数据集的模型配置可以将不同来源的数据整合,辅助数据最终能以可视化的方式呈现,帮助用户从多个角度全面地把握数据。在完成数据源接入后,就可以配置模型创建数据集。
前置说明:
抽取的数据集可以支持如下描述多表 Join 与多表合并 Union 操作;直连数据集会根据版本有如下限制:
在 V2.50.0 版本之前仅支持单表直连查询
从 V2.50.0 版本及之后,除 Finder 数据连接仅支持单表外,其他直连数据源可支持多表 Union、Join、自定义 SQL,多表不可跨数据源、跨数据连接使用,比如来自 A 数据连接的表 A 和来自 B 数据连接的表 B,不能进行 union/join/,或者在自定义 SQL 中同时存在表 A、B 的操作
抽取与直连区别见:数据源接入-->抽取与直连
产品支持将不同来源的数据整合在一起,只需用拖拽的方式,就能够完成数据模型的构建。
第一步 :左侧列表仅展示有权限的表信息,将需要制作数据集的表拖拽进入中间「模型区域」,系统支持跨源合并(Union)以及跨源连接(Join)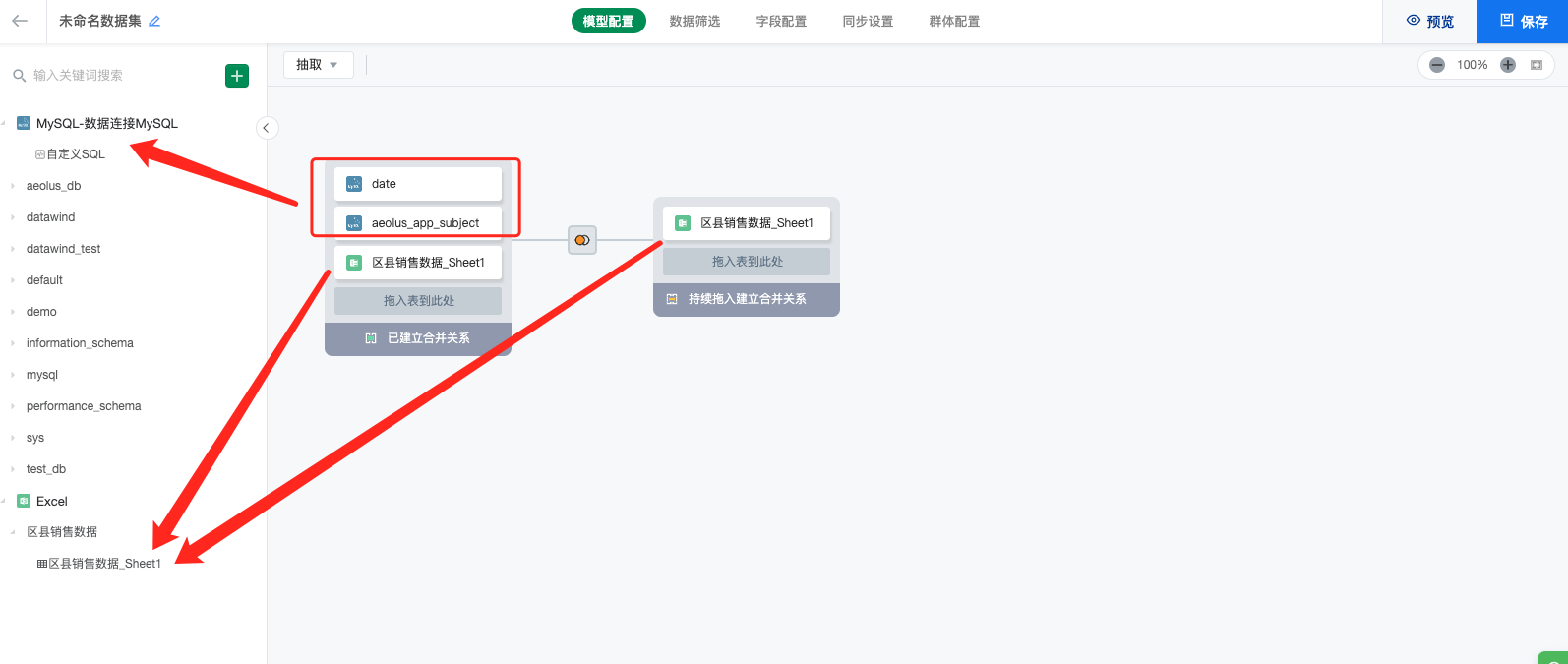
第二步 :点击每个表的胶囊选择需要使用的字段(列),未勾选的字段则不导入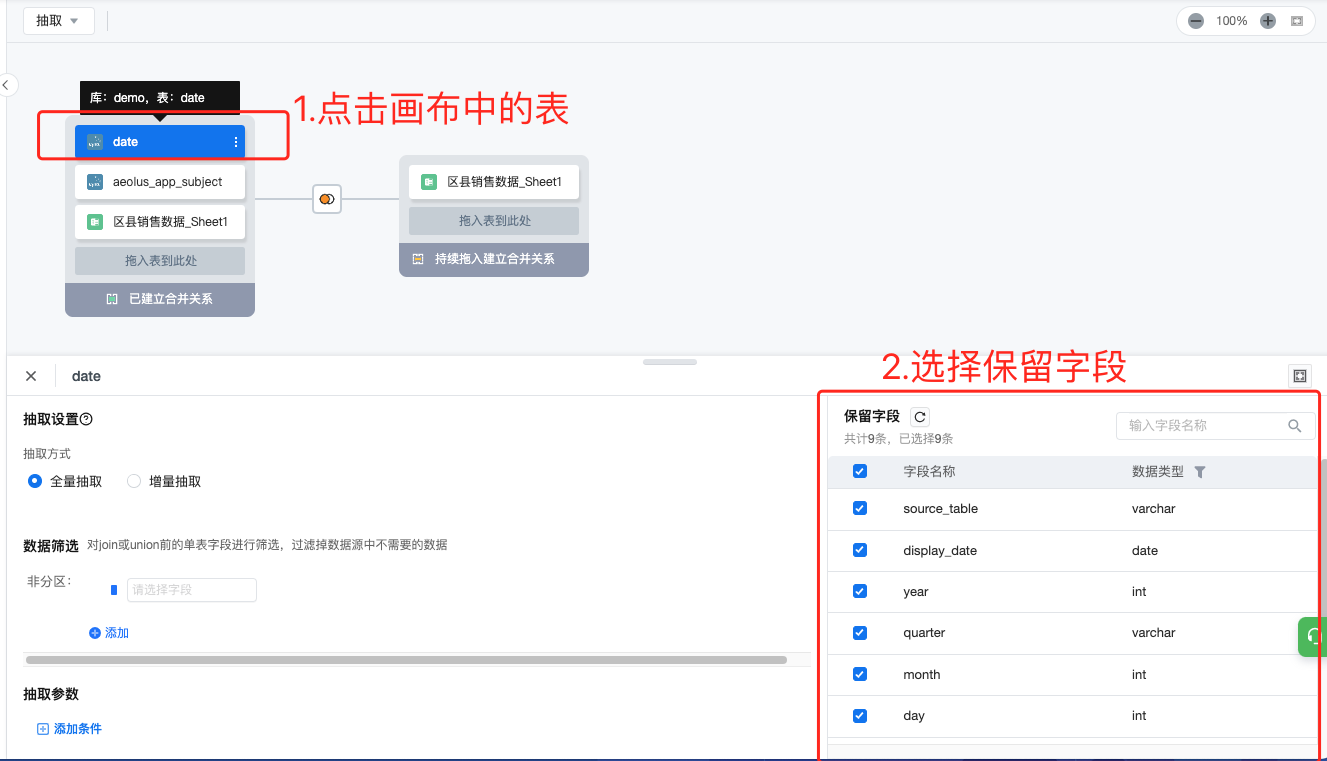
