控制面服务观测允许您监控集群控制面核心组件的工作状态。本文为您介绍如何配置控制面服务观测功能。
前提条件
已开启云原生观测功能,详情请参见 开启观测。
操作步骤
步骤一:开启观测
- 登录 容器服务控制台。
- 在左侧导航栏单击 集群,找到目标集群,单击集群名称。
- 在集群管理页面的左侧导航栏中,单击 观测配置,并选择 基础观测 页签。
- 选择 控制面服务 卡片,单击 启用,开启控制面服务观测。
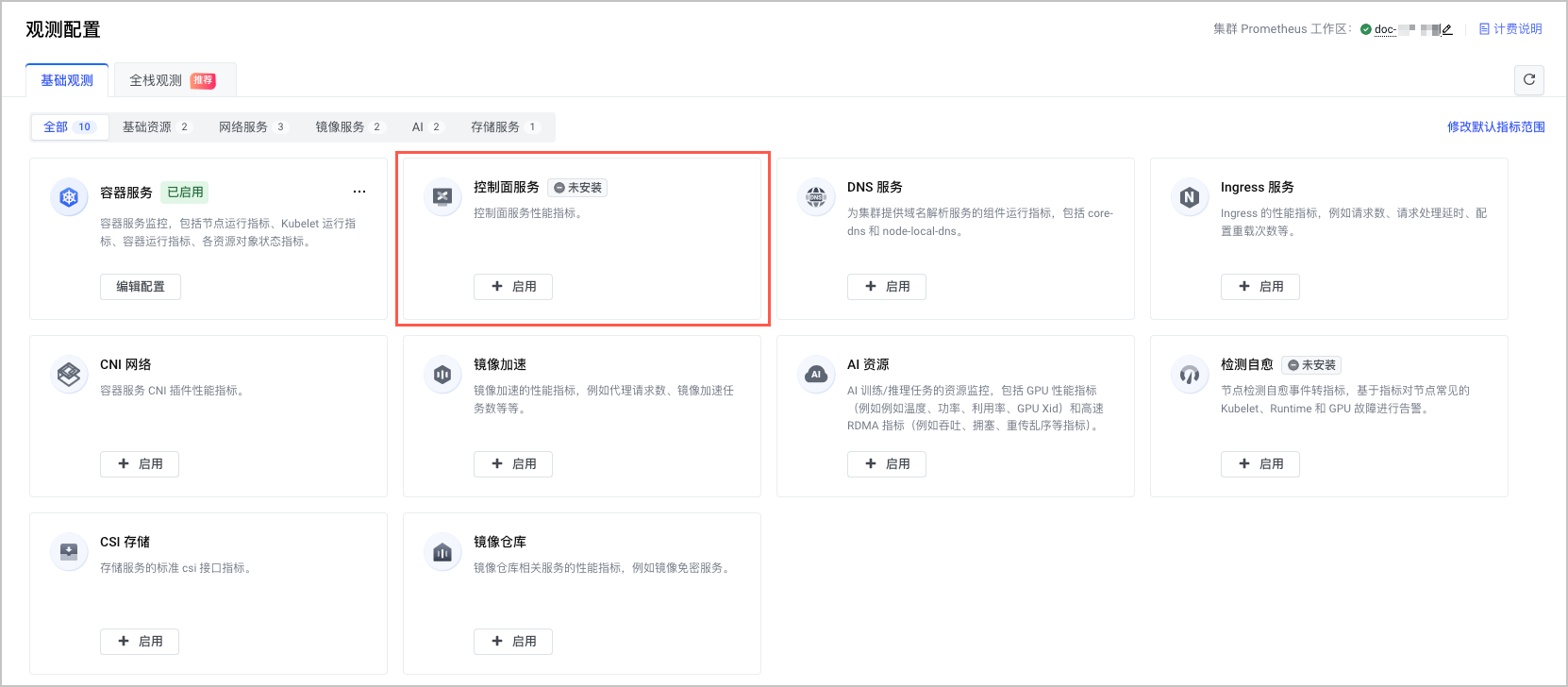
- 系统自动检查开启控制面服务观测所需的必要条件。包括:工作区配置。

- 单击 开启,开启控制面服务观测。
步骤二:配置采集规则
控制面组件监控开启后,您可以配置采集规则,选择需要采集的目标组件、具体指标项及采集间隔。可以根据实际需求丢弃一些不用的指标。
- 在集群管理页面的左侧导航栏中,单击 观测配置,并选择 基础观测 页签。
- 选择 控制面服务 卡片,单击 编辑配置 并选择 指标 页签,在组件列表 操作 列,单击开关,开启或关闭组件的采集规则。当关闭组件的采集规则时,系统不会采该集组件的所有指标。
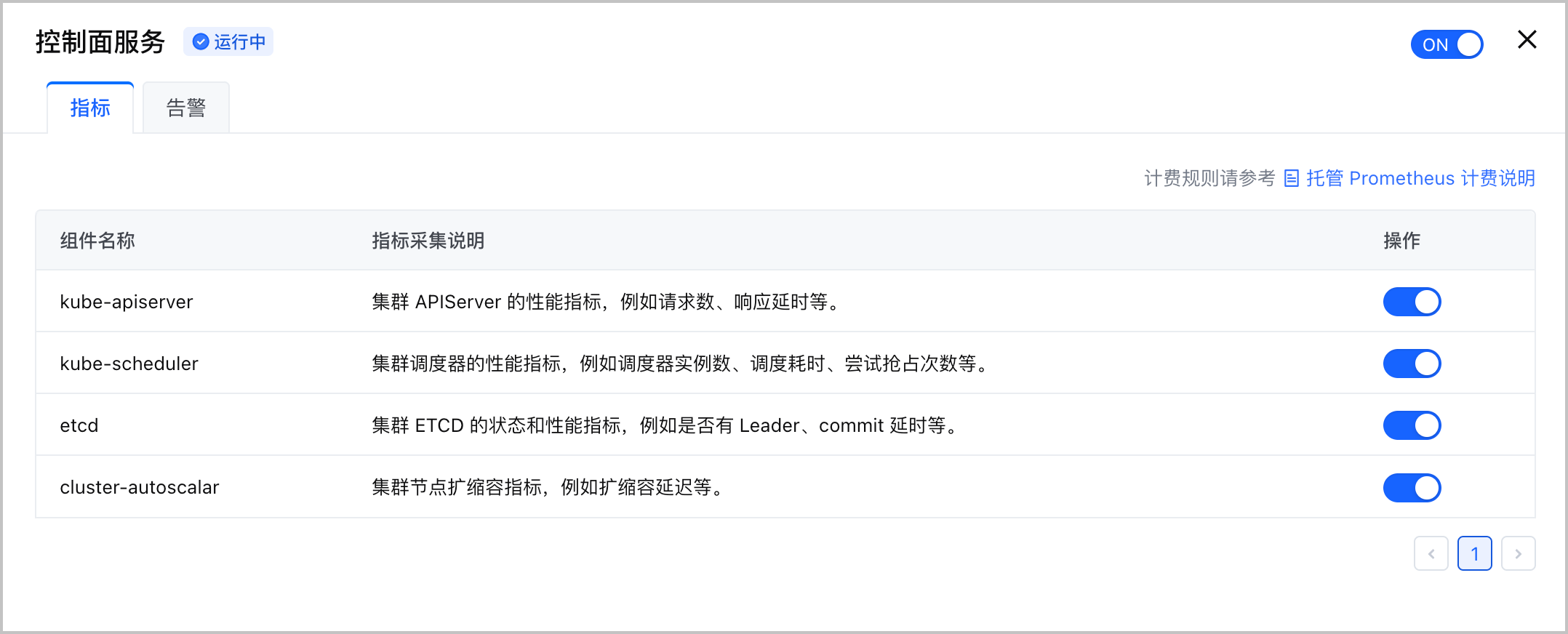
- 单击 确认,完成配置。
步骤三:配置告警
您可以基于系统预置的告警模板,快速完成控制面服务观测的告警配置。
- 在集群管理页面的左侧导航栏中,单击 观测配置,并选择 基础观测 页签。
- 选择 控制面服务 卡片,单击 编辑配置 并选择 告警 页签,配置告警的相关参数。
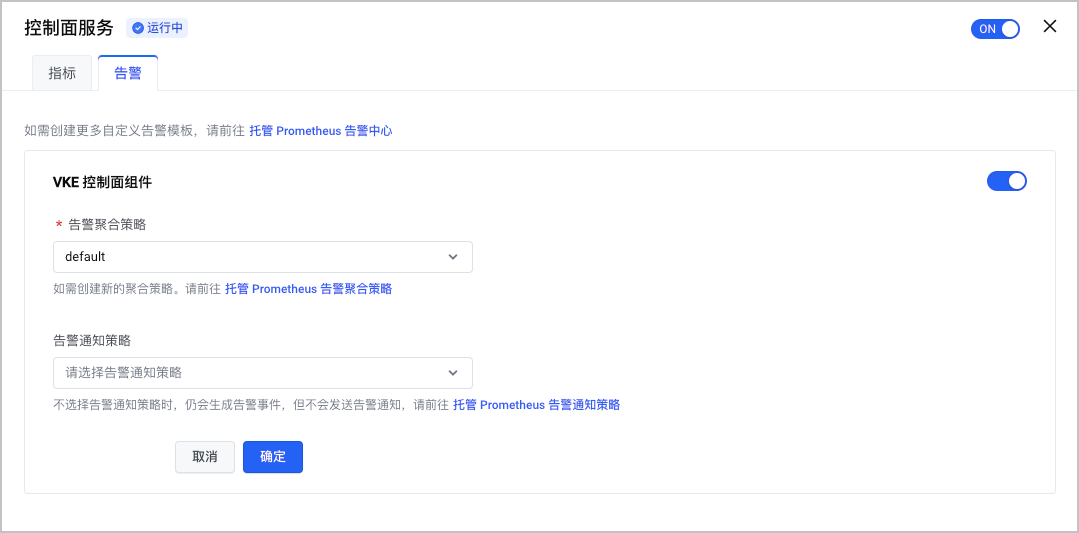
配置项 说明 告警模版 单击开启需要的告警模版。 告警聚合策略 在下拉菜单中选择告警聚合策略。详情请参见 创建告警聚合策略。 告警通知策略 在下拉菜单中选择告警通知策略。系统会使用通知策略中配置的告警等级和联系人组,将告警发送给指定的联系人。详情请参见 创建告警通知策略。 - 单击 确定,完成配置。
说明
如果告警模板无法满足您的要求,也可以在托管 Prometheus 的告警中心配置自定义告警,详情请参见 创建告警规则。
观测看板
kube-apiserver 监控
配置控制平面组件监控后,您可以查看控制面组件的指标大盘。设置查询的时间段,并指定刷新方式(手动刷新、自动刷新)。
- 在集群管理页面的左侧导航栏中,选择 监控中心 > 监控看板。
- 在左侧看板列表中选择 核心组件监控 > kube-apiserver 监控,即可查看监控看板。
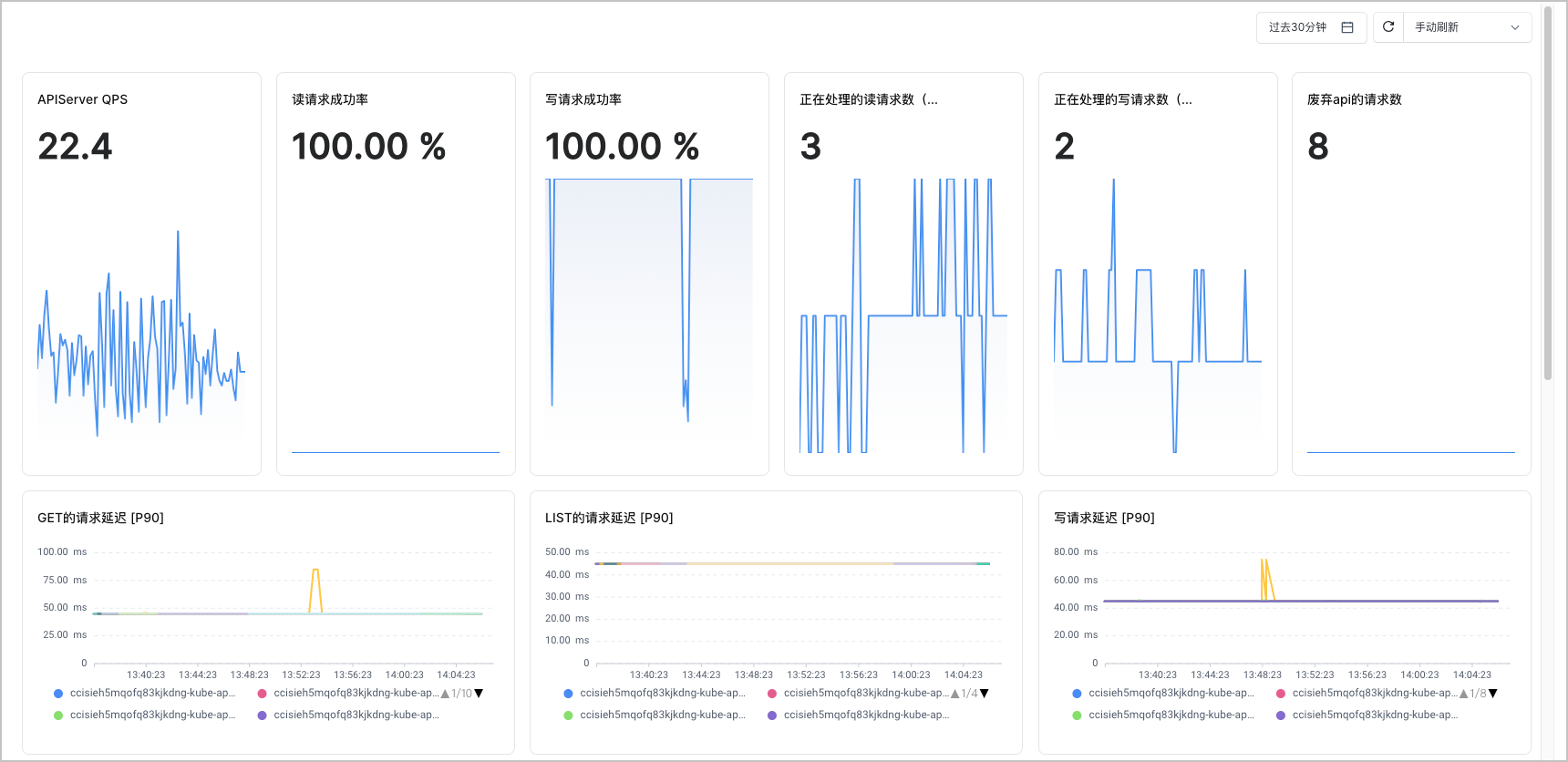
该看板的指标清单如下表所示。
| 看板名称 | PromQL 语句 |
|---|---|
