本文将为您介绍火山引擎 E-MapReduce(简称“EMR”)和源端 Hadoop 集群之间的数据迁移操作。
1 专线连接
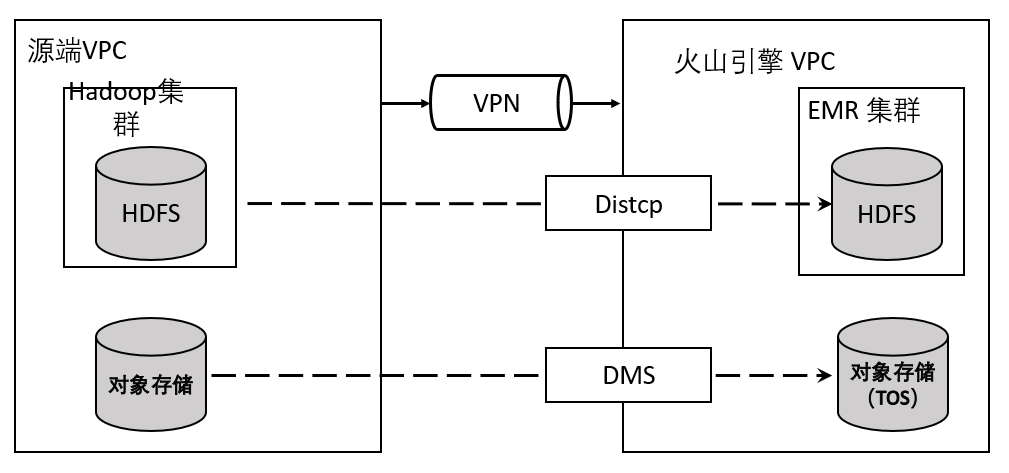
正式做迁移前,需要在源端 VPC 和火山引擎 VPC 之间建立 1Gb 或 10Gb 的专线连接,保障迁移的速度、安全和稳定性。
说明
迁移速度评估:
专线带宽为 :10Gb = 1.25GB
数据量为:100T = 100*1024 = 102400 GB
迁移时间为:102400/1.25/3600 = 22.75 小时
专线拉通后,可以开始不间断的大规模数据迁移。
2 迁移 HDFS 数据
EMR 集群和源端 Hadoop 集群建立连接后,可以使用 Distcp 工具进行数据迁移和校验。典型的迁移数据的命令如下所示:
hadoop distcp hdfs://源端hdfs文件夹 hdfs://目标端hdfs文件夹
注意
需要在目标集群上各节点的 /etc/hosts 中配置源集群各节点的域名与 IP。
2.1 HDFS 参数性能调优
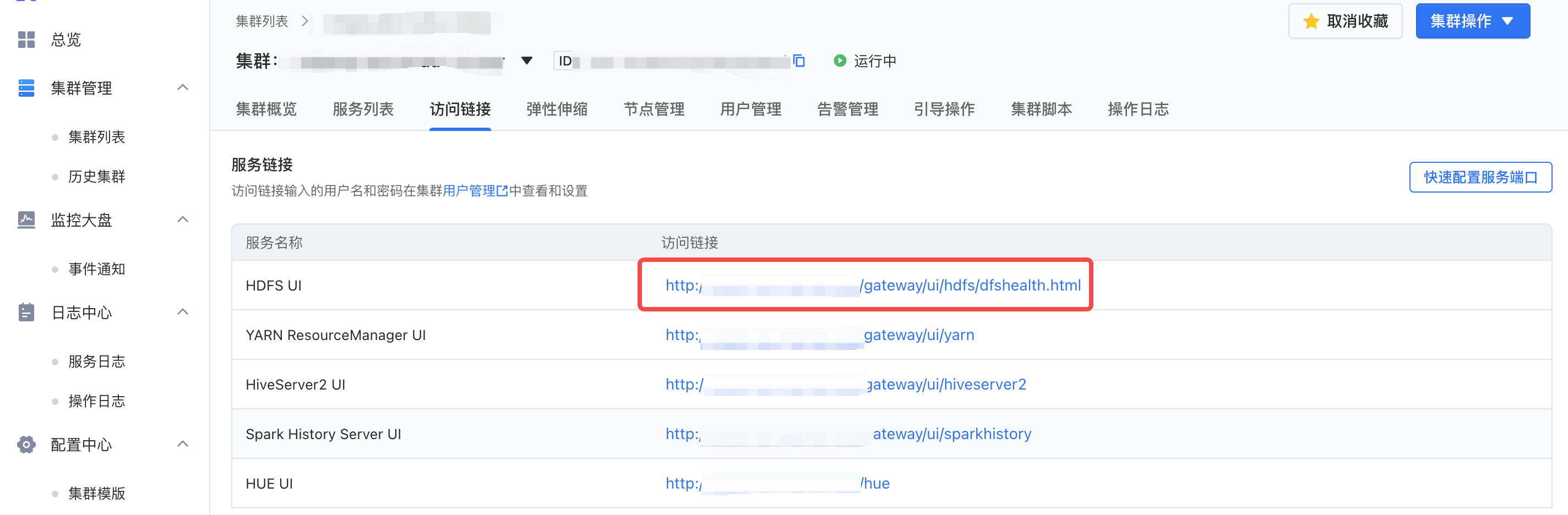
HDFS 的性能调优主要针对资源使用情况,合理的资源配给能提高 HDFS 稳定性及读写效率。火山 EMR 控制台提供 HDFS UI 入口,可以对 HDFS 进行诊断调优。
说明
HDFS UI 访问链接前提条件:
集群的访问链接需要 emr-master-1 节点的 ECS ID 实例绑定弹性公网IP。详见绑定公网IP。
