容器服务支持 P2P 镜像加速和镜像懒加载(Nydus)功能,大幅提升镜像拉取速度,缩短应用部署时间。同时,支持对镜像加速功能进行监控。本文为您介绍如何配置镜像加速功能观测。
背景信息
容器服务中的镜像加速功能,主要包括:
- P2P 镜像加速:利用节点的内网带宽资源,在节点之间分发镜像,减少对镜像仓库的压力,大幅提升镜像拉取速度,缩短应用部署时间。方案详情,请参见 P2P 镜像加速方案。
- 镜像懒加载(Nydus):集群通过 Nydus 实现镜像懒加载,提升创建 Pod 过程的镜像拉取速度。方案详情,请参见 容器镜像懒加载方案。
前提条件
操作步骤
步骤一:开启观测
- 登录 容器服务控制台。
- 在左侧导航栏单击 集群,找到目标集群,单击集群名称。
- 在集群管理页面的左侧导航栏中,单击 观测配置,并选择 基础观测 页签。
- 选择 镜像加速 卡片,单击 启用,开启集群镜像加速观测。
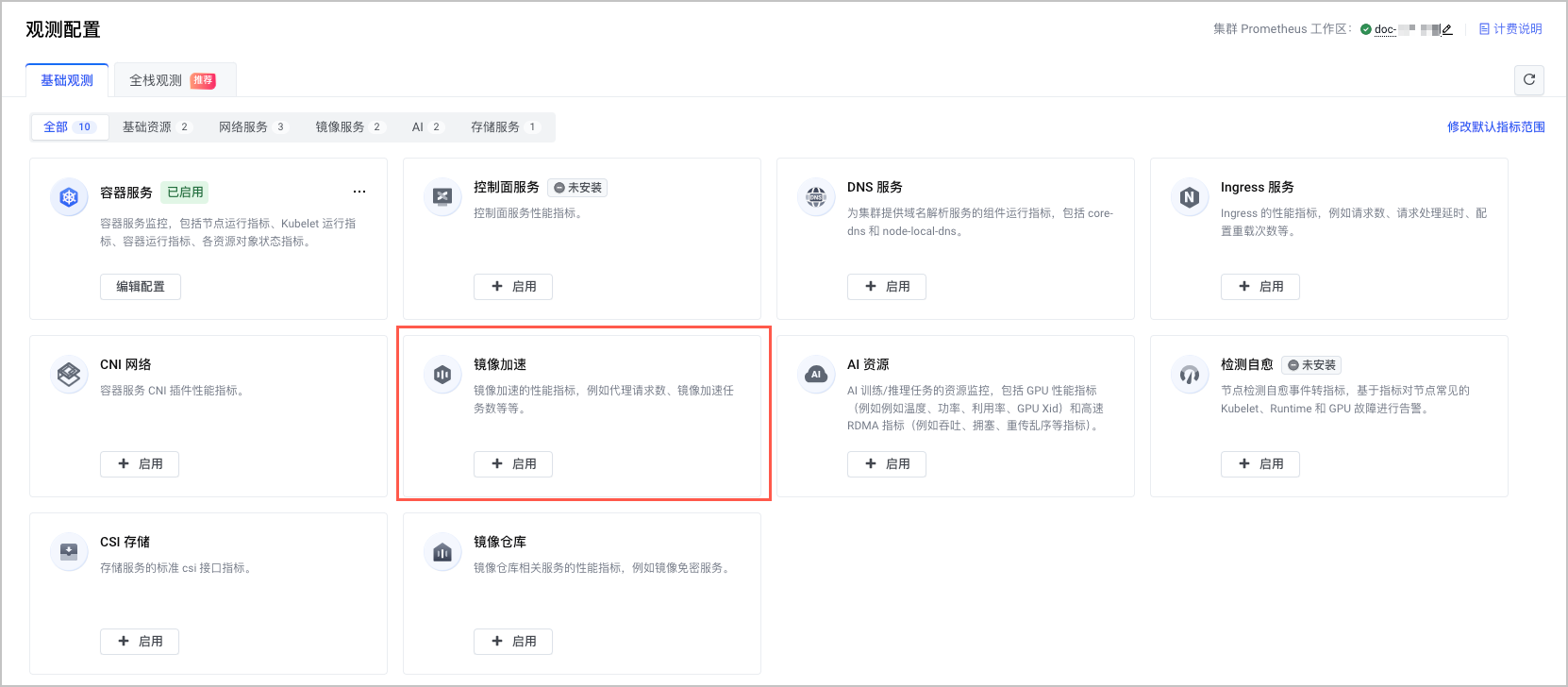
- 系统自动检查开启观测所需的必要条件。包括:工作区配置、组件状态等。
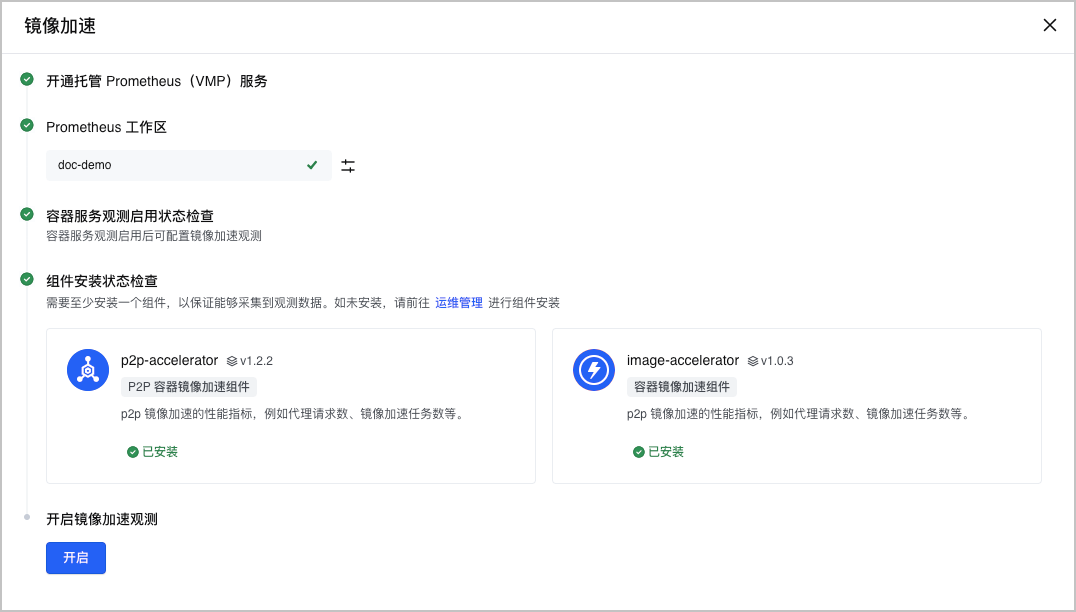
- 单击 开启,开启镜像加速观测。
步骤二:配置采集规则
镜像加速观测功能开启后,您可以配置采集规则,选择需要采集的目标组件、具体指标项及采集间隔。可以根据实际需求丢弃一些不用的指标。
- 在集群管理页面的左侧导航栏中,单击 观测配置,并选择 基础观测 页签。
- 选择 镜像加速 卡片,单击 编辑配置 并选择 指标 页签,配置采集规则,并选择具体的采集指标。
- 在组件列表 操作 列,单击开关,开启或关闭组件的采集规则。当关闭组件的采集规则时,系统不会采该集组件的所有指标。
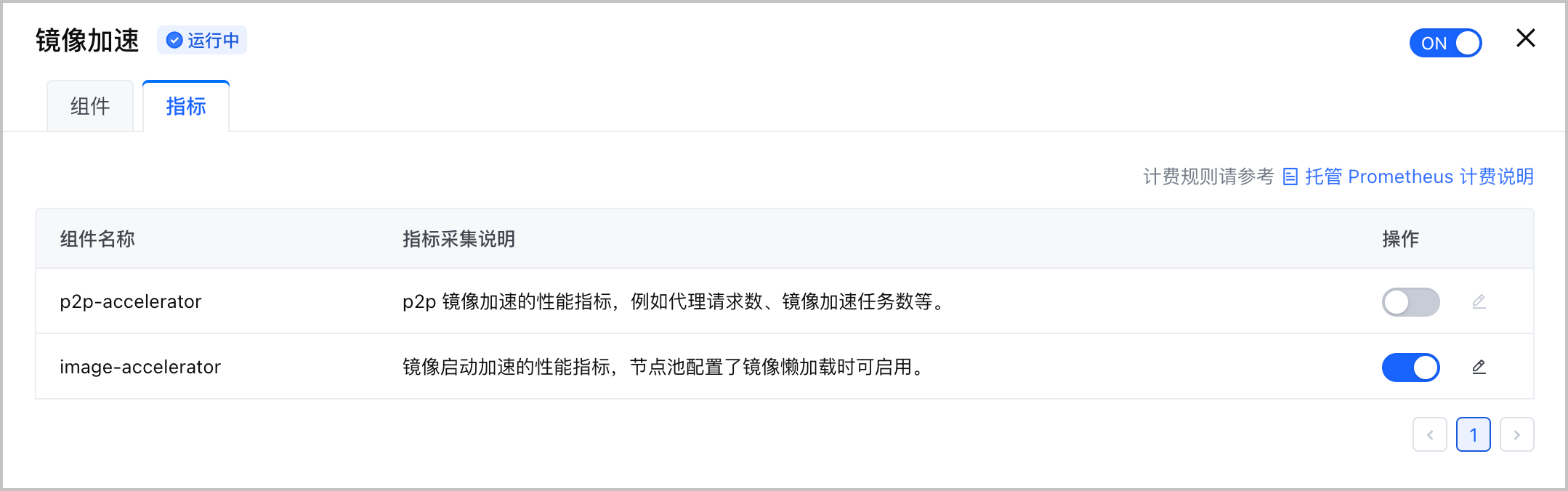
- 单击组件列表 操作 栏中的
