HDFS 作为业界使用最广泛的开源分布式文件系统,具有高容量、高吞吐的特点,经常用于大规模数据应用。
HDFS 数据源为您提供可视化读和实时写入 HDFS 的数据集成通道能力,实现和不同数据源之间进行数据传输。
本文将为您介绍 DataSail 对 HDFS 数据同步能力的支持情况。
1 支持的版本
- 支持火山引擎 E-MapReduce(EMR)Hadoop 集群类型数据源。
- 其余连接串形式的 HDFS 数据源支持以下版本:
- Hadoop 2.7
- Hadoop 3.1
- Hadoop 3.2
2 使用限制
- 子账号新建数据源时,需要有项目的管理员角色,方可以进行新建数据源操作。各角色对应权限说明,详见:管理成员。
- HDFS 数据源配置选择 EMR HDFS 接入方式时,您需要填写 EMR 集群信息,因此您需提前创建好 EMR 集群且需包含 HDFS 组件。详见创建集群。
- 目前仅支持可视化离线读取和实时写入 HDFS 数据。
- 确保同步任务使用的独享集成资源组具有目标 HDFS 集群 DataNode 和 NameNode 的网络访问能力:
- EMR 集群使用的 VPC 需和独享集成资源组中的 VPC 保持一致,其 VPC 下的子网和安全组也尽可能保持一致。
- 若是连接串形式访问,您可通过公网或内网形式访问,不同网络环境处理方式详见网络连通解决方案。
- 离线读限制
- HDFS 读取作业以 root 账户读取文件,所以您需要确保 HDFS 集群内 root 账户具有目标 HDFS 文件的读权限。
- DataSail 支持读取以下格式的文件:
- Json:要求文件内每行为一个 Json 数据,其中 key 字段大小写敏感。
- Pb:Protobuf 格式,需要在作业配置界面填写 Pb 类定义和需要读取的类名。
- 目前底层使用的 Apache Hadoop SDK 版本为 3.2.1,在 Hadoop 2.7、Hadoop 3.1、Hadoop 3.2 环境中可正常使用。
- 实时写
- 目前实时写仅支持写入 EMR HDFS 数据源。
- HDFS 数据源对上游数据格式有要求,目前支持 Json 和 Pb。其中 Pb 格式需要在作业配置界面指定 Pb 类定义和目标类名。
- HDFS Writer 会先写入一个临时目录,在一定时间区间的数据全部到达后,再将临时文件移动到目标目录,因此文件在目标目录可见存在一定延迟。目前支持天级和小时级延迟的写入。
- HDFS Writer 以 flowagent 作为 Hadoop user 写入文件,需提前确认指定路径的读写权限。
- HDFS 实时 Writer 目前上游只能承接 BMQ、RocketMQ、Kafka 和 DataSail 这四种消息队列类型数据源。这四种数据源会将消息的原始负载直接发送到 HDFS Writer,然后由 HDFS Writer 直接以二进制形式写入 HDFS 文件,因此不需要配置 column 字段。
3 支持的字段类型
3.1 离线读
目前支持离线读取 Json 和 Pb 格式的文件,内部支持的数据类型如下:
类型分类 | 数据集成 column 配置类型 | Json 数据类型 | Pb 数据类型 |
|---|---|---|---|
整数类 | tinyint、int、bigint | 数字 | int32、int64、 |
浮点类 | float、double、decimal | float、double | |
字符串类 | string | 字符串 | string、enum |
时间类 | date、timestamp | 时间字符串、整数时间戳 | 时间字符串、整数时间戳 |
布尔类 | boolean | 布尔值 | bool |
数组类 | array | 数组 | repeated |
字典类 | map | 对象 | message |
二进制类型 | binary | bytes |
4 数据同步任务开发
4.1 数据源注册
新建数据源操作详见配置数据源,以下为您介绍不同接入方式的 HDFS 数据源配置相关信息:
EMR-HDFS 数据源
注意
EMR 集群所在的 VPC 需和独享集成资源组中的 VPC 保持一致,确保网络能互相访问。不同 VPC 情况时,详见“2 使用限制”相关说明。
其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。
参数
说明
基本配置
*数据源类型
HDFS
*接入方式
EMR HDFS
*数据源名称
数据源的名称,可自行设置,仅支持中文,英文,数字,“_”,100个字符以内。
参数配置
*EMR 集群 ID
下拉选择已创建成功的 EMR Hadoop 类型的集群名称,若还未创建相关集群,您可前往 EMR-控制台创建。详见创建集群。
连接串形式 HDFS 数据源
用连接串形式配置 HDFS 数据源,其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。参数
说明
基本配置
*数据源类型
HDFS
*接入方式
连接串
*数据源名称
数据源的名称,可自行设置,仅支持中文,英文,数字,“_”,100个字符以内。
参数配置
defaultFS
填写 Hadoop HDFS 文件的 namenode 节点地址,以 hdfs://ServerIP:Port 的形式填写。
扩展配置
输入必要的 HDFS 扩展配置属性,例如 Hadoop HA 的配置。默认情况无需额外配置,填写
<configuration></configuration>即可。
自建的高可用集群您可参考以下扩展属性配置示例:<configuration> <property> <name>dfs.nameservices</name> <value>test_name</value> </property> <property> <name>dfs.ha.namenodes.test_name</name> <value>namenode1,namenode2</value> </property> <property> <name>dfs.namenode.rpc-address.namenode1</name> <value>xxx.xx.x.xx:port</value> </property> <property> <name>dfs.namenode.rpc-address.namenode2</name> <value>xxx.xx.x.xx:port</value> </property> <property> <name>dfs.client.failover.proxy.provider.test_name</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> </configuration>说明
