问题描述
若 Pod(容器组) 长期停留在 CrashLoopBackOff 状态,表示容器在重新启动后反复崩溃。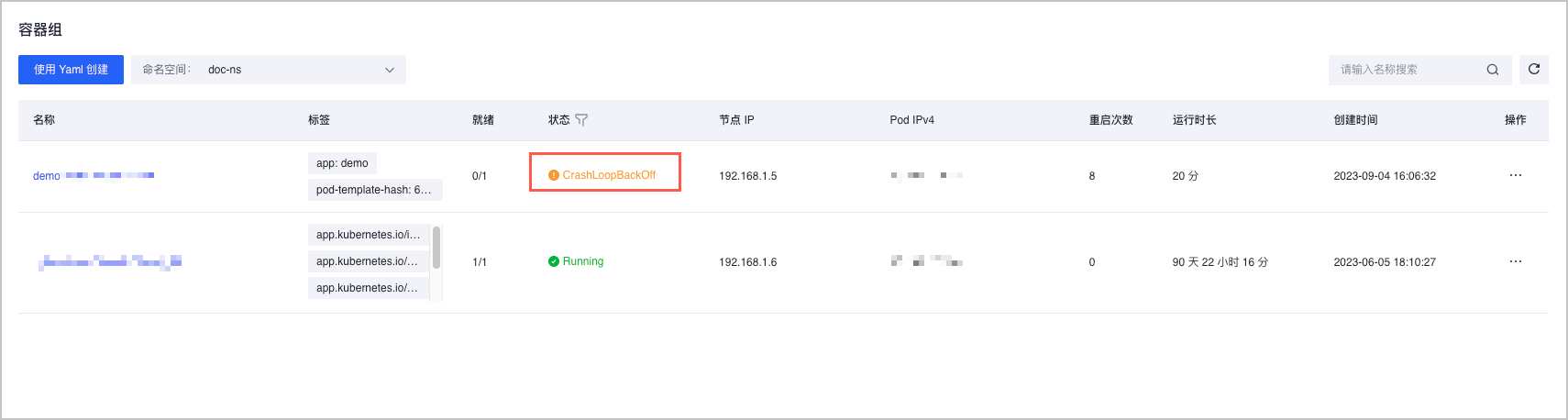
原因分析
如果 Pod 处于 CrashLoopBackOff 状态,说明容器启动存在问题。可能的原因如下:
- 容器进程主动退出
- 系统 OOM
- cgroup OOM
- 健康检查失败
解决方法
容器主动退出
容器进程主动退出时,退出状态码一般为 0~128。根据规定,正常退出时状态码为 0,状态码为 1~127 则说明为程序发生异常导致其主动退出。导致异常的原因可能来自于业务 BUG,也可能是其他原因。您可以查看 Pod 事件信息,确定退出状态码。
- 登录 容器服务控制台。
- 单击左侧导航栏中的 集群。
- 在集群列表页面,单击目标集群。
- 在集群管理页面的左侧导航栏中,单击 工作负载 > 容器组。
- 在 命名空间 下拉菜单中,选择 Pod 所在命名空间,单击目标 Pod 的名称,进入容器组详情页。

- 选择 概览 页签,在右上方选择
...> 编辑 Yaml,确认容器启动命令及相关配置是否正确。
说明
您也可以通过 kubectl 命令查看容器配置信息,命令为
kubectl get pod <pod-name> -n <pod-namespace> -o yaml。 - 选择 事件 页签,查看容器组的事件详情。