 ,支持选择或丢弃组件的具体指标,并配置面向该组件的采集间隔。
,支持选择或丢弃组件的具体指标,并配置面向该组件的采集间隔。
- 在 采集间隔 中,选择该组件指标的采集间隔。不同组件支持的采集间隔不同。
- 在 指标列表 中,勾选指标,则采集该指标。取消勾选,则丢弃该指标。单击 全部、基础指标 或 其他指标 页签,允许基于指标类型对指标项进行筛选。
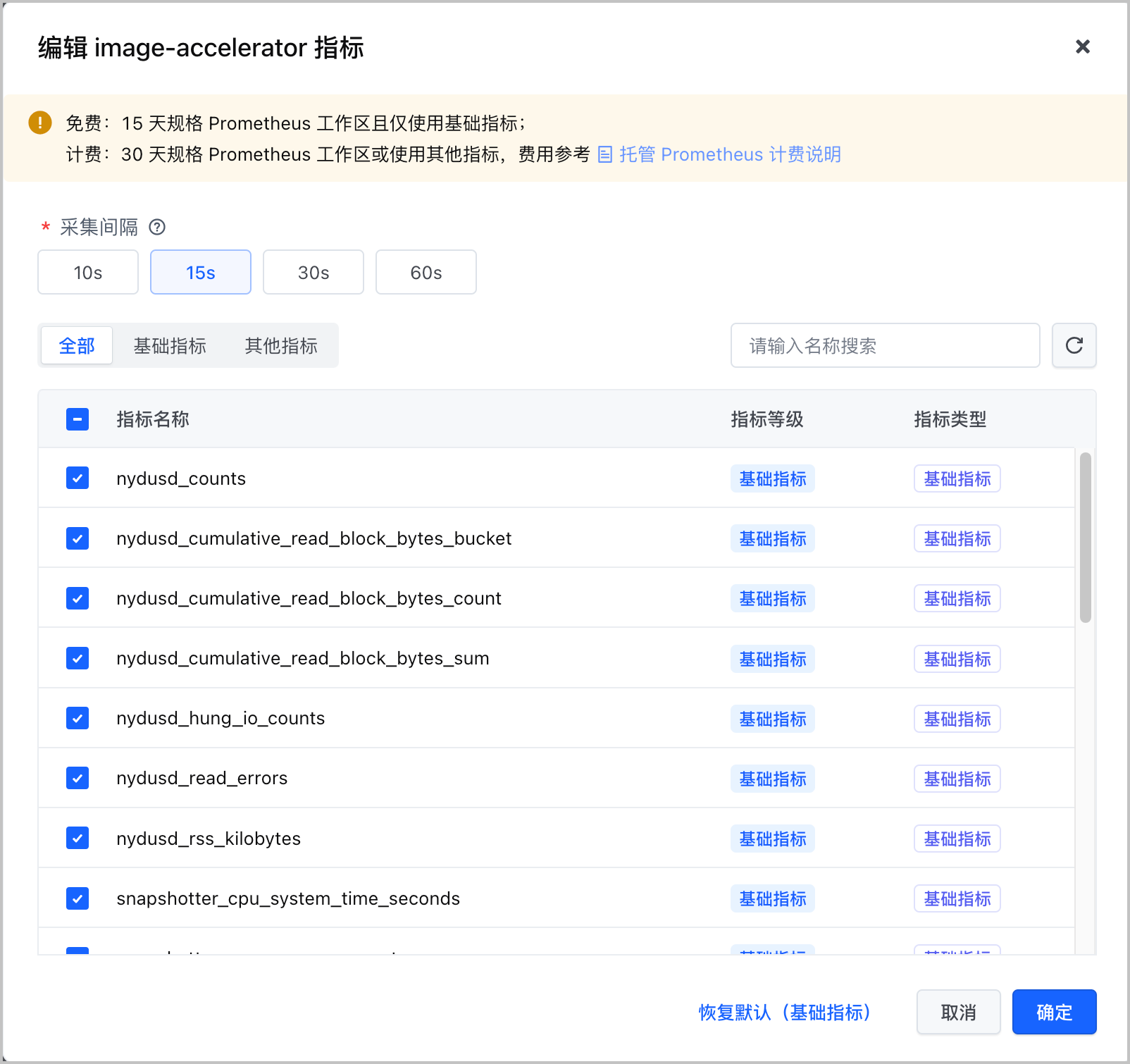
说明
- 减小指标采集间隔,会增加单位时间内上报的指标数量,可以提升监控精度。但会增加托管 Prometheus 标准版工作区的费用。增加指标采集间隔,会减少单位时间内上报的指标数量,可以减少托管 Prometheus 标准版工作区的费用,但会降低监控精度。请根据实际需要配置。
- 云产品的指标类型分为 基础指标 和 其他指标,不同类型指标的计费方式不同,详情请参见 托管 Prometheus 计费方式。
- 在组件列表 操作 列,单击开关,开启或关闭组件的采集规则。当关闭组件的采集规则时,系统不会采该集组件的所有指标。
- 单击 确认,完成配置。
步骤三:配置告警
镜像加速功能暂不支持告警规则模板。如需配置告警规则,请参见 创建告警规则。
观测看板
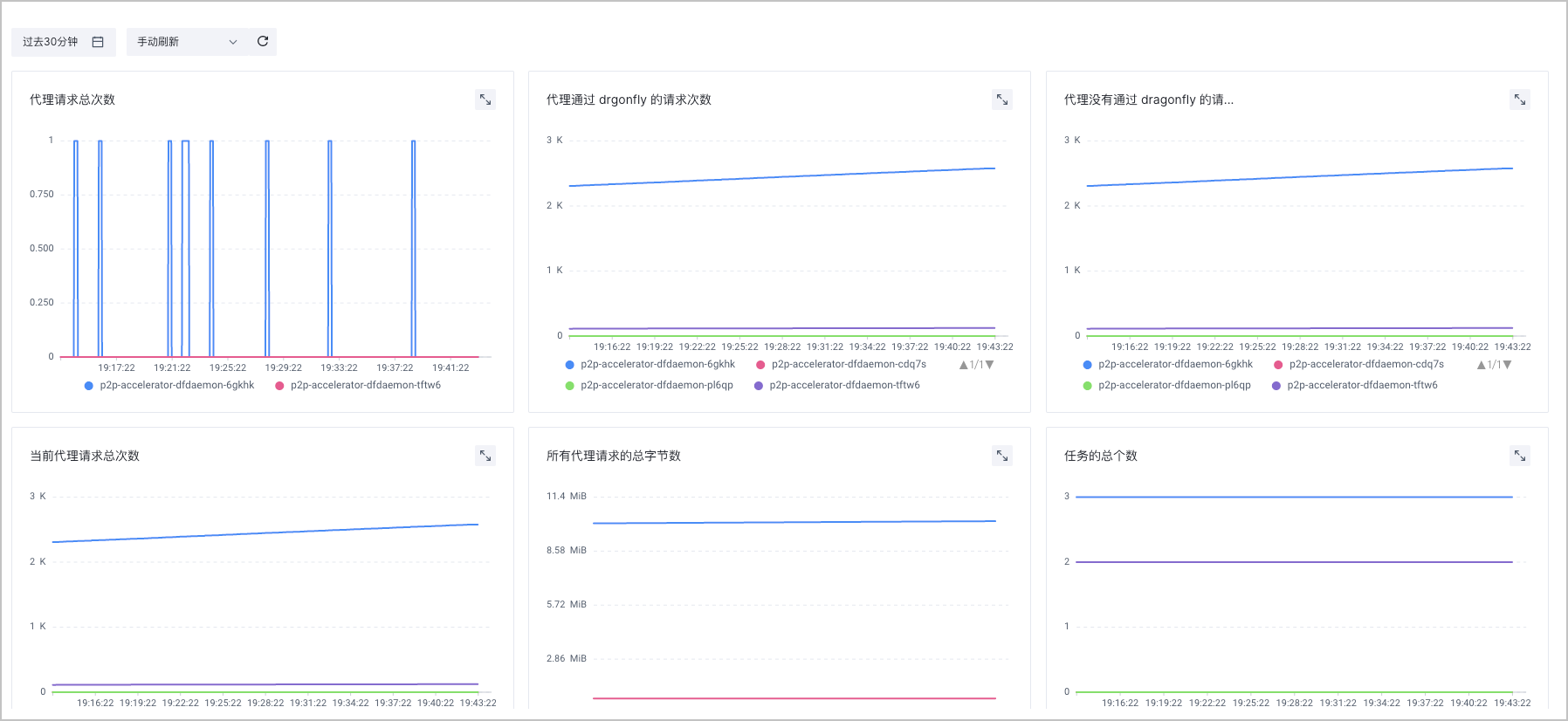
P2P 镜像加速监控
您可以在容器服务控制台中,查看预置的监控大盘。包括:代理请求总次数、当前代理请求总次数、任务总个数、失败的任务总个数、分片的总个数等。
- 在集群管理页面的左侧导航栏中,选择 监控中心 > 监控看板。
- 在左侧看板列表中选择 镜像加速服务监控 > p2p 镜像加速监控,即可查看监控看板。
说明
您也可以在集群中自建 Grafana,并通过 Grafana 查看指标和创建大盘。详情请参见 在容器服务集群中部署 Grafana 并接入工作区。
该看板的指标清单如下表所示。
| 看板名称 | PromQL 语句 |
|---|---|
| 代理请求总次数 | sum(dragonfly_dfdaemon_proxy_request_running_total{cluster="$clusterId"})by(instance) |
| 代理通过 drgonfly 的请求次数 | dragonfly_dfdaemon_proxy_request_via_dragonfly_total{cluster="$clusterId"} |
| 代理没有通过 dragonfly 的请求次数 | dragonfly_dfdaemon_proxy_request_not_via_dragonfly_total{cluster="$clusterId"} |
| 当前代理请求总次数 | dragonfly_dfdaemon_proxy_request_running_total{cluster="$clusterId"} |
| 所有代理请求的总字节数 | sum(dragonfly_dfdaemon_proxy_request_bytes_total{cluster="$clusterId"})by(instance) |
| 任务的总个数 | sum(dragonfly_dfdaemon_peer_task_total{cluster="$clusterId"})by(instance) |
| 失败任务的总个数 | sum(dragonfly_dfdaemon_peer_task_failed_total{cluster="$clusterId"})by(instance) |
| 分片的总个数 | sum(dragonfly_dfdaemon_piece_task_total{cluster="$clusterId"})by(instance) |
| 失败的分片总个数 | sum(dragonfly_dfdaemon_piece_task_failed_total{cluster="$clusterId"})by(instance) |
| 文件类型任务总个数 | sum(dragonfly_dfdaemon_file_task_total{cluster="$clusterId"})by(instance) |
| 流式类型任务总个数 | sum(dragonfly_dfdaemon_stream_task_total{cluster="$clusterId"})by(instance) |
| 作为 Seed Peer 下载总次数 | sum(dragonfly_dfdaemon_seed_peer_download_total{cluster="$clusterId"})by(instance) |
| 作为 Seed Peer 下载失败总次数 | sum(dragonfly_dfdaemon_seed_peer_download_failure_total{cluster="$clusterId"})by(instance) |
| 预取任务总个数 | sum(dragonfly_dfdaemon_prefetch_task_total{cluster="$clusterId"})by(instance) |
| 作为 Seed Peer 的并行下载个数 | sum(dragonfly_dfdaemon_seed_peer_concurrent_download_total{cluster="$clusterId"})by(instance) |
| 命中缓存任务个数 | sum(dragonfly_dfdaemon_peer_task_cache_hit_total{cluster="$clusterId"})by(instance) |
说明
