大数据研发治理套件
大数据研发治理套件






- 文档首页
 大数据研发治理套件用户指南控制台项目管理流水线管理选择器扩展程序使用说明
大数据研发治理套件用户指南控制台项目管理流水线管理选择器扩展程序使用说明

前言
选择器是由DataLeap开发的扩展程序,旨在应对复杂业务场景下多分支的编排诉求,实现不同规则下执行不同分支的功能。借助表达式引擎的能力,使用者可以很方便的在选择器中定义各类规则。
参数说明
| 参数 | 说明 | 备注 |
|---|---|---|
匹配顺序 | 选择器规则的执行顺序。
| 无 |
所有规则均不匹配时 | 当所有规则都没有命中时,选择器自身状态流转的设置。
| 无 |
规则设置 | 由布尔表达式构成,求值结果为true/false。
参数设置示例如下:
| 关于表达式编写以及结合流水线如何使用的相关说明,请参考下节。 |
跳过(skipped)状态
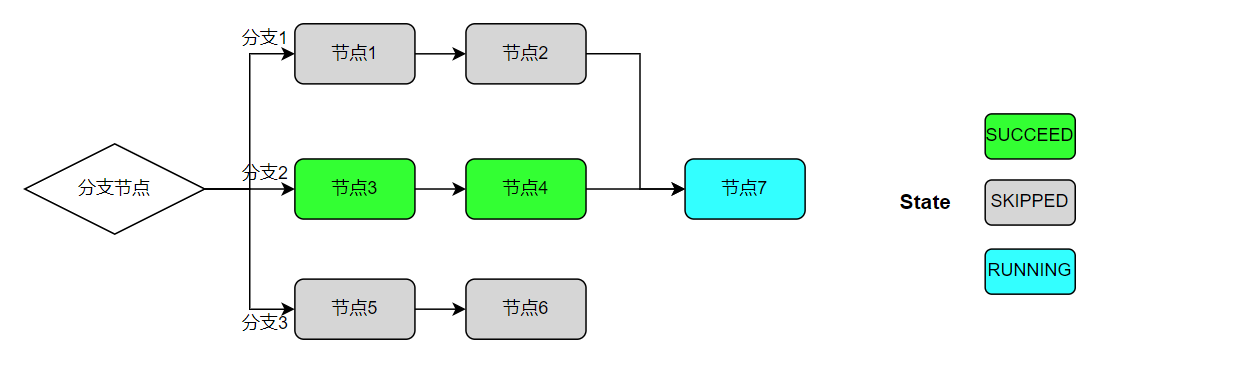
跳过状态表示当前节点跳过执行且不触发后续节点执行,状态为终态不允许置成功。以下图为例,假定分支设定的规则命中分支2并触发节点3执行,且分支1和分支3的节点状态会标记为skipped(节点1、节点5),对于已跳过分支的后续节点(节点2、节点6、节点7)的状态流转规则,会按照如下策略进行判定:
当所有前序节点的状态均为
skipped时,将当前节点同样置为skipped(如节点2,节点6)。当所有前序节点都进入终态,并且没有失败节点且至少有一个成功节点时,触发当前节点执行,状态为
running(节点7)。
分支规则
上节提到,分支规则是基于表达式引擎实现的。具体来说,是采用Spring Expression Language (SpEL)来提供表达式的相关能力,SpEL支持各类运算符: <,<=,==,>,>=,!=,&&,||,!等,并且还支持正则匹配matches,基本涵盖了分支判断所需要的运算符。更多细节可参考SpEL官方文档。
本节主要介绍如何利用流水线的输入数据来编写正确的表达式,下面从三部分进行说明。
基于流水线事件体(eventBody) 编写规则。
为了更方便的获取eventBody中的数据,选择器定义了
eventProperty函数,支持使用JSONPath从事件体中获取所需内容,示例如下://判断任务优先级是否为D1/D2任务 eventProperty('$.nodeInfo[0].priority') matches '(D1|D2)' //判断任务类型是否为hsql eventProperty('$.nodeInfo[0].type')=='hsql'基于流水线上下文(context)编写规则。
由于流水线在触发节点执行前,会自动对流水线上下文变量进行替换,因此使用起来会更加方便,示例如下:
//判断技术复查人是否包含xxx 'context:params:techReviewer' matches '.*xxx.*'基于前置节点输出(data) 编写规则。
与context类似,流水线也会对前置节点变量自动替换,示例如下:
//判断某个前置节点输出的实例id是否大于10w 格式:node:${nodeId}:params:$.data.instanceIds[0] > 100000 示例:node:dshcsfhfd:params:$.data.instanceIds[0] > 100000