1 概述
DataLeap 接入了流式计算Flink版,在 DataLeap 项目关联 Flink 的项目和资源池后,可以进行 Flink 作业开发。通过创建 Flink Batch SQL 任务,使用其 Flink 引擎,来执行 Batch SQL 语句。
例如:在某些情况下,您可以用和流式 Serverless Flink SQL 任务相同的 SQL 语句,通过离线 Flink Batch SQL 作业,来进行离线数据修正,实现流批一体操作,大幅降低开发和维护成本。
本文以一个简单的示例,将为您介绍 Flink Batch SQL 作业相关的开发流程操作。
2 使用前提
- DataLeap 产品需开通 DataOps 敏捷研发、大数据 分析、数据开发特惠版或分布式数据自治服务后,才可绑定 流式计算 Flink 引擎。绑定引擎操作详见:项目管理。
- 子账号操作项目绑定 Flink 引擎实例时:
- 主账号需要先在流式计算 Flink 版控制台导入 IAM 用户。操作详见:用户管理。
- 并将子账号加入到对应引擎项目中。操作详见:引擎项目成员管理。
3 任务配置说明
3.1 新建任务
- 登录 DataLeap租户控制台 。
- 在概览界面,显示加入的项目中,单击数据开发进入对应项目。
- 在任务开发界面,左侧导航栏中,单击新建任务按钮,进入新建任务页面。
- 选择任务类型:
- 分类:数据开发。
- 绑定引擎:流式计算 Flink 版。
- 关联引擎项目:默认选择引擎绑定时选择的引擎项目,不可更改。
- 选择任务:离线流式数据 Flink Batch SQL。
- 填写任务基本信息:
- 任务名称:输入任务的名称,只能由数字、字母、下划线、-和.组成, 首尾只能是数字、字母,且允许输入 1~63 个字符。
- 保存至: 选择任务存放的目标文件夹目录。
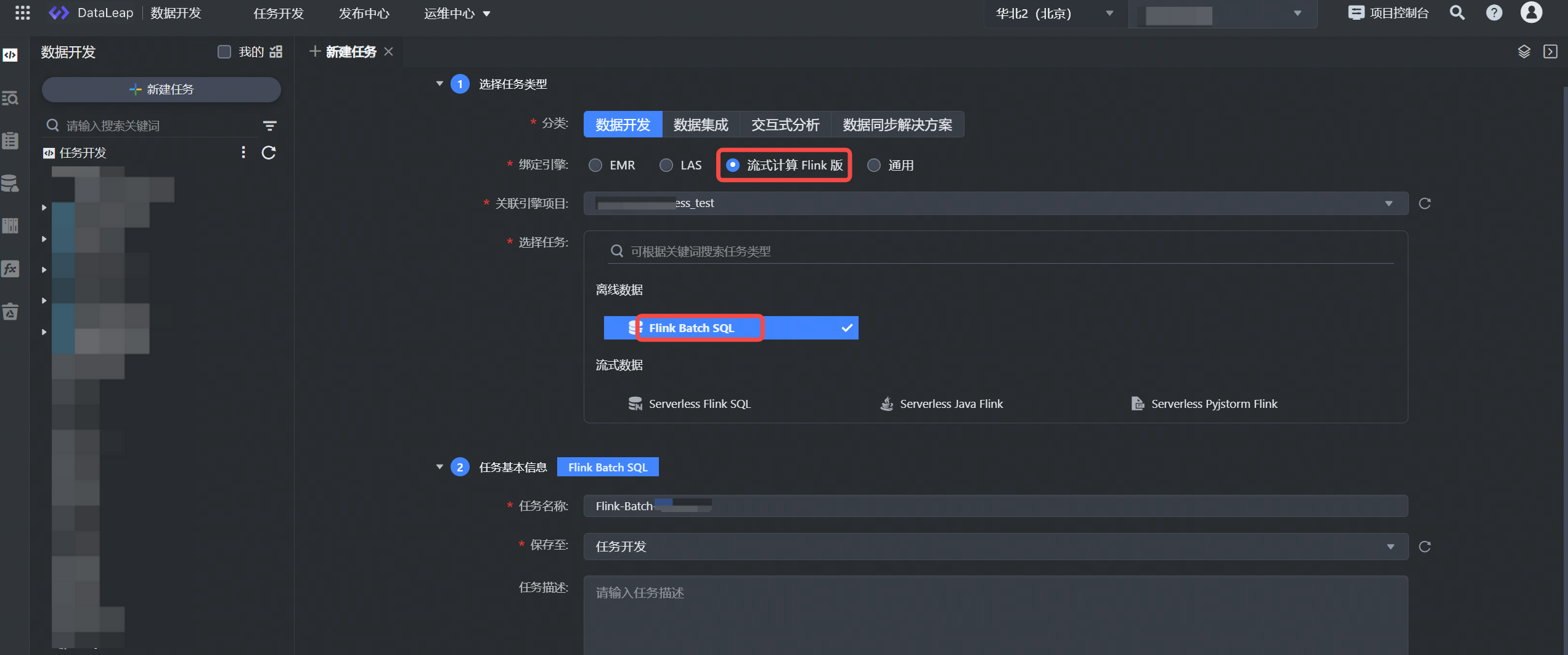
- 单击确认按钮,成功创建任务。
3.2 编辑任务
新建任务成功后,进入代码开发编辑界面,通过 DDL 和 DML 编辑 SQL。详细语法可参考各版本对应的 Flink 官方文档。
以下为示例 Demo:
将 Datagen 连接器生成的随机数,输出并写入到指定的 MySQL 数据库表中。
