本文将介绍如何在火山引擎容器服务的集群中,部署满血版 DeepSeek-V3/R1 模型推理服务,实现 Kubernetes 集群中的 DeepSeek-V3/R1 模型分布式推理。
说明
本文仅适用于普通 GPU 场景,mGPU 场景暂不支持。
背景信息
DeepSeek 是由中国 AI 初创公司深度求索(DeepSeek)发布的大语言模型。其主要的开源模型包含:
- DeepSeek-V3:通用大语言大模型(MoE 结构,671B 参数,激活参数 37B),在 14.8T token 上进行了预训练,可以提供信息检索、数据分析、自然语言处理等服务,能够适应多种应用场景,如客户服务、教育辅导、内容创作等。
- DeepSeek-R1:基于 DeepSeek-V3-Base 训练生成的推理模型,擅长数学、代码和自然语言推理等复杂任务,能够在复杂环境中稳定运行并完成指定任务,适用于工业自动化、家庭服务机器人等领域。
使用说明
下文主要介绍容器服务测试并验证通过的实践内容,为了获得符合预期的结果,同时符合容器服务的 使用限制,请按照本文方案(或在本文推荐的资源上)操作。如需替换方案,您可以联系对应的火山引擎客户经理咨询。
前提条件
推送模型文件到 TOS
预置模型信息
为了方便您使用 DeepSeek 模型,火山引擎提前在对象存储(TOS)服务中预置了部分模型。您可以直接通过 TOS 提供的工具,将预置模型转存至您自己的 TOS 存储桶(Bucket)中,作为之后推理服务的基础模型。
TOS 中的预置模型如下表所示。
| 模型名称 | TOS 路径 | 模型说明 |
|---|---|---|
| DeepSeek-R1 | tos://ai-public-models-cn-beijing/models/DeepSeek-R1/ | DeepSeek R1 模型 |
| DeepSeek-V3 | tos://ai-public-models-cn-beijing/models/DeepSeek-V3/ | DeepSeek V3 模型 |
模型上传
您可以将火山引擎预置的 DeepSeek 模型转存至自建 TOS 桶中,作为后续模型推理服务的基础模型。操作步骤如下:
登录 对象存储控制台。
在左侧菜单栏中选择 桶列表,单击 创建桶,创建一个 TOS 桶。
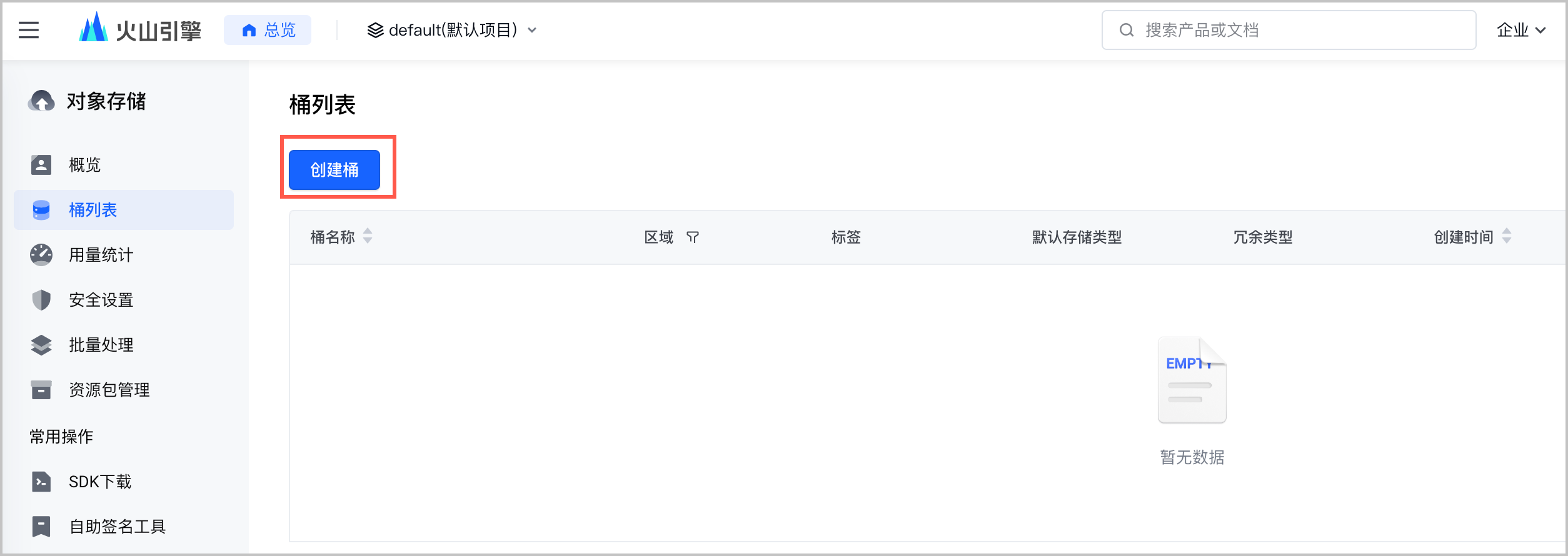
配置存储桶信息。需要注意 区域 选择 华北 2(北京)。详细的操作步骤和参数说明,请参见 创建存储桶。
在本地环境中,下载 TOS 官方提供的 tosutil 工具到本地,后续模型的复制需要依赖该工具。详情请参见 tosutil 下载与安装。
说明
tosutil 工具同时支持 Windows、Linux 及 macOS 系统,您可以根据实际环境下载和安装合适的版本。
在本地环境执行以下命令,配置 tosutil 工具信息。
tosutil config -e=tos-cn-beijing.volces.com -i=${AK} -k=${SK} -re=cn-beijing其中,请将
${AK}和${SK}替换为您火山引擎账号的 AccessKey ID(AK)和 Secret Access Key(SK)。AK/SK 获取方法,请参见 API访问密钥管理。在本地环境中执行以下命令,将预置模型复制到您的自建 TOS 桶中。
tosutil cp -r -j 6 -p 6 ${SOURCE_MODEL_TOS_PATH} tos://${TOS_BUCKET}其中:
${SOURCE_MODEL_TOS_PATH}:预置模型的 TOS 路径,以 DeepSeek-R1 模型为例,${SOURCE_MODEL_TOS_PATH}即为tos://ai-public-models-cn-beijing/models/DeepSeek-R1/。${TOS_BUCKET}:您在步骤 3 中创建的 TOS 存储桶名称。
创建高性能计算集群
高性能计算集群,用于实现高性能计算 GPU 实例(计算节点)的逻辑隔离,同一集群内实例间 RDMA 网络互联互通。详情请参见 创建高性能计算集群。
说明
高性能计算集群的 地域 选择 华北 2(北京),可用区 需要与 VKE 节点的可用区一致即可。
创建 VKE 集群
在容器服务中创建集群,需要注意以下列举的参数配置。其余参数说明和详细的操作步骤,请参见 创建集群。
| 配置项 | 说明 |
|---|---|
| 集群配置 | |
| Kubernetes 版本 | 选择 v1.28 及以上版本。 |
| 容器网络模型 | 选择 VPC-CNI。 |
| 节点池配置 | |
| 托管节点池 | 开启 托管节点池。 |
| 可用区 | 与 高性能计算计算集群 所在的可用区相同。 |
| 计算规格 | 由于 Deepseek 模型参数较大,因此需要选择有较大显存的 GPU 实例 ,如 ecs.hpcpni3ln, ecs.ebmhpcpni3ln, ecs.ebmhpcpni3l(H20 8 卡) 等。 |
| 高性能计算机群 | 选择之前创建的高性能计算集群。 |
| 节点数量 | 2 个。 |
| 数据盘 | 选择 1 TiB 极速型 SSD 盘。 |
节点标签 (Labels) | 设置节点标签来配置 RDMA 使用模式。 |
Kubelet 自定义参数 | 通过 Kubelet 自定义参数配置 RDMA 设备的 NUMA 亲和策略。 |
| 组件配置 | |
平台功能组件 | 在集群中安装如下组件:
|
创建模型存储卷
在 VKE 集群中创建对象存储静态存储卷,实现基于 TOS 的 VKE 集群网络存储能力。详情请参见 使用对象存储静态存储卷。
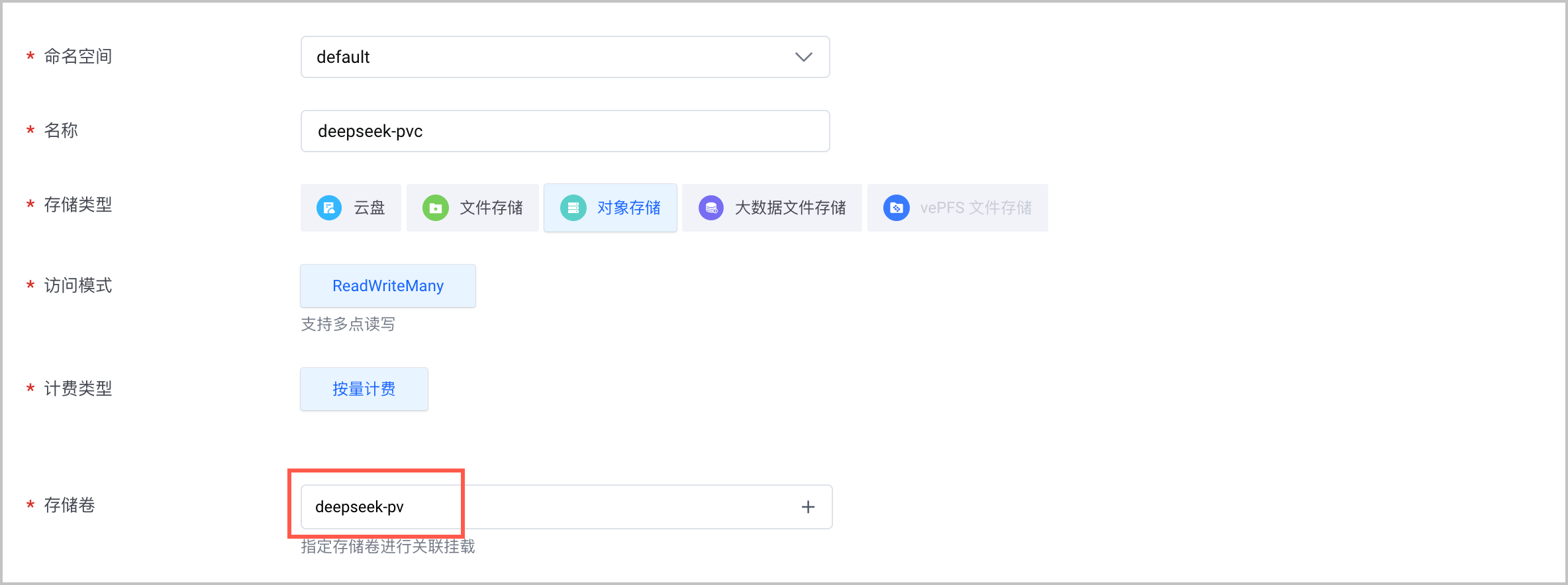
- 在已创建的 VKE 集群中创建存储卷(PV),需要注意以下列举的参数配置。
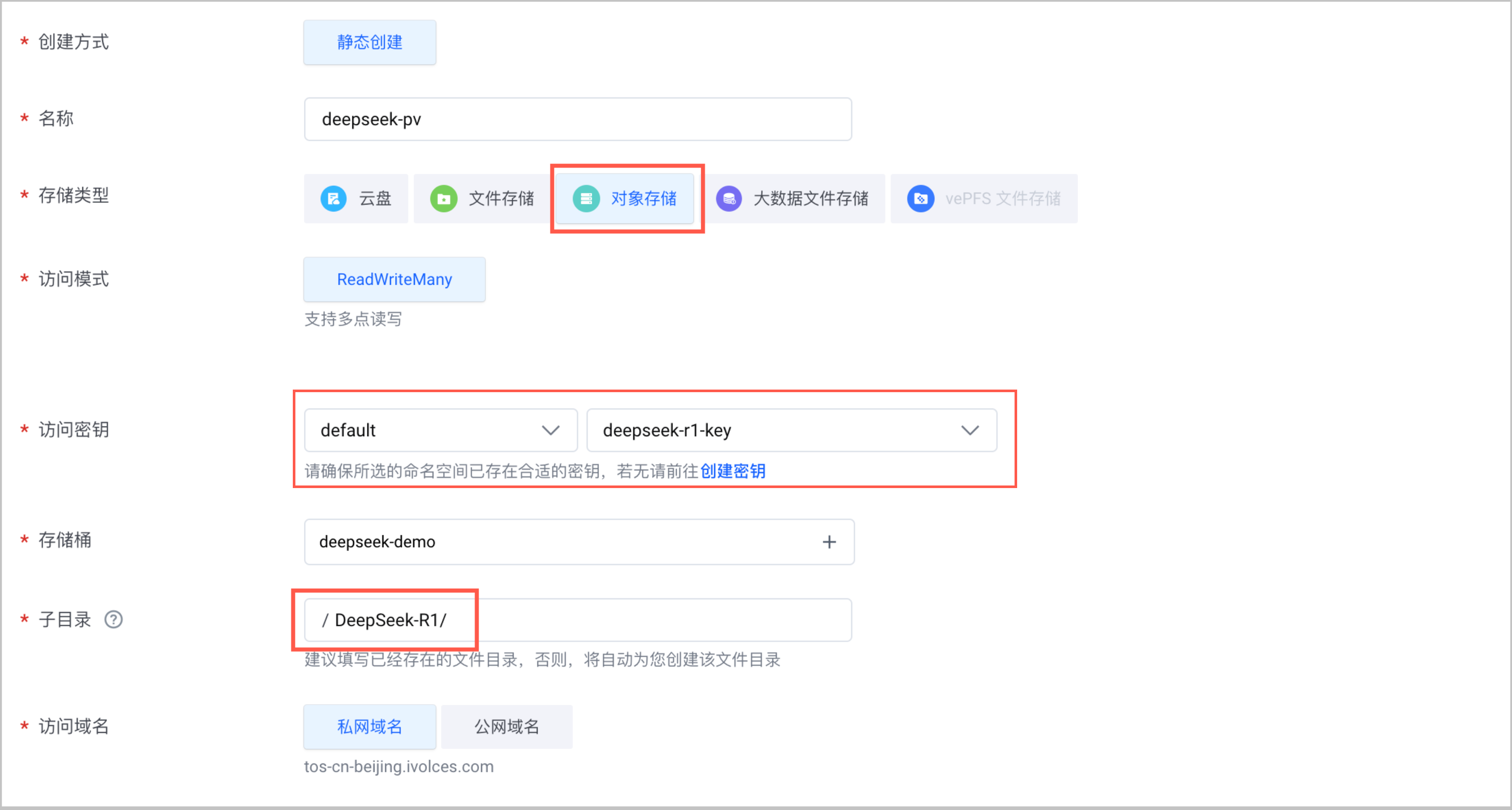
配置项 说明 存储类型 选择 对象存储。 访问密钥 单击 创建秘钥,完成秘钥配置。其中 AccessKey ID 和 AccessKey Secret 为您火山引擎账号的 AK/SK。获取方法,请参见 API访问密钥管理。 存储桶 选择已创建的 TOS 桶。 子目录 设置为 DeepSeek-R1/。 - 创建存储卷声明(PVC),关联上一步创建的 PV。
部署模型
完成部署模型前的准备工作后,开启正式部署满血版 DeepSeek-R1 模型的步骤。
步骤一:安装 LeaderWorkerSet
本文使用 LWS (LeaderWorkerSet) 来编排多节点的推理负载 (例如 DeepSeek V3/R1 需要跨两个节点部署),LWS 支持把一组 Pod 作为 Replicate 的对象。
使用预置 CR 镜像
说明
该操作方式仅支持 华北 2 地域。
- 在本地环境中下载如下 YAML 文件。


- 通过 kubectl 连接已创建的 VKE 集群。详情请参见 连接集群。
- 执行以下命令,使用预置 CR 镜像安装 LeaderWorkerSet。
kubectl apply --server-side -f manifest.yaml
使用官方镜像仓库
说明
该安装方式需要访问公网镜像仓库,因此需要集群开启公网访问和 Proxy,或者集群位于海外地域。
- 通过 kubectl 连接已创建的 VKE 集群。详情请参见 连接集群。
- 执行以下命令,使用官方镜像仓库安装 LeaderWorkerSet。
VERSION=v0.5.1
kubectl apply --server-side -f https://github.com/kubernetes-sigs/lws/releases/download/$VERSION/manifests.yaml
步骤二:部署推理负载
- 创建 DeepSeek-R1 模型应用。示例 YAML 文件
sglang.yaml如下所示。其中,LWS 控制器会创建一个 StatefulSet 管理所有 leader Pod,并为每一组负载 (此处固定 2 个 Pod 一组分布在两个节点上) 创建 StatefulSet。
说明
下方 YAML 文件的 SGLang 命令中 NCCL_IB_GID_INDEX 参数值,需要在容器中执行show_gids命令获取。如下图所示,选择使用 IPv4 地址且 VER 为 V2 的 INDEX,图中 INDEX 取值为 3。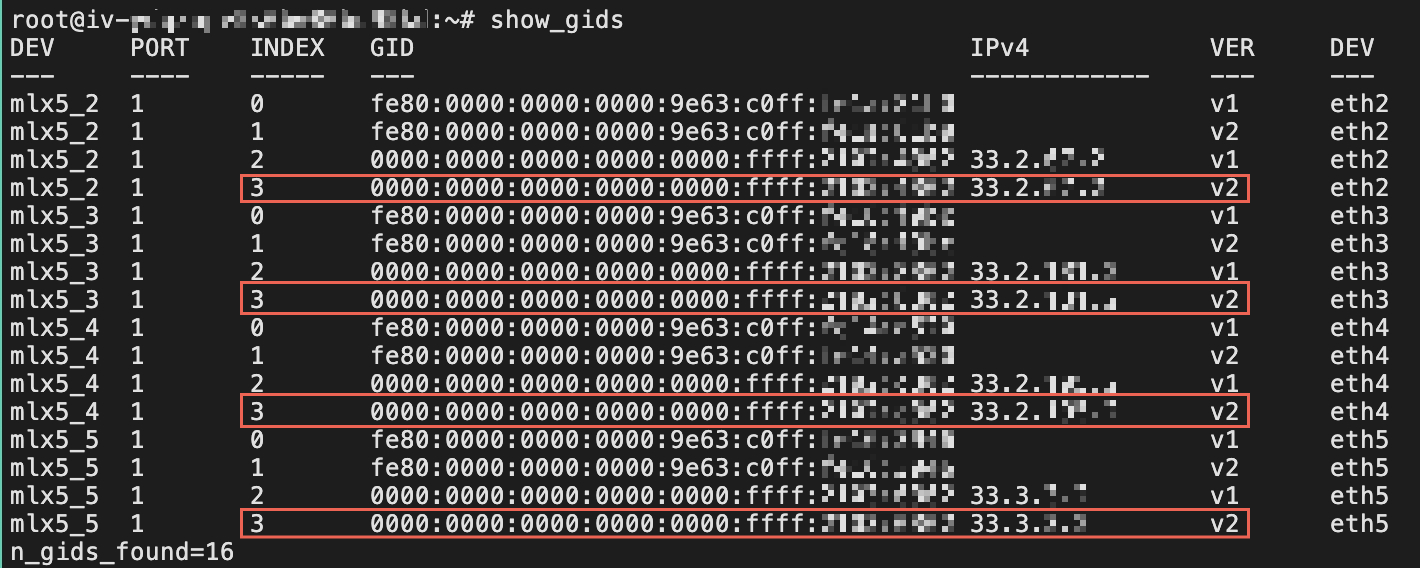
apiVersion: leaderworkerset.x-k8s.io/v1
kind: LeaderWorkerSet
metadata:
name: sglang
spec:
replicas: 1 # pod group 数量
startupPolicy: LeaderCreated
rolloutStrategy:
type: RollingUpdate
rollingUpdateConfiguration:
maxSurge: 0
maxUnavailable: 2
leaderWorkerTemplate:
size: 2
restartPolicy: RecreateGroupOnPodRestart
leaderTemplate:
metadata:
labels:
role: leader
annotations:
# 如需创建多张网卡设备,需要在 k8s.volcengine.com/pod-networks 中配置重复 N(网卡数)次。
k8s.volcengine.com/pod-networks: |
[
{
"cniConf":{
"name":"rdma"
}
},
{
"cniConf":{
"name":"rdma"
}
},
{
"cniConf":{
"name":"rdma"
}
},
{
"cniConf":{
"name":"rdma"
}
}
]
spec:
containers:
- name: sglang-head
image: ai-containers-cn-beijing.cr.volces.com/deeplearning/sglang:v0.4.3.post4-cu124
imagePullPolicy: IfNotPresent
workingDir: /sgl-workspace
command:
- bash
- -c
- 'cd /sgl-workspace && GLOO_SOCKET_IFNAME=eth0 NCCL_SOCKET_IFNAME=eth0 NCCL_IB_DISABLE=0 NCCL_IB_GID_INDEX=3 NCCL_IB_HCA=mlx5_ python3 -m sglang.launch_server --model-path /models/deepseek --tp 16 --dist-init-addr $LWS_LEADER_ADDRESS:20000 --nnodes $LWS_GROUP_SIZE --node-rank 0 --trust-remote-code --context-length 131072 --mem-fraction-static 0.9 --enable-metrics --host 0.0.0.0 --port 8080'
ports:
- containerPort: 8080
name: http
protocol: TCP
- containerPort: 20000
name: distributed
protocol: TCP
resources:
limits:
nvidia.com/gpu: "8"
vke.volcengine.com/rdma: "4" # 此处设置的网卡数量,需要与 Annotation:k8s.volcengine.com/pod-networks 中 RDMA 配置的重复次数相同。
requests:
nvidia.com/gpu: "8"
vke.volcengine.com/rdma: "4"
securityContext:
capabilities:
add:
- IPC_LOCK
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /models/deepseek
name: models
- mountPath: /dev/shm
name: shared-mem
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 10
volumes:
- name: models
persistentVolumeClaim:
claimName: deepseekr1
- emptyDir:
medium: Memory
name: shared-mem
dnsPolicy: ClusterFirst
workerTemplate:
metadata:
annotations:
# 如需创建多张网卡设备,需要在 k8s.volcengine.com/pod-networks 中配置重复 N(网卡数)次。
k8s.volcengine.com/pod-networks: |
[
{
"cniConf":{
"name":"rdma"
}
},
{
"cniConf":{
"name":"rdma"
}
},
{
"cniConf":{
"name":"rdma"
}
},
{
"cniConf":{
"name":"rdma"
}
}
]
spec:
containers:
- name: sglang-worker
image: ai-containers-cn-beijing.cr.volces.com/deeplearning/sglang:v0.4.3.post4-cu124
imagePullPolicy: IfNotPresent
workingDir: /sgl-workspace
command:
- bash
- -c
- 'cd /sgl-workspace && GLOO_SOCKET_IFNAME=eth0 NCCL_SOCKET_IFNAME=eth0 NCCL_IB_DISABLE=0 NCCL_IB_GID_INDEX=3 NCCL_IB_HCA=mlx5_ python3 -m sglang.launch_server --model-path /models/deepseek --tp 16 --dist-init-addr $LWS_LEADER_ADDRESS:20000 --nnodes $LWS_GROUP_SIZE --node-rank $LWS_WORKER_INDEX --trust-remote-code --context-length 131072 --mem-fraction-static 0.9 --enable-metrics --host 0.0.0.0 --port 8080'
env:
- name: LWS_WORKER_INDEX
valueFrom:
fieldRef:
fieldPath: metadata.labels['leaderworkerset.sigs.k8s.io/worker-index']
ports:
- containerPort: 8080
name: http
protocol: TCP
- containerPort: 20000
name: distributed
protocol: TCP
resources:
limits:
nvidia.com/gpu: "8"
vke.volcengine.com/rdma: "4" # 此处设置的网卡数量,需要与 Annotation:k8s.volcengine.com/pod-networks 中 RDMA 配置的重复次数相同。
requests:
nvidia.com/gpu: "8"
vke.volcengine.com/rdma: "4"
securityContext:
capabilities:
add:
- IPC_LOCK
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /models/deepseek
name: models
- mountPath: /dev/shm
name: shared-mem
dnsPolicy: ClusterFirst
volumes:
- name: models
persistentVolumeClaim:
claimName: deepseekr1
- emptyDir:
medium: Memory
name: shared-mem
- 执行如下命令,部署推理负载。
kubectl apply -f sglang.yaml
步骤三:配置服务和路由
为所有 leader 节点,即 HTTP 服务所在的节点,创建服务。示例文件
service-demo.yaml代码如下:apiVersion: v1 kind: Service metadata: name: sglang-api-svc labels: app: sglang spec: selector: leaderworkerset.sigs.k8s.io/name: sglang role: leader ports: - protocol: TCP port: 8080 targetPort: http name: http type: ClusterIP执行以下命令,创建服务。
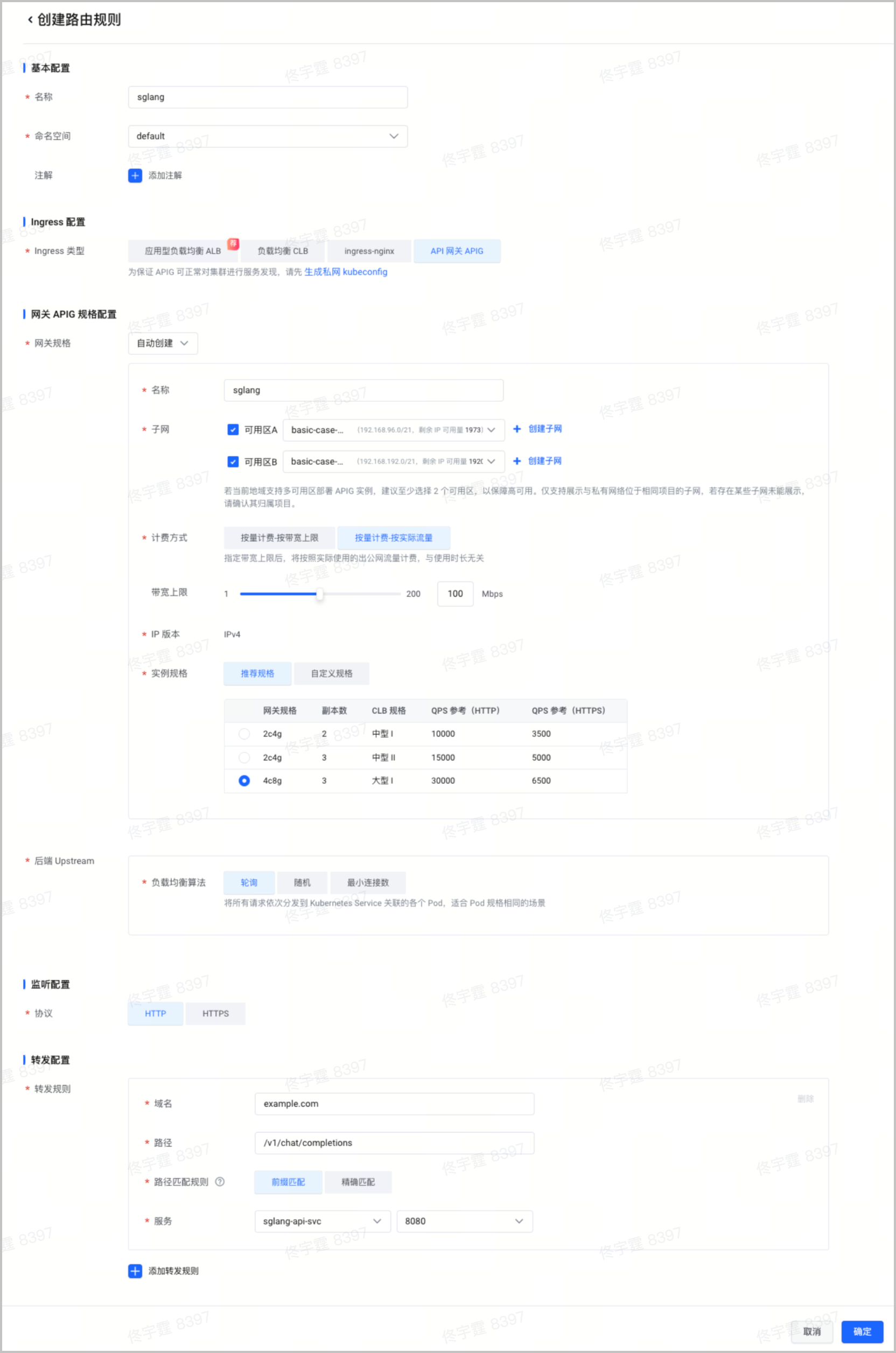
kubectl apply -f service-demo.yaml在集群管理页面的左侧导航栏中,选择 服务与路由 > 路由规则,单击 创建路由规则。使用 API 网关对外暴露集群内的模型服务。配置详情,请参见 通过控制台创建 APIG Ingress。
说明
使用 API 网关(APIG)暴露集群中的模型服务时,配置建议如下:
- 实例规格:建议选择 4c8g 规格,默认双可用区高可用。
- 负载均衡算法:建议配置为 轮询。在后端负载近似均衡的前提下,更适用于后端升级变更的场景。
- 请求超时:API 网关默认不超时,建议保持默认。如有超时需求,支持在 API 网关控制台 中配置超时,详情请参见 高级路由策略。
- 带宽上限:VKE 控制台上的配置项为 API 网关下 CLB 负载均衡的带宽,如需更大带宽,可以在 API 网关控制台 中绑定自定义 CLB 实例,详情请参见 添加访问入口。
- 可观测性:在 VKE 控制台上创建的 API 网关实例,默认情况下未开启监控告警和日志功能。如有需要,建议您在 API 网关控制台 中开启对应实例的日志和监控告警能力。
- 实例监控:能够帮助您从入口网关层面及时发现整个系统链路上的非预期现象。例如:后端不健康、后端 Crash 等,在 API 网关会报
503错误码,以及具体的错误详情。 - 实例日志:从访问日志里能够查看请求错误详情、请求耗时、请求在后端各个 Pod 的分布等详情。
- 实例监控:能够帮助您从入口网关层面及时发现整个系统链路上的非预期现象。例如:后端不健康、后端 Crash 等,在 API 网关会报
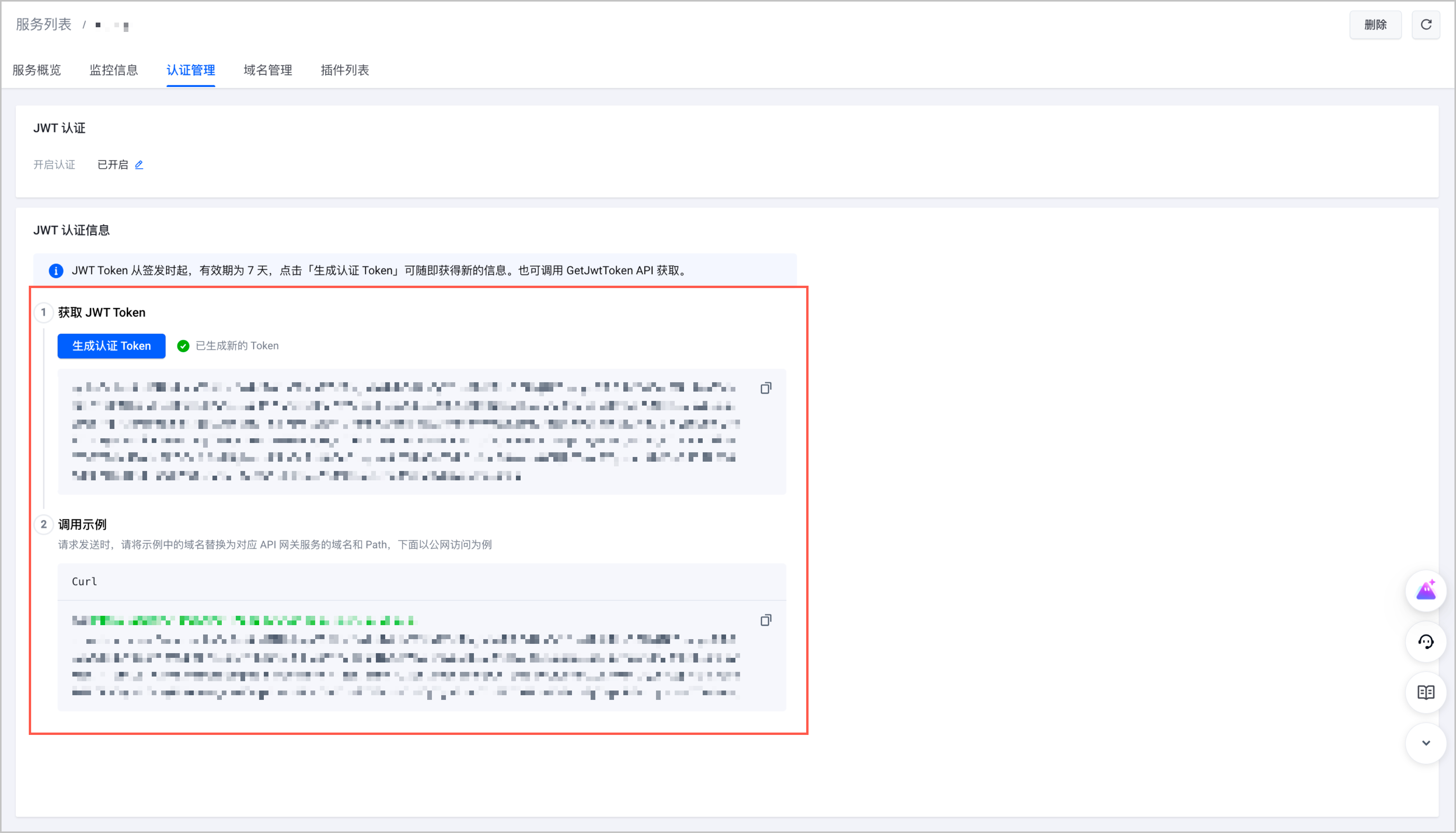
- (可选)配置 API 网关认证鉴权。
- 登录 API 网关控制台。
- 在左侧导航栏中选择 服务列表(域名)。
- 单击目标服务名称,进入服务详情页面。选择 认证管理 页签。
