StarRocks 数据源,同步火山引擎 E-MapReduce(EMR)引擎中 StarRocks 集群数据库下的数据,为您提供通过离线、流式任务方式,读取和写入 StarRocks 的双向通道能力,实现不同数据源与 StarRocks 之间的进行数据传输。
本文为您介绍 DataSail 中 StarRocks 数据源配置、可视化配置能力说明。
1 支持的版本
支持采集 EMR-3.1.1 及以上 StarRocks 集群和 OLAP 服务中 1.1.0 及以上版本全托管 StarRocks 引擎中的数据。
2 使用前提
- 子账号新建数据源时,需要有项目的管理员角色,方可以进行新建数据源操作。各角色对应权限说明,详见:管理成员
- 访问 StarRocks 数据源,需先在项目控制台 > 服务绑定 > 引擎绑定中,绑定相应 StarRocks 集群。详见创建项目。
- StarRocks 数据源配置时,EMR 集群对应的集群信息、数据库用户名密码需填写正确:
- 必须有账户密码,其中 root 账户无密码,不符合安全规范,数据源配置时无法使用。
- EMR StarRocks 数据源类型,填写的数据库用户名信息,必须拥有相应数据库表的读写权限,来保障任务数据能够被正常读取或写入 StarRocks 中。您可在 EMR 集群详情 > 服务列表 > StarRocks 服务名称 > 服务参数 > starrocks-env 参数文件下,看到 StarRocks 已经预置了一个账户和密码,您可使用该账户/密码来配置 StarRocks 数据源。
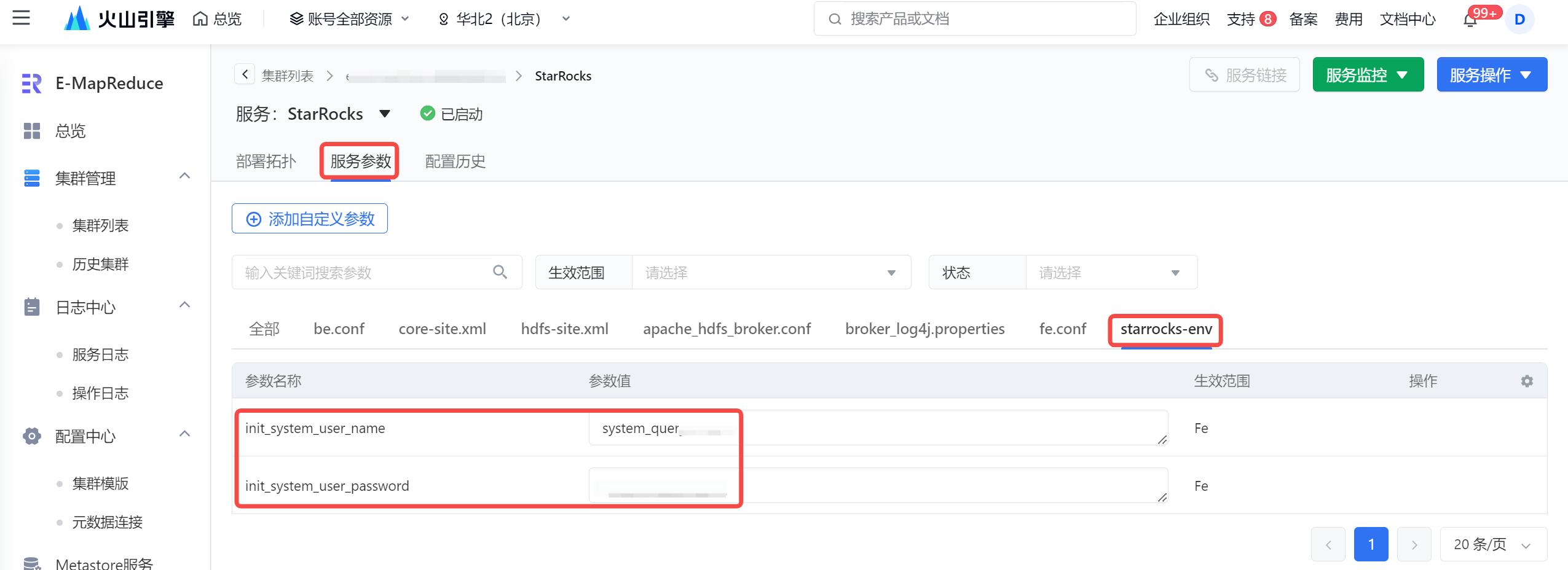
其余用户创建方式详见 CREATE USER。 - EMR Serverless StarRocks 数据源类型,填写的数据库用户名信息,必须拥有 db_admin 和 user_admin 角色,来保障解决方案能够正常执行,您可前往 EMR Serverless StarRocks 控制台 > 用户管理 > 用户权限详情中授予。
详见 Serverless StarRocks 管理用户权限。
- EMR StarRocks 集群和独享集成资源组中的 VPC 必须一致。
- 其 VPC 下的子网和安全组也尽可能保持一致。
- 若 VPC 不一致时,需额外进行以下网络打通操作:
- 两个不同 VPC 需要通过云企业网或其他专线连接操作,将两个 VPC 做网络打通;
- 并在 EMR StarRocks 集群详情界面,进入集群所在的安全组,并添加入方向规则。
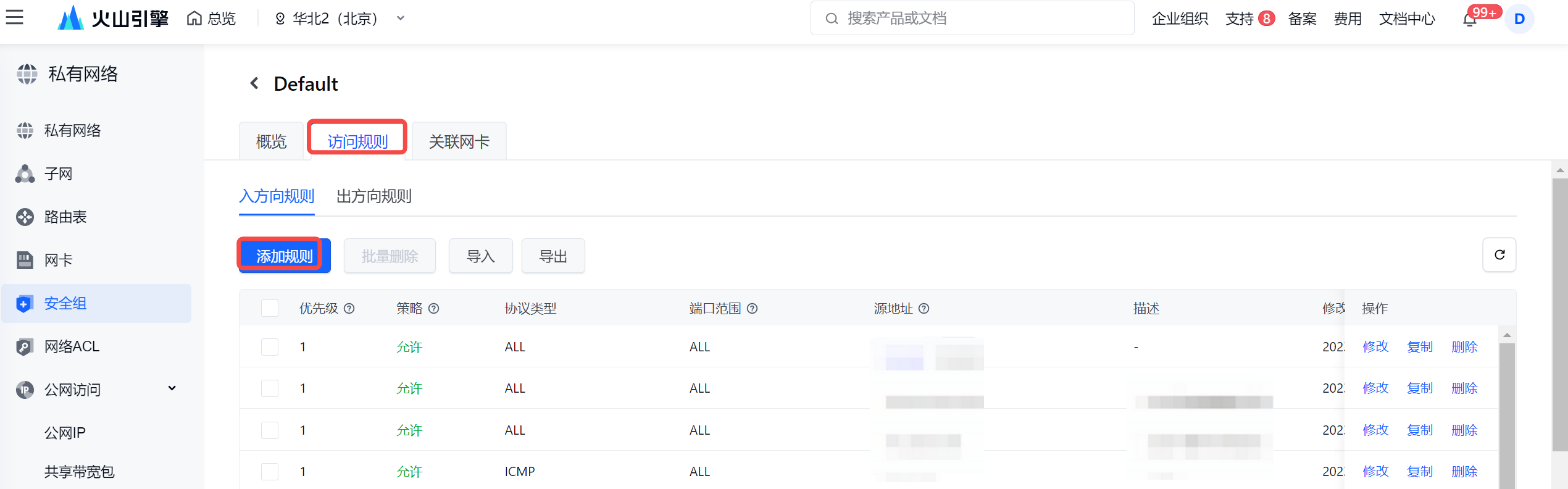
- 在弹窗中,填写独享集成资源组所在 VPC 和子网的 CIDR 网段信息:
- 安全组入方向规则添加完成后,您需额外通过提工单的方式,将独享集成资源组和 StarRocks 集群的 VPC 中的 CIDR 网段信息,提供给 EMR 技术支持同学,以便进行更细粒度的网络路由配置。
注意
当独享集成资源组与 StarRocks 集群处于不同 VPC 时,其网络配置较为复杂,在后续进行资源扩容时,仍需通过 EMR 技术支持来进行路由操作。因此,建议您将独享集成资源组与 StarRocks 集群使用的 VPC 信息保持一致。
- 在 DataSail 解决方案中,若把 StarRocks 作为目标数据源,并且通过该解决方案自动创建 StarRocks 表时,您需额外将 100.64.0.0/10 网段,添加到 StarRocks 集群所属的安全组中,以确保解决方案自动建表成功。
3 支持的字段类型与使用限制
支持大部分 StarRocks 类型,包括数值类型、字符串类型、日期类型:
字段类型 | 描述 | 支持情况 |
|---|---|---|
数值类型 | ||
