导航
CoreDNS 最佳实践
最近更新时间:2024.02.06 17:04:17首次发布时间:2022.04.08 15:53:16
DNS 是 Kubernetes 中服务发现的基础,CoreDNS 作为 CNCF 中的一个域名发现的项目,原生集成在 Kubernetes 中,本文为您介绍 CoreDNS 的原理和配置方法。
DNS 原理和配置说明
Kubernetes 集群 DNS 配置说明
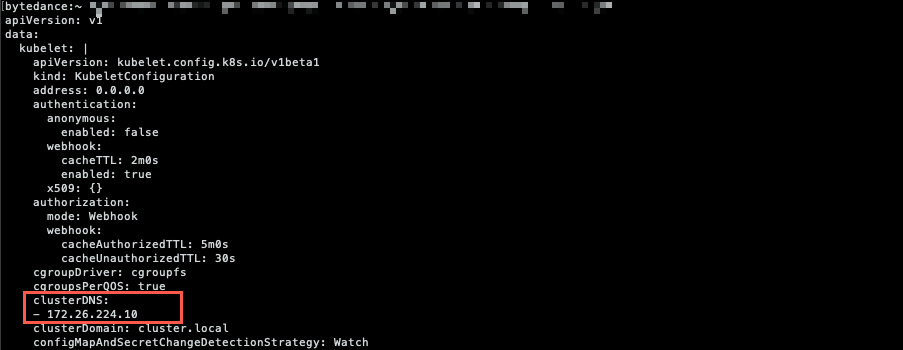
Kubernetes 集群中 kubelet 的启动参数有--cluster-dns=<dns-service-ip>和--cluster-domain=<default-local-domain>,分别被用来配置集群 DNS 服务器的 IP 地址和主域名后缀。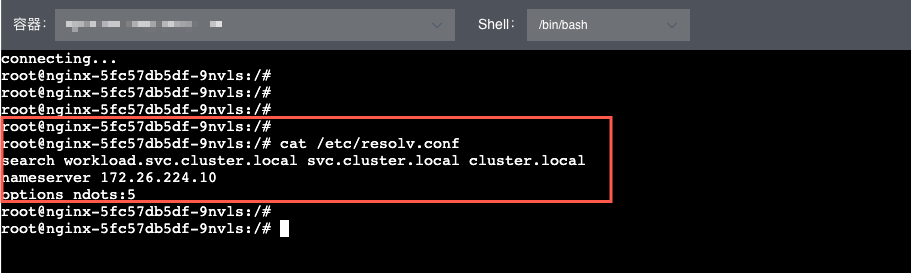

Pod DNS 配置说明
Pod 内的 DNS 域名解析配置文件为 /etc/resolv.conf,文件内容如下所示。
nameserver xx.xx.0.10 #定义 DNS 服务器的 IP 地址。 search kube-system.svc.cluster.local svc.cluster.local cluster.local #设置域名的查找后缀规则,查找配置越多,说明域名解析查找匹配次数越多。Kubernetes 集群匹配有 kube-system.svc.cluster.local、svc.cluster.local、cluster.local 3 个后缀,最多进行 8 次查询才能得到正确解析结果。 options ndots:5 #定义域名解析配置文件选项,例如该参数设置成 ndots:5,说明如果访问的域名字符串内的点字符数量超过 ndots 值,则认为是完整域名,并被直接解析;如果不足 ndots 值,则追加 search 段后缀再进行查询。
Pod 会根据上述的配置,进行域名的查询。
CoreDNS 配置说明
Corefile: | .:53 { errors #错误信息到标准输出。 log health { #健康检查配置。 lameduck 15s #关闭延迟时间。 } ready # CoreDNS 插件,一般用来做可读性检查,可以通过 http://localhost:8181/ready 读取。 kubernetes {{.ClusterDomain}} in-addr.arpa ip6.arpa { # CoreDNS Kubernetes 插件,提供集群内服务解析能力。 pods verified fallthrough in-addr.arpa ip6.arpa } #添加自定义 hosts。 