SQLServer 数据源为您提供读取和写入 SQLServer 的双向通道能力。
本文为您介绍 DataSail 的 SQLServer 数据源配置、同步任务可视化和脚本模式(DSL)配置能力,实现与不同数据源的数据互通能力。
1 支持的 SQLServer 版本
SQL Server 离线读写使用驱动版本是 com.microsoft.sqlserver mssql-jdbc 7.2.2.jre8,驱动能力请参见官网文档。该驱动支持的SQL Server版本如下所示:
版本 | 支持性(是/否) |
|---|---|
SQL Server 2017 | 是 |
SQL Server 2016 | 是 |
SQL Server 2014 | 是 |
SQL Server 2012 | 是 |
PDW 2008R2 AU34 | 是 |
SQL Server 2008 R2 | 是 |
SQL Server 2008 | 否 |
SQL Server 2019 | 否 |
SQL Server 2022 | 否 |
Azure SQL Managed Instance | 否 |
Azure Synapse Analytics | 否 |
Azure SQL Database | 是 |
2 使用前提
- 子账号新建数据源时,需要有项目的管理员角色,方可以进行新建数据源操作。各角色对应权限说明,详见:管理成员
- 确保集成同步任务使用的独享数据集成资源组,具有 SQLServer 数据库节点的网络访问能力。网络互通方案详见网络连通解决方案。
- 数据源为 RDS 云数据库实例时,需要将集成资源组所在 VPC 中的 IPv4 CIDR 地址添加到 SQLServer 访问白名单中:
- 确认集成资源组所在的 VPC:
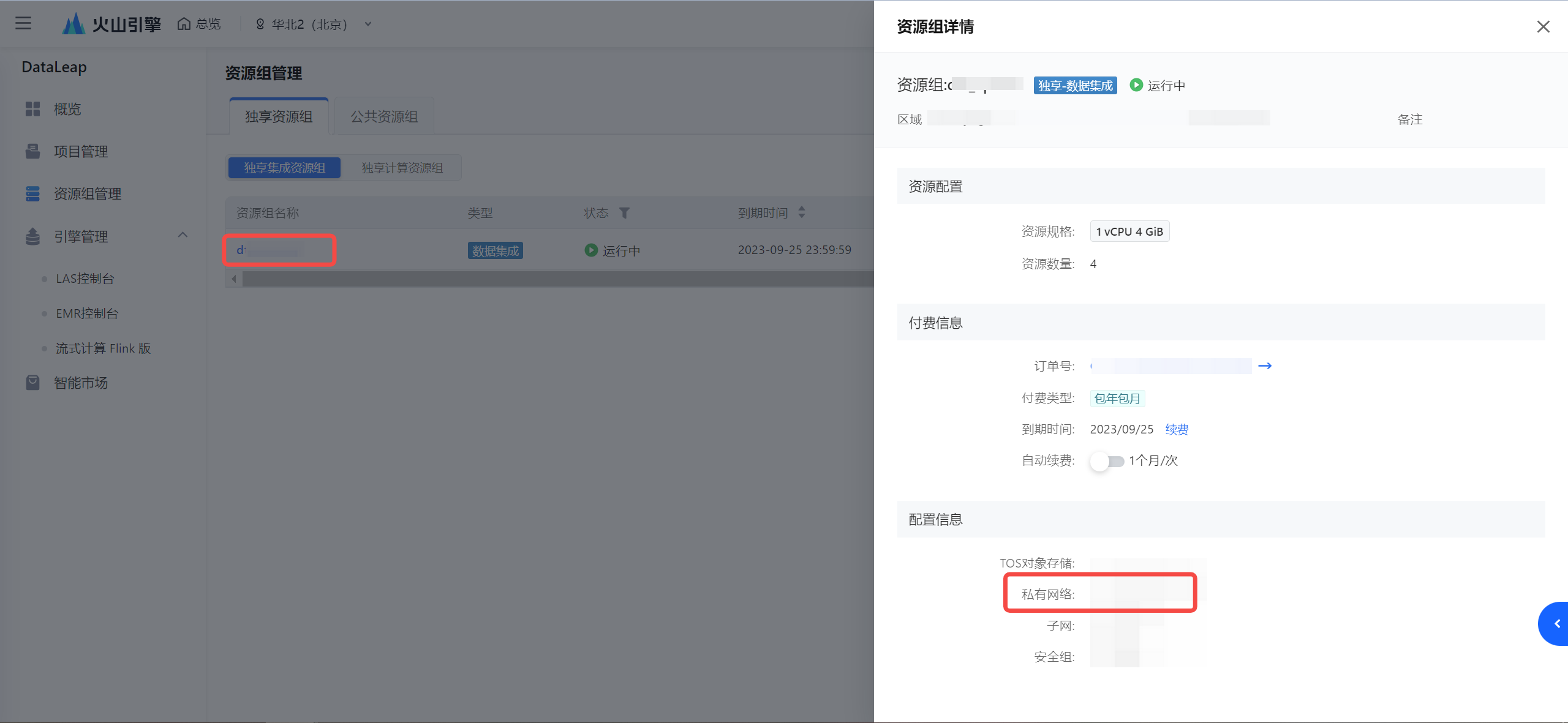
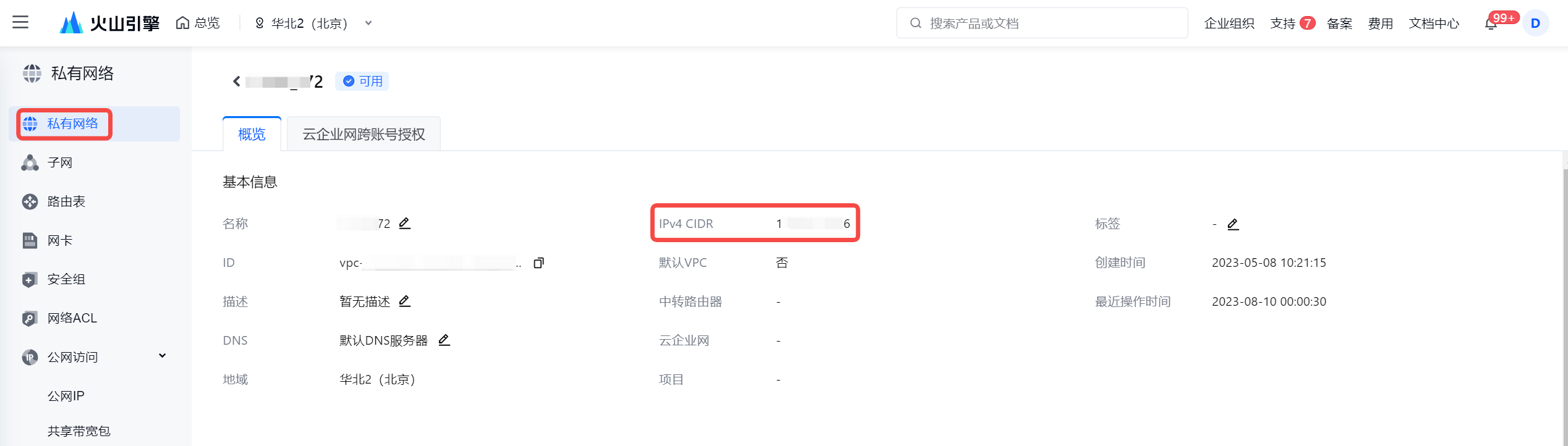
- 查看 VPC 的 IPv4 CIDR 地址:
注意
若考虑安全因素,减少 IP CIDR 的访问范围,您至少需要将集成资源组绑定的子网下的 IPv4 CIDR 地址加入到数据库白名单中。
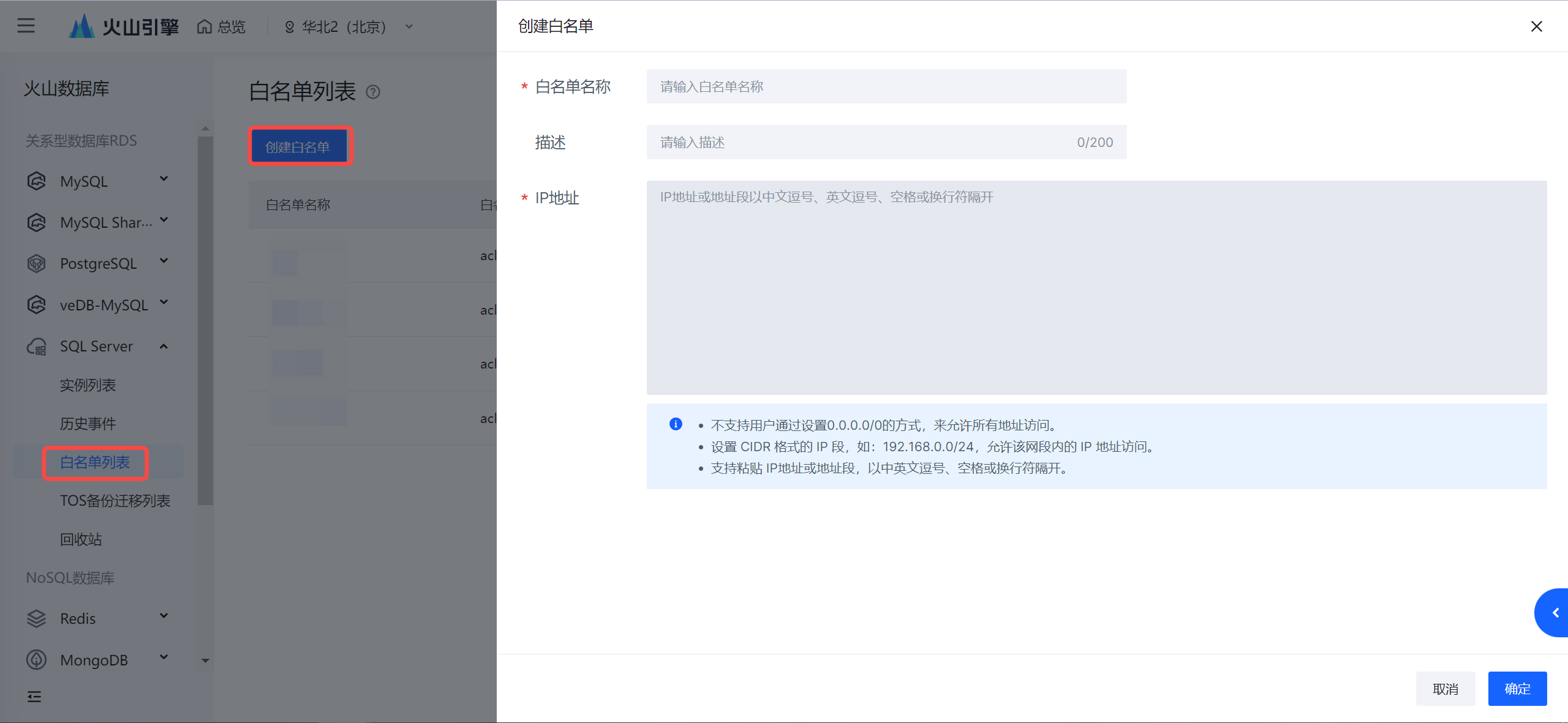
- 将获取到的 IPv4 CIDR 地址添加进 SQLServer 数据库白名单中,添加操作详见创建白名单。
- 确认集成资源组所在的 VPC:
- 数据源为公网自建数据源,需通过公网形式访问:
- 集成资源组开通公网访问能力,操作详见开通公网。
- 并将公网 IP 地址,添加进 SQLServer 数据库白名单中。
- 数据源为 RDS 云数据库实例时,需要将集成资源组所在 VPC 中的 IPv4 CIDR 地址添加到 SQLServer 访问白名单中:
3 支持的字段类型
SQL Server 全量的字段类型详见 SQL Server帮助文档。
以 SQL Server 2016 为例,列举常见的字段类型支持情况。
sql server 2016字段类型
SQL Server Reader
SQL Server Writer
bigint
支持
支持
bit
支持
支持
decimal
支持
支持
int
支持
支持
money
支持
支持
numeric
支持
支持
smallint
支持
支持
smallmoney
支持
支持
tinyint
支持
支持
float
支持
支持
real
支持
支持
date
支持
支持
datetime2
支持
支持
datetime
支持
支持
datetimeoffset
不支持
不支持
smalldatetime
支持
支持
time
支持
支持
char
支持
支持
text
支持
支持
varchar
支持
支持
nchar
支持
支持
ntext
支持
支持
nvarchar
支持
支持
binary
支持
支持
image
支持
支持
varbinary
支持
支持
cursor
不支持
不支持
hierarchyid
不支持
不支持
sql_variant
支持
支持
Spatial Geometry Types
不支持
不支持
table
不支持
不支持
rowversion
不支持
不支持
uniqueidentifier
支持
支持
xml
支持
支持
SQL Server Reader 和 SQL Server Writer 针对 SQL Server 的类型转换列表,如下所示。
类型分类
SQL Server 数据类型
整数类
BIGINT、INT、SMALLINT、TINYINT
浮点类
FLOAT、DECIMAL、REAL、NUMERIC、MONEY
字符串类
CHAR、NCHAR、NTEXT、NVARCHAR、TEXT、VARCHAR、XML、UNIQUEIDENTIFIER
日期时间类
DATE、DATETIME和TIME
布尔型
BIT
二进制类
BINARY、VARBINARY、VARBINARY、TIMESTAMP、IMAGE、SQL_VARIANT
4 数据同步任务开发
4.1 数据源注册
新建数据源操作详见配置数据源,下面为您介绍用连接串方式配置 SQLServer 数据源信息:
注意
SQLServer 侧如果是白名单访问机制,则不同网络环境的连接串地址,需要添加不同的 IP 地址到数据库白名单中,确保集成资源组使用的 VPC 与 SQLServer 网络能互通:
- 如果使用的是公网连接串访问,则需要给集成资源组添加公网 IP,并将公网 IP 地址加入到白名单中。
