在数据开发过程中,因实际业务通常需要引用函数来完成部分场景的计算需求。平台提供了函数库,支持函数的查询、显示、引用、自定义创建等操作。
1 概述
函数库页面展示数据分为两部分:公共函数以及自定义函数,支持引擎类型详情如下:
引擎类型 | 公共函数 | 自定义函数 |
|---|---|---|
E-MapReduce(EMR)Hadoop | 支持(离线) | 支持 |
EMR Serverless Spark、EMR Serverless Presto | 支持(离线) | 不支持 |
湖仓一体分析服务 (LAS) | 支持(离线、实时) | 支持 |
流式计算 Flink 版(Serverless Flink) | 不支持 | 支持 |
ByteHouse 云数仓版 | 支持(离线) | 不支持 |
- 公共函数:各引擎提供内置开箱即用的公共函数,覆盖日常数据清洗计算、分析等场景,无需自定义上传 JAR 包,便可直接进行调用。
- LAS 公共函数:函数说明文档
- EMR 公共函数:函数说明文档
- ByteHouse 云数仓版公共函数:ByteHouse 云数仓版函数文档
- 自定义函数:如果引擎提供的内置公共函数无法满足您的业务场景实践,您可在 JAR/File/Zip 等资源包上传后,通过自定义函数的方式,创建 UDF(用户定义函数)、UDTF(用户定义表生成函数)、UDAF(用户定义聚合函数) 等函数类型。
2 使用限制
- DataLeap 产品需开通 DataOps敏捷研发、大数据分析、数据开发特惠版或分布式数据自治 服务后,才可绑定 EMR、流式计算 Flink 引擎。
服务开通操作详见:开通服务;绑定引擎操作详见:创建项目。 - EMR Doris、EMR StarRocks、EMR Serverless Spark/Presto、EMR Serverless Presto、ByteHouse 云数仓版集群类型,不支持自定义创建函数。
3 使用前提
自定义函数创建时您需要先上传资源,通过引用资源,才可以创建和使用自定义函数。资源上传方式详见资源库。
4 功能介绍
资源库中上传指定引擎下的资源后,便可进行可视化创建自定义函数。
4.1 新建自定义函数
登录 DataLeap租户控制台。
进入具体的数据开发项目,并在左侧导航栏单击函数库进入。
在自定义函数区,您可任意通过以下几种方式来新建函数:
您也可以在创建自定义函数前,先新建子目录文件夹,通过不同子目录来分类管理不同的函数。进入函数库,在自定义函数部分单击 + ,进入新建函数页面,根据不同绑定引擎创建函数:
参数
说明
绑定引擎
支持选择 LAS、EMR、流式计算 Flink 版。
关联实例
不同引擎绑定关联对应的实例:
- LAS 引擎:默认关联 default 实例。
- EMR(Hadoop) 引擎:默认关联项目绑定时的 EMR 实例。
- 流式计算 Flink 引擎:默认关联项目绑定时的流式计算 Flink 实例。
保存至
函数保存的文件目录。
函数名称
输入函数名称,只允许由2-60个字符以内的数字、字母和_组成,并且以字母开头。
函数类名
定义函数的类名。
函数描述
输入函数描述内容,方便后续管理。
函数类型
- LAS 引擎:
- 离线数据类型:仅支持 UDF(用户定义函数)类型。
- 流式数据类型:支持 UDF(用户定义函数)、UDTF(用户定义表生成函数)、UDAF(用户定义聚合函数) 三种类型
- EMR(Hadoop)**、**流式计算 Flink 引擎支持 UDF(用户定义函数)、UDTF(用户定义表生成函数)、UDAF(用户定义聚合函数) 三种类型。
资源
下拉选择已创建的自定义函数,仅支持选择 Jar 资源。新建资源操作详见:资源库。
输入参数
函数输入的参数类型说明。
输出参数
函数输出的参数类型说明。
使用案例
函数使用例子,方便其他用户在使用函数时,知道如何去使用。
数据类型
- LAS/EMR 引擎支持流式、离线函数处理的数据类型。
- 流式计算 Flink 引擎仅支持流式函数处理的数据类型。
参数填写完成后,单击确定按钮,即创建函数成功。
注意
EMR 引擎类型的函数创建成功后,您需前往 EMR 控制台 > 集群详情 > 服务列表 > Hive 服务中,重启 HiveServer2 组件服务,使函数生效。
或者您也可以通过在 EMR Hadoop 集群的 Hive 组件下 hive-site.xml 文件里,设置自定义参数hive.allow.udf.load.on.demand=true;并重启 HiveServer2 组件服务,后续您新建的函数,便可以不用重启 HiveServer2 组件。您可在公共函数或自定义函数区,预览内置以及新创建的函数示例。
4.2 查找函数
- 进入函数库页面。
- 引擎选择框中,下拉选择 EMR、EMR Serverless Spark、EMR Serverless Presto、LAS、流式计算 Flink 版、ByteHouse 云数仓版 等引擎类型及实例类型,例如引擎类型选择 EMR,实例类型选择 emr-xxx。
- 选择离线/实时的数据类型,输入函数名称关键字进行搜索,搜索结果按照公共函数及自定义函数分类显示。
说明
ByteHouse 云数仓版、EMR Serverless Spark/Presto 引擎类型,仅支持离线公共函数类型查看。
4.3 引用函数
- 鼠标悬停到自定义函数名称时可显示函数详情,具体信息包括:
- EMR引擎函数:显示函数名、使用示例等。
- LAS、流式计算 Flink引擎函数:显示函数类名、描述、使用示例、最近修改时间等信息。
- 引用函数
- 先在任务开发 > 数据开发界面,打开任务编辑器界面,
- 切换到函数库,函数名称右侧单击引用函数按钮,将直接在编辑器内插入引用函数语句。下面以流式计算 Flink 版的实时函数引用为例:
- 任务中引用函数后,便可在自定义函数右侧边栏的引用记录中,查看引用任务和引用模板。
您可以看到已使用该函数的任务、模板详情,包括任务ID、任务名称、模板名称和责任人,您可以在搜索框中,根据任务名、模板名或责任人来搜索相关引用的任务。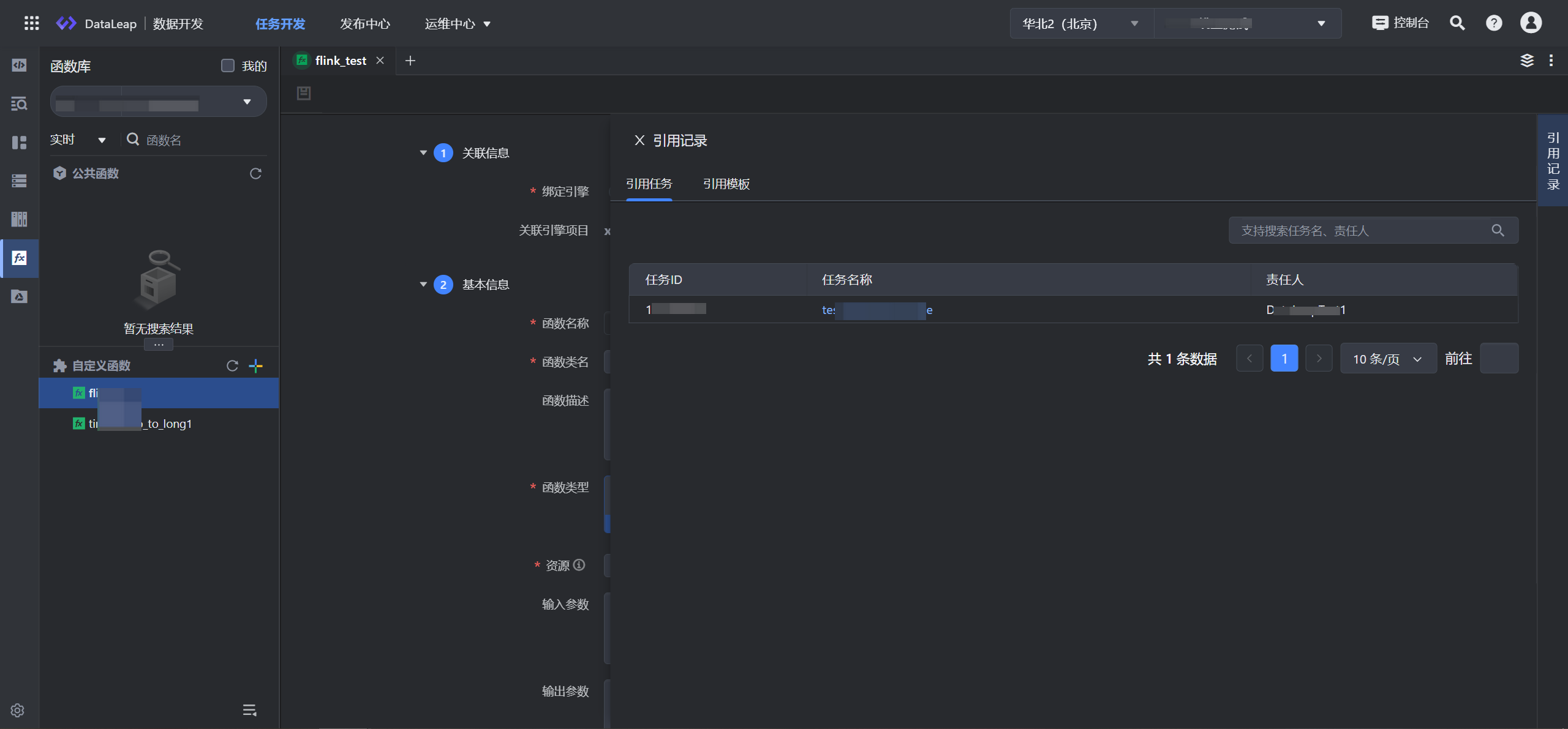
4.4 编辑自定义函数
项目成员在自定义函数库列表,单击函数名称,进入编辑界面 ,可以修改自定义函数的配置信息包括:
资源绑定引擎类型 | 可修改参数 | 说明 |
|---|---|---|
LAS、EMR、流式计算 Flink | 函数类名 | 您可以修改定义函数的类名。 |
函数描述 | 可修改资源描述说明,方便后续的管理。 | |
函数类型 |
| |
资源 | 可修改引用的资源文件。 | |
输入参数 | 可修改函数输入的参数类型说明。 | |
输出参数 | 可修改函数输出的参数类型说明。 | |
使用案例 | 支持使用案例的修改更新。 |
4.5 删除函数
在自定义函数列表中,单击函数名称 > 右侧 更多操作 > 单击 删除,在删除弹窗中单击删除按钮,即可删除函数。
注意
若该函数已被某个已上线的任务使用,则需要先下线任务,再删除函数。
4.6 移动函数
单击函数名称 > 右侧 更多操作 > 单击移动,可以移动函数至当前项目内当前引擎下的其他目录。