1 概述
DataLeap 接入流式计算 Flink 版,在关联 Flink 的项目和资源池后,可以进行 Java Flink Batch 离线作业开发,实现对海量历史数据进行复杂的离线统计分析与处理。
本文将为您介绍 Java Flink Batch 作业相关的开发流程操作。
2 使用前提
- DataLeap产品需开通 DataOps敏捷研发、大数据分析、数据开发特惠版或分布式数据自治服务后,才可绑定流式计算 Flink 引擎。绑定引擎操作详见:项目管理。
- 子账号操作项目绑定 Flink 引擎实例时:
- 主账号需要先在流式计算 Flink 版控制台导入 IAM 用户。操作详见:用户管理。
- 并将子账号加入到对应引擎项目中。操作详见:引擎项目成员管理。
3 任务配置说明
3.1 新建任务
- 登录 DataLeap租户控制台。
- 在概览界面,显示加入的项目中,单击数据开发进入对应项目。
- 在任务开发界面,左侧导航栏中,单击新建任务按钮,进入新建任务页面。
- 选择任务类型:
- 分类:数据开发。
- 绑定引擎:流式计算 Flink 版。
- 关联引擎项目:默认选择引擎绑定时选择的引擎项目,不可更改。
- 选择任务:离线数据 Java Flink Batch。
- 填写任务基本信息:
- 任务名称:输入任务的名称,只能由数字、字母、下划线、-和.组成, 首尾只能是数字、字母,且允许输入 1~63 个字符。
- 保存至: 选择任务存放的目标文件夹目录。
- 单击确认按钮,成功创建任务。
3.2 引用资源
通过下列参数设置资源 Jar 包:
- 选择 Jar 包可通过以下方式选择资源:
- 资源库中选取已创建的流式计算 Flink 版资源。
- 直接在下拉框中新建资源,或在左侧导航栏资源库中新建流式计算 Flink 资源,详见:资源库操作。
- 执行引擎:执行引擎目前支持选择 Flink 1.16、Flink 1.17 版本。
说明
目前 Flink 1.17 执行引擎版本,仅通过白名单形式放开,您可通过提工单的方式,咨询 DataLeap 支持同学加白后进行使用。
