Doris 是一个现代化的 MPP 分析型数据库产品,DataSail 中 Doris 数据源支持您通过配置数据集成同步任务方式,来读取或写入火山引擎 E-MapReduce(EMR)Doris 集群数据库中的数据,为您提供双向通道能力,实现不同数据源中的数据与 Doris之间进行数据传输。
本文为您介绍 DataSail 的 Doris 数据同步能力支持情况。
1 支持的版本
- Doris Writer 使用的驱动版本是 MySQL Driver 5.1.49,该驱动支持的内核版本为 Doris 1.2.X。驱动能力详情请参见Doris官网文档。
- Doris 数据源支持写入 EMR-3.2.0 及以上版本 Doris 集群和 OLAP 服务中 1.1.0 及以上版本全托管 Doris 引擎。
2 使用前提
- 子账号新建数据源时,需要有项目的管理员角色,方可以进行新建数据源操作。各角色对应权限说明,详见:管理成员。
- Doris 数据源配置时,EMR 集群对应的集群实例 ID 信息、数据库用户名密码需填写正确,Doris 集群操作详见 Doris 基础使用。
注意
- 填写的数据库用户名信息,必须拥有相应数据库表的读写权限,来保障任务数据能够被正常读取或写入 Doris 中。
- 必须有账户密码信息,其中 root 账户无密码,不符合安全规范,数据源配置时无法使用。
- EMR Doris 集群和独享集成资源组中的 VPC 必须一致,其 VPC 下的子网和安全组也尽可能保持一致。
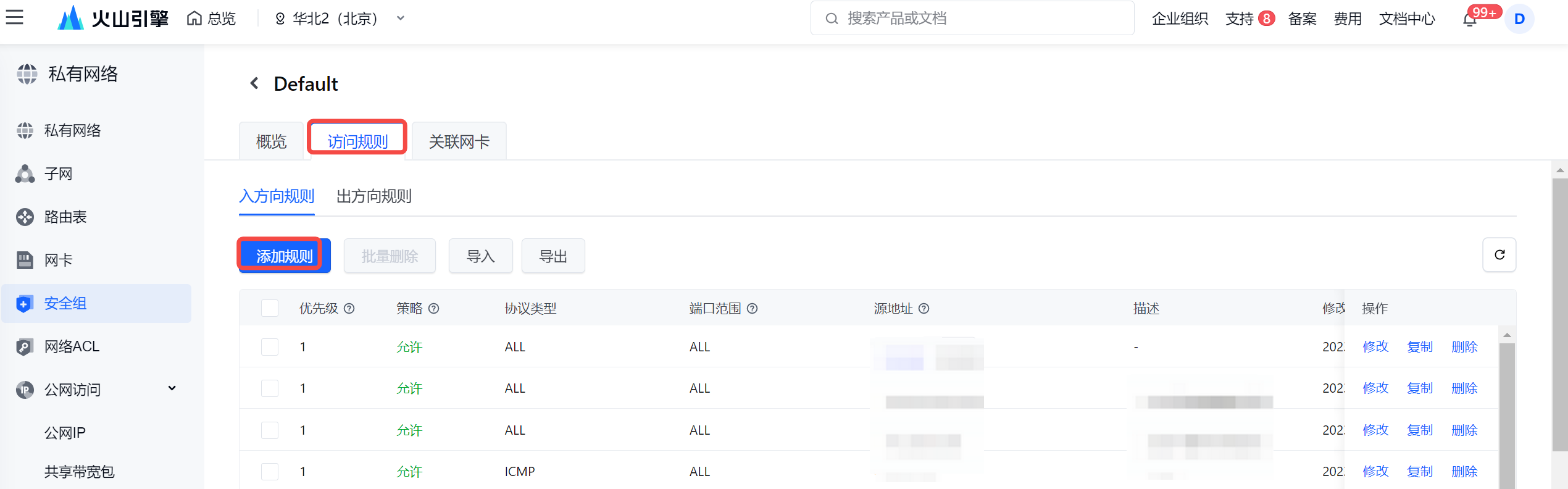
- 若子网和安全组不一致时,则需要在 Doris 集群的安全组上,在入方向规则处,添加独享集成资源组子网的 IP 网段:
- 在 EMR Doris 集群详情界面,进入集群所在的安全组,并添加入方向规则。
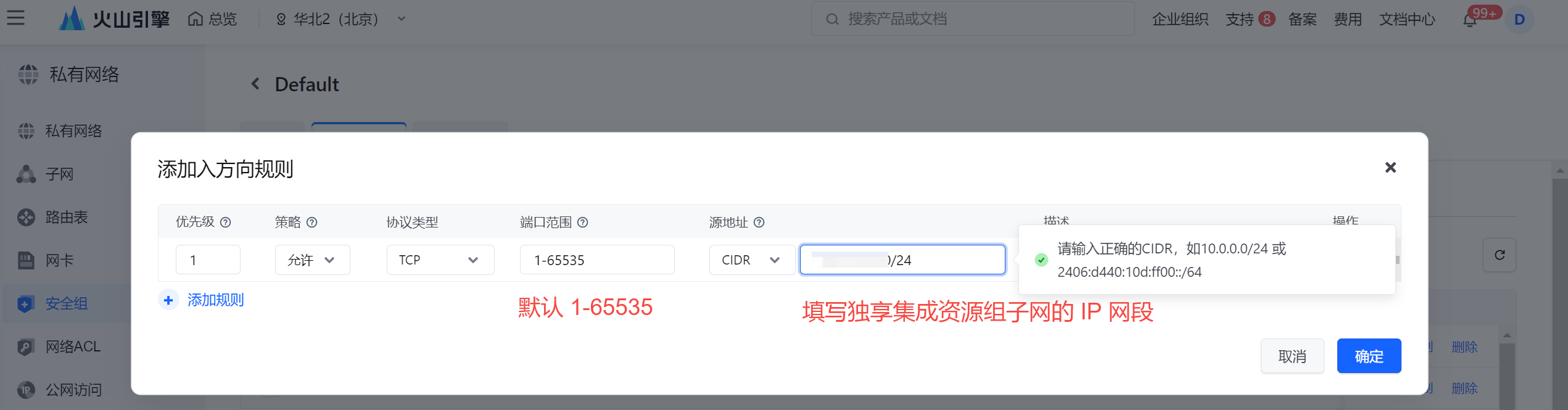
- 在弹窗中,填写独享集成资源组绑定子网的 IPv4 CIDR 网段:
- 在 EMR Doris 集群详情界面,进入集群所在的安全组,并添加入方向规则。
- 若子网和安全组不一致时,则需要在 Doris 集群的安全组上,在入方向规则处,添加独享集成资源组子网的 IP 网段:
3 支持的字段类型
类型 | 支持模型 | Doris版本 | 离线写入 |
|---|---|---|---|
SMALLINT | Aggregate,Unique,Duplicate | 1.2.x | 支持 |
INT | Aggregate,Unique,Duplicate | 1.2.x | 支持 |
BIGINT | Aggregate,Unique,Duplicate | 1.2.x | 支持 |
LARGEINT | Aggregate,Unique,Duplicate | 1.2.x | 支持 |
FLOAT | Aggregate,Unique,Duplicate | 1.2.x | 支持 |
DOUBLE | Aggregate,Unique,Duplicate | 1.2.x | 支持 |
DECIMAL | Aggregate,Unique,Duplicate | 1.2.x | 支持 |
DECIMALV2 | Aggregate,Unique,Duplicate | 1.2.x | 支持 |
DECIMALV3 | Aggregate,Unique,Duplicate | 1.2.x | 支持 |
DATE | Aggregate,Unique,Duplicate | 1.2.x | 支持 |
DATETIME | Aggregate,Unique,Duplicate | 1.2.x | 支持 |
DATEV2 | Aggregate,Unique,Duplicate | 1.2.x | 支持 |
DATATIMEV2 | Aggregate,Unique,Duplicate | 1.2.x | 支持 |
CHAR | Aggregate,Unique,Duplicate | 1.2.x | 支持 |
VARCHAR | Aggregate,Unique,Duplicate | 1.2.x | 支持 |
STRING | Aggregate,Unique,Duplicate | 1.2.x | 支持 |
VARCHAR | Aggregate,Unique,Duplicate | 1.2.x | 支持 |
ARRAY | Duplicate | 1.2.x | 支持 |
JSONB | Aggregate,Unique,Duplicate | 1.2.x | 支持 |
4 数据同步任务开发
下文将为您介绍 Doris 数据集成同步任务的配置流程:
4.1 数据源注册
新建数据源操作详见配置数据源,下面为您介绍配置 Doris 数据源相关信息:
参数 | 说明 |
|---|---|
基本配置 | |
数据源类型 | Doris |
接入方式 | 当前支持 EMR Doris、EMR Serverless Doris 两种作为数据源接入。 |
