1 CDC 概述
CDC(Change Data Capture) 是变更数据获取的简称。可以基于增量日志,以极低的侵入性来完成增量数据捕获的工作。
核心思想是,监测并捕获数据库的变动,包括数据或数据表的插入、更新以及删除等,将这些变更按发生的顺序完整记录下来,可以直接写入到消息中间件中以供其他服务进行订阅及消费,也可以直接对接其他数据源做业务或者数据分析&应用。
与批量同步相比,变更数据的捕获通常具有以下三项基本优势:
- CDC 通过仅发送增量的变更,来降低通过网络传输数据的成本;
- CDC 可以帮助用户根据最新的数据做出更快、更准确的决策。例如,CDC 会将事务直接传输到专供分析的应用上;
- CDC 最大限度地减少了对于生产环境网络流量的干扰。
2 方案简介
2.1 方案介绍
实时同步解决方案目前支持以下两种方案:
方案类型 | 说明 |
|---|---|
实时分库分表方案概述 |
|
实时整库方案概述 |
|
本文将为您介绍通过 DataSail 创建分库分表实时同步解决方案,实现多个数据库实例下的多个相同 Schema 分表,同步到目标端数据源的一个表中。
2.2 方案架构
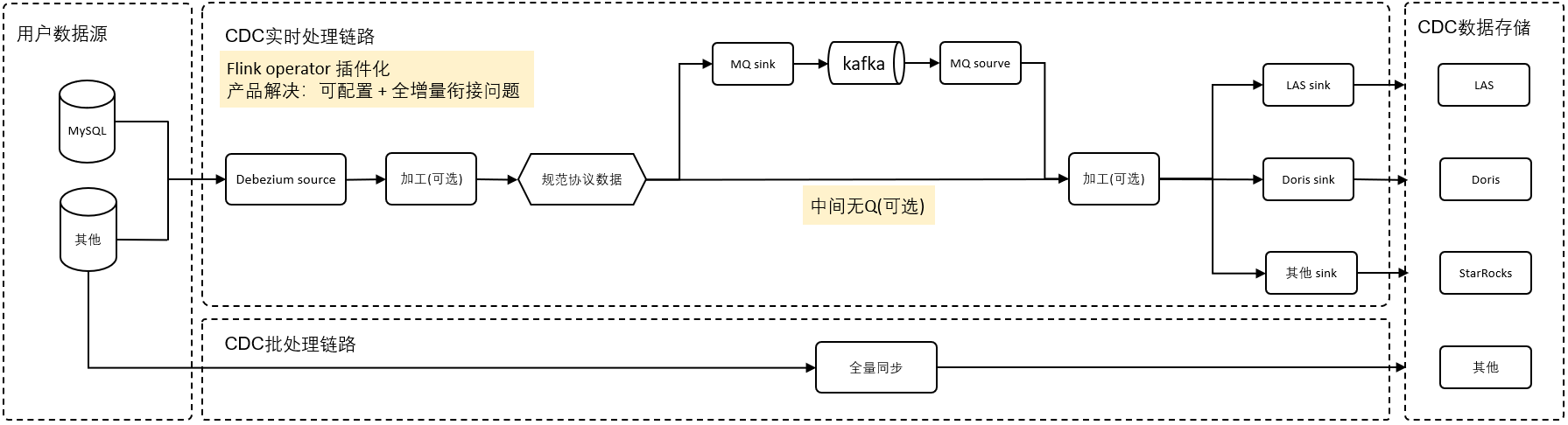
3 前置操作和注意事项
3.1 前置操作
- 已开通并创建 DataLeap 项目,创建的全量增量任务均会同步到该项目下。详见新建项目。
- 已开通全域数据集成(DataSail)产品。详见服务开通。
- 已创建合适资源规格的独享数据集成资源组,并将其绑定至创建成功的 DataLeap 项目下。购买操作详见资源组管理,项目绑定操作详见数据集成资源组。
- 已完成来源端和目标端的数据源准备工作。创建数据源操作详见配置数据源。
- 通过 Oracle CDC 数据源,配置实时整库同步、实时分库分表同步解决方案,使用基于 LogMiner 的日志进行采集时需进行一些前置配置操作。具体详见Oracle CDC 数据源 LogMiner 配置文档。
- 在 DataSail 解决方案中,若把 StarRocks 作为目标数据源,并且通过该解决方案自动创建 StarRocks 表时,您需额外将 100.64.0.0/10 网段,添加到 StarRocks 集群所属的安全组中,以确保解决方案自动建表成功。
3.2 注意事项
- 实时分库分表同步解决方案同时支持选择的源表数量目前上限为 2000 张,但建议先以 100 张以下表数量来试用。
- 支持自动创建目标端数据表,不支持自动建库,数据库需要在同步解决方案创建前在目标端提前建好。
4 数据源配置
在配置实时分库分表同步解决方案前,您需在数据源管理界面中,配置来源端和目标端相应的数据源。详见配置数据源。
- 独享数据集成资源组所在的 VPC 需要和来源端、目标端数据库实例所在的 VPC 保持一致,火山引擎 RDS 数据库类型需要将 VPC 中的 IPv4 CIDR 地址,加入到 RDS 数据库的白名单下,保证资源组与数据源之间的网络互通;
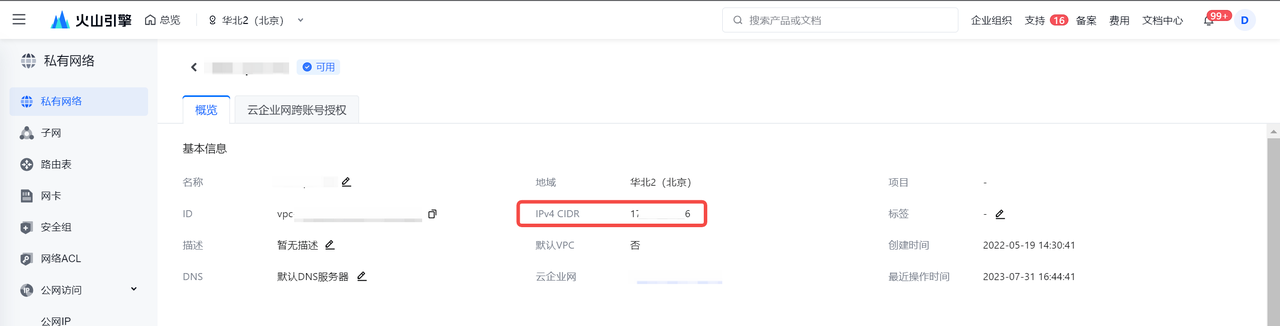
- 若资源组和数据源实例不在同一 VPC 环境时,您可通过公网或者通过专线形式进行互通。网络配置详见网络连通解决方案。
5 新建实时分库分表同步方案
数据源配置操作准备完成后,您可开始进行实时分库分表同步方案配置:
- 登录 DataSail 控制台。
- 在左侧导航栏中选择数据同步方案,进入同步方案配置界面。
- 单击目录树中项目选择入口,选择已创建的 DataLeap 项目。
- 在方案列表界面,单击右上角新建数据同步解决方案按钮,下拉选择实时分库分表同步按钮,进入方案配置界面。
进入配置界面后,按照以下步骤,完成方案的基本配置、数据缓存配置、映射配置等流程配置。
6 基本配置
实时分库分表同步方案基本配置参数说明如下。
6.1 基本信息
其中名称前带 * 的参数为必填参数,名称前未带 * 的参数为可选参数。
配置项 | 说明 |
|---|---|
*链路类型 | 下拉选择来源和目标端数据源类型。
|
*方案名称 | 输入实时分库分表同步方案名称。只允许字母、数字、下划线、连字符,且仅允许输入 1~63 个字符。 说明 解决方案实际生成的任务名称定义:
|
方案描述 | 输入此方案的描述信息,方便后续维护管理。 |
*保存至 | 单击选择框,在弹窗中选择方案保存路径,此路径为数据开发项目中的任务路径。创建方式详见任务目录树管理。 |
6.2 网络与资源配置
在网络与资源配置中,配置数据来源/目标端数据源信息、集成资源组信息。其中名称前带 * 的参数为必填参数,名称前未带 * 的参数为可选参数。
配置项 | 说明 |
|---|---|
*数据来源 | 在数据来源框中,选择数据源管理中创建成功的数据源,支持选择多个。
说明 目前对于 JDBC 类火山引擎数据源类型,您可通过批量新增数据源的方式,进行批量创建,单次最多创建 200 个数据源:
|
数据缓存 | 选择同步解决方案是否需要通过数据缓存的方式来采集数据:
|
*数据目标 | 在数据目标框中,选择数据源管理中创建成功的数据源。 |
*离线/实时集成任务资源组(离线全量/实时增量) | 下拉选择 DataLeap 项目控制台中已绑定的独享数据集成资源组:
|
6.3 资源组高级配置
您可在资源组高级配置中,配置离线全量同步、实时增量同步、任务调度等运行配置信息。
离线全量同步
设置解决方案中离线全量任务的运行参数情况。其中名称前带 * 的参数为必填参数,名称前未带 * 的参数为可选参数。配置项
说明
*离线集成任务资源组
默认选择在网络与资源配置中选择好的独享数据集成资源组。您也可下拉选择已在 DataLeap 项目控制台中绑定的其他独享数据集成资源组。
说明
- 选择的资源组,需要确保能与源端、目标端数据源连通。
- 您也可以单击资源组管理按钮,前往资源组管理界面进行资源组的查看或新建等操作,详见资源组管理。
*默认 Quota 数
设置可同时提交执行的集成任务数量,可根据独享集成资源组规格进行配置,如资源组的大小为 40CU,则 Quota 配置需必须小于 20(40/2),否则会因资源问题导致任务执行时异常。
说明
您也可按需勾选“每次提交执行时不询问”选项,建议您勾选。
若不勾选,方案每次提交执行时,在执行详情 > 任务 Quota 检测步骤中,需要人工进行 Quota 数确认。*期望最大并发数
设置离线任务同步时,可以从源端并行读取或并行写入目标端的最大线程数。
并发数影响数据同步的效率,并发设置越高对应资源消耗也越多,由于资源原因或者任务本身特性等原因,实际执行时并发数可能小于等于设置的期望最大并发数。集成高级参数设置