- 如果使用的是私网连接串访问,则需要将资源组 VPC 下的 IPv4 CIDR 地址加入到白名单中。
详见网络连通解决方案。
参数 | 说明 |
|---|---|
基本配置 | |
数据源类型 | SQLServer |
接入方式 | 连接串 |
数据源名称 | 数据源的名称,可自行设置,仅支持中文,英文,数字,“_”,100个字符以内。 |
参数配置 | |
主机名或IP地址 | SQLServer 数据库的主机名称或者 IP 地址。 |
端口 | 主机的端口号。 |
数据库名 | 输入已创建的 SQLServer 数据库名称。 |
用户名 | 有权限访问数据库的用户名信息。 |
密码 | 输入用户名对应的密码信息。 |
4.2 新建任务
SQLServer 数据源测试连通性成功后,进入到数据开发界面,开始新建 SQLServer 相关通道任务。
新建任务方式详见离线数据同步、流式数据同步。
4.3 可视化配置说明
任务创建成功后,您可根据实际场景,配置 SQLServer 批式读、SQLServer 批式写或 SQLServer 流式写等通道任务。
4.3.1 SQLServer 批式读
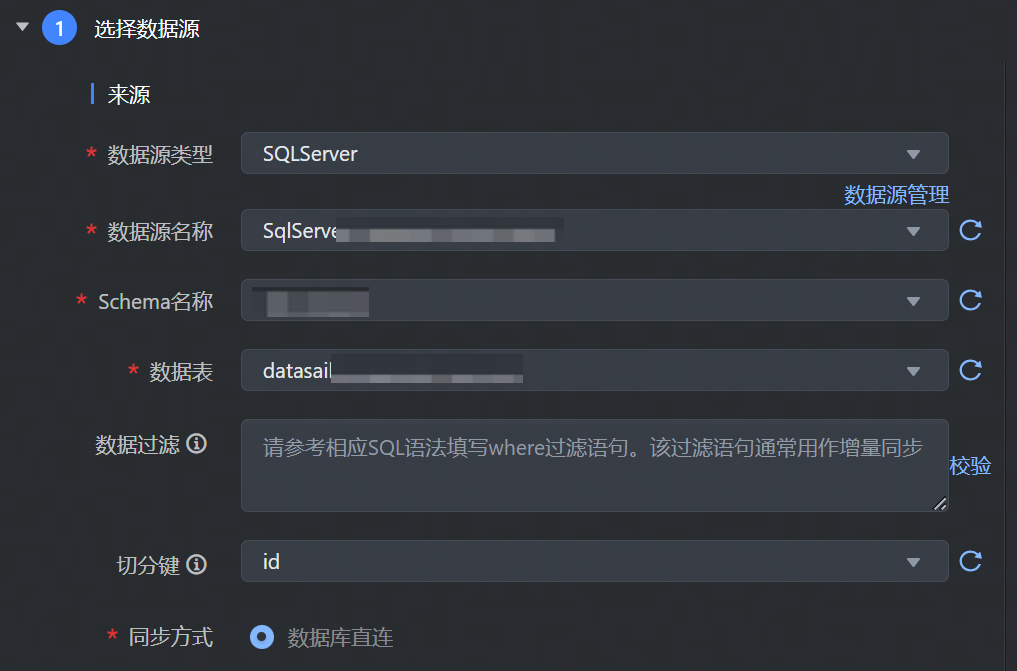
数据来源选择 SQLServer,并完成以下相关参数配置:
其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。
参数 | 说明 |
|---|---|
*数据源类型 | 下拉选择 SQLServer 数据源类型。 |
*数据源名称 | 已在数据源管理中注册成功的 SQLServer 数据源,下拉可选。 |
*Schema 目录 | 数据库下已有的 Schema 目录信息,下拉可选。 |
*数据表 | 选择需要采集的数据表名称信息,目前单个任务只支持将单表的数据采集到一个目标表中。 |
数据过滤 | 支持您将需要同步的数据进行筛选条件设置,只同步符合过滤条件的数据,可直接填写关键词 where 后的过滤 SQL 语句,例如:create_time > '${date}',表示只同步 create_time 大于等于 ${date} 的数据,不需要填写 where 关键字。 说明 该过滤语句通常用作增量同步,暂时不支持 limit 关键字过滤,其 SQL 语法需要和选择的数据源类型对应。 |
切分建 | 根据配置的字段进行数据分片,建议使用主键或有索引的列作为切分键:
说明 目前仅支持类型为整型或字符串的字段作为切分建。 |
4.3.2 SQLServer 批式写
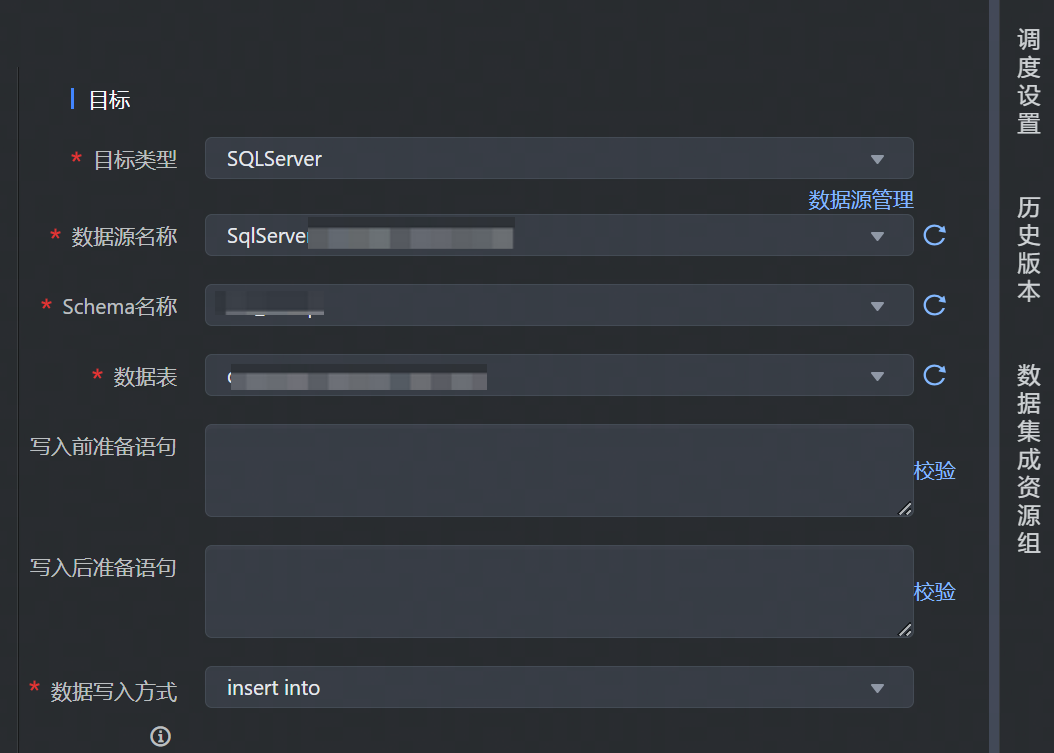
数据目标端选择 SQLServer,并完成以下相关参数配置:
其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。
参数 | 说明 |
|---|---|
*目标类型 | 数据去向目标类型选择 SQLServer。 |
*数据源名称 | 已在数据源管理界面注册的 SQLServer 数据源,下拉可选。 |
*Schema 目录 | 数据库下已有的 Schema 目录信息,下拉可选。 |
*数据表 | 数据源下所属需数据写入的表名,下拉可选。 |
写入前准备语句 | 在执行该数据集成任务前,需要率先执行的 SQL 语句,通常是为了使任务重跑时支持幂等。 说明 可视化通道任务配置中只允许执行一条写入前准备语句。 |
写入后准备语句 | 执行数据同步任务之后执行的 SQL 语句。例如写入完成后插入某条特殊的数据,标志导入任务执行结束。 说明 可视化通道任务配置中只允许执行一条写入后准备语句。 |
*数据写入方式 | 下拉选择数据写入 SQLServer 的方式:
说明 如果希望主键/唯一索引冲突时任务正常执行可以添加高级参数: |
4.3.3 SQLServer 流式写
支持可视化方式配置流式写入 SQLServer 单表。SQLServer Writer 通过 JDBC 远程连接 SQLServer 数据库,并执行相应的 SQL 语句,将数据写入 SQLServer。流式写入 SQLServer 配置方式如下:
数据目标端选择 SQLServer,并完成以下相关参数配置:
其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。
参数 | 说明 |
|---|---|
*目标类型 | 数据去向目标类型选择 SQLServer。 |
*数据源名称 | 已在数据源管理界面注册的 SQLServer 数据源,下拉可选。 |
*Schema 目录 | 数据库下已有的 Schema 目录信息,下拉可选。 |
*数据表 | 数据源下所属需数据写入的表名,下拉可选。 |
4.3.4 字段映射
数据来源和目标端配置完成后,需要指定来源和目标端的字段映射关系,根据字段映射关系,数据集成任务将源端字段中的数据,写入到目标端对应字段中。
您可通过以下三种方式操作字段映射关系:
- 自动添加:单击自动添加按钮,根据两端数据表信息,可以自动填充来源和目标的字段信息。
- 手动添加:单击手动添加按钮,可以手动编辑来源和目标的字段信息,可以逐个添加。
说明
来源端字段信息支持输入数据库函数和常量配置,单击手动添加按钮,在源表字段中输入需添加的值,并选择函数或常量类型,例如:
- 函数:支持您输入 getdate()、current_timestamp() 等 SQLServer 数据库支持的函数。
