1 概述
EMR Spark 任务适用于使用 Java\Python Spark 处理数据的场景,支持引用 Jar 资源包、TOS 资源文件和 Python 语句的方式来定时执行 EMR Spark 任务。
2 使用前提
- 已创建 EMR Hadoop 集群实例。详见创建集群。
- 若仅开通 DataLeap 版本中湖仓一体的服务,项目不支持绑定 EMR 引擎。详见DataLeap 公有云版本功能差异。
- 已在 DataLeap 租户控制台中,绑定相应的 EMR Hadoop 集群实例。详见绑定 Hadoop 集群。
- 在 DataLeap 项目控制台中,绑定 EMR Hadoop 集群实例。详见创建项目。
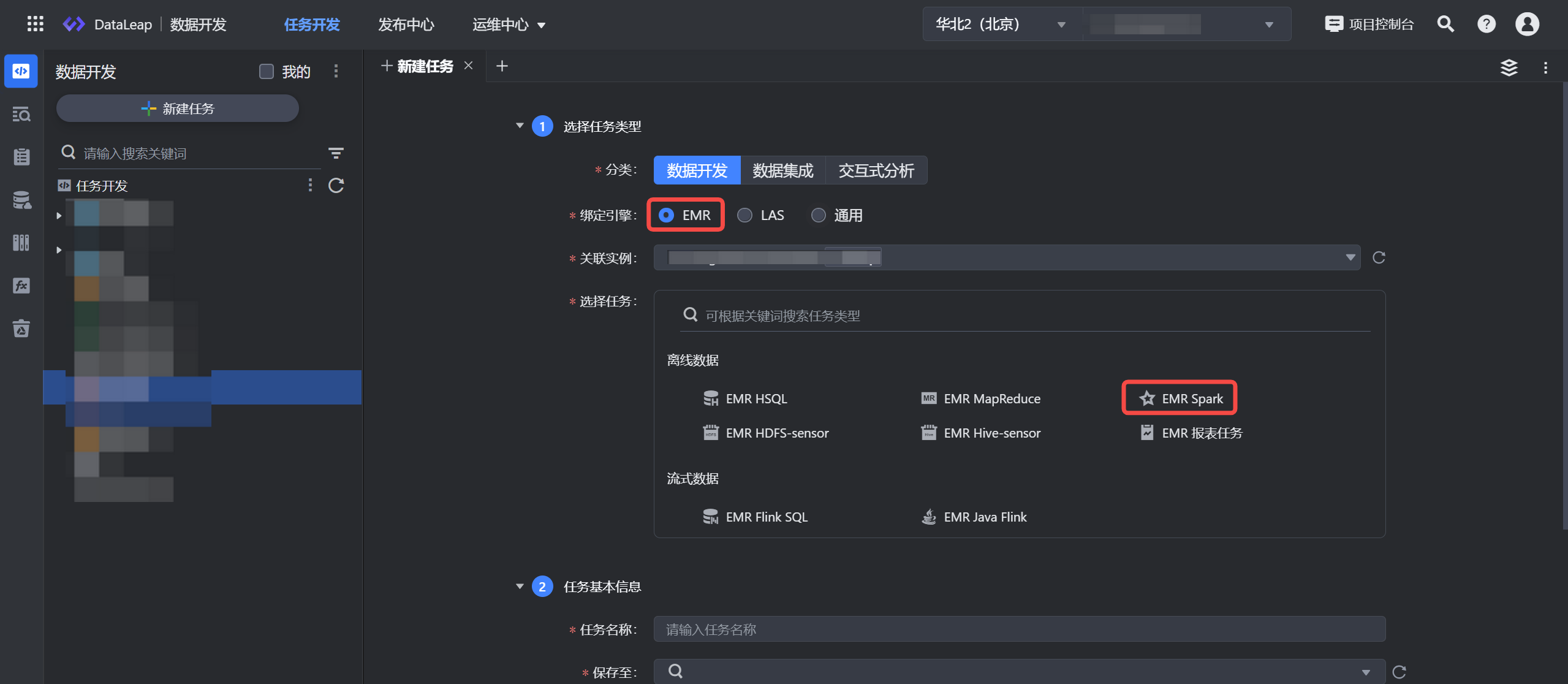
3 新建任务
- 登录 DataLeap租户控制台。
- 在概览界面,显示加入的项目中,单击数据开发进入对应项目。
- 在任务开发界面,左侧导航栏中,单击新建任务按钮,进入新建任务页面。
- 选择任务类型:
- 分类:数据开发。
- 绑定引擎:EMR。
- 关联实例:显示项目绑定时的集群实例信息。
- 选择任务:离线数据 EMR Spark 。
- 填写任务基本信息:
- 任务名称:输入任务的名称,只允许字符.、字母、数字、下划线、连字符、[]、【】、()、()以及中文字符,且需要在127个字符以内。
- 保存至:选择任务存放的目标文件夹目录。
- 单击确定按钮,成功创建任务。
4 任务配置说明
新建任务完成后,您可在任务配置界面完成以下参数配置:
4.1 语言设置
语言类型支持 Java、Python。
注意
语言类型暂不支持互相转换,切换语言类型会清空当前配置,需谨慎切换。
4.2 引入资源
- 语言类型选择 Java 时,资源类型支持 Jar 资源包、TOS 资源文件的形式,可以按以下方式选择资源:
- 语言类型选择 Python 时:
- 资源类型默认选择 Python 类型。
- 在编辑器中输入 Python 语句,执行引擎只支持 Python3.7。
注意
设置系统环境变量时,避免直接覆盖系统环境变量,请按照追加方式指定,例如
PATH=$PATH:/home/lihua/apps/bin/;
4.3 参数配置
参数 | 说明 |
|---|---|
Spark 参数 | |
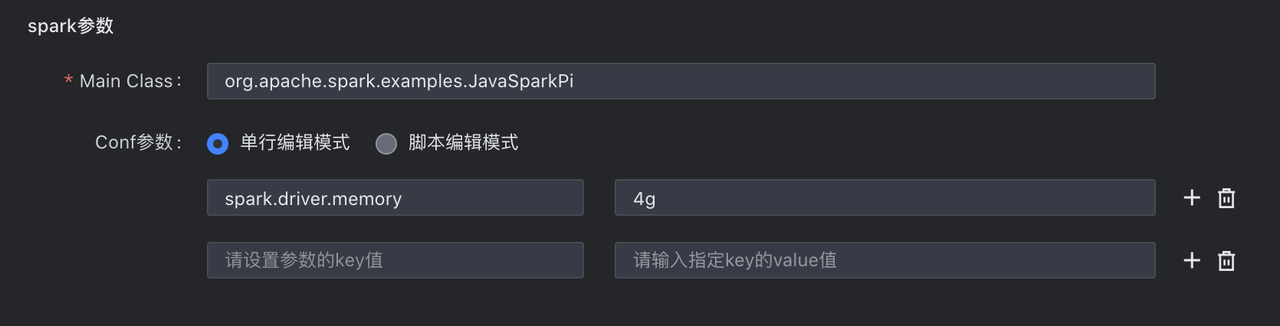
