E-MapReduce
E-MapReduce



组件与 API 参考

请输入


- 文档首页
 E-MapReduce组件操作指南Hue最佳实践通过hue进行数据查询
E-MapReduce组件操作指南Hue最佳实践通过hue进行数据查询

通过hue进行数据查询
本文为您介绍如何通过 Hue 进行数据查询。
1 使用前提
- 已创建包含 Hue 组件服务的 EMR 集群。详见 创建集群。
- 集群的访问链接中需要为 ECS 实例绑定弹性公网 IP,公网操作详见绑定公网IP,其余详见访问链接。
- 需要在 集群详情 > 访问链接 > 快速配置服务端口 中,给源地址和对应端口添加白名单才可继续访问。
2 登录 Hue UI
- 登录 EMR 控制台。
- 在左侧导航栏中,进入 集群列表 > 集群名称详情 > 访问链接, 点击 HUE UI 访问链接进入。
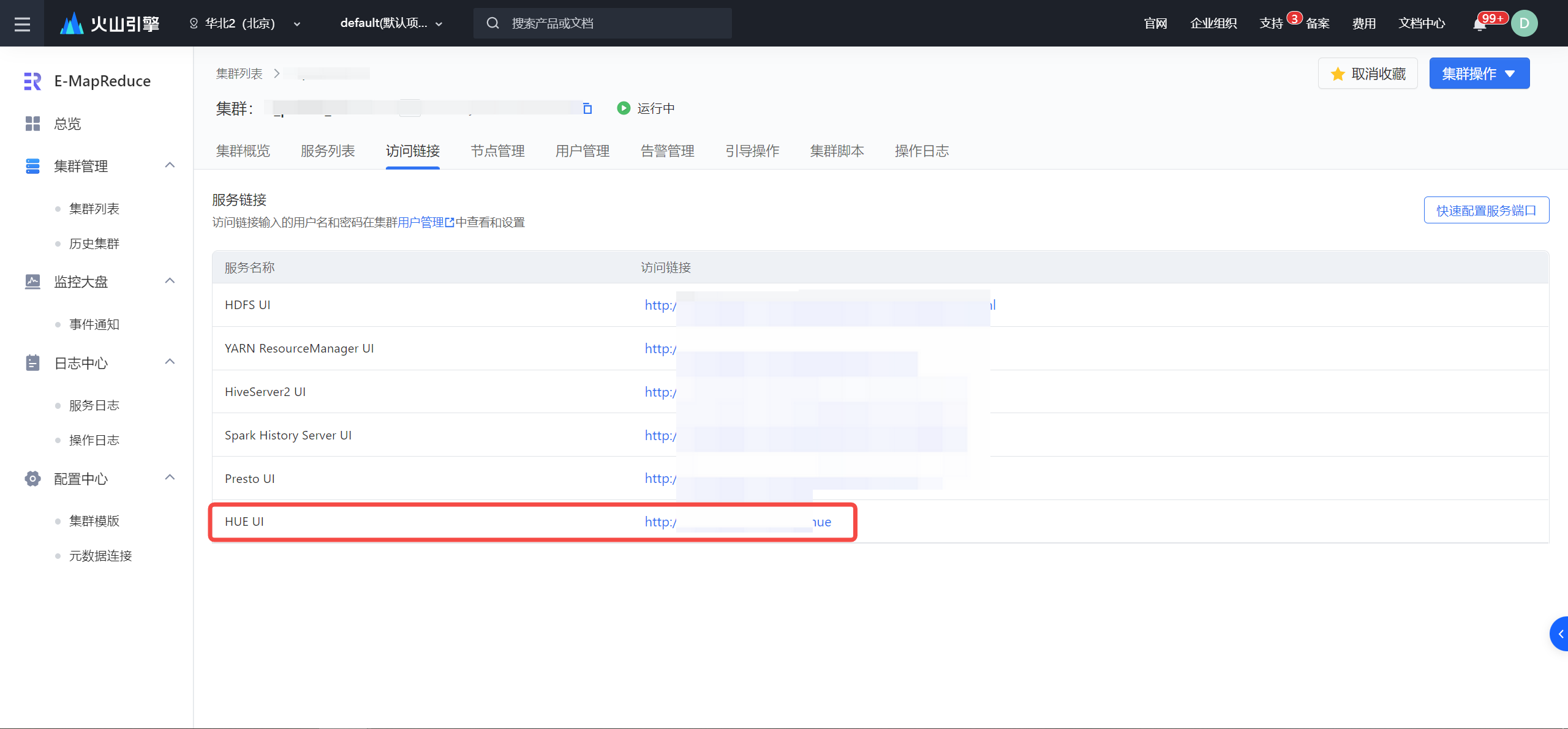
- 在窗口输入 Hue 登录的用户名和密码。
说明
Hue 已默认接入了 LDAP 鉴权,用户可使用 LDAP 中已有账号进行登录。首次登录需先添加用户,详细操作请参考:1 用户管理。
3 SQL查询
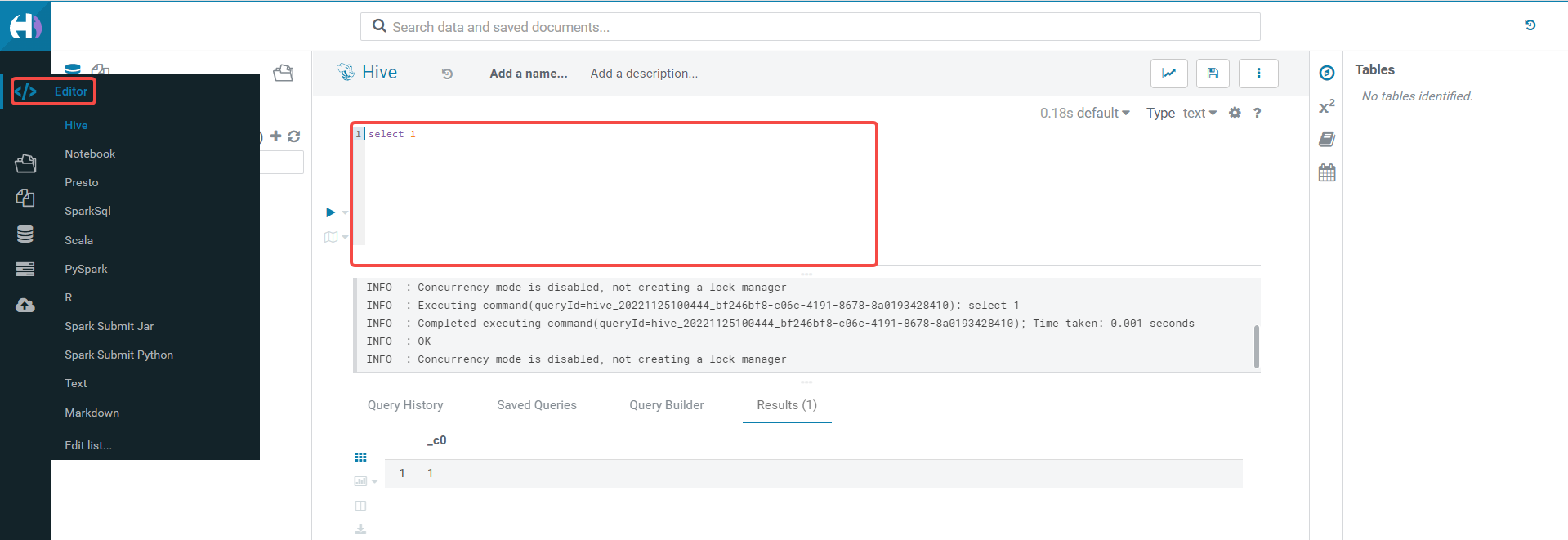
- 在左侧导航栏,Editor 中可以选择 Hive, SparkSQL, Presto, Trino 等已安装好的引擎。