| APIServer QPS | sum(irate(apiserver_request_total{cluster="$clusterId"}[1m])) |
| 读请求成功率 | sum(irate(apiserver_request_total{cluster="$clusterId",code=~"20.*",verb=~"GET|LIST"}[1m]))/sum(irate(apiserver_request_total{cluster="$clusterId",verb=~"GET|LIST"}[1m]))*100 |
| 写请求成功率 | sum(irate(apiserver_request_total{cluster="$clusterId",code=~"20.*",verb!~"GET|LIST|WATCH|CONNECT"}[5m]))/sum(irate(apiserver_request_total{cluster="$clusterId",verb!~"GET|LIST|WATCH|CONNECT"}[5m]))*100 |
| 正在处理的读请求数(当前值) | sum(apiserver_current_inflight_requests{cluster="$clusterId",request_kind="readOnly"}) |
| 正在处理的写请求数(当前值) | sum(apiserver_current_inflight_requests{cluster="$clusterId",request_kind="mutating"}) |
| 废弃 api 的请求数 | sum(apiserver_requested_deprecated_apis{cluster="$clusterId"}) |
| GET 的请求延迟 [P90] | histogram_quantile(0.90, sum(irate(apiserver_request_duration_seconds_bucket{cluster="$clusterId",verb="GET",resource!="",subresource!~"log|proxy"}[1m])) by ( verb, instance,resource, le)) |
| LIST 的请求延迟 [P90] | histogram_quantile(0.90, sum(irate(apiserver_request_duration_seconds_bucket{cluster="$clusterId",verb="LIST",resource!="",subresource!~"log|proxy"}[1m])) by ( verb, instance,resource, le)) |
