Elasticsearch 是一个基于 Lucene 的实时分布式的搜索与分析引擎,是当前主流的企业级搜索引擎。Elasticsearch可以快速地、近乎于准实时地存储、查询和分析超大数据集,通常被用来作为构建复杂查询特性和需求强大应用的基础引擎或技术。
DataSail Elasticsearch 数据源,为您提供离线任务读取和写入 Elasticsearch 的双向通道能力。本文为您介绍 DataSail 中 Elasticsearch 的数据源配置、离线任务可视化和脚本模式(DSL)配置能力,实现与不同数据源的数据互通能力。
1 支持的 Elasticsearch 版本
支持 Elasticsearch(ES)标品的 6.X、7.X 和开源 Elasticsearch 8.X 版本。
2 使用限制
- 子账号新建数据源时,需要有项目的管理员角色,方可以进行新建数据源操作。各角色对应权限说明,详见:管理成员
- DataSail 目前仅支持离线读、离线写 ES 能力。
3 支持的字段类型
字段类型 | ES Reader | ES Writer |
|---|---|---|
binary | 支持 | 支持 |
boolean | 支持 | 支持 |
keyword | 支持 | 支持 |
long | 支持 | 支持 |
integer | 支持 | 支持 |
short | 支持 | 支持 |
byte | 支持 | 支持 |
double | 支持 | 支持 |
float | 支持 | 支持 |
half_float | 支持 | 支持 |
date | 支持 | 支持 |
ip | 支持 | 支持 |
text | 支持 | 支持 |
nested | 支持 | 支持 |
completion | 支持 | 不支持 |
ip_range | 支持 | 不支持 |
object | 支持 | 不支持 |
integer_range | 支持 | 不支持 |
float_range | 支持 | 不支持 |
long_range | 支持 | 不支持 |
double_range | 支持 | 不支持 |
date_range | 支持 | 不支持 |
token_count | 支持 | 不支持 |
geo_point | 支持 | 不支持 |
geo_shape | 支持 | 不支持 |
4 数据同步任务开发
4.1 数据源注册
新建数据源操作详见配置数据源,以下为您介绍不同接入方式的 ES 数据源配置相关信息:
火山-云搜索服务方式配置
参数
说明
基本配置
数据源类型
Elasticsearch
接入方式
火山引擎 ES
数据源名称
数据源的名称,可自行设置,仅支持中文,英文,数字,“_”,100个字符以内。
参数配置
实例 ID
已在火山引擎云搜索服务中创建的 ES 实例名称,下拉可选。
ES 实例创建方式详见创建 ESCloud 实例。安全认证
火山-云搜索服务接入方式,默认只支持使用用户名密码方式登录。
用户名
输入有权限访问 ES 实例中索引数据库的用户名信息。
密码
输入用户名对应的密码信息。
连接串方式配置
参数
说明
基本配置
数据源类型
Elasticsearch
接入方式
连接串
数据源名称
数据源的名称,可自行设置,仅支持中文,英文,数字,“_”,100个字符以内。
参数配置
连接协议
支持选择 HTTP 或 HTTPS 连接协议。
EndPoint
集群访问地址,以主机名:端口的形式填写,多个请用逗号分隔,如:localhost:2181,localhost:2181
安全认证
支持使用用户名密码或匿名方式登录,其中匿名方式无需填写下方的用户名和密码信息。
