DataLeap接入了流式计算 Flink 版,在关联 Flink 的项目和资源池后,可以进行 Flink 作业开发。可以通过 Serverless Flink SQL 作业实现不同存储系统之间的 ETL 等。本文以一个简单的示例,将为您介绍 Serverless Flink SQL作业相关的开发流程操作。
1 使用限制
DataLeap产品需开通 DataOps敏捷研发、大数据分析、数据开发特惠版或分布式数据自治服务后,才可绑定流式计算 Flink 引擎。绑定引擎操作详见:项目管理。
2 使用前提
- 子账号操作项目绑定 Flink 引擎实例时:
- 主账号需要先在流式计算 Flink 版控制台导入 IAM 用户。操作详见:用户管理。
- 并将子账号加入到对应引擎项目中。操作详见:引擎项目成员管理。
- 目前 Flink 1.17 执行引擎版本,仅通过白名单形式放开,您可通过提工单的方式,联系我们加白后进行使用。
3 任务配置说明
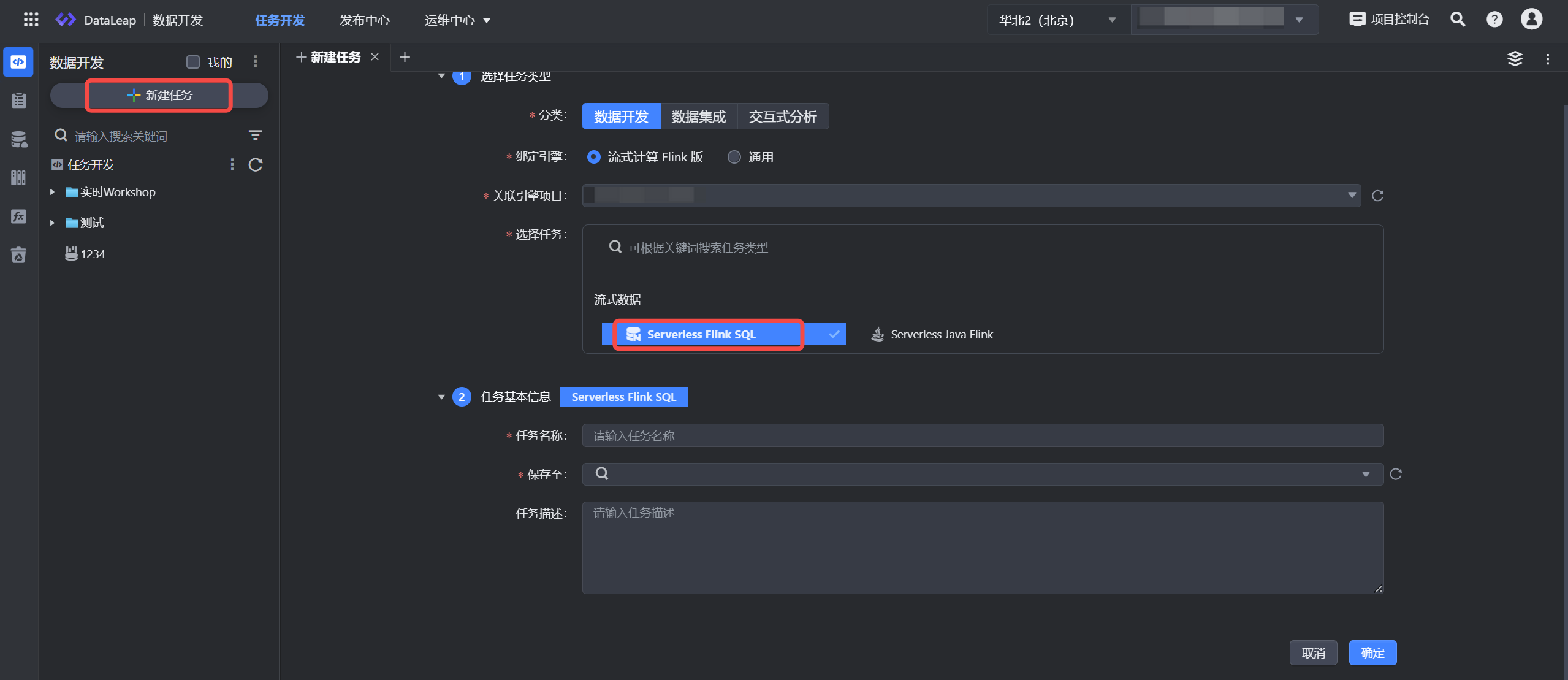
3.1 新建任务
- 登录 DataLeap租户控制台。
- 在具体项目中进入数据开发界面,并单击新建任务按钮进行任务新建。
- 依次选择数据开发 > 流式计算 Flink 版 > Serverless Flink SQL 任务类型。
- 填写任务基本信息,单击确定按钮,完成任务创建。
注意
- 在项目控制台管理界面中,如果新增或修改了引擎,那么在数据开发任务新建窗口中,需刷新整个 DataLeap 数据开发界面,才能看到新增或修改后的引擎任务类型。
- 任务名称信息仅允许数字、字母、下划线、-和.组成, 首尾只能是数字、字母,且允许输入 1~63 个字符。
3.2 编辑任务
新建任务成功后,进入代码开发编辑界面,通过 DDL 和 DML 编辑 SQL ,示例代码如下:
详细语法可参考各版本对应的 Flink 官方文档。
3.2.1 编辑SQL代码
以下为示例Demo:将 Datagen 连接器生成的随机数,输出并打印到 Stdout(标准输出)日志中。
