节点作为集群的基础设施,其工作状态对用户来说至关重要。火山引擎容器团队自研节点检查和自愈功能,面向节点进行常见故障检测和故障自愈。本文为您介绍如何配置节点检查自愈功能。
背景信息
自愈检查项
容器服务支持节点检查自愈功能,系统会按照规则配置,定期进行节点检查。当节点故障时,会记录 Node Event 事件,并执行自愈动作。目前支持的检查项和自愈动作,如下表所示。
| 检查项 | Event | 描述 | 自愈动作 |
|---|---|---|---|
| GPU 掉卡故障 | GpuCardFallen | 节点发生 GPU 掉卡故障 | 节点封锁、节点排干、ECS 重启、重新检测 |
| GPU 内部故障 | GpuUnknownError | 节点 GPU 发生内部故障 | 节点封锁、节点排干、ECS 重启、重新检测 |
| GPU 可恢复的内存故障 | GpuMemoryErrorRecoverable | 节点发生 GPU 可恢复的内存故障 | 节点封锁、节点排干、ECS 重启、重新检测 |
| GPU 不可恢复的内存故障 | GpuMemoryErrorUnrecoverable | 节点发生 GPU 不可恢复的内存故障 | 节点封锁 |
| GPU 运行时故障 | GpuRuntimeError | 节点 GPU 运行时相关组件故障 | 节点封锁、节点排干、ECS 重启、重新检测 |
| GPU 运行时警告 | GpuRuntimeWarning | 节点 GPU 运行时相关组件有警告信息, 用户进程不一定受损 | 节点封锁、节点排干、ECS 重启、重新检测 |
| GPU 链路故障 | GpuLinkError | 节点 GPU 链路故障或带宽使用不足 | 节点封锁 |
| GPU 链路性能下降 | GpuLinkUnhealthy | 节点 GPU 链路可用但发生掉速 | 节点封锁 |
| GPU 驱动故障 | GpuDriverError | 节点发生 GPU 驱动硬件故障 | 节点封锁、节点排干、ECS 重启、重新检测 |
| GPU 驱动警告 | GpuDriverWarning | 节点 GPU 驱动有警告信息,用户进程不一定受损 | 节点封锁、节点排干、ECS 重启、重新检测 |
| ECS 故障 | EcsFailure | ECS 发生故障时,快速摘除 ECS 上的节点,将业务受损时间从 5 分钟降低到 1分钟 | 节点排干 |
| 节点 Not Ready | NodeNotReady | 节点状态为 Not Ready 时,快速摘除节点上的 Backend,将业务受损时间降低到 1分钟 | 节点排干 |
| Kubelet 故障 | KubeletUnhealthy | Kubelet 运行状态异常导致节点不可用 | 重启 kubelet 服务 |
| Runtime 故障 | RuntimeUnhealthy | containerd / docker 运行状态异常导致节点不可用 | 重启 containerd 服务 |
| 时间同步服务异常 | NTPProblem | 时钟同步服务(chrony)异常 | 重启 chrony 服务 |
| 节点文件系统只读 | ReadonlyFilesystem | 节点文件系统变为只读,导致节点上业务运行异常 | 重启 ECS 实例 |