用户名
输入有权限访问 ES 实例中索引数据库的用户名信息。
密码
输入用户名对应的密码信息。
4.2 新建离线任务
ES 数据源测试连通性成功后,进入到数据开发界面,开始新建 ES 相关通道任务。
新建任务方式详见离线数据同步。
4.3 可视化配置说明
任务创建成功后,您可根据实际场景,配置 ES 批式读或 ES 批式写等通道任务。
4.3.1 ES 批式读
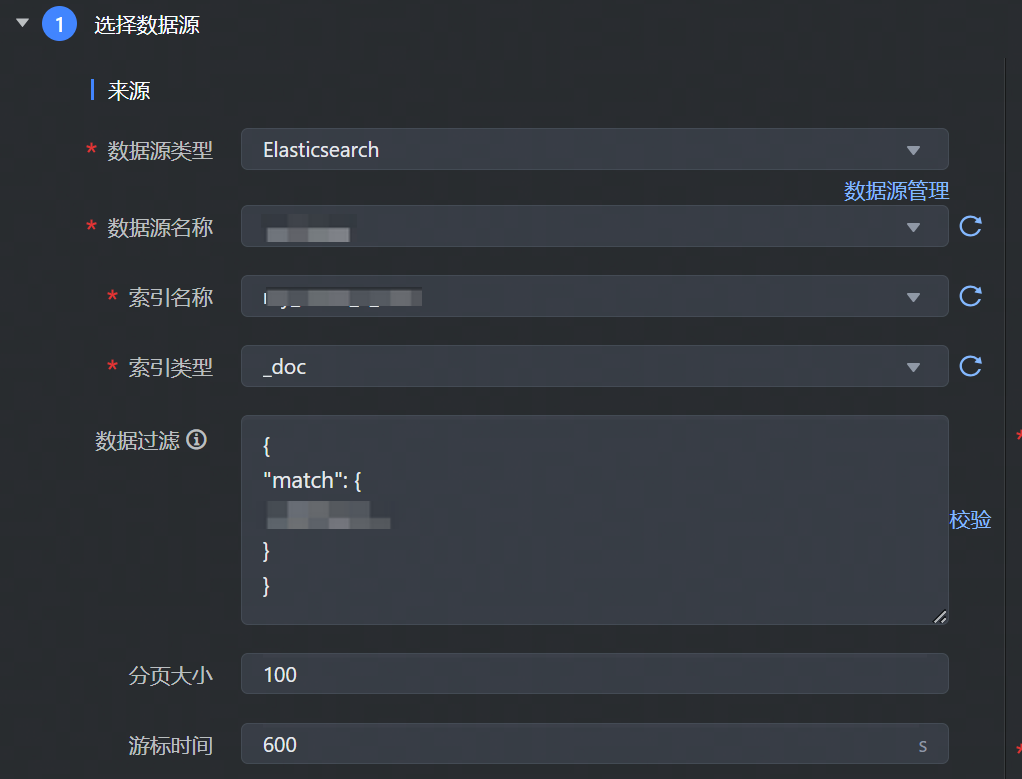
数据来源选择 Elasticsearch,并完成以下相关参数配置:
其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。
参数 | 说明 |
|---|---|
*数据源类型 | 下拉选择 Elasticsearch 数据源类型。 |
*数据源名称 | 已在数据源管理中注册成功的 ES 数据源,下拉可选。 |
*索引名称 | 下拉选择已创建成功的索引名称或索引别名信息。 说明 索引别名按照索引模版规则,可同步包含若干索引的数据。 |
*索引类型 | 下拉选择索引类型,不同 ES 版本,索引类型不同,ES 7.X 版本,索引类型默认为 _doc 。 |
数据过滤 | 支持您将需要同步的数据进行筛选条件设置,只同步符合过滤条件的数据,根据 ES 语法,筛选数据,如: 说明 该过滤语句通常用作增量同步,其语法需要和选择的数据源类型对应。 |
分页大小 | 决定了每次请求ES获取到的文档的数量。 |
游标时间 | 每次游标查询的过期时间,该时间内能获取单页数据即可。 |
4.3.2 ES 批式写
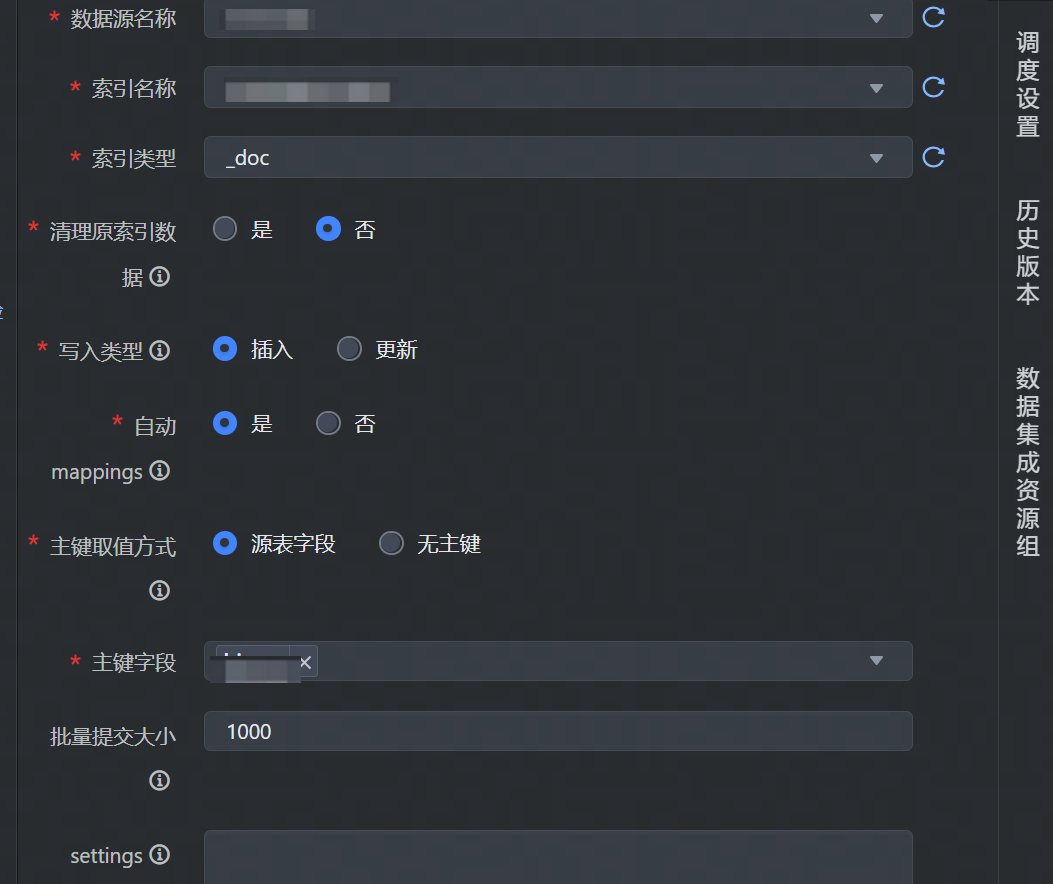
数据目标端选择 ES,并完成以下相关参数配置:
其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。
参数 | 说明 |
|---|---|
*数据源类型 | 下拉选择 Elasticsearch 数据源类型。 |
*数据源名称 | 已在数据源管理中注册成功的 ES 数据源,下拉可选。 |
*索引名称 | 下拉展现已创建成功的索引名称信息,选择需要写入数据的索引信息。 |
*索引类型 | 下拉选择 ES 中索引的类型,不同 ES 版本,索引类型不同,其中:
|
*清理原索引数据 | 选择写入时是否清理原索引中的数据:
|
*写入类型 | 选择数据写入方式:
|
*自动 mappings | 在文档中发现未存在的字段时,集成任务是否通过 Elasticsearch 动态映射机制为字段添加映射。 |
*主键取值方式 | 源表字段:document 的 id 使用源表的字段,支持多字段拼接。 |
*主键字段 | 主键取值方式为“源表字段”时,必须填写主键字段,您可通过下拉方式选择。 |
主键分隔符 | 有多个主键字段时,需填写将主键字段值拼接在一起的主键分隔符,默认分隔符是空字符串。 |
批量提交大小 | 一次性批量提交的 Document 条数 |
settings | 创建 index 时的 settings,与 Elasticsearch 官方一致,以 JSON 格式输入。 |
4.3.3 字段映射
数据来源和目标端配置完成后,需要指定来源和目标端的字段映射关系,根据字段映射关系,数据集成任务将源端字段中的数据,写入到目标端对应字段中。
说明
字段映射名称配置时,仅支持小写,如 Elasticsearch 中有大写字段名称,则需在字段映射源表字段处,将其修改为小写。
字段映射支持选择基础模式和转换模式配置映射:
注意