CREATE TABLE datagen_source ( siteid INT, citycode SMALLINT, username STRING, pv BIGINT ) WITH ( 'connector' = 'datagen', 'rows-per-second' = '{{project_param_rows}}', 'fields.username.length' = '30', 'fields.siteid.max' = '1000000000', 'fields.siteid.min' = '10000' ); CREATE TABLE print_sink ( siteid INT, citycode SMALLINT, username STRING, pv BIGINT ) WITH ( 'connector' = 'print', 'print-identifier' = 'out' ); insert into print_sink select * from datagen_source;
DataLeap 支持您在 SQL 脚本中直接使用项目或自定义参数变量形式,如 {{project_param_rows}},提升任务在不同环境中的执行效率。项目或自定义参数变量使用说明详见3.4.4 任务输入参数。
3.2.2 数据源格式
SQL 编辑完成后,您可在下方选择数据源格式:
支持选择其他和 Pb 数据类型。
Pb 类定义:需要将 Pb 类定义文件拖动到输入框中,或手动输入,如以下示例:
说明
- 一次只能有一个入口类。
- 若入口类下的字段有嵌套其他类,这些类必须放在一起定义。
填写示例: syntax = "proto2"; package abase_test; message AbaseTest { required int64 first_id = 1; required int64 latest_id = 2; }Pb 入口 message:填写类名信息
3.3 导航栏功能区解析
功能名称 | 描述 |
|---|---|
格式化 | 依据在个性化设置中的SQL格式化风格的设置,格式化书写的代码,使其语法结构看起来简洁明了。 |
解析 | 解析检查书写的 SQL 代码的语法和语义正确性,运行前检查语法错误信息,防止运行出错。 |