需要在集群详情 > 访问链接 > 快速配置服务端口中,给源地址和对应端口添加白名单才可继续访问。
常见的 HDFS 调优项包括:
参数 | 建议值(不同业务及资源情况可能会有偏差) | 描述 |
|---|---|---|
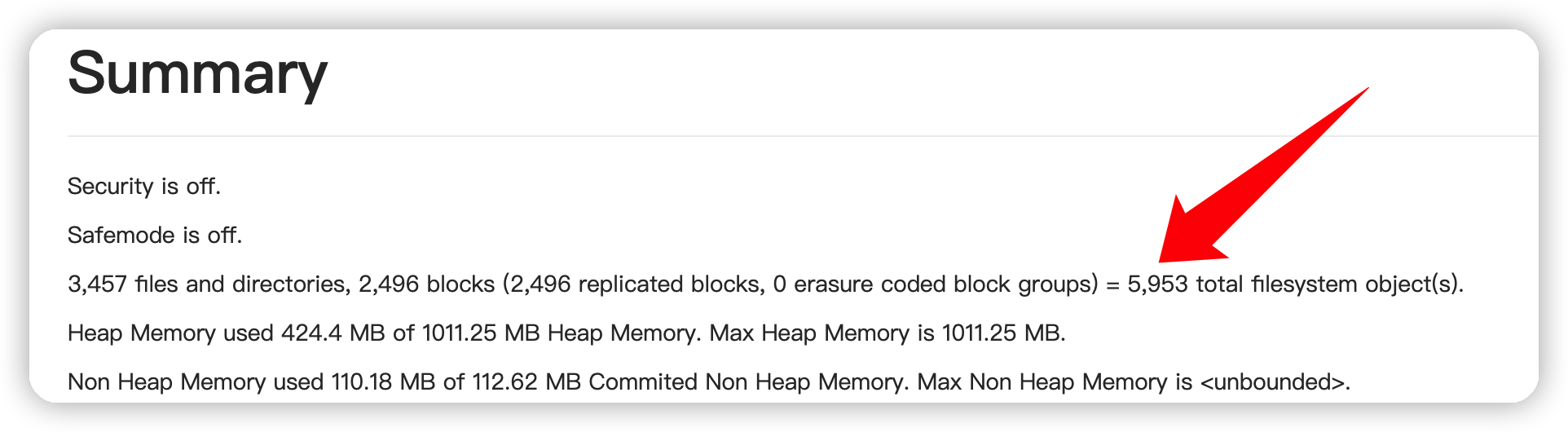
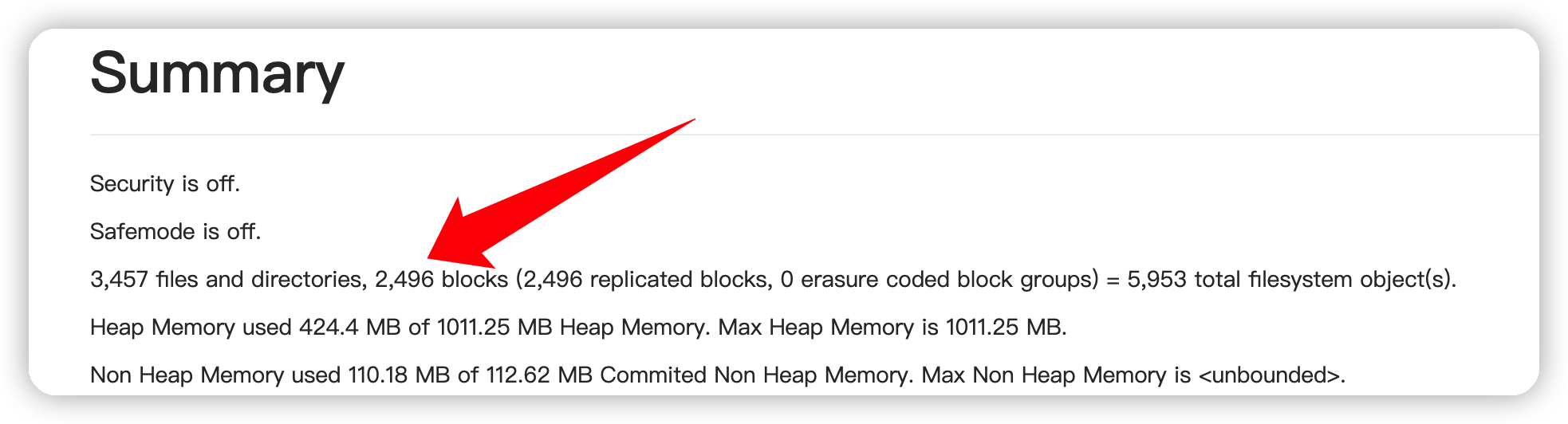
namenode_heapsize | (文件数+块数)÷100万×512 MB | HDFS 的 UI 上可以看到,如果小文件个数过多,则会造成 NameNode 的内存容量瓶颈。 |
dtnode_heapsize | 文件块数 Blocks÷100万×3÷DataNode 节点数×2048 MB | HDFS 的 UI 上可以看到,如果小文件个数过多,则会造成 DataNode 的内存容量瓶颈。 |
dfs.namenode.handler.count | 20×Log(2)N(其中N为 DataNode 个数,可用科学计算器进行计算) | NameNode 用于处理 RPC 的线程数; |
dfs.datanode.handler.count | 20 | DataNode 用于处理 RPC 的线程数;适当增加这个数值来提升 DataNode RPC 服务的并发度,线程数的提高将增加 DataNode 的内存需求。 |
dfs.blocksize | ≈磁盘吞吐量(MB/s) | 如果块太小,会降低NN的服务能力,在上传和读取一个文件时会带来额外的寻址时间消耗。 如果块太大,如果发生异常,需要重新传输,会造成网络 IO 消耗,而且不够灵活。 |