- 常量:您可自定义输入常量值,'123'、'${DATE}'、'${hour}' 等,输入值两侧需要加上英文单引号,支持结合时间变量参数使用。
- 移动\删除字段:您也可以根据需要移动字段映射顺序或删除字段。
4.4 DSL 配置说明
SQLServer 数据源支持使用脚本模式(DSL)的方式进行配置。
在某些复杂场景下,或当数据源类型暂不支持可视化配置时,您可通过任务脚本的方式,按照统一的 Json 格式,编写 SQLServer Reader 和 SQLServer Writer 参数脚本代码,来运行数据集成任务。
4.4.1 进入 DSL 模式
进入 DSL 模式操作流程,可详见 MySQL 数据源-4.4.1 进入DSL 模式。
4.4.2 SQLServer 批式读
进入 DSL 模式编辑界面后,您可根据实际情况替换相应参数,SQLServer 批式读脚本示例如下:
// 变量使用规则如下:
// 1.自定义参数变量: {{}}, 比如{{number}}
// 2.系统时间变量${}, 比如 ${date}、${hour}
// **************************************
{
// [required] dsl version, suggest to use latest version
"version": "0.2",
// [required] execution mode, supoort streaming / batch now
"type": "batch",
// reader config
"reader": {
// [required] datasource type
"type": "sql_server",
// [optional] datasource id, set it if you have registered datasource
"datasource_id": 12345,
// [required] user parameter
"parameter": {
// ********** please write here **********
// "key" : value
"columns": [
{
"name": "name_sample",
"type": "type_sample"
}
],
"filter": "id > 10",
"split_pk": "split_pk_sample",
"table_schema":"table_schema",
"table_name": "table_name_sample"
}
},
// writer config
"writer": {
},
// common config
"common": {
// [required] user parameter
"parameter": {
// ********** please write here **********
// "key" : value
}
}
}
Reader 参数说明,其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数:
参数名 | 描述 | 默认值 |
|---|---|---|
*type | 数据源类型,对于 SQLServer 类型,填写:sql_server | 无 |
*datasource_id | 注册的 SQLServer 数据源 ID。可以在项目控制台 > 数据源管理界面中查找。 | 无 |
*table_schema | 填写 SQLServer 数据库中的 Schema 名称。 | 无 |
*table_name | 需要同步的数据表名称,目前单个任务只支持将单表的数据采集到一个目标表中。 | 无 |
filter | 同步数据的筛选条件,同步数据时只会同步符合过滤条件的数据,直接填写关键词 where 后的过滤 SQL 语句。
| 无 |
split_pk | 根据配置的字段进行数据分片,建议使用主键或有索引的列作为切分键,同步任务会启动并发任务进行数据同步,提高同步速率:
说明 目前仅支持类型为整型或字符串的字段作为切分建。 | 无 |
*columns | 所配置的表中,需要同步的列名集合,使用 JSON 的数组描述字段信息。
| 无 |
4.4.3 SQLServer 批式写
根据实际情况替换 SQLServer 批式写相应参数,SQLServer 批式写脚本示例如下:
// **************************************
// 变量使用规则如下:
// 1.自定义参数变量: {{}}, 比如{{number}}
// 2.系统时间变量${}, 比如 ${date}、${hour}
// **************************************
{
// [required] dsl version, suggest to use latest version
"version": "0.2",
// [required] execution mode, supoort streaming / batch now
"type": "batch",
// reader config
"reader": {
// [required] datasource type
"type": "xx",
// [optional] datasource id, set it if you have registered datasource
"datasource_id": null,
// [required] user parameter
"parameter": {
// ********** please write here **********
// "key" : value
}
},
// writer config
"writer": {
// [required] datasource type
"type": "sql_server",
// [optional] datasource id, set it if you have registered datasource
"datasource_id": 12345,
// [required] user parameter
"parameter": {
// ********** please write here **********
// "key" : value
"table_schema":"table_schema",
"table_name":"table_1",
"pre_sql_list":[""],
"post_sql_list":[""],
"write_mode":"directlyInsert",
"columns": [
{
"name": "name_sample",
"type": "type_sample"
}
]
}
},
// common config
"common": {
// [required] user parameter
"parameter": {
// ********** please write here **********
// "key" : value
}
}
}
Writer 参数说明,其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数:
参数名 | 描述 | 默认值 |
|---|---|---|
*type | 数据源类型,对于 SQLServer 类型,填写:sql_server | 无 |
*datasource_id | 注册的 SQLServer 数据源 ID。可以在项目控制台 > 数据源管理界面中查找。 | 无 |
*table_schema | 填写 SQLServer 数据库中的 Schema 名称。 | |
*table_name | 填写需要同步的数据表名称,一个数据集成任务只能同步数据到一张目标表。 | 无 |
pre_sql_list | 写入前准备语句:在执行数据集成任务前,率先执行的 SQL 语句。此语句通常是为了使任务重跑时支持幂等。 说明 DSL 模式支持配置多条写入前准备语句,多条语句之间用英文逗号分隔。 | 无 |