- 以上配置示例中,nameservices 和 rpc-address 信息,您需根据实际集群信息进行替换。推荐您可直接将集群中的 hdfs-site.xml 和 core-site.xml 文件信息,配置到该扩展配置中。
- 若是火山引擎 EMR Hive 高可用集群方式接入时,无需配置额外高可用相关的扩展属性。
*认证方式
目前暂不支持配置认证方式。
4.2 新建离线任务
HDFS 数据源测试连通性成功后,进入到数据开发界面,开始新建 HDFS 相关通道任务。新建任务方式详见离线数据同步、流式数据同步。
任务创建成功后,您可根据实际场景,配置 HDFS 离线读通道任务。
说明
目前暂不支持 HDFS 以脚本模式(DSL)配置通道任务。
4.3 可视化配置 HDFS 离线读
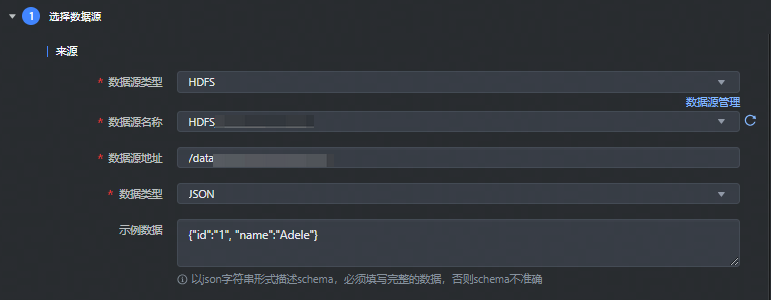
数据来源选择 HDFS,并完成以下相关参数配置:
其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。
参数 | 说明 |
|---|---|
*数据源类型 | 下拉选择 HDFS 数据源类型。 |
*数据源名称 | 已在数据源管理中注册成功的 HDFS 数据源,下拉可选。 |
*数据源地址 | 填写需要采集的数据文件所在路径:
|
*数据类型 | 支持选择 json、pb 等几种数据类型:
|
4.4 可视化配置 HDFS 实时写
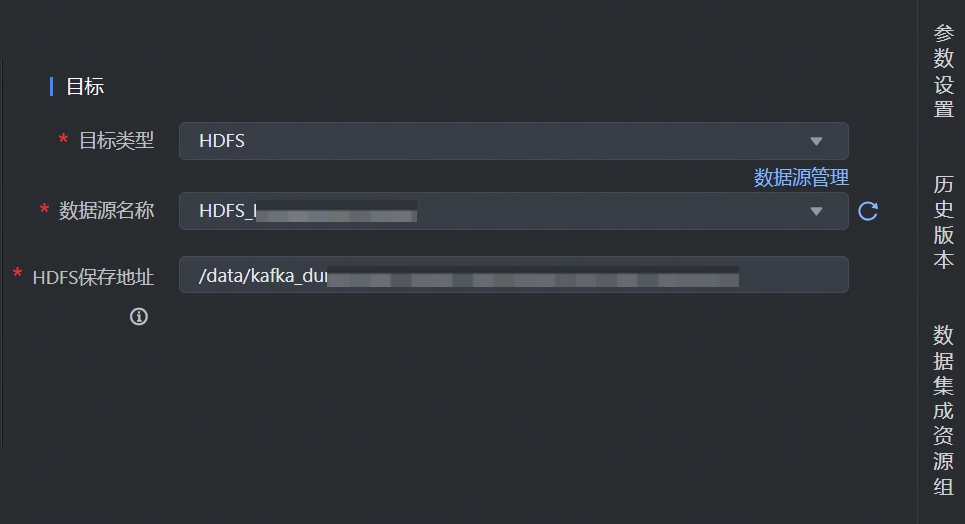
流式集成任务实时写入 HDFS 数据源,数据目标类型选择 HDFS,并完成以下相关参数配置:
其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。
参数 | 说明 |
|---|---|
*目标类型 | 下拉选择 HDFS 数据源类型。 |
*数据源名称 | 已在数据源管理中注册成功的 HDFS 数据源,下拉可选。 |
*HDFS 保存地址 | 填写需要写入数据的 HDFS 存储路径信息。 注意
|
4.5 字段映射
可视化离线读 HDFS,数据来源和目标端配置完成后,需要指定来源和目标端的字段映射关系,根据字段映射关系,数据集成任务将源端字段中的数据,写入到目标端对应字段中。
您可通过以下三种方式操作字段映射关系:
- 自动添加:单击自动添加按钮,根据两端数据表信息,可以自动填充来源和目标的字段信息。
- 手动添加:单击手动添加按钮,可以手动编辑来源和目标的字段信息,可以逐个添加。
- 移动\删除字段:您也可以根据需要移动字段映射顺序或删除字段。
说明
实时 HDFS Writer 目前上游只能承接 BMQ、RocketMQ、Kafka 和 DataSail 这四种消息队列类型数据源。这四种数据源会将消息的原始负载直接发送到 HDFS Writer,然后由 HDFS Writer 直接以二进制形式写入 HDFS 文件,因此不需要配置 column 字段。
5 高级参数可选配置
5.1 HDFS 通用高级参数
对于可视化通道任务,高级参数可在任务开发界面:任务运行参数 > 自定义参数设置中填写,通用参数需要加上 job.common. 前缀如图所示: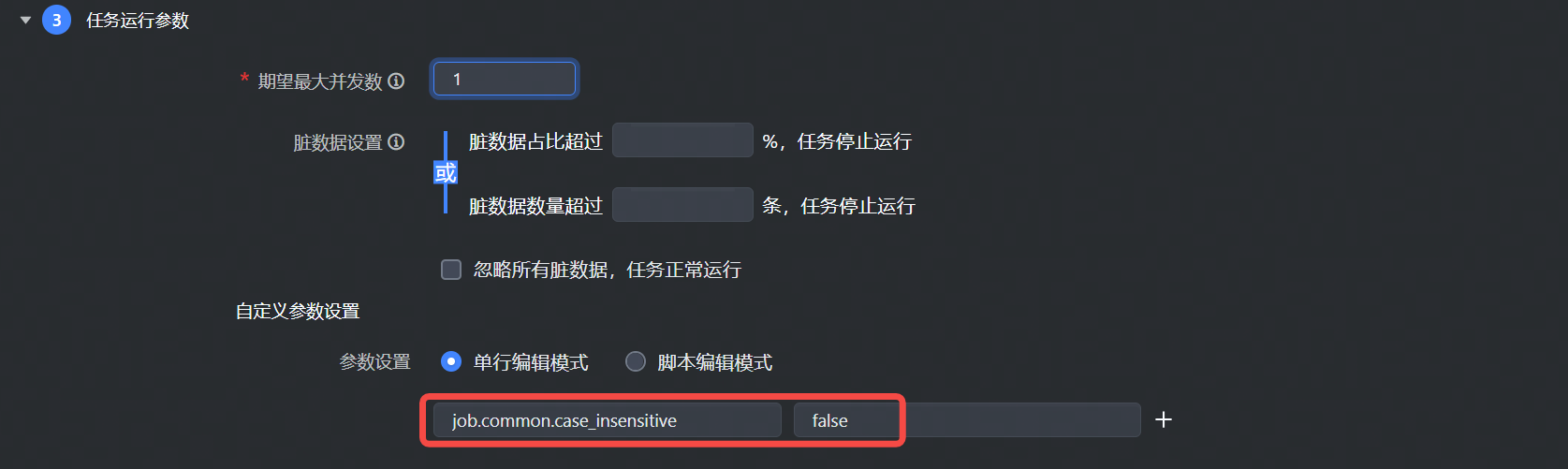
JSON 数据格式相关参数:
参数
描述
默认值
job.common.case_insensitive