Main Class | 语言类型为 Java 时填写,需填写主类信息,如 org.apache.spark.examples.JavaSparkPi。 |
Conf参数 | 配置任务中需设置的一些 conf 参数,例如您可通过
您可通过以下两种方式来进行配置:
|
任务参数 | |
自定义参数 | 输入任务中已定义的参数,多个参数以空格形式进行分隔,例如 param1 param2 param3,参数最终将以字符串形式传入。 |
4.4 任务产出登记
任务产出数据登记,用于记录任务---数据血缘信息,并不会对代码逻辑造成影响。对于系统无法通过解析获取产出信息的任务,可手动登记其产出信息。
如果任务含有 Hive 表或者 HDFS 目录的写入操作,强烈建议填写。您填写的内容即为任务产出,支持填写多个。其他任务的依赖推荐会根据此处填写的 Hive 表或者 HDFS 目录进行推荐。 具体登记内容包括:
- HDFS:该任务会写数据到 HDFS 目录,请填写 HDFS 路径名,路径名可以使用变量。
- Hive:该任务会写数据到 Hive 表,请填写Hive 库、表名、分区名,分区内容可以使用变量。
- 其他:该任务不写数据到 Hive 表或 HDFS 目录。
5 调度设置
任务配置完成后,在右侧导航栏中,单击调度配置按钮,进入调度配置窗口,您可以在此设置调度属性、依赖等信息,详细参数设置详见:调度设置。
6 使用示例
以下示例将为您演示如何通过 EMR Spark 任务中 Python 语言方式,来直接访问 EMR Hive 表中的数据。
6.1 数据准备
- 新建 EMR HSQL 作业,操作详见:EMR HSQL。
- 在代码编辑区,编辑并执行以下示例语句,创建 EMR Hive 示例表,并将数据写入表中:
CREATE TABLE ods.student_demo ( id STRING COMMENT 'id', name STRING COMMENT 'name', age STRING COMMENT 'age' ) PARTITIONED BY (dt STRING COMMENT 'date'); INSERT INTO ods.student_demo PARTITION (dt = '20230518') VALUES(1, 'TOM', 10);
6.2 配置 EMR Spark 任务
- 新建 EMR Spark 任务,详见上方新建任务。
- 进入任务配置界面,语言类型选择 Python,引入资源类型选择 Python。
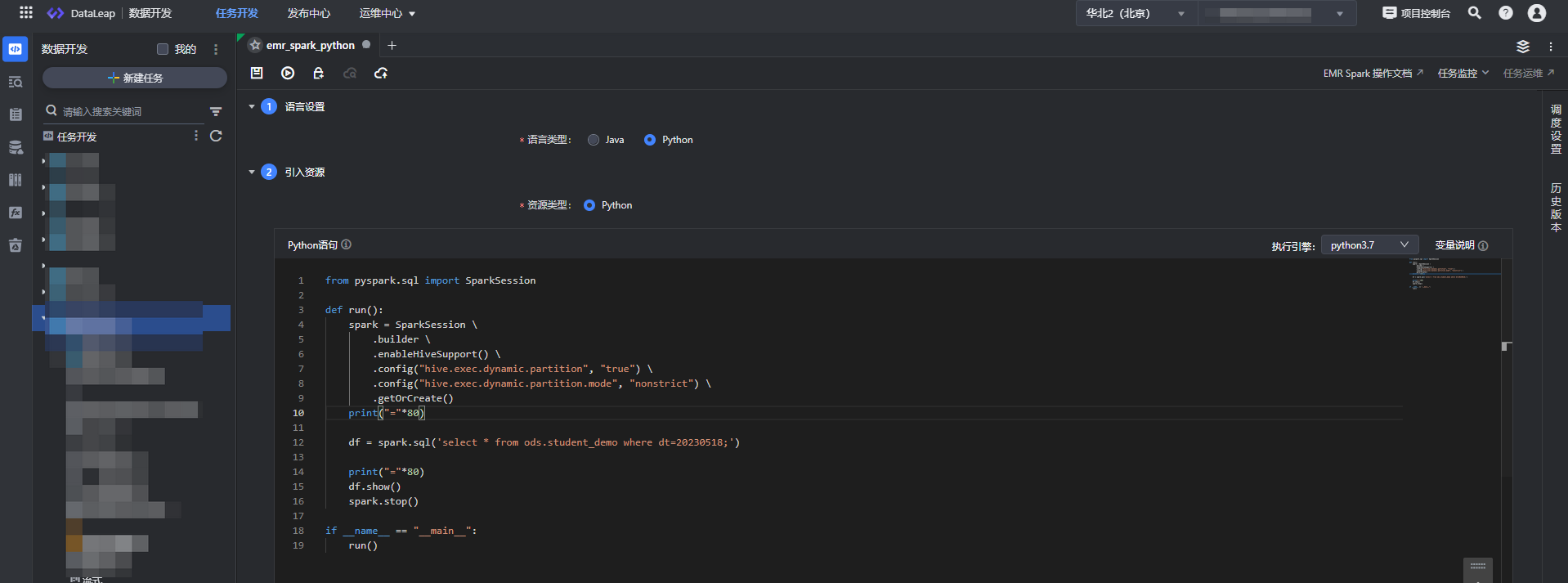
- 在代码编辑区域,编辑以下相关 Python 查询语句:
from pyspark.sql import SparkSession def run(): spark = SparkSession \ .builder \ .enableHiveSupport() \ .config("hive.exec.dynamic.partition", "true") \ .config("hive.exec.dynamic.partition.mode", "nonstrict") \ .getOrCreate() print("="*80) df = spark.sql('select * from ods.student_demo where dt=20230518;') print("="*80) df.show() spark.stop() if __name__ == "__main__": run()
6.3 调试运行
任务配置完成后,您可单击操作栏中的保存和调试按钮,进行任务调试。
注意
- 调试操作,直接使用线上数据进行调试,需谨慎操作。
- 本任务类型支持调试执行成功或失败后发送消息通知,您可根据业务情况,前往项目控制台 > 配置信息 > 消息通知设置中,选择是否开启任务调试运行成功或失败通知。
- 默认通知方式为邮箱,您需在“账号管理”中,提前绑定相应的安全邮箱信息;
- 您也可根据业务需要,自行配置飞书应用机器人,通过飞书的方式发送消息通知,飞书消息通知前置操作详见1.1 飞书应用机器人创建。
6.4 查看日志
待任务执行成功后,您可在结果页概览界面,单击 TrackingURL 链接,前往 Yarn UI 日志界面,查看任务执行结果。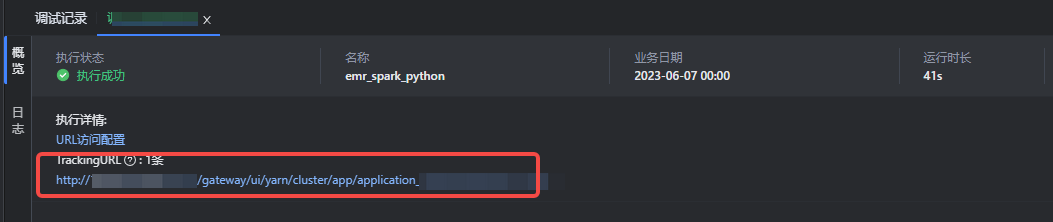
说明
登录 Yarn UI 界面,您需要先获取 Yarn UI 界面登录所需的账号信息,获取方式详见用户管理。
获取登录账号信息后,登录 Yarn UI 界面,单击 Logs,进入查看任务执行结果。
7 提交任务
调试任务成功,并查看日志校验数据情况无误后,返回数据开发界面,将任务提交发布到运维中心离线任务运维中执行。
单击上方操作栏中的保存和提交上线按钮,在提交上线对话框中,选择回溯数据、监控设置、提交设置等参数,最后单击确认按钮,完成作业提交。 提交上线说明详见:数据开发概述---离线任务提交。
后续任务运维操作详见:离线任务运维。