| 节点内核故障 | KernelOops | 节点存在内核错误,影响节点上的容器服务正常运行 | 重启 ECS 实例 |
| 节点内核死锁 | KernelHasNoDeadlock | 节点内核存在死锁 | 重启 ECS 实例 |
说明
- 在执行 kubelet 故障 与 Runtime 故障 修复时,会同时判断 kubelet 与 containerd 服务是否正常,如果存在服务异常则会一起修复。
- 【邀测·申请试用】节点 Not Ready 检查项目前处于邀测阶段,如需使用,请提交申请。
自愈流程
容器服务节点检查 GPU 相关规则的自愈流程,如下图所示。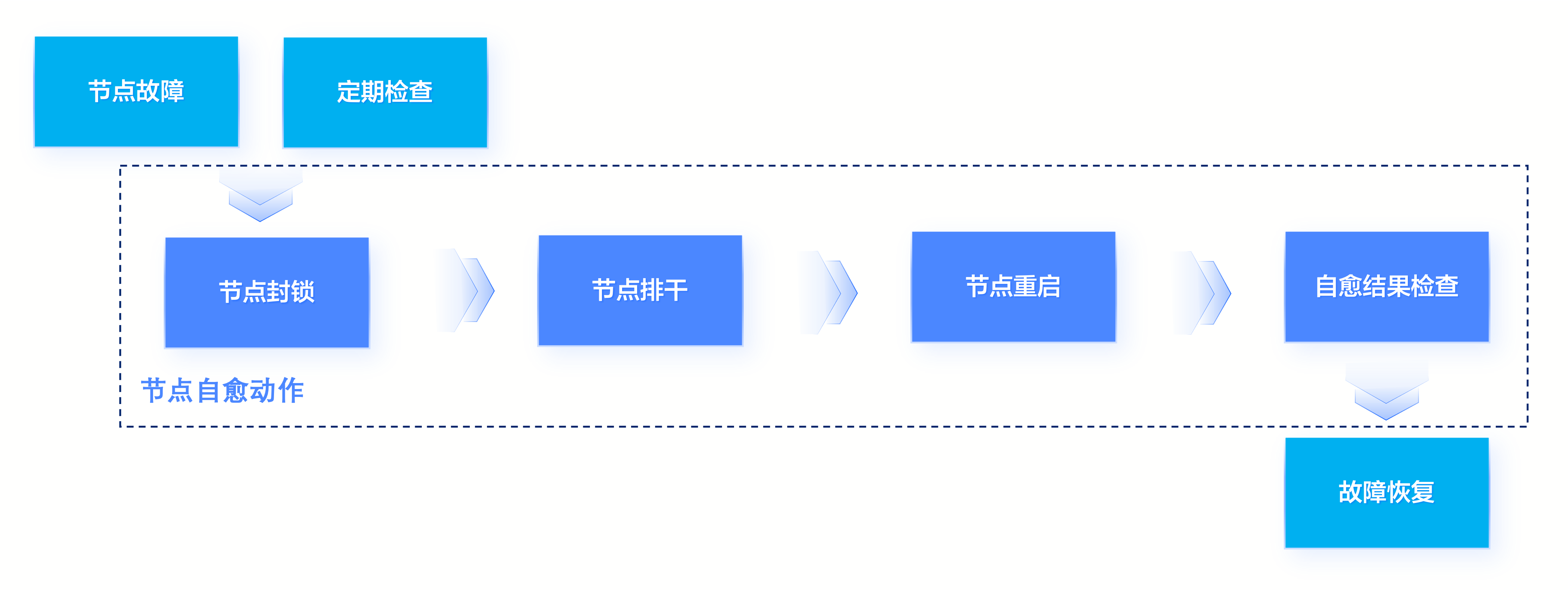
自愈任务事件
节点池绑定检查自愈规则后,系统会按照规则配置,定期进行节点检查。当节点 GPU 故障时,会记录 Node Event 事件。您可以在 事件中心 查看对应的事件。检查项和事件的对应关系,如下表所示。
| 事件 | 事件描述 | 消息 | 消息描述 | 事件类别 |
|---|---|---|---|---|
| NodeRepair | 开始自动故障处理 | Node {nodename} begin to repair | 开始执行故障处理 | Normal |
| NodeRepairAction | 自动故障处理 | Node {nodename} status is now: NodeCordon | 异常时禁止调度 | Warning |
| Node {nodename} status is now: NodeDrainStart | 开始排干节点 | Warning | ||