hosts { 192.168.11.241 www.testxx.com 192.168.11.240 harbor.testxx.com fallthrough in-addr.arpa ip6.arpa } prometheus :9153 # CoreDNS 自身 metrics 数据接口。 forward . /etc/resolv.conf { #当域名不在 Kubernetes 域时,将请求转发到预定义的解析器。 max_concurrent 1000 } cache 30 # DNS 查询缓存。 loop #环路检测,如果检测到环路,则停止 CoreDNS。 reload #允许自动重新加载已更改的 Corefile。编辑 ConfigMap 配置后,请等待两分钟以使更改生效。 loadbalance #循环 DNS 负载均衡器,可以在答案中随机 A、AAAA、MX 记录的顺序。 }
ClusterFirst 模式下,Pod DNS 请求解析过程
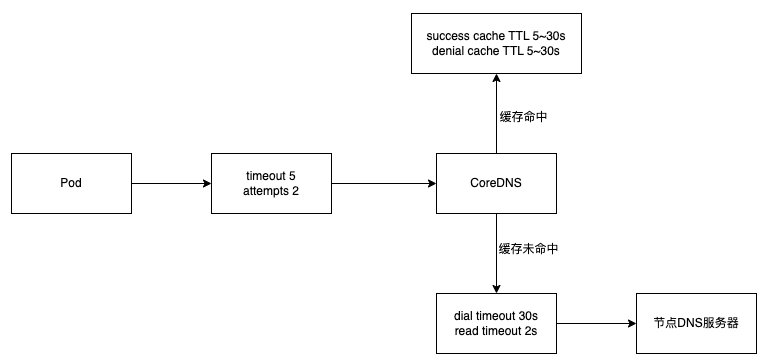
CoreDNS 服务端优化
合理调整 CoreDNS 副本数
CoreDNS 所能提供的域名解析 QPS 与 CPU 消耗成正相关,不同类型的业务对 CoreDNS 请求的 QPS 需求存在差异,所以对 CoreDNS 需要加强监控。根据 CoreDNS 负载和健康情况调整 CoreDNS 副本数。
手动调整 CoreDNS 副本数
kubectl scale --replicas={target} deployment/coredns -n kube-system #{target} 目标副本数量
通过 HPA 自动调整 CoreDNS 副本数
apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: coredns-hpa namespace: kube-system spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: coredns minReplicas: 2 maxReplicas: 10 metrics: - type: Resource resource: name: cpu targetAverageUtilization: 50
监控 CoreDNS 服务端
通过 Prometheus 监控 CoreDNS 关键指标
您可以在 Prometheus 中使用如下 PromQL 语句,监控 CoreDNS 的关键指标:
