火山引擎 E-MapReduce(EMR)支持通过 Spark SQL 写入、支持 Hive 和 Presto 引擎查询 Paimon 表。在查询方面,EMR 的 Paimon 版本对 Presto 有相关的适配,直接内置集成在了 presto 中,无需额外配置。
1 Paimon - Spark集成
本段主要介绍如何使用 Spark ThriftServer 配置连接 Paimon。
登录 EMR 控制台。
在左侧导航栏中,进入集群管理 > 集群列表 > 集群详情 > 服务列表 > Spark 服务参数界面。
安装完 Paimon 后,可以到 sparkthriftserver 配置页面,在 spark-defaults 中
修改 spark.sql.extensions 配置加上 org.apache.paimon.spark.extensions.PaimonSparkSessionExtensions (如果已有存在的值,用逗号隔开)
增加spark.sql.catalog.paimon=org.apache.paimon.spark.SparkCatalog
增加spark.sql.catalog.paimon.metastore=hive
使用 beeline 连接 sparkthriftserver 用于测试, 参考 LDAP 文档和 Spark最佳实践 ,来配置用户名密码进行 sparkthriftserver 连接。
beeline -u jdbc:hive2://emr-30f8q2lxxxxxxxxxx-master-1:10000/default -n xxxx -p xxxxx
然后您可使用标准SparkSQL操作Paimon表。
2 Paimon - Presto集成
修改paimon.properties的中的warehouse参数,指向实际的hive warehouse路径,比如:
