导航
AI 套件概述
最近更新时间:2024.04.16 15:12:50首次发布时间:2023.11.08 17:38:25
云原生 AI 套件是部署在火山引擎容器服务(VKE)上用于支撑人工智能(AI)平台统一管理基础设施需求的套件服务。本文主要介绍云原生 AI 套件的特点、架构、优势以及适用场景。
说明
该功能目前处于 公测 阶段。
套件介绍
云原生 AI 套件是由火山引擎容器服务提供的支撑大规模 AI 开发、训练、推理业务的服务套件。以 VKE 容器集群作为底座,针对 AI 业务基础设施的特性,提供一系列资源监控运维、性能加速、工作负载编排调度能力。
云原生 AI 套件具备以下特点:
- 开源原生
云原生 AI 套件的所有能力均通过 Kubernetes 原生(Kube-Native)的组件化方式提供,在 Kubernetes 定义的标准接口中实现可插拔,支持用户进行灵活选择以及与开源方案混合使用。 - 实践验证
云原生 AI 套件诞生于字节跳动内部基于容器平台开展大规模 AI 业务的应用实践。云原生 AI 套件经过了火山引擎外部客户的生产验证,应用于包括机器学习平台、大模型训练、模型推理平台、Stable Diffusion 模型(AI 绘图模型)精调等场景。
套件架构
AI 套件以开源兼容的 VKE 为底座,向上支撑客户自建的 AI 平台,向下接入各类 IaaS 资源并增强性能和可用性。AI 套件既支持客户通过控制台可视化的方式对复杂的组件依赖、多规格的 IaaS 资源和丰富的监控数据统一管理,也可以通过 API 和 ForwardKubernetes API 的方式,为所有上层业务提供 Kubernetes 原生的使用接口。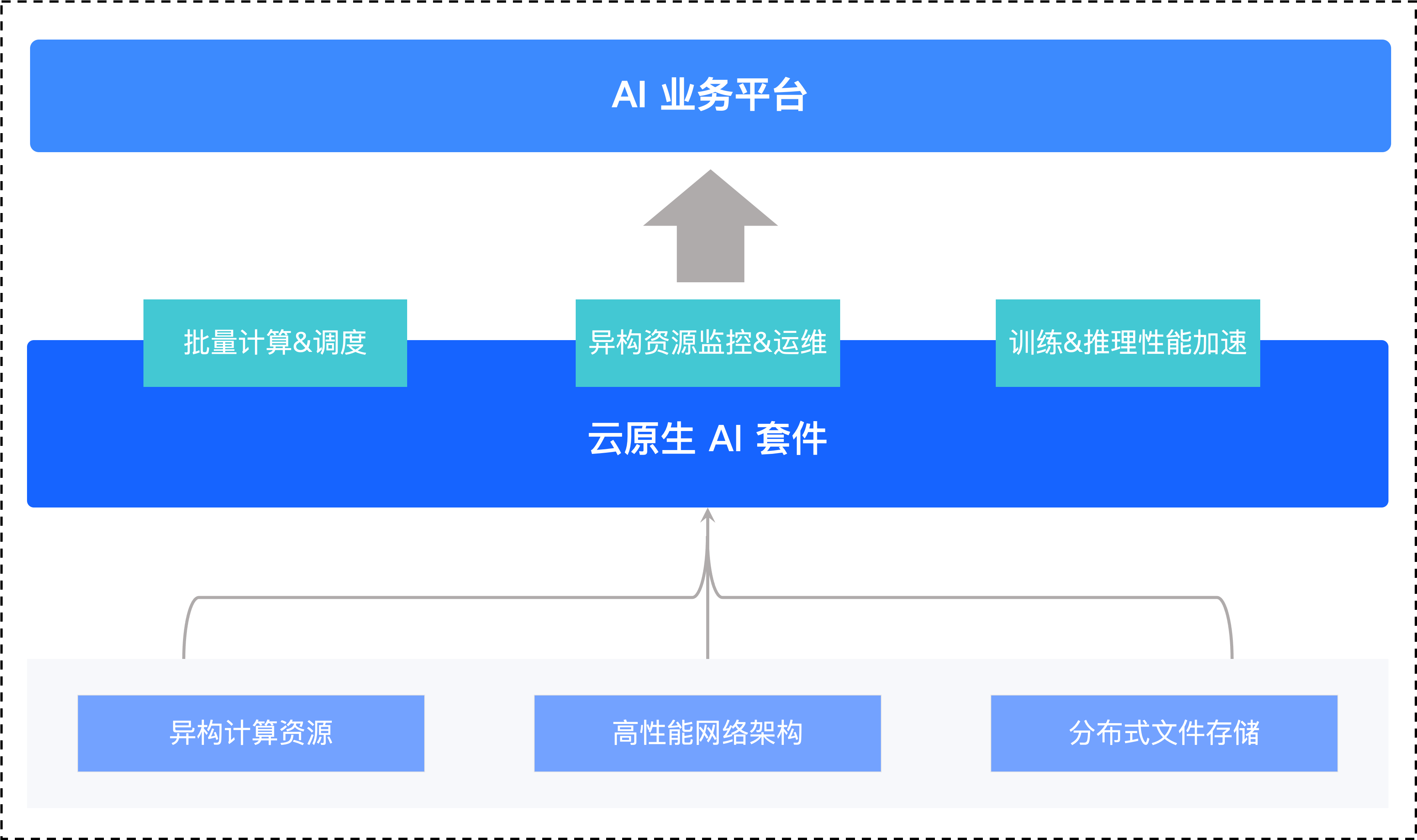
套件优势
云原生 AI 套件优势如下:
- 增强 AI 基础设施运维
统一接入和管理 AI 业务所需的复杂底层资源,包括 GPU、RDMA、高性能缓存、分布式存储等,并提供面向 AI 任务的监控视角和故障发现能力,大幅增强 AI 基础设施的运维能力。 - 降低 AI 资源成本
提供丰富的 AI 任务调度策略,包括 GPU 共享调度、拓扑亲和调度、弹性资源优先级调度等。减少资源碎片、消除木桶效应,实现 GPU 算力成本最优化。 - 提升 AI 应用效能
提供丰富的 AI 预置镜像、基于 P2P 镜像加速和镜像懒加载的镜像拉取加速、基于半托管文件缓存的数据访问加速等能力。从研发测试到任务流水线,全面提升 AI 应用的效率与性能。
应用场景
- 处理复杂的横向服务打通和组件管理场景
- 提供对火山引擎 IaaS 层资源的统一接入,实现了与 Kubernetes 资源管理和网络方案的兼容,用户可以无缝接入使用。
- 提供定制化的 CSI(Container Storage Interface)能力,接入了 vePFS、CloudFS 等火山引擎大数据存储服务,支持通过 Kubernetes 原生方式直接使用。
- 对于 JuiceFS、Alluxio 等开源的大数据存储方案,提供 Helm 半托管形式接入,降低用户的使用成本。
- 对所有的 Device Plugin 和 CSI 等组件,提供统一的面板进行管理,支持组件的安装、卸载和更新,并支持监控各个组件的健康状态。
- 深入云资源底层的监控和调优需求场景
- 在火山引擎托管 Prometheus 服务基础上开发了针对 GPU/RDMA 的全面监控指标和事件采集,并通过开源的 Grafana 为用户提供统一监控大盘。
- 将火山引擎 IaaS 层资源的健康检查和监控能力与 Kubernetes 原生机制进行了有机结合,既可以深度感知 GPU 节点等异构资源的故障状态进行告警,也可以通过原生的 Condition 和 Taint 来满足业务对于故障的感知和容灾。
- 云原生 AI 套件的调度组件统一采集了火山引擎 IaaS 层的网络拓扑和微拓扑信息,并通过 Kubernetes 原生的方式感知上层业务,实现 NUMA(Non-Uniform Memory Access)拓扑感知调度、RDMA 网络拓扑感知调度等一系列调优策略,帮助用户最大化利用 GPU、RDMA 的计算和网络性能。
- 与火山引擎的分布式存储服务和镜像仓库服务结合,提供了开箱即用的数据缓存加速、P2P 镜像加速等能力,支持秒级容器启动就绪速度,大幅缩短应用部署时间,节省了用户使用开源方案时,与云服务之间的适配成本。
- 大规模离线任务的调度场景
- 提供了可插拔的批量计算调度组件,对 Kubernetes 原生的 Job(任务)调度机制进行了拓展,提供了队列管理、任务优先级、弹性资源配额等功能。
- 基于 Kubernetes 原生调度器进行了插件扩展,提供了 Gang 调度、应用感知调度、任务级别的拓扑感知调度等高级调度功能。
- 针对 AI 特性的火山引擎 IaaS 层资源进行了调度策略优化,提供了基于 GPU、mGPU 的 Binpack/Spread 调度等能力,并支持 volcano 等开源方案的接入。