数据源名称 | 数据源的名称,可自行设置,仅支持中文,英文,数字,“_”,100个字符以内。 |
描述 | 对当前新建数据源的注释说明。 |
参数配置 | |
Doris 实例 ID | EMR 中创建的 Doris 集群或 OLAP 服务中全托管 Doris 集群实例 ID。 |
数据库名 | 输入集群中的 Doris 库名称。 |
用户名 | 数据库的账号。 |
密码 | 数据库的密码。 |
4.2 新建任务
Doris 数据源测试连通性成功后,进入到数据开发界面,开始新建 Doris 相关通道任务。
新建任务方式详见离线数据同步、流式数据同步。
4.3 可视化配置说明
任务创建成功后,您可根据实际场景,配置 Doris 离线读写、Doris 流式写等通道任务相关参数:
说明
Doris 流式读暂不支持。
4.3.1 Doris 离线读
数据来源选择 Doris,并完成以下相关参数配置:
其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。
参数 | 说明 |
|---|---|
*数据源类型 | 下拉选择 Doris 数据源类型。 |
*数据源名称 | 已在数据源管理中注册成功的 Doris 数据源,下拉可选。 |
*数据表 | 选择需要采集的数据表名称信息,目前单个任务只支持将单表的数据采集到一个目标表中。 |
数据过滤 | 支持您将需要同步的数据进行筛选条件设置,只同步符合过滤条件的数据,可直接填写关键词 where 后的过滤 SQL 语句,例如:create_time > '${date}',表示只同步 create_time 大于等于 ${date} 的数据,不需要填写 where 关键字。 说明 该过滤语句通常用作增量同步,暂时不支持 limit 关键字过滤,其 SQL 语法需要和选择的数据源类型对应。 |
*切分建 | 根据配置的字段进行数据分片,建议使用主键或有索引的列作为切分键:
说明 目前仅支持类型为整型的字段作为切分建。 |
4.3.2 Doris 离线写
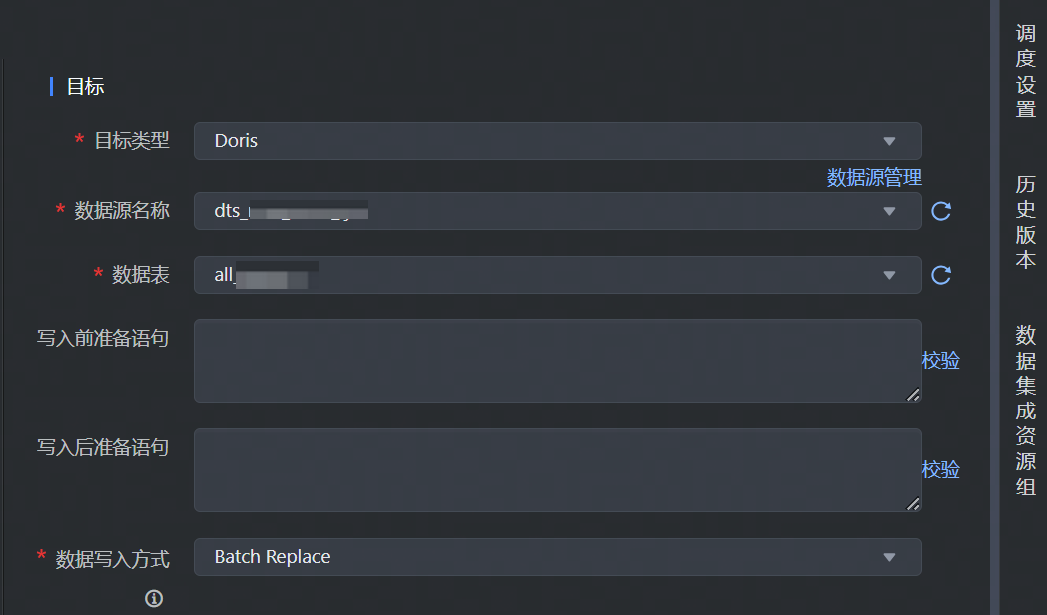
数据目标端选择 Doris,并完成以下相关参数配置:
其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。
参数 | 说明 |
|---|---|
*目标类型 | 数据去向目标类型选择 Doris。 |
*数据源名称 | 已在数据源管理界面注册的 Doris 数据源,下拉可选。 |
*数据表 | 数据源配置的数据库下,选择需数据写入的表名,下拉可选。 |
