您可以通过创建火山引擎 E-MapReduce(EMR)的 MapReduce 任务,调用 MapReduce 提供的接口处理存储在 hdfs 上的数据,也可以将复杂的数据集通过 MapReduce 任务,拆分为多个简单的 MapReduce 子任务来并行处理,提升运算效率。
本文将通过一个 WordCount 案例,即统计文件中的单词数量为例,来为您介绍如何创建 EMR MapReduce 节点,并应用到实际的开发流程场景中。
1 使用前提
- 已创建 EMR-3.2.1 及以上或 EMR-2.2.0 的 Hadoop 集群类型版本。详见创建集群。
- 若仅开通 DataLeap 版本中湖仓一体的服务,项目不支持绑定 EMR 引擎。详见DataLeap 公有云版本功能差异。
- 已在 DataLeap 租户控制台中,绑定相应的 EMR Hadoop 集群实例。详见绑定 Hadoop 集群。
- 在 DataLeap 项目控制台中,绑定 EMR Hadoop 集群实例。详见创建项目。
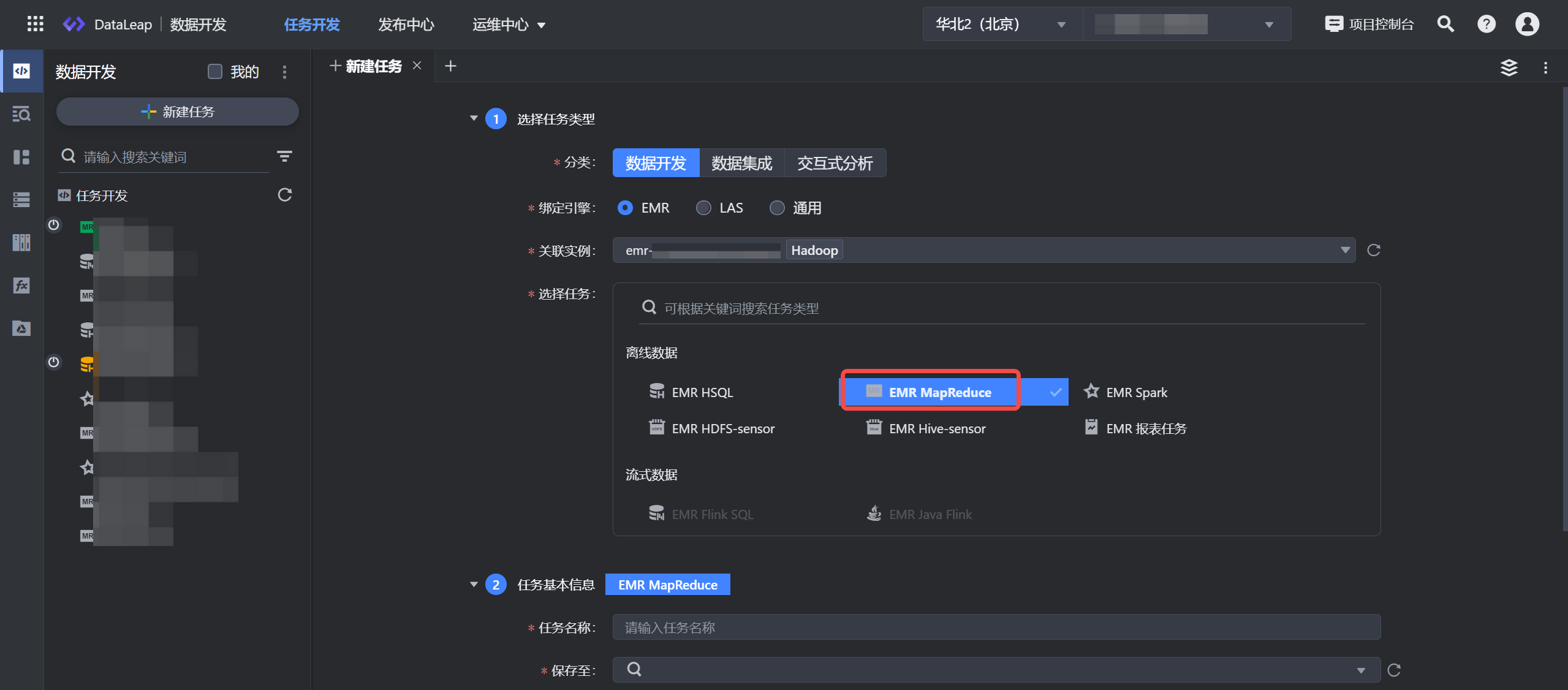
2 新建任务
- 登录 DataLeap租户控制台 。
- 在概览界面,显示加入的项目中,点击数据开发进入对应项目。
- 在任务开发界面,左侧导航栏中,点击新建任务按钮,进入新建任务页面。
- 选择任务类型:
- 分类:数据开发。
- 绑定引擎:EMR。
- 选择任务:离线数据 > EMR MapReduce 。
- 填写任务基本信息:
- 任务名称:输入任务的名称,只允许字符.、字母、数字、下划线、连字符、[]、【】、()、()以及中文字符,且在127个字符以内。
- 保存至: 选择任务存放的目标文件夹目录。
- 点击确定按钮,成功创建任务。
3 配置任务
任务创建成功后,进入到 MapReduce 任务配置界面,在配置界面中完成以下参数配置。
3.1 引入资源
资源类型支持 Jar 资源包的形式,可以按以下方式选择资源:
- 下拉从资源库选取已有的 EMR Jar 资源.
- 单击新建资源按钮,新创建资源。详见资源库。
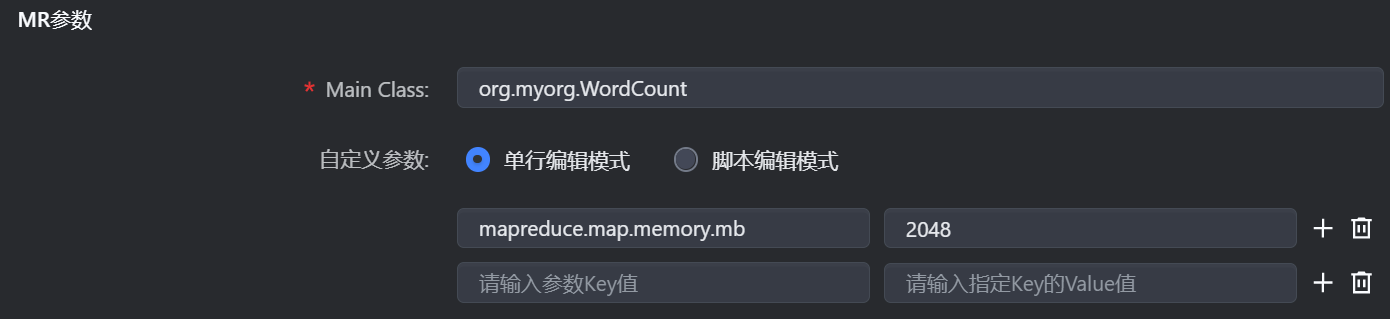
3.2 MR 参数配置
参数 | 说明 |
|---|---|
Main Class | 填写 Jar 包主类信息,如 org.myorg.WordCount |
自定义参数 | 根据实际情况,配置任务中可设置的一些 MapReduce 参数,例如您可通过
您可通过以下两种方式来进行配置:
|
Params | 输入任务中定义的参数,多个参数以空格形式进行分隔,例如您可输入 MapReduce 任务的 input 和 output 相关文件的路径地址。 |
3.3 任务产出登记
任务产出数据登记,用于记录任务---数据血缘信息,并不会对代码逻辑造成影响。对于系统无法通过解析获取产出信息的任务,可手动登记其产出信息。 如果任务含有 Hive 表或者 HDFS 目录的写入操作,强烈建议填写。您填写的内容即为任务产出,支持填写多个。其他任务的依赖推荐会根据此处填写的 Hive 表或者 HDFS 目录进行推荐。 具体登记内容包括:
- HDFS:该任务逻辑会将数据写入到 HDFS 目录,请填写 HDFS 路径名,路径名可以使用变量,例如 ${date}、${hour} 等。
- Hive:该任务逻辑会将数据写入到 Hive 表,请填写 Hive 库、表名、分区名,分区内容可以使用变量。
- 其他:该任务逻辑不写数据到 Hive 表或 HDFS 目录。
4 使用案例
4.1 文本内容及 Jar 资源包准备
通过 ssh 方式,登录到 EMR 集群中,详见登录集群。
在 EMR 集群环境中,执行
sudo vim wordcount.txt命令,创建 wordcount.txt,并插入文本,文本内容如下:He is Bob hello world hello MySQL MySQL python python python java java java java java将 wordcount.txt 上传至 HDFS 的 /tmp 目录下:
hdfs dfs -put wordcount.txt /tmp将如下 Jar 包资源下载到本地


4.2 上传资源
登录 DataLeap租户控制台 。
进入数据开发 > 资源库,进行 EMR 资源创建:
参数
说明
关联信息
引擎绑定
支持选择 EMR 引擎。
关联实例
默认关联项目绑定时的 EMR 实例。
保存至
资源上传后的文件路径。
基本信息
资源名称
输入资源名称,示例 emr_mr_wordcount,只允许数字、字母、下划线、-和.组成。
说明
相同引擎类型下,不能和已创建成功的资源名称重复。
资源类型
资源支持 Jar、File、Zip 类型,本次示例选择 Jar 资源类型。
资源来源
默认选择本地文件的来源方式
资源文件
将上方的资源包下载到本地后,单击点击上传按钮,完成 Jar 包资源上传。
单击确定按钮,完成资源创建。新增资源更多操作详见资源库。
4.3 创建任务配置
- 新建任务:
在左侧导航栏中,切换至数据开发页签,进行 EMR MapReduce 任务创建。详见 2 新建任务。 - 配置任务:
资源类型:选择上方创建的 emr_mr_wordcount 资源文件。
Main Class:org.myorg.WordCount,填写 Jar 资源中的主类信息。
Params:输入文件所在路径,及输出结果路径,以空格分隔:
/tmp/wordcount.txt /tmp/mr/out_'${date}'说明
- Params 参数,可根据实际的 Jar 资源包逻辑进行填写,若资源包中已指定源文件的路径及输出路径,可将 Params 置空。
- 路径支持自定义变量参数的方式填写,例如 '${date}' 时间变量,更多时间变量详见平台时间变量。
- 数据类型:
该示例会将产出的数据,写入到 HDFS 路径上,因此可在此手动登记任务产出:- 数据类型选择 HDFS。
- 填写 HDFS 路径地址:/tmp/mr/out_'${date}',后续任务可通过该路径进行依赖搜索。
4.4 数据验证
任务配置完成后,单击上方操作栏中的保存和调试按钮,进行 MapReduce 任务的调试。
注意
- 调试操作,直接使用线上数据进行调试,需谨慎操作。
- 本任务类型支持调试执行成功或失败后发送消息通知,您可根据业务情况,前往项目控制台 > 配置信息 > 消息通知设置中,选择是否开启任务调试运行成功或失败通知。
- 默认通知方式为邮箱,您需在“账号管理”中,提前绑定相应的安全邮箱信息;
- 您也可根据业务需要,自行配置飞书应用机器人,通过飞书的方式发送消息通知,飞书消息通知前置操作详见1.1 飞书应用机器人创建。
待任务运行完成后,进入 EMR 集群环境中,执行以下命令,进行查看任务运行结果:
##其中下方的 out_20230303 可按照具体执行的业务日期进行替换 hdfs dfs -cat /tmp/mr/out_20230303/part-00000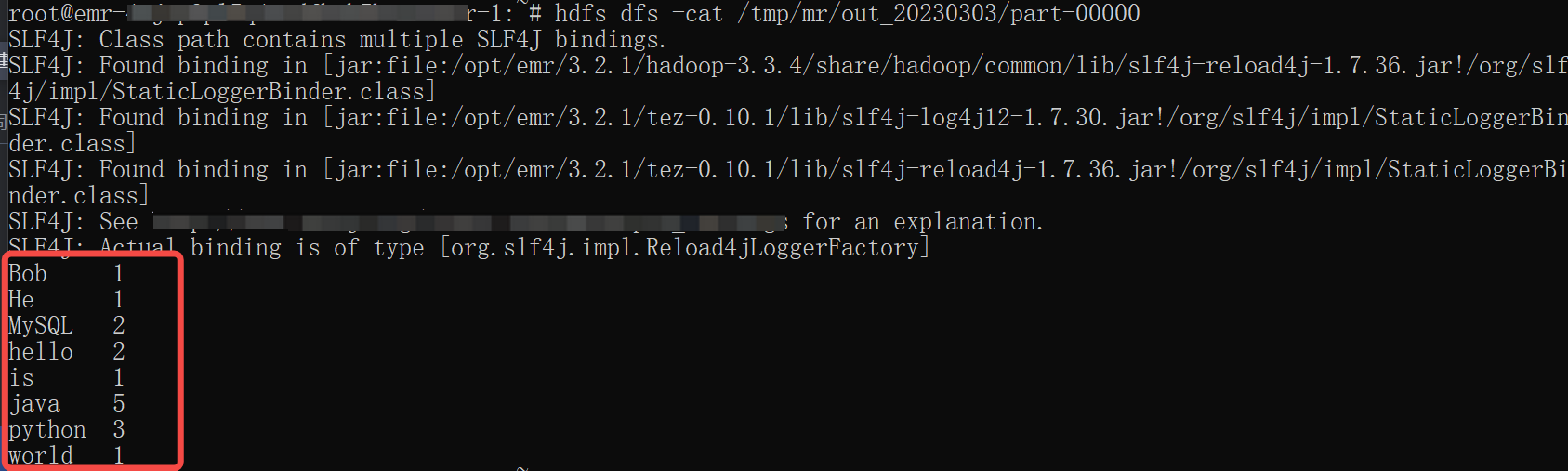
5 提交任务
数据验证确认无误后,您可进行后续的调度设置和将任务提交发布到运维中心离线任务运维中执行。
- 调度设置:
在右侧导航栏中,进入调度设置界面,您可以在此设置调度资源组、调度属性、依赖关系等信息,详细参数设置详见调度设置。 - 提交发布:
单击上方操作栏中的保存和提交上线按钮,在提交上线对话框中,选择回溯数据、监控设置、提交设置等参数,最后单击确认按钮,完成作业提交。 提交上线说明详见:数据开发概述---离线任务提交。
后续任务运维操作详见:离线任务运维。