| Node {nodename} status is now: NodeDrainCompleted | 排干节点完成 | Normal | ||
| Node {nodename} status is now: InstanceReboot | 排干后重启 ECS | Normal | ||
| Node {nodename} status is now: InstanceForceReboot | 未排干强制重启 ECS | Warning | ||
| Node {nodename} status is now: NotReady | 将节点置为 NotReady | Warning | ||
| Node {nodename} status is now: Eviting | 开始驱逐 Backend | Warning | ||
| Node {nodename} status is now: RecreateStatfulsetPod_{Statefulset 名称} | 重建 Statefulset Pod | Normal | ||
| NodeRepairActionFailed | 自动故障处理失败 | Node {nodename} status is now: NodeIngressControllerExist | 排干前检查节点运行了 ingress-controller pod | Warning |
| Node {nodename} status is now: NodeBindPodExist | 排干前检查节点存在强绑定节点的工作负载 | Warning | ||
| Node {nodename} status is now: NodeSingleInstanceWorkloadExist | 排干前检查节点存在单副本工作负载 | Warning | ||
| Node {nodename} status is now: NodeStaticPodExist | 排干前检查节点存在 static pod | Warning | ||
| Node {nodename} status is now: {Gpu 故障事件}AfterRepairAction | 故障自愈后再检测故障仍然异常 | Warning | ||
| Node {nodename} status is now: EvitionFailed | 驱逐 Backend 失败 | Warning | ||
| Node {nodename} status is now: RecreateStatfulsetPodFailed_{Statefulset 名称} | 重建 Statefulset Pod 失败 | Warning | ||
| Node {nodename} status is now: NodeRepairActionTerminated | 自愈动作被终止 | Normal | ||
| NodeRepairActionSucceeded | 自动故障处理成功 | {Gpu 故障事件}RecoveredAfterRepairAction | 故障自愈后再检测故障恢复 | Normal |
说明
前提条件
已在集群中安装 node-problem-detector 组件,并升级至 v0.8.19-vke.1 及以上版本。详情请参见 安装组件。
操作步骤
步骤一:配置检查自愈规则