dfs.datanode.failed.volumes.tolerated | 1(当数据盘数为1,则该参数配置为0) | 故障目录容忍度;即故障磁盘数小于该参数值时,则认为该 DataNode 节点还可用。 |
fs.trash.interval | 360 | 多少分钟后删除 checkpoint 文件。如果是0,那么 trash 功能被禁用。 |
fs.trash.checkpoint.interval | 30 | 两次 trash checkpoint 之间的分钟间隔,这个值应该被设置为小于等于 fs.trash.interval 的值。如果配置项为0,那么这个配置项的值会被设置为 fs.trash.interval 的值。 |
3 迁移对象存储数据至 TOS
源端 Hadoop 集群如果使用存算分离架构或者部分数据存储在对象存储中,需要将源端的对象存储数据迁移到 TOS 上。使用火山引擎存储迁移服务可以将其他云服务商对象存储服务的数据在线迁移至火山引擎对象存储TOS。
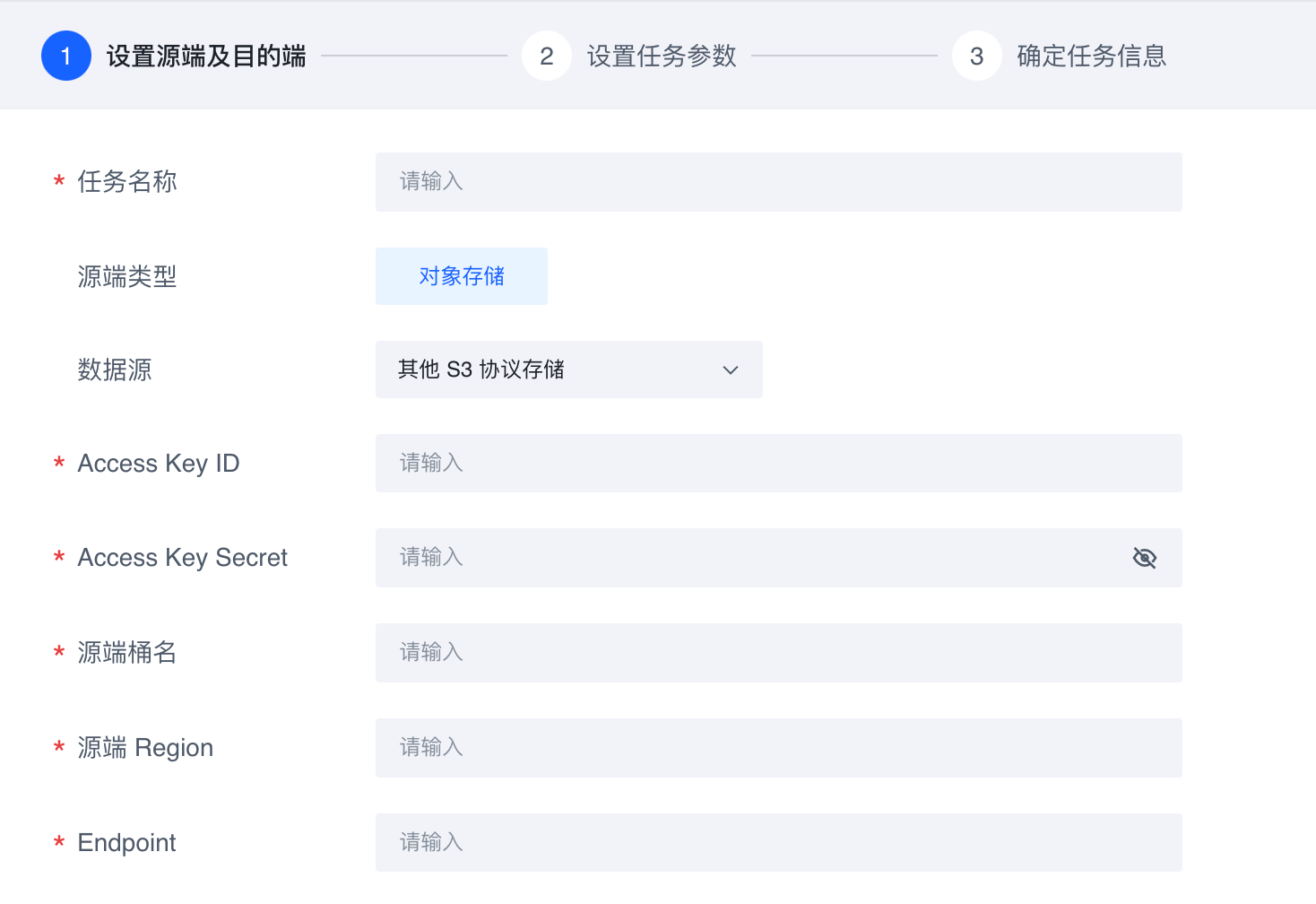
3.1 创建迁移任务
登录存储迁移服务控制台。
在迁移任务列表页面,单击创建迁移任务。
在设置源端及目的端页面,设置源端及目的端参数,以及相应的任务参数。配置任务流程详见创建迁移任务。
3.2 设置生命周期规则优化存储成本
对象存储的生命周期管理功能,根据文件最后一次修改的时间设置文件的生命周期规则,定期将存储桶内的文件转化为指定的存储类型或删除,从而节约存储费用。生命周期管理完整说明参考。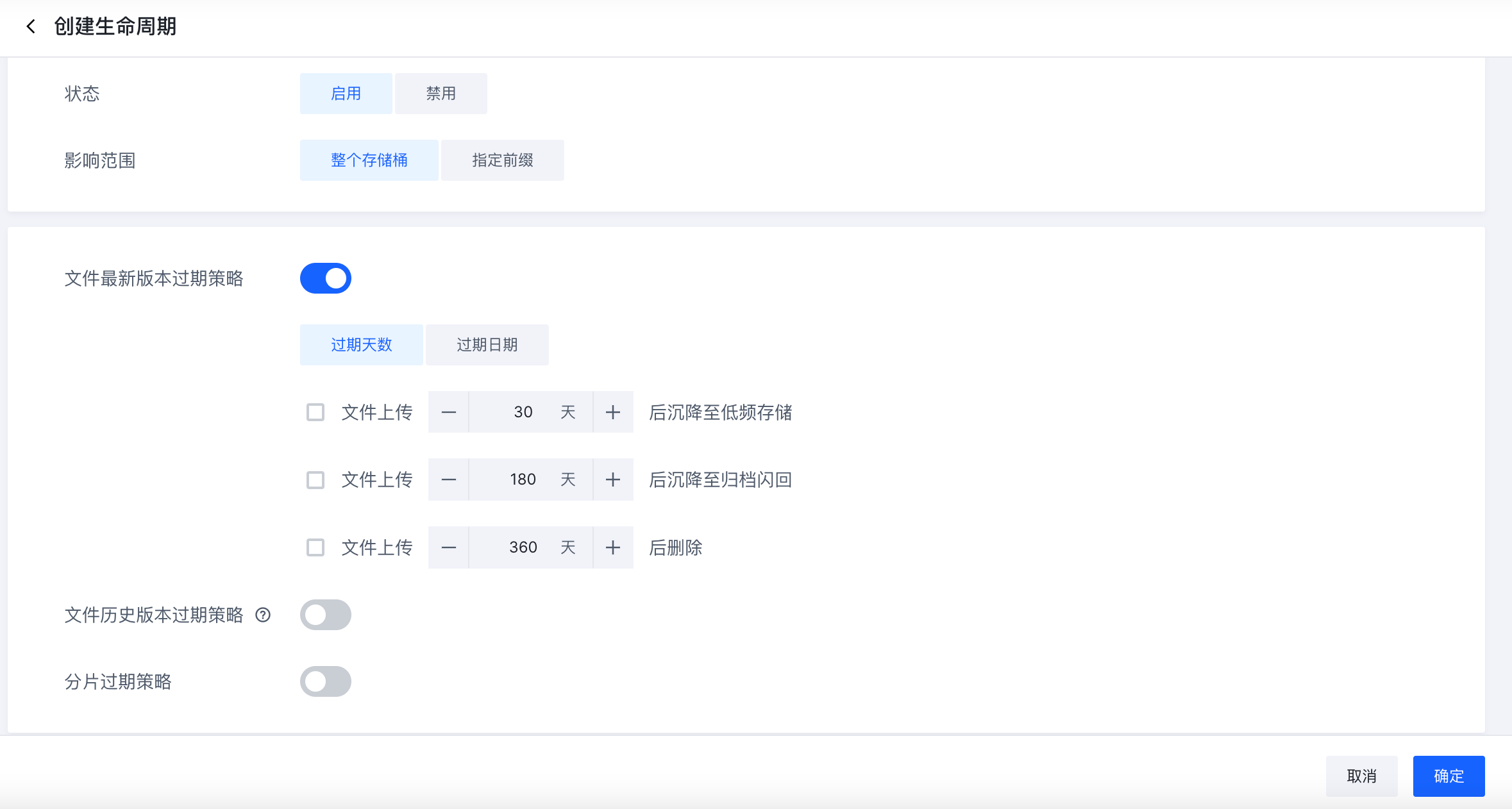
