1 前言
EMR存算分离是一种逐渐被人们广泛接受的弹性低成本的产品形态。更多关于火山EMR存算分离的信息,请参考 Proton 概述。
由于TOS对象存储自身语义与HDFS语义存在部分差异。这些差异主要体现在:
- TOS 对象存储的 Rename (包括目录和文件)比较耗时,且通常模拟Rename的实现无法保证原子性和性能。
- TOS 对象存储的 List 操作相对 HDFS 比较耗时。
因此,火山EMR团队针对EMR存算分离场景对大数据的写入流程做了适当优化,使得EMR写入TOS在性能和一致性方面都可以媲美HDFS存算一体场景。EMR在写入路径上最核心的优化点就是 Hadoop Job Committer 的定制化实现。
2 什么是 Job Committer
对于一个MR作业来说,整体的写入逻辑如下所示: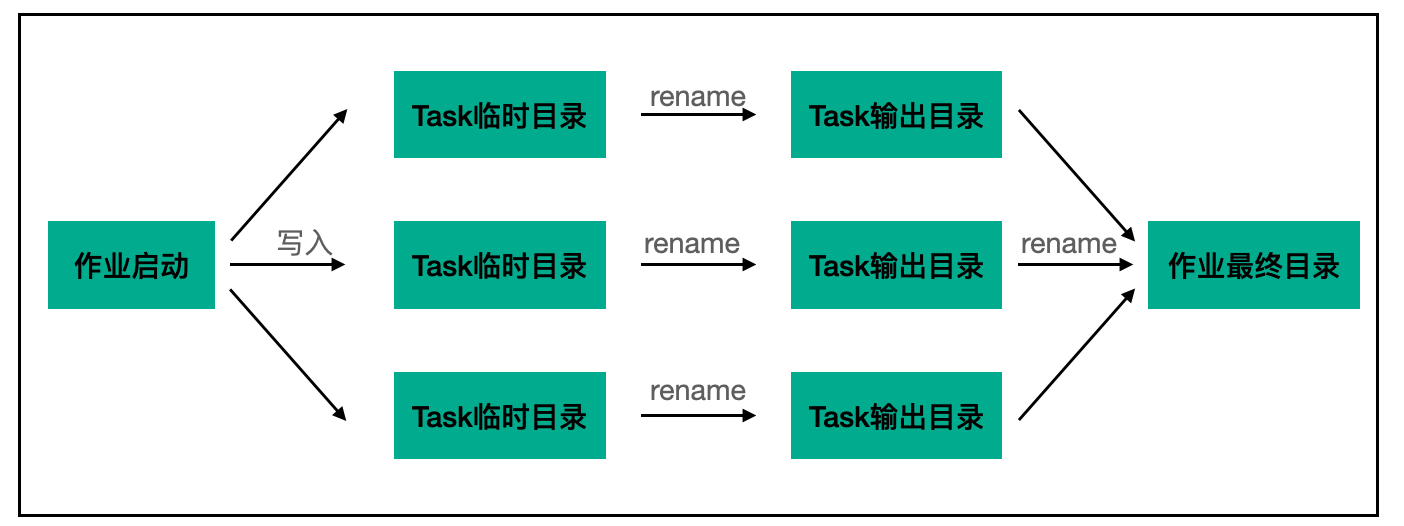
引擎会先写入数据到临时目录,等待数据写入完成后,使用rename命令将数据移动到最终目录下,在HDFS场景下,由于rename操作仅仅涉及元数据的变更,在NameNode中即可完成,因此时间复杂度是O(1),几乎不存在特别大的时间开销。
但在对象存储下,由于没有rename语义,当要实现rename行为时,只能借助象存储提供的copy+delete 能力组合完成,意味着当需要对一个大文件进行rename时,在对象存储中是先将此文件进行拷贝,再删除原文件,相比于HDFS来说,多了一次完整的文件写入时间。
因此如果不做任何优化,使用对象存储作为存储介质,相比于HDFS在性能上将会慢一倍以上,Job Committer便是在这个背景,提升写入对象存储速度的一种手段。
Job Committer借助了对象存储的MPU(MultipartUpload)能力,将一个大文件切分成多个分片,给每一个分片编号,并行上传,当所有分片上传完成后,让整个文件可见。