| 写请求延迟 [P90] | histogram_quantile(0.90, sum(irate(apiserver_request_duration_seconds_bucket{cluster="$clusterId",verb!~"GET|WATCH|LIST|CONNECT",resource!="",subresource!~"log|proxy"}[1m])) by ( verb, instance,resource, le)) |
| APIServer 非 2XX 返回值的读请求 | sum by (instance, resource)(increase(apiserver_request_total{cluster="$clusterId",verb="GET", resource!="", code!~"2.."}[1m]) ) |
| APIServer 非 2XX 返回值的写请求 | sum by (instance, resource)(increase(apiserver_request_total{cluster="$clusterId",verb=~"^(POST|PUT|PATCH|DELETE)$", resource!="", code!~"2.."}[1m]) ) |
| APIServer 在处理的读请求数 | sum(apiserver_current_inflight_requests{cluster="$clusterId",request_kind="readOnly"})by(instance) |
| APIServer 在处理的写请求数 | sum(apiserver_current_inflight_requests{cluster="$clusterId",request_kind="mutating"})by(instance) |
| Admit 准入控制器时延 [P90] | histogram_quantile(0.9, sum by(operation, le, type, rejected) (irate(apiserver_admission_controller_admission_duration_seconds_bucket{cluster="$clusterId",type="admit"}[1m]))) |
| Validate 准入控制器时延 [P90] | histogram_quantile(0.9, sum by(operation, le, type, rejected) (irate(apiserver_admission_controller_admission_duration_seconds_bucket{cluster="$clusterId",type="validate"}[5m]))) |