hdfs://emr-cluster/user/hive/warehouse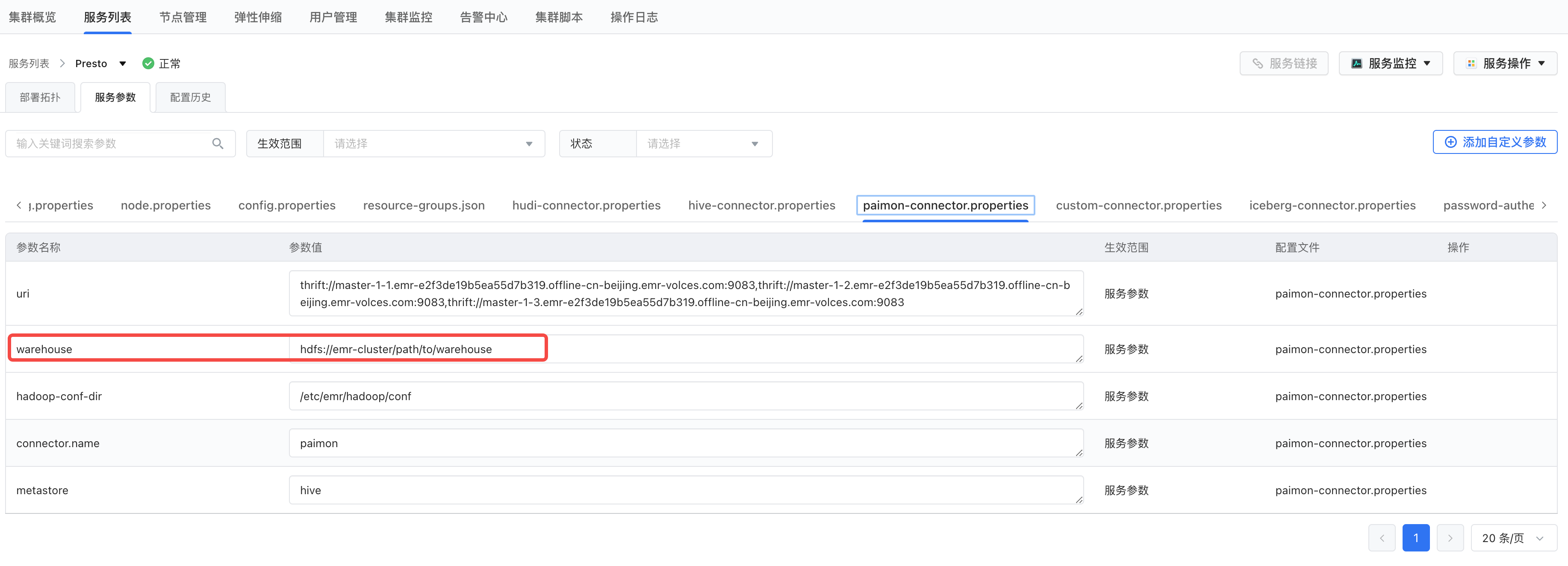
重启所有presto组件
查看catalog
SHOW CATALOGS;
创建schema
CREATE SCHEMA paimon.test_db;
查询数据
SELECT * FROM paimon.test_db.test_table;
3 Paimon - StarRocks集成
3.1 环境集成
将Hadoop集群的core-site.xml和hdfs-site.xml配置文件拷贝到StarRocks集群,并重启StarRocks服务。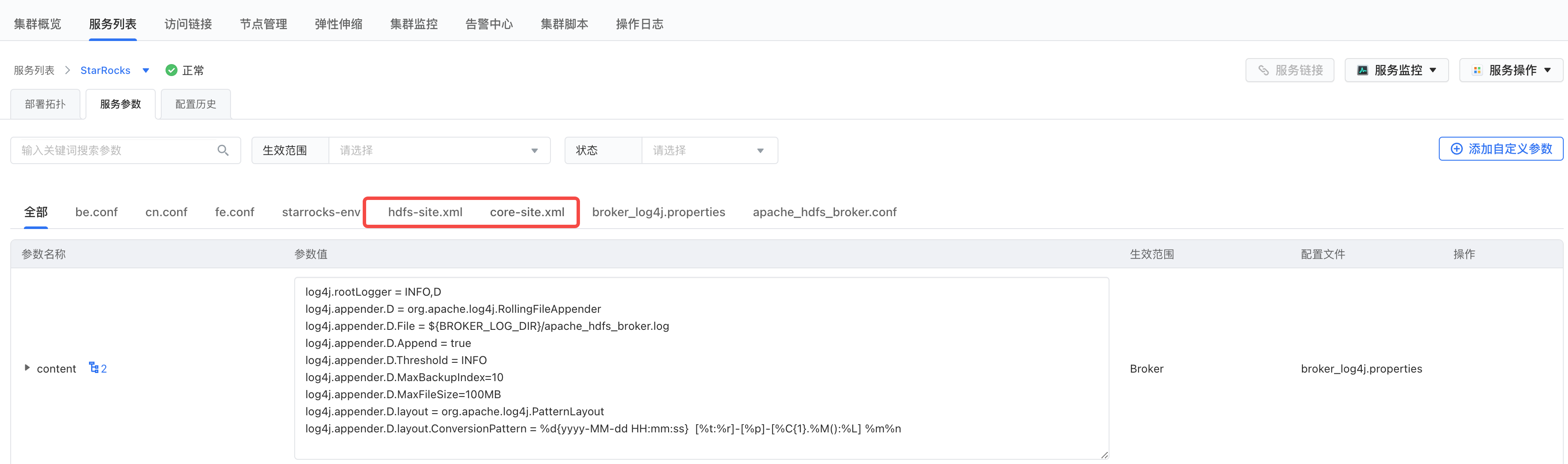
3.2 StarRocks查询Paimon表
创建Catalog
CREATE EXTERNAL CATALOG <catalog_name> [COMMENT <comment>] PROPERTIES ( "type" = "paimon", "paimon.catalog.type" = "hive", "paimon.catalog.warehouse" = "hdfs://nn:8020/path/to/warehouse", "hive.metastore.uris" = "thrift://master-1-1.xxx.emr-volces.com:9083" )
查看catalog下的库
SHOW DATABASES FROM <catalog_name>;
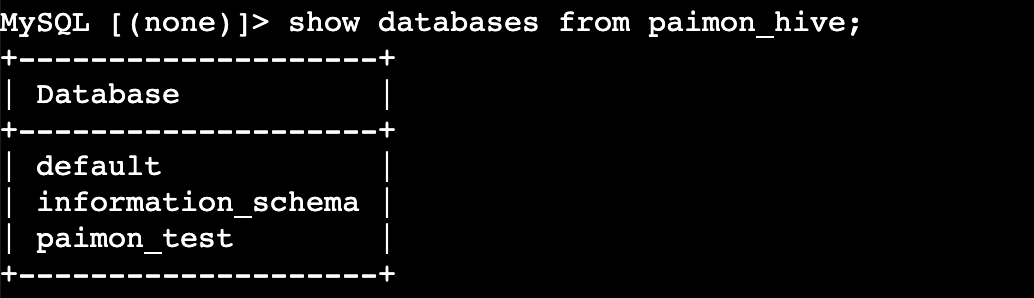
使用catalog
SET CATALOG <catalog_name>;
查询Paimon表
SELECT * FROM <table_name>;
