导航
检查自愈观测
最近更新时间:2025.02.06 16:17:58首次发布时间:2024.08.27 16:44:21
检查自愈观测允许您监控集群中节点池检查自愈功能,基于指标对节点常见的 Kubelet、Runtime 和 GPU 故障进行观测和告警。本文为您介绍如何配置检查自愈观测。
说明
检查自愈的详情,请参见 节点池节点检查自愈。
前提条件
操作步骤
步骤一:开启观测
- 登录 容器服务控制台。
- 在左侧导航栏单击 集群,找到目标集群,单击集群名称。
- 在集群管理页面的左侧导航栏中,单击 观测配置,并选择 基础观测 页签。
- 选择 检查自愈 卡片,单击 启用,开启集群检查自愈观测。
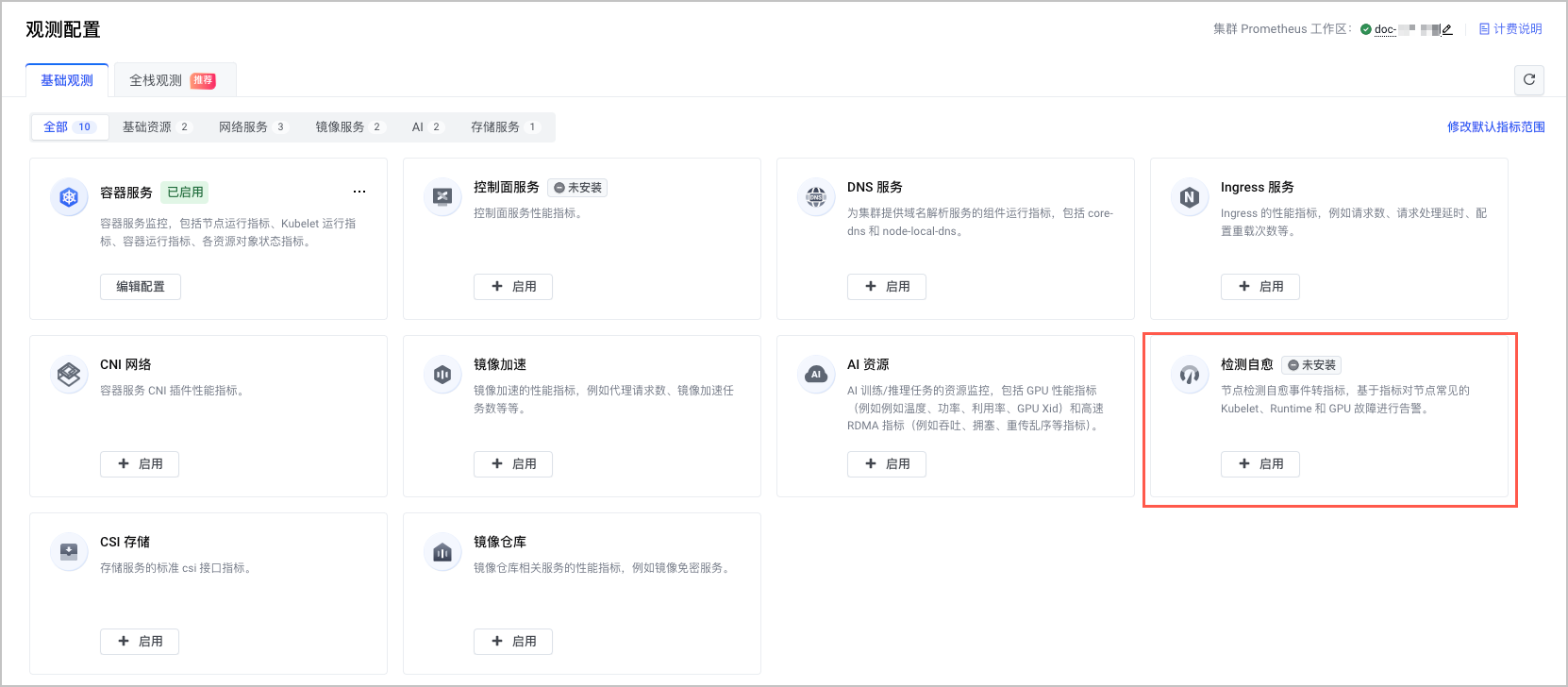
- 系统自动检查开启观测所需的必要条件。
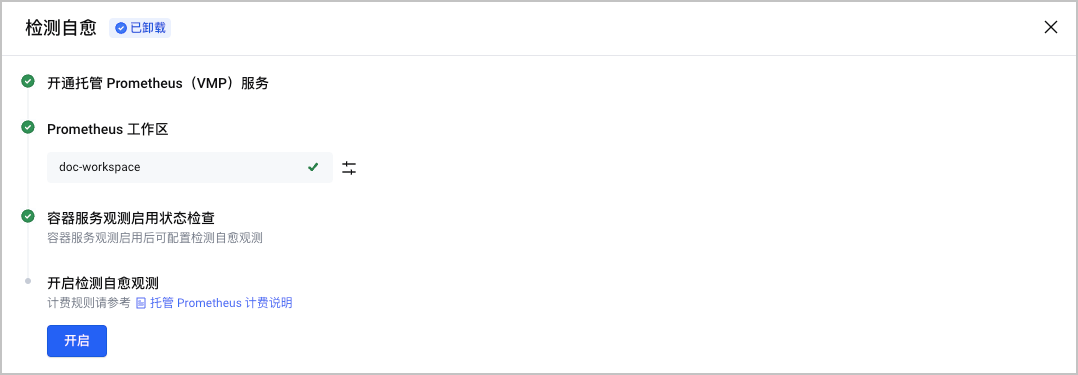
- 单击 开启,开启检查自愈观测。
步骤二:配置告警
为方便用户及时发现检查自愈规则事件,系统支持基于检查规则自愈的行为和节点的常见故障进行告警,如下表所示。
| 告警分类 | 告警规则 |
|---|---|
| 检查自愈行为 | 自愈开始执行。 |
| 自愈执行失败。 | |
| 自愈执行完成但未能修复问题。 | |
| 节点常见故障 | 节点出现 GPU 相关异常。 |
| 节点出现 NTP 相关异常。 | |
| 节点出现 ContainerRuntime 异常。 | |
| 节点检测到 Kubelet 异常。 |
配置检查自愈告警的操作步骤如下:
- 选择 检查自愈 卡片,单击 编辑配置,,并选择 基础观测 页签。
- 在 告警 页签中,单击开关,开启检查自愈告警,并配置告警相关参数。
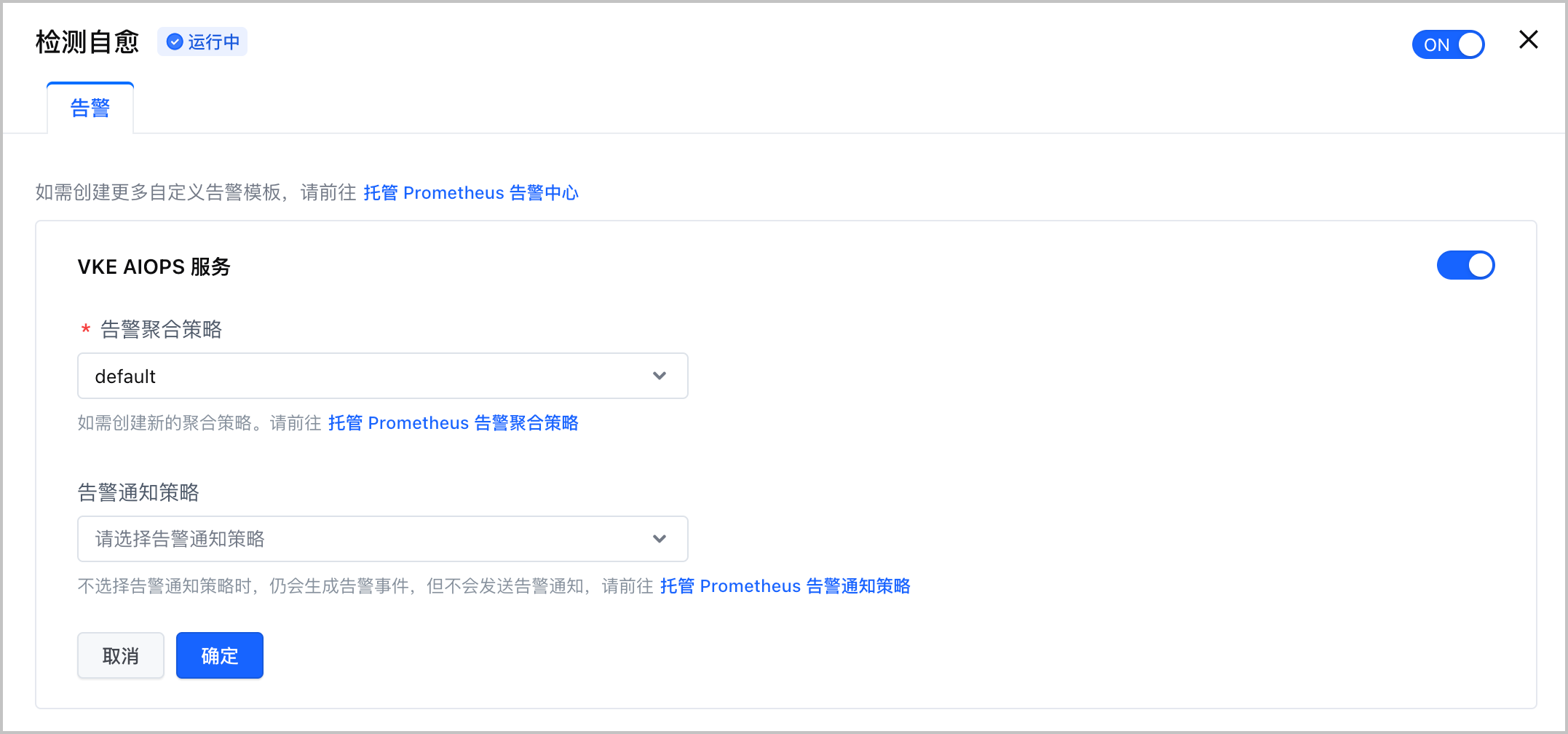