- 登录 容器服务控制台。
- 单击左侧导航栏中的 集群。
- 在集群列表页面,单击目标集群,进入集群管理页面。
- 在集群管理页面的左侧导航栏中,单击 检查自愈。单击 创建检查和自愈规则,创建规则。
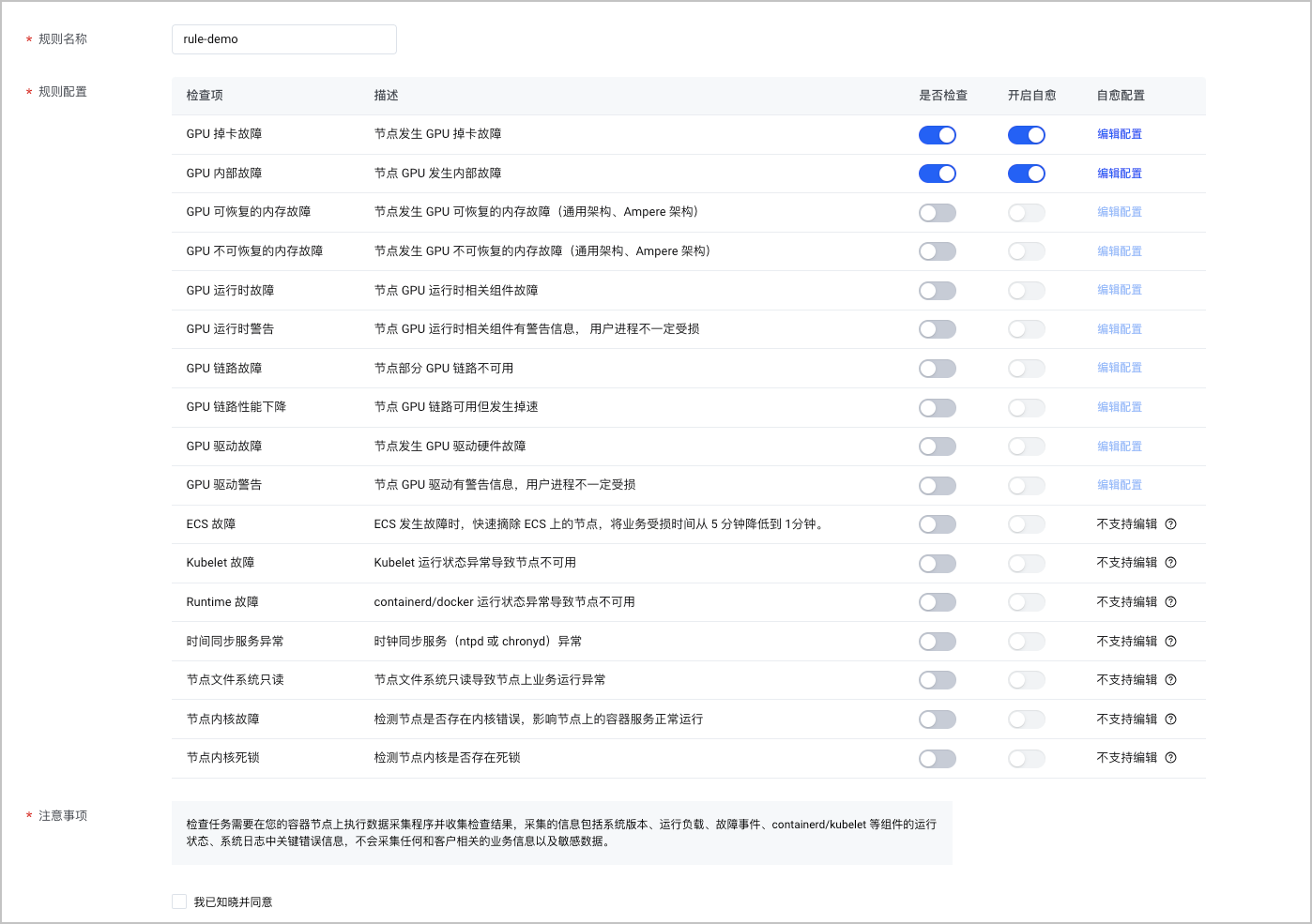
配置项 说明 规则名称 配置检查自愈规则的名称。同一个集群下,规则名称必须唯一。 规则配置
在预置检查项中选择需要检查的项目,并配置异常时是否开启自愈。
- 是否检查:开启或关闭具体的检查项。
- 开启自愈:配置检查异常时,是否开启节点自愈。当开启该功能,且检查异常时,系统会执行自愈动作。
自愈配置 单击 编辑配置,允许配置该检查项的自愈动作。部分检查项不支持配置自愈动作,系统缺省的自愈动作,请参见 自愈检查项。 - 开启自愈功能时,配置自愈动作。
- 异常时封锁节点:当开启该功能且检查异常时,系统会给对应的节点打上污点,禁止 Pod 调度到该节点。
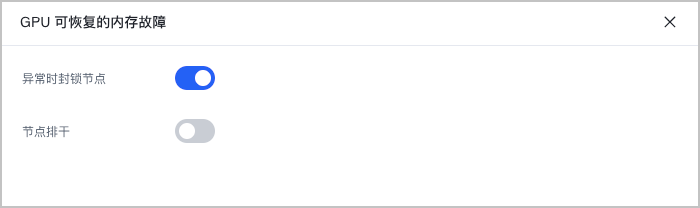
- 节点排干:当开启该功能且检查异常时,系统会终止并驱离节点上的工作负载。保证业务不会被部署在故障的节点上。

配置项 说明 节点排干时间
配置从节点被封锁到开始进行 Pod 驱逐的时间。支持多种时间段选择,包括:立刻、15 分钟、30 分钟、1 小时、2 小时、3 小时、6 小时、12 小时、24 小时、36 小时、2 天、3 天、4 天、5 天、6 天、7 天等。
注意
节点排干前会检查节点是否运行了以下工作负载,您需要确保节点上不存在这些工作负载,否则将不会进行节点排干的操作:
- ingress-controller pod