如果您需要在托管 Prometheus 中的 Explore 功能或告警中心使用上述 PromQL 语句查看具体的指标或配置告警,请修改或删除语句中关于集群、节点、容器组的变量。例如:将 cluster=~"$Cluster"参数中的$Cluster变量修改为具体的集群 ID ,或直接删除该参数。
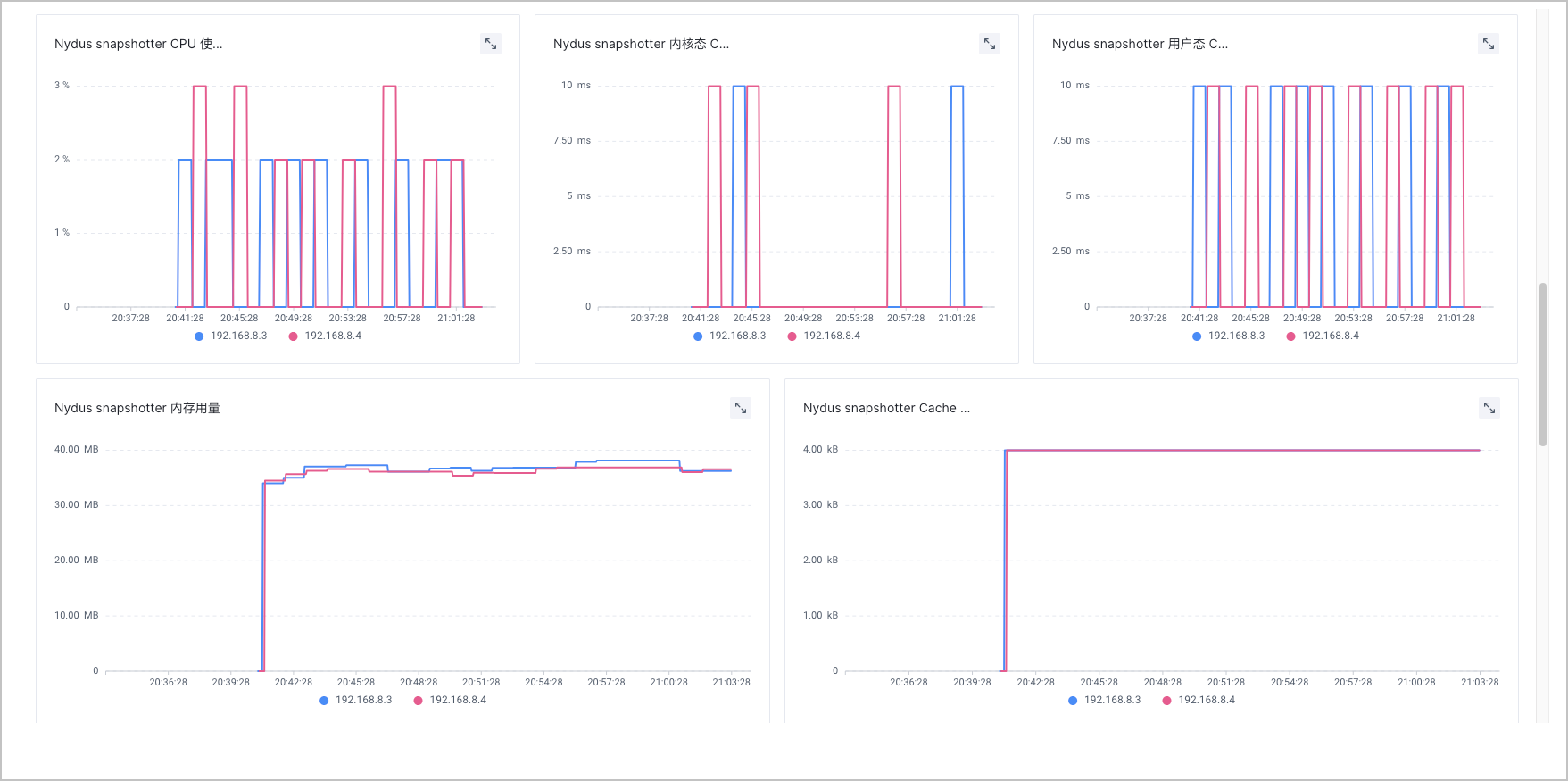
镜像懒加载(Nydus)监控
配置 Nydus 懒加载功能后,您可以在容器服务控制台中,查看预置的监控大盘。包括:Nydus Daemon 数量、Nydus Daemon 内存用量等。
- 在集群管理页面的左侧导航栏中,选择 监控中心 > 监控看板。
- 在左侧看板列表中选择 镜像加速服务监控 > 镜像懒加载(Nydus)监控,即可查看监控看板。
说明
您也可以在集群中自建 Grafana,并通过 Grafana 查看指标和创建大盘。详情请参见 将托管 Prometheus 数据接入自建 Grafana。
该看板的指标清单如下表所示。
| 大盘分类 | 大盘名称 | 指标单位 | PromQL 语句 |
|---|---|---|---|
| Nydus Daemon 监控 | Nydus Daemon 数量 | Count | sum(nydusd_counts{node=~"$node"})by(version) |
| Nydus Daemon 内存用量 | MB | topk(10,sum(nydusd_rss_kilobytes{cluster="$clusterId",node=~"$node"})by (node)) | |