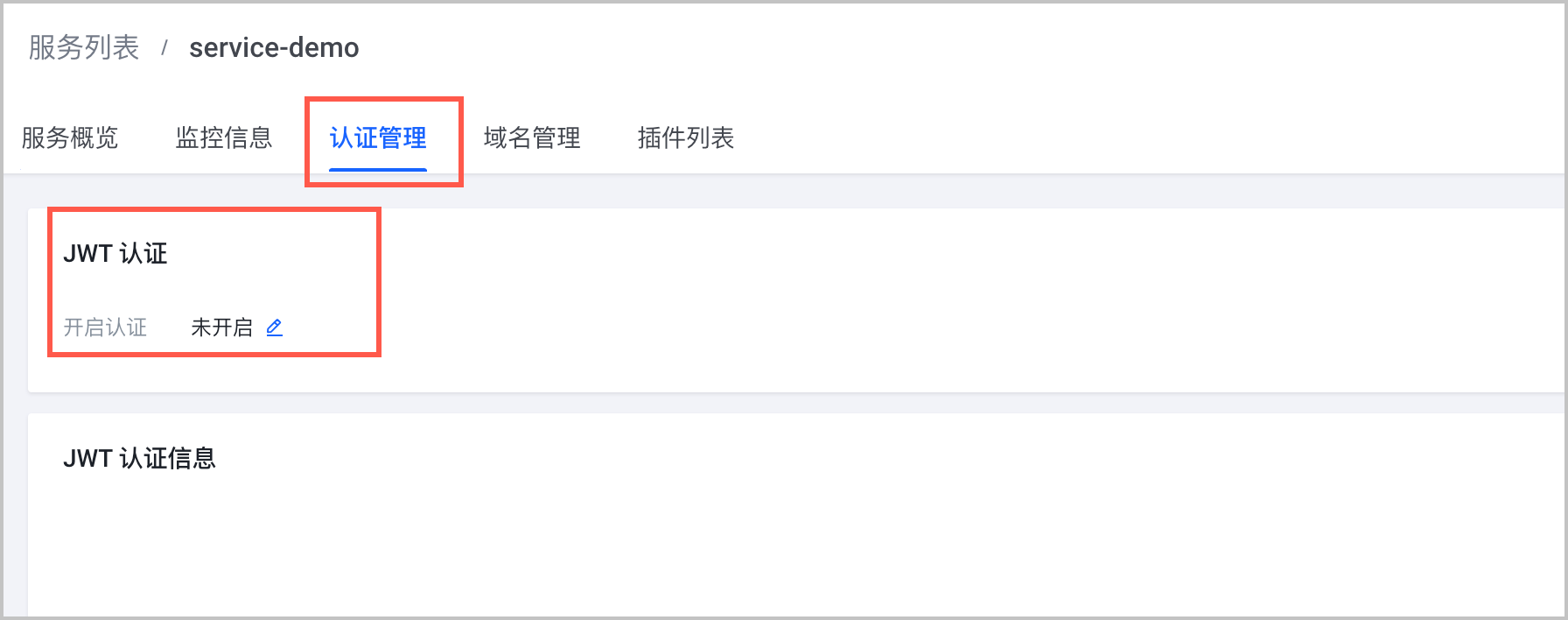
- 开启认证,并获取用于对用户进行校验的 JWT token。后续访问中,不携带该 Token 的请求将被拒绝。
步骤四:配置观测
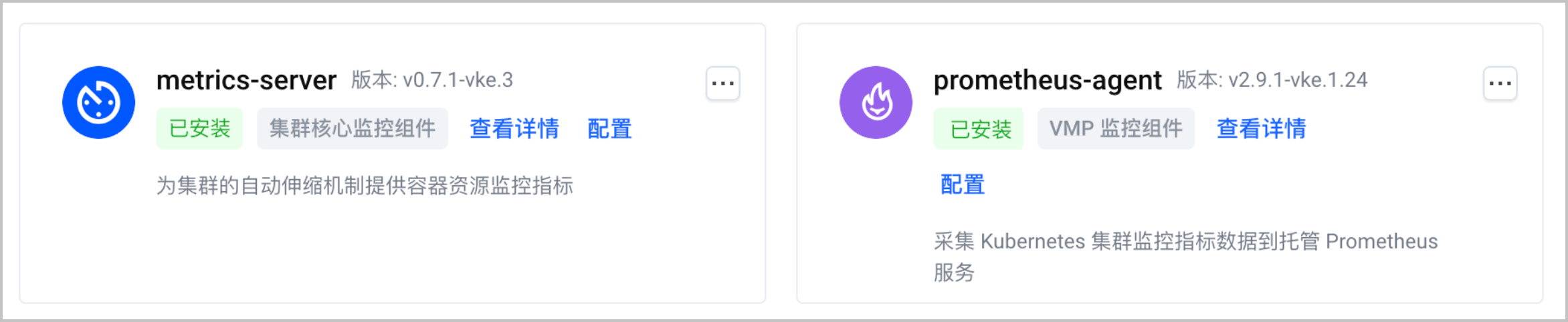
- 在集群管理页面的左侧导航栏中,选择 组件管理。
- 选择 监控 页签,确认 metrics-server 和 prometheus-agent 组件已安装。
- 在集群管理页面的左侧导航栏中,选择 云原生观测 > 概览,单击 立即启用,开启云原生观测和容器服务观测。更多配置详情,请参见 开启观测、容器服务观测。
- 在左侧菜单栏中选择 工作负载 > 对象浏览器。 单击 使用 Yaml 创建 ,通过 ServiceMonitor 配置服务发现。
- 在 类型 下拉菜单中选择 自定义。
- 在 Yaml 配置框内输入 Yaml 配置。
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: sglang-api-svc-discover # 配置采集规则名称
namespace: default # 配置 ServiceMonitor 命名空间
labels:
volcengine.vmp: "true" # 配置 ServiceMonitor 的标签,允许被 Prometheus-agent 发现
spec:
endpoints:
- port: http # 填写服务端口名称
namespaceSelector:
matchNames:
- default # 配置为服务所在的命名空间
selector:
matchLabels:
app: sglang # 配置服务的 Label 值,以定位和选择目标 Service
配置完成后,sglang 的应用指标就被采集到托管 Prometheus(VMP)了,您可以在托管 Prometheus 控制台中使用 Explore 查询指标,示例如下: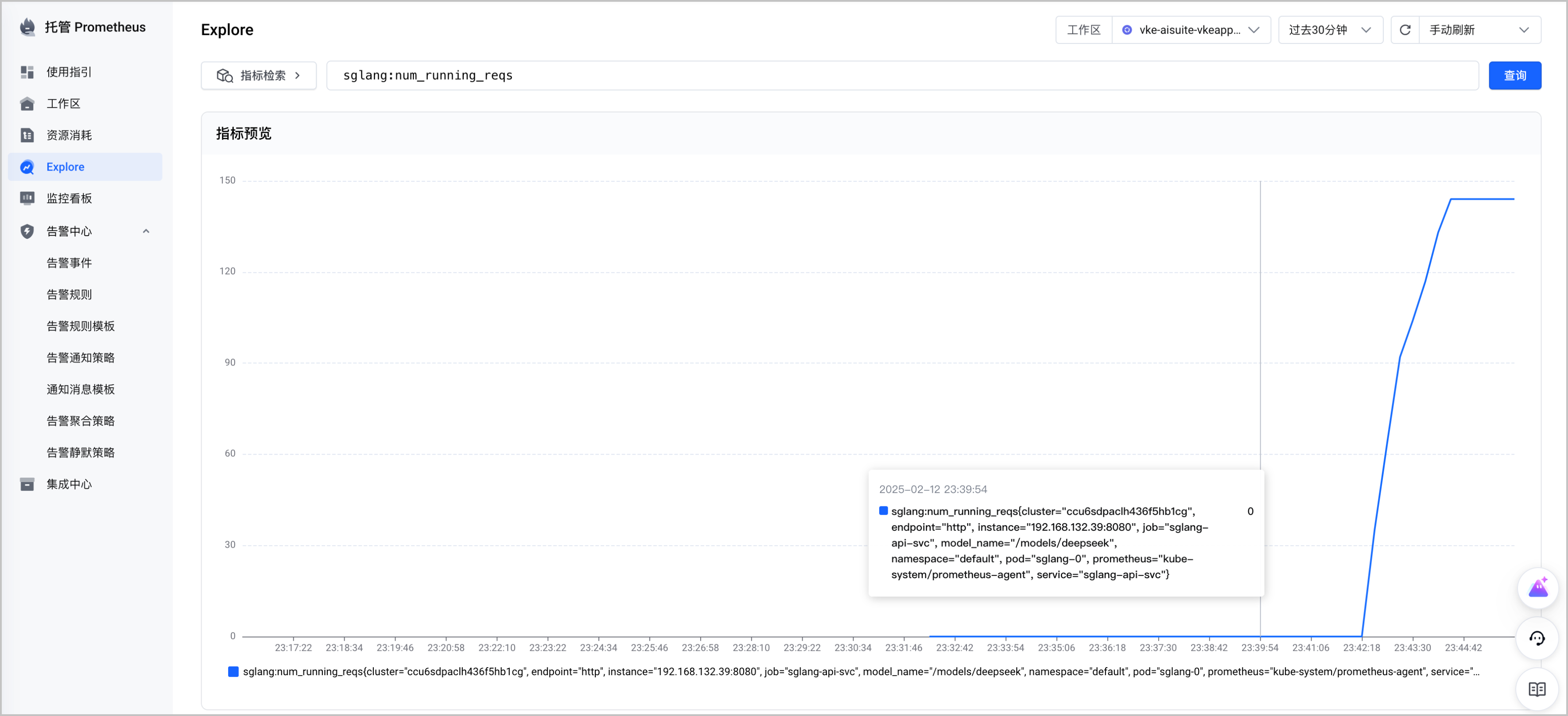
- 您也可以自建 Grafana,并搭建 sglang 的监控看版。操作方式请参见 在容器服务集群中部署 Grafana 并接入工作区。
- Grafana 部署完成后,使用默认用户名和密码登陆。
- 导入下面提供的监控看板 JSON 文件。
- 导入时数据源选择 VMP。
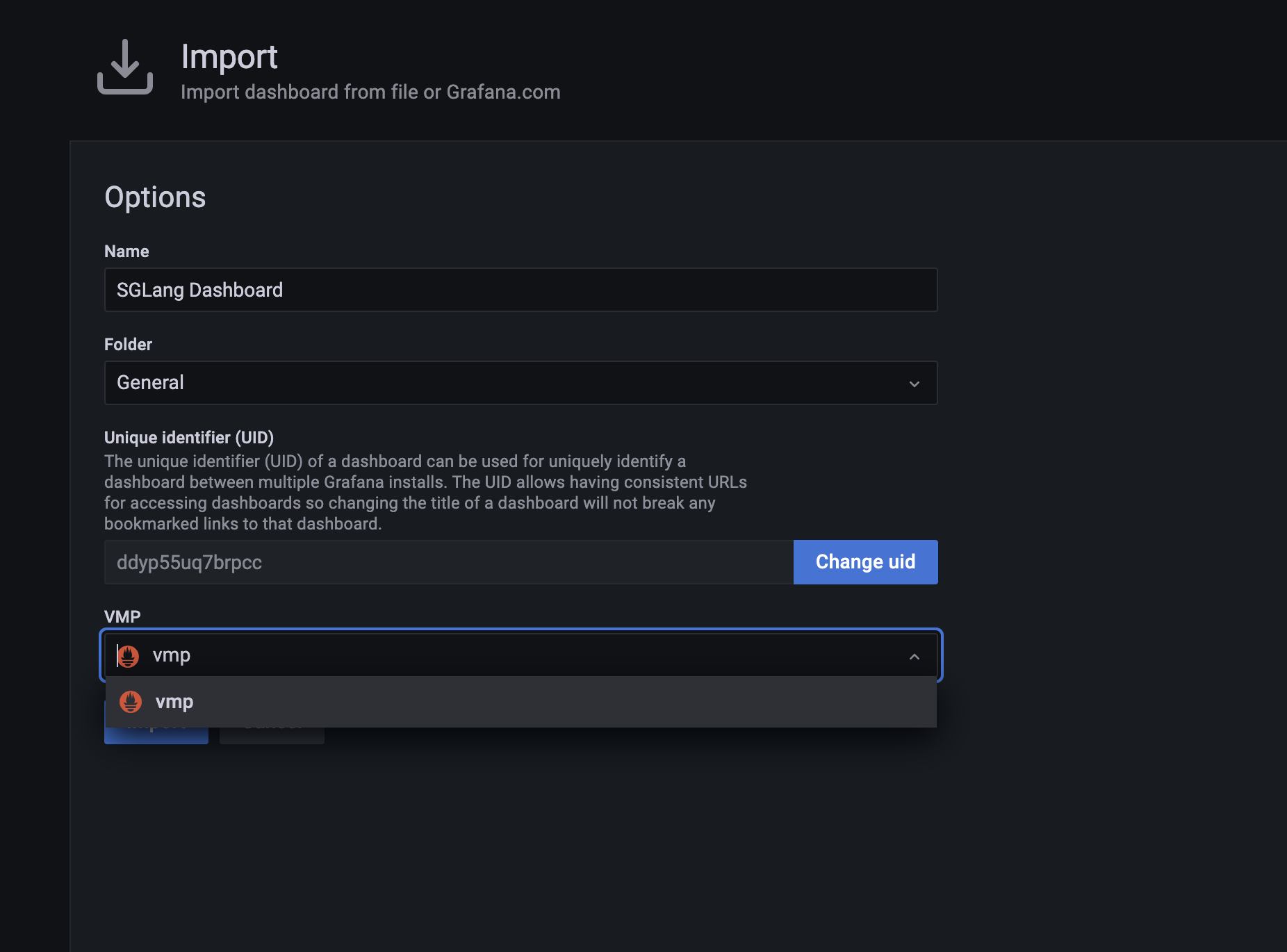
预期结果如下,您可以在 Grafana 中构建和查看监控大盘。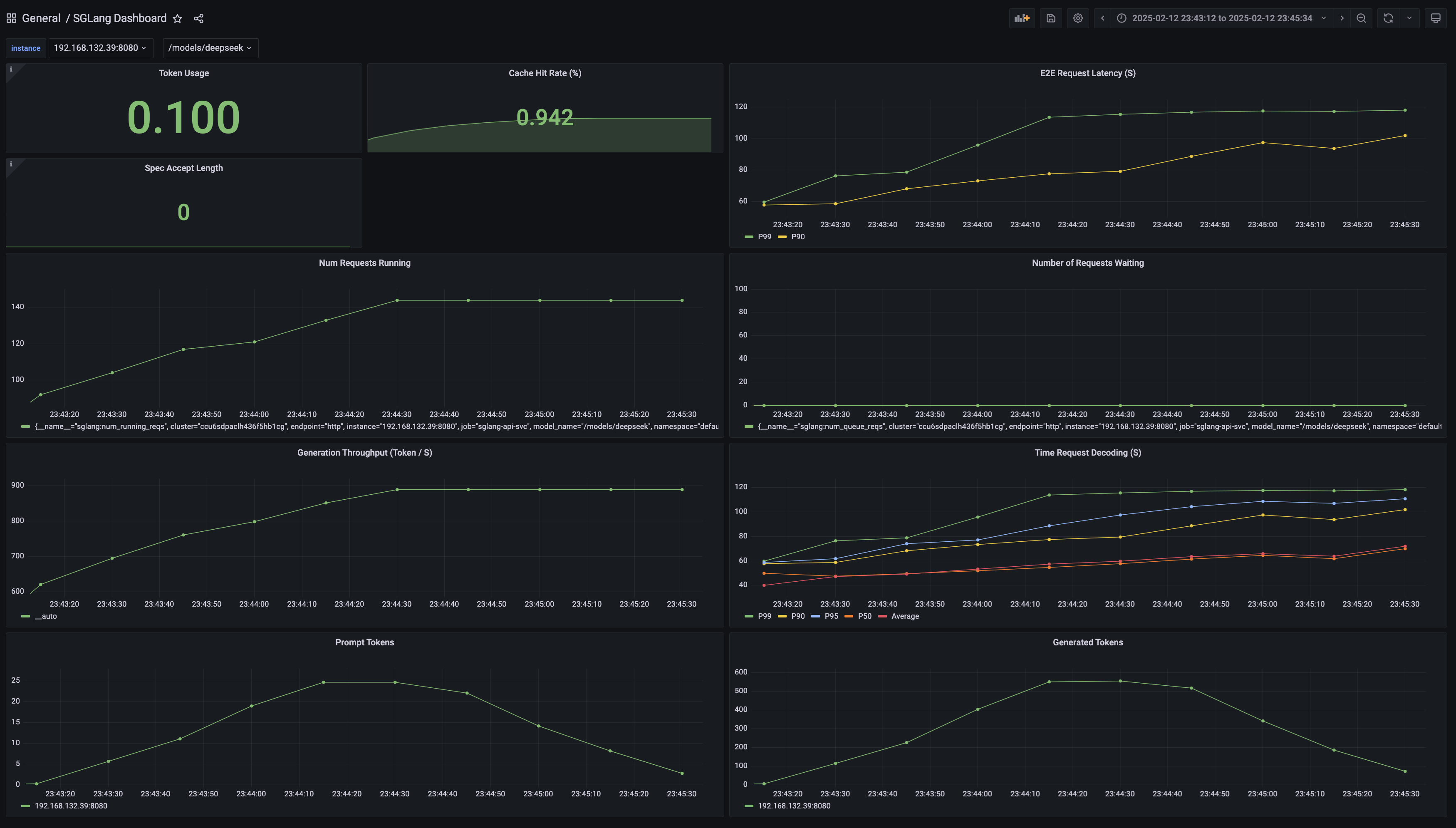
步骤五:配置弹性伸缩
为了提高资源利用率,您可以在集群中配置工作负载弹性伸缩和节点资源弹性伸缩。
工作负载弹性伸缩
说明
支持使用流量指标、GPU 指标和大模型指标,基于 KEDA 组件对 AI 负载进行伸缩。其中:
- 流量指标:由 API 网关提供。API 网关作为模型访问的入口,独立于 Pod 存在,因此可以实现将负载从 0 扩容。
- GPU 指标:开启云原生观测中的 AI 资源观测,系统会自动采集集群节点上 GPU 卡的指标,并将指标数据保存在托管 Prometheus 的工作区。
- 大模型指标:基于上文配置的 ServiceMonitor,系统实现了对集群中大模型工作负载的监控,并将指标数据保存在托管 Prometheus 的工作区。
- 在集群管理页面的左侧导航栏中,单击 观测配置,并选择 基础观测 页签。
- 选择 AI 资源 卡片,单击 启用,开启集群 AI 资源观测。
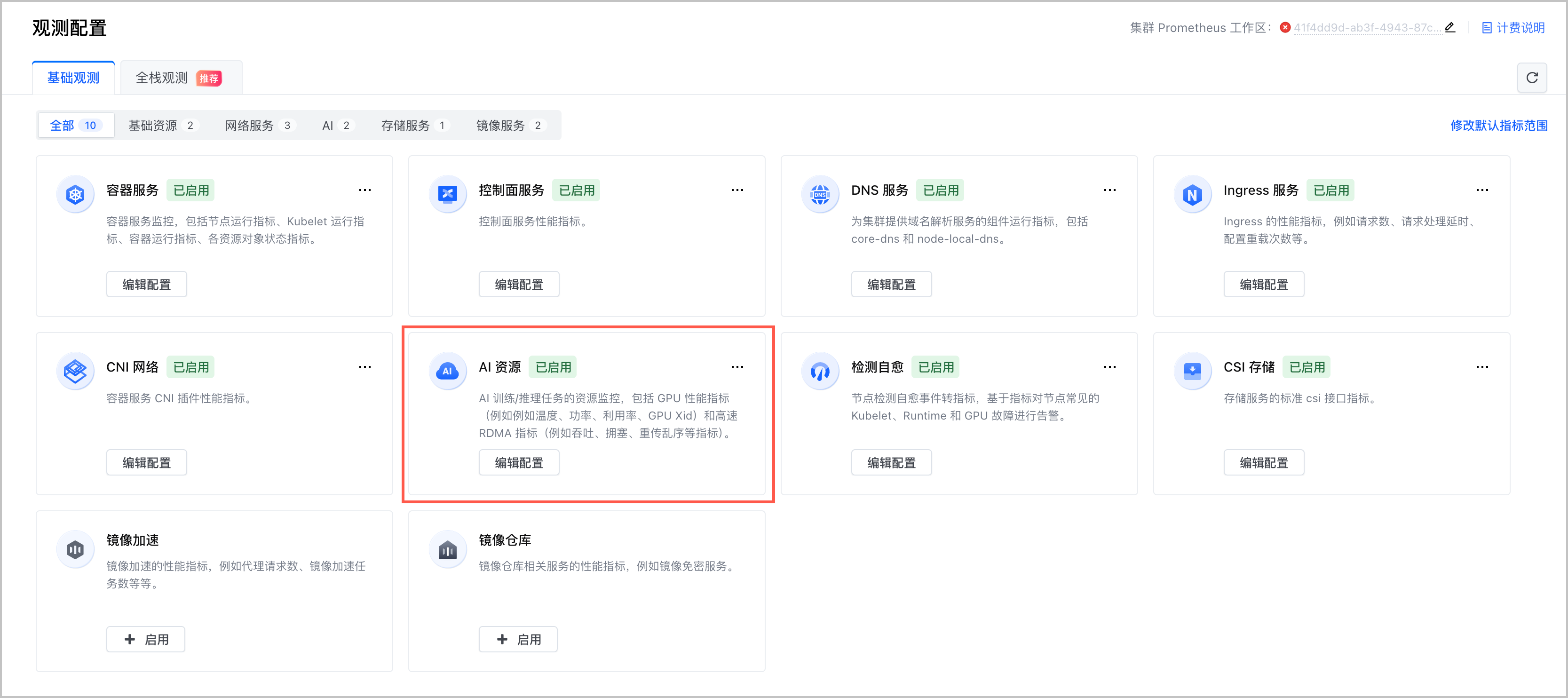
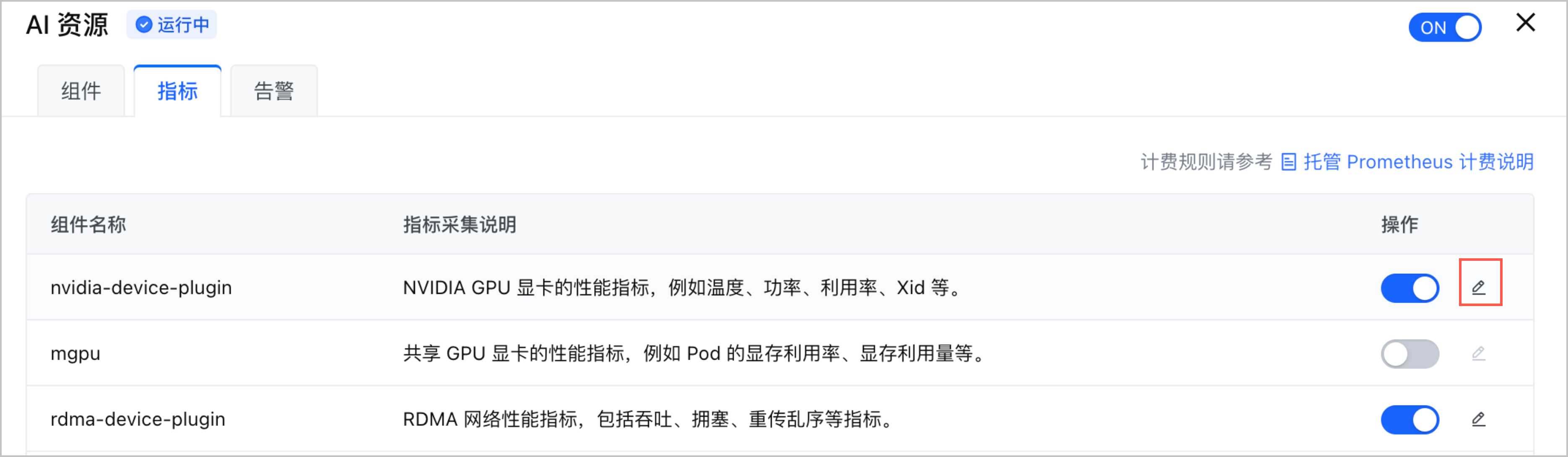