执行引擎 | 目前支持 Flink 1.11、Flink 1.16、Flink 1.17 执行引擎版本。 说明 目前 Flink 1.17 执行引擎版本,仅通过白名单形式放开,您可通过提工单的方式,联系我们加白后进行使用。 |
3.4 参数设置
单击右侧导航栏中参数设置,进行任务的基本信息、任务输入参数、资源设置、数据源登记、Flink 运行参数配置。
3.4.1 基本信息
Serverless Flink SQL 任务的基本信息配置如下:
参数名称 | 描述 |
|---|---|
任务名称 | 显示创建任务时输入的任务名称,参数设置中不支持修改,可以在左侧任务目录结构中的任务名称右侧更多单击重命名进行修改。 |
任务类型 | Serverless Flink SQL |
引擎类型 | 流式计算 Flink 版。 |
关联引擎项目 | DataLeap侧关联的引擎项目名称。 |
任务描述 | 非必填,可对任务进行详细描述,方便后续查看和管理。 |
责任人 | 仅限一个成员,默认为任务创建人(任务执行失败、复查通过或者失败时的默认接收者),可根据实际需要,修改为其他项目成员。
|
计算资源 | 从关联的引擎项目中选择目标资源池。 |
优先级 | 您可对流式任务设置任务优先级,指定当前任务的优先级情况:
|
标签 | 您可以自定义标签,用于标识某一类任务,以便快速搜索过滤,操作即时生效,无需重新上线任务。
|
3.4.2 引入资源
Flink SQL 任务支持通过引入资源 Jar 包、File 文件资源类型,可在 Jar、File 中自定义 connector 的方式,进行 Flink SQL 任务的编辑、Session 调试、提交上线执行等操作。
说明
- Jar、File 资源类型中自定义 connector 和内置 connector 重名时,不支持在同一个任务中使用,否则任务执行时会出现冲突异常的情形。内置 connector 详见连接器列表。
- 当线上正在运行的 Flink SQL 任务包含资源引用时,如果资源文件发生更新,那么在资源库更新资源文件之后,您需前往运维中心重启流式任务,以使资源变更生效。
在下拉框中,选择已通过资源库上传的 Jar、File 资源,可支持多选。若您还未上传资源,您可单击“新建资源”按钮,前往资源库进行资源创建,操作详见资源库。
