LOD 是 Level of detail 的简称,为详细级别表达式功能。详细级别指数据聚合粒度的层次,不同的级别代表着数据不同的聚合度和粒度。
LOD 表达式能够处理在一个可视化视图中包含多个数据详细级别的问题。如果分析过程中需要添加一个维度,其明细程度高于或者低于已有视图的可视化明细程度,但又不希望改变现有图形展示内容,就可采用详细级别表达式功能。
关于 LOD 表达式内如何引用字段 产品支持以下两种字段引用格式,用户可根据实际需求自行选择。更多说明详见模型字段与数据集字段的区别
- 模型字段使用 '字段名',示例如下:
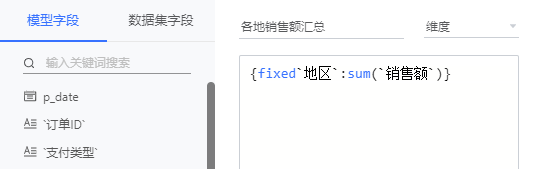
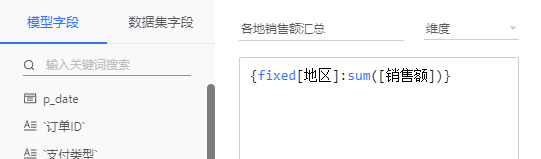
- 数据集字段使用 [字段名],示例如下:
第一步 :点击数据集名称右侧的设置,「添加字段」。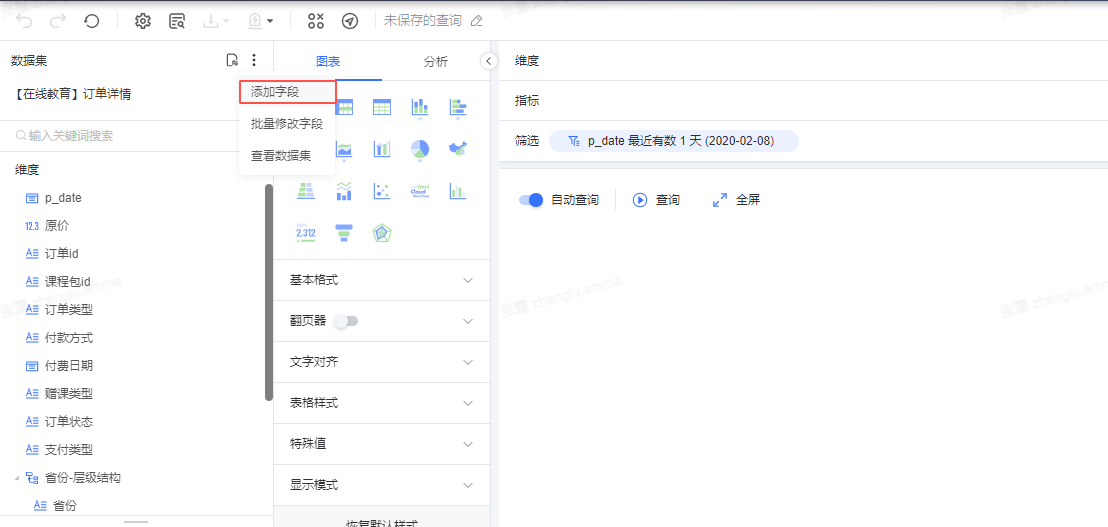
第二步 :填写该字段展示名称,指定维度指标分类,编辑表达式后点击保存。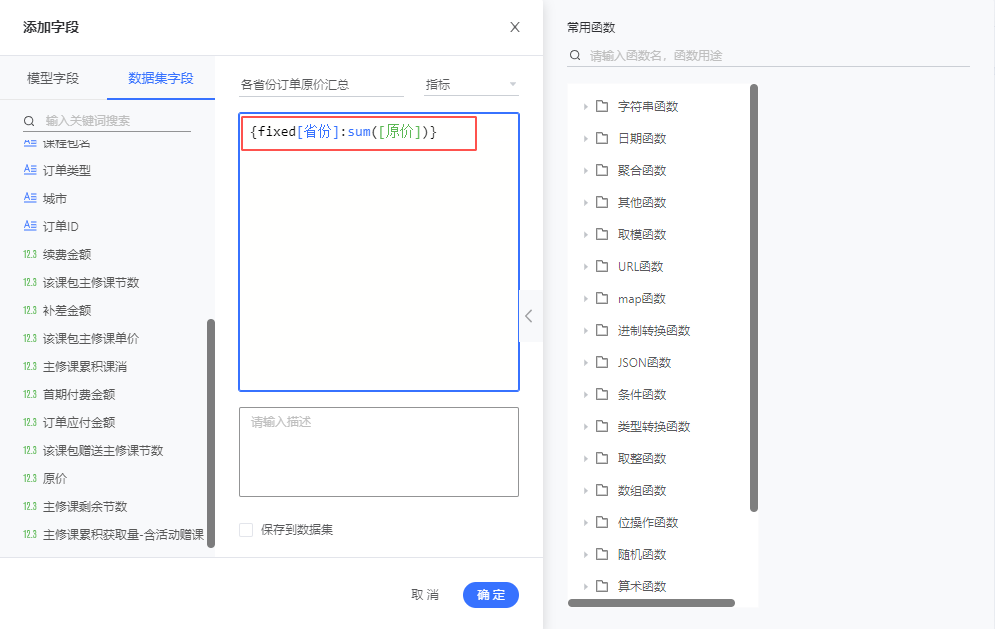
第三步 :使用新增字段进行可视化查询,可以看到相同省份的原价汇总额相同,不受订单类型变化。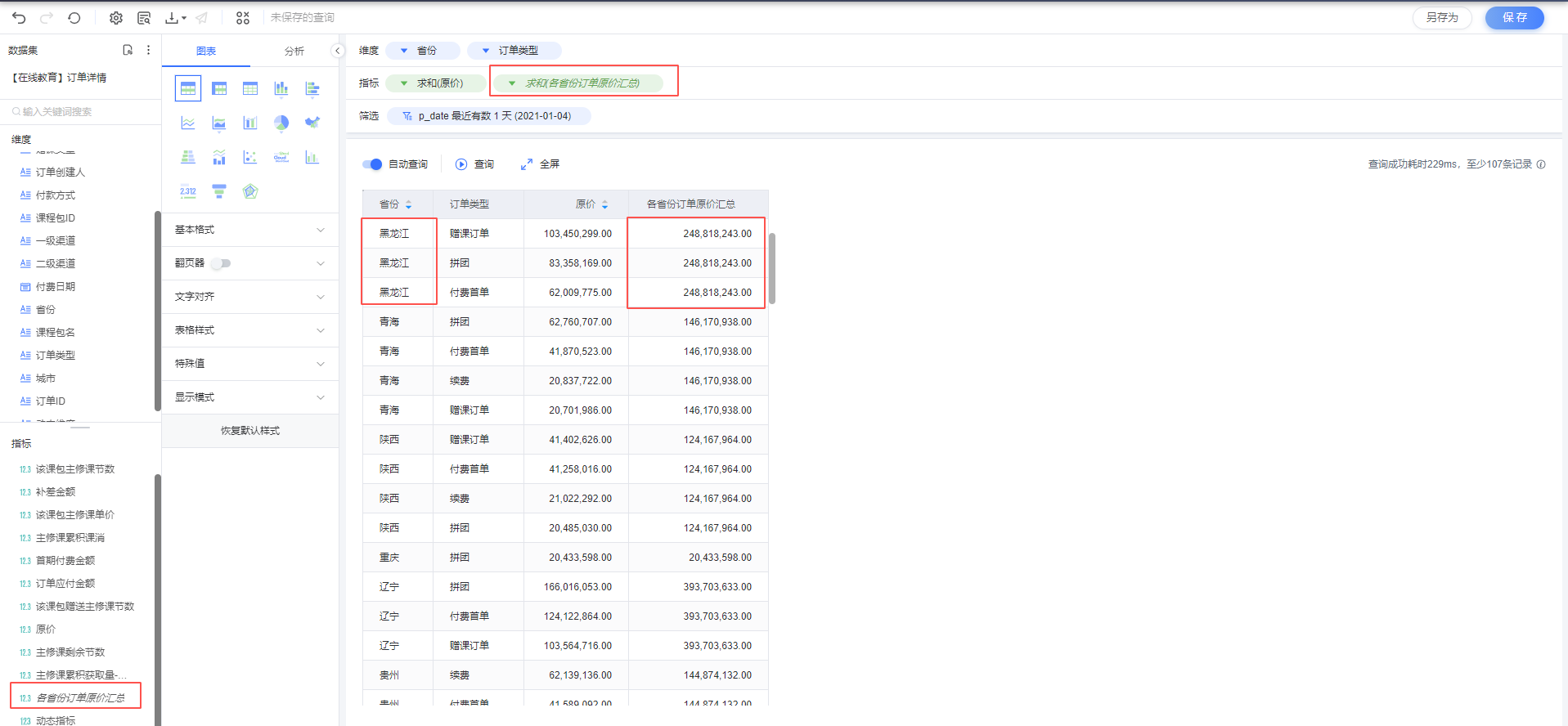