| Prepare 函数执行时间 P90 | ms | topk(10,histogram_quantile(0.9,sum(rate(snapshotter_snapshot_operation_elapsed_milliseconds_bucket{cluster="$clusterId",node=~"$node",snapshot_operation="PREPARE"}[5m]))by (le,node))) | |
| Cleanup 函数执行时间 P90 | ms | topk(10,histogram_quantile(0.9,sum(rate(snapshotter_snapshot_operation_elapsed_milliseconds_bucket{cluster="$clusterId",node=~"$node",snapshot_operation="CLEANUP"}[5m]))by (le,node))) | |
| Mount 函数执行时间 P90 | ms | topk(10,histogram_quantile(0.9,sum(rate(snapshotter_snapshot_operation_elapsed_milliseconds_bucket{cluster="$clusterId",node=~"$node",snapshot_operation="MOUNTS"}[5m]))by (le,node))) | |
| Remove 函数执行时间 P90 | ms | topk(10,histogram_quantile(0.9,sum(rate(snapshotter_snapshot_operation_elapsed_milliseconds_bucket{cluster="$clusterId",node=~"$node",snapshot_operation="REMOVE"}[5m]))by (le,node))) | |
| Nydus snapshotter 资源使用 | Nydus snapshotter CPU 使用率 | % | topk(10,sum(snapshotter_cpu_usage_percentage{cluster="$clusterId",node=~"$node"})by (node)) |
| Nydus snapshotter 内核态 CPU 时间 | ms | topk(10,sum(snapshotter_cpu_system_time_seconds{cluster="$clusterId",node=~"$node"})by (node)) | |
| Nydus snapshotter 用户态 CPU 时间 | ms | topk(10,sum(snapshotter_cpu_user_time_seconds{cluster="$clusterId",node=~"$node"})by (node)) | |
| Nydus snapshotter 内存用量 | MB | topk(10,sum(snapshotter_memory_usage_kilobytes{cluster="$clusterId",node=~"$node"})by (node)) | |
| Nydus snapshotter Cache 用量 | B | topk(10,sum(snapshotter_cache_usage_kilobytes{cluster="$clusterId",node=~"$node"})by (node)) | |
| Nydus 错误和事件 | Nydusd Read error 数量 | Count | topk(10,sum(nydusd_read_errors{cluster="$clusterId",node=~"$node"}) by(node)) |