写入前准备语句 | 在执行该数据集成任务前,需要率先执行的 SQL 语句,通常是为了使任务重跑时支持幂等。 说明 可视化通道任务配置中只允许执行一条写入前准备语句。 |
写入后准备语句 | 执行数据同步任务之后执行的 SQL 语句。例如写入完成后插入某条特殊的数据,标志导入任务执行结束。 说明 可视化通道任务配置中只允许执行一条写入后准备语句。 |
*数据写入方式 | 下拉选择数据写入 Doris 的方式,目前仅支持 Batch Replace 的方式写入。 |
4.3.3 Doris 流式写
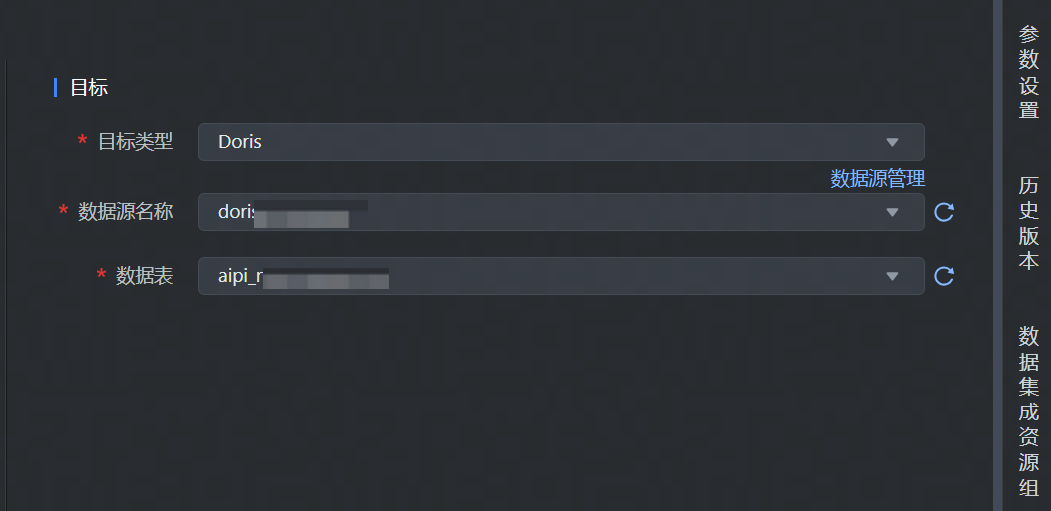
流式数据写入 Doris 集成任务,数据目标端选择 Doris,并完成以下相关参数配置:
其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。
参数 | 说明 |
|---|---|
*目标类型 | 数据去向目标类型选择 Doris。 |
*数据源名称 | 已在数据源管理界面注册的 Doris 数据源,下拉可选。 |
*数据表 | 数据源配置的数据库下,选择需数据写入的表名,下拉可选。 |
4.3.4 字段映射
数据来源和目标端配置完成后,需要指定来源和目标端的字段映射关系,根据字段映射关系,数据集成任务将源端字段中的数据,写入到目标端对应字段中。
您可通过以下三种方式操作字段映射关系:
- 自动添加:单击自动添加按钮,根据两端数据表信息,可以自动填充来源和目标的字段信息。
- 手动添加:单击手动添加按钮,可以手动编辑来源和目标的字段信息,可以逐个添加。
- 移动\删除字段:您也可以根据需要移动字段映射顺序或删除字段。
4.4 DSL 配置说明
Doris 数据源支持使用脚本模式(DSL)的方式进行配置。
在某些复杂场景下,您可通过任务脚本的方式,按照统一的 Json 格式,编写 Doris Writer 参数脚本代码,来运行数据集成任务。
4.4.1 进入 DSL 模式
- 在可视化任务编辑界面,单击上方工具栏切换至脚本模式按钮,进入编辑界面。
说明
切换脚本模式将清空现有可视化界面配置,一旦切换无法撤销。

- 首次使用 DSL 模式配置时,您可通过单击界面导入脚本模板按钮,在模板的基础上,进行相应配置的修改,提升任务配置效率。
 以下分别为您介绍 Doris 数据源写的示例脚本,您可根据实际情况替换相应参数:
以下分别为您介绍 Doris 数据源写的示例脚本,您可根据实际情况替换相应参数:说明