3.4.3 资源设置
设置任务运行时相关资源分配情况:
参数名称 | 描述 |
|---|---|
TaskManager 个数 | 设置 flink 作业中 TaskManager 的数量。 |
单 TaskManagerCPU 数 | 设置单个 TaskManager 所占用的 CPU 数量。 |
单 TaskManager 内存大小(MB) | 设置单个 TaskManager 所占用的内存大小。 |
单 TaskManager slot 数 | 设置单个 TaskManager 中 slot 的数量。 |
JobManager CPU数 | 设置单个 JobManager 所占用的 CPU 数量。 |
JobManager 内存 | 设置单个 JobManager 所占用的内存大小。 |
3.4.4 Flink 运行参数
可填写 Flink 相关的动态参数和执行参数,平台已为您提供一些常用的 SQL 参数、State 参数、Runtime 参数等,您可以根据实际情况进行选择,或者自行输入所需参数。更多参数详见 Flink 官方文档。
- 单行编辑模式:填写 key-value,key值只允许字母、数字、小数点、下划线和连字符。
- 添加一行参数
- 删除当前这行参数
- 清空输入框中已输入的参数值

- 脚本编辑模式:通过JSON、Yaml的格式填写运行参数。
- 子类查看模式:您通过上方编辑模式输入参数后,可单击子类查看模式,支持将添加的参数自动做分类,帮助您在众多参数下,能更方便了解输入的 Flink 参数。
说明
- 可在对应分类下,按照关键词搜索需要使用的参数。
- 若在指定分类下,无法搜索到对应参数,可在“其它参数”类别,自行进行输入。
- 填写在“其它参数”类别下的参数,若隶属于“SQL参数/State参数/Runtime参数”类别,完成编辑后,系统会将其归属到对应分类。
3.4.5 任务输入参数
若您希望同一套代码能在不同执行环境下,实现自动区分不同的引擎环境参数、项目参数、自定义参数等,则您可以通过设置任务的输入参数,实现此场景需求。
