mGPU 在离线混部功能支持将在线任务和离线任务混合部署在同一张 GPU 卡上,在内核与驱动层面,实现离线任务 100% 利用闲置算力、在线任务 100% 抢占离线任务,从而进一步压榨 GPU 资源,把 GPU 使用成本降到最低。本文为您详细介绍 mGPU 在离线混部调度方案的技术原理和使用步骤。
说明
mGPU 在离线混部功能目前处于 公测 阶段。
背景信息
功能概述
通常情况下,mGPU 会公平地分配 GPU 资源,其内核驱动会为各项任务分配等量的 GPU 时间片。然而,由于不同的 GPU 计算任务在运行特性与优先级方面存在差异,它们对 GPU 资源的使用需求也不尽相同,此时,可以通过在离线混部调度技术来进一步压榨 GPU 算力。例如,实时推理对 GPU 资源较为敏感,要求低延迟,在使用时需尽快获取 GPU 资源来进行计算,但它对 GPU 资源的使用率往往不高;而模型训练对 GPU 资源的使用量较大,但对延迟的敏感度较低,能够忍受一定时间的抑制。采用在离线混部,能有效提升 GPU 使用率,进一步压榨 GPU 资源。
mGPU 在离线混部功能支持将在线任务和离线任务混合部署在同一张 GPU 卡上,在内核与驱动层面,实现离线任务 100% 利用闲置算力、在线任务 100% 抢占离线任务,从而进一步压榨 GPU 资源,把 GPU 使用成本降到最低。
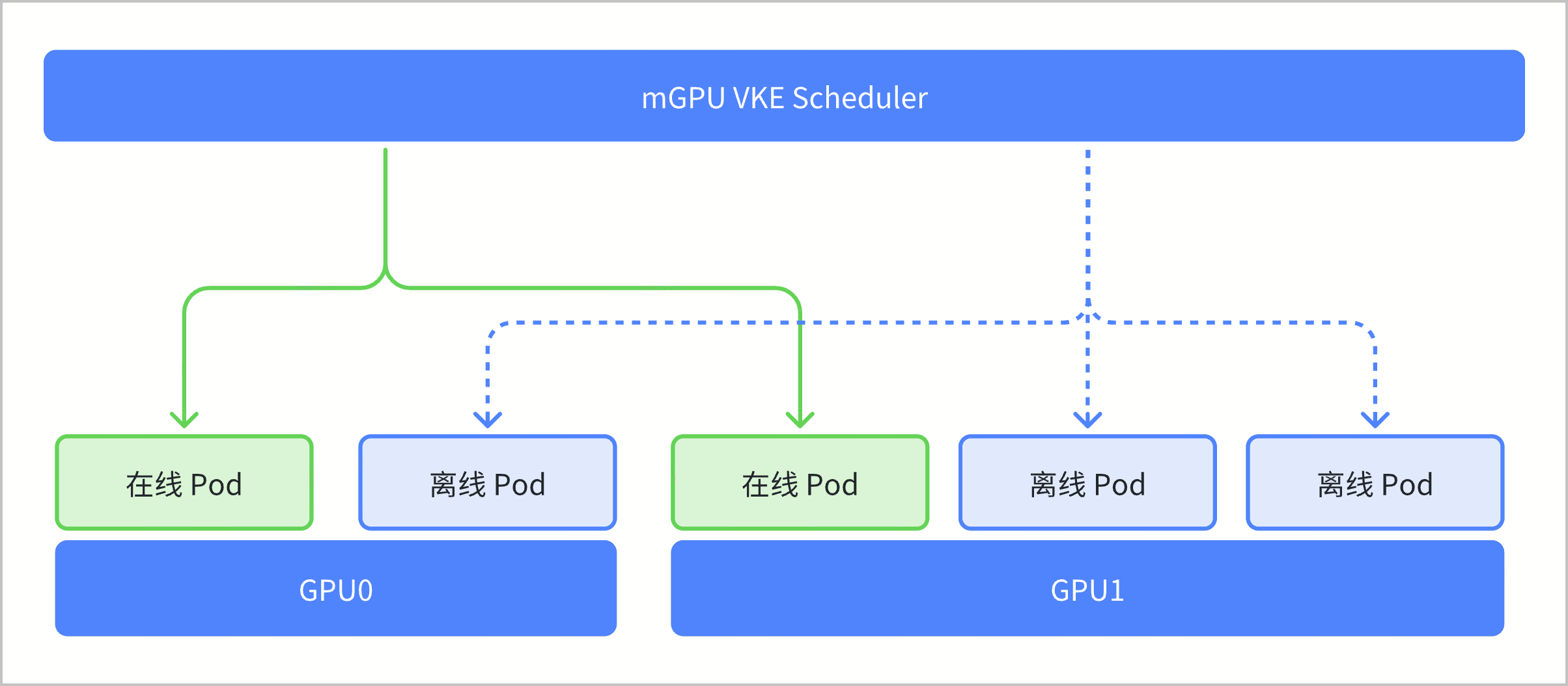
应用场景
通常可以将使用 GPU 算力互补的场景进行在离线混部,进一步压榨 GPU 资源。
在线推理与离线推理混部
搜索或推荐等实时推理任务主要根据已有数据进行逻辑推理以找到符合特定需求的结果,对 GPU 算力实时性要求高;而数据预处理等推理任务主要用于支持线下数据清洗和处理,对 GPU 算力实时性要求相对较低。通过将线上推理业务设置为在线任务,线下推理业务设置成离线任务,混合部署在同一张 GPU 卡上,进一步压榨 GPU 资源。在线推理与离线训练混部
搜索或推荐等实时推理任务主要根据已有数据进行逻辑推理以找到符合特定需求的结果,对 GPU 算力实时性要求高,但资源使用较少;而模型训练主要用于数据准备、训练参数设置、模型评估和调整,对 GPU 算力使用较多,但敏感度要求较低。通过将实时推理设置为在线任务,模型训练设置为低优任务,混合部署在同一张 GPU 卡上,进一步压榨 GPU 资源。
技术原理
- 离线 Pod 可以 100% 使用闲置算力
离线 Pod 在调度到节点 GPU 上后,如果 GPU 算力没有被在线 Pod 占用,离线 Pod 可以完全使用 GPU 算力。多个离线 Pod 共享 GPU 算力会受到 mGPU 算力分配策略控制。
- 在线 Pod 可以 100% 抢占离线 Pod