导入新的脚本模版将清空现有内容,一旦导入无法撤销。
4.4.2 Doris 离线写
进入 DSL 模式编辑界面后,您可根据实际情况替换相应参数,Doris 离线写脚本示例如下:
// ************************************** // 变量使用规则如下: // 1.自定义参数变量: {{}}, 比如{{number}} // 2.系统时间变量${}, 比如 ${date}、${hour} // ************************************** { // [required] dsl version, suggest to use latest version "version": "0.2", // [required] execution mode, supoort streaming / batch now "type": "batch", // reader config "reader": { // [required] datasource type "type": "xx", // [optional] datasource id, set it if you have registered datasource "datasource_id": null, // [required] user parameter "parameter": { // ********** please write here ********** // "key" : value } }, // writer config "writer": { // [required] datasource type "type": "doris", // [optional] datasource id, set it if you have registered datasource "datasource_id": null, // [required] user parameter "parameter": { // ********** please write here ********** // "key" : value "partitions": [ { "name": "partition_name_sample", "start_range": [ "start1", "start2" ], "end_range": [ "end1", "end2" ] } ], "columns": [ { "name": "name_sample", "type": "type_sample" } ], "pre_sql":[""], "post_sql":[""], "sink_write_mode": "BATCH_REPLACE", "table_name": "table_name_sample", "password": "password_sample", "db_name": "db_name_sample", "table_model": "PRIMARY/DUPLICATE/UNIQUE/AGGREGATE", "fe_hosts": "x.x.x.x:x,x.x.x.x:x", "class": "com.bytedance.dts.doris.sink.DorisWriterGenerator", "user": "user_sample" } }, // common config "common": { // [required] user parameter "parameter": { // ********** please write here ********** // "key" : value } } }
Writer 参数说明,其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数:
参数名 | 描述 | 默认值 |
|---|---|---|
*type | 数据源类型,对于 Doris 类型,填写:doris | 无 |
*datasource_id | 填写注册的 Doris 数据源 ID。可以在项目控制台 > 数据源管理界面中查找。
| 无 |
*table_name | 填写数据源下所需数据写入的表名。 | 无 |
pre_sql | 写入前准备语句:在执行数据集成任务前,率先执行的 SQL 语句。此语句通常是为了使任务重跑时支持幂等。 说明 DSL 模式支持配置多条写入前准备语句,多条语句之间用英文逗号分隔。 | 无 |
post_sql_list | 写入后准备语句:执行数据同步任务后执行的 SQL 语句。例如数据写入完成后,插入某条特殊的数据,标志导入任务执行结束。 说明 DSL 模式支持配置多条写入前准备语句,多条语句之间用英文逗号分隔。 | 无 |
*sink_write_mode | 数据导入模式,离线写通道支持 BATCH_REPLACE/BATCH_UPSERT 两种模式:
数据导入模式,流式写通道支持 STREAMING_UPSERT 模式:
| 无 |
