | |
| rdma_exporter_pod_infiniband_rp_cnp_handled_total | Counter | 入方向采集周期内网卡处理的 CNP 报文数量。需要降低发送频率。 | |
| rdma_exporter_pod_infiniband_rp_cnp_ignored_total | Counter | 入方向采集周期内网卡忽略的 CNP 报文数量。该指标不应该增长。如果增长要查看网卡的拥塞控制配置是否正常,是否使能 ECN/CNP。 | |
| rdma_exporter_pod_infiniband_rx_pause_duration_seconds | Counter | 入方向 pause 时长。该指标一般指向网络拥塞,代表网卡作为发送端收到的 PFC 包, 意味着接收端处于严重拥塞,接收端要求网卡停止发送。 | |
| rdma_exporter_pod_infiniband_tx_pause_duration_seconds | Counter | 出方向 pause 时长。该指标一般指向主机异常,网卡发出 PFC 包,意味着网卡作为接收端处于严重拥塞,网卡要求发送端停止发送。 | |
| rdma_exporter_pod_infiniband_rx_pause_total | Counter | 入方向接收到的 PFC pause 报文数量,当前都是使用了优先级 5。 | |
| rdma_exporter_pod_infiniband_tx_pause_total | Counter | 出方向发送的 PFC pause 报文数量。 |
rdma-device-plugin 组件的指标中自定义了部分标签,您可以使用这些标签对指标进行筛选和查看。常用指标标签说明如下表所示。
| 标签名称 | 说明 |
|---|---|
| Pod | 使用 RDMA 设备的容器组 ID,例如pcji9mk1***。 |
| Namespace | 使用 RDMA 设备的容器组所在命名空间。 |
RdmaMode | RDMA 网络模式,取值包括:
|
| Container | 使用 RDMA 设备的容器名称。 |
| Device | RDMA 网络设备名称,例如mlx5_1。 |
说明
Prometheus 通用标签,比如cluster、instance等,不再单独说明。
node-exporter 监控
node-exporter 采集的 RDMA 指标清单,请参见 官方文档。您可以在 Explore 中,通过node_infiniband_前缀查询这些指标。
查看指标
您可以使用托管 Prometheus 的 Explore 功能来快速查询和展示指标数据。详情请参见 指标查询。