- 选择 AI 资源 卡片,单击 编辑配置 并选择 指标 页签,单击 nvidia-device-plugin 组件右侧的编辑图标。
- 本文选择使用
DCGM_FI_PROF_SM_ACTIVE作为工作负载弹性伸缩的指标,请确保该指标采集已被选择。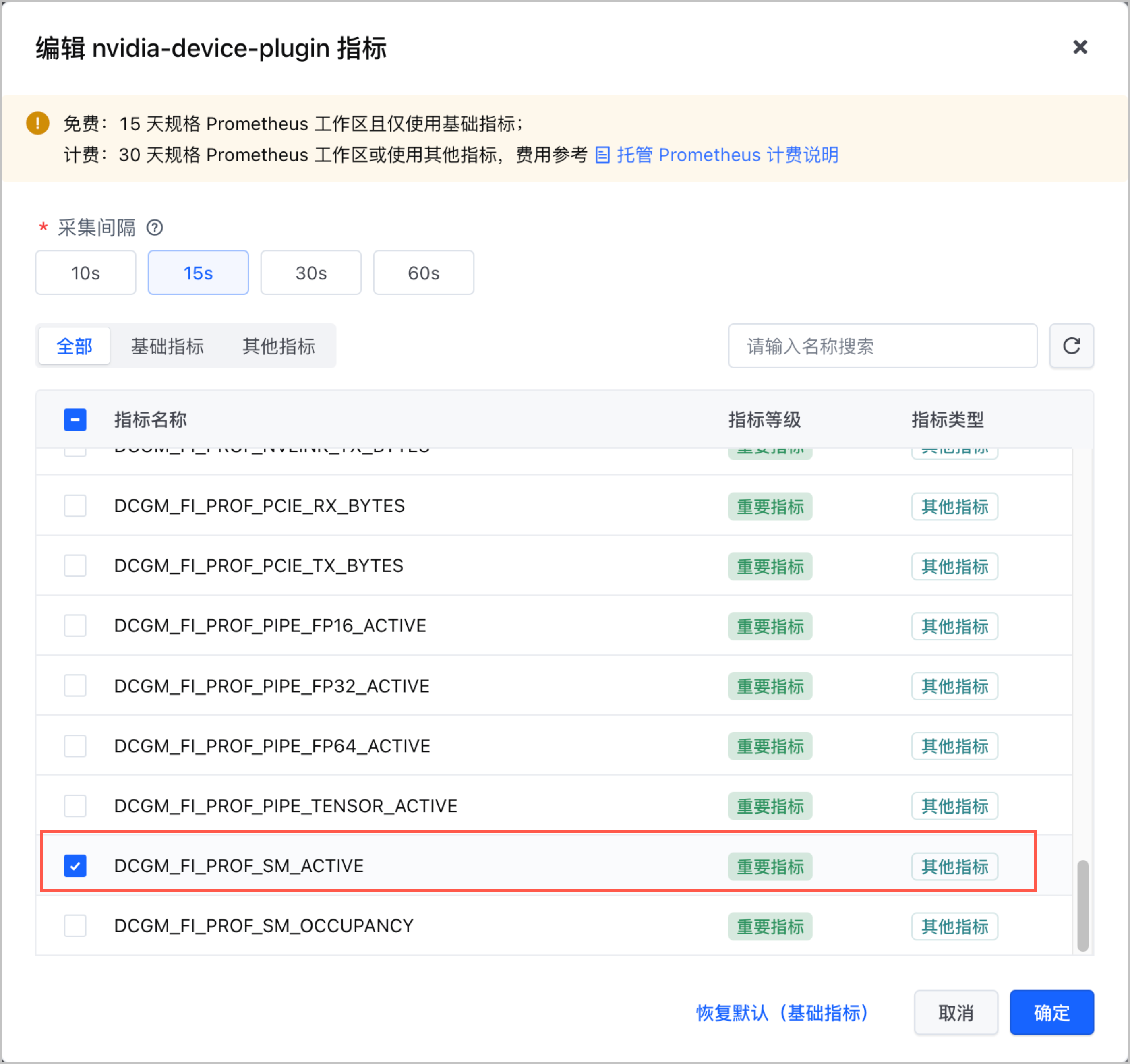
- 配置 KEDA,实现基于流量指标、GPU 指标和大模型指标的工作负载弹性伸缩。配置示例如下。
apiVersion: v1
kind: Secret
metadata:
name: keda-prom-secret
namespace: default
data:
username: "cm9vdA==" # Base64 编码后的工作区用户名,请根据实际修改
password: "UHdk******" # Base64 编码后的工作区密码,请根据实际修改
---
apiVersion: keda.sh/v1alpha1
kind: TriggerAuthentication
metadata:
name: keda-prom-creds
namespace: default
spec:
secretTargetRef:
- parameter: username
name: keda-prom-secret
key: username
- parameter: password
name: keda-prom-secret
key: password
---
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: sglang-scale
spec:
scaleTargetRef:
name: sglang # 指定部署推理负载时创建的 lws
kind: LeaderWorkerSet
apiVersion: leaderworkerset.x-k8s.io/v1
pollingInterval: 15
# 如果希望启用缩容到零能力,取消以下 3 行的注释。缩容到零可以在在没有流量时把副本数缩容到零,最大程度的减少资源闲置。
# idleReplicaCount: 0 # for keda trigger 0->1关键定义
# cooldownPeriod: 30 # 副本从1缩容到0的观察窗口期
# initialCooldownPeriod: 0 # cooldownPeriod 首次创建之后触发的观察窗口期
# 最小副本数(HPA)
minReplicaCount: 1
# 最大副本数(HPA)
maxReplicaCount: 2
triggers:
# APIG 流量指标
- type: prometheus
metadata:
serverAddress: http://query.prometheus-cn-beijing.ivolces.com/workspaces/64bc5ed***
threshold: '50'
query: sum(rate(istio_requests_total{request_host="example.com"}[1m])) by (request_host)
authModes: "basic"
authenticationRef:
name: keda-prom-creds
# sglang 指标
- type: prometheus
metadata:
serverAddress: http://query.prometheus-cn-beijing.ivolces.com/workspaces/64bc5ed***
threshold: '5'
query: avg(sglang:num_queue_reqs{cluster="ccu6***", service="sglang-api-svc"}) by (pod)
authModes: "basic"
authenticationRef:
name: keda-prom-creds
# GPU 指标
- type: prometheus
metadata:
serverAddress: http://query.prometheus-cn-beijing.ivolces.com/workspaces/64bc5ed***
threshold: '0.3'
query: avg(DCGM_FI_PROF_SM_ACTIVE{cluster="ccu6***", pod=~"sglang.*"})
authModes: "basic"
authenticationRef:
name: keda-prom-creds
上述示例中的部分参数需要根据实际环境修改,参数说明如下表所示。
| 参数 | 说明 |
|---|---|
keda-prom-secret | 托管 Prometheus 工作区的 BasicAuth 认证信息。详情请参见 管理工作区。
说明 原始用户名和密码必须首先进行 Base64 编码处理,然后再填写到此处。例如:如果您的原始密码为 |
| serverAddress | 托管 Prometheus 工作区 的 Query URL 地址。详情请参见 获取工作区地址。 |
| query | 指标查询语句,其中cluster=="ccu6***"为集群 ID,请填写为实际的集群 ID。 |
资源弹性伸缩
- 在集群管理页面的左侧导航栏中选择 节点池,单击 弹性伸缩配置,启用节点池弹性伸缩。
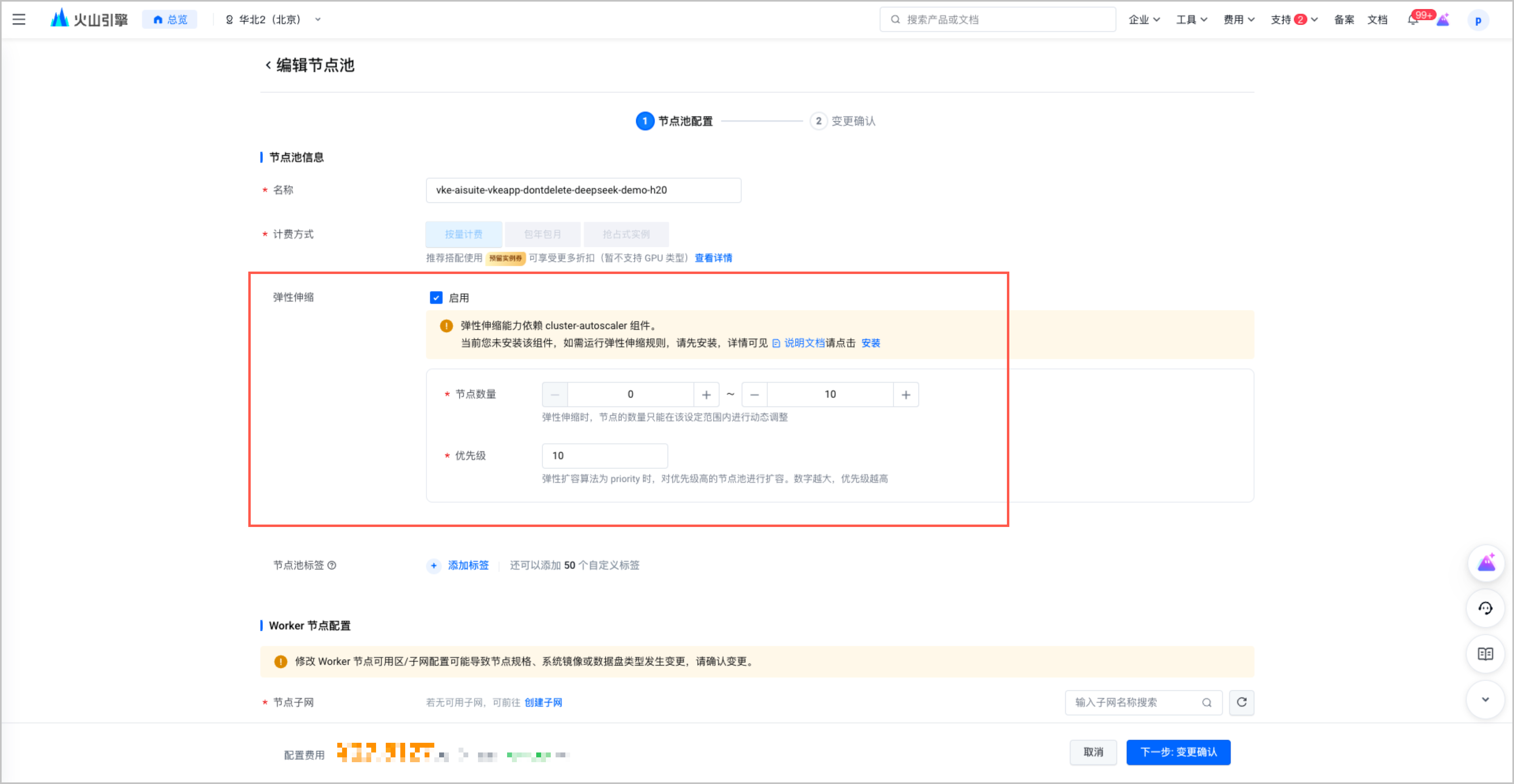
- 在 弹性伸缩配置 页面中,单击 编辑规则,配置弹性伸缩规则参数。

模型验证
使用 API 调用
大模型部署完成后,可以在本地环境中,使用自定义域名和接入点调用大模型并获取应答。示例如下。
curl http://example.com/v1/chat/completions -X POST \
-H "Content-Type: application/json" \
-d '{
"model": "/models/deepseek",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"}
]
}'
开启 API 网关的认证鉴权功能时,需要在请求中添加认证 Token,示例如下。
curl http://example.com/v1/chat/completions -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer eyJhbGciOiJSUzI1NiIsImtp***" \
-d '{
"model": "/models/deepseek",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"}
]
}'
使用第三方客户端调用
除使用 API 调用外,您也可以将上述模型添加到其他第三方客户端进行调用。例如:Dify 、cherrystudio、open-webui 等。
Dify
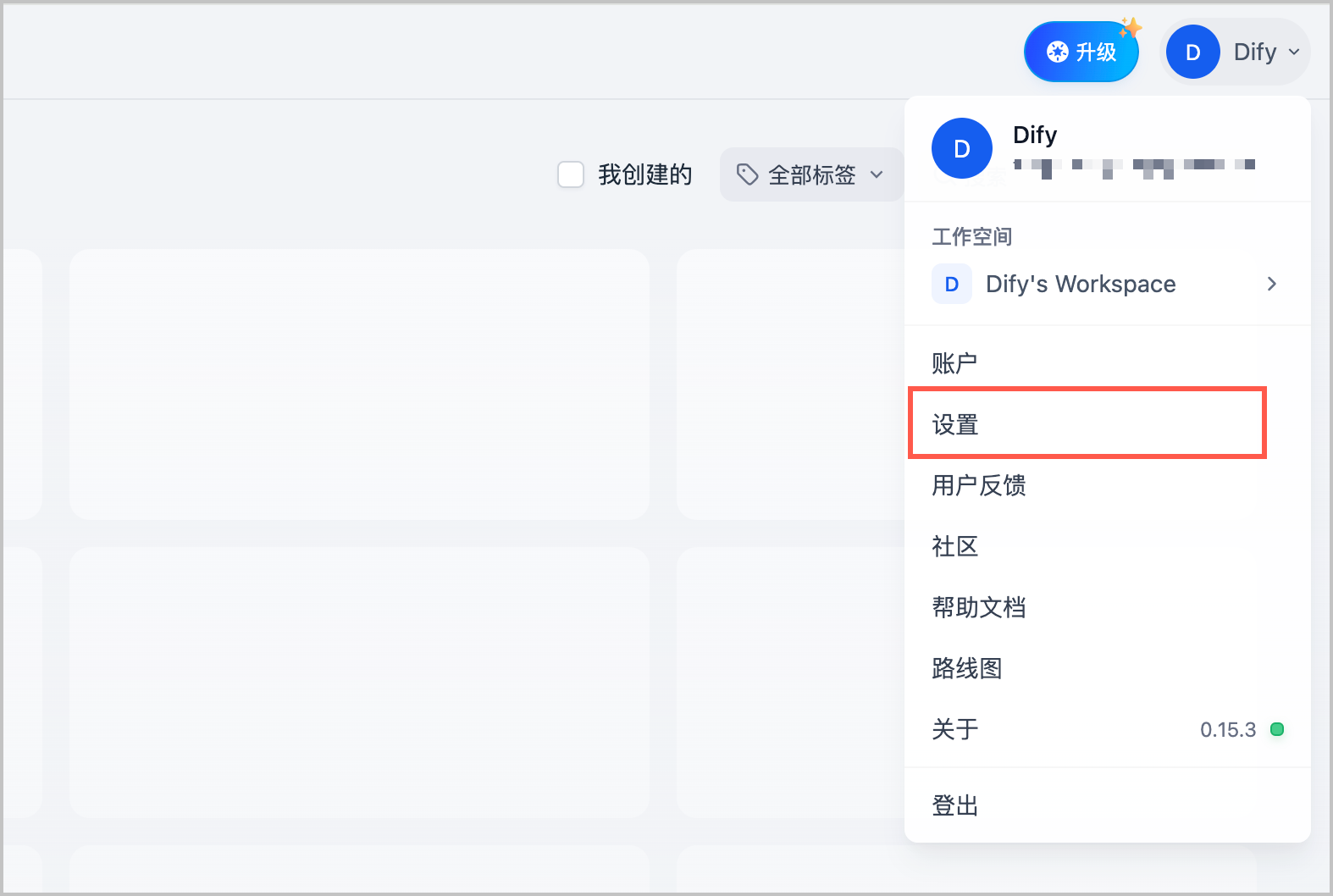
- 登录 Dify 首页。
- 在页面右上角单击 Dify 图标,在下拉菜单中选择 设置。
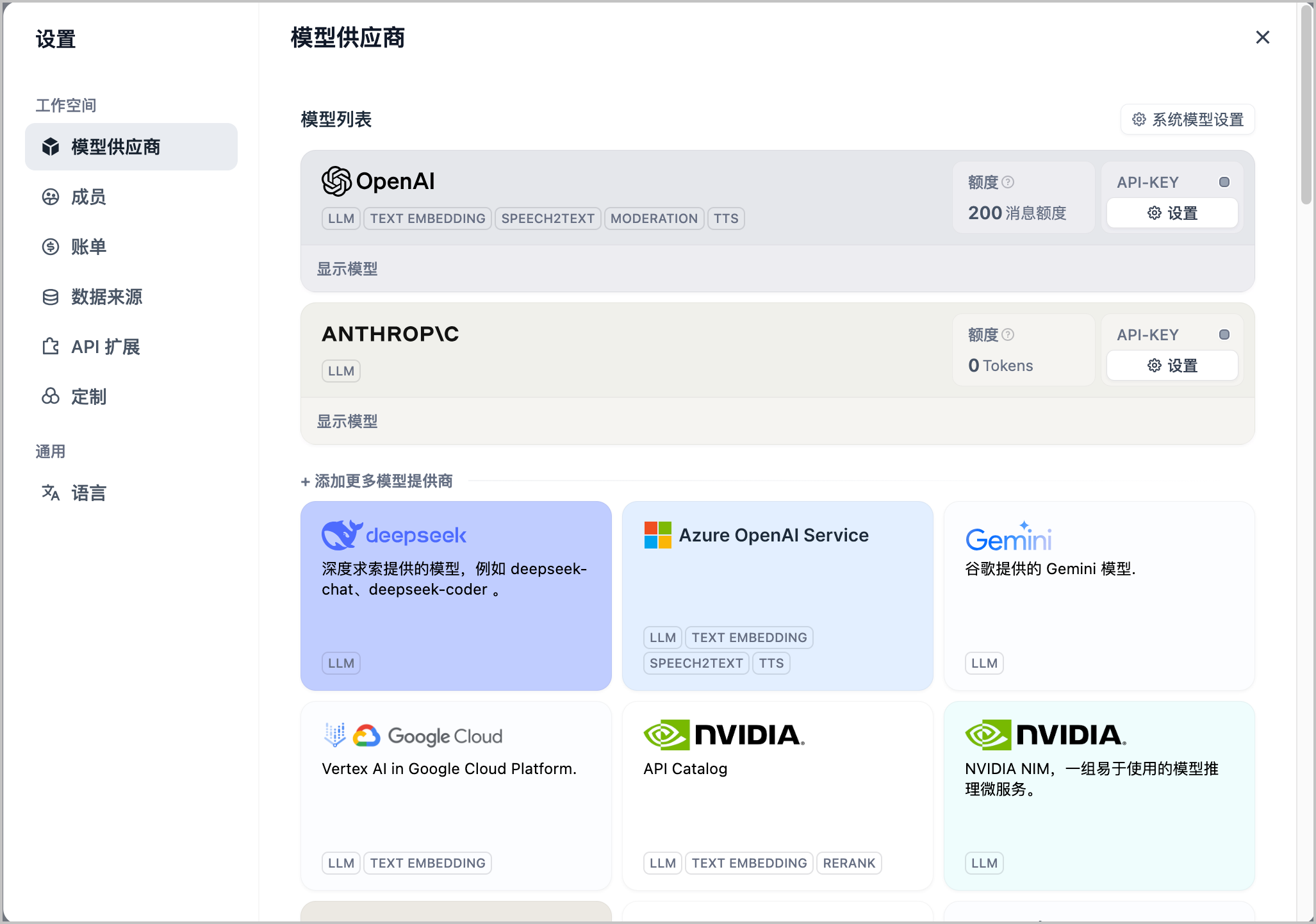
- 在 设置 页面的左侧导航栏中,选择 模型供应商。
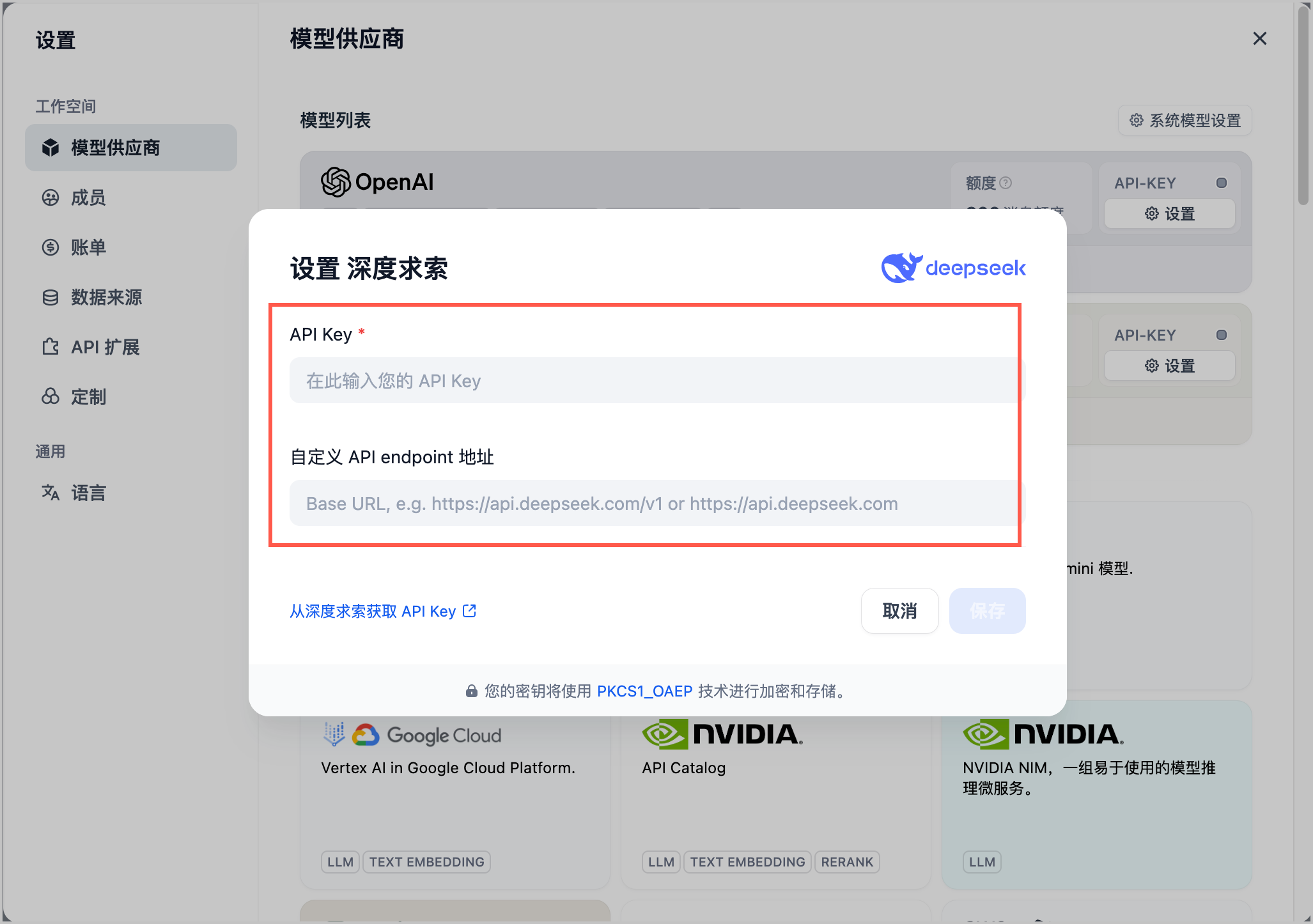
- 单击 设置,并填写 API 网关中配置的域名和 Token。
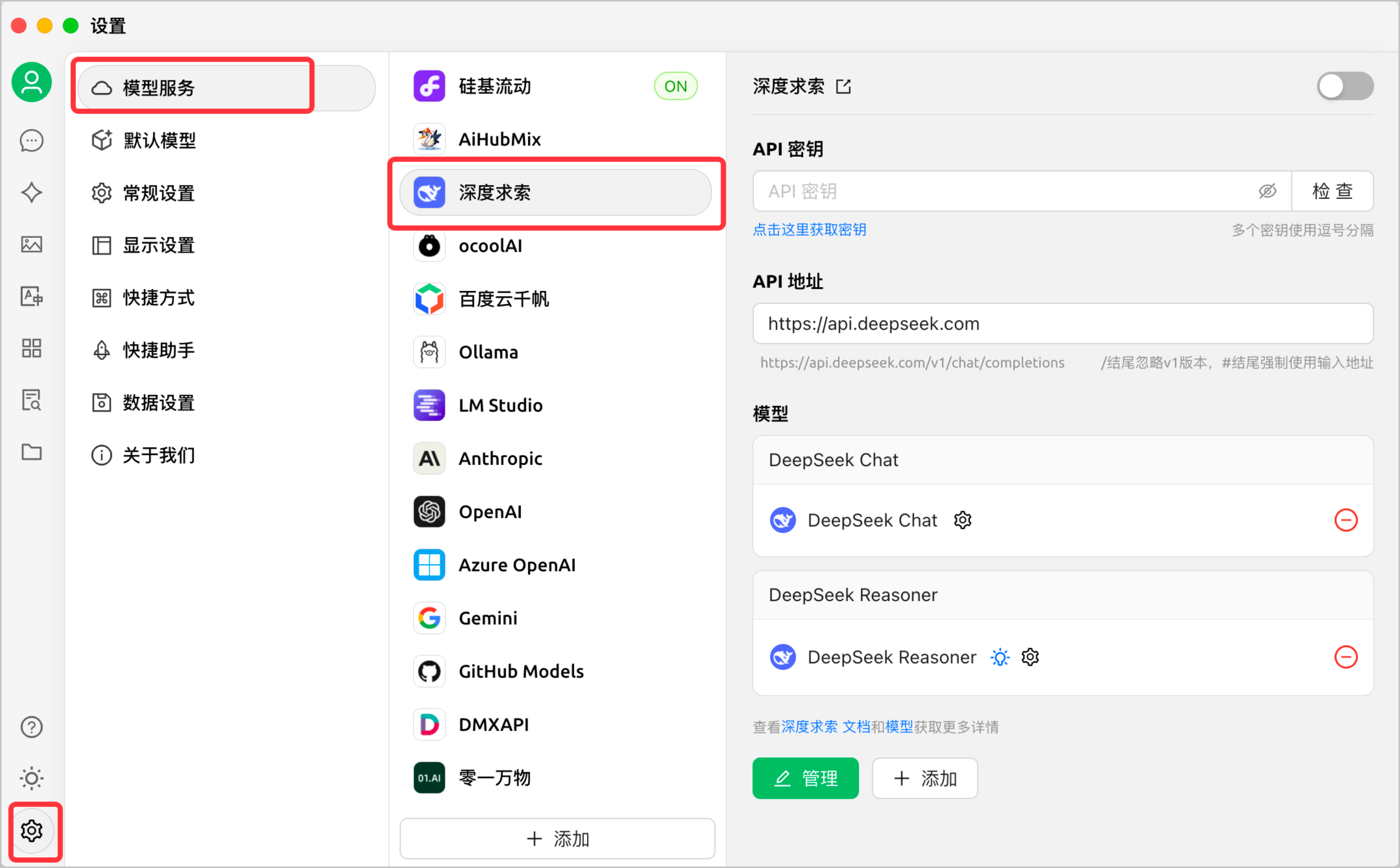
CherryStudio
- 在设置中选择 模型服务 > 深度求索。
- 在 API 地址、 API 密钥处填写 API 网关中配置的域名和 Token。