MultipartUpload相关的语义主要包括:
- CreateMultipartUpload: 在向一个key写入数据之前,需要先创建/注册一个Upload请求,获取对应的uploadID,一个key的写入,可能存在多个并发Upload写入,但最终结果只会取某一个Upload的数据。
- UploadPart: 发起UploadPart请求写入,一次Upload写入操作,可以有多个不同UploadPart写入操作组成,每次UploadPart写入请求包含key的path,uploadId,当前part number,当前part数据。
- AbortUpload: 某一次Upload写入过程中的每个UploadPart写入可能存在失败的场景,可以显式调用AbortUpload丢弃某一次Upload写入的内容。
- CompleteUpload: 当前Upload的所有UploadPart写入成功之后,会调用CompleteUpload将多次UploadPart的数据排序合并,并写入到key中。
借助MPU能力,可以避免文件在写入过程中,尚未写完的文件被读取到,因此就不需要写临时目录,可以直接写最终目录,在Job Committer的流程下,MR作业的写入流程优化为: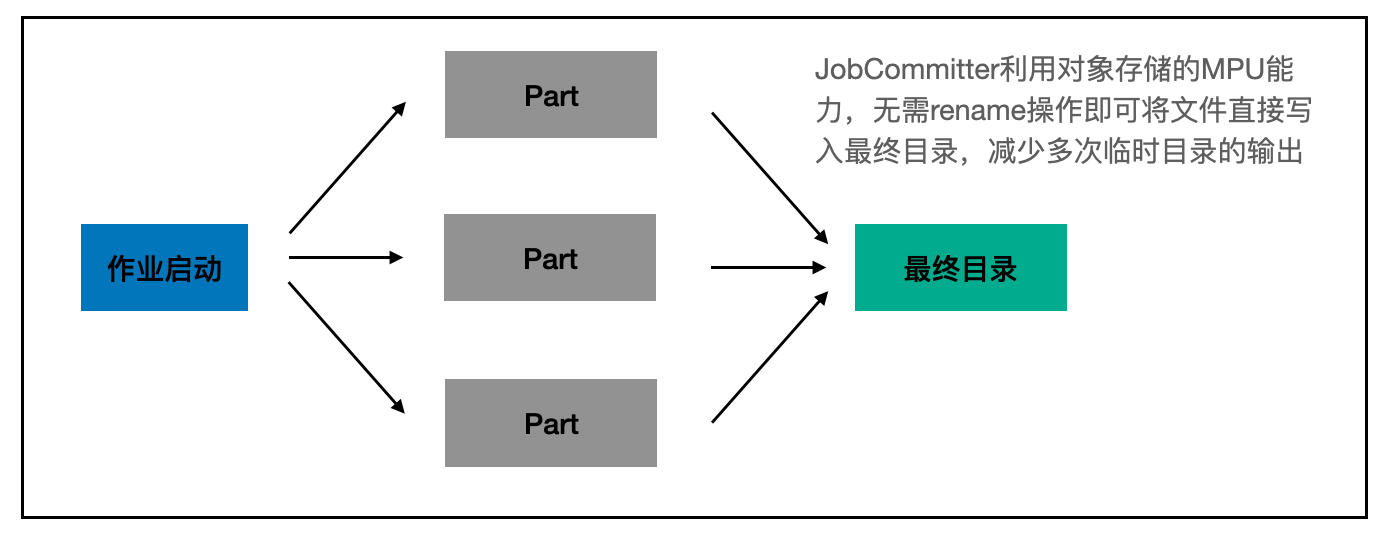
可见当有了Job Committer后,无需再写临时文件,直接写最终目录,当文件全部写完后,通过调用MPU的CompleteUpload让文件可见,减少原有的copy+delete,极大的提升了写入速度。
如下图所示,在常见的Hadoop MR测试场景下,火山EMR实现的深度优化的Job Commiter功能,可以实现TOS写入性能比开源方案快1倍。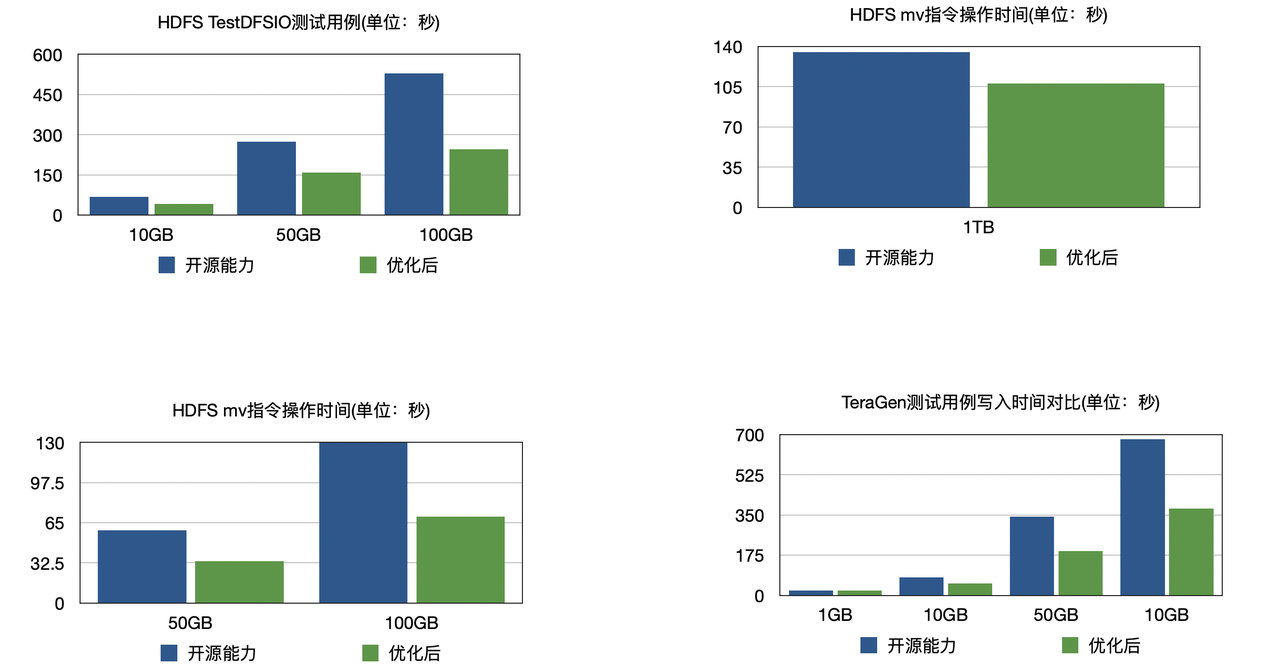
3 Hive TPC-DS测试