TINYINT | 1 字节有符号整数,范围 [-128, 127] | 支持 |
SMALLINT | 2 字节有符号整数,范围 [-32768, 32767] | 支持 |
INT | 4 字节有符号整数,范围 [-2147483648, 2147483647]。 | 支持 |
BIGINT | 8 字节有符号整数,范围 [-9223372036854775808, 9223372036854775807] | 支持 |
LARGEINT | 16 字节有符号整数,范围 [-2^127 + 1 ~ 2^127 - 1] | 不支持 |
DECIMAL | DECIMAL(P [, S]) | 支持 |
DOUBLE | 8 字节浮点数。 | 支持 |
FLOAT | 4 字节浮点数。 | 支持 |
BOOLEAN | BOOL, BOOLEAN | 不支持 |
字符串类型 | ||
CHAR | CHAR(M) | 支持 |
VARCHAR | VARCHAR(M)
| 支持 |
STRING | 字符串,最大长度 65533 字节 | 支持 |
时间类型 | ||
DATE | 日期类型,目前的取值范围是 ['0000-01-01', '9999-12-31']。 | 支持 |
DATETIME | 日期时间类型,取值范围是 ['0000-01-01 00:00:00', '9999-12-31 23:59:59']。 | 支持 |
其他类型 | ||
Binary | StarRocks 3.X 版本支持 Binary 数据类型,用于存储二进制数据,单位为字节。 | 支持 |
ARRAY | 数组(Array) 是数据库中的一种扩展数据类型,其相关特性在众多数据库系统中均有支持,可以广泛的应用于 A/B Test 对比、用户标签分析、人群画像等场景。StarRocks 当前支持多维数组嵌套、数组切片、比较、过滤等特性。 | 不支持 |
BITMAP | BITMAP 与 HLL (HyperLogLog) 类似,常用来加速 count distinct 的去重计数使用。 | 不支持 |
JSON | JSON 数据层次清晰,结构灵活易于阅读和处理,广泛应用于数据存储和分析场景。 | 不支持 |
HLL | HyperLogLog 类型,用于近似去重。
| 不支持 |
4 数据同步任务开发
下文将为您介绍 StarRocks 数据集成同步任务的配置流程:
4.1 数据源注册
新建数据源操作详见配置数据源,下面为您介绍配置 StarRocks 数据源相关信息:
参数 | 说明 |
|---|---|
基本配置 | |
数据源类型 | StarRocks |
接入方式 | 当前支持 EMR StarRocks、EMR Serverless StarRocks 两种作为数据源接入。 |
数据源名称 | 数据源的名称,可自行设置,仅支持中文,英文,数字,“_”,100 个字符以内。 |
描述 | 对当前新建数据源的注释说明。 |
参数配置 | |
StarRocks 实例 ID | EMR 中创建的半托管 StarRocks 集群或 OLAP 服务中全托管 Serverless StarRocks 集群实例 ID。 |
计算组 | 当数据源接入方式选择 EMR Serverless StarRocks 时,可下拉选择已在 EMR Serverless StarRocks 集群控制台中创建好的计算仓库。 说明 创建 EMR Serverless StarRocks 集群时,实例类型需选择“多仓版(存算分离)”,方可进行计算仓库的创建。 |
数据库名 | 输入集群中的 StarRocks 库名称。 |
用户名 | 数据库的账号。 注意
账号权限注意事项详见2 使用前提。 |
密码 | 数据库用户名对应的密码信息。 |
4.2 新建任务
StarRocks 数据源测试连通性成功后,进入到数据开发界面,开始新建 StarRocks 相关通道任务。
新建任务方式详见离线数据同步、流式数据同步。
4.3 可视化配置说明
任务创建成功后,您可根据实际场景,配置 StarRocks 批式读写、StarRocks 流式写等通道任务相关参数:
说明
StarRocks 流式读暂不支持。
4.3.1 StarRocks 批式读
数据来源选择 StarRocks,并完成以下相关参数配置:
其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。
参数 | 说明 |
|---|---|
*数据源类型 | 下拉选择 StarRocks 数据源类型。 |
*数据源名称 | 已在数据源管理中注册成功的 StarRocks 数据源,下拉可选。 |
*数据表 | 选择需要采集的数据表名称信息,目前单个任务只支持将单表的数据采集到一个目标表中。 |
数据过滤 | 支持您将需要同步的数据进行筛选条件设置,只同步符合过滤条件的数据,可直接填写关键词 where 后的过滤 SQL 语句,例如:create_time > '${date}',表示只同步 create_time 大于等于 ${date} 的数据,不需要填写 where 关键字。 说明 该过滤语句通常用作增量同步,暂时不支持 limit 关键字过滤,其 SQL 语法需要和选择的数据源类型对应。 |
切分建 | 根据配置的字段进行数据分片,建议使用主键或有索引的列作为切分键:
说明 目前仅支持类型为整型或字符串的字段作为切分建。 |
4.3.2 StarRocks 批式写
数据目标端选择 StarRocks,并完成以下相关参数配置:
其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。
参数 | 说明 |
|---|---|
*目标类型 | 数据去向目标类型选择 StarRocks。 |
*数据源名称 | 已在数据源管理界面注册的 StarRocks 数据源,下拉可选。 |
*数据表 | 数据源下所属需数据写入的表名,下拉可选。 说明
|
*分区类型 | 根据目标表分区情况,您可选择将数据写入静态分区或动态分区类型:
|
写入前准备语句 | 在执行该数据集成任务前,需要率先执行的 SQL 语句,通常是为了使任务重跑时支持幂等。 说明 可视化通道任务配置中只允许执行一条写入前准备语句。 |
写入后准备语句 | 执行数据同步任务之后执行的 SQL 语句。例如写入完成后插入某条特殊的数据,标志导入任务执行结束。 说明 可视化通道任务配置中只允许执行一条写入后准备语句。 |
*数据写入方式 | 下拉选择数据写入 StarRocks 的方式,目前仅支持 Stream Load 的方式写入。 |
4.3.3 StarRocks 流式写
流式数据写入 StarRocks 集成任务,数据目标端选择 StarRocks,并完成以下相关参数配置:
其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。
参数 | 说明 |
|---|---|
*目标类型 | 数据去向目标类型选择 StarRocks。 |
*数据源名称 | 已在数据源管理界面注册的 StarRocks 数据源,下拉可选。 |
*数据表 | 数据源下所属需数据写入的表名,下拉可选。 说明 在一键建表的弹窗界面中,您可根据实际情况修改新建表的 DDL 语句,如表名、字段名、字段描述等信息。您也可对建表语句进行格式化、复制或编辑操作。 |
*分区类型 | 目标表选择分区表时,您可选择将源端数据写入动态分区类型:
|
4.3.4 字段映射
数据来源和目标端配置完成后,需要指定来源和目标端的字段映射关系,根据字段映射关系,数据集成任务将源端字段中的数据,写入到目标端对应字段中。
字段映射支持选择基础模式和转换模式配置映射:
注意
基础模式和转换模式不支持互相切换,模式切换后,将清空现有字段映射中所有配置信息,一旦切换无法撤销,需谨慎操作。
转换模式:
字段映射支持数据转换,您可根据实际业务需求进行配置,将源端采集的数据,事先通过数据转换后,以指定格式输入到目标端数据库中。
转换模式详细操作说明详见4.1 转换模式
在转换模式中,你可依次配置:来源节点、数据转换、目标节点信息:配置节点
说明
来源节点
配置数据来源 Source 节点信息:
- 节点名称:自定义输入来源节点名称信息,只允许由数字、字母、下划线、-和.组成;且长度不能超过10。
- 数据字段:通过自动添加、手动添加等方式添加数据来源字段信息。
配置完成后,单击确认按钮,完成来源节点配置。
数据转换
单击数据转换右侧添加按钮,选择 SQL 转换方式,配置转换信息和规则:
- 节点名称:自定义输入来源节点名称信息,只允许由数字、字母、下划线、-和.组成;且长度不能超过10。
- SQL 脚本:输入 SQL 脚本转换规则,目前仅支持添加一个转换的 SQL 语句,且不能包括 “;”。
配置完成后,单击确认按钮,完成数据转换节点配置。SQL 脚本示例详见4.1.2 添加转换节点。
目标节点
配置目标节点 Sink 信息:
- 节点名称:自定义输入来源节点名称信息,只允许由数字、字母、下划线、-和.组成;且长度不能超过10。
- 数据字段:通过自动添加、手动添加等方式添加数据目标字段信息。
配置完成后,单击确认按钮,完成目标节点配置。
基础模式:
您可通过以下三种方式操作字段映射关系:
- 自动添加:单击自动添加按钮,根据两端数据表信息,可以自动填充来源和目标的字段信息。
- 手动添加:单击手动添加按钮,可以手动编辑来源和目标的字段信息,可以逐个添加。
说明
来源端字段信息支持输入数据库函数和常量配置,单击手动添加按钮,在源表字段中输入需添加的值,并选择函数或常量类型,例如:
- 函数:支持您输入 now()、current_timestamp() 等 StarRocks 数据库支持的函数。
- 常量:您可自定义输入常量值,'123'、'${DATE}'、'${hour}' 等,输入值两侧需要加上英文单引号,支持结合平台时间变量与常量说明使用。
- 移动\删除字段:您也可以根据需要移动字段映射顺序或删除字段。
4.4 DSL 配置说明
StarRocks 数据源支持使用脚本模式(DSL)的方式进行配置。
在某些复杂场景下,或当数据源类型暂不支持可视化配置时,您可通过任务脚本的方式,按照统一的 Json 格式,编写 StarRocks Writer 参数脚本代码,来运行数据集成任务。
4.4.1 进入 DSL 模式
进入 DSL 模式操作流程,可详见 MySQL 数据源-4.4.1 进入DSL 模式。
4.4.2 StarRocks Writer
进入 DSL 模式编辑界面后,您可根据实际情况替换相应参数,StarRocks Writer 脚本示例如下:
未创建 StarRocks 数据源示例:
// writer config "writer": { // [required] datasource type "type": "starrocks" , // [optional] datasource id, set it if you have registered datasource "datasource_id": null, // [required] user parameter "parameter": { "password":"****************", "db_name":"sr_sink_test", "columns":[ { "upperCaseName":"ID", "name":"id", "type":"BIGINT" }, { "upperCaseName":"NAME", "name":"name", "type":"STRING" } ], "sink_write_mode":"STREAMING_UPSERT", "mysql_hosts":"172.16.1.2:9030", "fe_hosts":"172.16.1.2:8030", "user":"**********", "class":"com.bytedance.bitsail.connector.starrocks.sink.StarRocksSink", "table_name":"starrocks_sink_table_partation_dy_new", "pre_sql_list": ["delete from all_field_small_sink_1 where Id >= 0"], "post_sql_list": ["delete from all_field_small_sink_1 where Id >= 0"] } }已创建 StarRocks 数据源示例:
// writer config "writer": { // [required] datasource type "type": "starrocks" , // [optional] datasource id, set it if you have registered datasource "datasource_id": 100, // [required] user parameter "parameter": { "columns":[ { "upperCaseName":"ID", "name":"id", "type":"BIGINT" }, { "upperCaseName":"NAME", "name":"name", "type":"STRING" } ], "sink_write_mode":"STREAMING_UPSERT", "class":"com.bytedance.bitsail.connector.starrocks.sink.StarRocksSink", "table_name":"starrocks_sink_table_partation_dy_new", "pre_sql_list": ["delete from all_field_small_sink_1 where Id >= 0"], "post_sql_list": ["delete from all_field_small_sink_1 where Id >= 0"] } }Writer 参数说明,其中参数名称前带*的为必填参数,名称前未带*的为可选填参数:
参数名
参数说明
*type
数据源类型,对于 StarRocks 类型,填写:starrocks
*datasource_id
填写注册的 StarRocks 数据源 ID。可以在项目控制台 > 数据源管理界面中查找。
- 目前 DSL 模式默认推荐不填写数据源 ID,这里可填写 null。
- 若通过数据源 ID 方式配置,下方的 user、password、db_name、mysql_hosts、fe_hosts 参数可不输入。
*user
输入登录 StarRocks 集群数据库的用户名信息。
*password
登录 StarRocks 数据库用户名对应的密码。
*db_name
输入需要数据写入的 StarRocks 数据库名称。
*table_name
填写数据源下所需数据写入的表名。
*class
starrocks writer connector type,默认固定值: com.bytedance.bitsail.connector.starrocks.sink.StarRocksSink
*columns
所配置的表中需要同步的列名集合,使用 JSON 的数组描述字段信息。
- 支持列裁剪:列可以挑选部分列进行导出。
- 支持列换序:列可以不按照表 Schema 信息顺序进行导出。
- 支持函数、常量形式添加列:
- 函数:StarRocks Reader 支持您输入 now()、current_timestamp() 等 StarRocks 数据库支持的函数。
- 常量:StarRocks Reader 支持您自定义输入常量值,如 '123'、'${DATE}'、'${hour}' 等,输入值两侧需要加上英文单引号,支持结合时间变量参数使用。
*sink_write_mode
输入数据写入 StarRocks 的方式,当前仅支持 streaming_upsert 方式写入,参数值:STREAMING_UPSERT。
*mysql_hosts
StarRocks 集群支持的 jdbc 节点信息,您可进入 EMR 控制台 > StarRocks 集群详情 > StarRocks 服务部署拓扑 > Fe 组件界面,获取 Fe ip 信息,端口号通常默认为 9030。
*fe_hosts
StarRocks 集群 Fe 节点信息,您可进入 EMR 控制台 > StarRocks 集群详情 > StarRocks 服务部署拓扑 > Fe 组件界面,获取 Fe ip 信息,端口号通常默认为 8030。
pre_sql_list
写入前准备语句:在执行数据集成任务前,率先执行的 SQL 语句。此语句通常是为了使任务重跑时支持幂等。
例如您可以通过填写写入前准备语句,清空表中的某些旧数据,清空完成后,再执行集成任务写入新的数据。如清空表中 p1,p2 分区:TRUNCATE TABLE table_name PARTITION(p1, p2);说明
DSL 模式支持配置多条写入前准备语句,多条语句之间用英文逗号分隔。
post_sql_list
写入后准备语句:执行数据同步任务后执行的 SQL 语句。例如数据写入完成后,插入某条特殊的数据,标志导入任务执行结束。
说明
DSL 模式支持配置多条写入后准备语句,多条语句之间用英文逗号分隔。
4.5 高级参数说明
4.5.1 高级参数配置方式
- 对于通道任务,读参数需要加上
job.reader.前缀,写参数需要加上job.writer.前缀,如下图所示: - 对于 DSL 任务,读参数请配置到
reader.parameter下,写参数请配置到writer.parameter下,直接输入参数名称和参数值。如下图所示:
4.5.2 StarRocks 批式写
批式写支持以下高级参数,您可根据实际情况进行配置:
参数名 | 参数默认值 | 参数说明 |
|---|---|---|
job.writer.sink_flush_interval_ms | 60000 | 写入 buffer 刷新时间,默认 60000 毫秒 |
job.writer.sink_buffer_size | 10485760 | 写入 buffer 数据大小,默认 10485760 (10MB) |
job.writer.sink_buffer_count | 8192 | 写入buffer 记录条数,默认 8192 |
job.writer.stream_load_properties | 整行更新 | 数据写入方式参数指定。
|
job.writer.request_read_timeouts | 60000 | 写入等待获取结果时间,默认 60000 毫秒 |
job.writer.request_connect_timeouts | 60000 | 写入连接超时时间,默认 60000 毫秒 |
job.writer.sink_enable_2PC | false | 写入时任务分两阶段提交,默认 false |