导航
E-MapReduce
搜索目录或文档标题搜索目录或文档标题
产品动态与公告
产品简介
发行版本
EMR on ECS
发行版本
版本说明
EMR 3.x版本
EMR-3.6.X 版本说明
EMR-3.4.X 版本
EMR 2.x版本
EMR 1.x版本
EMR 1.3.x版本
产品计费
快速入门
EMR on ECS 操作指南
集群管理
集群配置
集群监控
EMR on VKE 操作指南
EMR Serverless 操作指南
EMR Serverless 队列
EMR Serverless 实例(OLAP)
操作指南
数据湖查询(StarRocks)
性能调优
组件操作指南
MapReduce2
Hive
Spark
Spark(仅适用于EMR on VKE形态)
Spark(仅适用于EMR Serverless Spark形态)
Presto(仅适用于Serverless形态)
Knox
OpenLDAP
Ranger
HBase
Phoenix
Tez
Iceberg
StarRocks
数据湖分析
最佳实践
Proton
基础使用
高阶使用
Livy
Celeborn
Celeborn(仅适用于EMR on VKE形态)
Ray(仅适用于EMR on VKE及EMR Serverless形态)
Raycluster使用
最佳实践
EMR on ECS最佳实践
EMR on VKE最佳实践
开发参考
API 参考
EMR on ECS API参考
集群管理
节点组管理
用户管理
用户组管理
应用管理
EMR on VKE API参考
集群管理
应用管理
EMR Serverless API参考
SDK 参考
EMR on ECS SDK 参考
EMR Serverless SDK 参考
- 文档首页 /E-MapReduce/组件操作指南/Ray(仅适用于EMR on VKE及EMR Serverless形态)/最佳实践/RayCluster开启Autoscaler
RayCluster开启Autoscaler
最近更新时间:2024.05.20 17:27:25首次发布时间:2024.05.20 17:27:25
我的收藏
有用
有用
无用
无用
文档反馈
通过配置Ray Autoscaler可以实现自动扩、缩集群。Autoscaler 通过根据task、actor或placement group所需的资源来调整集群中的节点 (Ray Pod) 数量来实现。Autoscaler采用逻辑资源的请求(以ray.remote表示),而不是物理资源利用率进行集群扩缩的。另外,Autoscaler可以降低workload成本,但会增加节点启动开销。
Ray Autoscaler作为一个单独的实体,在Ray head Pod中的一个sidecar容器内,如下图: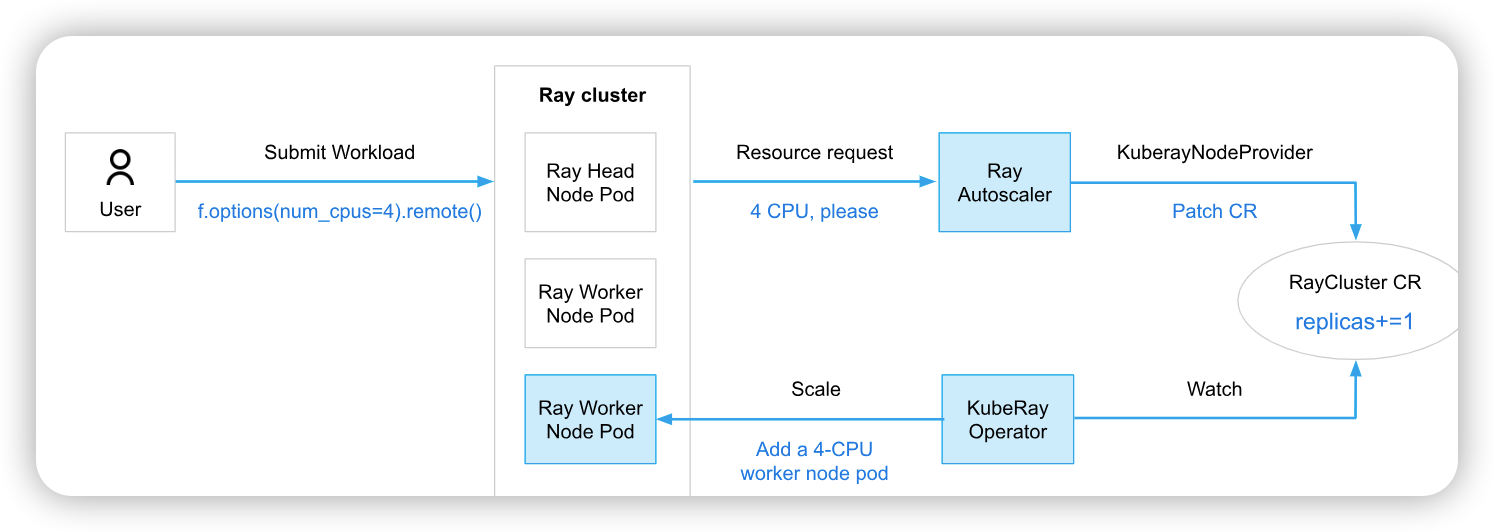
1 准备条件
部署EMR on VKE产品中Ray服务
提交作业到RayCluster,可以通过kubectl命令或者Ray的Client SDK提交。需要安装kubectl命令和部署Ray的环境,参考使用指导章节。
2 使用指导
部署RayCluster服务时,采用“通过YMAL添加”形式,在YAML文件中将enableInTreeAutoscaling配置true:


RayCluster部署完成后,可以在容器服务VKE中看下,在head的pod中查看autoscaler的状态,是否处于Running
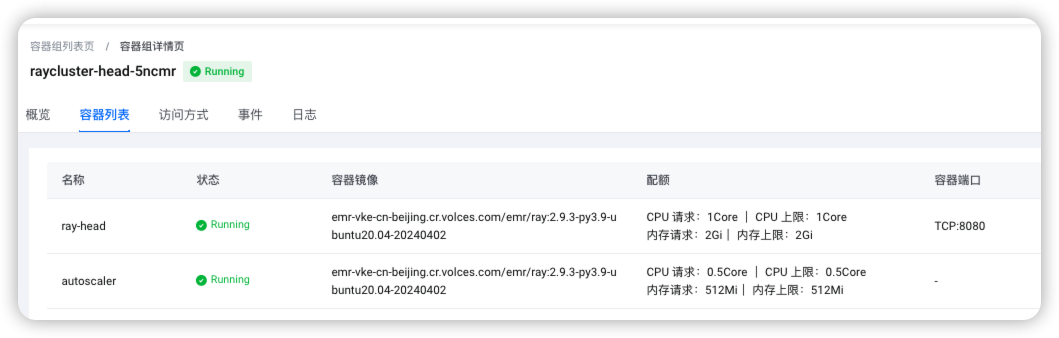
在Ray Cluster中运行提交如下Job。
定义了一个 long_running_task 远程函数,它会休眠600秒。提交了10个 long_running_task 任务:
import ray import time import os # 启动 Ray,使用 autoscaler 配置文件 ray.init(address='auto') @ray.remote(num_cpus=1) def long_running_task(): print(f"Sleeping for 600 seconds on node {os.uname()[1]}") time.sleep(600) return "Task completed" # 提交多个任务,这将触发 autoscaler 根据需要增加节点 object_refs = [long_running_task.remote() for _ in range(10)] # 等待所有任务完成 ray.get(object_refs) print("All tasks completed.")
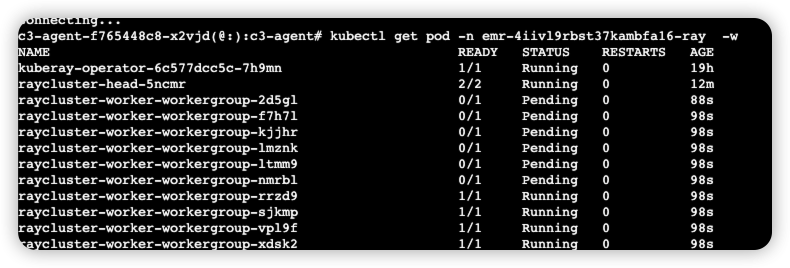
查看worker pod信息,有10个pod:
kubectl get pod -n <命名空间> -w
也可以查看autoscaler的日志,10个 long_running_task 任务,需要10个woker执行。从下面日志也可以看出来: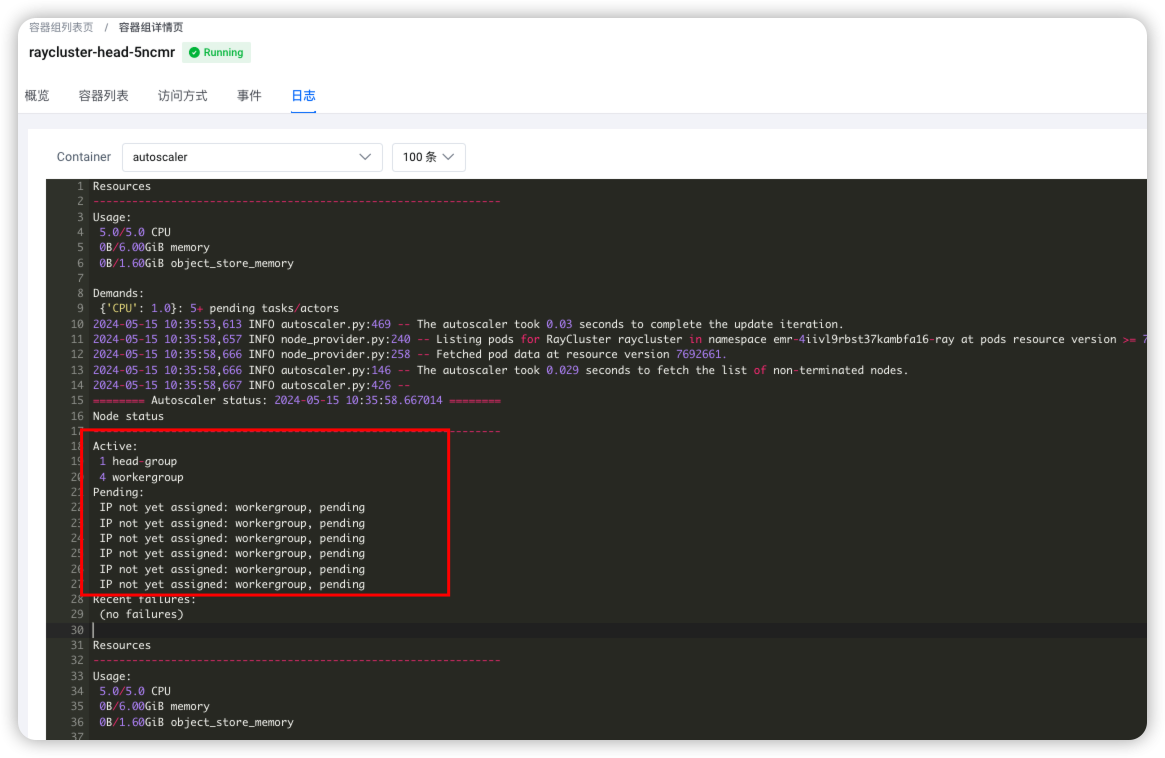
3 相关文档
获取更多相关信息可以参考官网KubeRay Autoscaling。