导航
容器服务
搜索目录或文档标题搜索目录或文档标题
容器服务 VKE
产品动态
Kubernetes 版本发布记录
组件发布记录
监控组件
DNS 组件
GPU 组件
安全公告
产品公告
用户指南
网络
服务(Service)
路由(Ingress)
ALB Ingress
CLB Ingress
Nginx Ingress
APIG Ingress
域名解析(DNS)
工作负载
存储管理
TOS 对象存储卷
NAS 文件存储卷
CloudFS 大数据文件存储卷
弹性伸缩
工作负载弹性伸缩
事件驱动伸缩(KEDA)
GPU
可观测性
AIOps 套件
注册集群
最佳实践
网络
解决方案
API 参考
集群管理
弹性容器实例
常见问题
通用 FAQ
集群 FAQ
集群管理
节点与节点池 FAQ
授权 FAQ
工作负载 FAQ
服务与路由 FAQ
存储 FAQ
弹性伸缩 FAQ
可观测性 FAQ
配额 FAQ
组件 FAQ
容器镜像 FAQ
弹性容器实例 VCI
最新动态
用户指南
对接 VCI
创建实例
- 文档首页 /容器服务/容器服务 VKE/用户指南/云原生 AI 套件/AI 数据加速/AI 数据加速概述
AI 数据加速概述
最近更新时间:2024.12.16 14:56:23首次发布时间:2024.09.14 17:59:30
我的收藏
有用
有用
无用
无用
文档反馈
AI 套件支持以预加载方式实现模型的缓存加速。加速了算力端加载模型的时间,全面提升了大模型应用的运行效率。
说明
该功能目前处于 公测 阶段。
背景信息
AI 大模型领域的模型文件通常都比较大,几个 GiB 甚至几十个 GiB 规格的模型文件非常常见。用户微调、部署这些模型时,需要加载大量的数据,耗时较多,大大影响推理服务的启动以及模型切换的效率,从而造成用户体验低下的问题。针对上述问题,云原生 AI 套件提供 AI 数据加速能力。
功能介绍
AI 数据加速是云原生 AI 套件基于数据缓存加速技术提供的数据集加速能力。AI 数据加速能力将数据从存储位置缓存到算力近端,加速了算力端加载模型的时间,大幅提升 AI 训练、大模型应用的推理速度和运行效率。
AI 数据加速在容器服务(VKE)存储访问加速中提供了两种解决思路:
- 托管缓存:基于 Fluid + CloudFS Runtime 的缓存方法。CloudFS 重点解决集群维度的整体性能,虽然对单机器单流量的提升有限,但其较大的带宽可以解决常见的限流问题,同时托管缓存具有较高的稳定性。
- 集群内缓存:基于 Fluid + Alluxio Runtime 的缓存方法。Alluxio Runtime 采用了集群内缓存设计,可以利用大机型剩余的内存或磁盘来进行数据缓存,同时解决了在相同集群内访问的常见限流问题。
AI 数据加速的架构示意图如下: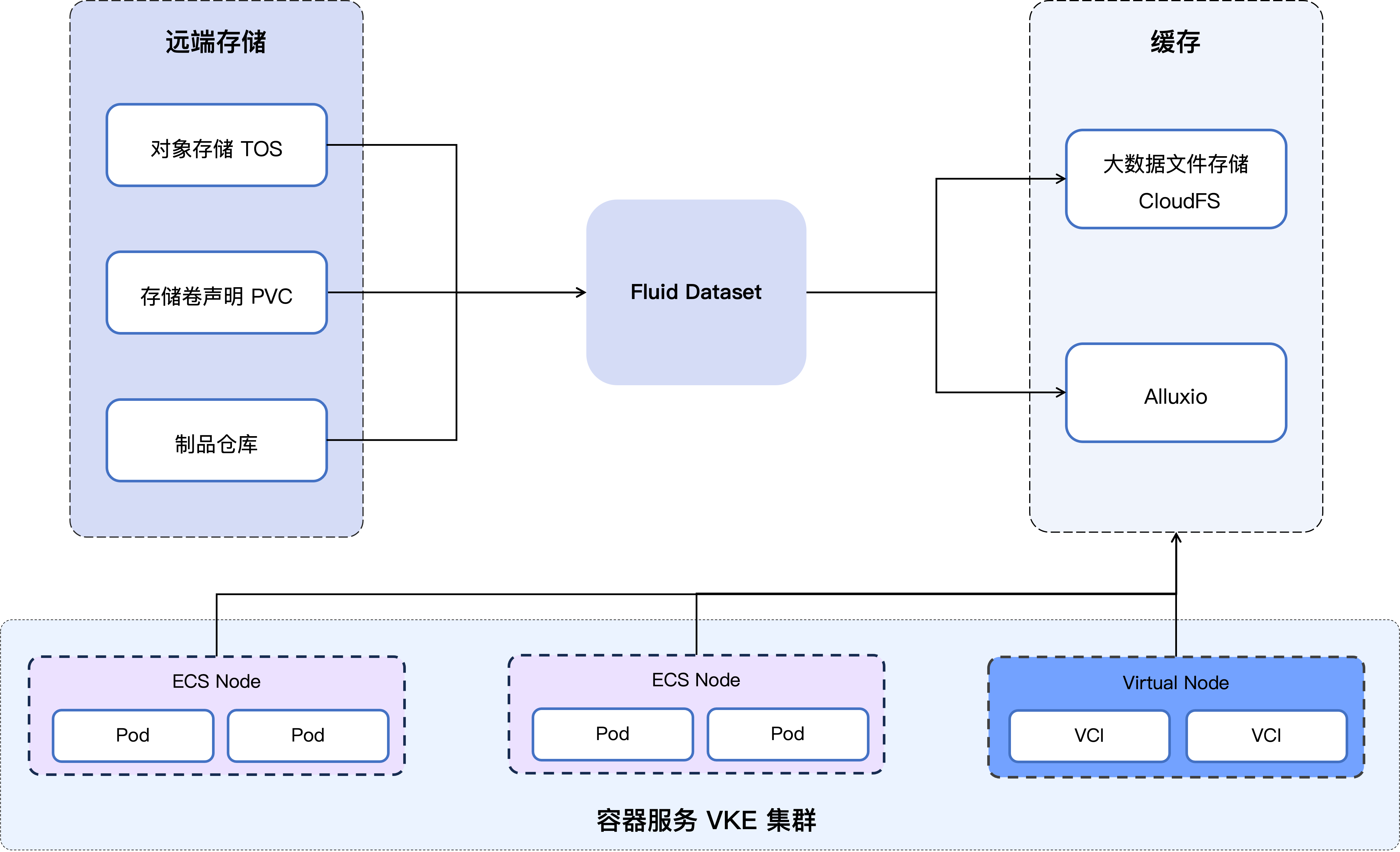
适用场景
- 推理场景下的数据加速
推理场景下通常涉及到模型文件的拉取与切换。常规存储产品受限于访问速度与访问带宽,会对推理请求的响应时间有较大影响,AI 数据加速可解决此类问题。 - 运行环境下的模型加载
通过预热的方式来指定具体的文件或文件夹为热点文件,并针对此类文件提供更快的读写速度。 - 运行环境下的模型切换
常规远端存储(例如 TOS)具有带宽限制,大量的模型切换以及多 Pod 的同时访问,都会造成存储侧的限流,AI 数据加速功能可加速运行环境的模型切换速度。
使用方法
不同的数据集目的端和不同的数据来源之间,配置数据集的方法略有不同,详情请参见: