本文将为您介绍如何通过大数据研发治理套件 DataLeap,实现火山引擎 E-MapReduce(EMR)集群相关的数据集成、开发、元数据管理以及质量监控等功能,例如:
- 通过数据集成任务将 MySQL数据源的数据,导入至 EMR Hive 库中。
- 通过数据开发任务创建并执行作业。
- 通过数据质量监控 Hive 表数据的波动并做数据探查。
- 通过数据地图查看 EMR 集群中的 Hive 库表信息。
前提条件
- 已开通 EMR 服务,并完成服务账号授权工作,详见 EMR 准备工作。
- 已开通 DataLeap 服务,并完成服务账号授权工作,详见 DataLeap 准备工作。
- 已创建和 EMR 集群同 VPC 下的数据集成资源组。详见资源组管理。
- 准备来源端 MySQL 数据源,此次案例使用火山引擎云数据库 MySQL 版。详见快速入门。
创建集群及项目
创建 EMR-Hadoop 集群
- 登录 EMR 控制台。
- 在左侧导航栏中,单击集群列表 > 创建集群入口,开始集群创建。
- 右上角单击快速创建按钮,完成软件配置、付费设置、可用地区、网络配置、实例设置、基础信息等配置。配置信息详见:创建集群。
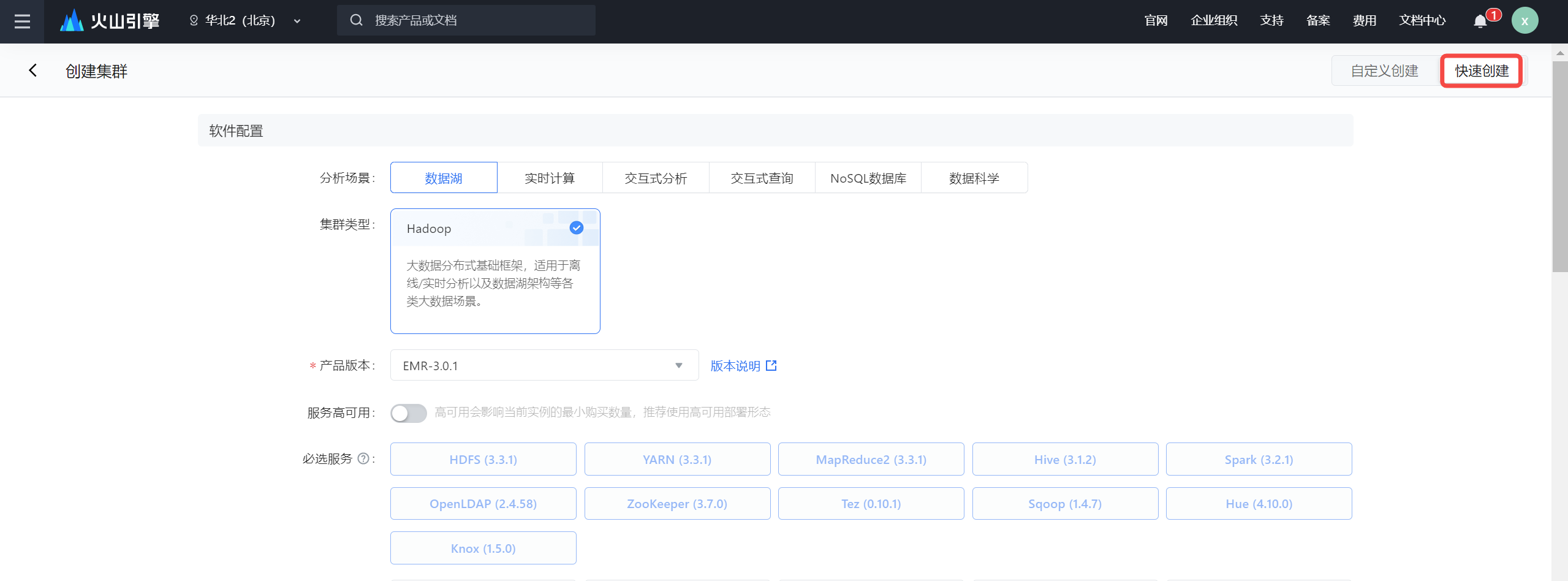
- 配置参数填写完成后,勾选我同意EMR服务条款, 单击立即创建按钮,完成集群创建。
- 进入集群控制台 > 集群列表查看创建的集群,待集群状态更新为运行中,即代表创建成功。
创建 DataLeap 项目
- 登录 DataLeap 租户控制台。
- 单击左侧导航栏的项目管理,进入项目管理页面。
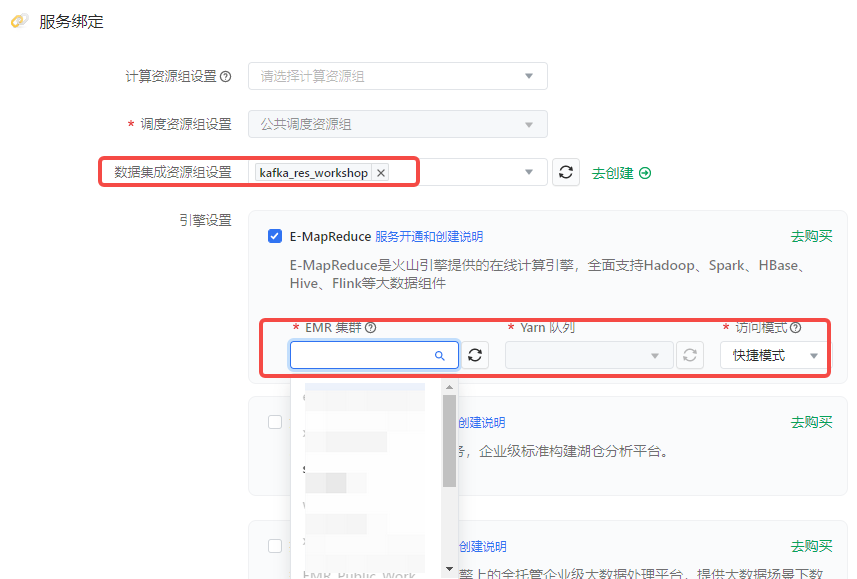
- 单击创建项目按钮,进入创建项目页面,完成项目基础信息、项目管控、服务绑定等项目配置工作。配置详见新建项目。
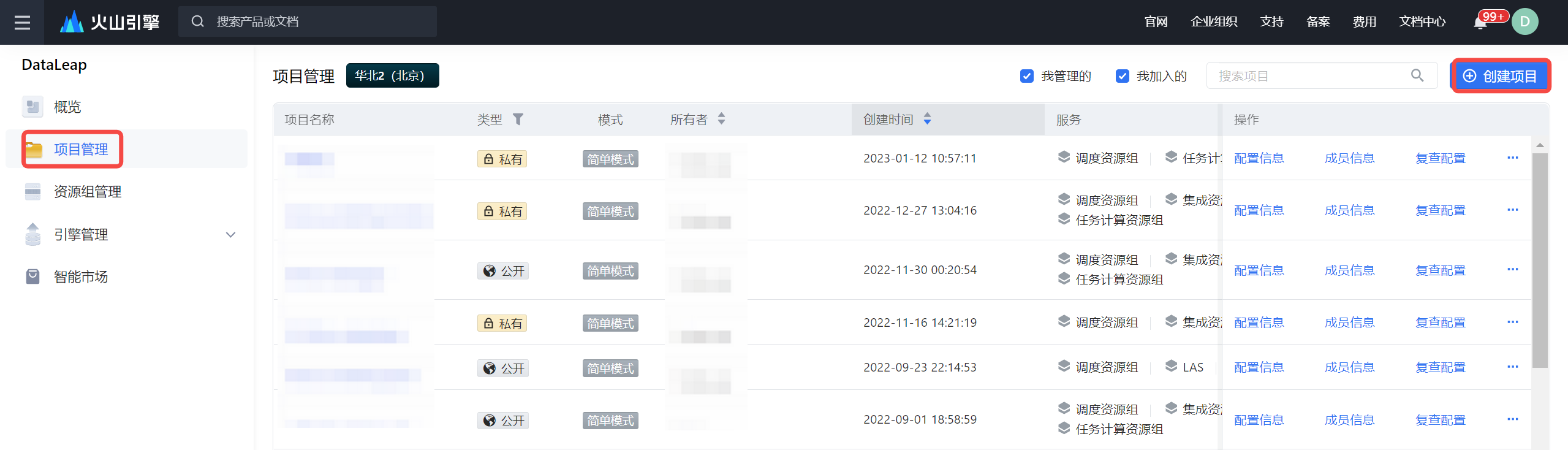
- 服务绑定时,选择已创建成功的数据集成资源组和 EMR 集群。
注意
DataLeap 目前支持以快捷模式绑定 EMR 集群进行使用,则其项目下所有 EMR 任务,EMR 内部实际的任务执行者为:flowagent(在3.4.0以上版本对应的执行用户变更为admin)。
配置数据集成任务
数据集成是稳定高效的数据同步平台,致力于提供丰富的异构数据源之间高速稳定的数据同步能力。
配置数据源
DataLeap 项目创建完成后,您可继续以下操作:
- 在项目管理列表中,单击配置信息,进入项目控制台。

- 在项目控制台界面,左侧导航栏中,点击数据源管理按钮,进入数据源管理页面。
- 在数据源管理页面,您可以开始新增 MySQL 和 Hive 数据源。详见配置 MySQL 数据源、配置 EMR Hive 数据源。其余数据源详见配置数据源。
注意
数据源测试连通性选择的数据集成资源组,需和 MySQL、EMR Hive 数据库处于同一个 VPC 下,保证网络能访问成功。若数据源存在于不同网络环境下,您可通过公网形式来访问或通过提工单的形式咨询 DataLeap 技术支持人员。
配置数据集成同步任务
数据源测试连通性成功后,您可继续往下配置数据集成同步任务。
- 在项目控制台界面左上角全部产品中,进入数据开发界面。
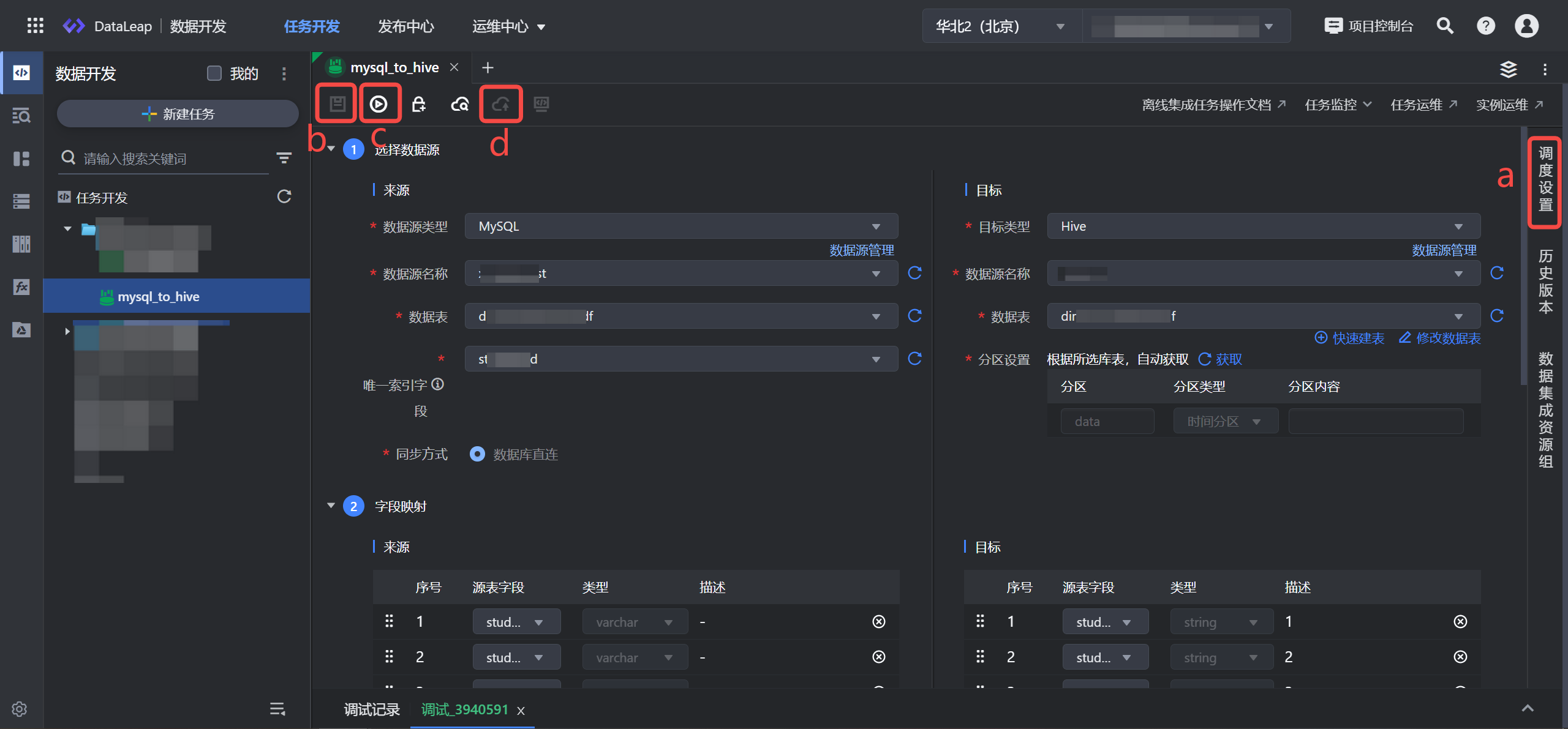
- 在数据开发页面,点击新建任务按钮,进入新建任务页面。
- 任务类型选择数据集成 > 离线集成 。
- 输入任务名称,并选择目标文件夹。
说明
注意: 任务名称只允许字符.、字母、数字、下划线、连字符、[]、【】、()、()以及中文字符,127个字符以内。
- 点击确定按钮,完成任务新建,进入任务配置页面。
- 通过界面向导的方式,来配置 MySQL_to_Hive 的集成任务。详见创建并运行离线数据同步任务。
集成任务配置完成后,您可以继续进行以下操作:
数据开发
DataLeap 数据开发即大数据开发 IDE,集批流开发为一体,为开发者提供高效、智能的开发环境。支持快速创建与 EMR 引擎相关的开发任务、进行代码开发、运行查询等。您可在 DataLeap 平台上,直接操作 EMR 相关数据。
数据开发类型
数据开发类型的任务,用于周期调度、手动调度执行的任务开发,EMR 引擎支持的任务类型如下:
注意
- EMR引擎目前支持绑定 Hadoop、TensorFlow、Flink、StarRocks、Doris 几种集群类型,其中 StarRocks、Doris 集群仅支持绑定 EMR-3.2.1 及以上集群版本,不同版本说明详见 EMR版本概述。
- EMR 流式数据任务创建,需满足以下条件之一:
- 支持 EMR-3.2.1 及以上版本的 Hadoop 集群类型,且需包含 Flink 和 GTS 组件服务。