coredns_dns_requests_total:请求次数可针对总量进行告警,判断当前域名解析 QPS 是否过高。coredns_dns_responses_total:响应次数可针对不同状态码 RCODE 的响应次数进行告警,例如服务端异常 SERVFAIL 出现时,可进行告警。coredns_panics_total:CoreDNS 程序异常退出的次数大于 0 则说明异常发生,应进行告警。coredns_dns_request_duration_seconds:域名解析延迟延迟过高时应进行告警。coredns_forward_max_concurrent_rejects_total:由于并发查询达到最大值而被拒绝的查询数。coredns_forward_healthcheck_failures_total:健康检查失败数。
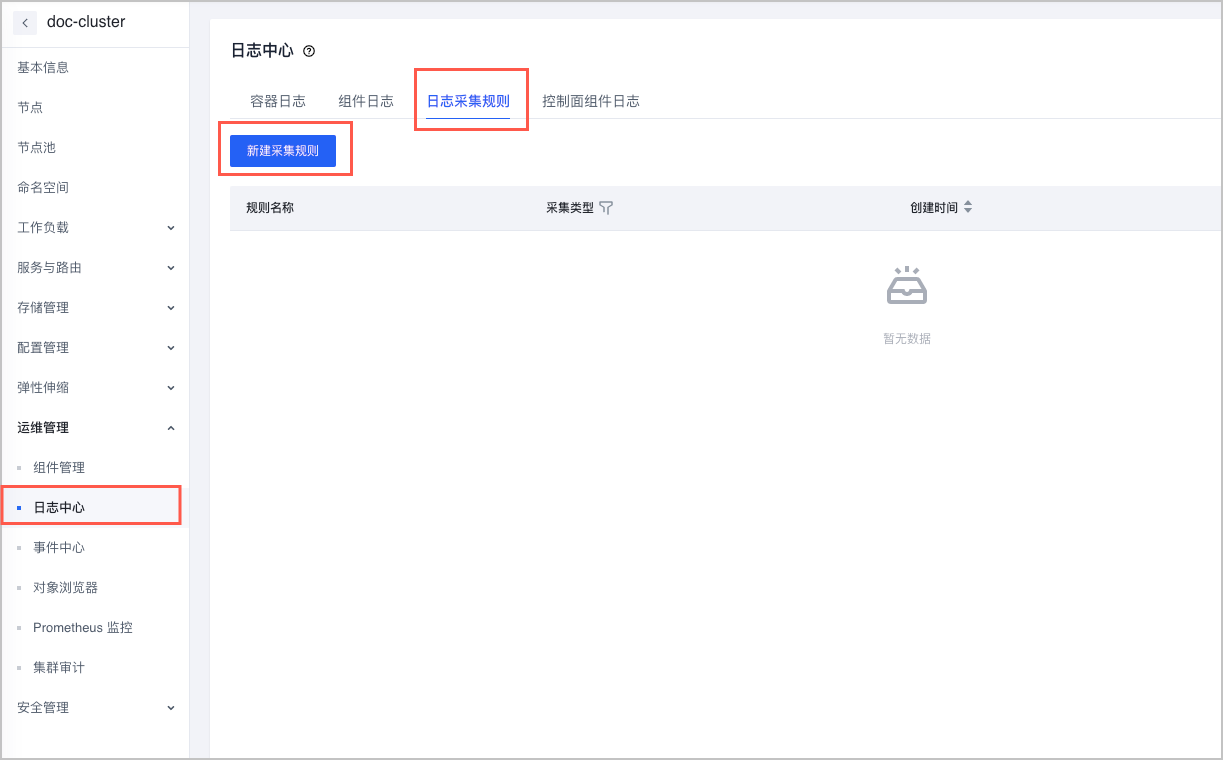
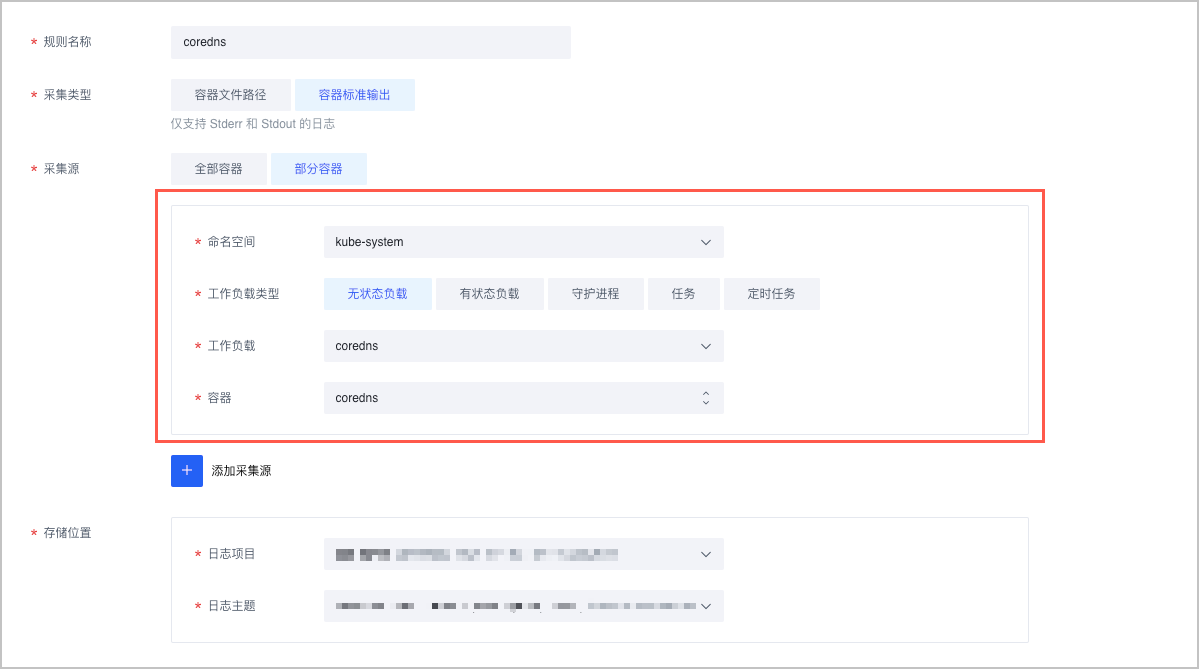
通过日志服务收集 CoreDNS 日志
日常排查 CoreDNS 问题时,分析 CoreDNS 解析日志是有效的方法,下面介绍在 VKE 平台下,如何收集 CoreDNS 日志。
修改 CoreDNS 日志级别
Corefile: | .:53 { debug #排查问题时修改日志解决 errors 为 debug。 log health { #健康检查配置。 lameduck 15s #关闭延迟时间。 } ready # CoreDNS 插件,一般用来做可读性检查,可以通过 http://localhost:8181/ready 读取。 kubernetes {{.ClusterDomain}} in-addr.arpa ip6.arpa { # CoreDNS Kubernetes 插件,提供集群内服务解析能力。 pods verified fallthrough in-addr.arpa ip6.arpa } #添加自定义 hosts。 hosts { 192.168.11.241 www.testxx.com 192.168.11.240 harbor.testxx.com fallthrough in-addr.arpa ip6.arpa } prometheus :9153 # CoreDNS 自身metrics 数据接口。 forward . /etc/resolv.conf { #当域名不在 Kubernetes 域时,将请求转发到预定义的解析器。 max_concurrent 1000 } cache 30 # DNS 查询缓存。 loop #环路检测,如果检测到环路,则停止CoreDNS。 reload #允许自动重新加载已更改的 Corefile。编辑 ConfigMap 配置后,请等待两分钟以使更改生效。 loadbalance #循环 DNS 负载均衡器,可以在答案中随机 A、AAAA、MX 记录的顺序。 }