打开高级参数输入按钮,根据实际业务要求,以 Key\Value 形式,在编辑框中输入离线任务所需的高级参数。
可参考下方任务通用高级参数表,更多参数详见高级参数-任务运行参数、高级参数-资源使用参数。实时增量同步
设置解决方案中实时增量任务的运行参数情况。其中名称前带 * 的参数为必填参数,名称前未带 * 的参数为可选参数。配置项
说明
*实时集成任务资源组
默认选择在网络与资源配置中选择好的独享数据集成资源组。您也可下拉选择已在 DataLeap 项目控制台中绑定的其他独享数据集成资源组。
说明
- 选择的资源组,需要确保能与源端、目标端数据源连通。
- 您也可以单击资源组管理按钮,前往资源组管理界面进行资源组的查看或新建等操作,详见资源组管理。
*资源设置
可通过自定义和默认两种设置方式,进行实时任务运行资源的设定,如单TaskManager CPU数量、单TaskManager内存大小、JobManager CPU数量等。
说明
默认设置中,各运行资源设置如下:
- 单 TaskManager CPU 数:2
- 单 TaskManager 内存:4096 MB
- 单 TaskManager slot 数:4
- JobManager CPU 数:1
- JobManager 内存:2048 MB
*镜像版本
全域数据集成产品版本更新速度相对较快,解决方案中的实时增量任务需配置流式镜像版本号,建议您下拉选择当前推荐标签的镜像版本号。
说明
历史解决方案建议及时升级到新的镜像版本,您便可以使用新版本的功能和特性,保障任务的稳定性和执行效率,降低运维成本。
更多镜像版本说明及注意事项详见全域集成引擎版本升级管理。集成高级参数设置
打开高级参数输入按钮,根据实际业务要求,以 Key\Value 形式,在编辑框中输入实时任务所需的高级参数。
可参考下方集成高级参数表,更多支持参数详见高级参数。Flink 运行参数设置
支持输入 Flink 相关的动态参数和执行参数,可参考下方 Flink 运行参数表,更多具体参数设置详见 Flink 官方文档。
调度设置
离线全量任务还需要任务调度资源组,来支持任务下发分配至独享数据集成资源组中运行,目前调度资源组支持选择公共调度资源组和独享调度资源组。
资源组高级配置完成后,单击配置窗口右上角关闭按钮,退出配置窗口,并检查基本配置所有参数无误后,单击右下角下一步按钮,进行方案的数据缓存配置。
7 数据缓存配置
基本配置 - 网络与资源配置中选择使用缓存时,需进行该配置。
通过使用中间缓存来采集源端数据,来源数据源需要绑定对应的 CDC 采集数据进入的 MQ。若还未创建采集方案,您需到解决方案-实时数据采集界面,进行方案创建。详见实时数据采集方案(新版)。
说明
- 使用缓存可对同步任务进行缓冲,在性能和稳定性上有所提升,适合对稳定性要求高以及数据量大的场景,但需额外增加缓存数据源及相应成本,请按需配置。
- Kafka、BMQ 数据源类型,也可通过创建相应的 CDC 数据订阅采集任务,将源端 MySQL 中的数据,通过数据库传输服务中数据订阅方式,实时采集到 Kafka 实例中。在数据来源配置时绑定对应的 CDC 采集数据进入的 Kafka。数据订阅操作详见数据库传输服务。