配置项 说明 告警聚合策略 在下拉菜单中选择告警聚合策略。详情请参见 创建告警聚合策略。 告警通知策略 在下拉菜单中选择告警通知策略。系统会使用通知策略中配置的告警等级和联系人组,将告警发送给指定的联系人。详情请参见 创建告警通知策略。 - 单击 确定,完成配置。
观测看板
您可以查看检查自愈的监控信息,包括:异常节点数、GPU 异常节点数、自愈操作数、自愈操作成功数等。支持设置查询的时间段,并指定刷新方式(手动刷新、自动刷新)。
- 在集群管理页面的左侧导航栏中,选择 监控中心 > 监控看板。
- 在左侧看板列表中选择 智能运维 > 检查自愈,即可查看监控大盘。
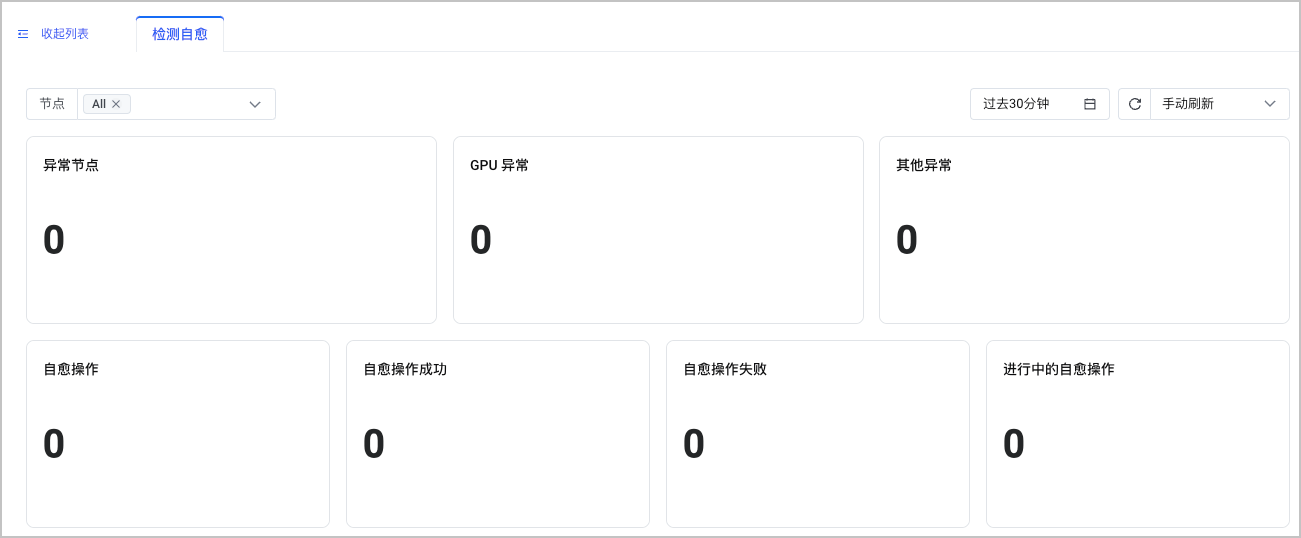
该看板的指标清单如下表所示。
| 看板名称 | PromQL 语句 |
|---|---|
| 异常节点 | count(count(aiops_resource_condition_abnormal{resource_kind="VkeNode",cluster_id="$ClusterId",resource_name=~"$Node"} == 1) by (resource_name)) or vector(0) |
| GPU 异常 | count(count(aiops_resource_condition_abnormal{resource_kind="VkeNode",cluster_id="$ClusterId", condition=~"GpuCardFallen |
| 其他异常 | count(count(aiops_resource_condition_abnormal{resource_kind="VkeNode",cluster_id="$ClusterId", condition!~"GpuCardFallen |