基础模式和转换模式不支持互相切换,模式切换后,将清空现有字段映射中所有配置信息,一旦切换无法撤销,需谨慎操作。
转换模式:
字段映射支持数据转换,您可根据实际业务需求进行配置,将源端采集的数据,事先通过数据转换后,以指定格式输入到目标端数据库中。
转换模式详细操作说明详见4.1 转换模式
在转换模式中,你可依次配置:来源节点、数据转换、目标节点信息:配置节点
说明
来源节点
配置数据来源 Source 节点信息:
- 节点名称:自定义输入来源节点名称信息,只允许由数字、字母、下划线、-和.组成;且长度不能超过10。
- 数据字段:通过自动添加、手动添加等方式添加数据来源字段信息。
配置完成后,单击确认按钮,完成来源节点配置。
数据转换
单击数据转换右侧添加按钮,选择 SQL 转换方式,配置转换信息和规则:
- 节点名称:自定义输入来源节点名称信息,只允许由数字、字母、下划线、-和.组成;且长度不能超过10。
- SQL 脚本:输入 SQL 脚本转换规则,目前仅支持添加一个转换的 SQL 语句,且不能包括 “;”。
配置完成后,单击确认按钮,完成数据转换节点配置。SQL 脚本示例详见4.1.2 添加转换节点。
目标节点
配置目标节点 Sink 信息:
- 节点名称:自定义输入来源节点名称信息,只允许由数字、字母、下划线、-和.组成;且长度不能超过10。
- 数据字段:通过自动添加、手动添加等方式添加数据目标字段信息。
配置完成后,单击确认按钮,完成目标节点配置。
基础模式:
您可通过以下三种方式操作字段映射关系:
- 自动添加:单击自动添加按钮,根据两端数据表信息,可以自动填充来源和目标的字段信息。
- 手动添加:单击手动添加按钮,可以手动编辑来源和目标的字段信息,可以逐个添加。
- 同名映射:目标表字段,可通过源端字段同名映射的方式,填充目标表字段信息。
- 移动\删除字段:您也可以根据需要移动字段映射顺序或删除字段。
4.3.4 期望最大并发数设置
Elasticsearch 设置期望最大并发数(MAX_PARALLELISM),读取 Elasticsearch 数据和写入 Elasticsearch 数据有以下区别:
- 读取 Elasticsearch 数据:
说明
读取 Elasticsearch 数据时,若在高级参数中,还同时设置了
job.reader.reader_parallelism_num参数,则以高级参数设置为准,但最终任务执行时的并发数量,最高不会超过 Elasticsearch 中索引 Shard 数目。- 当设置的 MAX_PARALLELISM 并发数值,小于 Elasticsearch 中索引 Shard 数目时,任务实际执行时的并发,便为设置的 MAX_PARALLELISM 并发数值。如:MAX_PARALLELISM 并发数为 3,索引 Shard 数目为 5 时,任务实际并发为 3 个并发;
- 当设置的 MAX_PARALLELISM 并发数值,大于 Elasticsearch 中索引 Shard 数目时,任务实际执行时的并发,便为索引 Shard 数。如:MAX_PARALLELISM 并发数为 8,索引 Shard 数目为 5 时,任务实际并发为 5 个并发;
- 当设置的 MAX_PARALLELISM 并发数值,小于 Elasticsearch 中索引 Shard 数目时,任务实际执行时的并发,便为设置的 MAX_PARALLELISM 并发数值。如:MAX_PARALLELISM 并发数为 3,索引 Shard 数目为 5 时,任务实际并发为 3 个并发;
- 写入 Elasticsearch 数据:
批式写入 Elasticsearch 数据时,默认最高写入并发为 5 个,即:- 当 MAX_PARALLELISM 并发数不超过 5 时,任务实际执行并发数为 MAX_PARALLELISM;
- 当 MAX_PARALLELISM 并发数超过 5 时,任务实际执行并发数为 5。
说明
批式写入 Elasticsearch 数据时,若在高级参数中,还同时设置了
job.reader.writer_parallelism_num参数,则以高级参数设置为准,但最终任务执行时的并发数量,写入最高并发上限为 5 个。
4.4 DSL 配置说明
ES 数据源支持使用 DSL 的方式进行配置。
在某些复杂场景下,或当数据源类型暂不支持可视化配置时,您可通过任务脚本的方式,按照统一的 Json 格式,编写 ES Reader 和 ES Writer 参数脚本代码,来运行数据集成任务。
4.4.1 进入 DSL 模式
进入 DSL 模式操作流程,可详见 MySQL 数据源-4.4.1 进入DSL 模式。
4.4.2 Elasticsearch Reader
进入 DSL 模式编辑界面后,您可根据实际情况替换相应参数,Elasticsearch Reader 脚本示例如下:
// ************************************** // 变量使用规则如下: // 1.自定义参数变量: {{}}, 比如{{number}} // 2.系统时间变量${}, 比如 ${date}、${hour} // ************************************** { // [required] dsl version, suggest to use latest version "version": "0.2", // [required] execution mode, supoort streaming / batch now "type": "batch", // reader config "reader": { "type": "es", "datasource_id": {datasource_id}, "parameter": { "columns": [ { "name": "name_sample", "type": "type_sample" } ], "es_index": "es_index_sample", "es_doc_type": "_doc", "query":"query_temp", "batch_size":100, "scroll_keep_alive":600 } }, "writer": { ··· }, "common": { ··· } }
Reader 参数说明,其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数:
参数名称 | 参数含义 |
|---|---|
*type | reader type, 默认固定值 es |
*datasource_id | 注册的 ES 数据源 ID。可以在项目控制台 > 数据源管理界面中查找。 |
*columns | 需要同步的字段名称。 |
*es_index | 需要读取数据的 ES 索引名称。 |
*es_doc_type | 不同 ES 版本,索引类型不同,ES 7.X 版本,索引类型默认为 _doc 。 |
query | 数据查询过滤语句,ES Query 语句的 JSON String 格式。 |
batch_size | 分页大小,指定每页返回的文档数量。默认2000。 |
scroll_keep_alive | 游标时间,设置游标的有效生命周期时间,单位秒。 默认200s。 |
4.4.3 Elasticsearch Writer
根据实际情况替换 Elasticsearch Writer 相应参数,脚本示例如下:
{ // [required] dsl version, suggest to use latest version "version": "0.2", // [required] execution mode, supoort streaming / batch now "type": "batch", // reader config "reader": { ... }, "writer": { "type": "es", "datasource_id": {datasource_id}, "parameter": { "bulk_max_actions":1000, "is_cleanup_index":false, "columns":[ { "upperCaseName":"ID", "name":"id", "type":"text" }, { "upperCaseName":"NAME", "name":"name", "type":"text" }, { "upperCaseName":"ADDRESS", "name":"address", "type":"text" } ], "is_dynamic_mapping":true, "es_doc_type":"_doc", "es_index":"es_test1_liuxu", "es_id_fields":"id", "es_upsert":false } }, "common": { ... } }
Writer 参数说明,其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数:
参数名称 | 参数含义 |
|---|---|
*type | writer type, 默认固定值 es |
*datasource_id | 注册的 ES 数据源 ID。可以在项目控制台 > 数据源管理界面中查找。 |
*columns | 需要同步的字段名称。 |
*es_index | 需要写入数据的 ES 索引名称。 |
*es_doc_type | 不同 ES 版本,索引类型不同,其中:
|
is_cleanup_index | 是否清理原索引数据。默认 false |
es_upsert | 数据写入类型,默认 false:
|
is_dynamic_mapping | 是否开启自动 mapping。在文档中发现未存在的字段时,集成任务是否通过 Elasticsearch 动态映射机制为字段添加映射。 |
bulk_max_actions | 批量提交大小。默认1000 |
es_id_fields | ES 主键对应字段,不设置则自动生成 id。 |
4.5 高级参数说明
- 对于可视化通道任务,读参数需要加上
job.reader.前缀,写参数需要加上job.writer.前缀,如下图所示: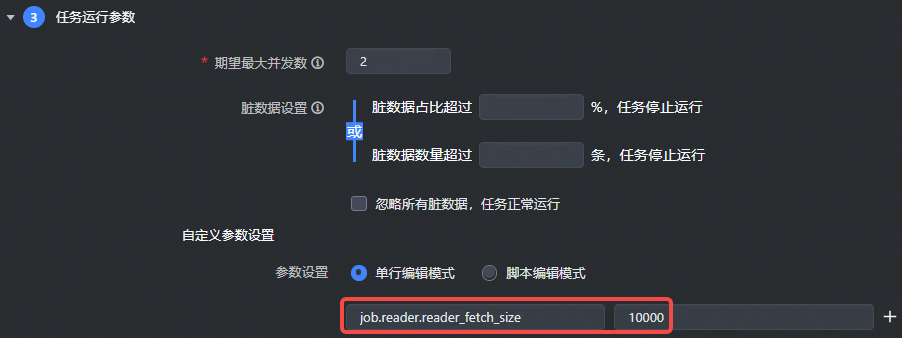
- 对于 DSL 任务,读参数请配置到
reader.parameter下,写参数请配置到writer.parameter下,直接输入参数名称和参数值。
4.5.1 Elasticsearch 批式读
参数名 | 描述 | 默认值 |
|---|---|---|
job.reader.case_insensitive | 读取数据时字段大小写是否需要敏感。 | true |