详细级别表达式具有以下结构: {[FIXED | INCLUDE | EXCLUDE] < 维度声明 > : < 聚合表达式 >} 示例:{INCLUDE [地区],[颜色]:sum([销售额])}
< 维度声明 >: 指定聚合表达式要联接到的一个或多个维度。使用逗号分隔各个维度。例如: [Segment], [Category], [Region]
< 聚合表达式 >: 聚合表达式是所执行的计算,一个聚合结果
4.1 FIXED
FIXED 详细级别表达式使用指定的维度计算值,而不引用视图中的维度。
希望明细筛选对计算生效? 推荐使用{filter=true:fixed <维度声明> : <聚合表达式>} filter=true 为非必填参数,可令筛选器里的维度和指标明细筛选对 fixed 函数中计算聚合表达式的时候生效
4.1.1 计算每个区域的销售额总和
{fixed [地区]:sum([销售额])} 维度为 [ 地区 ] 加 [ 省/自治区 ],但由于 FIXED 详细级别表达式不考虑视图详细级别,因此计算只使用计算中引用的维度,在本例中为 [ 地区 ]。出于此原因,您可能会看到各区中单个省/自治区的值是相同的。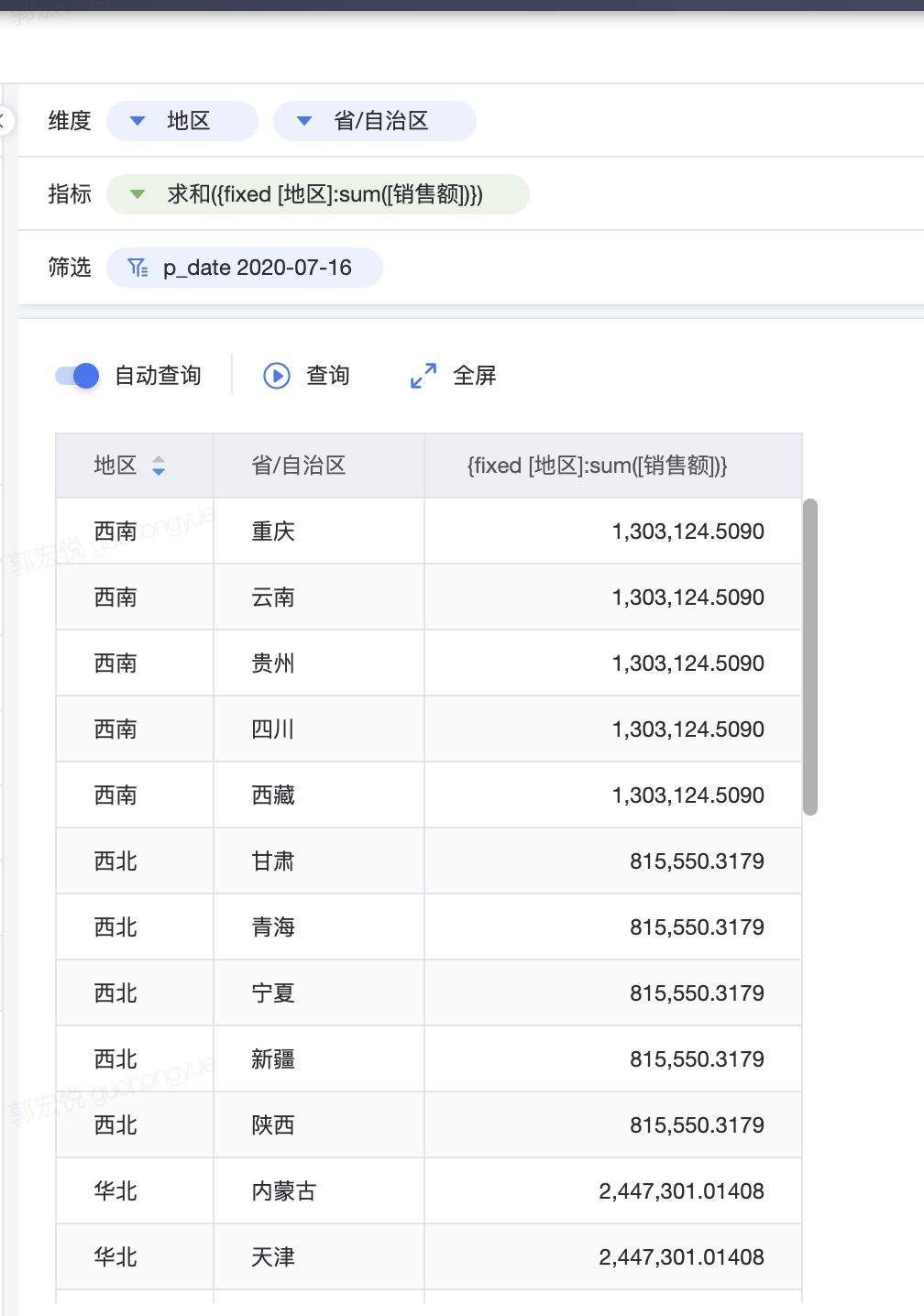
4.1.2 Fixed 作为维度,客户购买频次
我们经常会遇到“客户购买频次”分析,通过查看客户购买次数的数量和分布,来分析客户的复购黏性, 命题:客户的购买频率分布,即购买过一次、两次、三次……的顾客分别多少。