- 在右侧 notebook 编辑框中,编辑和执行相关 SQL 语句并查看结果。
4 本地提交Spark作业
从本地文件上传到 Hadoop 集群进行 Spark 计算,只需从 Hue 界面上进行简单操作,即可查看到计算结果。例如下方以计算 pi 的值为例:
准备好本地文件demo.py:
# # Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # import sys from random import random from operator import add from pyspark.sql import SparkSession if __name__ == "__main__": """ Usage: pi [partitions] """ spark = SparkSession\ .builder\ .appName("PythonPi")\ .getOrCreate() partitions = int(sys.argv[1]) if len(sys.argv) > 1 else 2 n = 100000 * partitions def f(_): x = random() * 2 - 1 y = random() * 2 - 1 return 1 if x ** 2 + y ** 2 <= 1 else 0 count = spark.sparkContext.parallelize(range(1, n + 1), partitions).map(f).reduce(add) print("Pi is roughly %f" % (4.0 * count / n)) spark.stop()在左侧导航栏 Editor 中选择 Spark Submit Python 并单击进入上传界面。
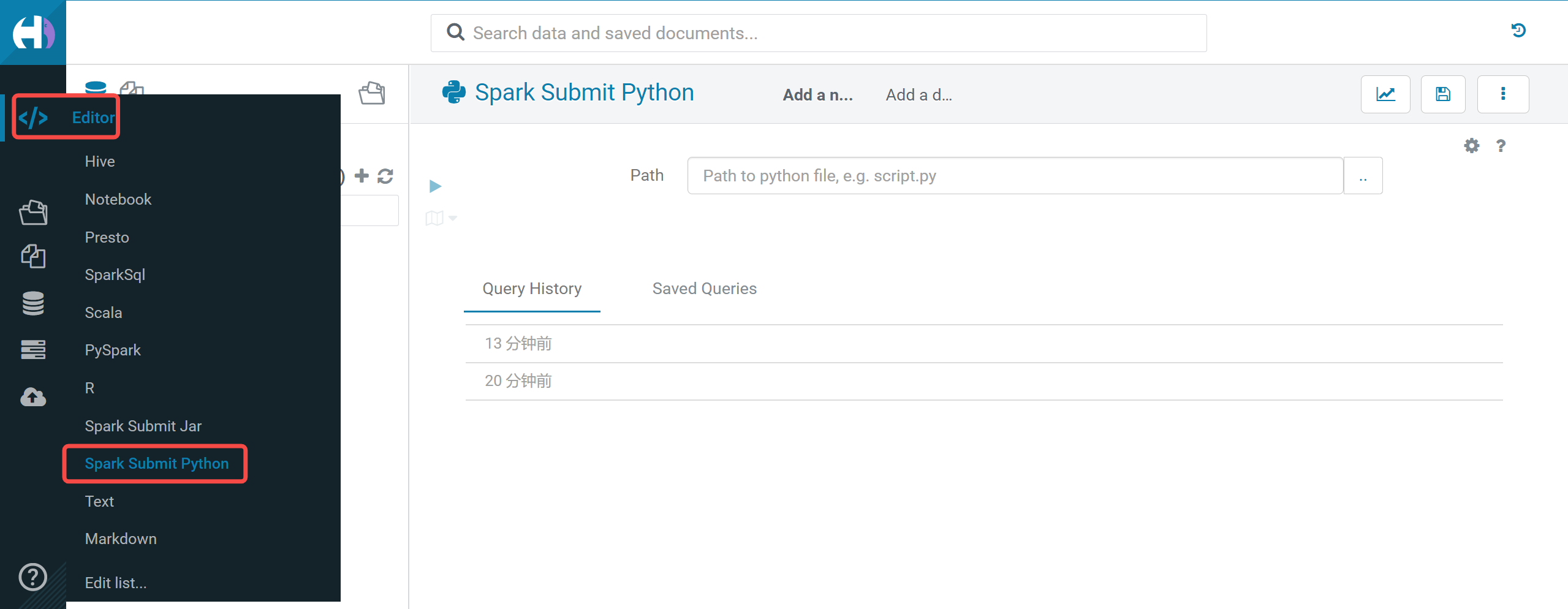
从本地上传 demo.py 文件
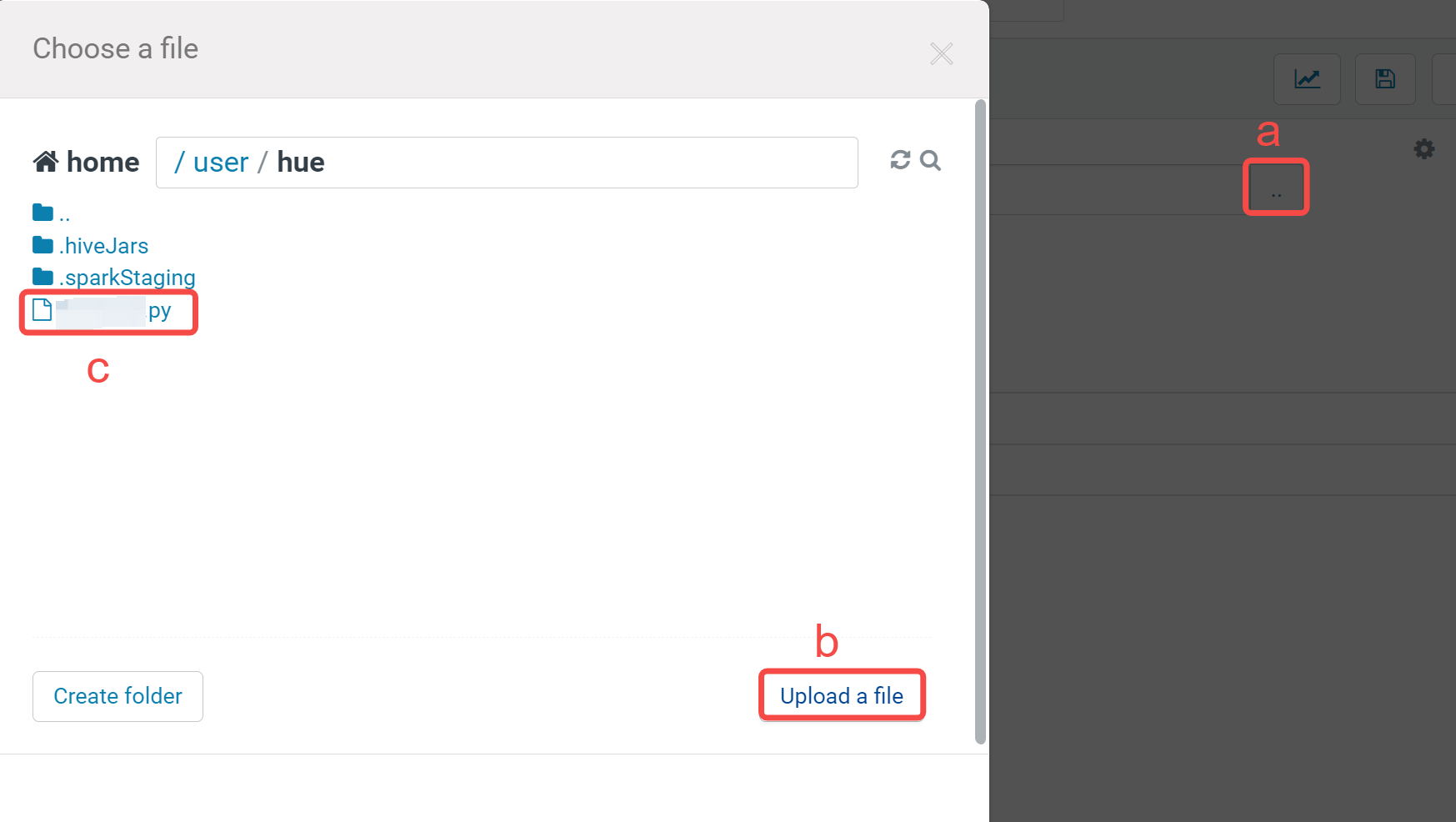
- 单击文件入口。
- 单击 Upload a file 按钮,并选择本地 demo.py 文件上传。
