DataLeap接入了流式计算 Flink 版,在关联 Flink 的项目和资源池后,可以进行 Flink 作业开发。可以通过 Serverless Java Flink 作业实现原生任务的托管和运维。本文以一个简单的示例,将为您介绍 Serverless Java Flink 作业相关的开发流程操作。
1 使用限制
- DataLeap产品需开通 DataOps敏捷研发、大数据分析、数据开发特惠版或分布式数据自治服务后,才可绑定流式计算 Flink 引擎。绑定引擎操作详见:项目管理。
- Serverless Java Flink 暂不支持自动解析功能来登记数据源。
2 使用前提
- 子账号操作项目绑定 Flink 引擎实例时:
- 主账号需要先在流式计算 Flink 版控制台导入 IAM 用户。操作详见:用户管理。
- 并将子账号加入到对应引擎项目中。操作详见:引擎项目成员管理。
- 目前 Flink 1.17 执行引擎版本,仅通过白名单形式放开,您可通过提工单的方式,联系我们加白后进行使用。
3 任务配置说明
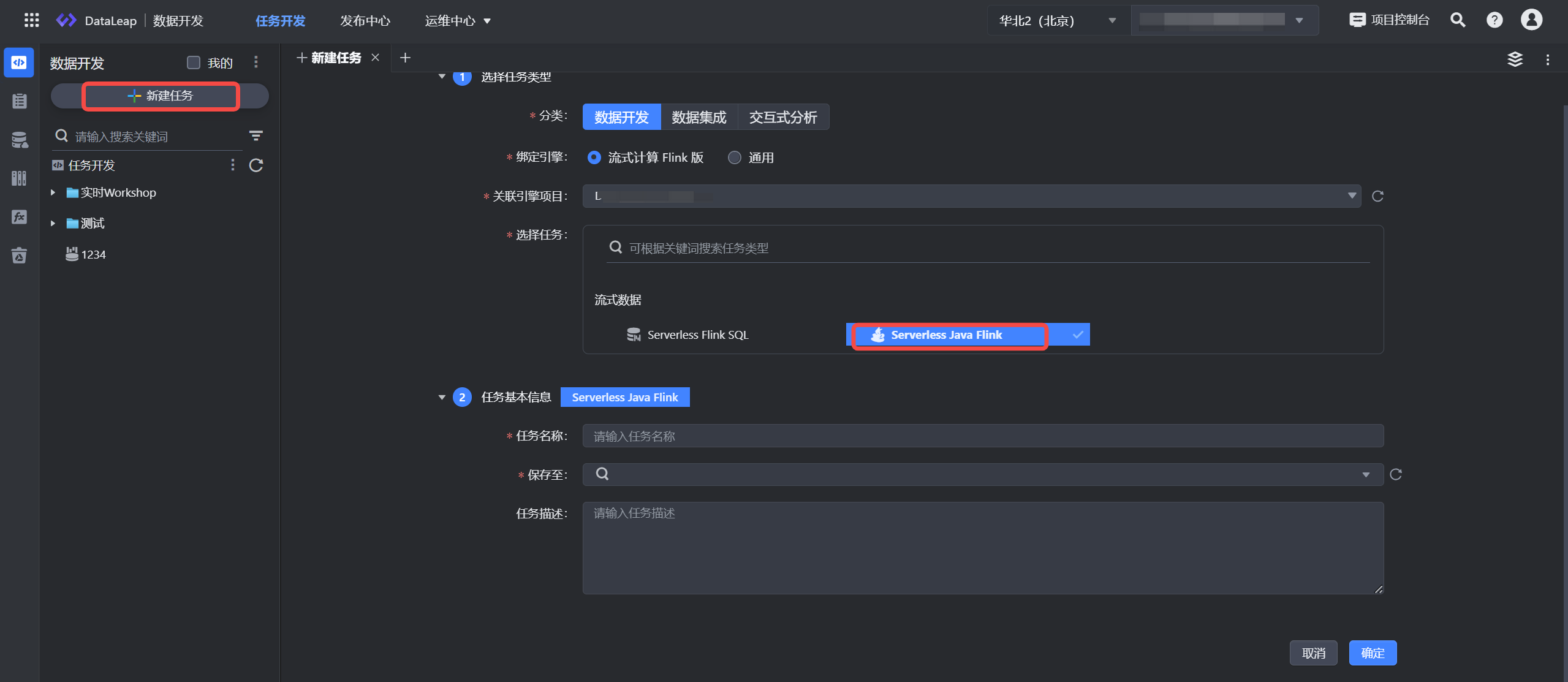
3.1 新建任务
- 登录 DataLeap租户控制台。
- 在具体项目中进入数据开发界面,并单击新建任务按钮进行任务新建。
- 依次选择数据开发 > 流式计算 Flink 版 > Serverless Java Flink 任务类型。
- 填写任务基本信息,单击确定按钮,完成任务创建。
注意
- 在项目控制台管理界面中,如果新增或修改了引擎,那么在数据开发任务新建窗口中,需刷新整个 DataLeap 数据开发界面,才能看到新增或修改后的引擎任务类型。
- 任务名称信息仅允许数字、字母、下划线、-和.组成, 首尾只能是数字、字母,且允许输入 1~63 个字符。
3.2 引用资源
通过下列参数设置 Jar 包:
- 选择 Jar 包可通过以下方式选择资源:
- 资源库中选取已有资源。
- 直接在下拉框中新建资源,或在左侧导航栏资源库中新建流式计算 Flink 资源,详见:资源库操作。
- 执行引擎:执行引擎支持选择 Flink 1.11、Flink 1.16、Flink 1.17 版本。
说明
目前 Flink 1.17 执行引擎版本,仅通过白名单形式放开,您可通过提工单的方式,联系我们加白后进行使用。
- Main Class:填写 Jar 包程序的主类,例如:com.bytedance.openplatform.datastream.DatagenToPrint。
3.3 资源设置
设置任务运行时相关资源分配情况
参数名称 | 描述 |
|---|---|
TaskManager个数 | 设置 flink 作业中 TaskManager 的数量。 |
单TaskManagerCPU数 | 设置单个 TaskManager 所占用的 CPU 数量。 |
单TaskManager内存大小(MB) | 设置单个 TaskManager 所占用的内存大小。 |
单TaskManager slot数 | 设置单个 TaskManager 中 slot 的数量。 |
JobManager CPU数 | 设置单个 JobManager 所占用的 CPU 数量。 |