关于Hive 2.x 及 Hive3.x 开启使用TOS JobCommitter的内容,请参考 Hive 使用 Proton。
开启 TOS JobCommitter | 关闭TOS Job Committer | |
|---|---|---|
Hive On MR (Load 1TB) | 3410.943 (s) | 5784.555 (s) |
Hive On Tez (Load 1TB) | 2728.777 (s) | 5259.840 (s) |
结论
- 在Hive on MR场景下,Load 1TB tpc-ds数据开启TOS JobCommtiter可带来 70% 的性能提升;
- 在Hive On Tez场景下,Load 1TB tpc-ds 数据开启TOS JobCommitter 可带来 93% 的性能提升。
4 Spark TPC-DS测试
关于Spark2.x及Spark3.x开启使用TOS JobCommitter的内容,请参考 Spark 使用 Proton。
开启 TOS JobCommitter | 关闭TOS Job Committer | |
|---|---|---|
Spark 2.x (Load 1TB) | 1645.693 (s) | 3110.361 (s) |
Spark 3.x (Load 1TB) | 1507.178 (s) | 2938.998 (s) |
结论
- 在Spark 2.x,Load 1TB tpc-ds数据开启TOS JobCommtiter可带来89%性能提升;
- 在Spark 3.x,Load 1TB tpc-ds 数据开启TOS JobCommitter 可带来95%左右性能提升。
5 客户案例
场景介绍 | |
|---|---|
A. K12在线教育 |
|
B. 车联网数据分析 |
|
C. 智能驾驶公司 |
|
D. 基础模型厂商 |
|