| Admit 准入 Webhook 时延 [P90] | histogram_quantile(0.90, sum by(operation, type,le, rejected) (rate(apiserver_admission_webhook_admission_duration_seconds_bucket{cluster="$clusterId",type="admit"}[5m]))) |
| Validate 准入 Webhook 时延 [P90] | histogram_quantile(0.90, sum by(operation,le, type, rejected) (rate(apiserver_admission_webhook_admission_duration_seconds_bucket{cluster="$clusterId",type="validating"}[5m]))) |
| UserAgent 请求 QPS Top 10 | topk(10,sum(rate(apiserver_request_useragent_total{cluster="$ClusterId"}[5m])) by(useragent,verb,resource)) |
| UserAgent List 请求 QPS Top 10 | topk(10,sum(rate(apiserver_request_useragent_total{cluster="$ClusterId",verb="LIST"}[5m])) by(useragent,resource)) |
说明
如果您需要在托管 Prometheus 中的 Explore 功能或告警中心使用上述 PromQL 语句查看具体的指标或配置告警,请修改或删除语句中关于集群、节点、容器组的变量。例如:将 cluster=~"$ClusterId"参数中的$ClusterId变量修改为具体的集群 ID ,或直接删除该参数。
etcd 监控
配置控制平面组件监控后,您可以查看控制面组件的指标大盘。设置查询的时间段,并指定刷新方式(手动刷新、自动刷新)。
- 在集群管理页面的左侧导航栏中,选择 监控中心 > 监控看板。
- 在左侧看板列表中选择 核心组件监控 > etcd 监控,即可查看监控看板。
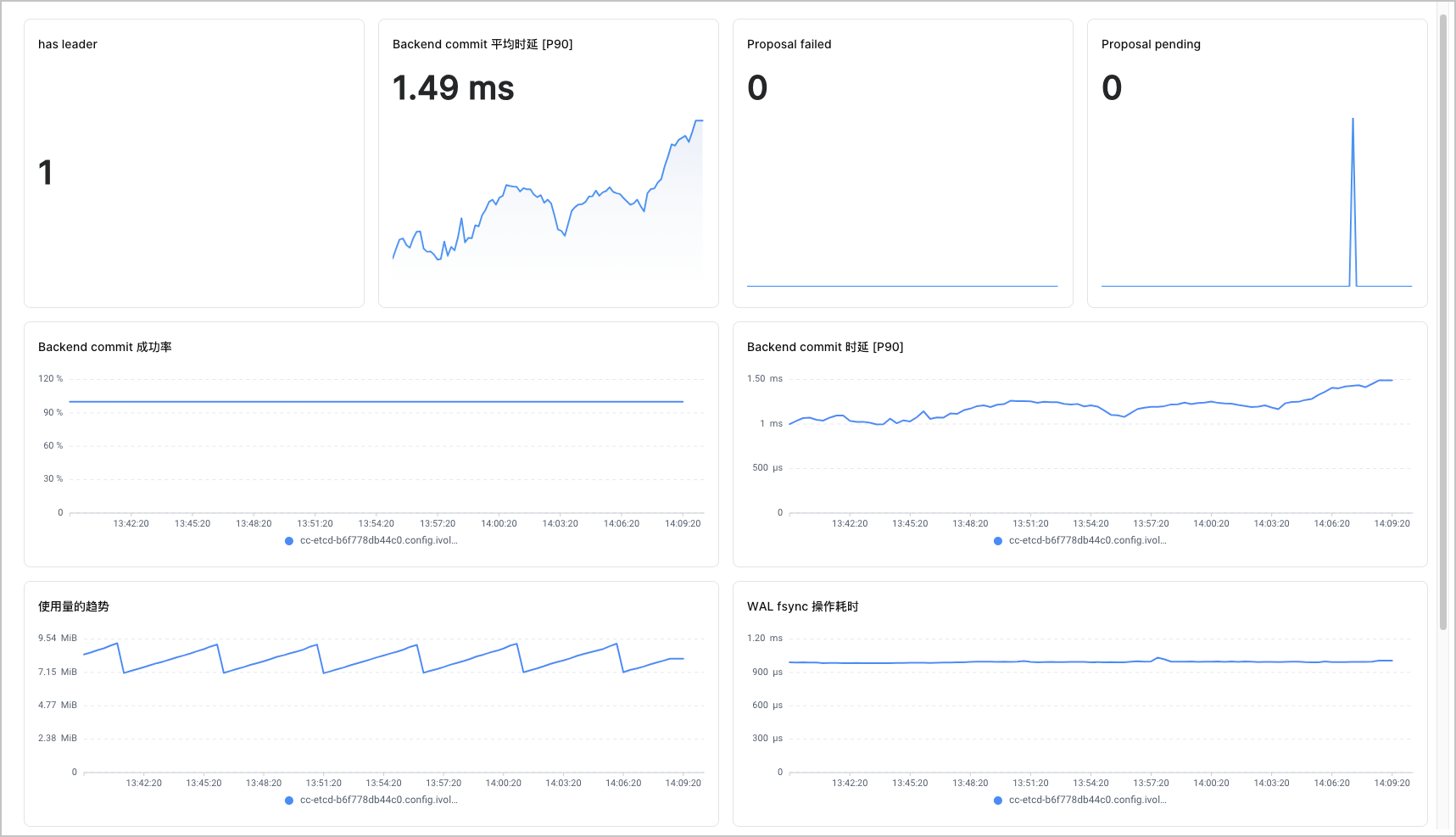
该看板的指标清单如下表所示。
| 看板名称 | PromQL 语句 |
|---|---|
| has leader | etcd_server_has_leader{cluster="$clusterId"} |
