1 StarRocks 表设计
1.1 列式存储
StarRocks 中的表由行和列构成。每行数据对应用户一条记录,每列数据具有相同的数据类型。所有数据行的列数相同,可以动态增删列。在 StarRocks 中,一张表的列可以分为维度列(也称为 Key 列)和指标列(也称为 Value 列)。维度列用于分组和排序。
在 StarRocks 中,表数据按列存储。物理上,一列数据会经过分块编码、压缩等操作,然后持久化存储到非易失设备上。但在逻辑上,一列数据可以看成是由相同类型的元素构成的一个数组。 一行数据的所有列值在各自的数组中按照列顺序排列,即拥有相同的数组下标。数组下标是隐式的,不需要存储。表中所有的行按照维度列,做多重排序,排序后的位置就是该行的行号。
1.2 索引
StarRocks 通过前缀索引 (Prefix Index) 和列级索引,能够快速找到目标行所在数据块的起始行号。
StarRocks 表设计原理如下图所示。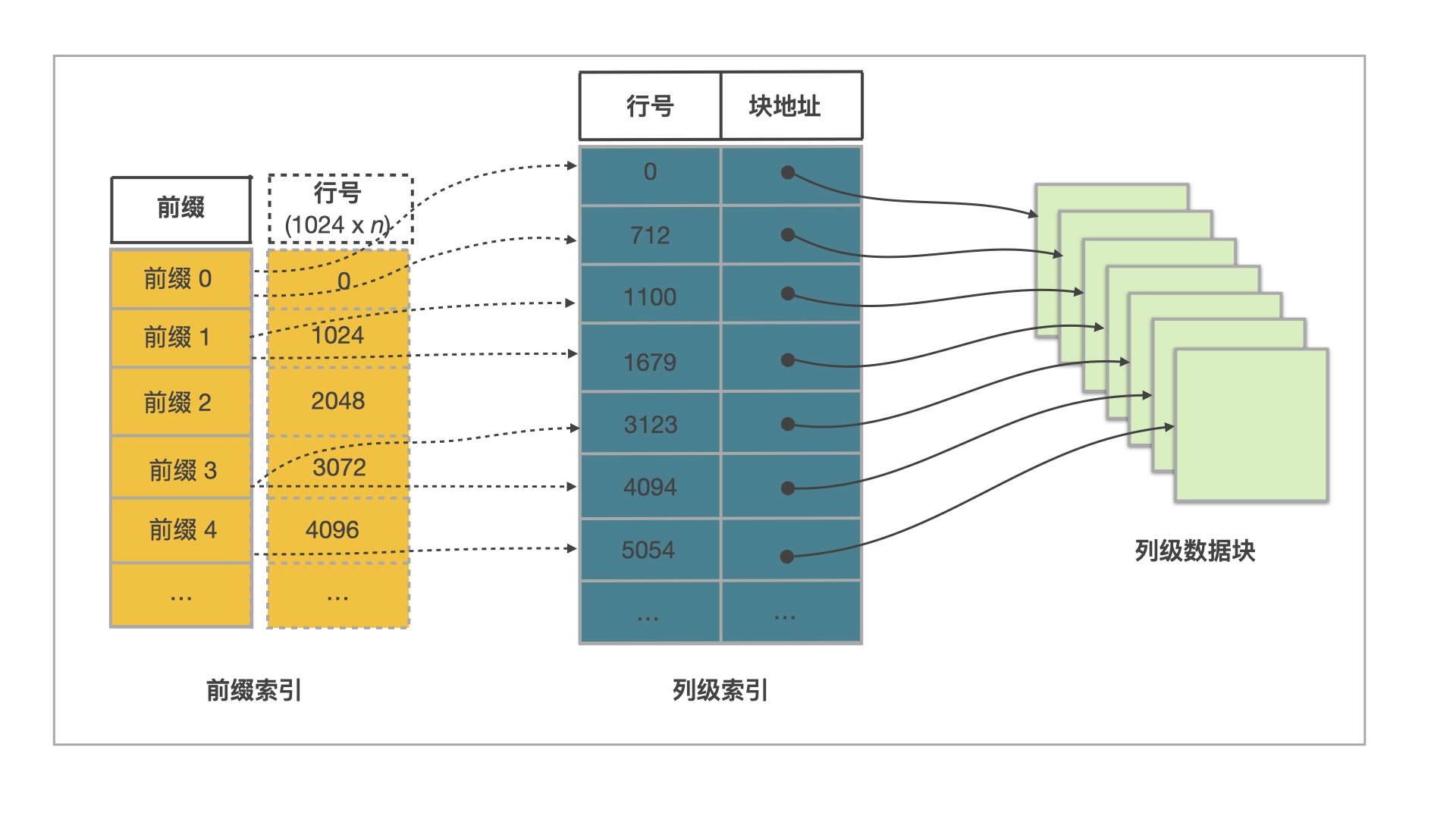
一张表中的数据组织主要由三部分构成:
前缀索引
表中每 1024 行数据构成一个逻辑数据块 (Data Block)。每个逻辑数据块在前缀索引表中存储一个索引项,索引项的内容为数据块中第一行数据的维度列所构成的前缀,长度不超过 36 字节。前缀索引是一种稀疏索引。使用表中某行数据的维度列所构成的前缀查找前缀索引表,可以确定该行数据所在逻辑数据块的起始行号。
列级数据块
表中每列数据都按 64 KB 分块存储。数据块作为一个单位单独编码、压缩,也作为 I/O 单位,整体写回设备或者读出。
列级索引
表中每列数据都有一个独立的行号索引。行号索引表中,该列的数据块和行号一一对应。每个行号索引项由对应数据块的起始行号、位置和长度信息构成。用某行数据的行号查找行号索引表,可以获取包含该行号对应的数据块所在的位置,读取目标数据块后,可以进一步查找数据。
由此可见,通过某行数据的维度列所构成的前缀查找该行数据的过程包含以下五个步骤:
先查找前缀索引表,获得逻辑数据块的起始行号。
查找维度列的行号索引,定位到维度列的数据块。
读取数据块。
解压、解码数据块。
从数据块中找到维度列前缀对应的数据项。
2 明细模型
明细模型是默认的建表模型。如果在建表时未指定任何模型,默认创建的是明细类型的表。
创建表时,支持定义排序键。如果查询的过滤条件包含排序键,则 StarRocks 能够快速地过滤数据,提高查询效率。明细模型适用于日志数据分析等场景,支持追加新数据,不支持修改历史数据。
2.1 适用场景
分析原始数据,例如原始日志、原始操作记录等。
查询方式灵活,不需要局限于预聚合的分析方式。
导入日志数据或者时序数据,主要特点是旧数据不会更新,只会追加新的数据。
2.2 创建表
例如,需要分析某时间范围的某一类事件的数据,则可以将事件时间(event_time)和事件类型(event_type)作为排序键。
在该业务场景下,建表语句如下:
CREATE TABLE IF NOT EXISTS detail ( event_time DATETIME NOT NULL COMMENT "datetime of event", event_type INT NOT NULL COMMENT "type of event", user_id INT COMMENT "id of user", device_code INT COMMENT "device code", channel INT COMMENT "" ) DUPLICATE KEY(event_time, event_type) DISTRIBUTED BY HASH(user_id) PROPERTIES ( "replication_num" = "3" );
注意
建表时必须使用 DISTRIBUTED BY HASH 子句指定分桶键,否则建表失败。分桶键的更多说明,请参见分桶。
2.3 使用说明
排序键的相关说明:
在建表语句中,排序键必须定义在其他列之前。
排序键可以通过
