导航
E-MapReduce
搜索目录或文档标题搜索目录或文档标题
产品动态与公告
产品简介
发行版本
EMR on ECS
发行版本
版本说明
EMR 3.x版本
EMR-3.6.X 版本说明
EMR-3.4.X 版本
EMR 2.x版本
EMR 1.x版本
EMR 1.3.x版本
产品计费
快速入门
EMR on ECS 操作指南
集群管理
集群配置
集群监控
EMR on VKE 操作指南
EMR Serverless 操作指南
EMR Serverless 队列
EMR Serverless 实例(OLAP)
操作指南
数据湖查询(StarRocks)
性能调优
组件操作指南
MapReduce2
Hive
Spark
Spark(仅适用于EMR on VKE形态)
Spark(仅适用于EMR Serverless Spark形态)
Presto(仅适用于Serverless形态)
Knox
OpenLDAP
Ranger
HBase
Phoenix
Tez
Iceberg
StarRocks
数据湖分析
最佳实践
Proton
基础使用
高阶使用
Livy
Celeborn
Celeborn(仅适用于EMR on VKE形态)
Ray(仅适用于EMR on VKE及EMR Serverless形态)
Raycluster使用
最佳实践
EMR on ECS最佳实践
EMR on VKE最佳实践
开发参考
API 参考
EMR on ECS API参考
集群管理
节点组管理
用户管理
用户组管理
应用管理
EMR on VKE API参考
集群管理
应用管理
EMR Serverless API参考
SDK 参考
EMR on ECS SDK 参考
EMR Serverless SDK 参考
- 文档首页 /E-MapReduce/组件操作指南/Celeborn/Celeborn概述
Celeborn概述
最近更新时间:2024.01.29 16:33:20首次发布时间:2024.01.29 16:33:20
我的收藏
有用
有用
无用
无用
文档反馈
Apache Celeborn 是一个面向大数据计算引擎的统一中间数据服务,支持将引擎产生的 Shuffle、Spilled 等中间数据从引擎本身剥离到外置介质存储,并提供对于这些数据的读写和管理服务,从而真正消除计算节点对大容量磁盘的依赖。
1 组件说明
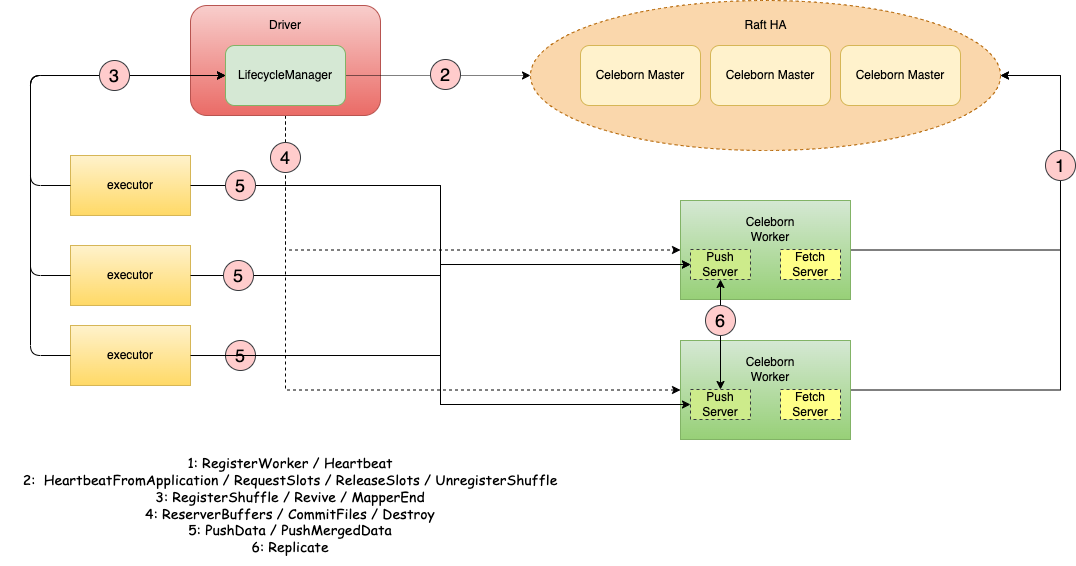
Celeborn 架构如上图所示,整体分为 Master、Worker 和 Client 三类组件:
Master:集群管理节点,提供对于集群的状态管理和资源分配能力,并支持基于 Raft 协议实现 HA 部署。
Worker:集群工作节点,核心在于提供对于 Shuffle 数据的存储、读写,以及管理能力,同时也提供对于集群的流控、健康检查,以及优雅降级等特性。
Client:集群接入客户端,大数据引擎通过 Client 实现与 Celeborn 集群的交互,实现 Shuffle 数据的读写,同时 Client 也提供了对于应用 Shuffle 数据的生命周期管理能力。
EMR 在部署拓扑上将 Celeborn Master 节点部署在 master 节点组上,将 Worker 节点部署在 core 节点组上,并为大数据引擎按照版本提供相应 Celeborn Client 开箱支持。此外,对于启用了 HA 的 EMR 集群而言,Celeborn 默认以 HA 的形式部署,即在 master 节点组所有节点上部署 Celeborn Master 节点。
2 更多信息
接下来,您可以访问:
如果您希望了解关于 Celeborn 更多详细信息,可以参考 Celeborn 官方文档。