- 数据源选择:根据实际情况,按需选择数据源类型及对应的数据源名称,数据缓存方式需要额外配置 Kafka 数据源、DataSail(内置 Topic) 数据源、BMQ 数据源。
注意
- DataSail(内置 Topic) 、BMQ 数据源缓存方式,目前仅支持 MySQL2Doris、MySQL2StarRocks、MySQL2Elasticsearch 通道进行该缓存方式配置。
- 源端为 GaussDB 数据类型时,必须通过 Kafka 数据缓存方式进行配置,暂不支持直连模式。
- 订阅格式:需根据不同缓存数据源类型中的数据格式进行选择
- Kafka 数据源:支持选择火山 MySQL PROTO、Debezium Json 格式,不同源端数据源类型,支持的格式不同;
- DataSail(内置 Topic) 数据源:仅支持选择 Debezium Json 格式;
- BMQ 数据源:仅支持选择 Debezium Json 格式。
- 映射配置:
数据源类型选择完成后,单击刷新数据源和Topic映射按钮,根据数据源类型,进行相关的映射配置。您可在下拉框中,选择已创建的来源、目标端数据源、Topic 名称和绑定解决方案信息。说明
实时采集解决方案支持绑定多个。
- 单击“添加映射配置”按钮,您可按需添加多个数据源和 Topic 映射关系;
- 单击“映射字段全量配置”按钮,可为多个映射关系,批量操作添加对应的 Topic 和绑定解决方案操作。
确认数据缓存同步方式配置完成后,单击右下角下一步按钮,进入映射设置。
8 映射配置
在映射配置界面中,您需完成数据来源库表与库表映射规则匹配策略:
8.1 数据源配置
进行来源库表的选择,其中名称前带 * 的参数为必填参数,名称前未带 * 的参数为可选参数。
配置项 | 说明 |
|---|---|
*数据源 | 默认展示在网络与资源配置中选择的数据来源名称。
|
*源库、源 Schema、源表/集合选择限定条件 | 您可通过设置源库、源 Schema、源表的限定条件,来获取源表信息。
|
表/集合 | 单击获取源表或获取源集合按钮,平台根据源库、源表/集合限定条件的设置,自动加载符合条件的表/集合。 注意
|
8.2 数据转换配置
DataSail 实时/离线整库同步、实时分库分表同步解决方案,支持添加自定义 SQL 转换规则。它支持将源端采集的数据,对其进行各种数据转换操作,以满足各类业务场景需求。
数据转换可以应用于各种轻量级数据处理场景,例如:
- 字段拆分、合并、重排序:可以灵活使用 SELECT 语句,对源表的字段做拆分、合并、顺序调整。
- 清洗过滤:可以使用 WHERE 条件语句,过滤冗余数据、处理缺失值、纠正数据错误等。
- 预处理:可以使用条件函数,对数据(例如 null 值)进行标准化等预处理。
- 格式转换:可以使用转换函数、加解密函数,将数据从一种格式转换为另一种格式。
单击配置详情按钮,展开数据转换配置界面。在数据转换配置界面,您可进行以下配置操作:
- 语法检查:
- 编辑行:在编辑行中输入 SQL 脚本转换规则语句,来实现数据转换,具体数据转换配置及注意事项,详见解决方案数据转换配置指南。
- 增加/删除行:解决方案中有多个目标表,需要多条数据转换语句时,可进行增加或删除行操作。
- 调整语句顺序:当存在多条转换规则 SQL 时,您可通过上移或下移语句按钮,进行语句顺序调整。
- 函数库:
数据转换 SQL 语句中支持多种函数语法,具体函数说明详见数据转换函数库。 - 高级参数
您可为同步解决方案配置多表映射高级参数,以key-value的形式输入。如指定表的主键字段信息等:primary_keys=new_id。
8.3 目标库表映射配置
来源库表选择完成后,您便可进行后续的库表映射规则配置。
自动分区设置
目前通过 DataSail 实时分库分表解决方案自动建表时,LAS、Doris、StarRocks、ByteHouse CDW、ByteHouse CE 数据源仅支持写入非分区表。高级配置
展开高级配置按钮,进行解决方案 DML、使用已有表、高级参数等相关配置,其中名称前带 * 的参数为必填参数,名称前未带 * 的参数为可选参数。配置项
说明
DML 配置
解决方案执行过程中,支持同步 DML 事件类型,支持插入、更新、删除事件类型。
说明
- 若取消勾选 DML 事件类型,则源端进行相应操作时,解决方案将不同步对应操作类型的数据;
- 若在任务高级参数中配置了 DML 相关语句过滤,则以高级参数中的配置为准,此处勾选不生效。
使用已有表配置
当目标表已存在,即下方“表建立方式”为“使用已有表”时,若此时源表与目标表中已有字段列不一致时,可通过列匹配规则,根据实际场景进行列映射规则设置,目前支持自动映射、同名取交映射两种匹配规则配置:
- 自动映射:默认映射规则,字段列不一致时,提示目标检查异常。
- 同名取交映射:字段列不一致时,仅同名映射匹配到的字段进行数据同步,未匹配到的字段不做同步,任务正常执行。
源表和目标刷新配置
整库离线方案配置的源表和目标表数量较多时,您可设置单次拉取表数量,来分批进行表映射配置,默认单次拉取数量为 100 张表,您可根据实际情况进行调整,填写范围 1~2000。
高级参数配置
您可为同步解决方案配置全局的高级参数,以 key-value 的形式输入。如您可通过设置参数:
storage_dialect_type=MYSQL,来设定 ByteHouse CDW 表为 MySQL 属性表。库/表名映射配置
单击库/表名映射配置按钮,在弹窗中配置库表匹配策略,支持选择与来源库表同名和自定义方式匹配:- 来源库表名同名:目前暂时不支持。
- 自定义:您可通过自定义匹配方式,设置源端与目标库表名称的转换规则,在目标库表名框中输入相应的库表名称信息。配置方式详见“9 库表映射规则说明”。
注意
- 目前暂不支持自动创建同名数据库,您需先在目标端,如 StarRocks 集群中创建好同名的数据库。
- 目标端为 EMR Doris 半托管集群数据源时,建议开启集群高可用服务,使 Doris Master 节点数量在 3 个以上,保障 DataSail 解决方案自动创建表成功;若 Doris 半托管集群仅有 1 Master+1 Core 或 1 Master+2 Core 节点数量时,您需在目标 Doris 数据库中进行手动创建表,并需手动指定副本参数 replication_num,示例如下:
CREATE TABLE demo.t3 (pk INT, v1 INT SUM) AGGREGATE KEY (pk) DISTRIBUTED BY hash (pk) PROPERTIES ('replication_num' = '1');
映射规则配置完成后,单击弹窗右上角关闭按钮,即规则映射配置完成。
DDL 配置
在实时整库 CDC、分库分表、离线整库解决方案中,通常会遇到较多来源端新增表、新增列等 DDL 操作场景。此时您可根据实际业务场景,对来源端不同的 DDL 消息,在配置解决方案同步到目标端数据源时,可进行预设不同的处理策略。说明
在解决方案开启数据缓存模式的情况下,不支持配置解决方案 DDL 能力。
- 单击 DDL 配置按钮,在弹窗中进行消息处理策略配置;
- 按需进行新建表、新增列、删除列、重命名列、修改列类型等处理策略选择;
- DDL 策略配置完成后,单击弹窗右上角关闭按钮,DDL 配置即完成。
DDL 消息处理策略说明详见解决方案 DDL 策略配置
刷新逻辑表和目标表映射
库/表映射配置、DDL 等配置完成后,您可单击刷新源表和目标表映射按钮,自动加载源表和目标表信息,您可以在列表中进行以下操作:操作项
说明
逻辑表名
单击逻辑表名信息,可查看所选的源库表信息。
分片键、分表键
设置分库分表中分片字段和分表键字段信息,其中分表键,默认分配为 “src_meta_info” 字段,便可在目标表中新增该字段,用于标识区分不同的来源库表名称信息。
排序策略
排序策略将影响实时增量任务,若无排序字段,可能会出现上游乱序导致下游数据源错误,建议增加排序策略。
- 无排序:根据上游数据写入顺序,新数据覆盖旧数据;
- 自适应排序:根据目标表属性自动推断排序策略,表/索引建立方式为使用已有表或数据表不存在时,会选择自适应排序方式。
表建立方式
表建立方式分为使用已有表、自动建表和数据表不存在几种方式:
- 使用已有表:当映射配置检查,目标端数据库中若存在相应库表映射规则转换后的表名时,则会直接使用已有表,来执行方案。
注意
使用已有表时,目标端为 ByteHouse CDW、ByteHouse CE 表时,需保证以下表结构:
- ByteHouse CDW 表,表配置时必须要设置唯一键字段;
- ByteHouse CE 表,表引擎必须选择为 HaUniqueMergeTree:
- ByteHouse CDW 表,表配置时必须要设置唯一键字段;
- 自动建表:当映射配置检查,目标端数据库中若不存在相应库表映射规则转换后的表名时,将会通过任务,以映射规则定义的目标表名,自动创建目标表。
说明
- 通过实时分库分表同步方案创建目标表时,需确保数据源中配置的账号有建表的权限,防止在执行自动建表流程时出现失败情况。
- StarRocks 作为目标数据源,并且通过该解决方案自动创建 StarRocks 表时,您需额外将 100.64.0.0/10 网段,添加到 StarRocks 集群所属的安全组中,以确保解决方案自动建表成功。
- 数据表不存在:当映射配置检查,目标端数据库中若不存在相应库表映射规则转换后的表名,且无法通过 DataSail 自动建表时,您需要手动在目标端数据库表中创建目标表,再继续配置解决方案。
全量同步
- 按钮开启时,同步解决方案将创建全量离线任务和实时增量任务,进行历史全量数据和增量数据的同步。
- 按钮关闭时,同步解决方案仅创建实时增量任务,仅同步后续增量变更的源端表数据。
清表策略
您可根据实际情况,选择是否开启清表策略,开启表示在数据写入目标表前,会清空原有目标表中的数据,通常是为了使任务重跑时支持幂等操作。
查看字段信息
可以查看来源表、目标表的字段名和其对应的字段类型等信息。在弹窗中,您也可对自动创建的目标表字段类型和字段描述信息,进行手动编辑调整。
配置
您可为同步解决方案配置多表映射高级参数,以 key-value 的形式输入。
批量操作
当目标表数量较多时,您可勾选多个表后,批量对目标表进行全量同步设置、清表策略设置操作。
提交方案
目标库表映射配置完成后,单击右下角提交方案按钮,进行方案的提交,在弹窗中,您可根据实际情况勾选方案是否立即执行,并单击确定按钮,完成实时数据同步解决方案的创建。
9 方案运维
方案创建完成后,进入到方案列表界面,便可查看方案的执行概况,同时您也可以在列表界面进行以下操作:
9.1 解决方案筛选
在创建众多的解决方案后,您可在方案列表界面通过搜索或筛选的方式进行快速定位方案。
- 您可通过方案名称、方案 ID、数据来源名称、数据目标名称等信息,输入搜索的方式进行筛选。
- 您也可通过下拉选择方案操作状态、方案类型、数据来源名称、数据目标类型、创建人等选项进行任务的定位操作。
9.2 解决方案运维
在方案列表的运维列中,您可操作执行方案运维相关内容:
说明
启动中的解决方案不支持进行提交执行、方案编辑、方案删除操作。
运维操作 | 说明 |
|---|---|
执行详情 |
|
提交执行 | 未在启动中的任务,您可单击运维操作列的提交执行按钮,将任务提交到运行状态,开启增量流任务的运行。
|
方案查看 | 单击运维操作列更多中的方案查看按钮,可对当前解决方案的各个配置步骤进行查看。 |
方案编辑 | 单击运维操作列更多中的方案编辑按钮,可对当前解决方案的方案名称、数据来源端、目标端、DDL 策略配置、运行配置步骤进行修改编辑,如您可在数据来源配置步骤中,为当前解决方案新增同步表或删除已选择的同步表,或者调整独享集成资源组等操作。 |
方案复制 | 单击运维操作列更多中的方案复制按钮,在弹窗中设置新方案的名称信息,单击确定按钮,完成复制。 |
方案解绑 | 解决方案提交后,在 DataLeap 数据开发界面均会生成相应的集成任务。 说明 方案解绑后,无法在解决方案列表中再次恢复,也不能在该列表里进行方案提交执行、编辑、复制、解绑、删除等操作。您可前往数据开发或运维中心界面进行后续维护。 |
方案删除 | 单击运维操作列更多中的方案删除按钮,将处于非运行中、非启动中的方案进行删除,当前仅删除解决方案本身,已生成的表和集成任务不会被删除。 |
运行监控 | 单击运维操作列更多中的运行监控按钮,为当前实时分库分表同步方案配置一次性全量、实时增量任务的运行监控。 |
强制重启 | 单击运维操作列更多中的强制重启按钮,将之前创建的解决方案再次提交执行,区别于提交执行,强制重启会位点初始化、全量批任务清理、重启全量批任务等操作。 |
提交停止 | 单击运维操作列更多中的提交停止按钮,可将处于正常运行中的增量流任务进行停止操作。 |
操作历史 | 单击运维操作列更多中的操作历史按钮,您可查看当前同步方案的操作历史情况,如创建方案、重启方案、提交停止等操作,均会记录在操作历史中。您可单击操作列中的查看详情按钮,对历史版本的操作进行查看。 |
10 更多材料
其余关于 DataSail 更多内容,详见全域数据集成-火山引擎、实时整库同步(新版)等。