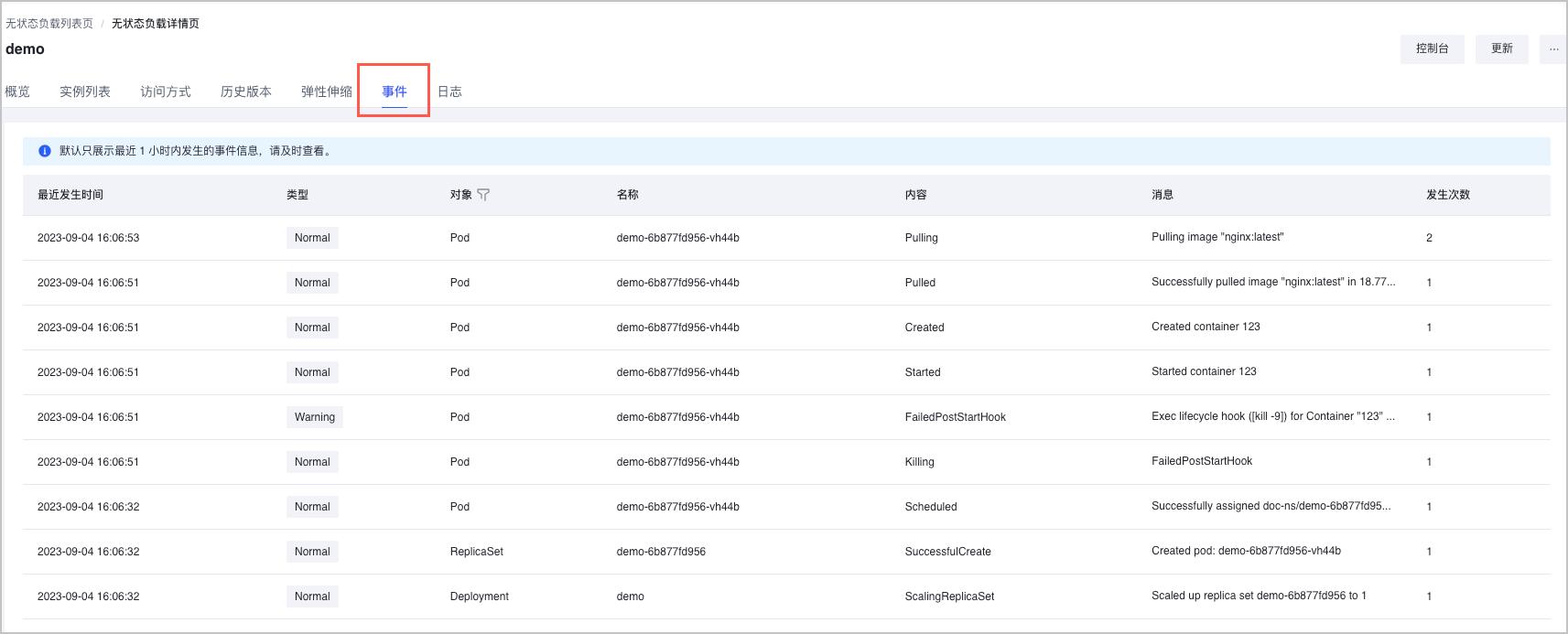
说明
您也可以通过 kubectl 命令查看 Pod 事件,命令为
kubectl descirbe pod <pod-name> -n <pod-namespace>,返回信息示例如下:Containers: demo: Container ID: containerd://83c6dd7f7930e*** Image: nginx:latest Image ID: docker.io/library/nginx@sha256:104c7c*** Port: <none> Host Port: <none> State: Waiting Reason: CrashLoopBackOff Last State: Terminated Reason: Completed Exit Code: 127 Started: Mon, 04 Sep 2023 16:28:17 +0800 Finished: Mon, 04 Sep 2023 16:28:17 +0800 Ready: False Restart Count: 9 Environment: <none> - 选择 日志 页签,查看容器组的日志详情,通过日志内容排查问题。
