E-MapReduce
E-MapReduce



组件与 API 参考

请输入


- 文档首页
 E-MapReduce组件操作指南Ray最佳实践Ray任务运行在GPU上
E-MapReduce组件操作指南Ray最佳实践Ray任务运行在GPU上

Ray任务运行在GPU上
Ray支持在GPU上运行任务,这对于需要大量计算资源的应用(如深度学习)来说非常有用。本文是在火山引擎容器服务VKE上使用Ray运行GPU任务的步骤。
1 前提条件
VKE集群运行正常。
VKE集群中至少有一个节点配置了 NVIDIA GPU 并安装了相应的驱动程序。
部署EMR on VKE产品中的Ray服务
2 选择Ray镜像
在EMR on VKE产品中部署RayCluster组件时,采用的镜像不包含CUDA依赖的。
EMR中提供含CUDA依赖的Ray镜像,里面也包括TensorFlow 、PyTorch依赖,参考镜像仓库获取相关镜像。
3 Pod中配置GPU资源
在EMR管控平台中提供有RayCluster的安装部署,可以通过Yaml文件方式指定Ray镜像和GPU个数。对于RayJob方式,也可以通过Yaml文件方式。Yaml文件如下示例:
groupName: gpu-group replicas: 0 minReplicas: 0 maxReplicas: 5 ... template: spec: ... containers: - name: ray-node image: emr-vke-public-cn-beijing.cr.volces.com/emr/ray:2.9.3-cu11.8.0-py3.9-ubuntu20.04-1.2.0 ... resources: nvidia.com/gpu: 1 # Optional, included just for documentation. cpu: 3 memory: 50Gi limits: nvidia.com/gpu: 1 # Required to use GPU. cpu: 3 memory: 50Gi ...
示例中nvidia.com/gpu表明可以使用 Nvidia GPUs ,可以配置RayCluster的Yaml中headGroupSpec和workerGroupSpecs片段中。同时Ray Autoscaler特性也使用对GPU的弹性。
4 Ray作业中使用GPU资源
一旦部署了可以访问 GPU 的 Ray pod,就能够执行带有 GPU 请求的task和 actor。例如,通过@ray.remote(num_gpus=1) 注释 1 个 GPU 的 actor:
import ray ray.init() @ray.remote(num_gpus=1) class GPUActor: def say_hello(self): print("I live in a pod with GPU access.") # Request actor placement. gpu_actors = [GPUActor.remote() for _ in range(2)] # The following command will block until two Ray pods with GPU access are scaled # up and the actors are placed. ray.get([actor.say_hello.remote() for actor in gpu_actors]) # scale up GPU resources. ray.autoscaler.sdk.request_resources(bundles=[{"GPU": 1}] * 2) ray.autoscaler.sdk.request_resources(bundles=[])
示例中@ray.remote(num_gpus=1)表明actor需要一个GPU。
5 使用示例
"""Example of a custom gym environment and model. Run this for a demo. This example shows: - using a custom environment - using a custom model - using Tune for grid search You can visualize experiment results in ~/ray_results using TensorBoard. """ import argparse import ray from ray import air, tune from ray.rllib.examples.env.gpu_requiring_env import GPURequiringEnv from ray.rllib.utils.framework import try_import_tf, try_import_torch from ray.rllib.utils.test_utils import check_learning_achieved from ray.tune.registry import get_trainable_cls from pyarrow import fs tf1, tf, tfv = try_import_tf() torch, nn = try_import_torch() parser = argparse.ArgumentParser() parser.add_argument( "--run", type=str, default="PPO", help="The RLlib-registered algorithm to use." ) parser.add_argument( "--framework", choices=["tf", "tf2", "torch"], default="torch", help="The DL framework specifier.", ) parser.add_argument("--num-gpus", type=float, default=0.5) parser.add_argument("--num-workers", type=int, default=1) parser.add_argument("--num-gpus-per-worker", type=float, default=0.0) parser.add_argument("--num-envs-per-worker", type=int, default=1) parser.add_argument( "--as-test", action="store_true", help="Whether this script should be run as a test: --stop-reward must " "be achieved within --stop-timesteps AND --stop-iters.", ) parser.add_argument( "--stop-iters", type=int, default=50, help="Number of iterations to