- 强绑定节点的工作负载
- 单副本的工作负载
- static pod
节点排干不能完全保证终止/驱离节点上的工作负载,如果有工作负载无法被驱离,在不进行人工干预的前提下,将不会执行下一步自愈操作直至强制重启(若配置强制重启时间)。
- 排干后重启 ECS:当开启该功能时。节点排干后会在指定的时间后重启,尝试修复节点故障,完成自愈。

配置项 说明 最长重启等待时间 配置从节点排干到重启的时间。支持多种时间段选择,包括:30 分钟、1 小时、2 小时、3 小时、6 小时。 修复成功后解除节点封锁
配置节点重启并修复故障后,是否自动解除封锁。当开启该功能时,节点重启后系统会再次进行 GPU 检测,当所有检测项均无异常时,将解除节点封锁。
注意
系统仅能确保的已有检测项无异常,若发生超出节点检测项范围的故障,仍有可能导致训练或推理任务运行异常,如果自愈流程完成后,仍然存在问题,请 提交工单 获取技术支持。
- 异常时封锁节点:当开启该功能且检查异常时,系统会给对应的节点打上污点,禁止 Pod 调度到该节点。
- 配置完成后,勾选 我已知晓并同意,单击 确定,完成配置。
步骤二:节点池绑定检查自愈规则
您可以在创建节点池时绑定检查自愈规则,也可以为存量节点池绑定检查自愈规则。本文以创建节点池时绑定检查自愈规则为例。
- 在集群管理页面的左侧导航栏,选择 节点管理 > 节点池,单击 创建节点池,创建新的节点池,并在 运维配置 处绑定检查自愈规则。

配置项 说明 检查和自愈
配置是否开启节点检查自愈功能。
- 开启:通过配置节点自愈规则,系统会自动检查节点上的 GPU 卡状态,当 GPU 卡故障时及时封锁节点,禁止 Pod 调度到节点上。
- 关闭:(默认)不开启节点检查自愈功能。
检查和自愈规则 在下拉菜单中选择节点检查自愈规则。 说明
节点池的其他配置详情,请参见 创建节点池。
- 单击 确定,完成绑定。
后续操作
查看检查自愈规则
- 在集群管理页面的左侧导航栏中,单击 检查自愈。
- 在自愈规则列表中,单击检查自愈规则名称,即可查看规则的详情。
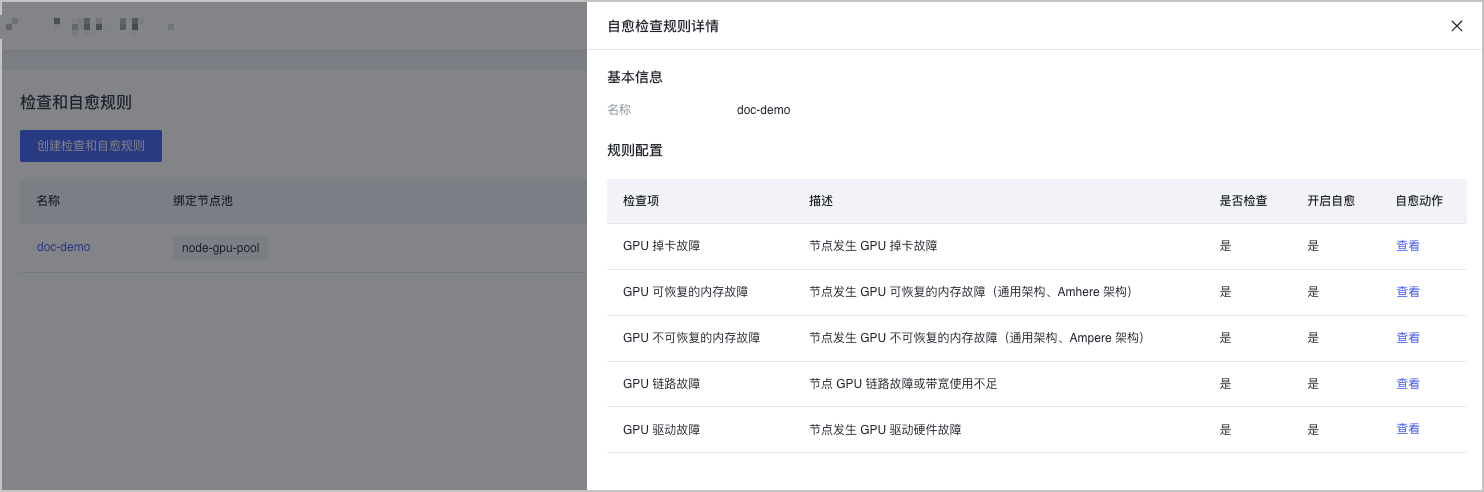
- 单击 自愈动作 列的 查看,可以查看自愈动作的配置详情。
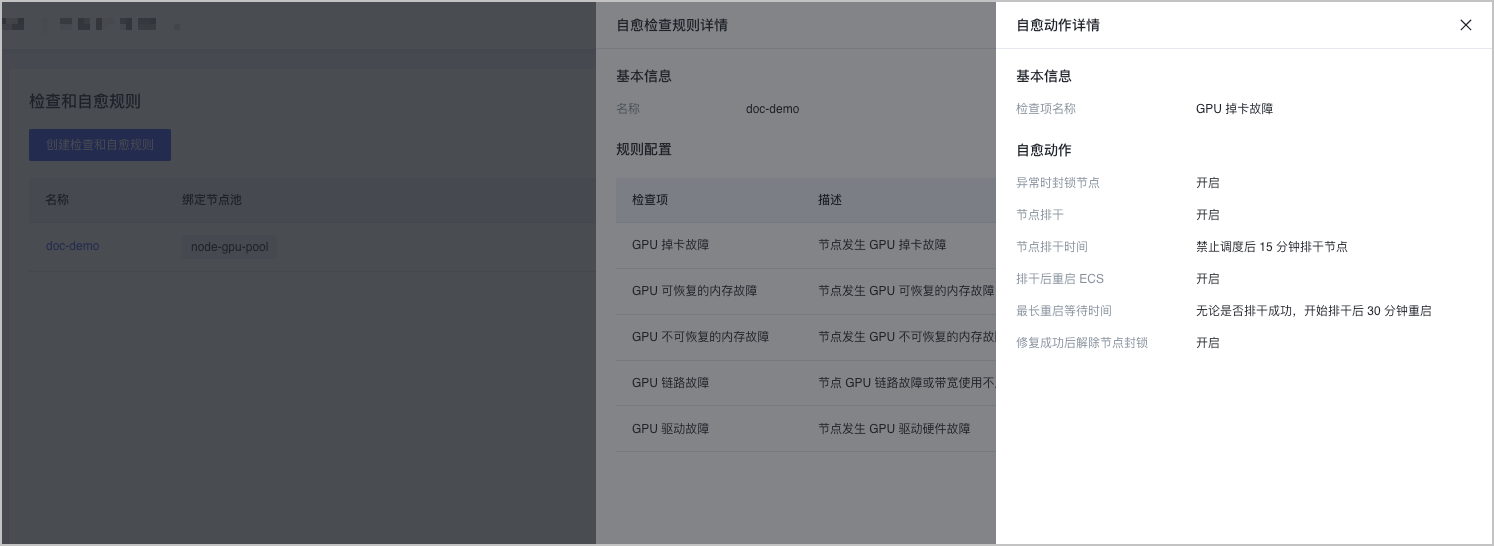
查看自愈任务详情
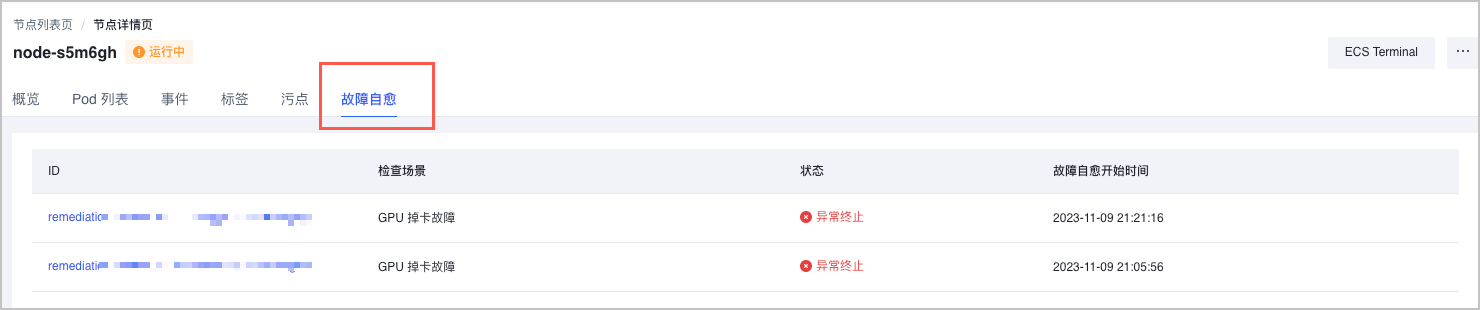
- 在集群管理页面的左侧导航栏,选择 节点。
- 单击目标节点名称,进入节点详情页面。
- 选择 故障自愈 页签,即可查看当前节点的故障自愈任务详情。
配置检查自愈观测
为方便用户及时发现检查自愈规则事件,系统支持使用云原生观测,基于检查规则自愈的行为和节点的常见故障进行观测和告警。详情请参见 检查自愈观测。
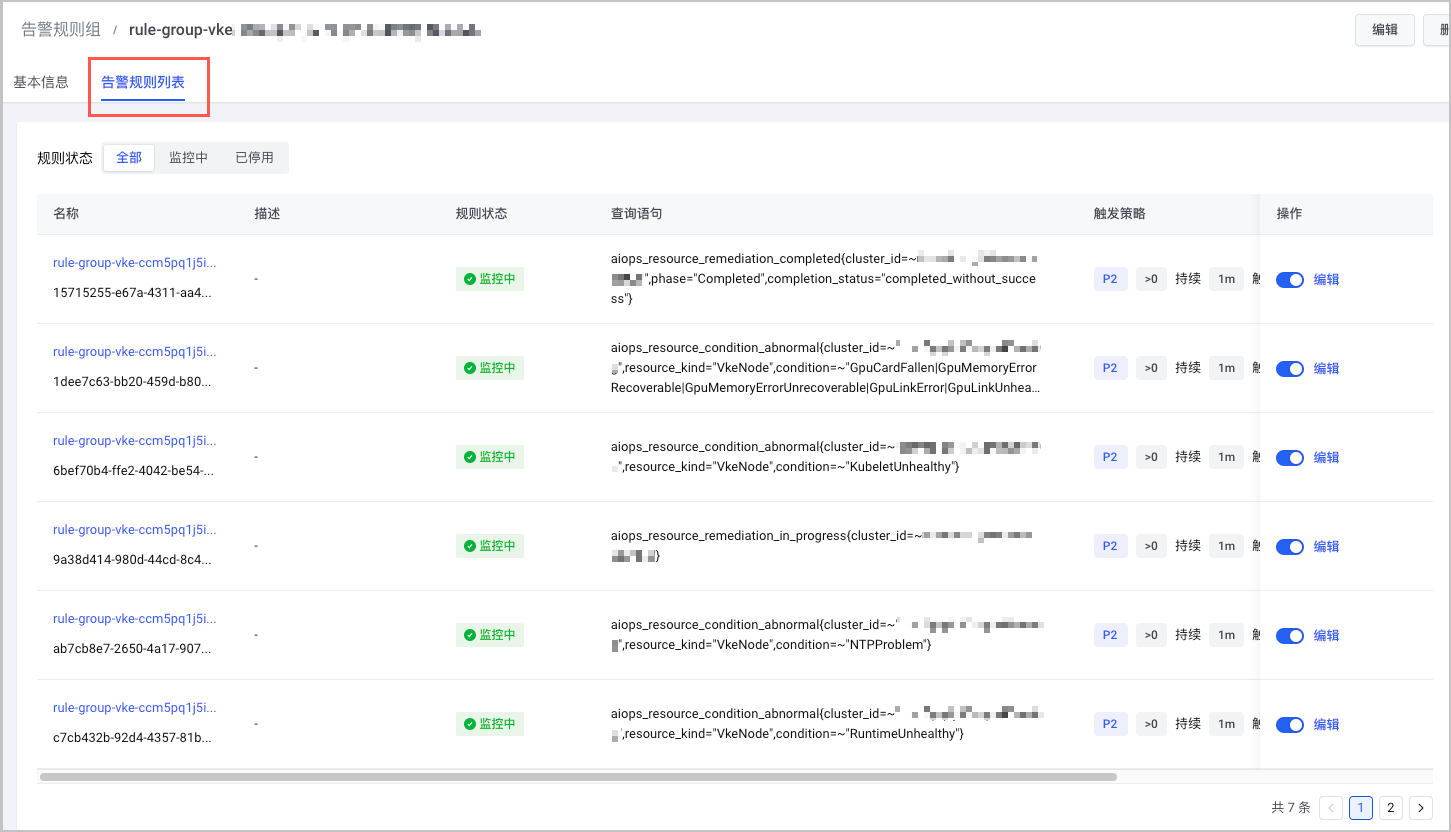
查看告警规则详情
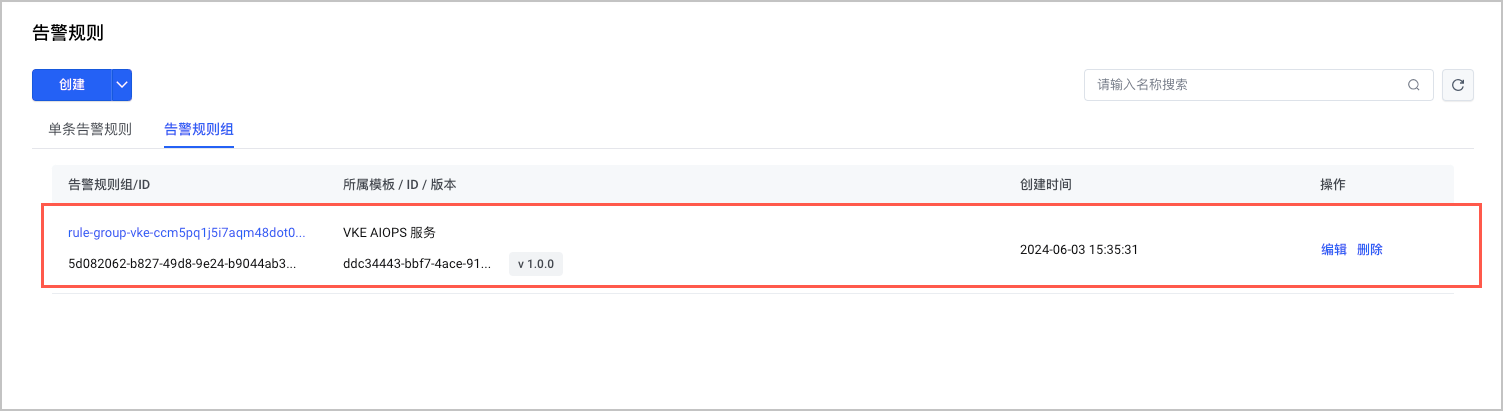
配置检查自愈告警后,可以在 VMP 控制台查看对应的告警规则详情。
- 登录 VMP 服务控制台。
- 单击左侧导航栏的 告警中心 > 告警规则。在 告警规则组 页签中,查看配置的检查自愈告警规则组。
- 单击告警规则组名称,进入告警规则组详情页面,选择 告警规则列表 页签,查看告警规则详情。