4 迁移流式数据
4.1 迁移 Kafka 数据
Apache Kafka 是由 Apache 软件基金会开发的一个开源流处理平台。 其持久化层本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”,这使它作为企业级基础设施来处理流式数据非常有价值。
可以使用 Apache Flume 或者 MirrorMaker 将源端 Kafka 数据迁移至火山 EMR Kafka 上。
使用 Apache Flume 迁移 Kafka 数据
Apache Flume 是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。支持在日志系统中定制各类数据发送方,用于收集数据。Flume 支持对数据进行简单处理,写到各种数据源(比如文本、HDFS、TOS 等)的能力 。可使用 Apache Flume 在两个 Kafka 集群间进行数据传输。
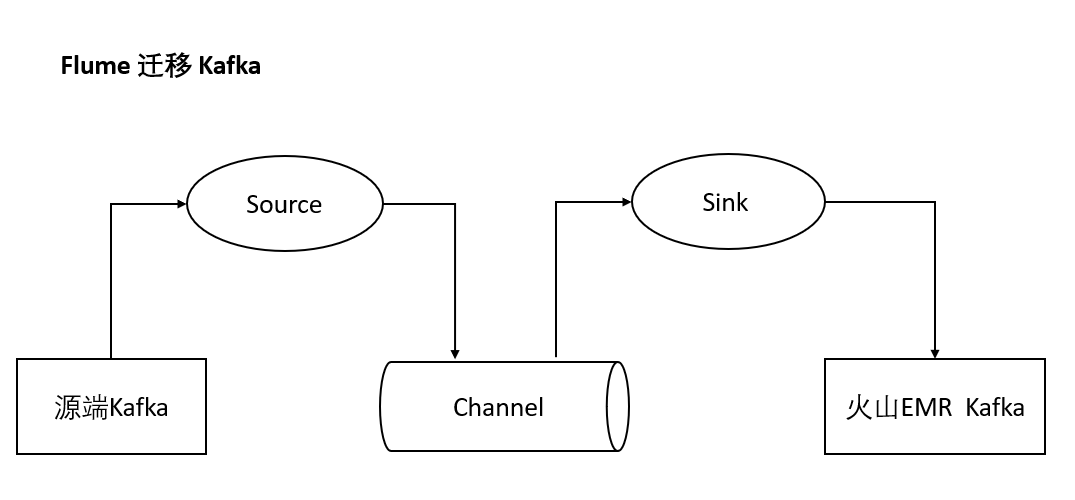
使用 Apache Flume 迁移 Kafka 数据,需要在 Flume 配置文件 flume.properties 中配置 channel 信息,包括 source 和 sink 端信息,比如:
# KAFKA_sources a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource a1.sources.r1.batchSize = 5 a1.sources.r1.batchDurationMillis = 10 a1.sources.r1.kafka.bootstrap.servers =<source-kafka-host1:port1,source-kafka-host2:port2...> a1.sources.r1.kafka.topics = flume-test a1.sources.r1.kafka.consumer.group.id = flume-group a1.sources.r1.channels=c1 a1.channels.c1.type=memory a1.channels.c1.capacity=10 a1.channels.c1.transactionCapacity=10 # KAFKA_sinks a1.sinks.k1.channel = c1 a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.batchSize = 5 a1.sinks.k1.kafka.topic = flume-target a1.sinks.k1.kafka.bootstrap.servers = <target-kafka-host1:port1,target-kafka-host2:port2...> a1.sinks.k1.custom.encoding=UTF-8 a1.sinks.k1.kafka.producer.acks=1使用 MirrorMaker 迁移 Kafka 数据
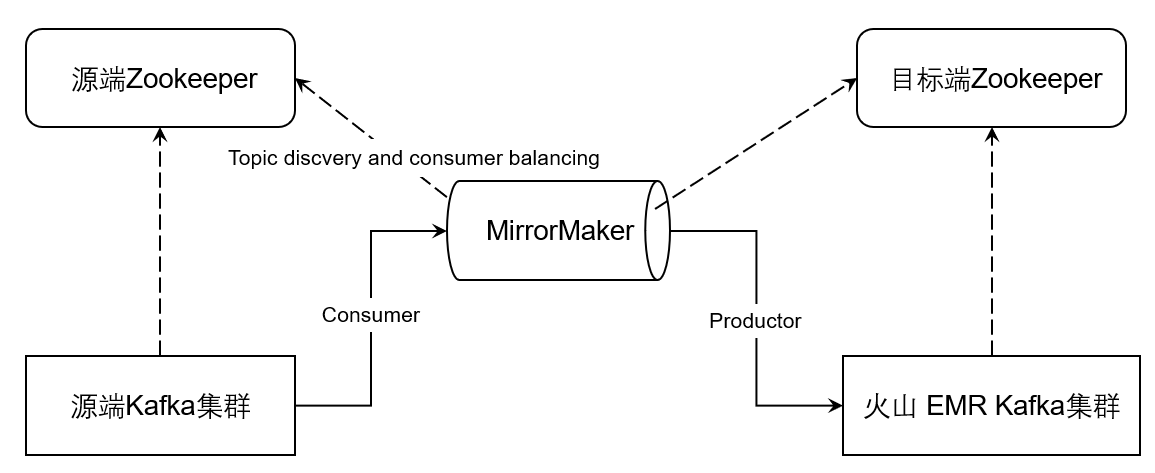