- Main Class:填写 Jar 包程序的主类,例如:com.bytedance.openplatform.datastream.DatagenToPrint。
3.3 Flink运行参数
填写 Flink 相关的动态参数和执行参数,平台已为您提供一些常用的 SQL 参数、State 参数、Runtime 参数等,您可以根据实际情况进行选择,或者自行输入所需参数。更多参数详见 Flink 官方文档。
说明
平台提供的常用参数,您需要事先在引用资源中,设置相应的执行引擎版本后,方能提示在下拉框中。
- 单行编辑模式:填写 key-value,key值只允许字母、数字、小数点、下划线和连字符。
a. 添加一行参数
b. 删除当前这行参数
c. 清空输入框中已输入的参数值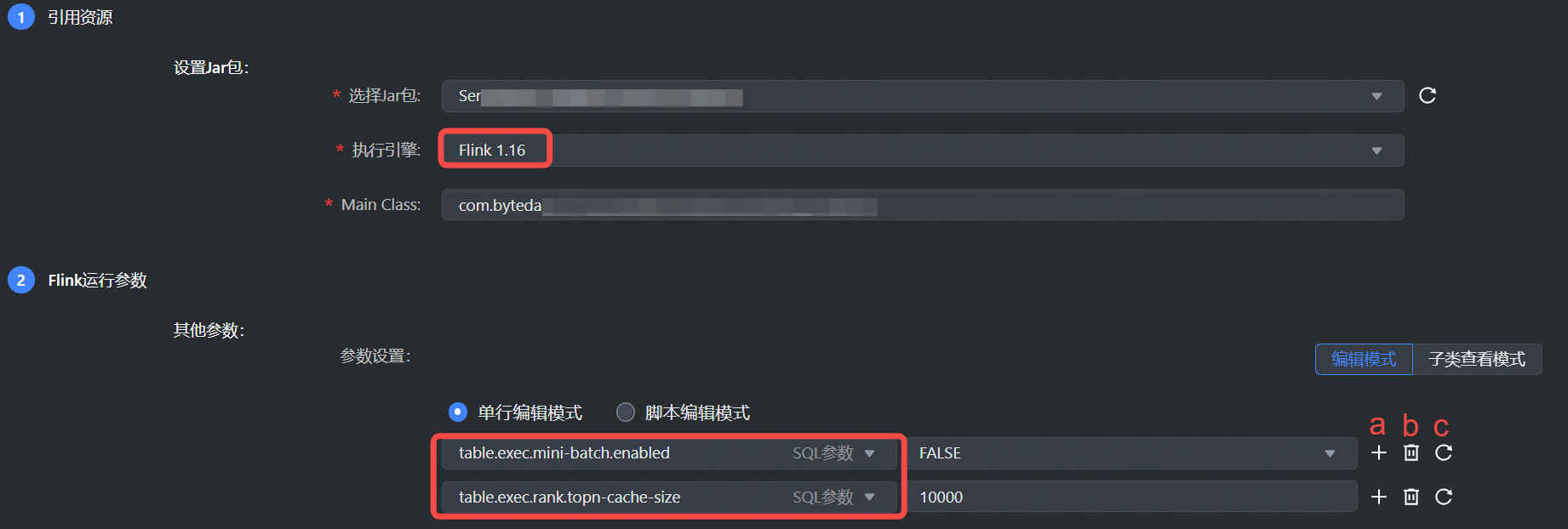
- 脚本编辑模式:通过 JSON、Yaml 的格式填写运行参数。
- 子类查看模式:您通过上方编辑模式输入参数后,可单击子类查看模式,支持将添加的参数自动做分类,帮助您在众多参数下,能更方便了解输入的 Flink 参数。
说明
- 可在对应分类下,按照关键词搜索需要使用的参数。
- 若在指定分类下,无法搜索到对应参数,可在“其它参数”类别,自行进行输入。
- 填写在“其它参数”类别下的参数,若隶属于“SQL参数/State参数/Runtime参数”类别,完成编辑后,系统会将其归属到对应分类。
3.4 用户自定义参数
用户自定义参数,可填写数据来源端相关实例参数信息,例如 kafka 消息队列接入时,需要填写 Topic、接入点地址等参数信息;也可填写任务执行资源配置或处理数据时间等相关参数。
- 单行编辑模式:填写 key-value,key 值只允许字母、数字、小数点、下划线和连字符。
- 脚本编辑模式:通过 JSON、Yaml 的格式填写运行参数。
3.5 调度设置
任务配置完成后,在右侧导航栏中,单击调度配置按钮,进入调度配置窗口,您可以在此设置任务基本信息、调度属性、依赖、任务输入输出等信息,详细参数设置详见:调度设置。
3.5.1 高级参数