- 支持 EMR-1.3.1 版本的 Hadoop 或 Flink 集群类型,且需包含 Flink 组件服务。
- 若 Flink 组件服务,是在 EMR 集群创建成功后,通过添加服务的方式添加时,则需要先在 EMR 管控端重启 OSSA 服务,方可继续使用对应服务相关功能。
- 若项目绑定 EMR-3.4.0 或之后的版本,可以通过添加 Kyuubi 服务,并重启 OSSA 服务的方式,加速 EMR Spark 任务的执行效率。
- 离线数据:
- EMR HSQL:通过编辑EMR HSQL语句,实现对EMR数据进行加工处理。
- EMR Spark:实现使用Java Spark处理数据,多用于大规模的数据分析处理等。
- EMR HDFS-sensor:实现对上游HDFS文件路径下数据的监控。
- EMR Hive-sensor:实现对上游Hive表分区数据的监控。
- EMR 报表任务:将 EMR SQL 查询的数据结果,以邮件形式,进行对外传输。
- 流式数据:
- EMR Flink SQL:通过 EMR Flink SQL 实现不同存储系统之间的ETL等。
- EMR Java Flink:实现EMR Java Flink原生任务的托管和运维。
临时查询类型
临时查询类型,用于在 EMR 引擎能力上,进行单次简单的测试查询。例如,配置数据集成任务中,集成任务调试成功后,您便可在临时查询界面创建查询任务,来查询 EMR Hive 表数据。详见临时查询。
临时查询支持以下查询类型:
注意
- 各查询类型,需 EMR 集群组件中,包含 Presto、Trino、Spark、Hive 这 4 类组件,则支持创建以下各自组件对应的查询类型。