train." ) parser.add_argument( "--stop-timesteps", type=int, default=100000, help="Number of timesteps to train." ) parser.add_argument( "--stop-reward", type=float, default=180.0, help="Reward at which we stop training." ) if __name__ == "__main__": args = parser.parse_args() ray.init() # These configs have been tested on a p2.8xlarge machine (8 GPUs, 16 CPUs), # where ray was started using only one of these GPUs: # $ ray start --num-gpus=1 --head # Note: A strange error could occur when using tf: # "NotImplementedError: Cannot convert a symbolic Tensor # (default_policy/cond/strided_slice:0) to a numpy array." # In rllib/utils/exploration/random.py. # Fix: Install numpy version 1.19.5. # Tested arg combinations (4 tune trials will be setup; see # tune.grid_search over 4 learning rates below): # - num_gpus=0.5 (2 tune trials should run in parallel). # - num_gpus=0.3 (3 tune trials should run in parallel). # - num_gpus=0.25 (4 tune trials should run in parallel) # - num_gpus=0.2 + num_gpus_per_worker=0.1 (1 worker) -> 0.3 # -> 3 tune trials should run in parallel. # - num_gpus=0.2 + num_gpus_per_worker=0.1 (2 workers) -> 0.4 # -> 2 tune trials should run in parallel. # - num_gpus=0.4 + num_gpus_per_worker=0.1 (2 workers) -> 0.6 # -> 1 tune trial should run in parallel. config = ( get_trainable_cls(args.run) .get_default_config() # Setup the test env as one that requires a GPU, iff # num_gpus_per_worker > 0. .environment( GPURequiringEnv if args.num_gpus_per_worker > 0.0 else "CartPole-v1" ) .framework(args.framework) .resources( # How many GPUs does the local worker (driver) need? For most algos, # this is where the learning updates happen. # Set this to > 1 for multi-GPU learning. num_gpus=args.num_gpus, # How many GPUs does each RolloutWorker (`num_workers`) need? num_gpus_per_worker=args.num_gpus_per_worker, ) # How many RolloutWorkers (each with n environment copies: # `num_envs_per_worker`)? .rollouts( num_rollout_workers=args.num_workers, # This setting should not really matter as it does not affect the # number of GPUs reserved for each worker. num_envs_per_worker=args.num_envs_per_worker, ) # 4 tune trials altogether. .training(lr=tune.grid_search([0.005, 0.003, 0.001, 0.0001])) ) stop = { "training_iteration": args.stop_iters, "timesteps_total": args.stop_timesteps, "episode_reward_mean": args.stop_reward, } # Note: The above GPU settings should also work in case you are not # running via ``Tuner.fit()``, but instead do: # >> from ray.rllib.algorithms.ppo import PPO # >> algo = PPO(config=config) # >> for _ in range(10): # >> results = algo.train() # >> print(results) s3 = fs.S3FileSystem(access_key='xxx', secret_key='xxx',endpoint_override='xxx', force_virtual_addressing=True) results = tune.Tuner( args.run, param_space=config.to_dict(), run_config=air.RunConfig(stop=stop, storage_path="ceshi-dts/ray-store", storage_filesystem = s3) ).fit() if args.as_test: check_learning_achieved(results, args.stop_reward) ray.shutdown()
示例中是采用GPU执行torch模型训练,作业执行过程中的中间数据存储到对象存储TOS中,所以需要填写实际的access_key、secret_key和endpoint_override参数。
可以在Ray dashboard中可以GPU资源的使用情况。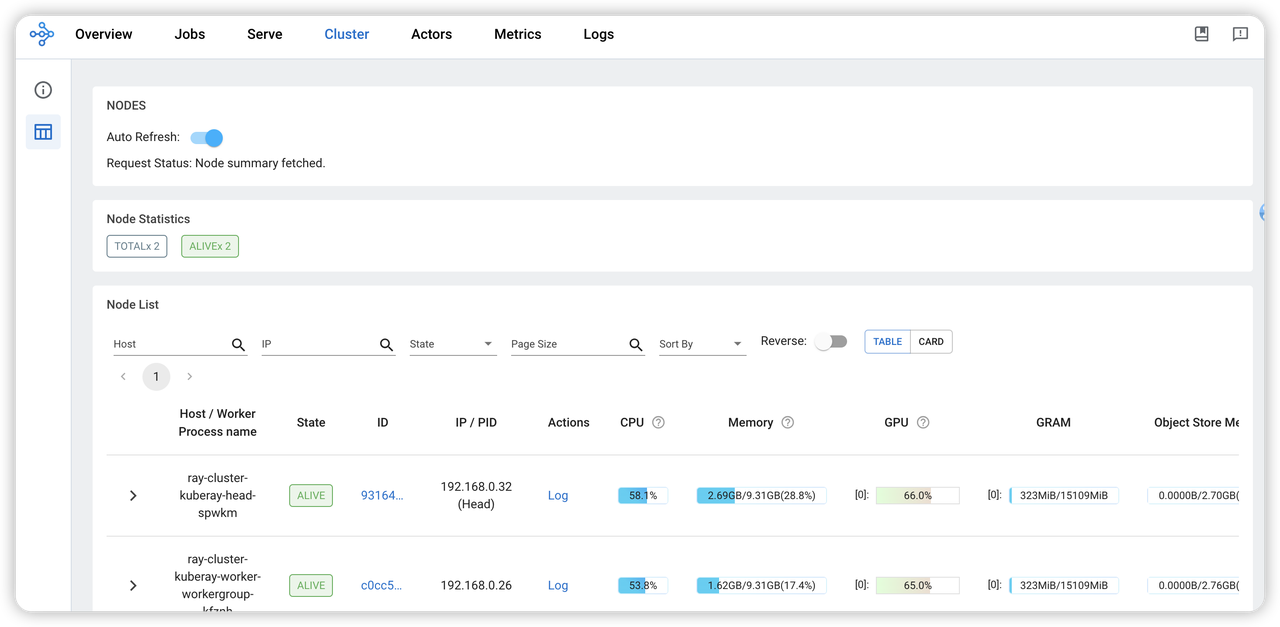
最近更新时间:2024.05.20 17:27:19
这个页面对您有帮助吗?
有用
有用
无用
无用