DUPLICATE KEY显式定义。本示例中排序键为event_time和event_type。
- 如果未指定,则默认选择表的前三列作为排序键。
- 明细模型中的排序键可以为部分或全部维度列。
建表时,支持为指标列创建 BITMAP、Bloom Filter 等索引。
3 聚合模型
建表时,支持定义排序键和指标列,并为指标列指定聚合函数。当多条数据具有相同的排序键时,指标列会进行聚合。在分析统计和汇总数据时,聚合模型能够减少查询时所需要处理的数据,提升查询效率。
3.1 适用场景
适用于分析统计和汇总数据。比如:
通过分析网站或 APP 的访问流量,统计用户的访问总时长、访问总次数。
广告厂商为广告主提供的广告点击总量、展示总量、消费统计等。
通过分析电商的全年交易数据,获得指定季度或者月份中,各类消费人群的爆款商品。
在这些场景中,数据查询和导入,具有以下特点:
多为汇总类查询,比如 SUM、MAX、MIN等类型的查询。
不需要查询原始的明细数据。
旧数据更新不频繁,只会追加新的数据。
3.2 原理
从数据导入至数据查询阶段,聚合模型内部同一排序键的数据会多次聚合,聚合的具体时机和机制如下:
数据导入阶段:数据按批次导入至聚合模型时,每一个批次的数据形成一个版本。在一个版本中,同一排序键的数据会进行一次聚合。
后台文件合并阶段 (Compaction) :数据分批次多次导入至聚合模型中,会生成多个版本的文件,多个版本的文件定期合并成一个大版本文件时,同一排序键的数据会进行一次聚合。
查询阶段:所有版本中同一排序键的数据进行聚合,然后返回查询结果。
因此,聚合模型中数据多次聚合,能够减少查询时所需要的处理的数据量,进而提升查询的效率。
例如,导入如下数据至聚合模型中,排序键为 Date、Country:
| Date | Country | PV |
|---|---|---|
| 2020.05.01 | CHN | 1 |
| 2020.05.01 | CHN | 2 |
| 2020.05.01 | USA | 3 |
| 2020.05.01 | USA | 4 |
在聚合模型中,以上四条数据会聚合为两条数据。这样在后续查询处理的时候,处理的数据量就会显著降低。
| Date | Country | PV |
|---|---|---|
| 2020.05.01 | CHN | 3 |
| 2020.05.01 | USA | 7 |
3.3 创建表
例如需要分析某一段时间内,来自不同城市的用户,访问不同网页的总次数。则可以将网页地址 site_id、日期 date 和城市代码 city_code 作为排序键,将访问次数 pv 作为指标列,并为指标列 pv 指定聚合函数为 SUM。
在该业务场景下,建表语句如下:
CREATE TABLE IF NOT EXISTS example_db.aggregate_tbl ( site_id LARGEINT NOT NULL COMMENT "id of site", date DATE NOT NULL COMMENT "time of event", city_code VARCHAR(20) COMMENT "city_code of user", pv BIGINT SUM DEFAULT "0" COMMENT "total page views" ) AGGREGATE KEY(site_id, date, city_code) DISTRIBUTED BY HASH(site_id) PROPERTIES ( "replication_num" = "3" );
注意
3.4 使用说明
排序键的相关说明:
在建表语句中,排序键必须定义在其他列之前。
排序键可以通过
AGGREGATE KEY显式定义。如果
AGGREGATE KEY未包含全部维度列(除指标列之外的列),则建表会失败。如果不通过
AGGREGATE KEY显示定义排序键,则默认除指标列之外的列均为排序键。
排序键必须满足唯一性约束,必须包含全部维度列,并且列的值不会更新。
指标列:通过在列名后指定聚合函数,定义该列为指标列。一般为需要汇总统计的数据。