mGPU 驱动层实现了优先级绝对抢占能力:
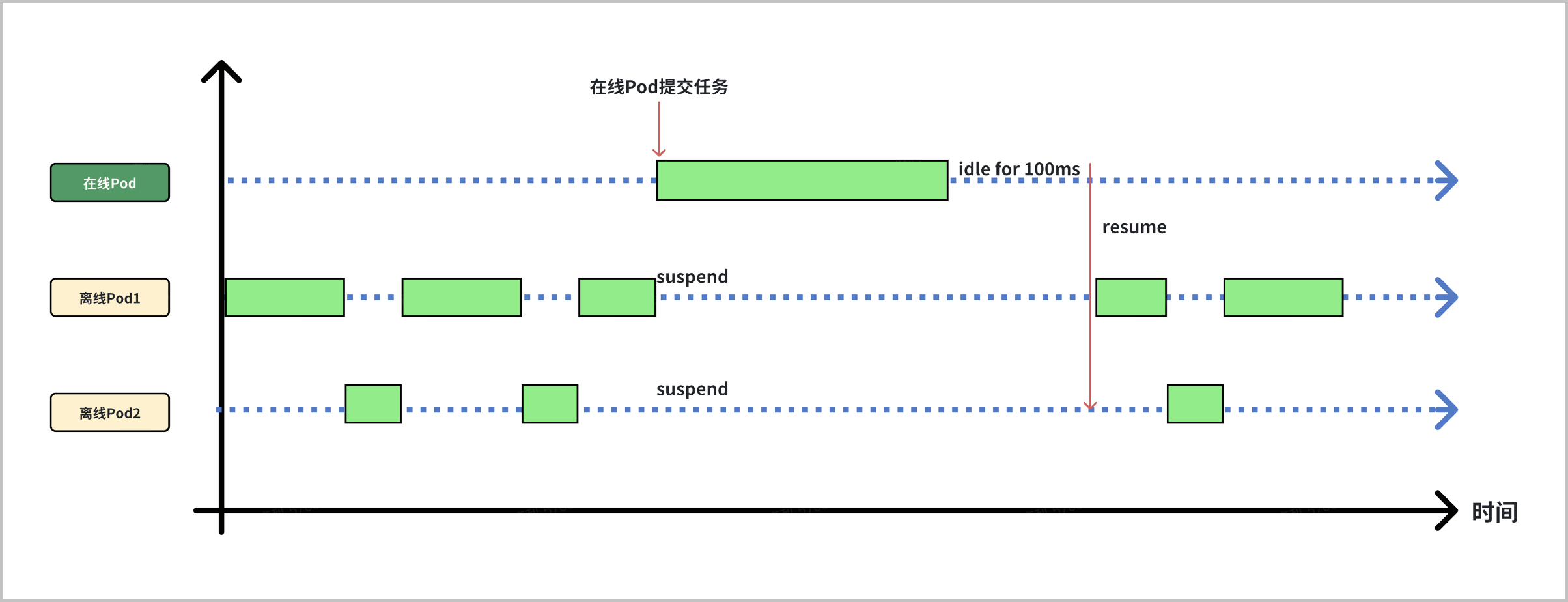
- 首先,在线 Pod 一旦提交涉及 GPU 算力的计算任务,mGPU 驱动会在第一时间将算力全部提供给在线 Pod 使用。多个在线 Pod 共享 GPU 算力也会受到 mGPU 算力分配策略控制。当在线 Pod 无任务运行时,驱动会在 100ms 后释放所占用算力,并重新分配给离线 Pod 使用。
- 其次,mGPU 驱动可以支持计算任务的暂停和继续。当在线 Pod 有计算任务运行时,原有占用 GPU 的离线 Pod 会立刻被暂停,将 GPU 算力让出,给在线 Pod 使用。当在线 Pod 任务结束,离线 Pod 会随即被唤醒,按照中断点继续计算。
前提条件
- 已经创建集群并完成 mGPU 相关基础资源配置,包括:安装 mGPU 组件、创建 GPU 节点。详细介绍参见:mGPU 使用方法。
- 已经根据实际场景配置 mGPU 算力分配策略,mGPU 在离线混部场景支持
fixed-share、guaranteed-burst-share算力分配策略,详细介绍参见:配置 mGPU 算力分配策略。
使用限制
- 在离线混部场景目前仅支持使用
fixed-share、guaranteed-burst-share算力分配策略,暂不支持使用native-burst-share算力分配策略。若要最大程度保障在线业务的性能,建议使用guaranteed-burst-share算力分配策略。 - 多卡共享模式暂不支持在离线混部。
- 目前仅支持算力的在离线抢占,暂不支持显存的在离线抢占。
- 使用 velinux2.0/ubuntu22.04 镜像的节点暂不支持使用在离线混部。
操作步骤
步骤一:配置集群
mGPU 在离线混部场景依赖 GPU 容器集群的多个组件,推荐新建集群和节点进行部署。若期望使用已有集群和节点搭建该场景,请提交 工单申请 获取技术支持,协助升级依赖组件的版本。各组件详细要求如下:
| 依赖组件 | 版本限制 | 查看方法 |
|---|---|---|
Kubernetes |
| 前往控制台的集群基本信息页面查看,详细介绍参见:如何查看集群的 Kubernetes 版本? |
mGPU 驱动 | 0.07.35.23 及以上 | 登录 mGPU 所属云服务器,执行 |
| mGPU 组件 | v0.6.0 及以上 | 前往控制台的组件管理页面查看,详细操作步骤参见:查看组件。 |
| general-webhook | v1.20.0 及以上 | 托管组件,控制台不可见。新建集群已经使用最新版本,存量集群需联系官方技术支持查看或升级版本。 |
步骤二:配置业务