任务输入参数支持您通过使用自定义参数和项目参数,以变量或常量形式传入流式任务中使用,通过 {{参数名}} 的方式在代码中使用:
在参数设置 > 任务输入参数栏,单击手动添加按钮,进入添加输入参数界面操作。
输入参数具体分为以下两类:
- 项目参数:将项目控制台中设置的参数信息当作输入,操作流程如下:
- 在界面右上角,单击项目控制台, 进入项目配置信息界面。
- 单击右侧导航栏中的参数信息 > 新建参数按钮,来添加项目参数。
- 在弹窗中设置项目参数名称、开发环境参数值、生产环境参数值和描述等信息,并单击确定按钮,完成参数新建。配置详见参数信息设置。
- 控制台项目参数新建完成后,返回数据开发参数设置窗口,添加输入参数,参数类型为项目, 来源选择上方新建的参数名称。
- 单击确定按钮,完成项目输入参数添加。
- 自定义参数:将用户自定义的参数当作输入,操作流程如下:
- 在数据开发参数设置窗口中,添加输入参数,依次设置参数名称、下拉选择自定义参数类型,并填入参数值,支持常量或变量形式输入。
- 单击确定按钮,完成自定义输入参数添加。
任务输入参数配置完成后,将任务提交发布并启动,进入实时运维中心 > 日志 > Application Url > Job Manager > Stdout 中,查看实际替换后的运行代码: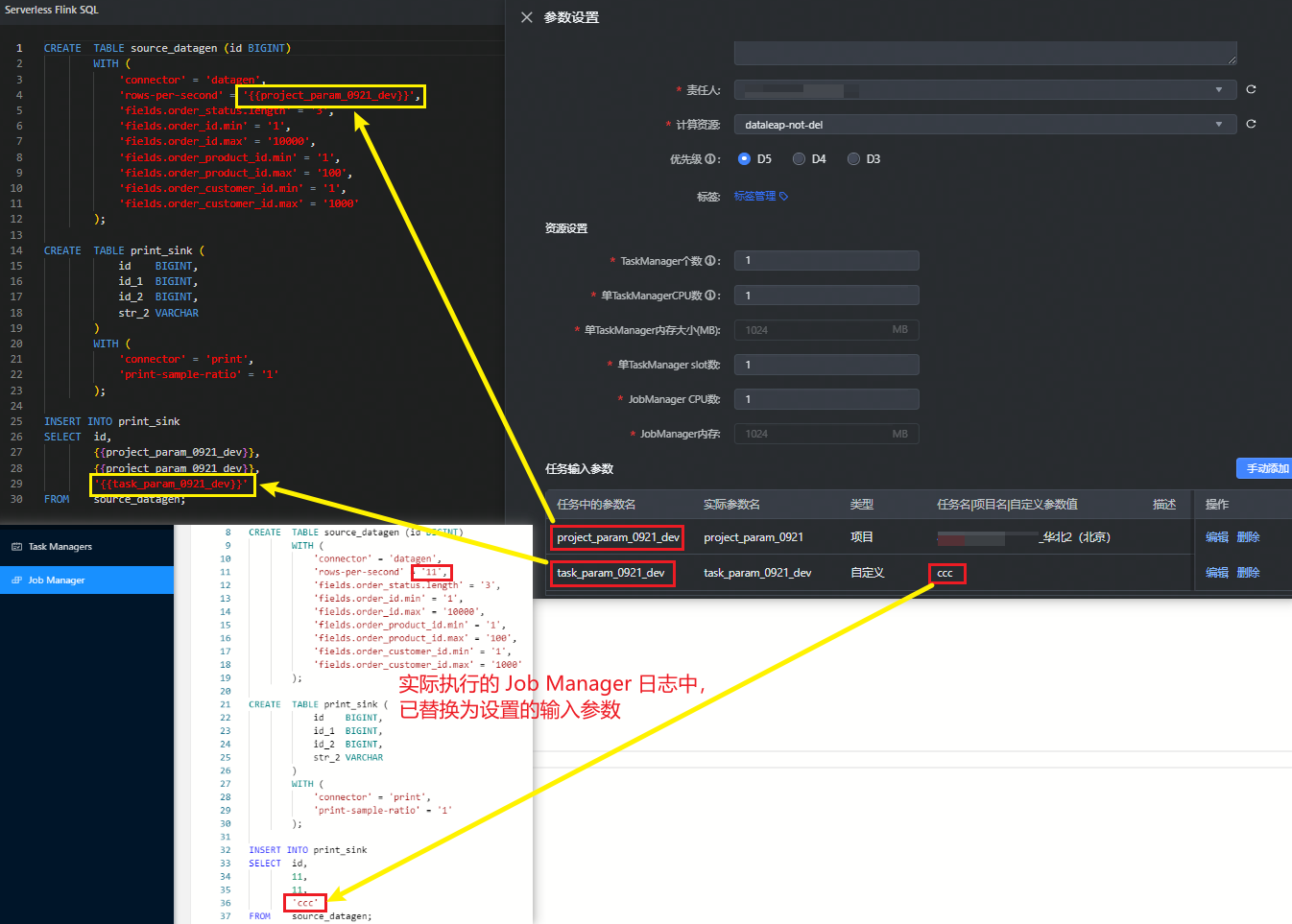
3.4.6 数据源登记
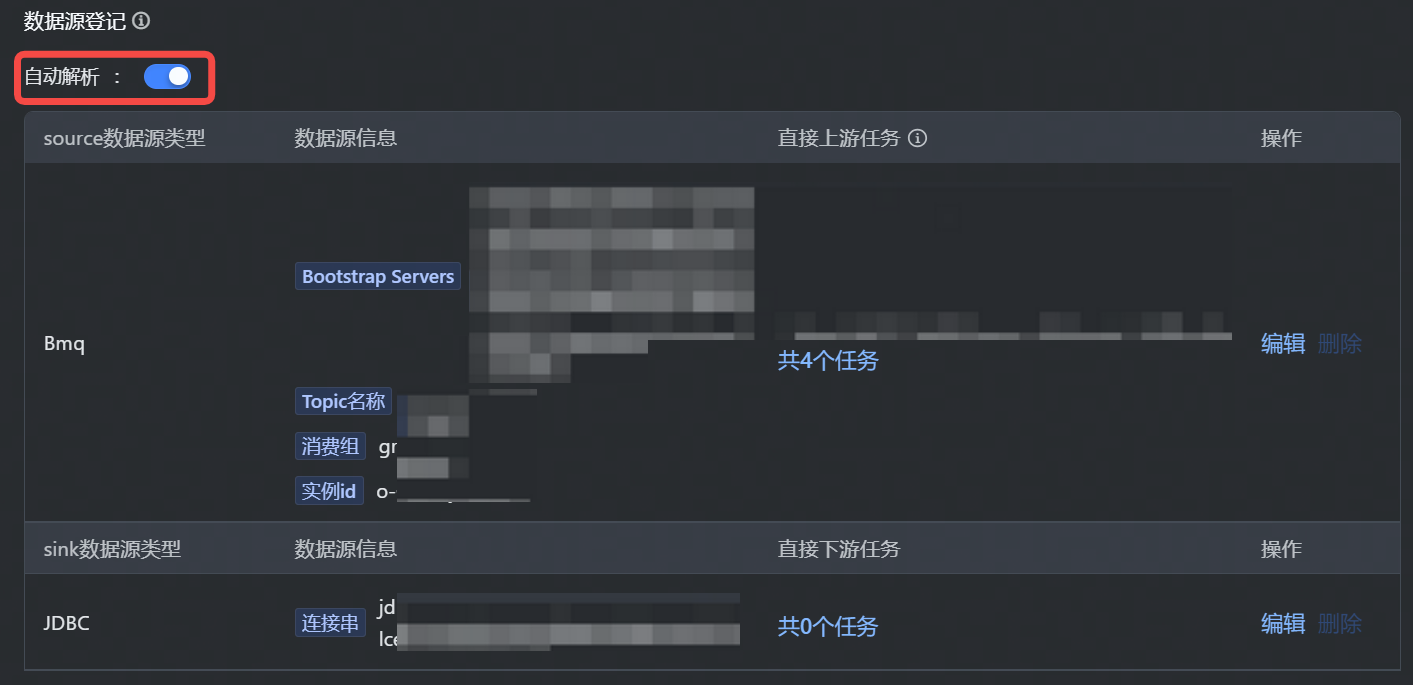
登记该任务使用的 Source 和 Sink 信息,以用于后续监控配置和血缘构建。支持通过自动解析和手动添加方式。
- 自动解析:保存 SQL 逻辑后,单击自动解析按钮,可根据 SQL 逻辑自动进行数据源上下游登记。
- 源/目标:支持源/目标 Source 和 Sink 的选择。
- 数据源类型:支持选择 DataGen、Rmq、Bmq、JDBC、Abase、火山/自建 Kafka 这些 Connector 的数据源自动解析。
说明
Abase 和 Rmq 数据源类型,仅支持解析操作,暂不支持上线发布后运行。且 Abase 数据源通常是在火山引擎内部业务上云中使用。
- 各数据源类型需补充填写相应的信息,您可根据实际场景进行配置,如 Kafka 的数据源类型,需填写具体的Bootstrap Servers、Topic 名称、消费组等信息。
- 直接上游任务:根据数据源匹配逻辑,自动解析出上游任务。您也可通过下方手动添加的方式,进行搜索上游任务名称,单击添加按钮,进行手动添加。
- 直接下游任务:根据数据源匹配逻辑,自动解析出下游任务,但无法通过手动添加的方式进行操作,仅展现通过数据源匹配后的结果。
- 自动解析的数据源,您可通过关闭自动解析按钮,将登记的数据源给删除。
- 手动添加:您也可以通过手动添加的方式进行数据源登记。
- 批量删除:手动添加的数据源,您可通过勾选已登记的数据源后,单击右侧删除或批量删除按钮 ,删除勾选中的数据源。
- 上下游任务查看:数据源登记解析出的上下游任务,您可对上游依赖任务进行编辑、添加、删除、禁用等操作;下游任务仅支持查看。
4 调试任务
任务所需参数配置完成后,您可进行 Serverless Flink SQL 任务的调试操作。
操作栏中单击调试按钮,进行开发环境调试工作。
说明
Flink 1.17 执行引擎,暂不支持任务调试能力。
4.1 任务调试检查
在调试窗口,默认会进行以下任务前置配置信息检查:
- 基本配置检查
- 流式 SQL 检查
- PB 配置检查(如有 PB 的数据类型存在)
4.2 任务调试数据
待任务自动检测通过后,您可开始进行调试相关配置:
4.2.1 构建数据
调试配置时可使用测试数据或线上数据作为调试的输入数据,当使用测试数据作为输入时,您需先在构建数据页签中,构建相应的测试数据。构建操作如下: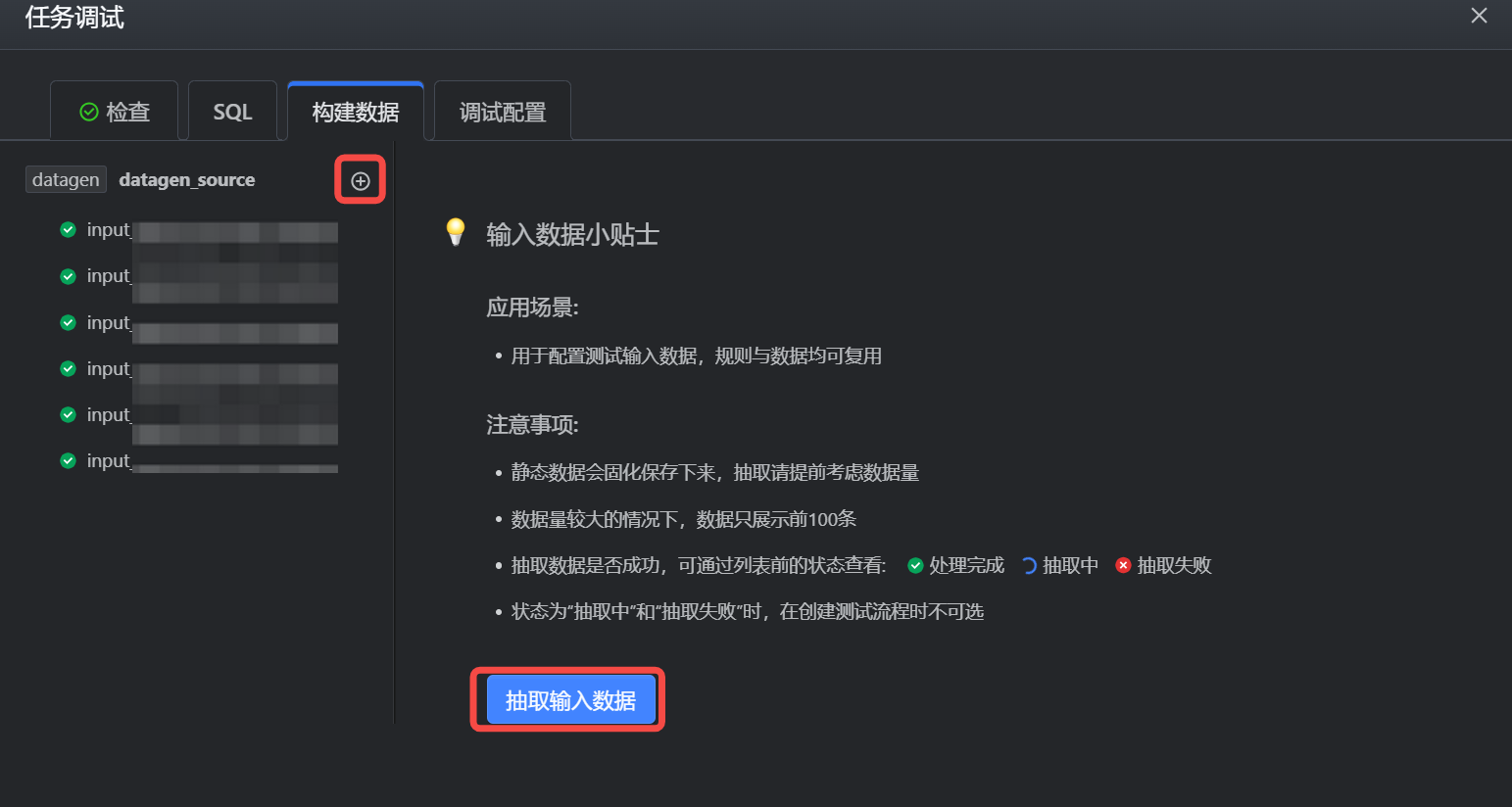
单击左侧列表上的构建输入数据按钮,或单击界面的抽取输入数据按钮,进入测试数据新建界面,并完成以下配置内容:
参数
说明
所属数据源
下拉选择所属数据源的信息。默认会解析您 SQL 代码中的 Source 数据源信息。
输入数据名称
填写输入数据的名称,支持中文、字母、数字、下划线组合。
获取方式
输入数据获取方式,支持手动构造、本地上传两种方式:
- 手动构造:支持 json、excel 形式进行手动构造数据。
- 本地上传:将本地数据文件拖入,单击上传即可,文件大小限制 20MB。
数据构造完成后,您可单击下方保存并预览数据按钮,左侧列表展示当前任务相关数据源的输入数据情况及抽取状态,显示绿色时,即表示抽取成功。
若后续需替换测试数据,您也可单击测试数据详情右侧的数据配置按钮,重新进行数据上传或构造。说明
- 构建数据状态为“抽取中”和“抽取失败”时,在调试配置选择测试数据流程时不可选择此测试数据。
- 数据量较大的情况下,数据只展示前100条。
- 静态数据会固化保存下来,抽取请提前考虑数据量
4.2.2 调试配置
在调试配置界面,您需进行任务的运行模式、输入数据选择。
配置项 | 说明 |
|---|---|
运行模式 | 调试运行模式仅支持快速模式,并下拉选择正常运行态中的 Session 集群。若您还未创建可运行的 Session 集群,您可单击创建集群按钮,前往流式集群控制台进行创建。Session 集群操作详见流式集群管理。 说明 Session 集群仅运行中的状态,且新建集群时选择的引擎版本,需和 Serverless Flink SQL 任务中的执行引擎版本保持一致时,才可被选中。 |
输入数据 | 输入数据支持选择测试数据、线上数据类型:
说明 自定义 connector 不支持使用测试数据进行调试,您可直接使用线上数据进行调试校验。 |
调试配置完成后,您可单击实际执行代码预览按钮,进行实际执行代码的 Review,检查是否符合调试要求。
4.3 开始测试
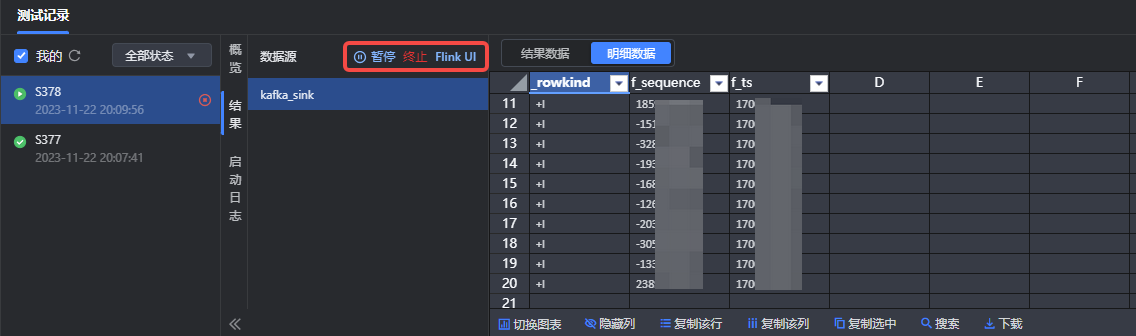
数据配置完成后,单击窗口的开始测试按钮,即开始调试运行,在下方的测试记录窗口,查看任务运行概览、结果、启动日志等信息。
在结果界面,您可以动态的查看最终结果和明细数据情况,也可进行测试暂停、终止、和查看 Flink UI 界面等操作。
说明
若输入数据选择为测试数据,且执行引擎为 Flink 1.16 时,明细数据结果暂不支持查看。
5 提交发布
任务所需参数配置完成后,将任务提交发布到运维中心实时任务运维中执行。
单击操作栏中的保存和提交上线按钮,在弹窗中,需先通过任务上线检查和提交上线等上线流程,最后单击确认按钮,完成作业提交。详见概述---流式任务提交发布。
后续任务运维操作详见:实时任务运维。