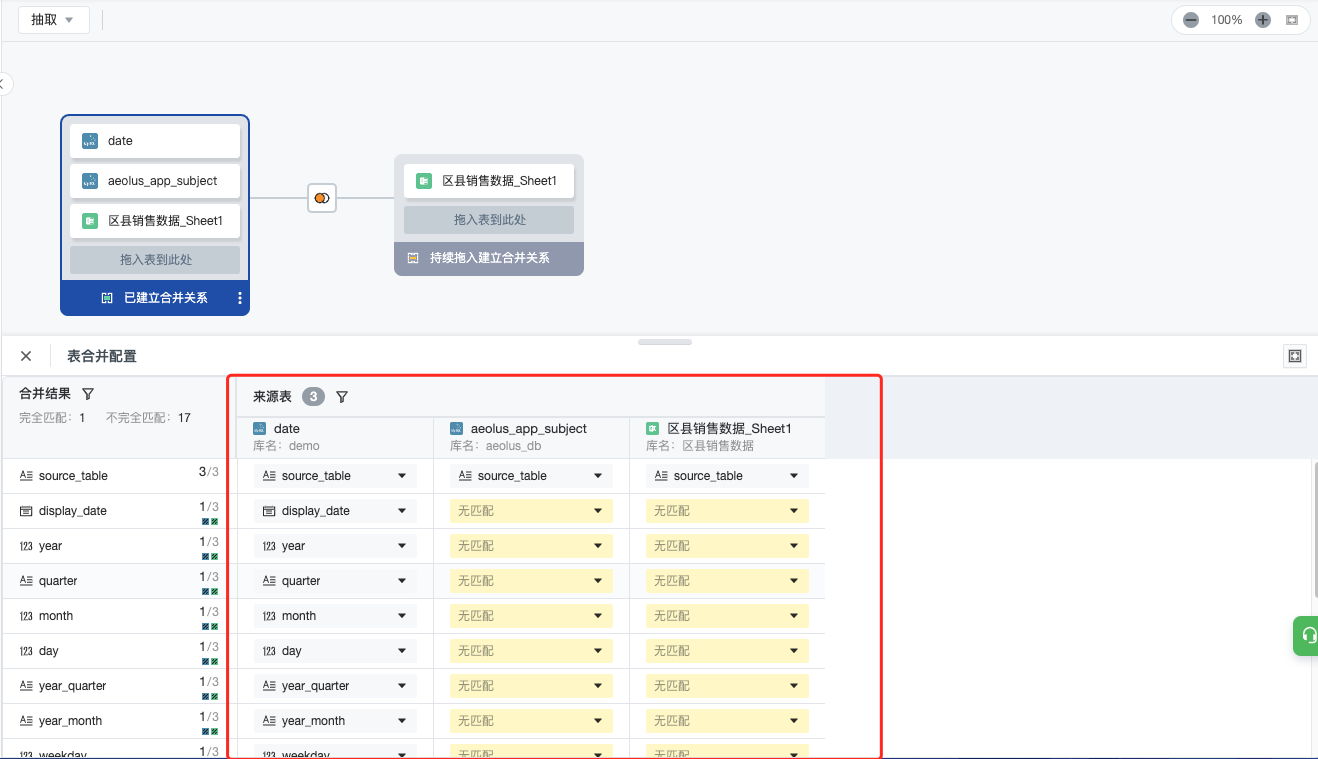
第三步 :配置合并的匹配关系/关联方式及关联字段
- 合并(Union):点击'已建立合并关系'蓝色区域,在下方配置合并的匹配关系
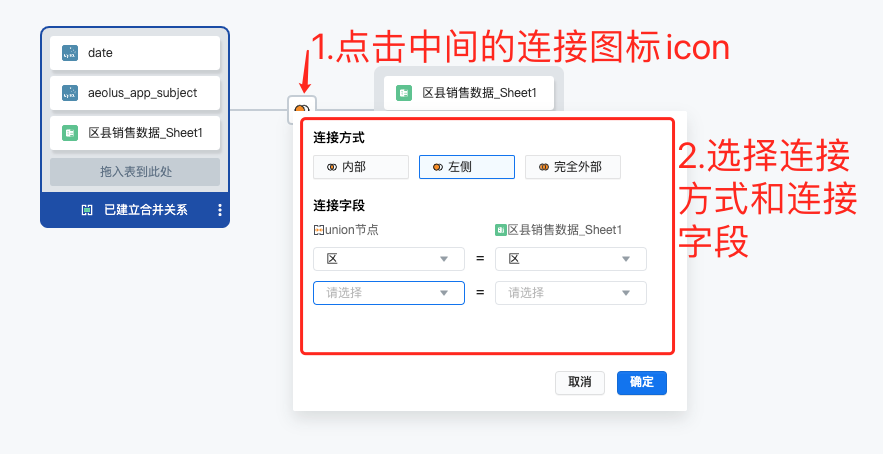
- 关联(Join):点击中部连接图标,在弹窗内设置关联方式及关联字段
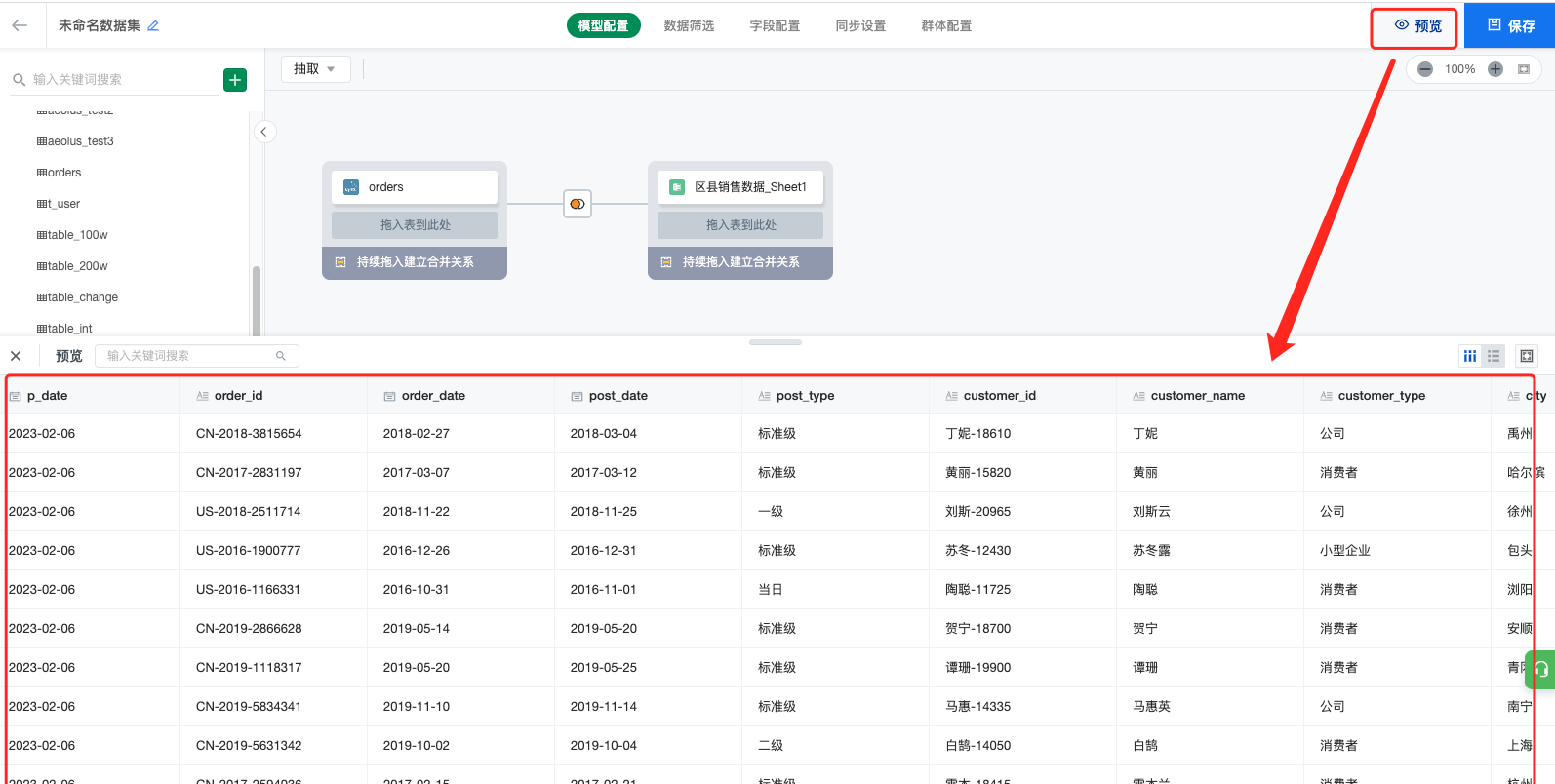
第四步 :模型构建过程中,可点击右上角的「预览」按钮用于预览数据
注意:该预览结果为随机抽样数据,仅供参考
3.1 使用限制
抽取模式的多表关联(Join):支持数据来自同一个数据连接/数据源,也可以支持来自不同数据连接/数据源
直连模式会根据版本有如下限制:
在 V2.50.0 版本之前仅支持单表直连查询,不支持多表关联(Join)
从 V2.50.0 版本及之后,除 Finder 数据连接仅支持单表外,其他直连数据源可支持来自同一个数据连接的多表关联,不支持跨数据源、跨数据连接使用
3.2 使用方法
(1)点击左侧列表上方的“+”,来添加更多类型的数据连接;可以在一个画布中选择多个数据连接。
(2)然后将同一数据连接/不同数据连接的表拖进入中间的「模型区域」,之后即可选择所需字段并配置关联关系。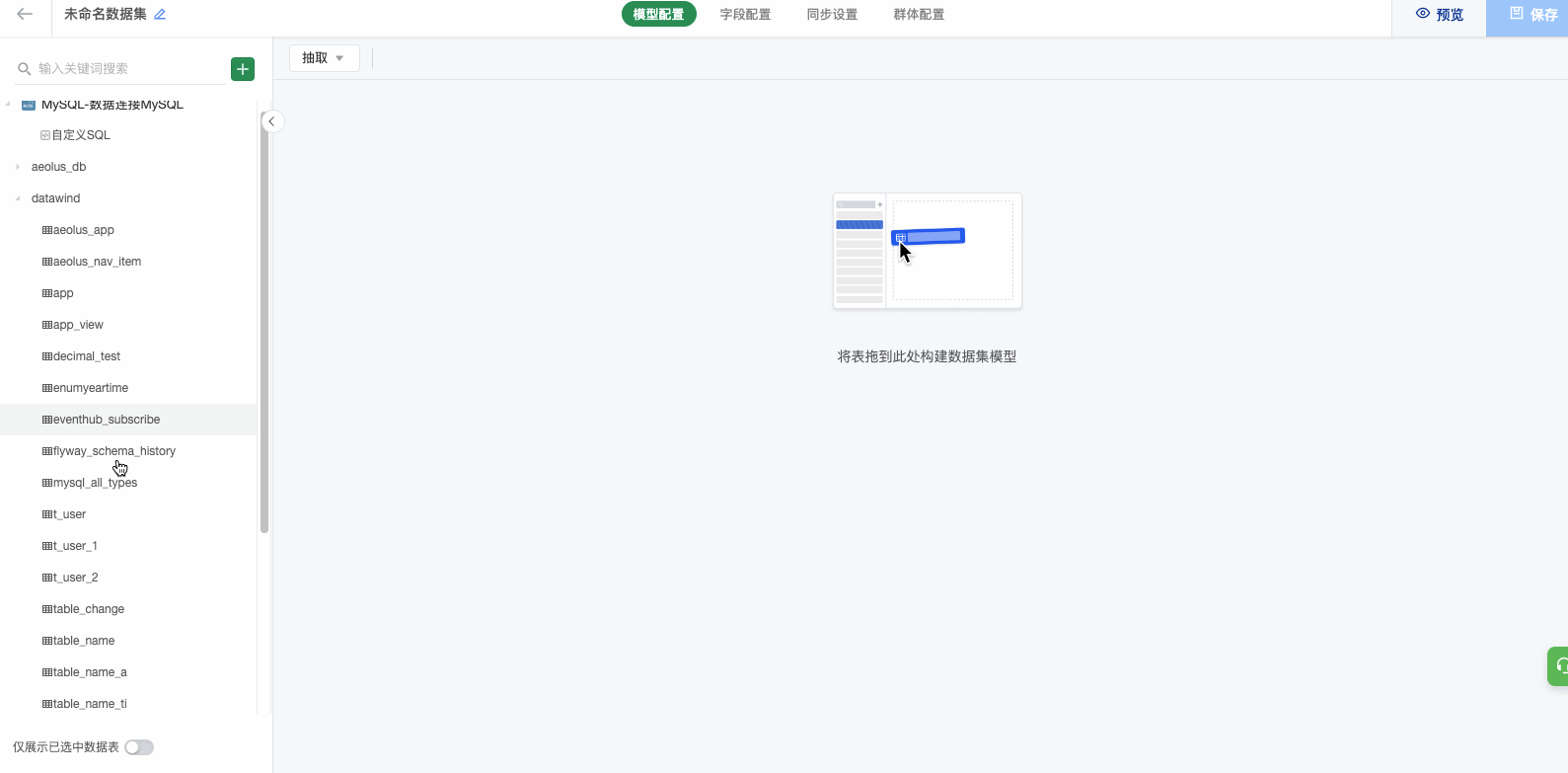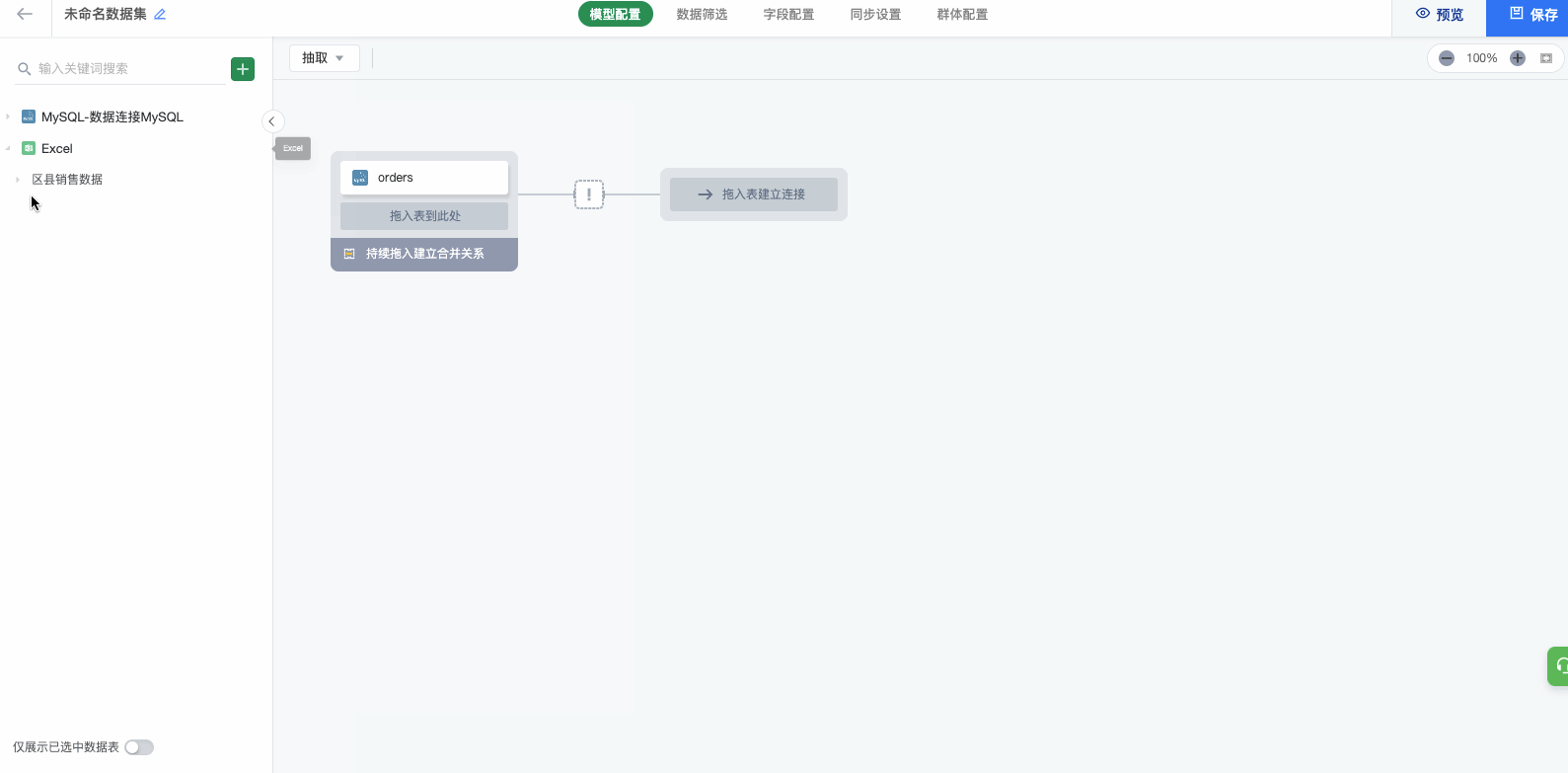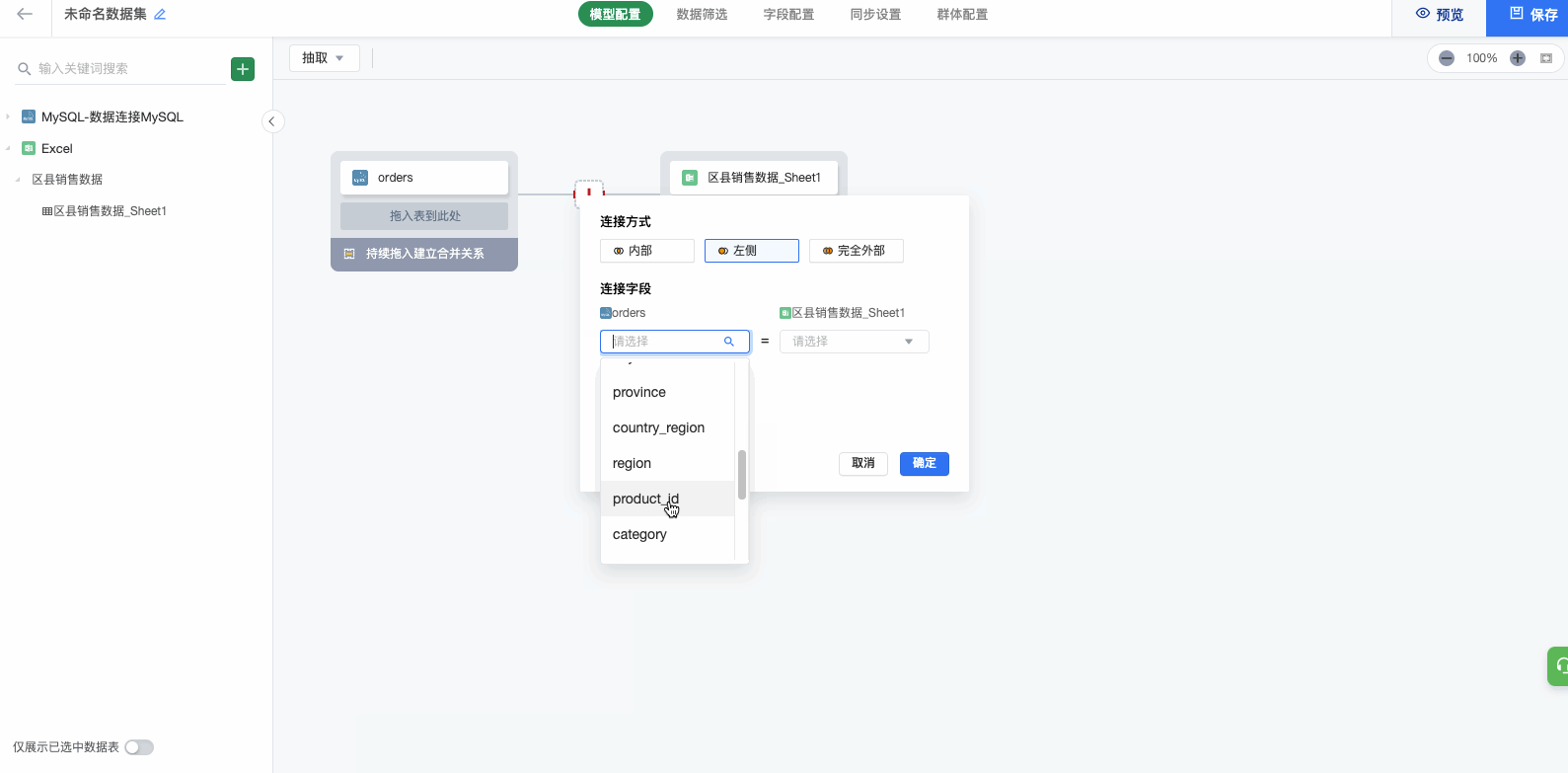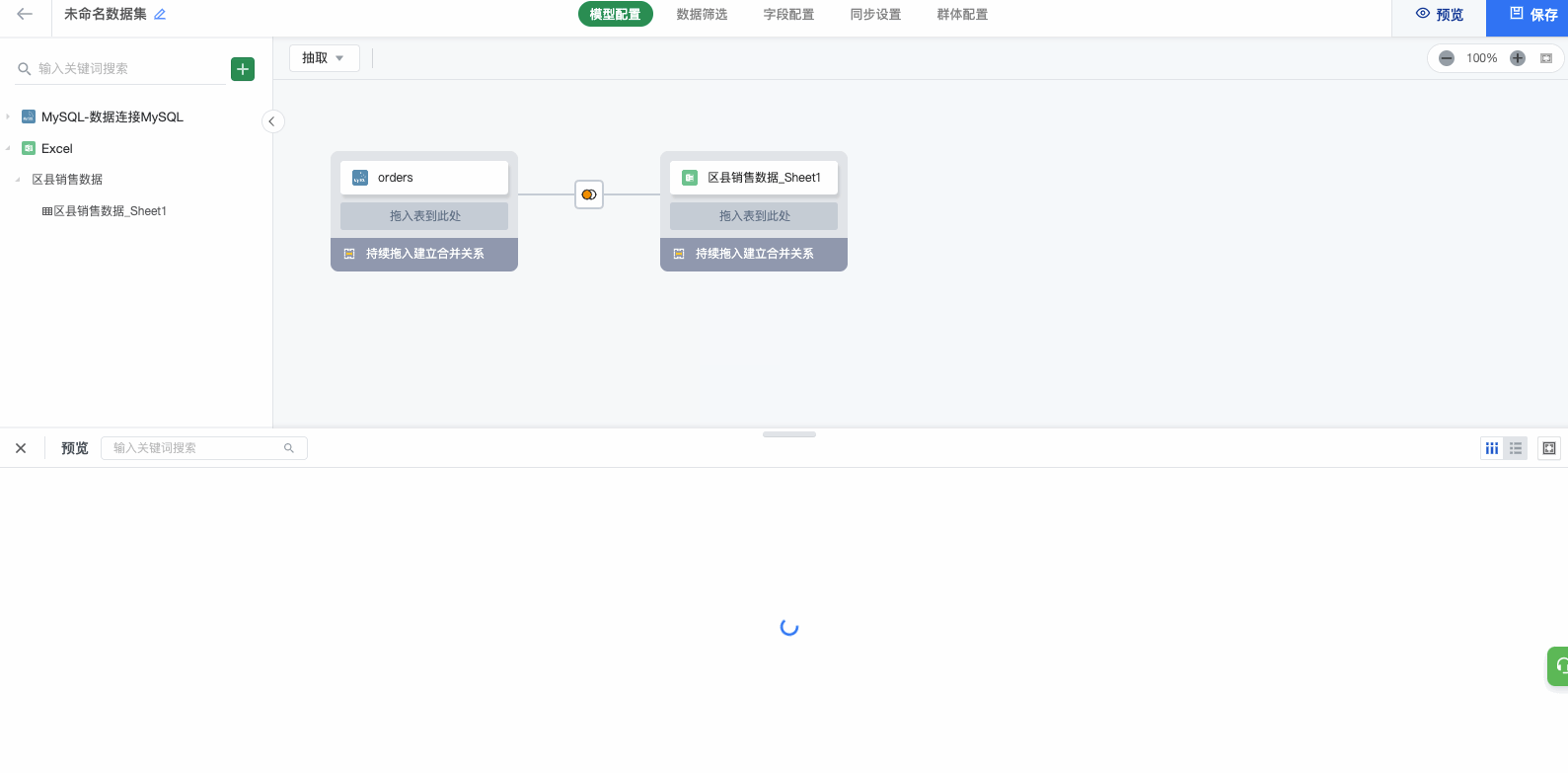
3.3 常见关联(Join)类型
3.3.1 关联(Join)
JOIN 是用来连接不同的数据表,常用于用来分析的数据,根据不同的目的存储在不同的表中;那么在分析数据时,就要根据不同表中的相同字段,将想要的数据连接起来。比如,一份订单,通过订单号把客人、菜品、厨房、供应商等连接在一起。
注意:做关联的字段类型需要保持一致
3.3.2 Inner join 内部
逻辑是取 Table1 表与 Table2表 的连接字段中条件相同值的“交集”,从而把交集范围内两表对应的数据行取出来,做对应的列拼接,如下所示: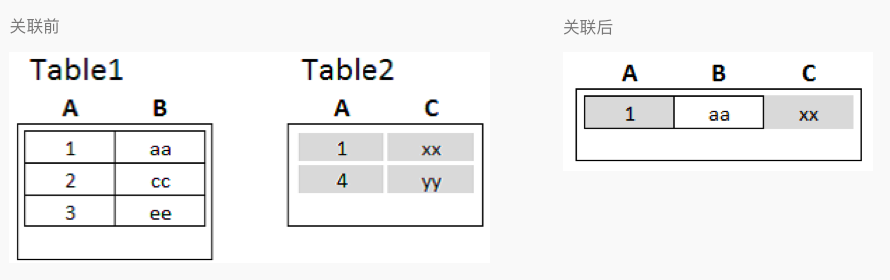
3.3.3 Left join 左连接
表示以左边的表的行数据为出发点,按照join的条件去寻找右边的表里符合join字段条件的数据行,从而把该行里指定的字段与左表拼成一行完整数据;如下面所示: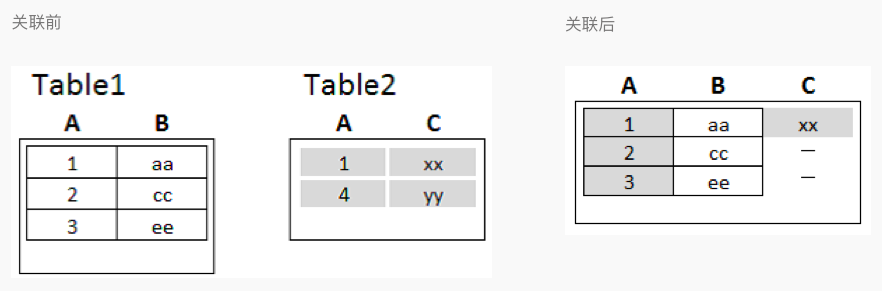