- 单击上传成功的文件加入到 Path。
上传文件后,单击左侧执行按钮,Spark 即开始运行作业。
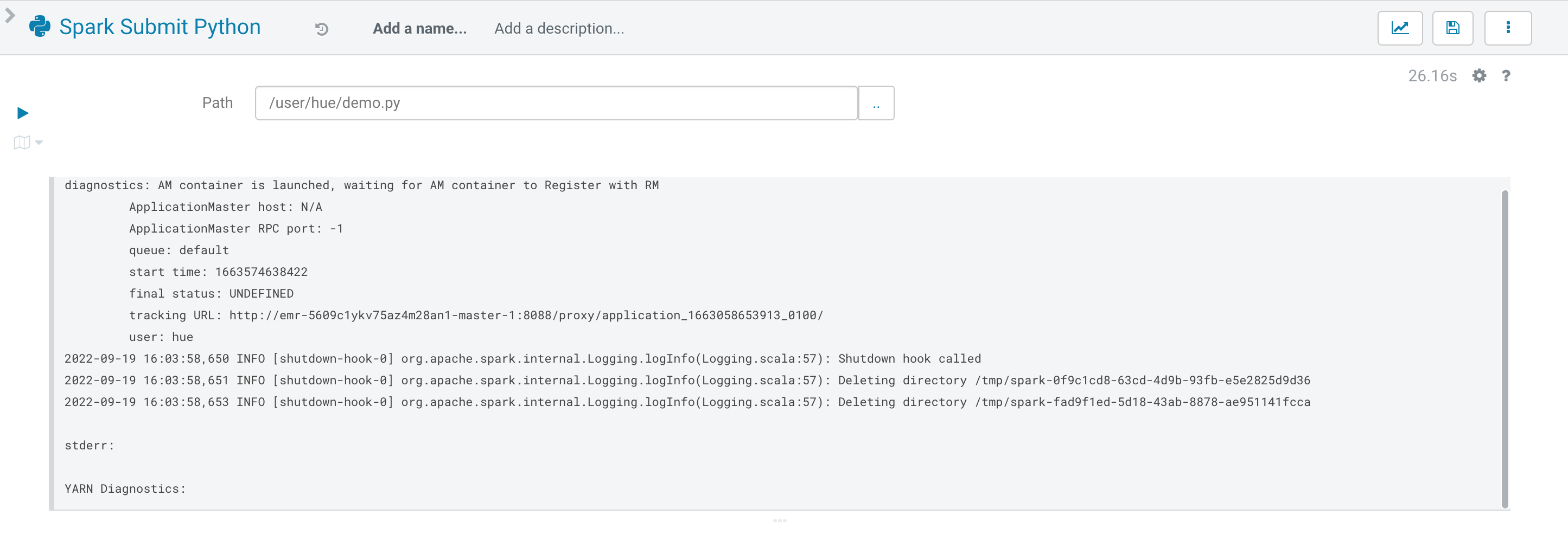
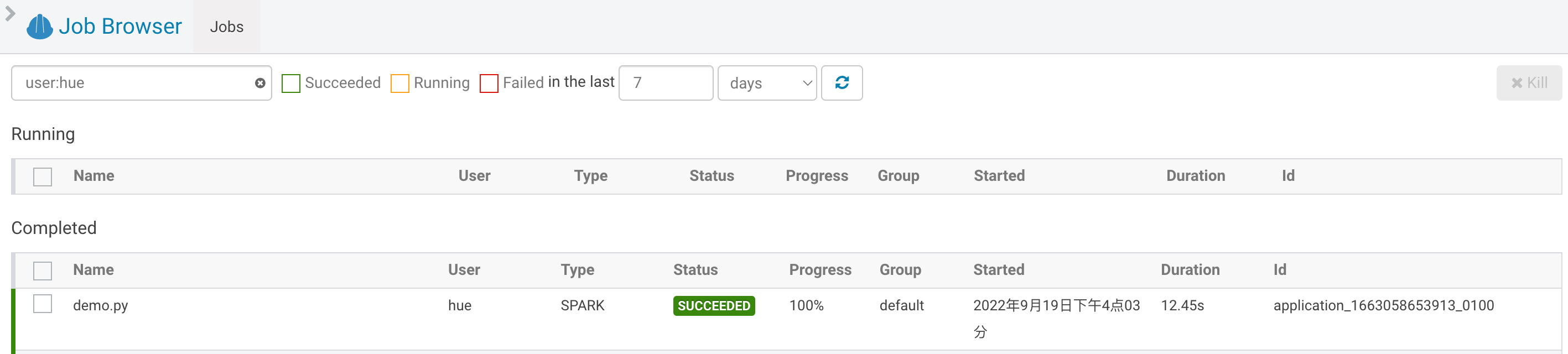
待作业运行成功后,从左侧导航栏单击并进入 Jobs 界面,可以看到刚才 demo 的作业,查看计算结果。
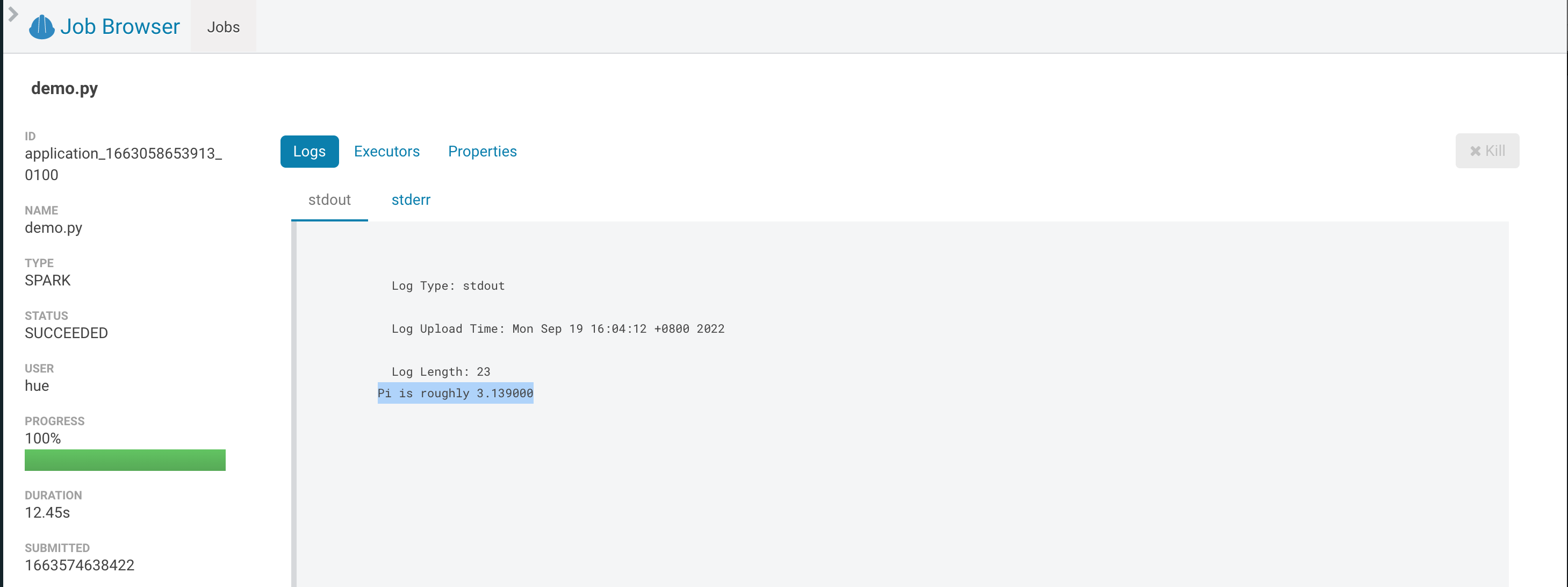
点击该 application,可以查看详情,包括该计算的输出结果(Pi 的近似值)。
最近更新时间:2024.09.29 14:09:16
这个页面对您有帮助吗?
有用
有用
无用
无用