post_sql_list | 写入后准备语句:执行数据同步任务后执行的 SQL 语句。例如数据写入完成后,插入某条特殊的数据,标志导入任务执行结束。 说明 DSL 模式支持配置多条写入后准备语句,多条语句之间用英文逗号分隔。 | 无 |
*write_mode | 数据导入模式,支持 insert into 模式:
| 无 |
*columns | 所配置的表中需要同步的列名集合,使用 JSON 的数组描述字段信息。
| 无 |
4.5 高级参数说明
- 对于可视化通道任务,读参数需要加上
job.reader.前缀,写参数需要加上job.writer.前缀,如下图所示: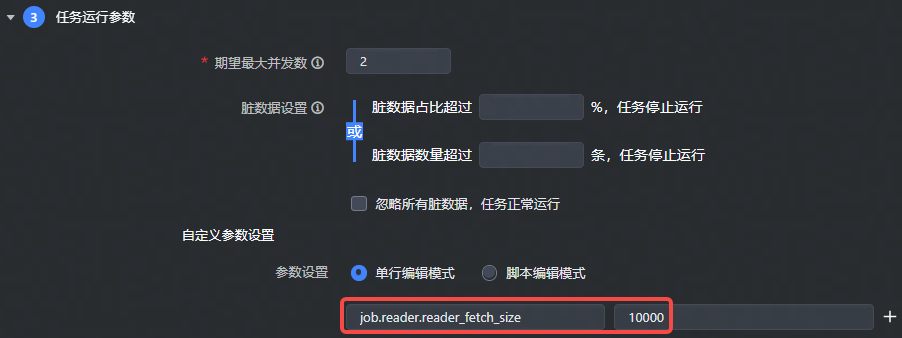
- 对于 DSL 任务,读参数请配置到
reader.parameter下,写参数请配置到writer.parameter下,直接输入参数名称和参数值。如下图所示: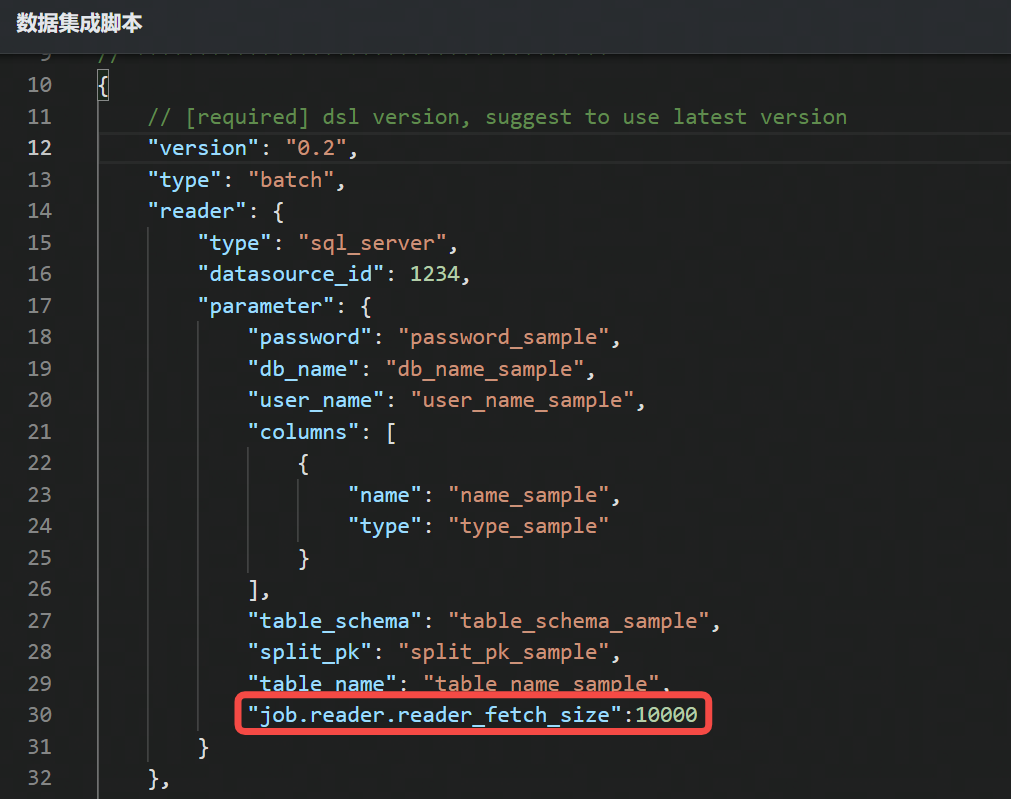
4.5.1 SQLServer 批式读
参数名 | 描述 | 默认值 |
|---|---|---|
init_sql | 读取数据前执行的 SQL 语句。对于视图的查询可能需要使用 init SQL 语句初始化环境 | 无 |
reader_fetch_size | 每次拉取的数据条数,只在准确分片中有效。 | 10000 |
shard_split_mode | 分片模式,支持准确分片、并发分片、不分片三种模式:
| 准确分片 |
customized_sql | 自定义查询读取 SQL 语句。filter 过滤配置项不足以描述所筛选的条件,可通过该配置项来自定义执行较复杂的查询 SQL。 说明 配置该高级参数项后,数据同步任务仍需配置 table_name、column 、split_pk 、shard_split_mode 等必填配置项。然而,在执行同步时,系统将忽略这些配置项信息,直接使用该高级参数项中配置的内容进行数据查询和筛选。 | 无 |
4.5.2 SQLServer 批式写
参数名 | 描述 | 默认值 |
|---|---|---|
is_insert_ignore | insert into 模式时,主键或者唯一键冲突时任务失败还是忽略冲突 | false |
write_batch_interval | 一次性批量提交的数据条数,该值可以减少与 SQLServer 网络的交互次数并提升整体吞吐量。如果该值设置过大可能会导致数据同步进程 OOM。 | 100 |
write_retry_times | SQLServer 写入失败时重试次数。 | 3 |
retry_interval_seconds | 写入失败后两次重试的时间间隔,单位秒 | write_batch_interval / 10 |