| Backend commit 平均时延 [P90] | histogram_quantile(0.9, avg(rate(etcd_disk_backend_commit_duration_seconds_bucket{cluster="$clusterId"}[5m]))by (instance, le)) |
| Proposal failed | sum(etcd_server_proposals_failed_total{cluster="$clusterId"}) |
| Proposal pending | sum(etcd_server_proposals_pending{cluster="$clusterId"}) |
| Backend commit 成功率 | sum(etcd_server_proposals_applied_total{cluster="$clusterId"})by(instance)/sum(etcd_server_proposals_committed_total{cluster="$clusterId"})by(instance)*100 |
| Backend commit 时延 [P90] | histogram_quantile(0.9, sum(rate(etcd_disk_backend_commit_duration_seconds_bucket{cluster="$clusterId"}[5m]))by (instance, le)) |
| 使用量的趋势 | etcd_mvcc_db_total_size_in_use_in_bytes{cluster="$clusterId"} |
| WAL fsync 操作耗时 | histogram_quantile(0.90, rate(etcd_disk_wal_fsync_duration_seconds_bucket{cluster="$clusterId"}[5m])) |
| Proposal failed 数量趋势 | etcd_server_proposals_failed_total{cluster="$clusterId"} |
| Proposal pending 数量趋势 | etcd_server_proposals_pending{cluster="$clusterId"} |
| Proposal commit - apply 数量趋势 | abs(etcd_server_proposals_committed_total{cluster="$clusterId"}-etcd_server_proposals_applied_total{cluster="$clusterId"}) |
说明