聚合函数:指标列使用的聚合函数。聚合模型支持的聚合函数,请参见 CREATE TABLE。
查询时,排序键在多版聚合之前就能进行过滤,而指标列的过滤在多版本聚合之后。因此建议将频繁使用的过滤字段作为排序键,在聚合前就能过滤数据,从而提升查询性能。
建表时,不支持为指标列创建 BITMAP、Bloom Filter 等索引。
4 更新模型
建表时,支持定义主键和指标列,查询时返回主键相同的一组数据中的最新数据。相对于明细模型,更新模型简化了数据导入流程,能够更好地支撑实时和频繁更新的场景。
4.1 适用场景
实时和频繁更新的业务场景,例如分析电商订单。在电商场景中,订单的状态经常会发生变化,每天的订单更新量可突破上亿。
4.2 原理
更新模型可以视为聚合模型的特殊情况,指标列指定的聚合函数为 REPLACE,返回具有相同主键的一组数据中的最新数据。
数据分批次多次导入至更新模型,每一批次数据分配一个版本号,因此同一主键的数据可能有多个版本,查询时返回版本最新(即版本号最大)的数据。相对于明细模型,更新模型通过简化导入流程,能够更好地支持实时和频繁更新。
例如下表中,ID 是主键,value 是指标列,_version 是 StarRocks 内部的版本号。其中,ID 为 1 的数据有两个导入批次,版本号分别为 1 和 2;ID 为 2 的数据有三个导入批次,版本号分别为 3、4、5。
| ID | value | _version |
|---|---|---|
| 1 | 100 | 1 |
| 1 | 101 | 2 |
| 2 | 100 | 3 |
| 2 | 101 | 4 |
| 2 | 102 | 5 |
查询 ID 为 1 的数据时,仅会返回最新版本 2 的数据,而查询 ID 为 2 的数据时,仅会返回最新版本 5 的数据,最终查询结果如下:
| ID | value |
|---|---|
| 1 | 101 |
| 2 | 102 |
4.3 创建表
在电商订单分析场景中,经常按照日期对订单状态进行统计分析,则可以将经常使用的过滤字段订单创建时间 create_time、订单编号 order_id 作为主键,其余列订单状态 order_state 和订单总价 total_price 作为指标列。这样既能够满足实时更新订单状态的需求,又能够在查询中进行快速过滤。
在该业务场景下,建表语句如下:
CREATE TABLE IF NOT EXISTS orders ( create_time DATE NOT NULL COMMENT "create time of an order", order_id BIGINT NOT NULL COMMENT "id of an order", order_state INT COMMENT "state of an order", total_price BIGINT COMMENT "price of an order" ) UNIQUE KEY(create_time, order_id) DISTRIBUTED BY HASH(order_id) PROPERTIES ( "replication_num" = "3" );
注意
4.4 使用说明
主键的相关说明:
在建表语句中,主键必须定义在其他列之前。
主键通过
UNIQUE KEY定义。主键必须满足唯一性约束,且列的值不会修改。
设置合理的主键。
查询时,主键在聚合之前就能进行过滤,而指标列的过滤通常在多版本聚合之后,因此建议将频繁使用的过滤字段作为主键,在聚合前就能过滤数据,从而提升查询性能。
聚合过程中会比较所有主键,因此需要避免设置过多的主键,以免降低查询性能。如果某个列只是偶尔会作为查询中的过滤条件,则不建议放在主键中。
建表时,不支持为指标列创建 BITMAP、Bloom Filter 等索引。
5 主键模型
主键模型支持分别定义主键和排序键。数据导入至主键模型的表时先按照排序键排序后存储。查询时返回主键相同的一组数据中的最新数据。相对于更新模型,主键模型在查询时不需要执行聚合操作,并且支持谓词和索引下推,能够在支持实时和频繁更新等场景的同时,提供高效查询。