3.3.4 Right join 右连接
本质上与左连接的逻辑是一样的,此时是以右边的表作为主数据行进行数据列的笛卡尔积计算;即:A Right join B = B left join A
3.3.5 Full join 完全外部连接
完整外部连接返回左表和右表中的所有行。当某行在另一个表中没有匹配行时,则另一个表的选择列表列包含空值。如果表之间有匹配行,则整个结果集行包含基表的数据值。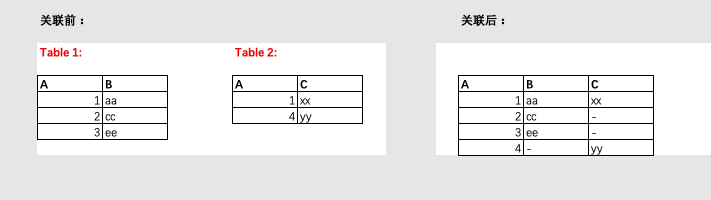
4.1 使用限制
抽取模式的多表合并(Union):支持数据来自同一个数据连接/数据源,也可以支持来自不同数据连接/数据源
直连模式会根据版本有如下限制:
在 V2.50.0 版本之前仅支持单表直连查询,不支持多表合并(Union)
从 V2.50.0 版本及之后,除Finder数据连接仅支持单表外,其他直连数据源可支持来自同一个数据连接的多表合并,但不支持跨数据源、跨数据连接使用
4.2 使用方法
(1)点击左侧列表上方的“+”,来添加更多类型的数据连接;可以在一个画布中选择多个数据连接。
(2)然后将同一数据连接/不同数据连接的表拖进入中间的「模型区域」。