- 可视化焦点:不同购买次数下的顾客数量。
- 可视化维度:购买频次(1,2,3,N)
- 需要引用的背景信息:每个顾客的购买次数
- {fixed [客户 id]:uniq([订单 id])}
在视图中,我们使用了购买频次和顾客的计数。这是用一个数值去区分另一个数值,LOD fixed 可以轻松地把一个度量转化为维度,这是 include 和 exclude 不能做的。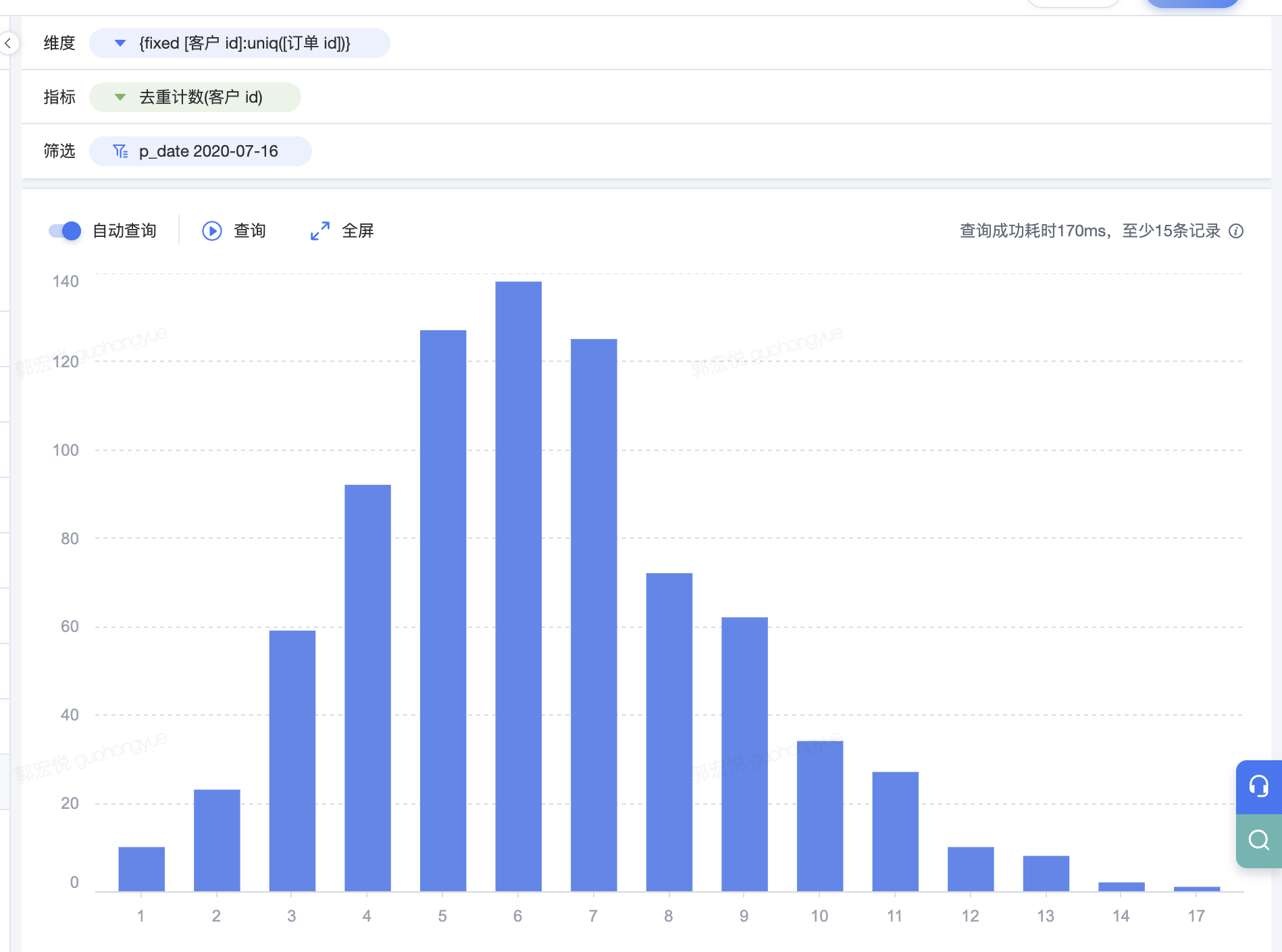
4.1.3 表范围详细级别表达式
“表范围详细级别表达式”只是省略了维度限定,其实就是没有维度声明的 fixed 详细级别表达式。因此,我们可以把“表范围详细级别表达式”视为最简单的详细级别表达式。 {avg([数量])} 在明细数据中全部数量的范围内,返回平均值 {sum([数量])} 在明细数据中全部数量的范围内,返回求和值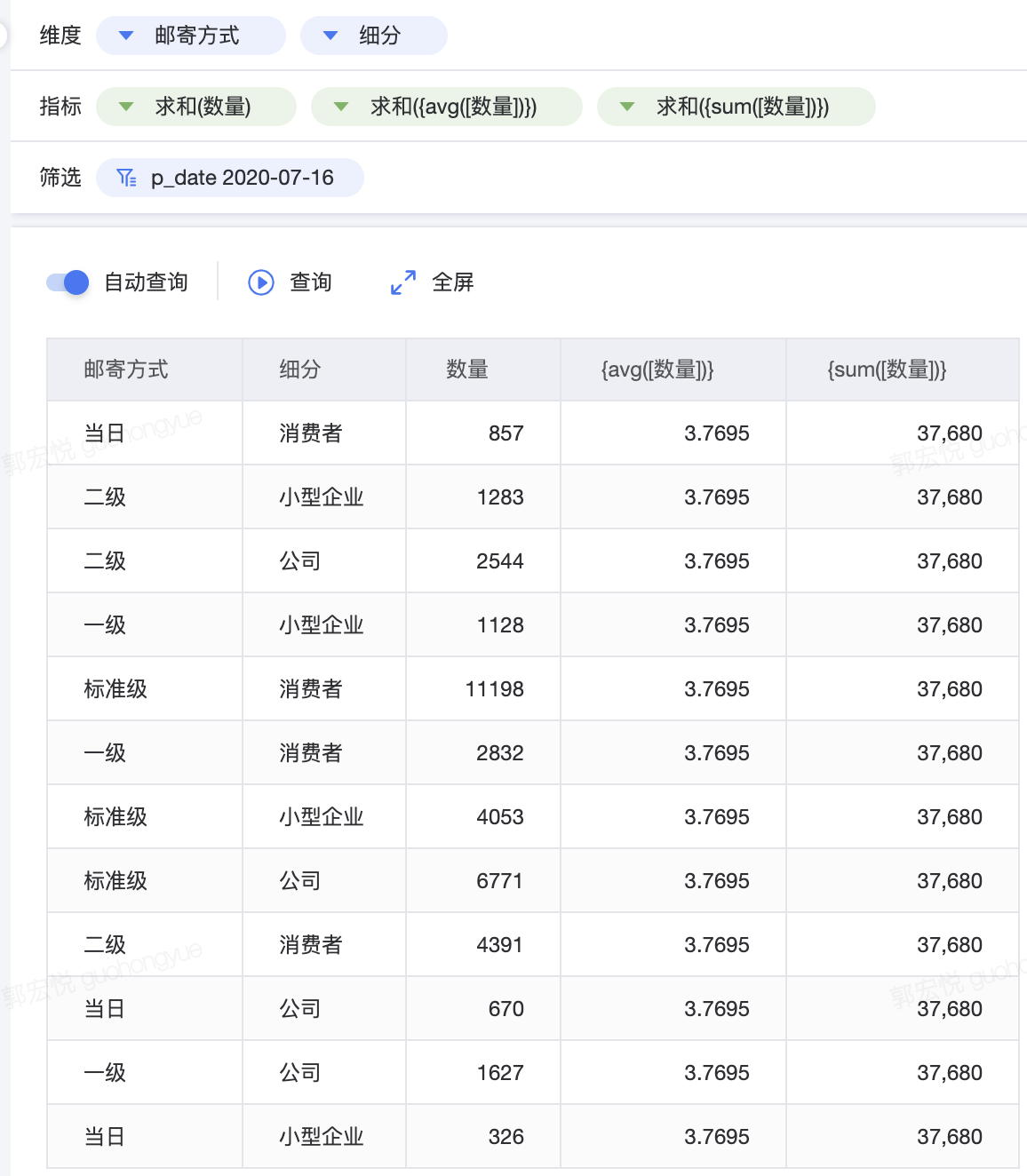
4.2 INCLUDE
INCLUDE函数可以对聚合函数进一步细分,更精准地进行计算。其包含两个参数,表达式为 {INCLUDE [维度a]:聚合函数([指标b])},意为根据维度a将指标b聚合计算。
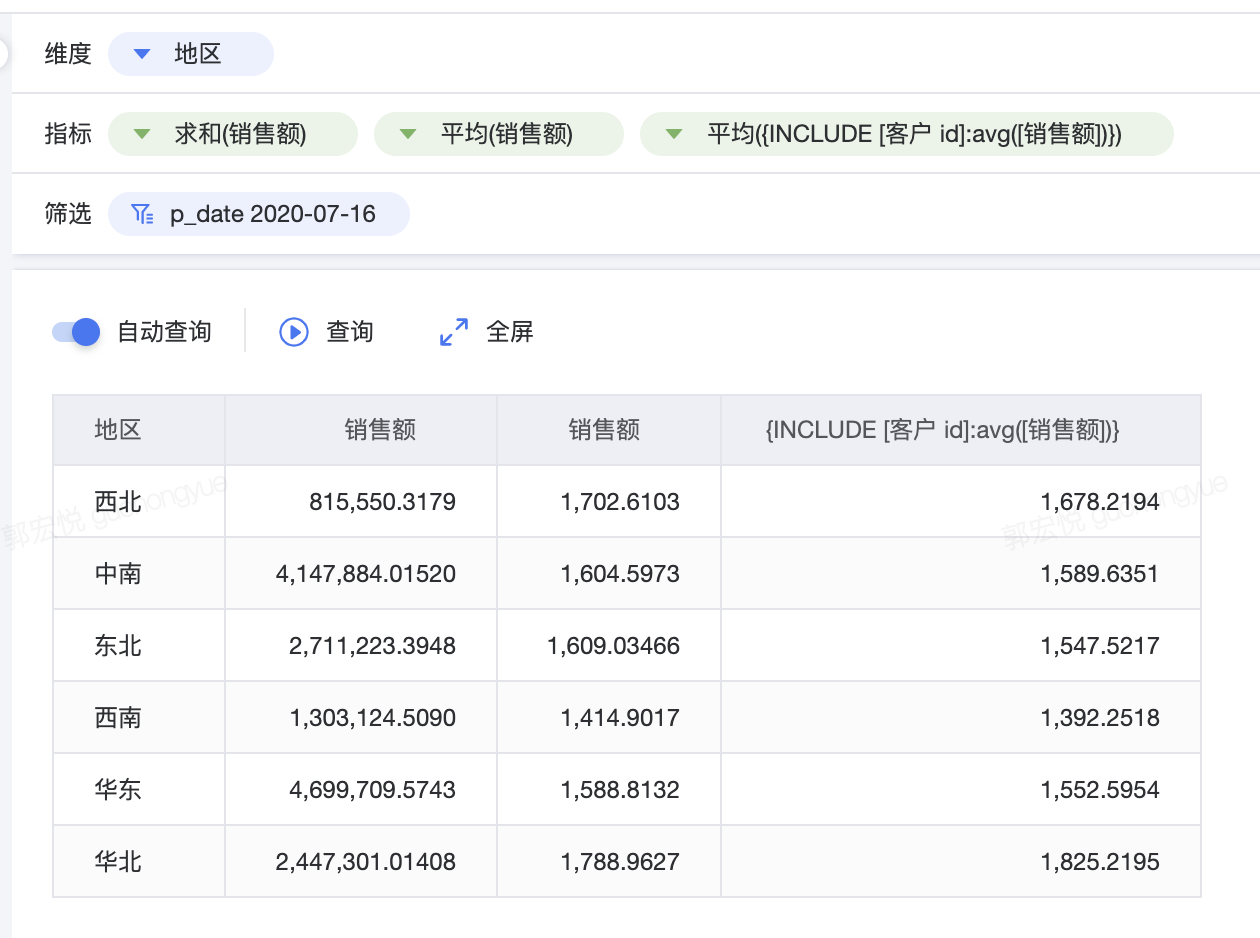
例如,表达式 {INCLUDE [客户 id]:avg([销售额])}意为,根据客户id计算平均销售额。在应用场景中,将[地区] 放到维度上,下图三个指标分别代表的含义为:
- 求和(销售额):每个地区的销售额总和
- 平均(销售额):各个地区的平均销售额(销售总和/订单总数)
- 平均({INCLUDE [客户 id]:avg([销售额])}):每个地区的平均客户销售额。在计算过程中,首先计算出每个客户的平均销售额(该客户销售总额/该客户订单数量),再对该地区中每个客户的销售额求算术平均(平均销售额加总/客户数量)
以东北为例,先计算东北里面每个客户id对应的平均销售额,再计算东北里面全部客户平均销售额的平均值为1547.5217。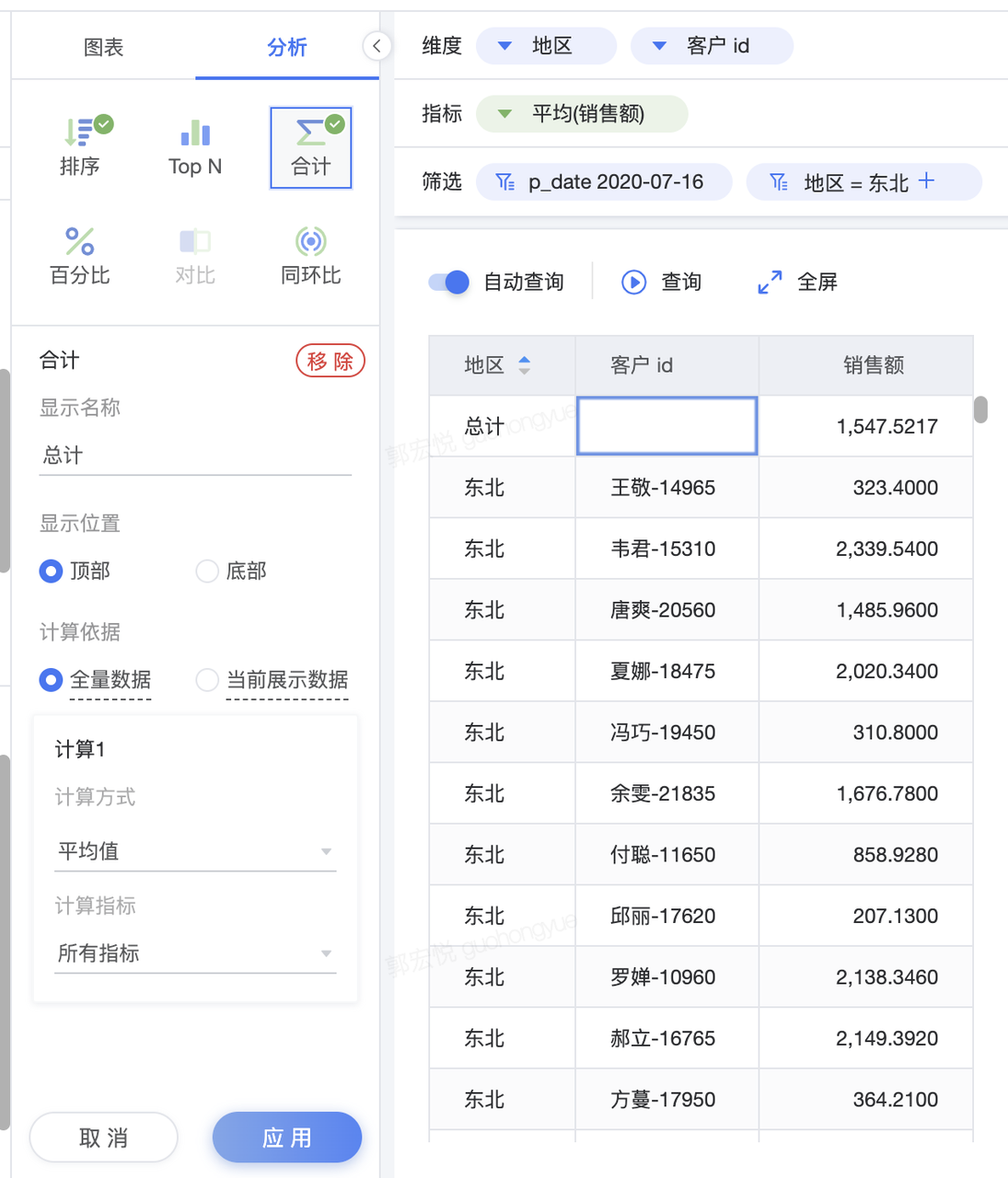
4.3 EXCLUDE
EXCLUDE 详细级别表达式声明要从视图详细级别中忽略的维度。 EXCLUDE 详细级别表达式对于“占总计百分比”或“与总体平均值的差异”方案非常有用。 以下详细级别表达式从 [销售额] 的总和计算中排除 [省/自治区]: {exclude [省/自治区]:sum([销售额])}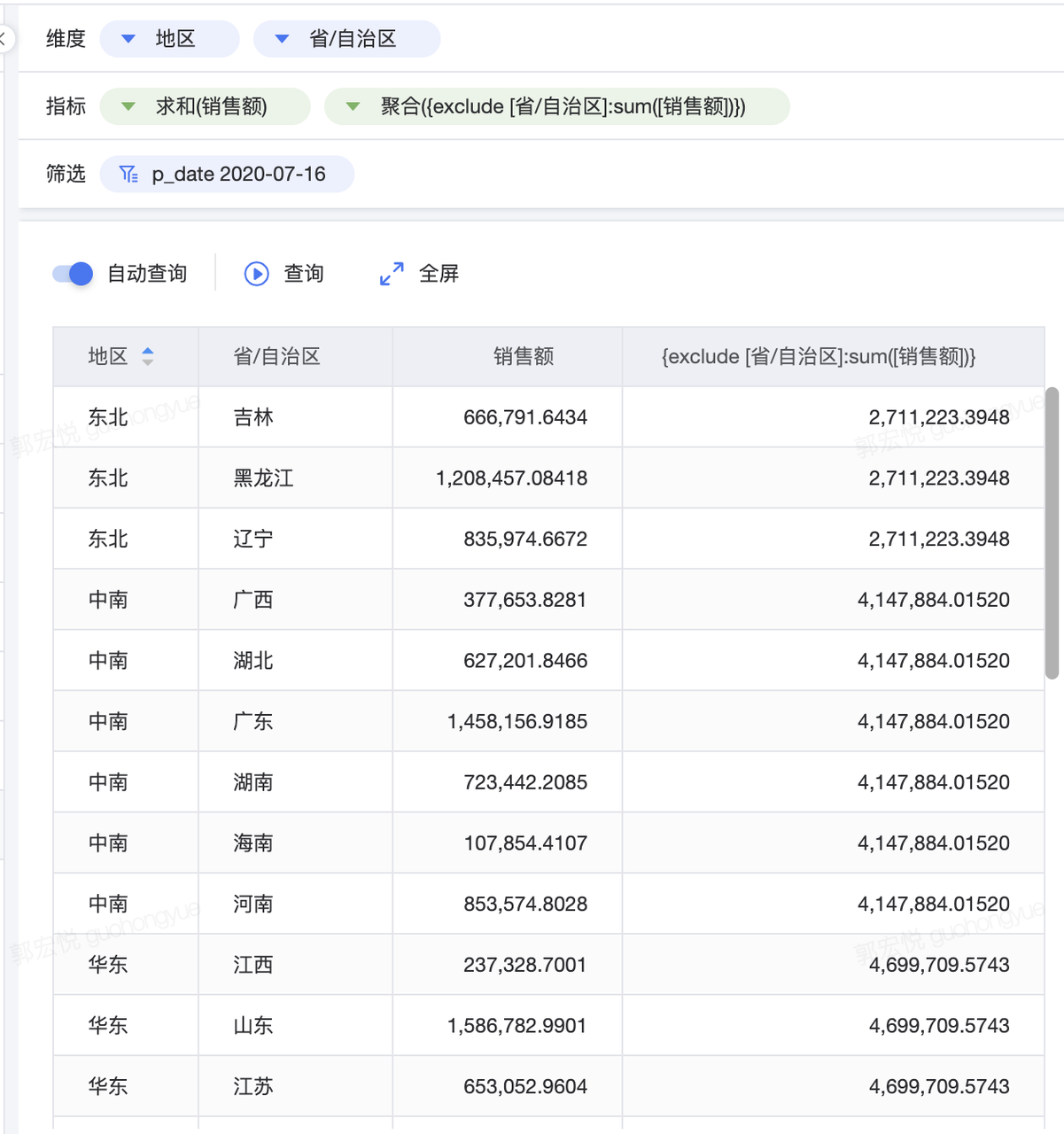
{exclude [省/自治区]:sum([销售额])}为对应地区的销售额总和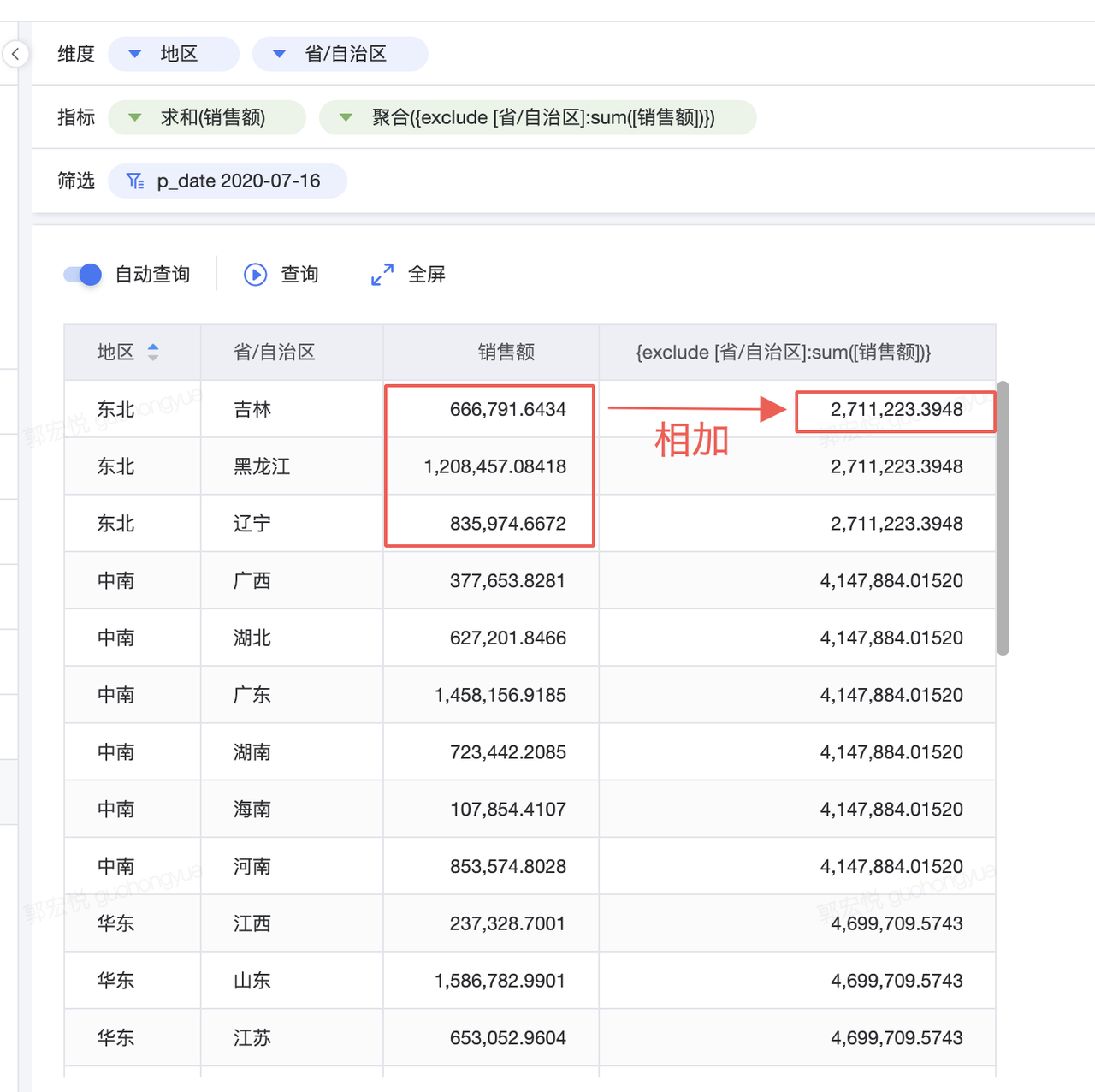
5.1 LOD 函数作为指标
表达式 |
|---|
sum({include |
sum({include [地区]:sum([销售额])}) |
sum({include [地区]:avg([销售额])}) |
sum({fixed [地区]:avg([销售额])}) |
sum({exclude [地区]:avg([销售额])}) |
sum({avg( |
sum({fixed:avg( |
sum({include [地区]:sum([销售额])+sum([数量])}) |
sum({fixed [地区]:sum([销售额])+avg([数量])}) |
avg({ include case when [细分]='公司' then 1 else 0 end: sum([销售额])+max([数量])}) |
sum({fixed [地区]:avg([销售额])}+[折扣]) |
sum({include [地区]:avg([销售额])}+[折扣]) |
5.2 Fixed 作为维度
表达式 |
|---|
{fixed [地区]:avg([销售额])} |
{ fixed case when [细分]='公司' then 1 else 0 end: sum([销售额])+max([数量])} |
{ fixed case when [细分]='公司' then 1 else 0 end: sum([销售额])} |
{ fixed case when [细分]='公司' then 1 else 0 end: sum([销售额])} |
6.1 计算最大值之和
6.1.1 场景示例
在进行机房配额管理时,需要 按照 psm 分组 ,获取 psm 下 各机房近 7 天的容量最大值 ,并按照 psm进 行 分组求这个最大值之和,同时展现最大值总和 ,以评估各 psm 和机房总配额容量。
针对此类需要二次聚合的场景,可以使用 LOD 函数进行处理。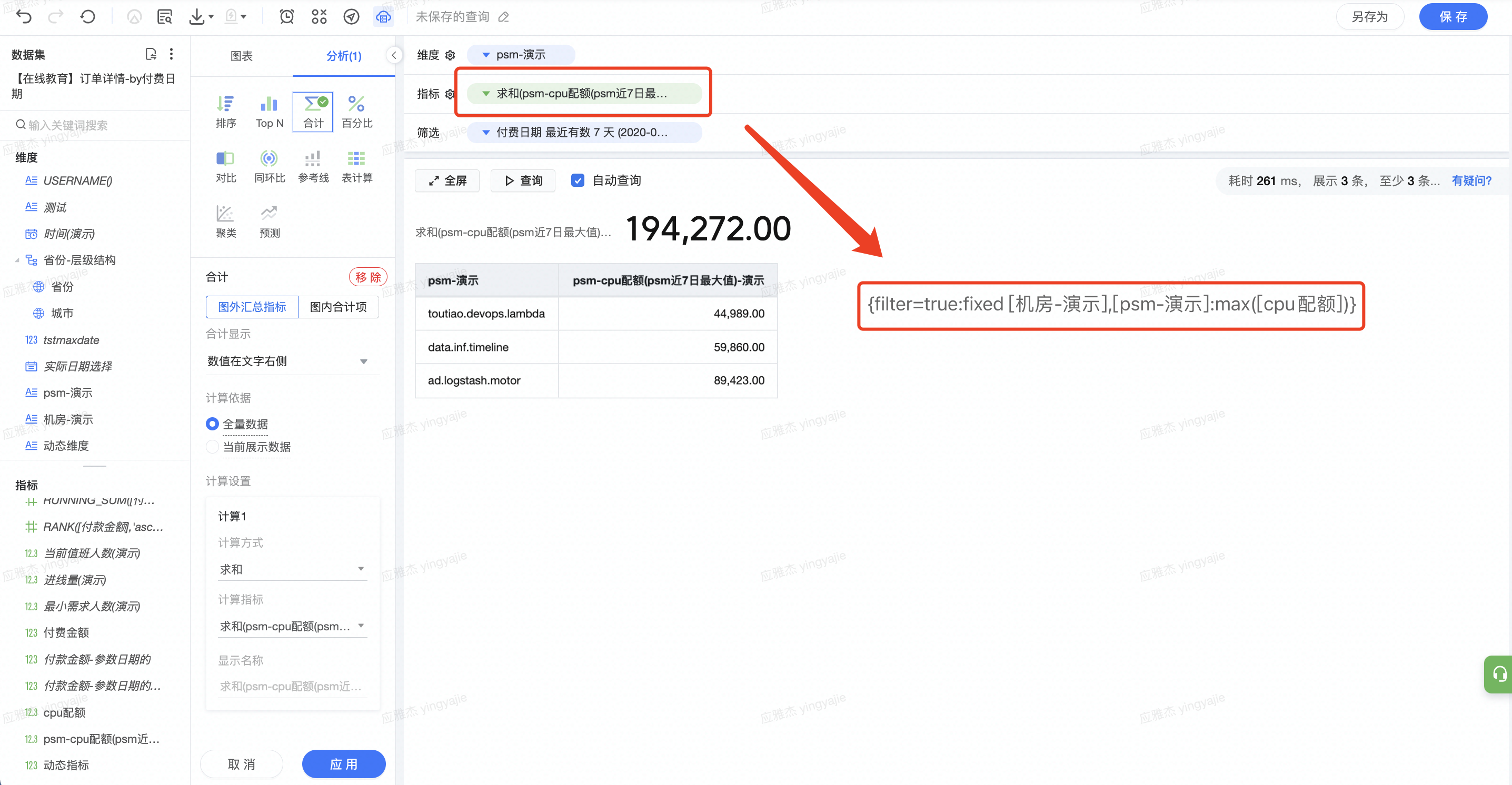
6.1.2 设计思路
本案例中,已有每天各 psm 各机房的配额数据,但使用资源每天会波动,而保险起见,实际给予的配额应大于近 7 天的最大资源配额(每个 psm 下有多个机房)。
因此在本案例中,聚合的思路如下:
(1)筛选近 7 日数据,根据 psm 和机房聚合, 计算 7 日内机房粒度的配额最大值
(2)根据 psm 聚合,计算各机房配额,即上述最大值的求和值
(3)通过合计功能,计算总配额
6.1.3 操作步骤
(1)计算 7 日内机房粒度的配额最大值
已有机房、psm、每日配额字段,使用 LOD 函数,将日期筛选设定在最近有数 7 天,计算出 7 日内机房粒度的配额最大值,并保存为指标字段。
表达式如下:
{fixed [机房-演示],[psm-演示]:max([cpu配额])}
解读:依据机房和 psm 字段聚合,求 cpu 配额字段的最大值。由于筛选选定了最近 7 天,所以求出结果为最近 7 天的最大值。
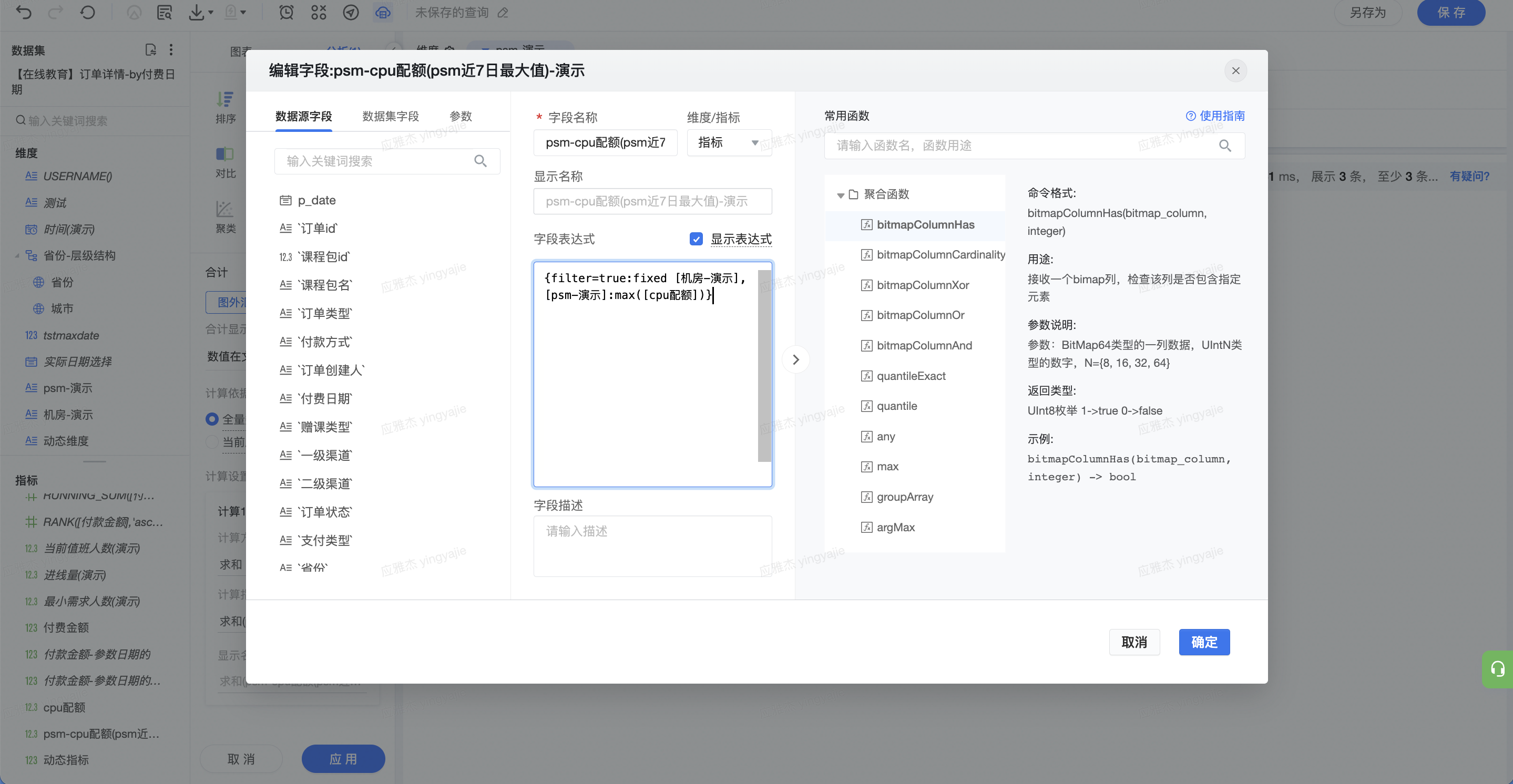
(2)设为指标
维度选择 psm,拖拽上述字段到指标栏,聚合方式选择“求和”,求各 psm 的应有配额。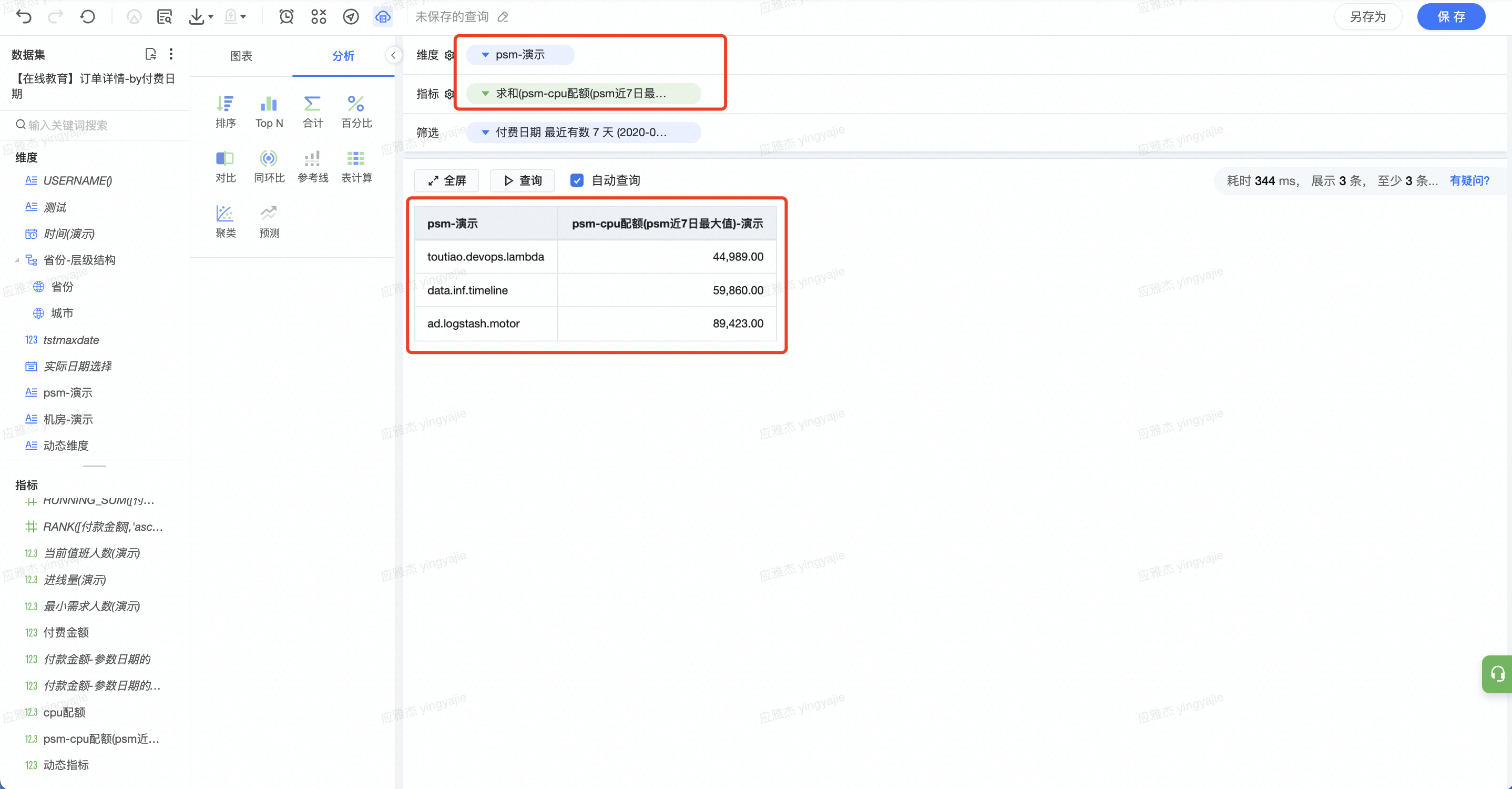
(3)计算总配额
使用「合计」功能,对各 psm 总配额求和,显示在图表上方。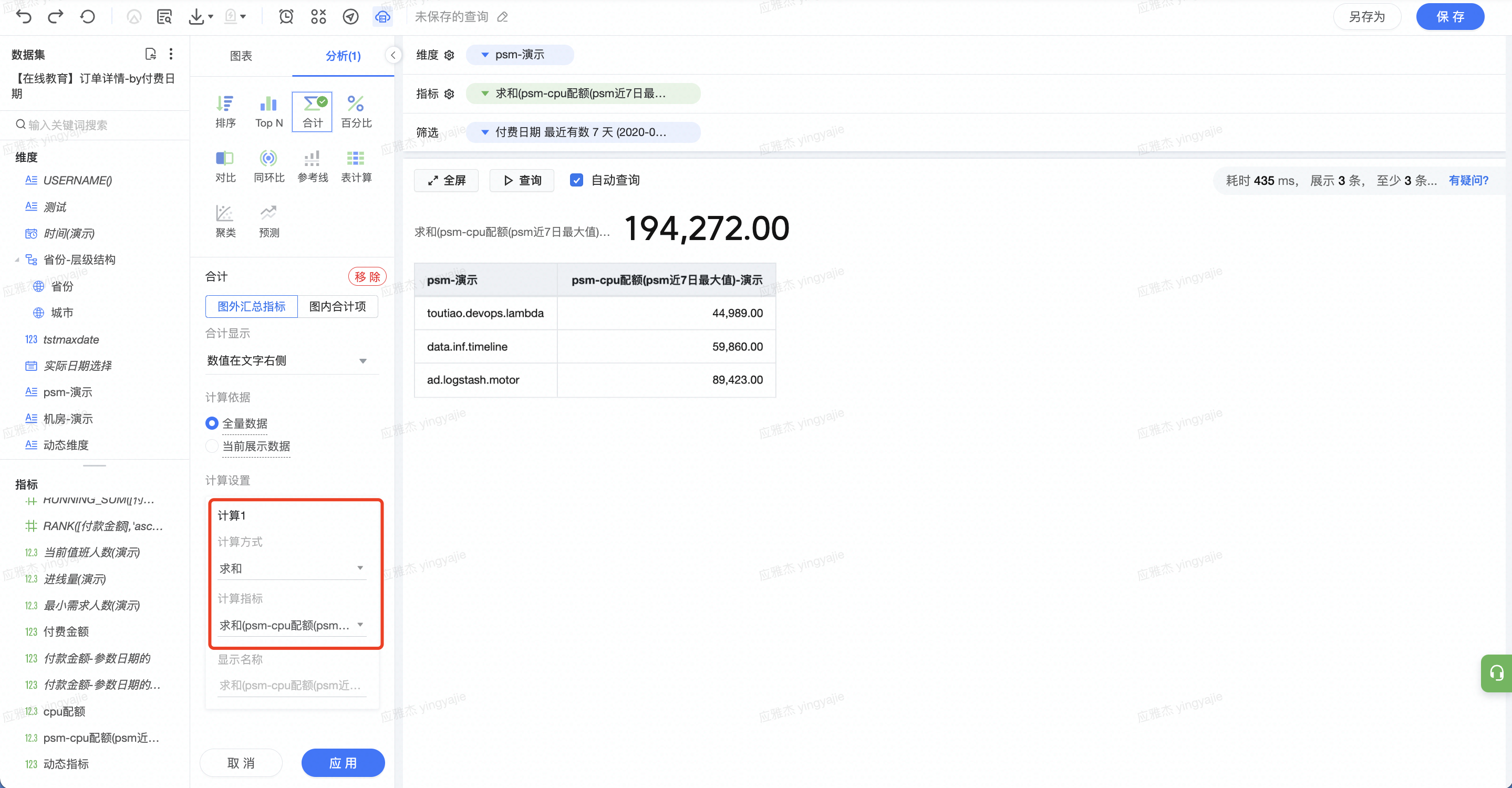
6.2 指定聚合维度,查看数值分布
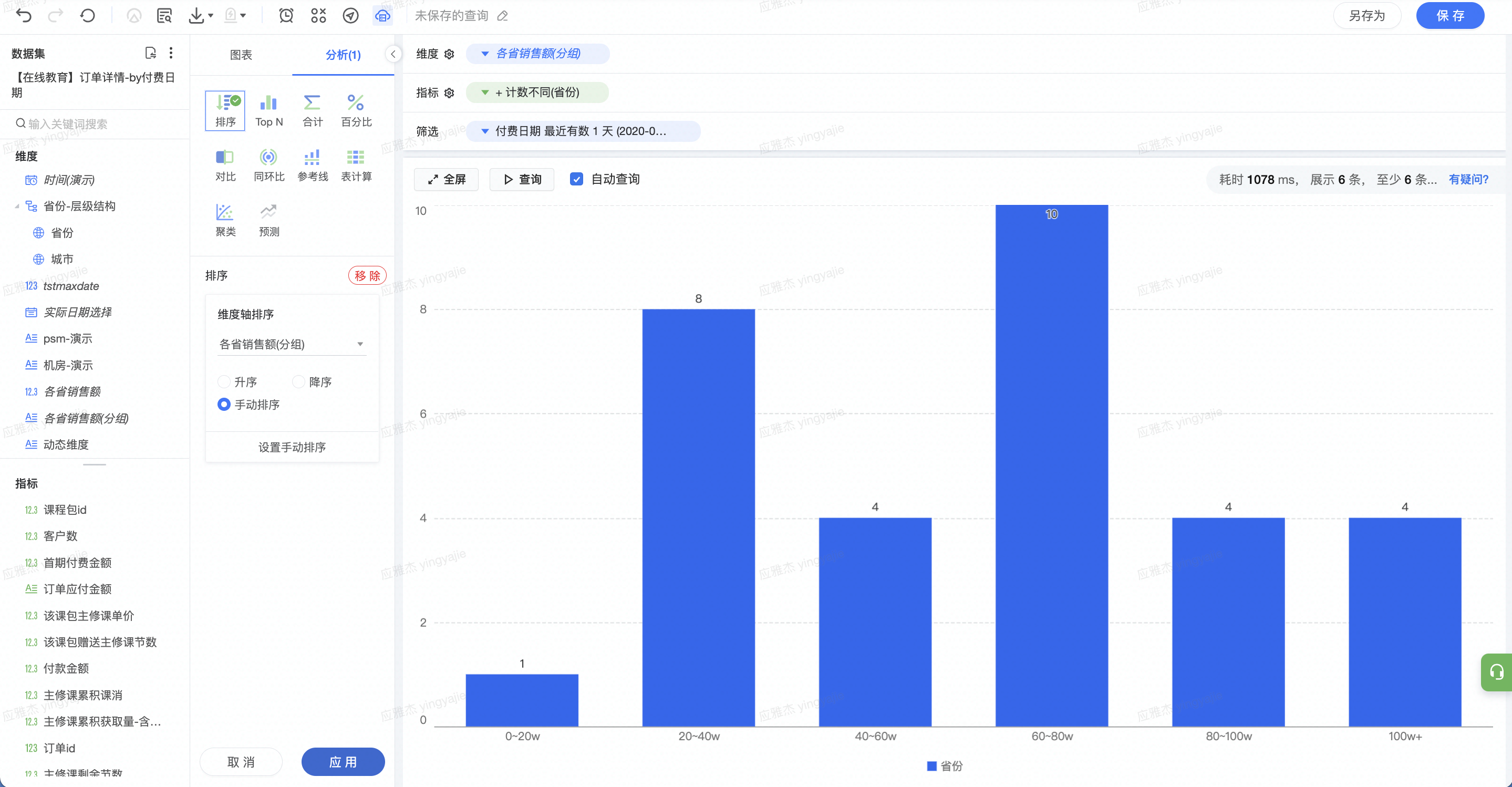
6.2.1 场景示例
背景 : 如图所示为一张订单粒度的数据集,具有每笔订单的详情数据,包括订单 ID、订单发生的省份、订单金额等。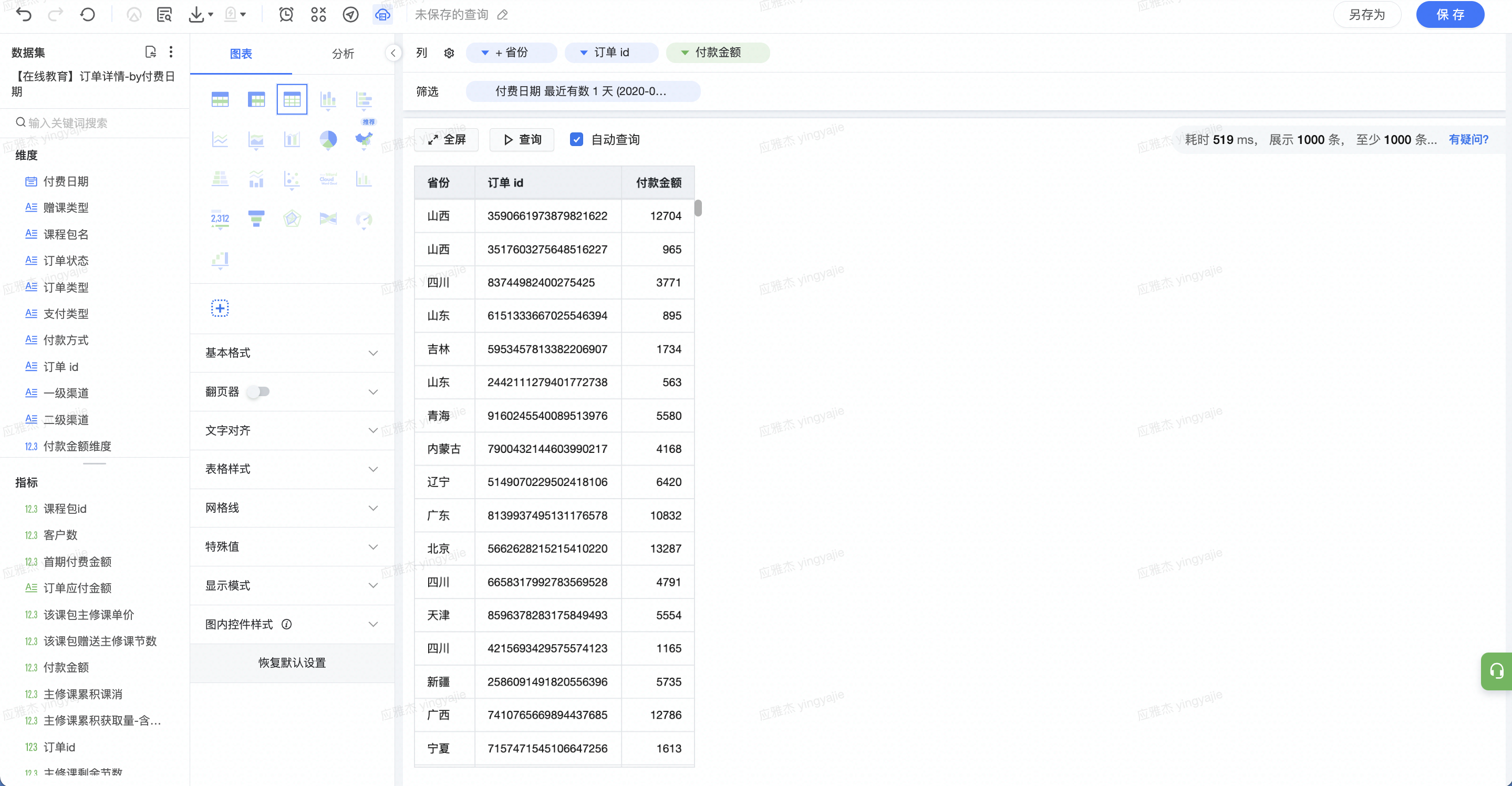
需求 : 根据省份聚合,计算各省份的总销售额(付款金额之和),并查看此数据(即各省销售额)的分布。分布:查看在0(20w、20)40w、40(60w、60)80w、80~100w、100w以上这些区间内的分布,即销售额在这些区间内的省份数量。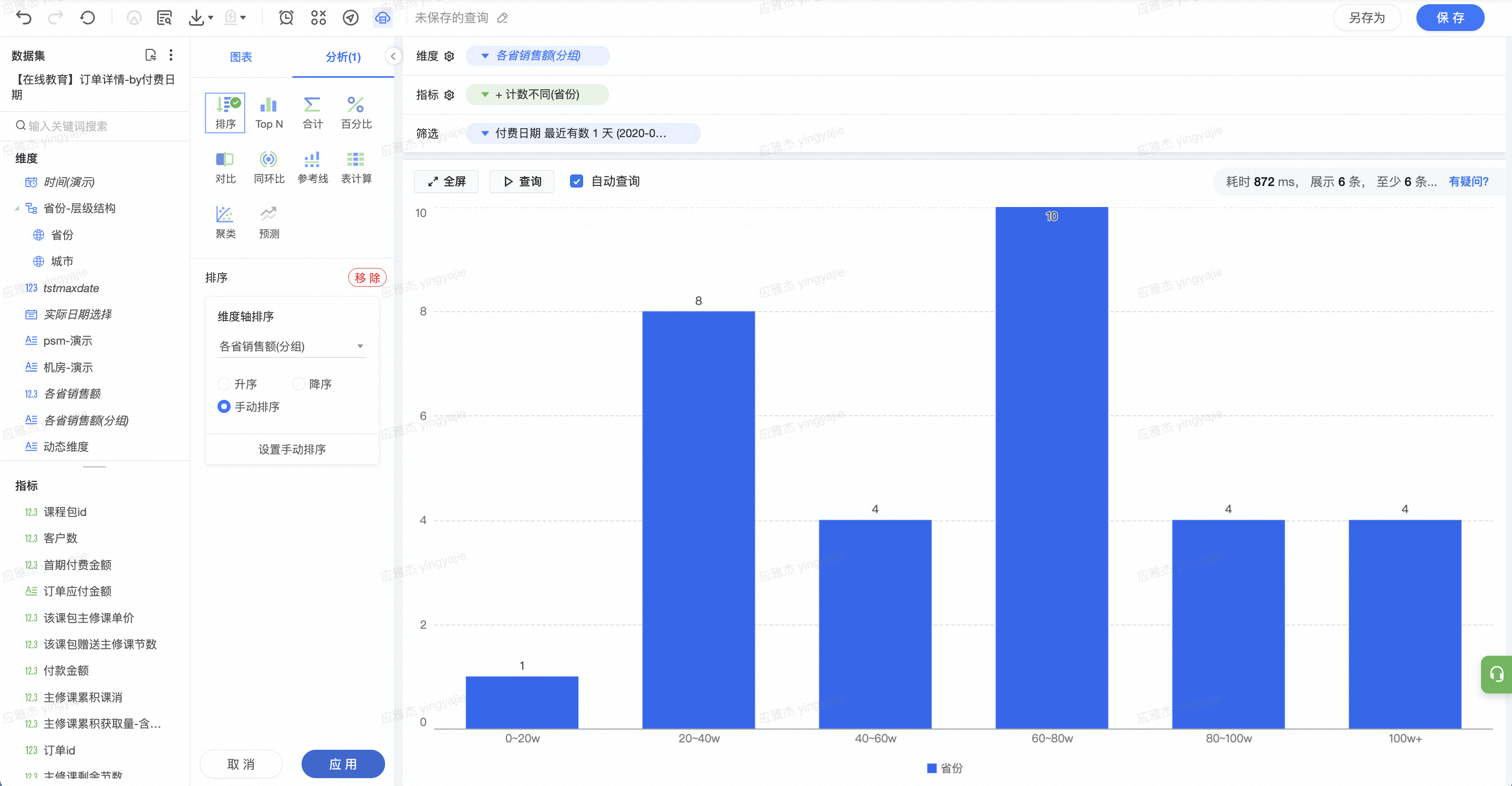
