场景描述
当前硬件设备正以前所未有的速度智能化升级,成为人工智能领域成长最快的赛道之一。AI 与硬件的结合正逐渐渗透到我们生活的方方面面,如陪伴类机器人,智能家居、教育硬件以及智能穿戴设备等。
火山引擎 RTC 与嵌入式芯片厂商合作内置一站式解决方案,可实现音视频数据的高效传输,并在云端深度整合大模型、 语音识别、语音合成等人工智能技术,企业只需通过简洁的 API 接口,即可调用云端智能体,实现适配硬件设备的 AI 实时通话服务。
技术方案
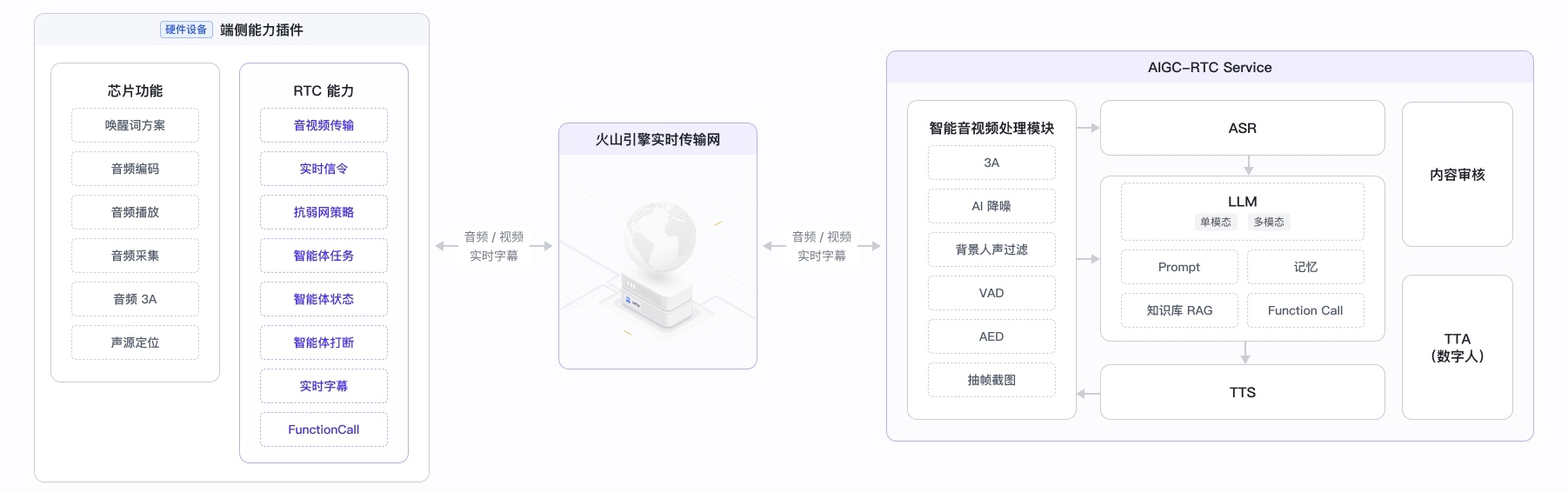
在端侧,芯片集成其先进的音频处理,包括自动唤醒功能和音频3A(自动增益控制、噪声抑制、回声消除)等,保证音频输入的清晰度和准确性。云端的智能体服务则提供 Function calling 和知识库支持,使得硬件设备能够提供个性化服务和智能决策,满足用户的深层次需求。
核心功能
| 功能 | 场景应用 |
|---|---|
| 实时音频互动 | 流式传输技术可以确保语音和视频数据的连续性和稳定性,减少延迟和抖动,提供接近于真人的高质量互动。 |
| 语音识别(ASR) | 提供火山引擎大模型和小模型识别能力,拥有超高的准确率,可复杂场景下通话,提供更类真人的交互体验。 |
大语言模型(LLM) | 提供火山引擎和其他第三方 LLM 厂商接入,能够更好地理解对话的上下文,从而实现连贯的对话交流。 |
| 语音合成(TTS) | 提供火山引擎和其他第三方 TTS 厂商接入,生成符合要求的音色进行互动。根据上下文,智能预测文本的情绪、语调等信息。并生成超自然、高保真、个性化的语音,以满足不同用户的个性化需求。 |
| 智能打断 | 用户无需通过按键或其他输入方式,即可享受自然流畅的双向通话体验。毫秒级人声检测和打断响应,支持随时精准打断,让交流更加灵活。 |
实时响应 | 在保持极低功耗的同时,实现端到端响应延时可低至1秒,为用户提供了实时的交互体验,让沟通更加丝滑。 |
| Function Calling | 允许大模型识别用户对话中的特定需求,并在内容的过程中调用外部函数或 API,来执行它自身无法独立完成的任务,如处理实时数据检索、文件处理、数据库查询等。 |
| 弱网卡顿优化 | 即使在网络条件不佳,丢包率高达80%的情况下,够保证通话的稳定性,确保语义信息的完整传输,不丢失任何重要内容。 |
| 多平台支持 | 嵌入式Linux、RTOS、Android 等常见硬件全平台支持 |
构建流程
嵌入式 Linux 以及 RTOS 相关系统的设备端 SDK 请联系技术支持获取。
对话式 AI 服务端 demo 示例代码可参考开源嵌入式硬件解决方案。
前提条件:
开始前,你需要参看开通服务和 获取临时 Token 开通需要服务、配置策略并获取 Token。
构建嵌入式硬件的基本流程如下:
开启智能体任务
在嵌入式硬件唤醒准备通话时你需要开启智能体任务:
你需要在服务端生成 token 以便后续嵌入式硬件进入房间。生成 Token 逻辑参看使用 Token 完成鉴权。
你需要传入 AppId,RoomId,嵌入式硬件对应 UserId 等参数开启智能体任务。智能体详细参数请查看启动智能体 StartVoiceChat。在实现智能体调用相关逻辑前,你可前往线上调试工具 APIExplorer先进行调试。
// demo中封装好了启动智能体的函数 ... int start_ret = start_voice_bot(room_info); ...
采集并编码音视频信号
你需要使用与设备适配的原生库实现音视频信号采集与编码。
音频编码格式默认为 OPUS,如需 G711A、 AAC、或 G722 格式请联系技术支持加白。视频编码格式为 H.264 或 ByteVC1。
嵌入式硬件客户端进房
你需要调用 byte_rtc_create 创建引擎,调用 byte_rtc_init初始化引擎示例,调用byte_rtc_set_audio_codec 设置音频编码格式,调用 byte_rtc_set_video_codec 设置视频编码格式,并调用 byte_rtc_join_room 加入房间。
硬件客户端 RoomId、UserId 必须与开启智能体任务时传入的值一致才能互通。
进行双向通话
在进行双向通话期间,在业务端通过 byte_rtc_send_audio_data 将采集到的音频信息传给智能体进行对话,默认 20ms 发送一次编码后的音频数据,硬件设备自动订阅对话消息。
如对话过程中调用 UpdateVoiceChat 进行打断操作,或使用 Function calling 功能,通过 byte_rtc_rts_send_message 发送实时信令信息。
此外在通话期间可通过 on_message_received 收到字幕消息。
结束通话
你需调用 byte_rtc_leave_room 接口退出房间,调用 byte_rtc_destory 销毁引擎示例,并在服务端调用StopVoiceChat 接口关闭智能体。
体验示例
火山引擎与乐鑫等芯片厂商联合开源嵌入式硬件解决方案,详情请查看开源嵌入式硬件解决方案