如果您需要在托管 Prometheus 中的 Explore 功能或告警中心使用上述 PromQL 语句查看具体的指标或配置告警,请修改或删除语句中关于集群、节点、容器组的变量。例如:将 cluster=~"$ClusterId"参数中的$ClusterId变量修改为具体的集群 ID ,或直接删除该参数。
kube-scheduler 监控
配置控制平面组件监控后,您可以查看控制面组件的指标大盘。设置查询的时间段,选择查询的实例,并指定刷新方式(手动刷新、自动刷新)。
- 在集群管理页面的左侧导航栏中,选择 监控中心 > 监控看板。
- 在左侧看板列表中选择 核心组件监控 > kube-scheduler 监控,即可查看监控看板。
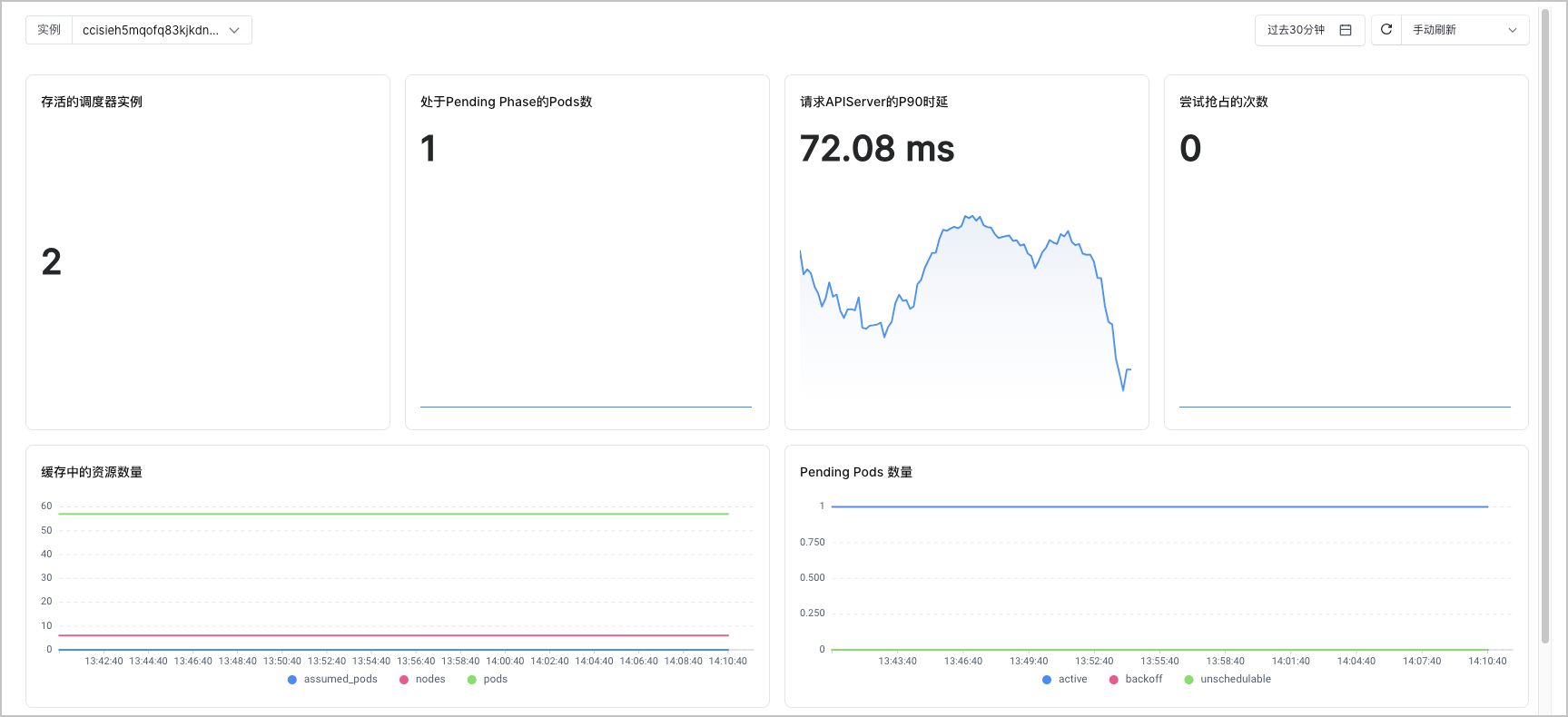
该看板的指标清单如下表所示。
| 看板名称 | PromQL 语句 |
|---|---|
| 存活的调度器实例 | count(sum(scheduler_pod_scheduling_attempts_sum{cluster="$clusterId"})by(instance)) |
| 处于 Pending Phase 的 Pods 数 | sum(scheduler_pending_pods{cluster="$clusterId",instance=~"$instances"}) |
| 请求 APIServer 的 P90 时延 | sum(histogram_quantile(0.9, sum(rate(rest_client_request_duration_seconds_bucket{cluster="$clusterId"}[5m])) by (verb,url,le))) |
| 尝试抢占的次数 | sum(scheduler_preemption_attempts_total{cluster="$clusterId",instance=~"$instances"}) |
| 缓存中的资源数量 | sum(scheduler_scheduler_cache_size{cluster="$clusterId",type="assumed_pods",instance=~"$instances"})by(type) |
| Pending Pods 数量 | sum(scheduler_pending_pods{cluster="$clusterId",instance=~"$instances"})by(queue) |
| 各阶段 Pod 调度数量 | sum(increase(scheduler_scheduling_algorithm_duration_seconds_count{cluster="$clusterId",instance=~"$instances"}[1m])) |
| 各阶段 Pod 调度耗时 | histogram_quantile(0.99, sum(rate(scheduler_e2e_scheduling_duration_seconds_bucket{cluster="$clusterId",instance=~"$instances"}[5m])) by (le)) |
| 请求 APIServer 的 QPS | sum(rate(rest_client_requests_total{cluster="$clusterId"}[1m])) by (method,code) |
| 请求 APIServer 的时延趋势图 [P90] | histogram_quantile(0.9, sum(rate(rest_client_request_duration_seconds_bucket{cluster="$clusterId"}[1m])) by (verb,url,le)) |
说明
如果您需要在托管 Prometheus 中的 Explore 功能或告警中心使用上述 PromQL 语句查看具体的指标或配置告警,请修改或删除语句中关于集群、节点、容器组的变量。例如:将 cluster=~"$ClusterId"参数中的$ClusterId变量修改为具体的集群 ID ,或直接删除该参数。
cluster-autoscaler 监控
配置控制平面组件监控后,您可以查看控制面组件的指标大盘。设置查询的时间段,选择查询的实例,并指定刷新方式(手动刷新、自动刷新)。
- 在集群管理页面的左侧导航栏中,选择 监控中心 > 监控看板。
- 在左侧看板列表中选择 核心组件监控 > cluster-autoscaler 监控,即可查看监控看板。
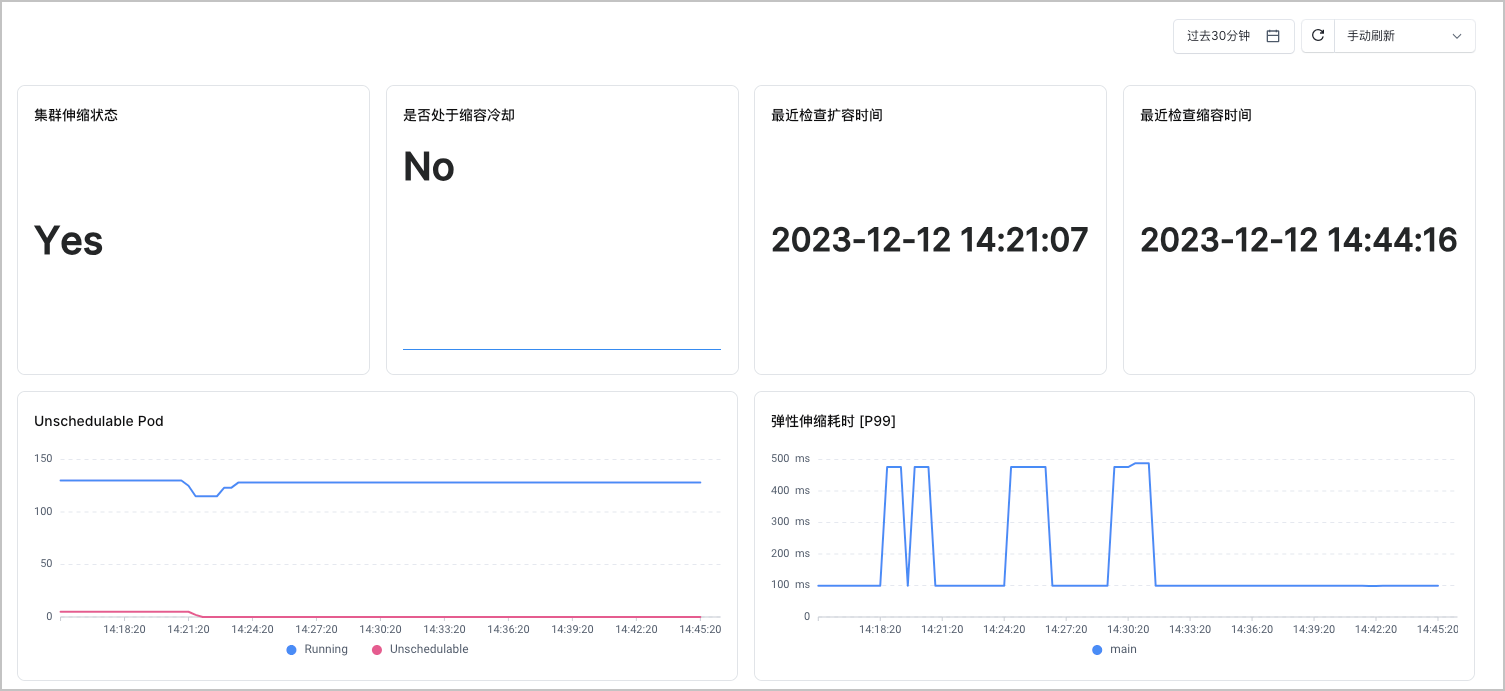
该看板的指标清单如下表所示。
| 看板名称 | PromQL 语句 |
|---|---|
| 集群伸缩状态 | max(cluster_autoscaler_cluster_safe_to_autoscale{cluster="$ClusterId"}) or vector(0) |
| 是否处于缩容冷却 | sum(cluster_autoscaler_scale_down_in_cooldown{cluster="$ClusterId"}) or vector(0) |
| 最近检查扩容时间 | 1000*max(cluster_autoscaler_last_activity{cluster="$ClusterId",activity="scaleUp"}) |
| 最近检查缩容时间 | 1000*max(cluster_autoscaler_last_activity{cluster="$ClusterId",activity="scaleDown"}) |
| Unschedulable Pod | sum(cluster_autoscaler_unschedulable_pods_count{cluster="$ClusterId"})by(cluster) |
| count(kube_pod_status_phase{cluster="$ClusterId",phase="Running"}) | |
| 弹性伸缩耗时[P99] | histogram_quantile(0.99, sum(rate(cluster_autoscaler_function_duration_seconds_bucket{cluster="$ClusterId",function="main"}[1m])) by (le)) |
| CA 添加节点数 | sum(increase(cluster_autoscaler_scaled_up_nodes_total{cluster="$ClusterId"}[15s])) |
| sum(increase(cluster_autoscaler_scaled_up_gpu_nodes_total{cluster="$ClusterId"}[15s])) | |
| CA 移除节点数 | sum(increase(cluster_autoscaler_scaled_down_nodes_total{cluster="$ClusterId"}[15s])) by (reason) |
| sum(increase(cluster_autoscaler_scaled_down_gpu_nodes_total{cluster="$ClusterId"}[15s]))by(reason) | |
| CA 驱逐 Pod 数 | sum(increase(cluster_autoscaler_evicted_pods_total{cluster="$ClusterId"}[15s])) |
| CA 扩容失败次数 | sum(increase(cluster_autoscaler_failed_scale_ups_total{cluster="$ClusterId"}[15s]))by(reason) |
说明
如果您需要在托管 Prometheus 中的 Explore 功能或告警中心使用上述 PromQL 语句查看具体的指标或配置告警,请修改或删除语句中关于集群、节点、容器组的变量。例如:将 cluster=~"$ClusterId"参数中的$ClusterId变量修改为具体的集群 ID ,或直接删除该参数。
查看指标
您可以使用托管 Prometheus 的 Explore 功能来快速查询和展示指标数据。详情请参见 指标查询。