- 若 Presto、Trino 组件服务,是在 EMR 集群创建成功后,通过添加服务的方式添加时,需要先在 EMR 管控端重启 OSSA 服务,方可继续使用对应服务相关功能。
- 若项目绑定 EMR-3.4.0 或之后的版本,可以通过添加 Kyuubi 服务,并重启 OSSA 服务的方式,加速 EMR Spark 任务的执行效率。
- EMR Hive SQL:自 EMR-1.0.0 版本开始支持。
- EMR Spark SQL:自 EMR-1.0.0 版本开始支持。
- EMR Presto:自 EMR-1.3.0 版本开始支持。
- EMR Trino:自 EMR-1.3.0 版本开始支持。
- EMR Doris:只支持在 Doris 集群执行,自 EMR-3.2.1 版本开始支持。
- EMR Starrocks:只支持 StarRocks 集群执行,自 EMR-3.2.1 版本开始支持。
发布中心
发布中心模块,主要目标是提高数据研发效率,规范任务发布流程,区分开发-生产环境,提高生产安全及稳定性,完善数仓研发全链路能力建设。 数据开发类型的任务提交上线时,若只选择仅提交,则您需进入发布中心,在此进行代码提交和发布包管理等操作。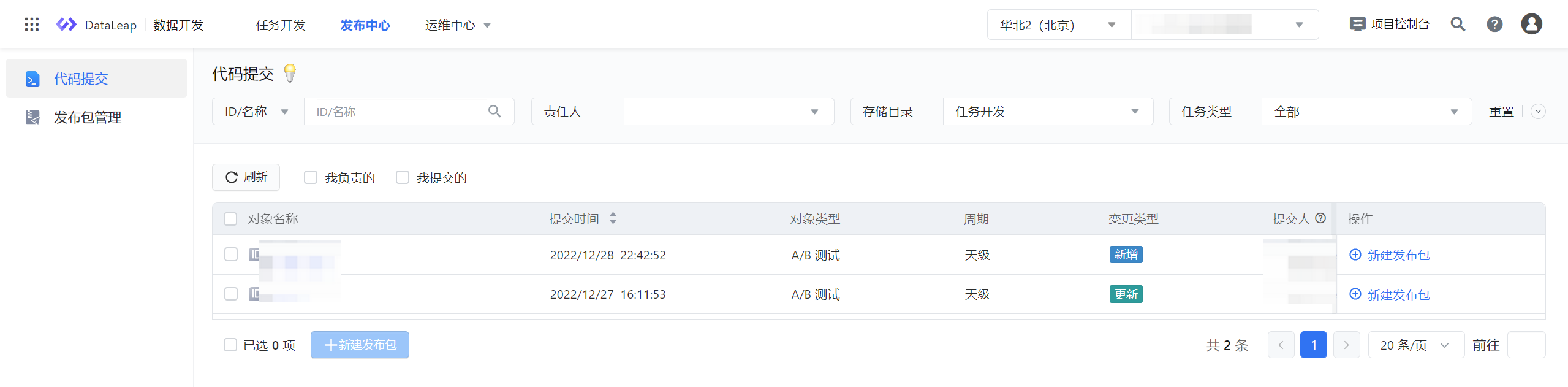
运维中心
任务提交发布成功后,可进入运维中心查看任务运维。 在上方导航栏中,进入离线任务运维、实时任务运维。您可在运维中,按需查看任务运行情况,可对任务进行监控报警设置、开启任务、停止任务、查看运行日志等运维操作。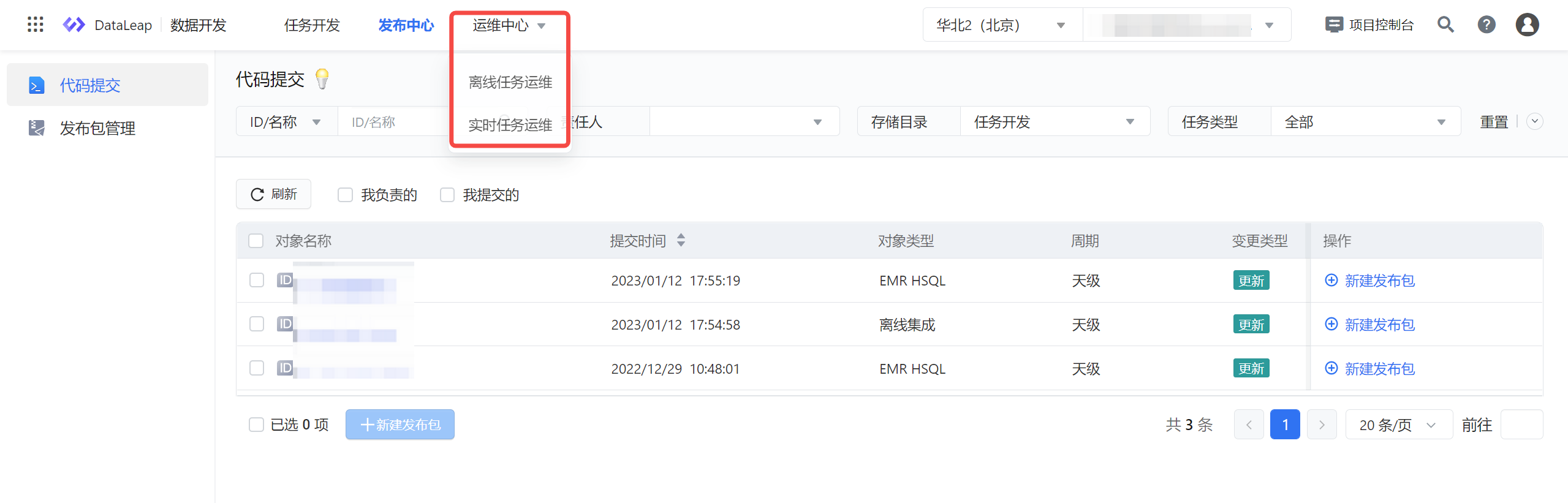