说明
- 3.0 版本之前,主键模型不支持分别定义主键和排序键。
- 自 3.1 版本起,存算分离模式支持创建主键模型表,并且自 3.1.4 版本起,支持基于本地磁盘上的持久化索引。
5.1 适用场景
主键模型适用于实时和频繁更新的场景,例如:
实时对接事务型数据至 StarRocks。事务型数据库中,除了插入数据外,一般还会涉及较多更新和删除数据的操作,因此事务型数据库的数据同步至 StarRocks 时,建议使用主键模型。通过 Flink-CDC 等工具直接对接 TP 的 Binlog,实时同步增删改的数据至主键模型,可以简化数据同步流程,并且相对于 Merge-On-Read 策略的更新模型,查询性能能够提升 3~10 倍。
利用部分列更新轻松实现多流 JOIN。在用户画像等分析场景中,一般会采用大宽表方式来提升多维分析的性能,同时简化数据分析师的使用模型。而这种场景中的上游数据,往往可能来自于多个不同业务(比如来自购物消费业务、快递业务、银行业务等)或系统(比如计算用户不同标签属性的机器学习系统),主键模型的部分列更新功能就很好地满足这种需求,不同业务直接各自按需更新与业务相关的列即可,并且继续享受主键模型的实时同步增删改数据及高效的查询性能。
5.2 注意事项
如果开启持久化索引,主键模型大大降低了主键索引对内存的占用。因为导入时少部分主键索引存在内存中,大部分主键索引存在磁盘中。单条主键编码后的最大长度为 128 字节。
如果不开启持久化索引,主键模型适用于主键占用空间相对可控的场景,因为导入时将主键索引加载至内存中。单条主键编码后的最大长度和内存占用上限为 128 字节。 如下两个场景中,主键占用空间相对可控:
- 数据有冷热特征,即最近几天的热数据才经常被修改,老的冷数据很少被修改。例如,MySQL订单表实时同步到 StarRocks 中提供分析查询。其中,数据按天分区,对订单的修改集中在最近几天新创建的订单,老的订单完成后就不再更新,因此导入时其主键索引就不会加载,也就不会占用内存,内存中仅会加载最近几天的索引。
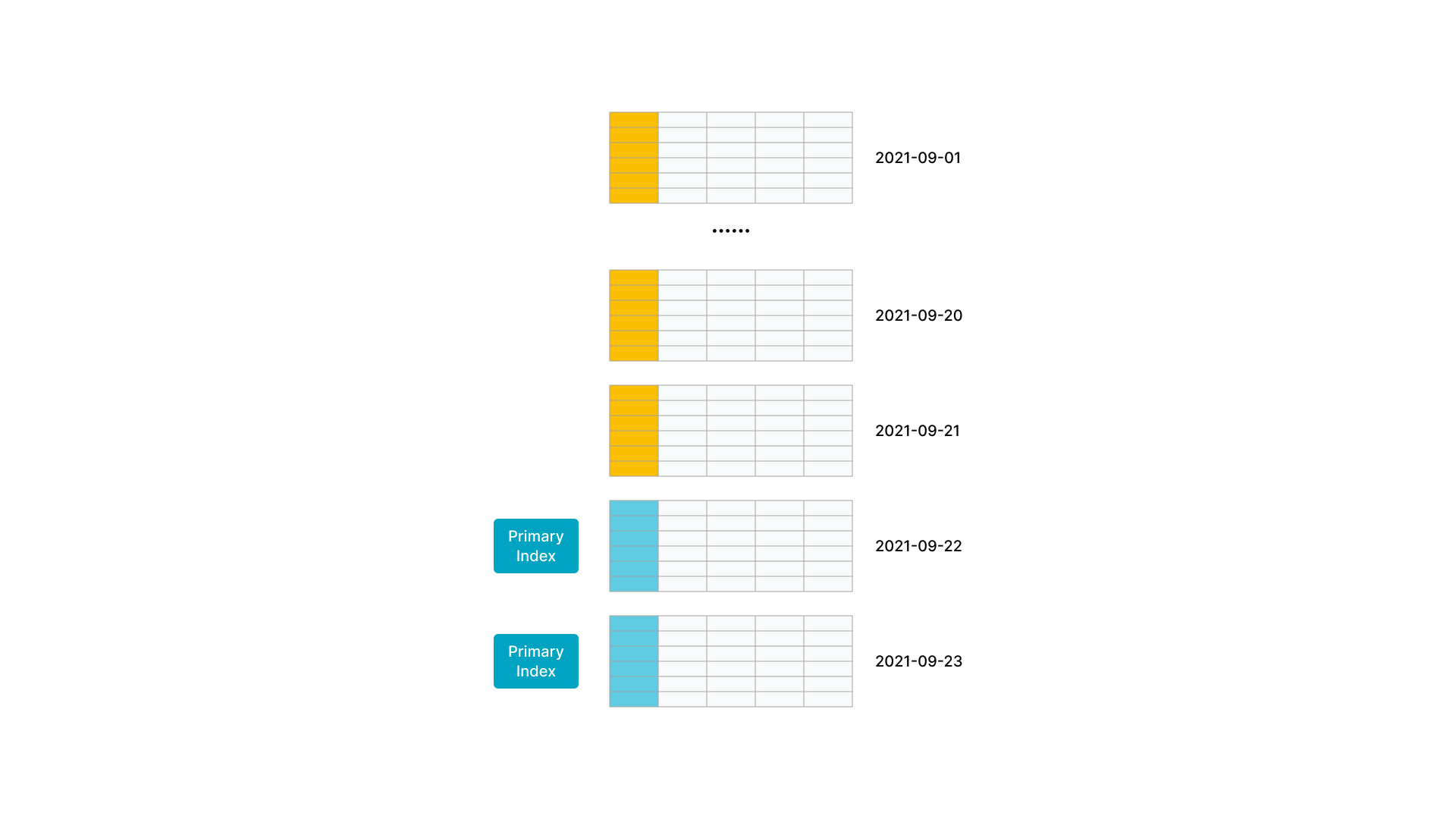
如图所示,数据按天分区,最新两个分区的数据更新比较频繁。
- 大宽表(数百到数千列)。主键只占整个数据的很小一部分,其内存开销比较低。比如用户状态和画像表,虽然列非常多,但总的用户数不大(千万至亿级别),主键索引内存占用相对可控。
如图所示,大宽表中主键只占一小部分,且数据行数不多。
5.3 原理
主键模型是由 StarRocks 全新设计开发的存储引擎支撑。相比于更新模型,主键模型的元数据组织、读取、写入方式完全不同,不需要执行聚合操作,并且支持谓词和索引下推,极大地提高了查询性能。
更新模型整体上采用了 Merge-On-Read 的策略。虽然写入时处理简单高效,但是查询时需要在线聚合多版本。并且由于 Merge 算子的存在,谓词和索引无法下推,严重影响了查询性能。
而主键模型采用了 Delete+Insert 的策略,保证同一个主键下仅存在一条记录,这样就完全避免了 Merge 操作。具体实现方式如下:
StarRocks 收到对某记录的更新操作时,会通过主键索引找到该条记录的位置,并对其标记为删除,再插入一条新的记录。相当于把 Update 改写为 Delete+Insert。
StarRocks 收到对某记录的删除操作时,会通过主键索引找到该条记录的位置,对其标记为删除。
这样,查询时不需要执行聚合操作,不影响谓词和索引的下推,保证了查询的高效执行。
5.4 创建表
- 例如,需要按天实时分析订单,则可以将时间
dt、订单编号order_id作为主键,其余列为指标列。建表语句如下:
create table orders ( dt date NOT NULL, order_id bigint NOT NULL, user_id int NOT NULL, merchant_id int NOT NULL, good_id int NOT NULL, good_name string NOT NULL, price int NOT NULL, cnt int NOT NULL, revenue int NOT NULL, state tinyint NOT NULL ) PRIMARY KEY (dt, order_id) PARTITION BY RANGE(`dt`) ( PARTITION p20210820 VALUES [('2021-08-20'), ('2021-08-21')), PARTITION p20210821 VALUES [('2021-08-21'), ('2021-08-22')), PARTITION p20210929 VALUES [('2021-09-29'), ('2021-09-30')), PARTITION p20210930 VALUES [('2021-09-30'), ('2021-10-01')) ) DISTRIBUTED BY HASH(order_id) PROPERTIES ( "replication_num" = "3", "enable_persistent_index" = "true" );
注意
- 例如,需要按地域、最近活跃时间实时分析用户情况,则可以将表示用户 ID 的
user_id列作为主键,表示地域的address列和表示最近活跃时间的last_active列作为排序键。建表语句如下:
create table users ( user_id bigint NOT NULL, name string NOT NULL, email string NULL, address string NULL, age tinyint NULL, sex tinyint NULL, last_active datetime, property0 tinyint NOT NULL, property1 tinyint NOT NULL, property2 tinyint NOT NULL, property3 tinyint NOT NULL ) PRIMARY KEY (user_id) DISTRIBUTED BY HASH(user_id) ORDER BY(`address`,`last_active`) PROPERTIES ( "replication_num" = "3", "enable_persistent_index" = "true" );
5.5 使用说明
主键相关的说明:
在建表语句中,主键必须定义在其他列之前。
主键通过
PRIMARY KEY定义。主键必须满足唯一性约束,且列的值不会修改。本示例中主键为
dt、order_id。主键支持以下数据类型:BOOLEAN、TINYINT、SMALLINT、INT、BIGINT、LARGEINT、DATE、DATETIME、VARCHAR/STRING。并且不允许为 NULL。
分区列和分桶列必须在主键中。
enable_persistent_index:是否持久化主键索引,同时使用磁盘和内存存储主键索引,避免主键索引占用过大内存空间。通常情况下,持久化主键索引后,主键索引所占内存为之前的 1/10。您可以在建表时,在PROPERTIES中配置该参数,取值范围为true或者false(默认值)。自 2.3.0 版本起,StarRocks 支持配置该参数。
如果磁盘为固态硬盘 SSD,则建议设置为
true。如果磁盘为机械硬盘 HDD,并且导入频率不高,则也可以设置为true。建表后,如果您需要修改该参数,请参见 ALTER TABLE 修改表的属性 。
自 3.1 版本起,存算分离模式支持创建主键模型表,并且自 3.1.4 版本起,支持基于本地磁盘上的持久化索引。
如果未开启持久化索引,导入时主键索引存在内存中,可能会导致占用内存较多。因此建议您遵循如下建议:
合理设置主键的列数和长度。建议主键为占用内存空间较少的数据类型,例如 INT、BIGINT 等,暂时不建议为 VARCHAR。
在建表前根据主键的数据类型和表的行数来预估主键索引占用内存空间,以避免出现内存溢出。以下示例说明主键索引占用内存空间的计算方式:
假设存在主键模型,主键为
dt、id,数据类型为 DATE(4 个字节)、BIGINT(8 个字节)。则主键占 12 个字节。假设该表的热数据有 1000 万行,存储为三个副本。
则内存占用的计算方式:
(12 + 9(每行固定开销) ) * 1000W * 3 * 1.5(哈希表平均额外开销) = 945 M
通过
ORDER BY关键字指定排序键,可指定为任意列的排列组合。
注意
- 如果指定了排序键,就根据排序键构建前缀索引;如果没指定排序键,就根据主键构建前缀索引。
支持使用 ALTER TABLE 进行表结构变更,但是存在如下注意事项:
不支持修改主键。
对于排序键,支持通过 ALTER TABLE ... ORDER BY ... 重新指定排序键。不支持删除排序键,不支持修改排序键中列的数据类型。
不支持调整列顺序。
自2.3 版本起,除了主键之外的列新增支持 BITMAP、HLL 数据类型。
创建表时,支持为除了主键之外的列创建 BITMAP、Bloom Filter 等索引。
自 2.4 版本起,支持基于主键模型的表创建异步物化视图。
6 表模型最佳实践
您可以在建表阶段通过以下方式优化 StarRocks 性能。
6.1 选择表类型
StarRocks 支持四种表类型:主键表 (PRIMARY KEY),聚合表 (AGGREGATE KEY),更新表 (UNIQUE KEY),以及明细表 (DUPLICATE KEY)。四种类型的表中数据都是依据 KEY 进行排序。
聚合表
聚合表中,如果新写入的记录的 Key 列与表中的旧记录相同时,新旧记录被聚合,目前支持的聚合函数有 SUM,MIN,MAX,以及 REPLACE。聚合表可以提前聚合数据,适合报表和多维分析业务。
CREATE TABLE site_visit ( siteid INT, city SMALLINT, username VARCHAR(32), pv BIGINT SUM DEFAULT '0' ) AGGREGATE KEY(siteid, city, username) DISTRIBUTED BY HASH(siteid);
更新表 (UNIQUE KEY)
更新表中,如果新写入的记录的 Key 列与表中的旧记录相同时,则新记录会覆盖旧记录。目前 UNIQUE KEY 的实现与 AGGREGATE KEY 的 REPLACE 聚合方法一样,二者本质上可以认为相同。更新表适用于有更新的分析业务。
CREATE TABLE sales_order ( orderid BIGINT, status TINYINT, username VARCHAR(32), amount BIGINT DEFAULT '0' ) UNIQUE KEY(orderid) DISTRIBUTED BY HASH(orderid);
明细表 (DUPLICATE KEY)
明细表只用于排序,相同 DUPLICATE KEY 的记录会同时存在。明细表适用于数据无需提前聚合的分析业务。
CREATE TABLE session_data ( visitorid SMALLINT, sessionid BIGINT, visittime DATETIME, city CHAR(20), province CHAR(20), ip varchar(32), brower CHAR(20), url VARCHAR(1024) ) DUPLICATE KEY(visitorid, sessionid) DISTRIBUTED BY HASH(sessionid, visitorid);
主键表 (PRIMARY KEY)
主键表保证同一个主键下仅存在一条记录。相对于更新表,主键表在查询时不需要执行聚合操作,并且支持谓词和索引下推,能够在支持实时和频繁更新等场景的同时,提供高效查询。
CREATE TABLE orders ( dt date NOT NULL, order_id bigint NOT NULL, user_id int NOT NULL, merchant_id int NOT NULL, good_id int NOT NULL, good_name string NOT NULL, price int NOT NULL, cnt int NOT NULL, revenue int NOT NULL, state tinyint NOT NULL ) PRIMARY KEY (dt, order_id) DISTRIBUTED BY HASH(order_id);
6.2 使用 Colocate Table
StarRocks 支持将分布相同的相关表存储与共同的分桶列,从而相关表的 JOIN 操作可以直接在本地进行,进而加速查询。更多信息,参考 Colocate Join。
CREATE TABLE colocate_table ( visitorid SMALLINT, sessionid BIGINT, visittime DATETIME, city CHAR(20), province CHAR(20), ip varchar(32), brower CHAR(20), url VARCHAR(1024) ) DUPLICATE KEY(visitorid, sessionid) DISTRIBUTED BY HASH(sessionid, visitorid) PROPERTIES( "colocate_with" = "group1" );
6.3 使用星型模型
StarRocks 支持选择更灵活的星型模型 (star schema) 来替代传统建模方式的大宽表。通过星型模型,您可以用一个视图来取代宽表进行建模,直接使用多表关联来查询。在 SSB 的标准测试集的对比中,StarRocks 的多表关联性能相较于单表查询并无明显下降。
相比星型模型,宽表的缺点包括:
维度更新成本更高。宽表中,维度信息更新会反应到整张表中,其更新的频率直接影响查询的效率。
维护成本更高。宽表的建设需要额外的开发工作、存储空间和数据 Backfill 成本。
导入成本更高。宽表的 Schema 字段数较多,聚合表中可能包含更多 Key 列,其导入过程中需要排序的列会增加,进而导致导入时间变长。
建议您优先使用星型模型,可以在保证灵活的基础上获得高效的指标分析效果。但如果您的业务对于高并发或者低延迟有较高的要求,您仍可以选择宽表模型进行加速。StarRocks 提供与 ClickHouse 相当的宽表查询性能。
6.4 使用分区和分桶
StarRocks支持两级分区存储,第一层为 RANGE 分区(Partition),第二层为 HASH 分桶(Bucket)。
RANGE 分区用于将数据划分成不同区间,逻辑上等同于将原始表划分成了多个子表。在生产环境中,多数用户会根据按时间进行分区。基于时间进行分区有以下好处:
可区分冷热数据。
可使用 StarRocks 分级存储(SSD + SATA)功能。
按分区删除数据时,更加迅速。
HASH 分桶指根据 Hash 值将数据划分成不同的 Bucket。
建议采用区分度大的列做分桶,避免出现数据倾斜。
为方便数据恢复,建议单个 Bucket 保持较小的 Size,应保证其中数据压缩后大小保持在 100MB 至 1GB 左右。建议您在建表或增加分区时合理考虑 Bucket 数目,其中不同分区可指定不同的 Bucket 数量。
不建议采用 Random 分桶方式。建表时,请指定明确的 Hash 分桶列。
6.5 使用稀疏索引和 Bloomfilter
StarRocks 支持对数据进行有序存储,在数据有序的基础上为其建立稀疏索引,索引粒度为 Block(1024 行)。
稀疏索引选取 Schema 中固定长度的前缀作为索引内容,目前 StarRocks 选取 36 个字节的前缀作为索引。
建表时,建议您将查询中常见的过滤字段放在 Schema 的前部。区分度越大,频次越高的查询字段应当被放置于更前部。VARCHAR 类型的字段只能作为稀疏索引的最后一个字段,因为索引会在 VARCHAR 字段处截断,VARCHAR 数据如果出现在前面,索引的长度可能不足 36 个字节。
例如,对于上述 site_visit表,其排序列包括 siteid,city,username 三列。其中,siteid 所占字节数为 4,city 所占字节数为 2,username 所占字节数为 32,所以该表的前缀索引的内容为 siteid + city + username 的前 30 个字节。
除稀疏索引之外,StarRocks 还提供 Bloomfilter 索引。Bloomfilter 索引对区分度比较大的列过滤效果明显。如果需要将 VARCHAR 字段前置,您可以建立 Bloomfilter 索引。
6.6 使用倒排索引
StarRocks 支持倒排索引,采用位图技术构建索引(Bitmap Index)。您可以将索引应用在明细表的所有列、聚合表和更新表的 Key 列上。位图索引适合取值空间较小的列,例如性别、城市、省份等信息列上。随着取值空间的增加,位图索引会同步膨胀。
6.7 使用物化视图
物化视图(Rollup)本质上可以理解为原始表(Base table)的一个物化索引。建立物化视图时,您可以只选取 Base table 中的部分列作为 schema,schema 中的字段顺序也可与 Base table 不同。下列情形可以考虑建立物化视图:
- Base table 中数据聚合度不高。这通常是因为 Base table 有区分度比较大的字段而导致。此时,您可以考虑选取部分列,建立物化视图。对于上述
site_visit表,siteid可能导致数据聚合度不高。如果有经常根据城市统计pv需求,可以建立一个只有city,pv的物化视图。
ALTER TABLE site_visit ADD ROLLUP rollup_city(city, pv);
- Base table 中的前缀索引无法命中,这通常是因为 base table 的建表方式无法覆盖所有的查询模式。此时,您可以考虑调整列顺序,建立物化视图。对于上述
session_data表,如果除了通过visitorid分析访问情况外,还有通过brower,province分析的情形,可以单独建立物化视图。
ALTER TABLE session_data ADD ROLLUP rollup_brower(brower,province,ip,url) DUPLICATE KEY(brower,province);
6.8 优化导入性能
StarRocks 目前提供 Broker Load 和 Stream Load 两种导入方式,通过指定导入 label 标识一批次的导入。StarRocks 对单批次的导入会保证原子生效,即使单次导入多张表也同样保证其原子性。
Stream Load:通过 HTTP 推流方式导入数据,用于微批导入。该模式下,1MB 数据导入延迟可维持在秒级别,适合高频导入。
Broker Load:通过拉取的方式批量导入数据,适合大批量数据的导入。
6.9 优化 Schema Change 性能
StarRocks 目前支持三种 Schema Change 方式,即 Sorted Schema Change,Direct Schema Change,Linked Schema Change。
- Sorted Schema Change:改变列的排序方式,需对数据进行重新排序。例如删除排序列中的一列,字段重排序。
ALTER TABLE site_visit DROP COLUMN city;
- Direct Schema Change:无需重新排序,但是需要对数据做一次转换。例如修改列的类型,在稀疏索引中加一列等。
ALTER TABLE site_visit MODIFY COLUMN username varchar(64);
- Linked Schema Change:无需转换数据,直接完成。例如加列操作。
ALTER TABLE site_visit ADD COLUMN click bigint SUM default '0';
建议您在建表时考虑好 Schema,以便加快后续 Schema Change 速度。