其中 Java Flink Batch 任务,支持在调度属性参数中设置高级参数, 您可在此输入 Flink 任务中所需用到的参数,支持以下两种添加方式:
- 单行编辑模式:填写 key-value,key值只允许字母、数字、小数点、下划线和连字符。
- 添加一行参数
- 删除当前这行参数
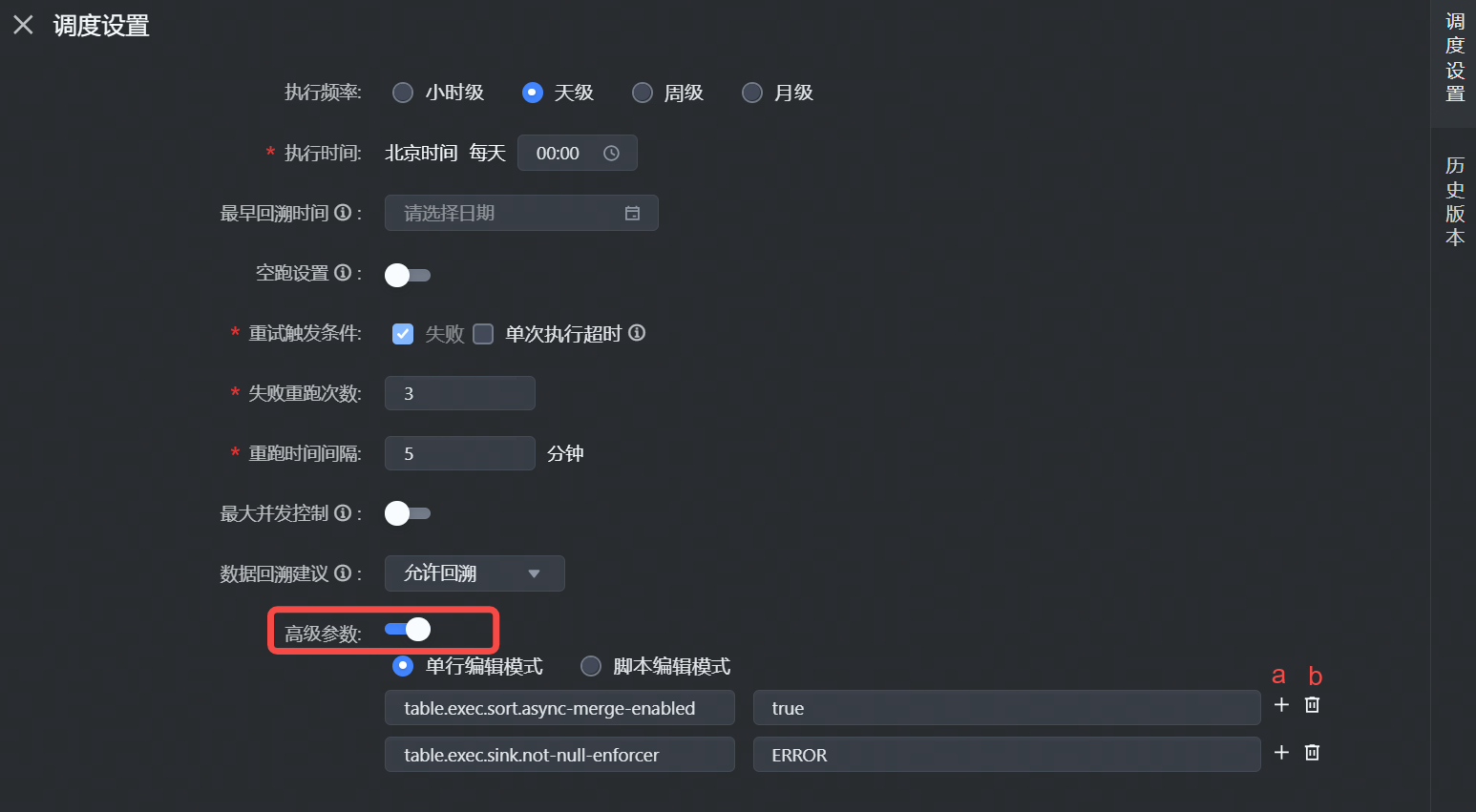
- 脚本编辑模式:通过 JSON、Yaml 的格式填写运行参数。
高级参数说明详见 Flink 参数配置文档。
3.4.2 依赖关系
您可在此配置离线任务的上下游依赖关系,完成数据血缘构建,以此保障下游执行时,能够准确获取到上游产出的数据,确保数据质量,提升数据开发效率。
上下游依赖配置操作详见任务调度依赖。
3.4.3 输入输出参数
在设置任务上游依赖后,您可通过设置任务的输入输出参数,可实现参数在上游和下游任务之间进行传递,该参数的内容值,可来源于上游任务的输出结果、项目参数或是自定义参数值。
输入输出参数操作详见输入输出参数设置。
3.4.4 资源设置
设置任务运行时相关资源分配情况:
参数名称 | 描述 |
|---|---|
TaskManager个数 | 设置 flink 作业中 TaskManager 的数量。 |
单TaskManagerCPU数 | 设置单个 TaskManager 所占用的CPU数量。 |
单TaskManager内存大小(MB) | 设置单个 TaskManager 所占用的内存大小。 |
单TaskManager slot数 | 设置单个 TaskManager 中slot的数量。 |
JobManager CPU数 | 设置单个 JobManager 所占用的CPU数量。 |
JobManager内存 | 设置单个 JobManager 所占用的内存大小。 |
4 提交任务
SQL 语句和任务所需参数配置完成后,可将任务提交发布到运维中心离线任务运维中周期执行。
单击上方操作栏中的保存和提交上线按钮,在提交上线对话框中,选择回溯数据、监控设置、提交设置等参数,最后单击确认按钮,完成作业提交。 提交上线说明详见:数据开发概述---离线任务提交。
后续任务运维操作详见:离线任务运维。