MirrorMaker 是一个独立的工具,用于两个 Kafka 集群间的数据同步。可以将 MirrorMaker 看成是 Kafka 生产者与消费者的一个整合,通过 consumer 从源 Kafka 集群消费数据,然后通过 producer 将数据重新推送到目标 Kafka 集群。MirrorMaker 的使用请参考 Kafka Mirroring(MirrorMaker)。
5 迁移至火山 EMR OLAP
5.1 使用火山引擎 EMR Clickhouse 集群
ClickHouse 是一个主要用于 OLAP 的开源列式数据库管理系统(RDBMS)。ClickHouse 采用了大规模并行处理(Massively Parallel Processing,简称 MPP)以及无共享(Shared-nothing)的架构,拥有线性扩展的能力,从1个节点的单机模式可以扩展到数千台服务器的集群模式。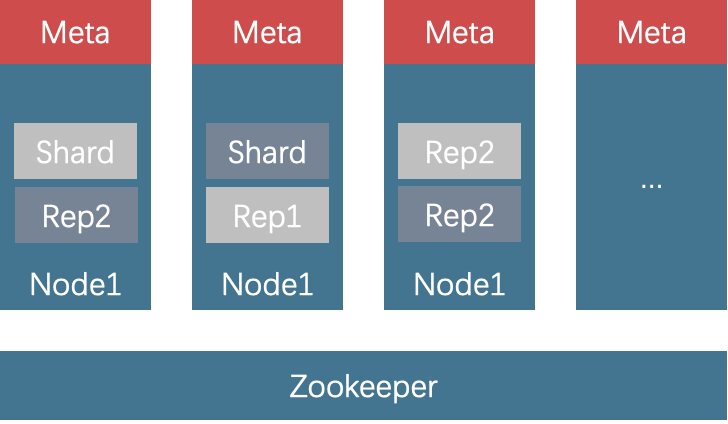
ClickHouse 拥有强劲的数据查询性能,能很好地支撑对分析查询性能和时效性有较高要求的业务场景,实时数仓、行为分析和交互式分析等,就是 ClickHouse 应用场景的典型代表。ClickHouse 广泛应用于广告、金融、工业互联网行业。
ClickHouse 也是一个存算一体数据库引擎,因此搬迁的时候,需要保证元数据和增量/历史数据的一致性。
元数据的迁移
元数据迁移可以通过show create table获取对应的建表语句,并在目标集群建表完成。show create table table_name;增量数据迁移
如果是实时表,即通过 flink 任务实时有数据插入的表或者通过数据库传输服务等云上工具同步 Binlog 的表,数据搬迁需要区分增量数据和历史数据。增量数据可以通过创建火山引擎 EMR Flink 任务或者 DTS 任务进行同步。
历史数据迁移
历史数据可以使用 clickhouse-copier 进行迁移。对于离线表,在做历史数据迁移的时候,如果有新的任务出现,可以通过配置项中的 `enabled_partitions` 将新任务影响的分区先删除分区数据再重新导入一次。
5.2 使用火山引擎 EMR Doris 集群
Apache Doris 是一款简单易用、高性能和统一的分析数据库,兼容 MySQL 协议、使用列式存储、支持向量化引擎、允许从 HDFS/S3 或者 MySQL Binlog/Kafka 进行数据导入。Doris 常用于实时数仓场景,除此之外通过 Multi-Catalog 功能支持作为一个执行引擎查询数据湖上数据。
5.2.1 使用 Doris 搭建实时数仓和数据湖
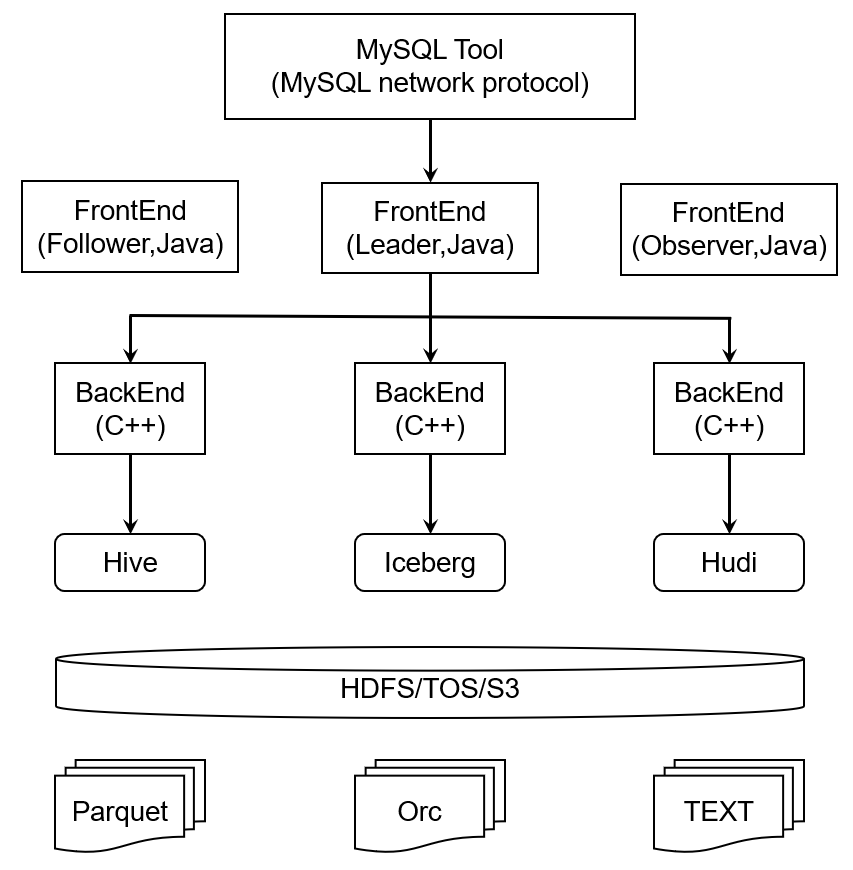
Doris 作为数据湖执行引擎
Doris 支持读取 Hive、Iceberg 和 Hudi 表,支持 Parquet、Orc 和 TEXT 存储格式。通过 Multi-Catalog 功能,Doris 可以作为数据湖的执行引擎读写相关数据。
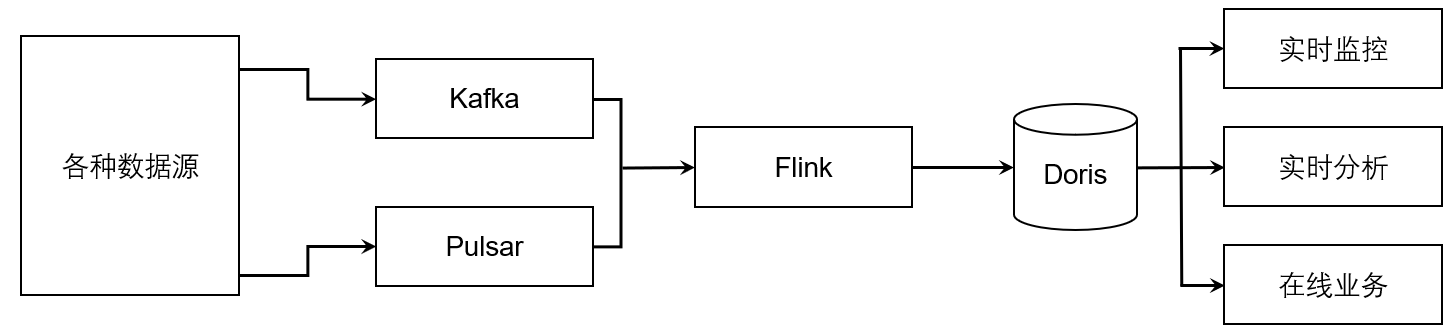
实时数仓场景
实时数仓要求数据流式入场后秒级可见、秒级或者亚秒级数据查询性能、万级 QPS、实时指标聚合和多维分析。Flink+Doris 是典型的实时数仓架构。数据通过 Flink 实时处理后写入到 Doris,Doris 作为执行引擎供在线业务和实时分析查询。
5.3 迁移 Apache Kudu
可以使用 Impala 和或者社区提供的 Kudu Backup 和 Restore 工具对 Kudu 进行迁移。
5.3.1 使用 Kudu Backup 和 Restore 工具完成 Kudu 迁移
EMR Kudu 支持社区 1.14 版本,可以使用社区提供的备份和恢复的工具进行数据的迁移。更多信息参考 Kudu备份和恢复。
## 备份 spark-submit --class org.apache.kudu.backup.KuduBackup kudu-backup2_2.11-1.14.0.jar \ --kuduMasterAddresses master1-host,master-2-host,master-3-host \ --rootPath hdfs:///kudu-backups \ foo bar ## 恢复 spark-submit --class org.apache.kudu.backup.KuduRestore kudu-backup2_2.11-1.14.0.jar \ --kuduMasterAddresses master1-host,master-2-host,master-3-host \ --rootPath hdfs:///kudu-backups \ foo bar