根据实际需求,在同一集群中混合部署在线 Pod 和离线 Pod,使其调度到同一 GPU 中争抢算力。
- 离线 Pod:通过 Annotation
katalyst.kubewharf.io/qos_level: reclaimed_cores标识离线 Pod,通过vke.volcengine.com/reclaimed-mgpu-core申请离线算力。本文以创建无状态负载(Deployment)为例进行举例,离线 Pod 的 Yaml 示例如下:
apiVersion: apps/v1 kind: Deployment metadata: name: mgpu-deployment-offline # Deployment 名称。 namespace: default # Deployment 所属命名空间。 annotations: katalyst.kubewharf.io/qos_level: reclaimed_cores # 在离线混部标识。shared_cores 表示在线;reclaimed_cores 表示离线;不添加此 annotation 标识时,默认为在线。 vke.volcengine.com/mgpu-compute-policy: guaranteed-burst-share # mGPU 算力分配策略,在离线混部场景目前仅支持使用 guaranteed-burst-share、fixed-share。 spec: replicas: 2 # Pod 实例个数。 selector: matchLabels: app: mgpu-deployment template: spec: containers: - name: mgpu-container-offline # 容器名称。 image: nginx:1.14.2 # 容器镜像地址。 resources: limits: vke.volcengine.com/mgpu-memory: 4096 # GPU 显存,单位为 MiB,此处表示 GPU 显存为 4 GiB。 vke.volcengine.com/reclaimed-mgpu-core: 30 # 离线 GPU 算力百分比,此处表示配置 30% 的 GPU 算力。 ports: - containerPort: 80 metadata: labels: app: mgpu-deployment
- 在线 Pod:通过 Annotation
katalyst.kubewharf.io/qos_level: shared_cores或不配置此 Annotation 来标识在线 Pod,通过vke.volcengine.com/mgpu-core申请在线算力。本文以创建无状态负载(Deployment)为例进行举例,在线 Pod 的 Yaml 示例如下:
apiVersion: apps/v1 kind: Deployment metadata: name: mgpu-deployment-online # Deployment 名称。 namespace: default # Deployment 所属命名空间。 annotations: katalyst.kubewharf.io/qos_level: shared_cores # 在离线混部标识。shared_cores 表示在线;reclaimed_cores 表示离线;不添加此 annotation 标识时,默认为在线。 vke.volcengine.com/mgpu-compute-policy: guaranteed-burst-share # mGPU 算力分配策略,在离线混部场景目前仅支持使用 guaranteed-burst-share、fixed-share。 spec: replicas: 2 # Pod 实例个数。 selector: matchLabels: app: mgpu-deployment template: spec: containers: - name: mgpu-container-online # 容器名称。 image: nginx:1.14.2 # 容器镜像地址。 resources: limits: vke.volcengine.com/mgpu-memory: 4096 # GPU 显存,单位为 MiB,此处表示 GPU 显存为 4 GiB。 vke.volcengine.com/mgpu-core: 30 # 在线 GPU 算力百分比,此处表示配置 30% 的 GPU 算力。 ports: - containerPort: 80 metadata: labels: app: mgpu-deployment
结果验证
从在离线混部的技术原理可知,同一 GPU 中存在以下三种算力调度情况:
- 当同一张 GPU 卡上只存在在线任务时,不属于在离线混部场景。此时,原有算力分配策略生效。
- 当同一张 GPU 卡上只存在离线任务时,不属于在离线混部场景。此时,原有算力分配策略生效。
- 当同一张 GPU 卡上同时存在在线任务和离线任务时,属于在离线混部场景。此时,在线任务运行时,离线算力将被 100% 压制,即便在线任务并未占满 GPU 算力;在线任务的 GPU 实际使用量为 0 时,允许离线任务 100% 利用闲置算力。
因此,可以通过观察 GPU 卡上在线任务和离线任务的GPU算力使用率来判断混部是否生效。例如:同一张 GPU 卡上,当在线任务一直不间断在使用 GPU 算力处理请求时,离线任务的 GPU 算力使用率会被一直压制为 0%。