JSON 内容解析时是否对字段 Key 大小写敏感。
true
job.common.support_json_path
是否支持带
.的字段名。true为支持,false 为不支持。false
job.common.json_serializer_features
DataSail 使用 fastjson 解析 JSON 内容,用户可以通过此参数设置 JSON 解析的 features,详情参考 SerializerFeature - fastjson 1.2.83 javadoc。多个 SerializerFeature 使用逗号分隔。
无
job.common.convert_error_column_as_null
是否将类型转化失败的字段默认置为 null。
false
job.common.host_ips_mapping
HDFS 数据源通过连接串形式配置时,需在高级参数中配置 ip_mapping 信息,将 hdfs 集群的节点域名与 ip 进行映射,示例如下:
job.common.host_ips_mapping = { "master-1-1.emr-c7axxxxxxxxx9b.cn-beijing.emr-volces.com":"xxx.xx.x.xx", "master-1-3.emr-c7axxxxxxxxx9b.cn-beijing.emr-volces.com":"xxx.xx.x.xx", "core-1-1.emr-c7axxxxxxxxx9b":"xxx.xx.x.xx", "master-1-1.emr-c7axxxxxxxxx9b":"xxx.xx.x.xx", "core-1-1.emr-c7axxxxxxxxx9b.cn-beijing.emr-volces.com":"xxx.xx.x.xx", "core-1-2.emr-c7axxxxxxxxx9b":"xxx.xx.x.xx", "master-1-2.emr-c7axxxxxxxxx9b.cn-beijing.emr-volces.com":"xxx.xx.x.xx", "master-1-3.emr-c7axxxxxxxxx9b":"xxx.xx.x.xx", "core-1-2.emr-c7axxxxxxxxx9b.cn-beijing.emr-volces.com":"xxx.xx.x.xx", "master-1-2.emr-c7axxxxxxxxx9b":"172.16.1.68" }无
5.2 HDFS 实时写高级参数
实时写高级参数可在任务开发界面:任务运行参数 > 高级参数中,选择开启按钮后,进行填写,写参数时需要加上 job.writer. 前缀:
参数 | 描述 | 默认值 |
|---|---|---|
job.writer.rolling.max_part_size | 文件切割大小,单位字节,默认 10G。 注意 这里是指未压缩读的数据大小, 而非 HDFS 最终文件大小。 | 10737418240 |
job.writer.hdfs.replication | HDFS 副本数 | 3 |
job.writer.hdfs.compression_codec | HDFS 压缩格式,支持
| zstd |
job.writer.dump.directory_frequency | 写入 HDFS 文件夹的频率,支持以下参数:
| dump.directory_frequency.day |