*columns | 所配置的表中需要同步的列名集合,使用 JSON 的数组描述字段信息。
注意
| 无 |
partitions | 指定写入的 Doris 分区,格式如下(可含有多个分区):
参数代表意义:
| 无 |
table_model | 支持如下四种表类型:AGGREGATE/UNIQUE/PRIMARY/DUPLICATE | Doris 表数据模型(建表时指定) |
*fe_hosts | Doris FE 连接串,可从 EMR Doris 集群详情 > 服务列表 > 部署拓扑中获取,格式:host1:port,host2:port,host3:port | 无 |
*class | Doris writer connector type,默认固定值填写:com.bytedance.dts.doris.sink.DorisWriterGenerator | com.bytedance.dts.doris.sink.DorisWriterGenerator |
*db_name | 输入需要写入的数据库名称。 | 无 |
*user | 输入登录 Doris 数据库的用户名信息。 | 无 |
*password | 登录 Doris 数据库用户名对应的密码。 | 无 |
4.5 高级参数说明
- 对于可视化通道任务,配置到自定义参数设置中,写参数需要加上
job.writer.前缀,如下图所示: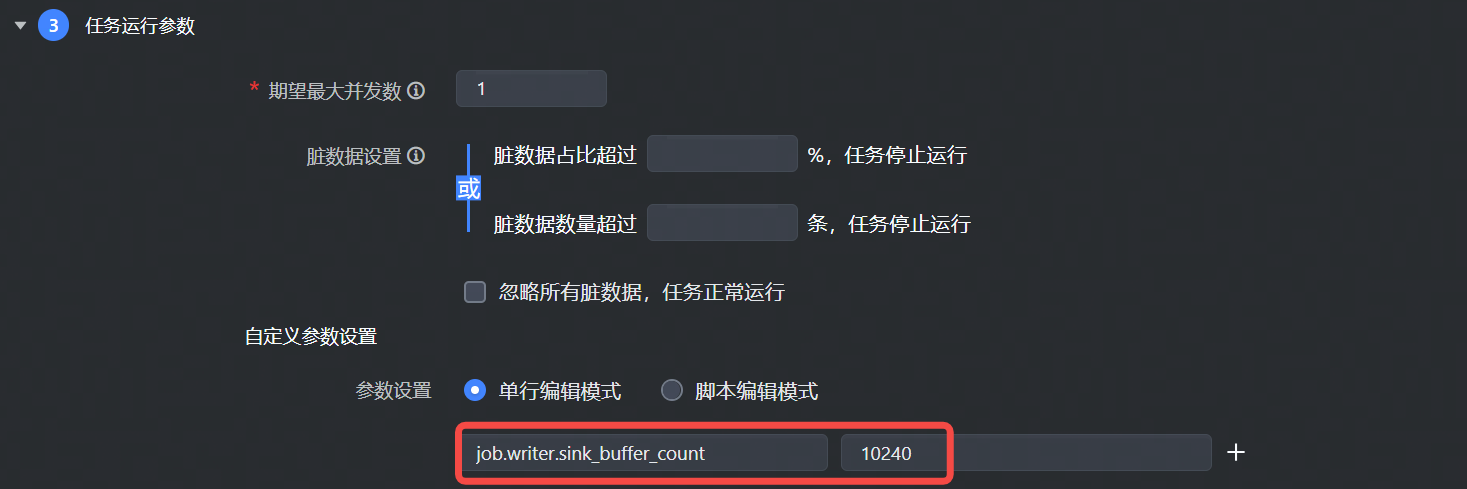
- 对于 DSL 任务,写参数请配置到
writer.parameter下,直接输入参数名称和参数值。如下图所示: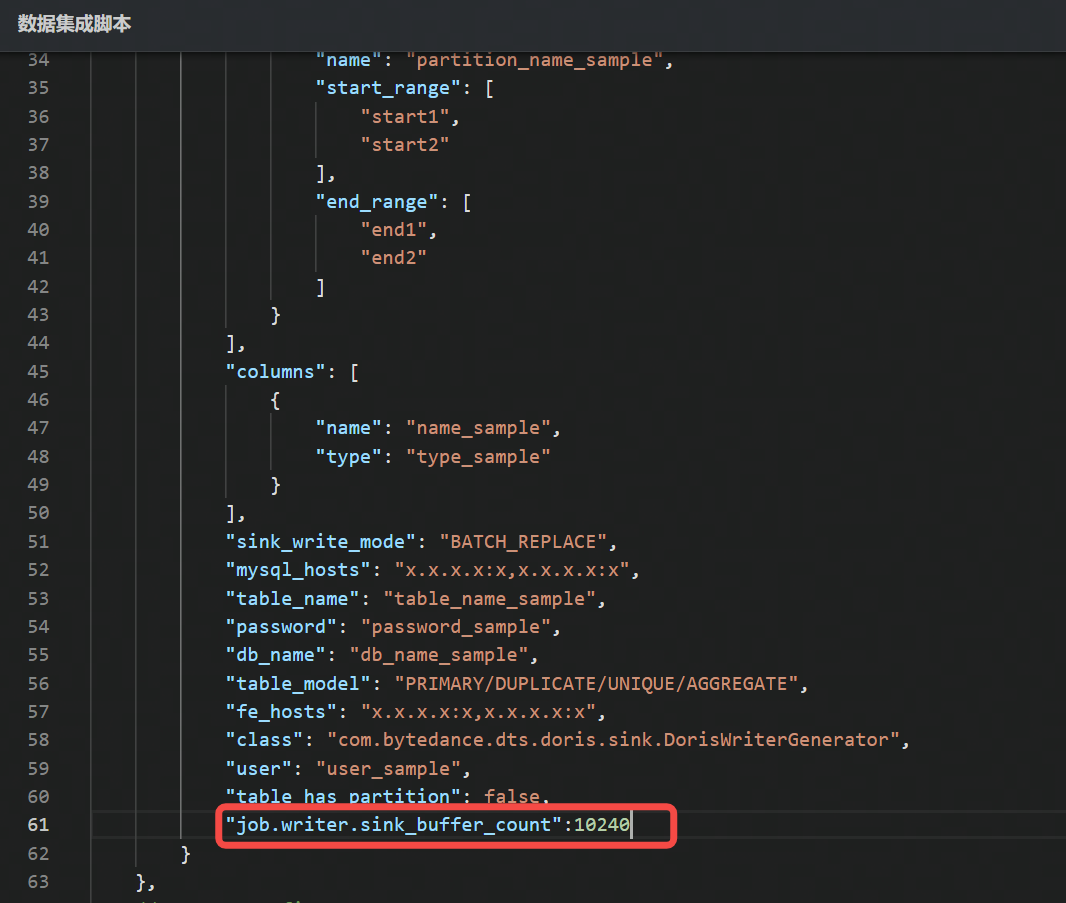
4.5.1 Doris 写入高级参数(可选配置)
支持以下高级参数,您可根据实际情况进行配置:
参数名 | 描述 | 默认值 |
|---|---|---|
job.writer.sink_buffer_size | 单次 stream load 的数据量上限,和 sink_buffer_count 之中其一满足条件即开始导入数据。 | 离线模式:256 * 1024 * 1024 |
job.writer.sink_buffer_count | 单次 stream load 的数据条数上限,和 sink_buffer_size 之中其一满足条件即开始导入数据。 | 8192 |
job.writer.sink_flush_interval_ms | 流式模式下,每次强制导入数据的时间间隔,单位:ms | 60s |