(3)点击显示为'已建立合并关系'的蓝色区域,在下方配置匹配关系。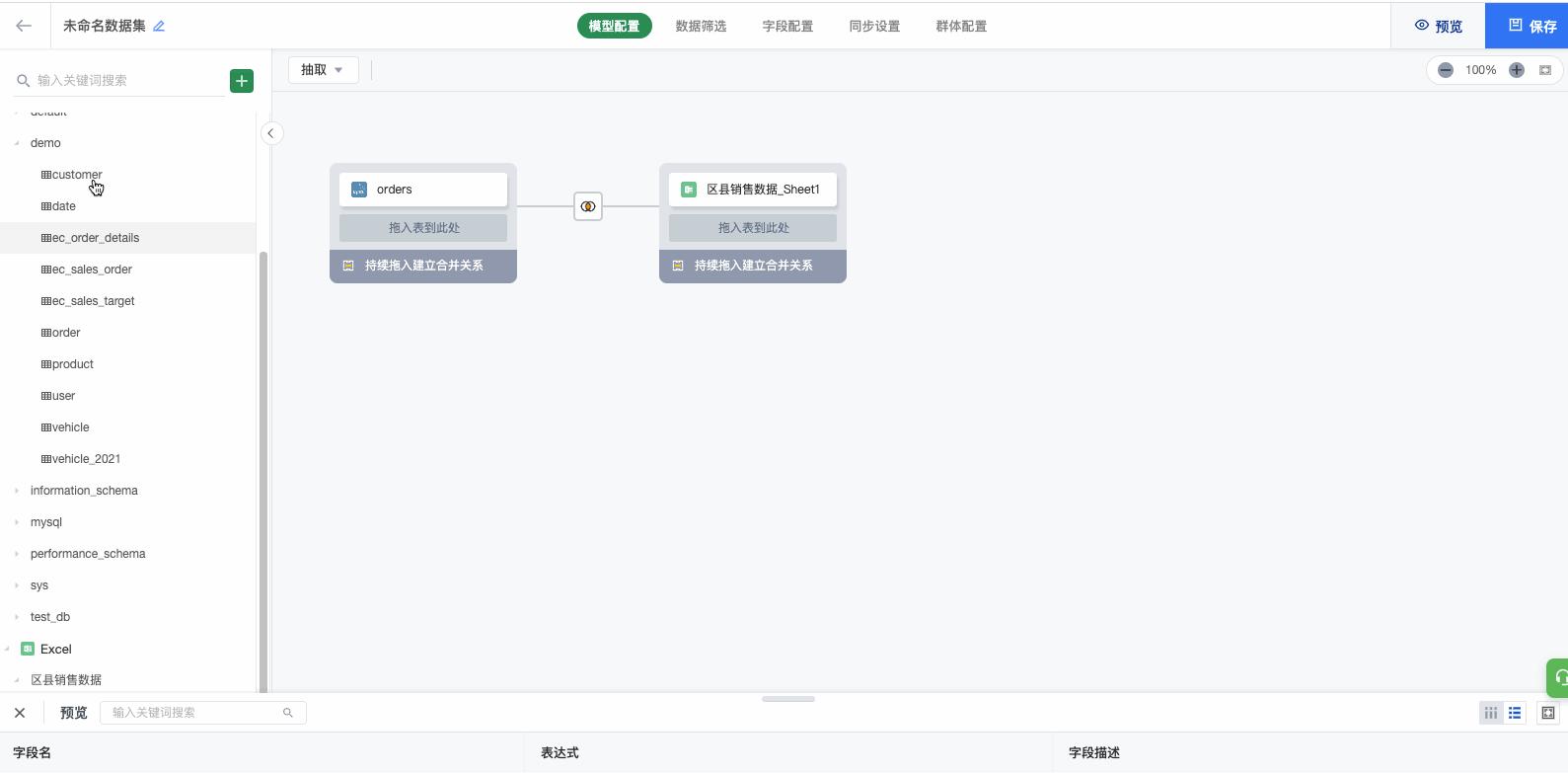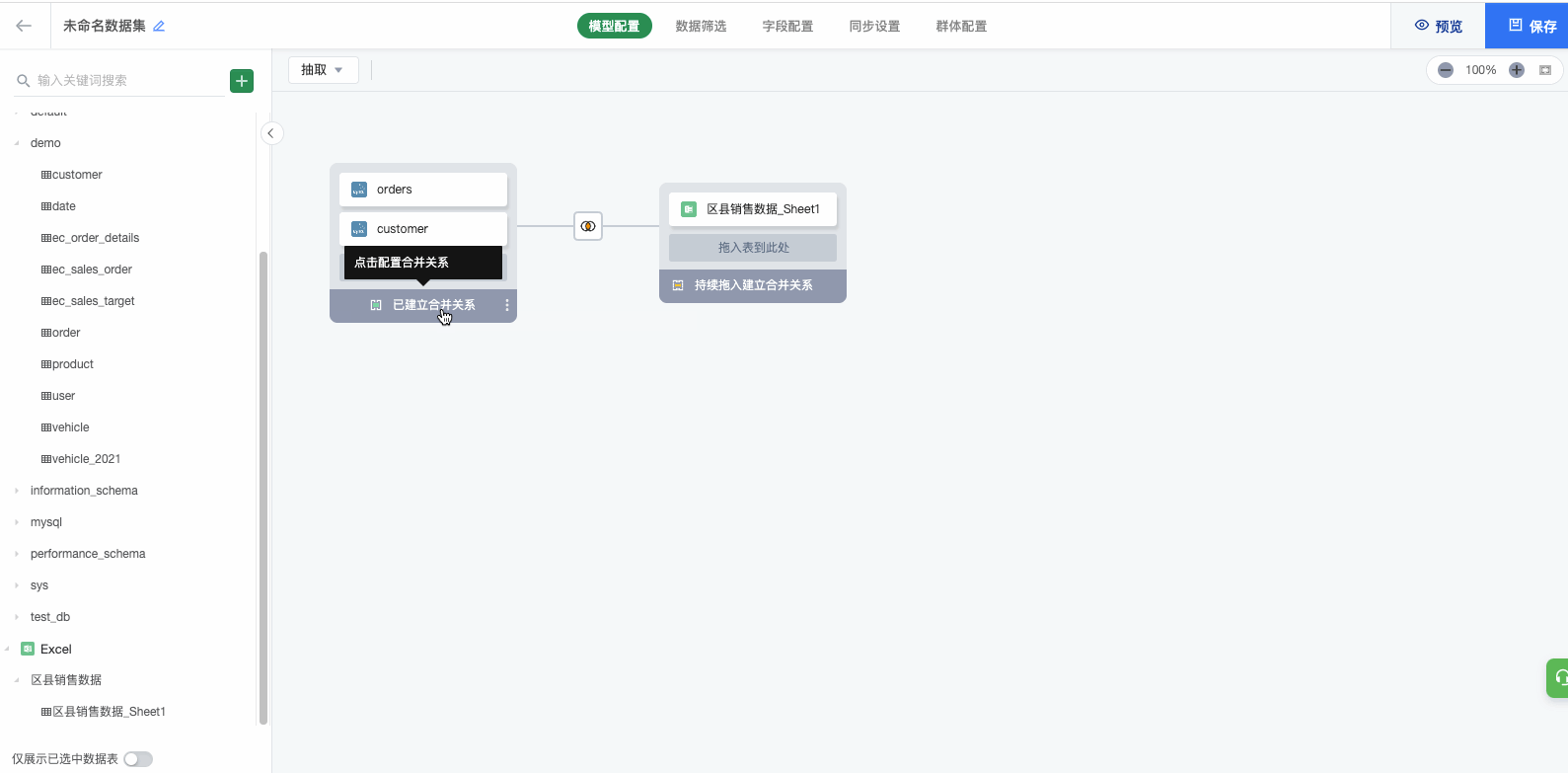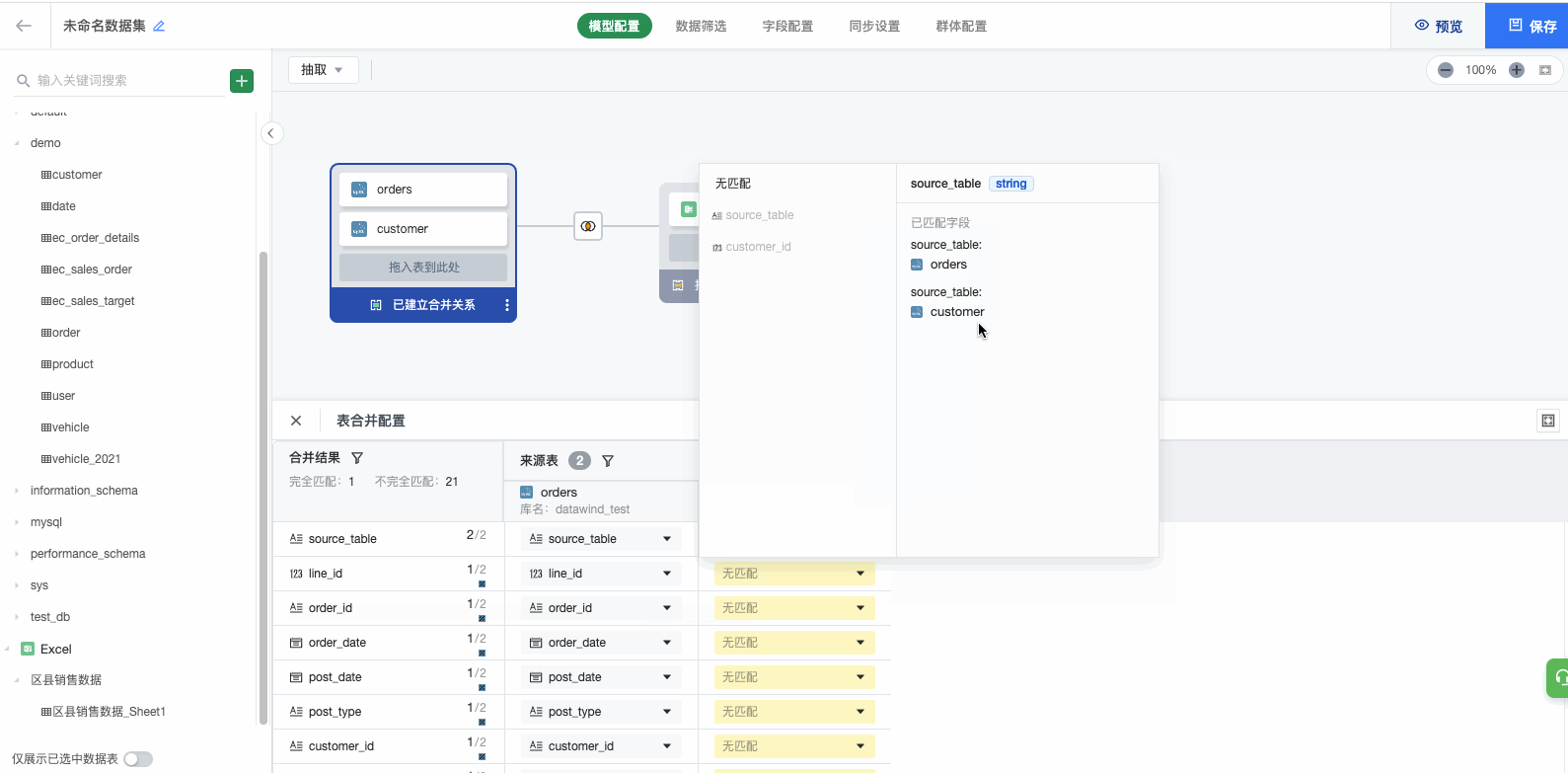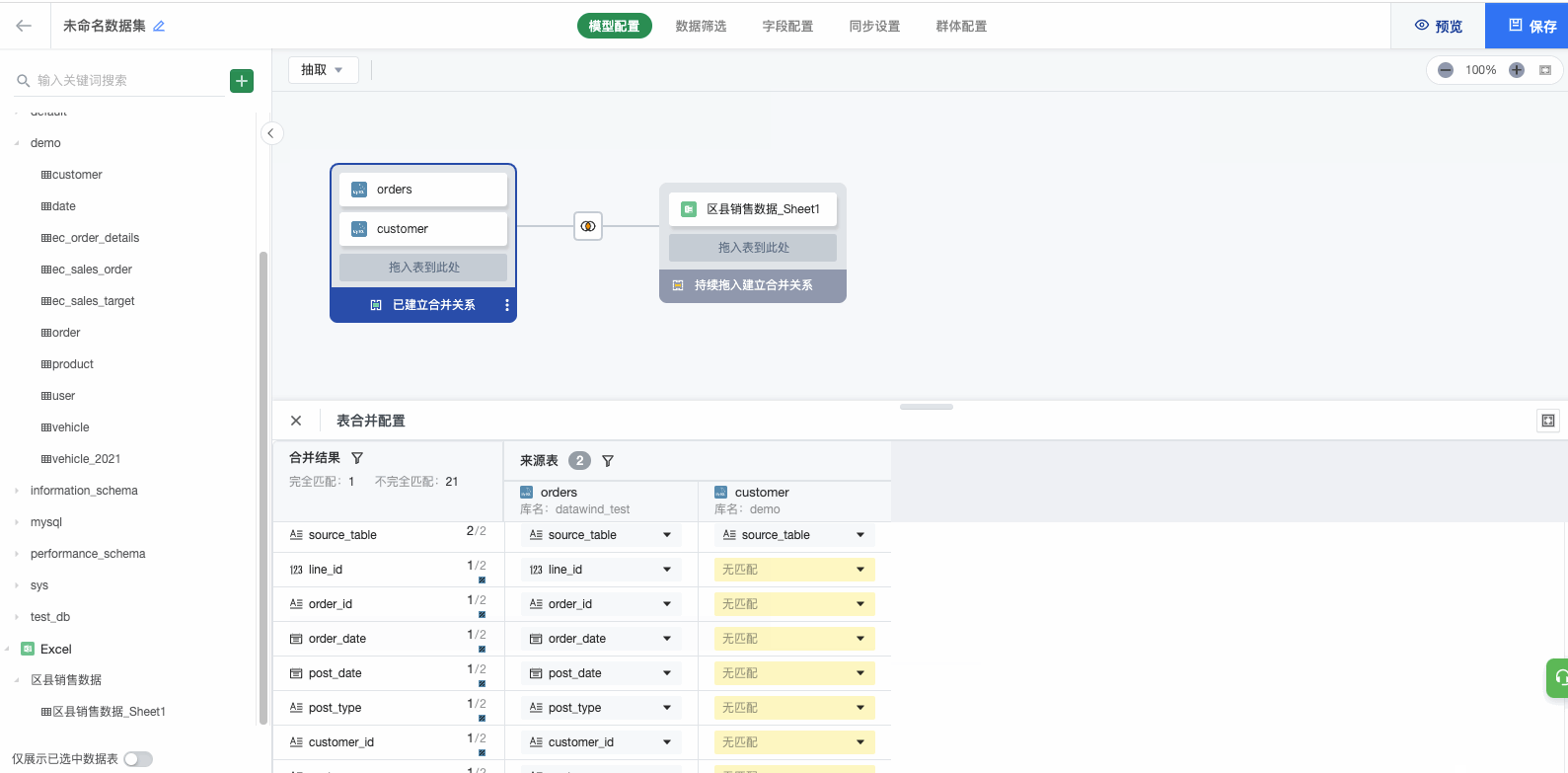
5.1 替换表
数据集上已经拖拽到画布中的表支持替换,例如将原有的 Mysql 数据表替换为 Excel 数据表
抽取模式支持跨数据源表/数据连接替换,但直连模式仅支持数据表来自同一数据连接下
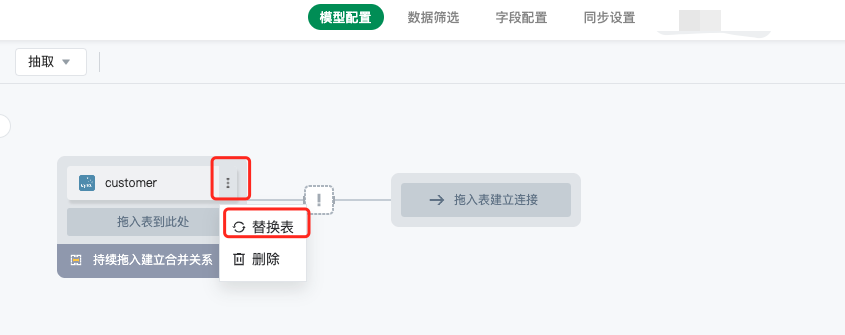
点击上述「替换表」按钮之后,在左侧选择目标替换表,鼠标点击将目标表拖拽到右侧,即可进行表替换。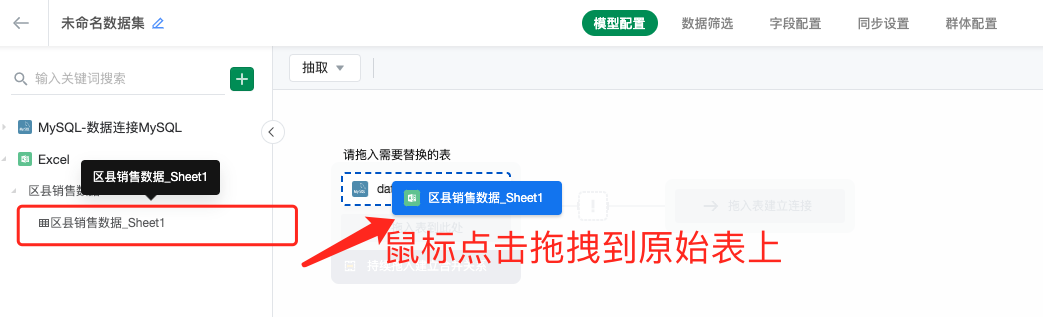
替换表时须注意,由于替换前后表的字段有差异,需要确认删除与新增的字段;新增字段支持选中应用,删除字段仅提供预览。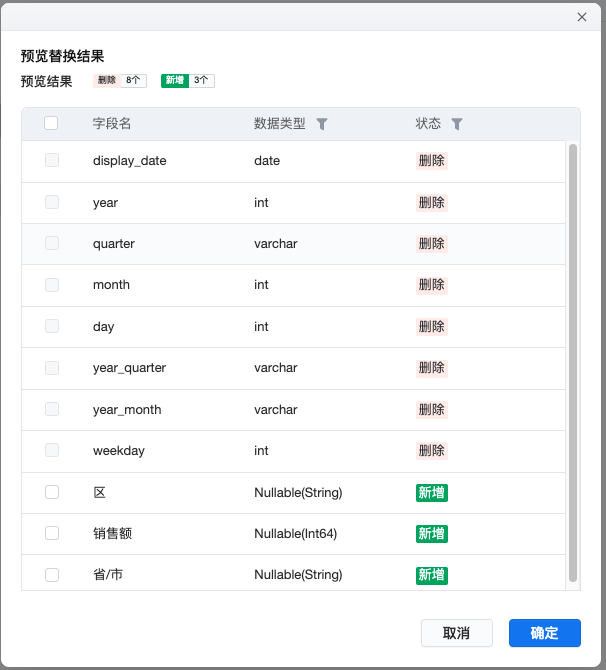
由于原始表字段可能在后续被应用,因此删除掉的字段被应用到会带来一些报错,比如基于原始字段创建新表达式、基于该字段创建图表/仪表盘等都将报错。因此建议当出现以下警告弹窗时,请谨慎确认后进行下一步操作。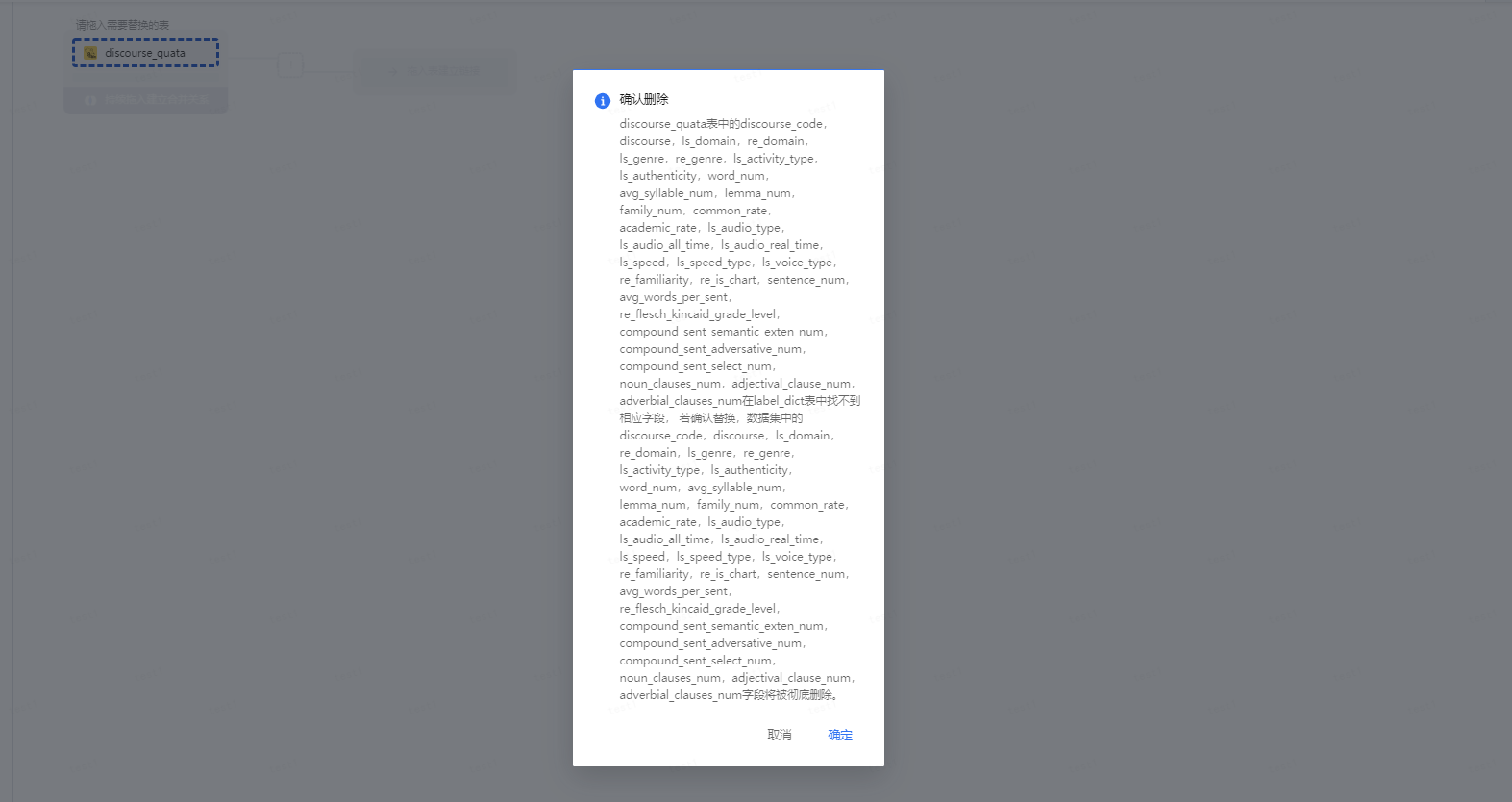
5.2 追加文件
仅离线文件(Excel,Csv,Access)支持文件追加,用户可通过文件追加的方式将新增数据手动添加至数据集。
文件追加功能不影响追加前文件内数据的同步,例如当用户按如下进行操作:
04月12日:用户使用 A 文件(内含100行数据)创建数据集并完成首次同步 04月13日:用户使用文件追加功能上传 B 文件(内含10行数据)保存后重新同步数据
则系统内各分区数据如下:
P_date=0412:100行数据(来源于 A 文件) P_date=0413:110行数据(来源于 A 文件+B 文件)
用户可通过重新同步历史数据,将追加数据更新至系统。
重新同步0412的数据后,P_date=0412应包含110行数据(来源于 A 文件+B 文件)
操作步骤
- 右键选择「追加文件」
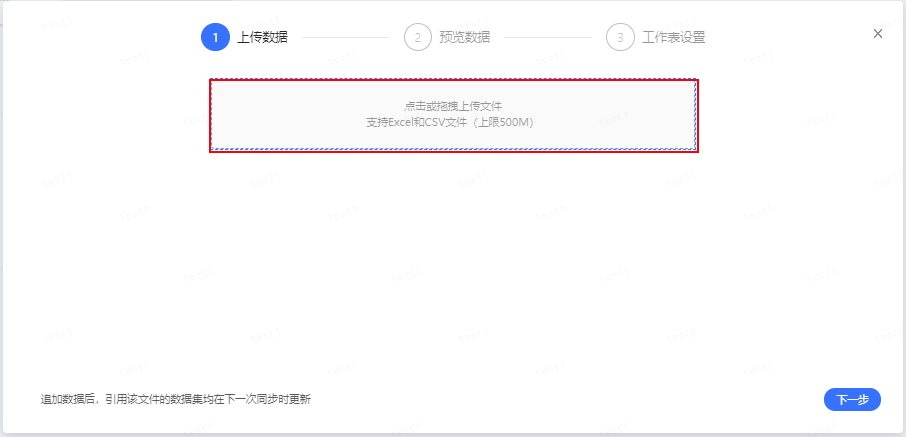
- 点击或拖拽上传追加文件
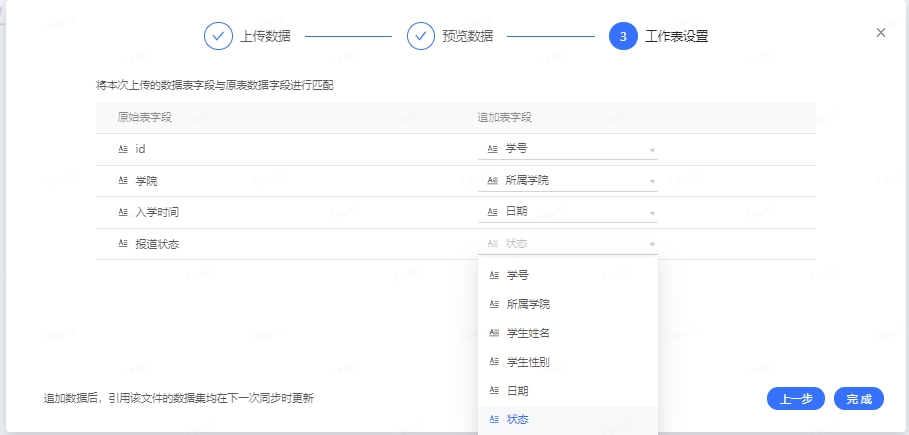
- 预览追加文件数据后,对追加文件与原表字段设置匹配关系点击完成即可。
- 保存数据集后,抽取方式创建的数据链接需手动同步,方可将新增数据同步至底表,直连表则无需手动同步。
用户也可在数据连接按照上述步骤进行文件追加操作,参考:本地文件-追加文件。
5.3 替换文件
仅离线文件(Excel,Csv,Access)支持文件替换。
文件替换后,被替换文件内数据将停止同步,例如当用户按如下进行操作:
04月12日:用户使用 A 文件(内含100行数据)创建数据集并完成首次同步 04月13日:用户使用文件替换功能上传 B 文件(内含10行数据)保存后重新同步数据
则系统内各分区数据如下:
P_date=0412:100行数据(来源于 A 文件) P_date=0413:10行数据(来源于 B 文件)
用户可通过重新同步历史数据,将替换数据更新至系统。
重新同步0412的数据后,P_date=0412应包含10行数据(来源于 B 文件)
操作步骤
右键选择[替换文件]
点击或拖拽上传替换文件
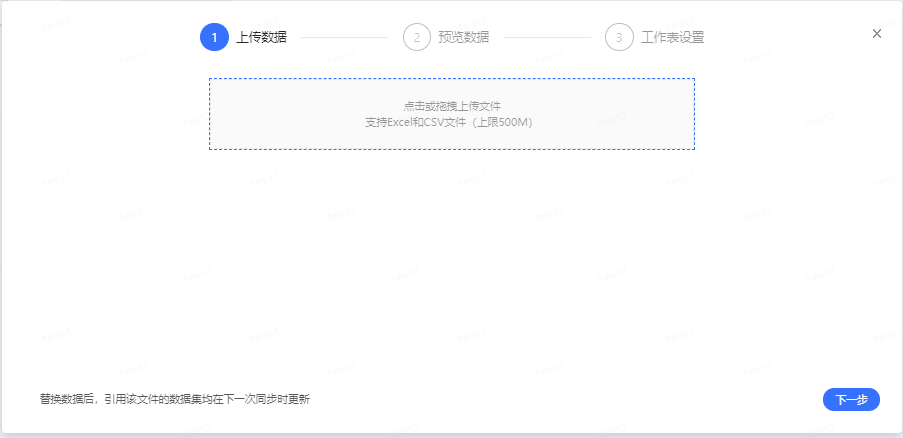
- 预览替换文件数据后,对替换文件与原表字段设置匹配关系点击完成即可。
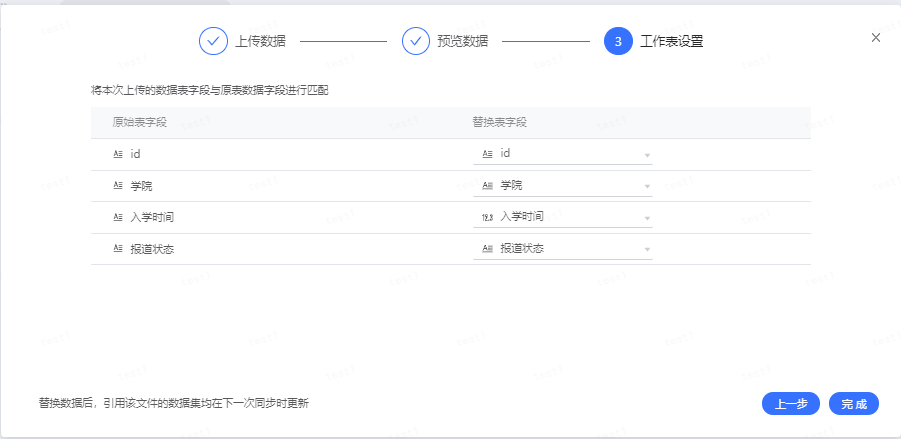
用户也可在数据连接按照上述步骤进行文件追加操作,参考:本地文件-替换文件
6.1 使用方法
针对抽取表,在模型中点击该表,在下方即可展示出该表的抽取设置;在抽取设置中选择抽取方式是全量/增量,选择筛选部分数据,有需要添加抽取参数即可。
注意:如果模型中存在多表,则可以针对模型中的每个单表进行设置
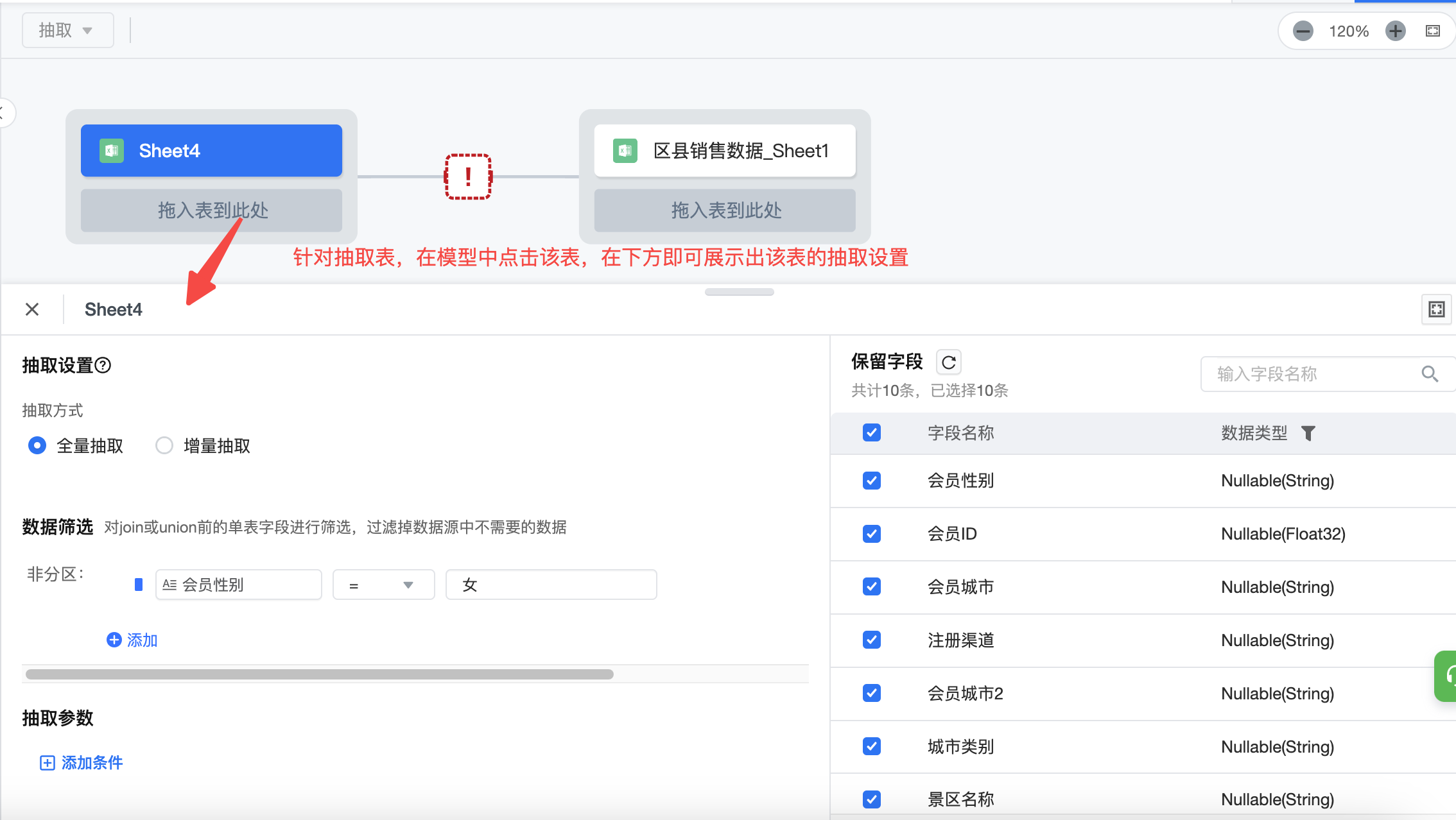
6.2 抽取设置
6.2.1 全量抽取
如果该表数据量不大,或者原始数据更新频繁,可以使用全量抽取的方式同步该表数据。
每次数据同步时,该表会将全量数据全部同步到产品的存储计算引擎中。
6.2.2 增量抽取
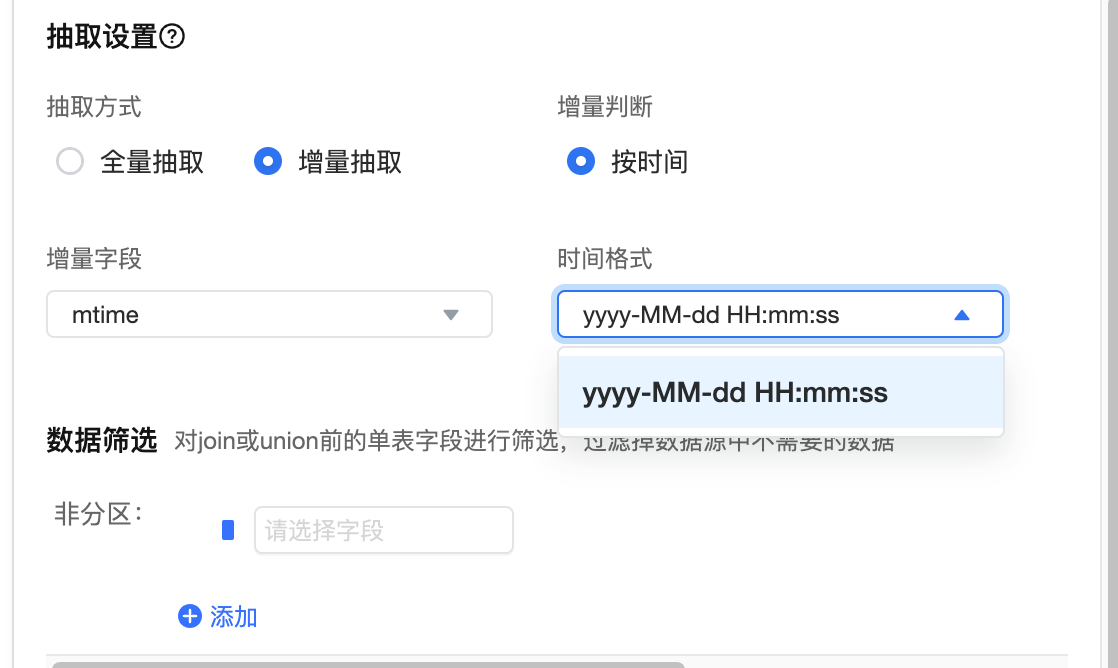
增量判断:目前仅支持通过时间戳来进行增量判断
增量字段:选择判断增量的字段,目前仅支持通过时间字段来判断
时间格式:增量字段为日期格式,则显示为 yyyy-MM-dd HH:mm:ss 或者 yyyy-MM-dd 的格式;其他格式则需选择几位时间戳
6.3 其他功能
6.3.1 数据筛选
针对该表数据进行筛选,可以过滤掉不需要的数据,这些过滤字段无需抽取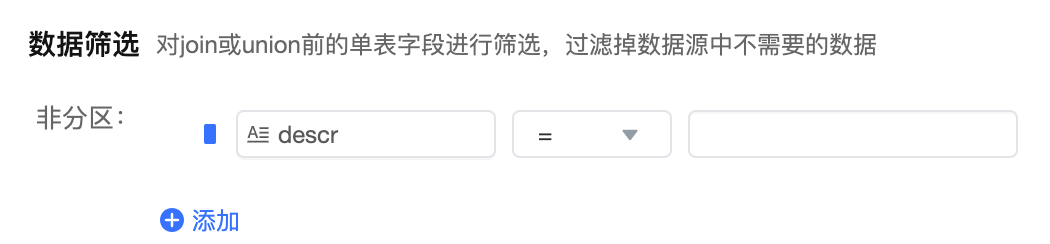
6.3.2 抽取参数
在抽取参数下点击「添加条件」,即可增加更多要设置的参数,详细设置可见:抽取参数
在数据集保存之后,不支持数据抽取与直连之间的切换
在数据建模过程中,一些复杂逻辑可以通过使用自定义 SQL 模型创建数据集实现。DataWind 支持通过自定义 SQL 建模分析,扩展敏捷 BI 支撑的场景深度,满足复杂的数据分析场景诉求,详细可见自定义 SQL。