| 自愈操作 | sum(increase(aiops_resource_remediation_in_progress{resource_kind="VkeNode",cluster_id="$ClusterId",resource_name=~"$Node"}[$__range])) or vector(0) |
| 自愈操作成功 | sum(increase(aiops_resource_remediation_completed{resource_kind="VkeNode",cluster_id="$ClusterId", phase!"Failed",resource_name="$Node"}[$__range])) or vector(0) |
| 自愈操作失败 | sum(increase(aiops_resource_remediation_completed{resource_kind="VkeNode",cluster_id="$ClusterId", phase="Failed",resource_name=~"$Node"}[$__range])) or vector(0) |
| 进行中的自愈操作 | count(aiops_resource_remediation_in_progress{resource_kind="VkeNode",cluster_id="$ClusterId",resource_name=~"$Node"} == 1) or vector(0) |
| 异常节点 | sum(aiops_resource_condition_abnormal{resource_kind="VkeNode",cluster_id="$ClusterId",resource_name=~"$Node"}) by (resource_name, condition) > 0 |
| 执行自愈操作 Top 10 节点 | topk(10, sum(increase(aiops_resource_remediation_action_in_progress{resource_kind="VkeNode",cluster_id="$ClusterId",resource_name=~"$Node"}[$__range])) by (resource_name)) |
| 异常节点数 | count(count(aiops_resource_condition_abnormal{resource_kind="VkeNode",cluster_id="$ClusterId", resource_name=~"$Node"} == 1) by (resource_name)) |
| 各类型的异常节点数 | sum(count(aiops_resource_condition_abnormal{resource_kind="VkeNode",cluster_id="$ClusterId", resource_name=~"$Node"} == 1) by (condition)) by (condition) |
| 各类型的自愈操作数 | count(count(aiops_resource_remediation_action_completed{resource_kind="VkeNode",cluster_id="$ClusterId", resource_name=~"$Node"} == 1) by (remedy_policy_name)) by (remedy_policy_name) |
说明
如果您需要在托管 Prometheus 中的 Explore 功能或告警中心使用上述 PromQL 语句查看具体的指标或配置告警,请修改或删除语句中关于集群、节点、容器组的变量。例如:将 cluster=~"$ClusterId"参数中的$ClusterId变量修改为具体的集群 ID ,或直接删除该参数。
查看指标
您可以使用托管 Prometheus 的 Explore 功能来快速查询和展示指标数据。详情请参见 指标查询。