CREATE TABLE datagen_source (id INT, age INT) WITH ( 'connector' = 'datagen', 'number-of-rows' = '10', 'rows-per-second' = '1' ); CREATE TABLE jdbc_sink (id INT, age INT) WITH ( 'connector' = 'jdbc', 'url' = 'jdbc:mysql://mysql*****.rds.ivolces.com/teat_db', 'table-name' = 'datagen_table', 'username' = 'user_*****', 'password' = '*****', 'scan.partition.column' = 'id', 'scan.partition.num' = '2', 'scan.partition.lower-bound' = '0', 'scan.partition.upper-bound' = '100', 'scan.fetch-size' = '1' ); INSERT INTO jdbc_sink SELECT * FROM datagen_source;
3.3 导航栏功能区解析
功能名称 | 描述 |
|---|---|
格式化 | 依据在个性化设置中的 SQL 格式化风格的设置,格式化书写的代码,使其语法结构看起来简洁明了。 |
解析 | 解析检查书写的 SQL 代码的语法和语义正确性,运行前检查语法错误信息,防止运行出错。 |
执行引擎 | 目前支持 Flink 1.11、Flink 1.16、Flink 1.17 执行引擎版本。 说明 目前 Flink 1.17 执行引擎版本,仅通过白名单形式放开,您可通过提工单的方式,咨询 DataLeap 支持同学加白后进行使用。 |
SQL 方言 | 支持下拉选择 DEFAULT 类型。 |
3.4 调度设置
任务配置完成后,在右侧导航栏中,单击调度配置按钮,进入调度配置窗口,您可以在此设置任务基本信息、调度属性、依赖、任务输入输出等信息,详细参数设置详见:调度设置。
3.4.1 高级参数
其中 Flink Batch SQL 任务,支持在调度属性参数中设置高级参数, 您可在此输入 Flink 任务中所需用到的参数,支持以下两种添加方式:
- 单行编辑模式:填写 key-value,key值只允许字母、数字、小数点、下划线和连字符。
- 添加一行参数
- 删除当前这行参数
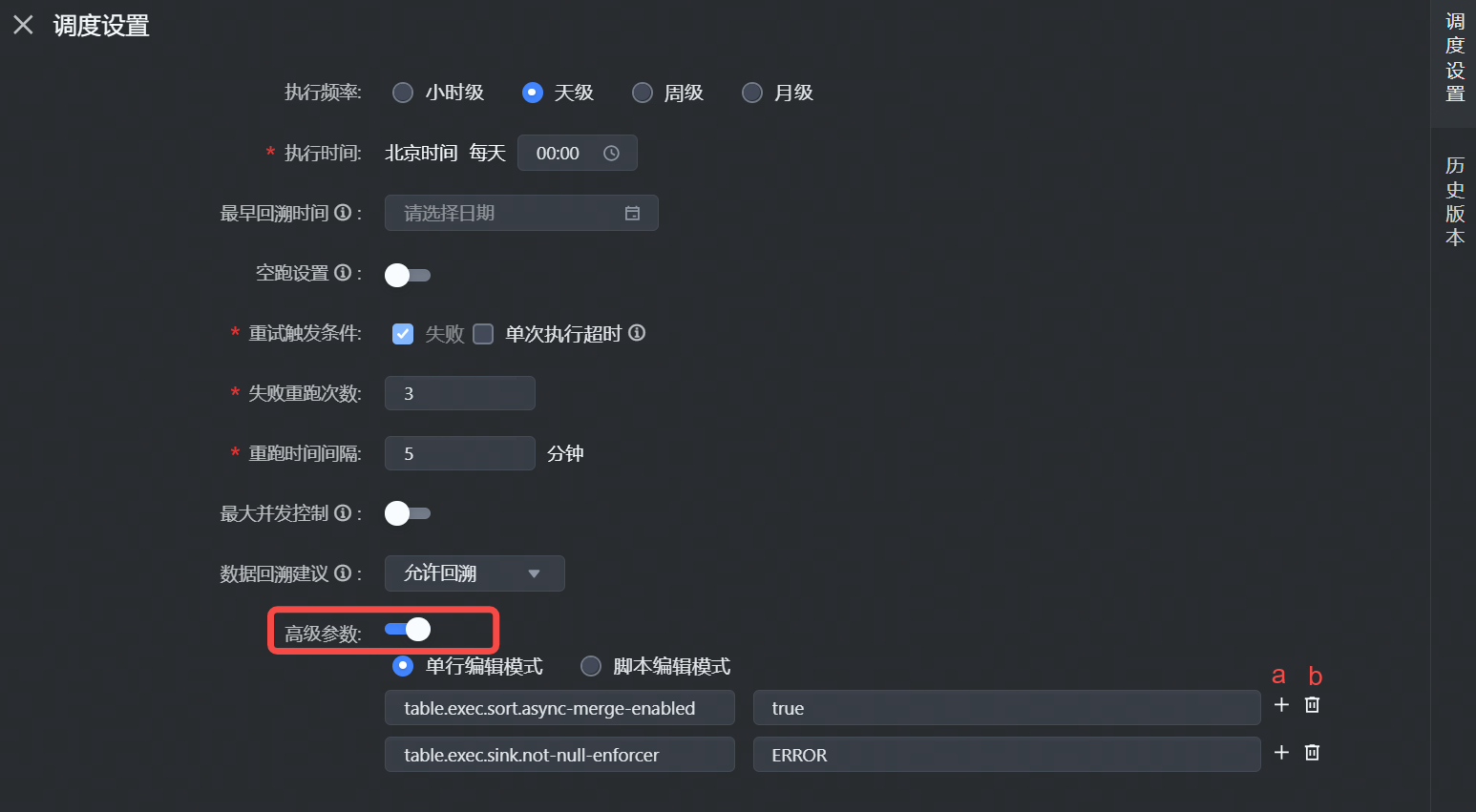
- 脚本编辑模式:通过 JSON、Yaml 的格式填写运行参数。
高级参数说明详见 Flink 参数配置文档。
3.4.2 依赖关系
您可在此配置离线任务的上下游依赖关系,完成数据血缘构建,以此保障下游执行时,能够准确获取到上游产出的数据,确保数据质量,提升数据开发效率。
上下游依赖配置操作详见任务调度依赖。
3.4.3 输入输出参数
在设置任务上游依赖后,您可通过设置任务的输入输出参数,可实现参数在上游和下游任务之间进行传递,该参数的内容值,可来源于上游任务的输出结果、项目参数或是自定义参数值。
输入输出参数操作详见输入输出参数设置。
3.4.4 资源设置
设置任务运行时相关资源分配情况:
参数名称 | 描述 |
|---|---|
TaskManager个数 | 设置 flink 作业中 TaskManager 的数量。 |
单TaskManagerCPU数 | 设置单个 TaskManager 所占用的CPU数量。 |
单TaskManager内存大小(MB) | 设置单个 TaskManager 所占用的内存大小。 |
单TaskManager slot数 | 设置单个 TaskManager 中slot的数量。 |
JobManager CPU数 | 设置单个 JobManager 所占用的CPU数量。 |
JobManager内存 | 设置单个 JobManager 所占用的内存大小。 |
4 调试任务
任务代码逻辑和参数配置完成后,您可在编辑器上方,单击操作栏中的保存和调试按钮,进行任务调试。
说明
调试操作,直接使用线上数据进行调试,需谨慎操作,您可用少量数据来线上输出和需求验证。
5 提交任务
SQL 语句和任务所需参数配置完成后,可将任务提交发布到运维中心离线任务运维中周期执行。
单击上方操作栏中的保存和提交上线按钮,在提交上线对话框中,选择回溯数据、监控设置、提交设置等参数,最后单击确认按钮,完成作业提交。 提交上线说明详见:数据开发概述---离线任务提交。
后续任务运维操作详见:离线任务运维。