JobManager内存 | 设置单个 JobManager 所占用的内存大小。 |
3.3 Flink运行参数
填写 Flink 相关的动态参数和执行参数,平台已为您提供一些常用的 SQL 参数、State 参数、Runtime 参数等,您可以根据实际情况进行选择,或者自行输入所需参数。更多参数详见 Flink 官方文档。
说明
平台提供的常用参数,您需要事先在引用资源中,设置相应的执行引擎版本后,方能提示在下拉框中。
- 单行编辑模式:填写 key-value,其中:
- key 值只允许字母、数字、小数点、下划线和连字符;
- value 值您可输入固定值,也可根据实际场景输入项目或自定义参数变量形式,如 {{project_param_rows}},参数变量形式提升任务在不同环境中的执行效率。项目或自定义参数变量使用说明详见3.4.5 任务输入参数。
其余操作说明如下:
a. 添加一行参数
b. 删除当前这行参数
c. 清空输入框中已输入的参数值
- 脚本编辑模式:通过 JSON、Yaml 的格式填写运行参数。
- 子类查看模式:您通过上方编辑模式输入参数后,可单击子类查看模式,支持将添加的参数自动做分类,帮助您在众多参数下,能更方便了解输入的 Flink 参数。
说明
- 可在对应分类下,按照关键词搜索需要使用的参数。
- 若在指定分类下,无法搜索到对应参数,可在“其它参数”类别,自行进行输入。
- 填写在“其它参数”类别下的参数,若隶属于“SQL参数/State参数/Runtime参数”类别,完成编辑后,系统会将其归属到对应分类。
3.4 用户自定义参数
用户自定义参数,填写实时数据来源端相关实例信息,例如 kafka 消息队列接入时,需要填写 Topic、接入点地址等参数信息。
- 单行编辑模式:填写 key-value,其中:
- key 值只允许字母、数字、小数点、下划线和连字符;
- value 值您可输入固定值,也可根据实际场景输入项目或自定义参数变量形式,如 {{project_param_rows}},参数变量形式提升任务在不同环境中的执行效率。项目或自定义参数变量使用说明详见3.4.5 任务输入参数。
- 脚本编辑模式:通过 JSON、Yaml 的格式填写运行参数。
3.5 参数设置
单击右侧导航栏中参数设置,进行任务的基本信息、资源设置、数据源登记配置。
3.5.1 基本信息
Serverless Java Flink 任务的基本信息配置如下:
参数名称 | 描述 |
|---|---|
任务名称 | 显示创建任务时输入的任务名称,参数设置中不支持修改,可以在左侧任务目录结构中的任务名称右侧更多单击重命名进行修改。 |
任务类型 | Serverless Java Flink |
引擎类型 | 流式计算 Flink 版。 |
关联引擎项目 | DataLeap侧关联的引擎项目名称。 |
任务描述 | 非必填,可对任务进行详细描述,方便后续查看和管理。 |
责任人 | 仅限一个成员,默认为任务创建人(任务执行失败、复查通过或者失败时的默认接收者),可根据实际需要,修改为其他项目成员。
|
计算资源 | 从关联的引擎项目中选择目标资源池。 |
优先级 | 您可对流式任务设置任务优先级,指定当前任务的优先级情况:
|
标签 | 您可以自定义标签,用于标识某一类任务,以便快速搜索过滤,操作即时生效,无需重新上线任务。
|
3.5.2 引入资源
Serverless Java Flink 任务支持通过引入资源 Jar 包、File 文件资源类型,可在 Jar、File 中自定义 connector 的方式,进行 Flink SQL 任务的编辑、Session 调试、提交上线执行等操作。
说明
- Jar、File 资源类型中自定义 connector 和内置 connector 重名时,不支持在同一个任务中使用,否则任务执行时会出现冲突异常的情形。内置 connector 详见连接器列表。
- 当线上正在运行的 Java Flink 任务包含资源引用时,如果资源文件发生更新,那么在资源库更新资源文件之后,您需前往运维中心重启流式任务,以使资源变更生效。
在下拉框中,选择已通过资源库上传的 Jar、File 资源,可支持多选。若您还未上传资源,您可单击“新建资源”按钮,前往资源库进行资源创建,操作详见资源库。
3.5.3 任务输入参数
若您希望同一套代码能在不同执行环境下,实现自动区分不同的引擎环境参数、项目参数、自定义参数等,则您可以通过设置任务的输入参数,实现此场景需求。
任务输入参数支持您通过使用自定义参数和项目参数,以变量或常量形式传入流式任务中使用,通过 {{参数名}} 的方式在代码中使用。配置操作详见3.4.5 任务输入参数。
3.5.4 数据源登记
登记该任务使用的 Source 和 Sink 信息,以用于后续监控配置和血缘构建,支持通过手动添加。
- 手动添加:单击手动添加按钮,可根据 SQL 逻辑进行数据源上下游登记。
- 源/目标:支持源/目标 Source 和 Sink 的选择。
- 数据源类型:支持选择 DataGen、Rmq、Bmq、JDBC、Abase、火山/自建 Kafka 这些 Connector 的数据源自动解析。
- 各数据源类型需补充填写相应的信息,您可根据实际场景进行配置,如 Kafka 的数据源类型,需填写具体的Bootstrap Servers、Topic 名称、消费组等信息。
- 直接上游任务:您可通过手动输入任务名称方式,进行搜索上游任务,单击添加按钮,进行手动添加。
- 直接下游任务:无法通过手动添加的方式进行操作,仅展现通过数据源匹配后的结果。
说明
- Abase 和 Rmq 数据源类型,仅支持解析操作,暂不支持上线发布后运行。且 Abase 数据源通常是在火山引擎内部业务上云中使用。
- Serverless Java Flink 暂不支持自动解析功能来登记数据源。
- 批量删除:手动添加的数据源,您可通过勾选已登记的数据源后,单击右侧删除或批量删除按钮 ,删除勾选中的数据源。
- 上下游任务查看:数据源登记解析出的上下游任务,您可对上游依赖任务进行编辑、添加、删除、禁用等操作;下游任务仅支持查看。
4 提交发布
任务所需参数配置完成后,将任务提交发布到运维中心实时任务运维中执行。
单击操作栏中的保存和提交上线按钮,在弹窗中,需先通过任务上线检查和提交上线等上线流程,最后单击确认按钮,完成作业提交。详见概述---流式任务提交发布。
后续任务运维操作详见:实时任务运维。