6.2.2 设计思路
本案例的难点在于,数据集是订单粒度的,而需求查看的分布数据是省份粒度。因此需要依据省份聚合后,再做二次处理,查看分布数据。
聚合的思路如下:
(1)指定依据省份维度,求付款金额之和,形成「各省付款金额」字段
(2)利用分组功能,对各省付款金额分段:0(20w、20)40w、40(60w、60)80w、80~100w、100w
(3)将分段后的各省付款金额字段作为维度,计算省份的去重计数值,即省份数
6.2.3 操作步骤
(1)新建「各省付款金额」字段
指定依据[省份]维度,求[付款金额]之和, 并保存为维度 。表达式为:
{fixed [省份]: sum([付款金额])}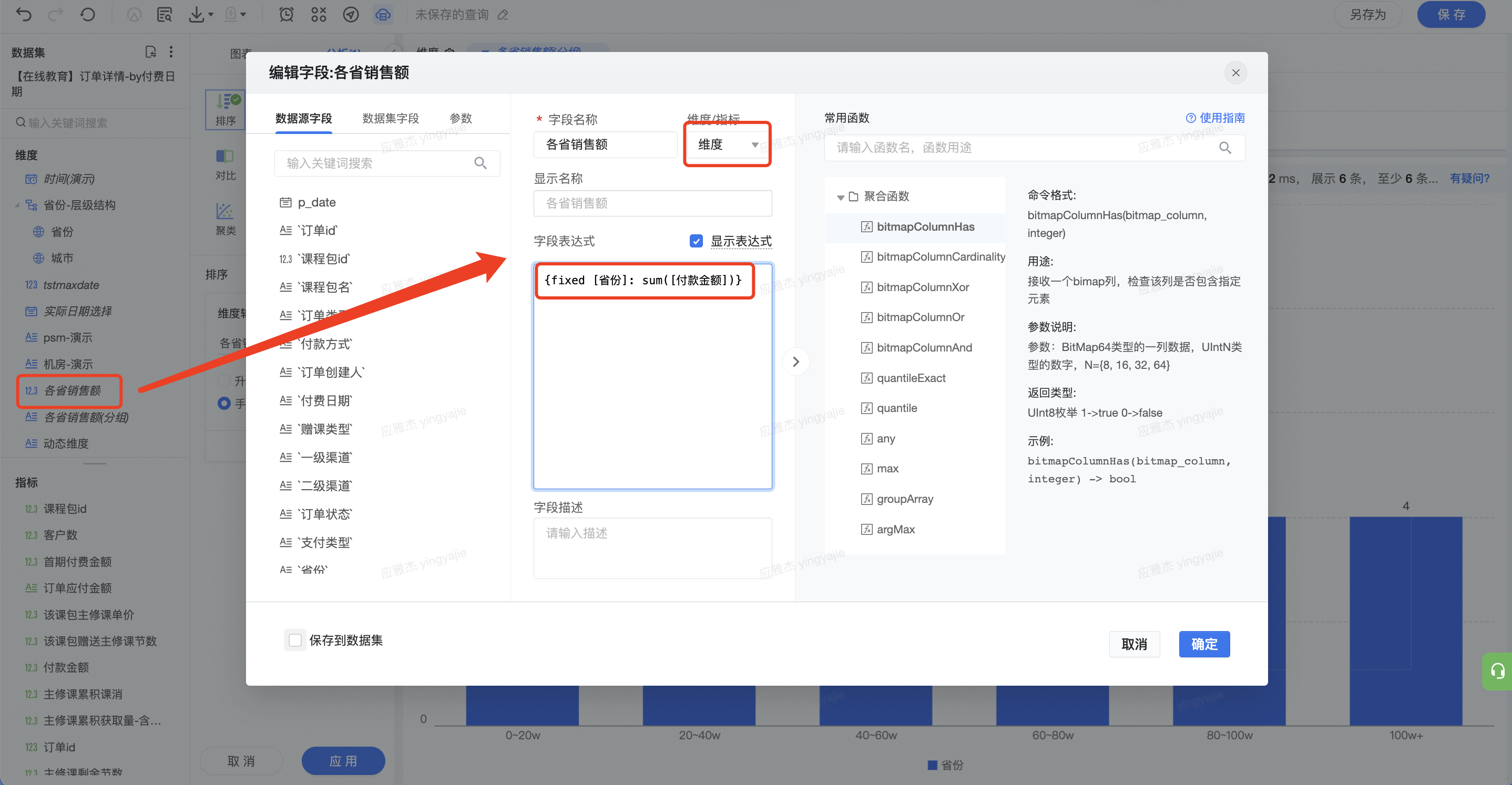
(2)对各省付款金额分段
选择字段并「创建组」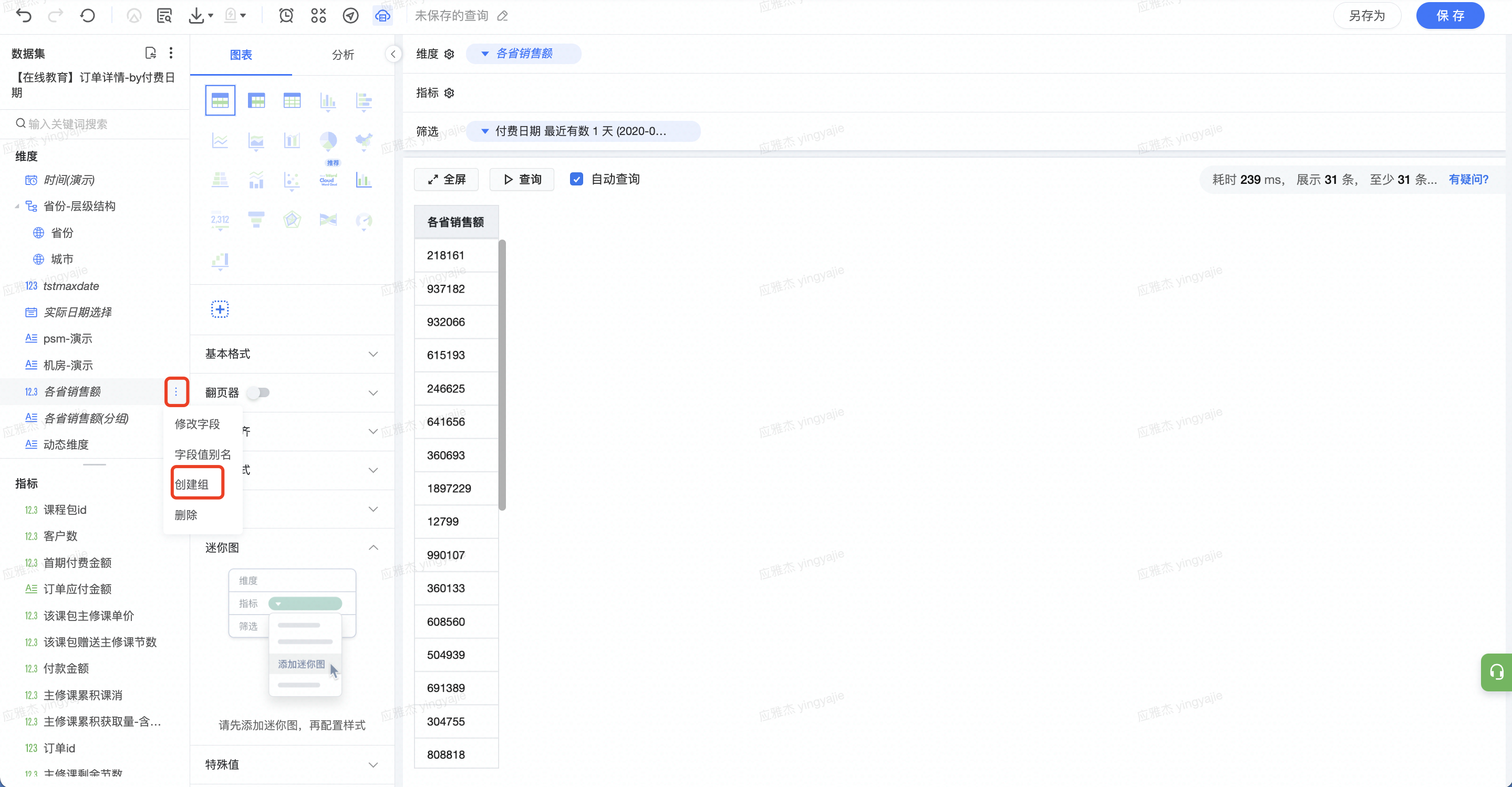
按照步长分组,根据需求设置每个组的名称和条件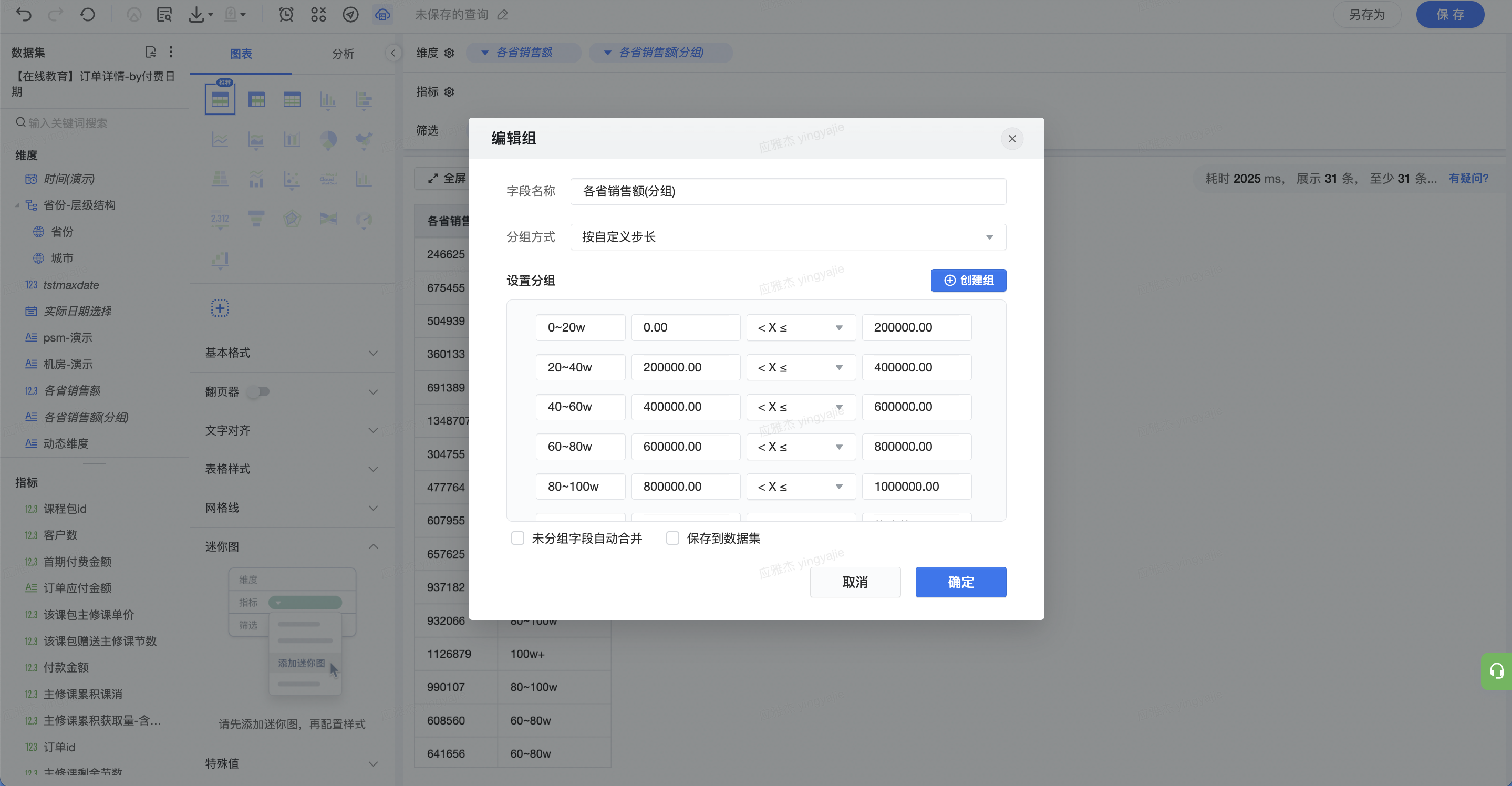
(3)计算各分段的省份数
将上述分组字段作为维度,拖拽「省份」字段到指标栏,聚合方式选择为“去重计数”作为指标。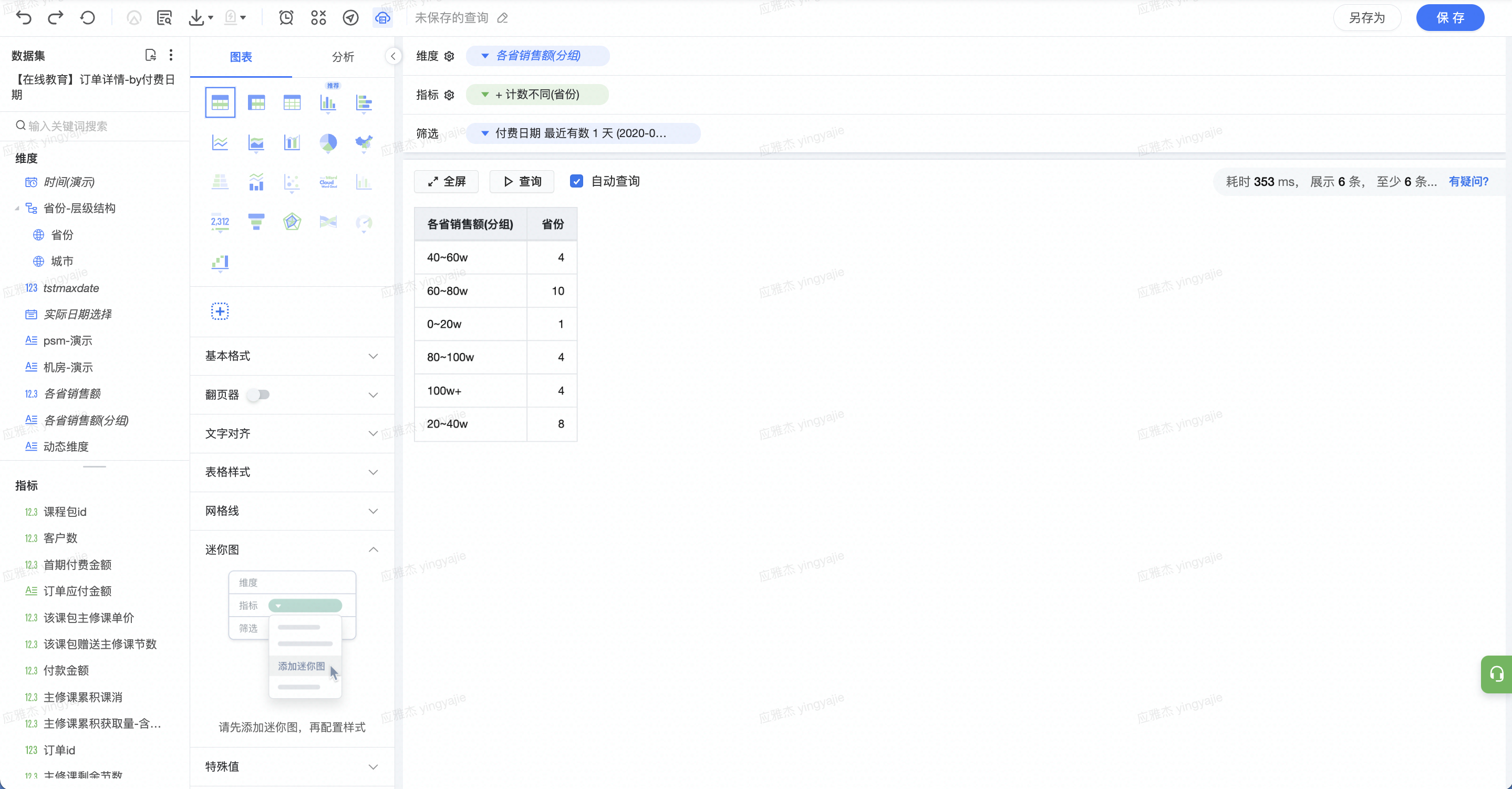
图表类型选择为柱状图,并设置好排序。