| Nydusd Died event 数量 | Count | topk(10,sum(nydusd_lifetime_event_counts{cluster="$clusterId",node=~"$node",nydusd_event="DIED"})by (node)) | |
| Nydus read 性能 | Nydus read P90 延迟 | ms | topk(10,histogram_quantile(0.9,sum(rate(nydusd_read_latency_microseconds_bucket{cluster="$clusterId",node=~"$node"}[5m]))by(le,node))) |
| Nydus read 成功数量 | Count | topk(10,sum(nydusd_read_hits{cluster="$clusterId",node=~"$node"})by(node)) | |
| Nydus read 总 Size | B | topk(10, sum(nydusd_total_read_bytes{cluster="$clusterId", node=~"$node"})by (node)) | |
| Nydus read hang IO 数量 | Count | topk(10,sum(nydusd_hung_io_counts{cluster="$clusterId",node=~"$node"})by (node)) |
说明
如果您需要在托管 Prometheus 中的 Explore 功能或告警中心使用上述 PromQL 语句查看具体的指标或配置告警,请修改或删除语句中关于集群、节点、容器组的变量。例如:将 cluster=~"$Cluster"参数中的$Cluster变量修改为具体的集群 ID ,或直接删除该参数。
查看指标
您可以使用托管 Prometheus 的 Explore 功能来快速查询和展示指标数据。详情请参见 指标查询。