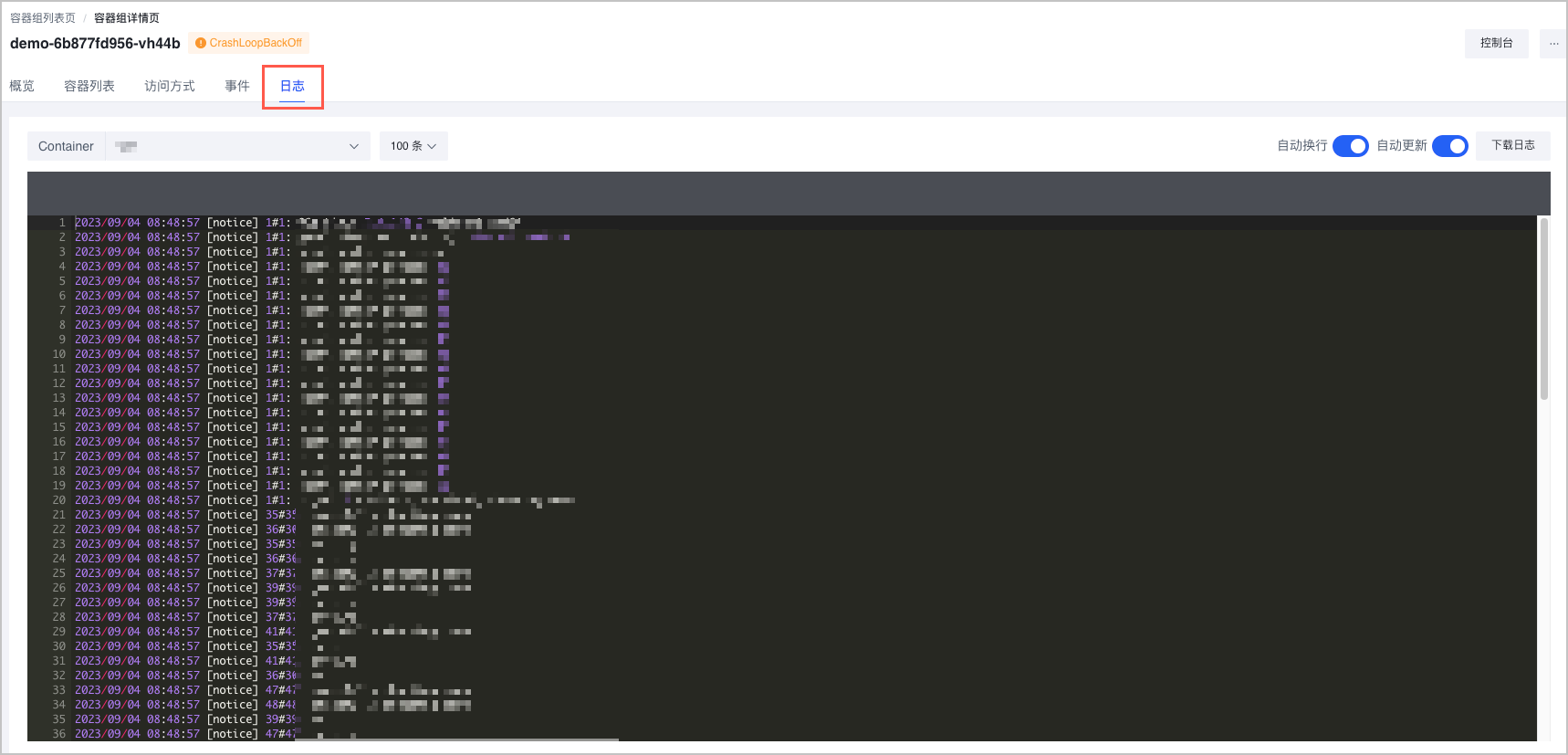
说明
您也可以通过 kubectl 命令查看容器日志信息,命令为
kubectl logs <pod-name> -n <pod-namespace> [-c CONTAINER]。
系统 OOM
如果发生系统 OOM,Pod 中容器退出状态码为 137,表示其被 SIGKILL 信号停止,同时内核将会出现以下报错信息。
Out of memory: Kill process ...
该异常通常是由于节点上部署的其他非容器进程(例如 kubelet、kube-proxy 等)消耗了过多的内存,或者是由于 kubelet 的 --kube-reserved 和 --system-reserved 分配的内存太小,没有足够的空间运行其他非容器进程。
解决方法:请根据实际需求对预留空间进行合理的调整。
cgroup OOM
如果是因 cgroup OOM 而停止的进程,可看到 Pod 事件下Reason为OOMKilled,说明容器实际占用的内存已超过 limit,同时内核日志会报Memory cgroup out of memory错误信息。
解决方法:请根据需求调整容器内存的 limit。
健康检查失败
健康检查失败,也会导致 Pod 处于 CrashLoopBackOff 状态。详情请参考 Pod 健康检查失败。