操作详见:离线任务运维、流式任务运维。
数据质量
数据质量平台是一款针对数据及其生产链路的数据质量管理平台,功能包括数据量、数据个性化指标的波动监控及异常报警,数据内容探查及差异对比等,保证了数据在生产及使用流程中的可靠性和合理性。
新建监控规则
- 在界面左上角全部产品中,进入数据质量界面。
- 在离线数据监控 > 监控对象界面,下拉选择引擎类型为项目绑定的 EMR 引擎。
- 单击右侧的监控对象按钮,进行新建监控对象。详见创建模板规则。
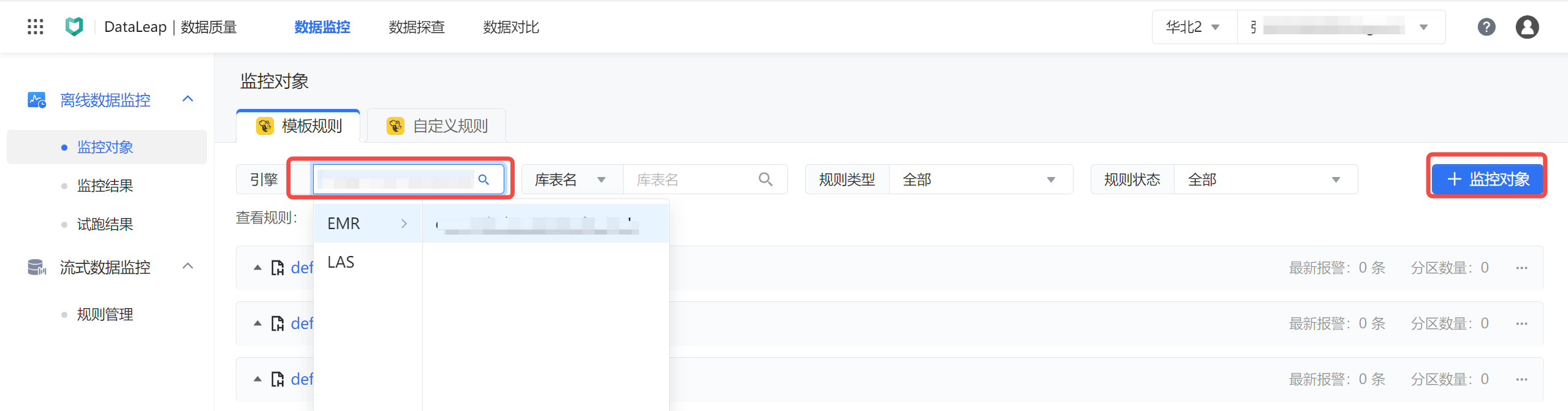
- 您可根据需要,配置 EMR Hive 表的数据监控规则类型。
- 监控配置完成后,单击右下角的完成或完成并试跑按钮,完成规则创建。
查看试跑结果
配置监控规则时,单击完成并试跑按钮,即可开始规则试跑。
- 单击左侧导航栏中的试跑结果,进入试跑结果页查看。
- 您可在操作栏中,查看当前 Hive 表试跑的规则、执行 SQL 和运行日志等信息。详见管理试跑结果。
数据探查
在 EMR Hive 表使用过程中,您可以对其进行数据探查工作,并一键生成探查报告及结果的查看。
目前支持对 EMR 引擎下库表的全量探查和动态探查的能力。
数据地图
数据地图采用图形化全链路数据表管理工具,提供字段、分区级元数据血缘展示,并通过数据血缘关系,获取数据生产全链路信息,解决找数难、理解数据难的痛点。
您可以在数据地图上完成 EMR 引擎库表的数据检索、元数据采集、库表管理和查看血缘图谱的操作: